British Fleming once said: "don't wait for luck, you should try to master knowledge."
1 Preface
Hello, I'm amu! Your harvest is my love, and your praise is my recognition.
As a graduate with one-year development experience, we talked with the interviewer about the list type of basic data structure of redis in the previous chapter. With the accumulation of daily knowledge, we launched the scene of love and killing with the interviewer and the inner activities during the interview. By combining the application cases of the project in the actual scene and the details of knowledge points, we can answer the questions smoothly.
In this chapter, the interviewer will test the principle, scenario, precautions and actual combat of the hash data structure of redis.
Well, let's start our game with the interviewer. This will be a long, long interview process. Please!
2 understanding of data structure hash
Interviewer: "young man, let me test your hash data structure knowledge of redis today. It's not very powerful. I can't do it without giving you a blow. I don't have face. I don't want face?". It's over. How do you understand our next topic?
I'm not afraid to tell the interviewer, "Oh, I'm not afraid of it.". Say with great confidence:
The hash (hash or hash) in redis stores many key value pairs internally in the form of key - [field value]. It is also a two-dimensional structure of array + linked list (itself is also a key value pair structure). Because of this, we can usually use hash to store an object information. Here is my diagram of hash:
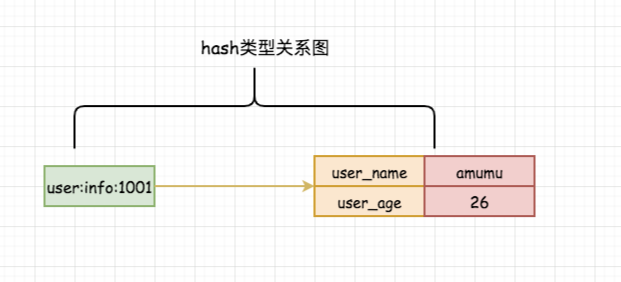
Note: from the above figure, we can see that the relationship of hash is actually the mapping of field - > value, and they are a pair.
Interviewer: "don't be complacent when you know a little concept. This is the most basic concept of development."
3 commonly used hash instructions
Interviewer: Based on your understanding of hash above, can you briefly introduce the more common instructions of hash?
Interviewer: "it's estimated that I'm young and think my experience is false. This is to test my foundation, isn't it? Then I'm not polite.". Well, let me talk about some operation instructions I often use.
1. Find select instruction operation:
hget Instruction: hget key field Get hash table key The value of the given field in does not exist and is returned nil;Time complexity O(1). hgetall Instruction: hgetall key Get hash table key If all fields and values in the do not exist, an empty list will be returned; Time complexity O(n),n Is the size of the hash table. hlen Instruction: hlen key Get hash table key in field If the quantity does not exist, return 0; Time complexity O(1). hmget Instruction: hmget key [field ...] Get hash table key The value of one or more given fields in does not exist and is returned nil;Time complexity O(n),n Is the number of fields given. hkeys Instruction: hkeys key Get hash table key If all fields in the table do not exist, an empty table will be returned; Time complexity O(n),n Is the size of the hash table. hscan Instruction: hscan key cursor(cursor) [MATCH pattern(Matching pattern)] [COUNT count(Specifies how many elements are returned from the dataset. The default value is 10 )] Get hash table key Match elements in. hvals Instruction: hlen key Get hash table key If the value of all fields in does not exist, an empty table will be returned; Time complexity O(n),n Is the size of the hash table. hexists Instruction: hexists key field Get hash table key in field Whether it exists, returns 1 if it exists, and returns 0 if it does not exist; Time complexity O(1). hstrlen Instruction: hstrlen key field Get hash table key If the field length does not exist, return 0; otherwise, return the length integer; Time complexity O(1). Copy code
2. Add insert instruction:
hset Instruction: hset key value Hash table key The value of the field in is set to value,If it does not exist, the setting will be created, otherwise the old value will be overwritten; Time complexity O(1). Note: if the field in the hash table already exists and the old value has been overwritten by the new value, return 0 instead of 1, and you can't make a mistake. hmset Instruction: hmset field value [field value ...] Multiple at a time field-value The data is set into the hash table, and the existing fields in the table will be directly overwritten; Time complexity O(n),n by field-value Number of. Note: different from hset,If the field value already exists in the hash table, the duplicate setting will be returned OK,Instead of 0. hsetnx Instruction: hsetnx key field value It can be set only when the field in the hash table does not exist, otherwise it is invalid; Time complexity O(1). Note: follow setnx The difference is that if the set field already has a value, the current operation will return a result set of 0 instead of OK. hincrby Instruction: hincrby key field increment Add a value to the specified field in the hash table; Time complexity O(1). Note: Execution hincrby The latest value of the field is returned after the command, not ok Or 1. Copy code
3. delete instruction operation:
hdel Instruction: hdel key field [field ...] Delete one or more fields in the hash table. If they do not exist, they will be ignored; Time complexity O(n),n Is the number of fields to delete. Note: the return value of the deletion operation is the number of successful deletions. Fields that do not exist will be ignored. Copy code
The following is the time complexity of sorting hash type commands. You can refer to this table:
| instructions | Time complexity |
|---|---|
| hget key field | O(1) |
| hgetall key | O(n), n is the size of the hash table |
| hlen key | O(1) |
| hmget key [field ...] | O(n), n is the number of given fields |
| hkeys key | O(n), n is the size of the hash table |
| hexists key field | O(1) |
| hstrlen key field | O(1) |
| hset key value | O(1) |
| hmset field value [field value ...] | O(n), n is the number of field values |
| hsetnx key field value | O(1) |
| hincrby key field increment | O(1) |
| hdel key field [field ...] | O(n), n is the number of fields to be deleted |
Interviewer: "eh, young people are good at sorting out function division! Yes, it's OK. Taking notes like this is also a good choice.". Well, I see on your resume that you are proficient in the application scenario of redis. Can you briefly say how you use hash data table in the project?
Interviewer: "this is not a piece of cake for Zhang Fei to eat bean sprouts.". Hello, interviewer; No problem. Let me elaborate on my specific scene
3.1 usage scenario of hash
Interviewer: in fact, the use of hash is the most common data structure in the project, so we usually use hash structure to store the basic information of website users; It can also be used to regularly count the total number of reading specified articles, etc. In fact, we all decide how to use it according to our own business scenarios.
Interviewer: Well, how do you use it? The interviewer still had a serious expression, as if I owed her tens of thousands of dollars. I didn't rely on the interview for being so serious.
3.1.1 user information
First, we create a relational user information data table to store the user's basic information (if there is separation of hot and cold data, or separate tables and databases. The practice is the same):
CREATE TABLE `mumu_user` ( `user_id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'user ID', `user_name` varchar(255) NOT NULL DEFAULT '' COMMENT 'User nickname', `user_pwd` varchar(64) NOT NULL DEFAULT '' COMMENT 'User password', `user_email` varchar(125) NOT NULL DEFAULT '' COMMENT 'User mailbox', `user_gender` tinyint(2) NOT NULL DEFAULT '0' COMMENT 'User gender 0-Confidentiality; one-Male; two-female', `user_desc` varchar(255) NOT NULL DEFAULT '' COMMENT 'User description', `create_at` int(10) NOT NULL DEFAULT '0' COMMENT 'Registration time', PRIMARY KEY (`user_id`), ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='User information basic table'; Copy code
We can add several pieces of user data:
insert into `mumu_user` (`user_name`, `user_pwd`,`user_email`,`user_desc`,`create_at`) VALUES('Li amu', '123456', '2511221051@qq.com', 'I'm amu', unix_timestamp());
insert into `mumu_user` (`user_name`, `user_pwd`,`user_email`,`user_desc`,`create_at`) VALUES('Li amu 1', '123456789', 'lw1772363381@163.com', 'I'm amu', unix_timestamp());
Copy codeThe schematic diagram of using Redis hash structure to store user information is as follows:

<?php
<?php
// Instantiate redis
$redis = new Redis();
$redis->connect('127.0.0.1', 6379);
//echo "Server is running: " . $redis->ping();
$data = [
'user_id' => 1001,
'user_name' => 'Li amu',
'user_email' => '2511221051@qq.com',
'user_desc' => 'I'm amu',
];
$key = sprintf('user:info:%u', $data['user_id']);
//Batch adding data to hash table: hMset
$result = $redis->hMSet($key, $data);
$redis->expire($key,120);
if ($result) exit('Batch setting of user information succeeded!');
exit('Failed to set user information in batch!');
-- Terminal query
127.0.0.1:6379> HGETALL user:info:1001
1) "user_id"
2) "1001"
3) "user_name"
4) "\xe6\x9d\x8e\xe9\x98\xbf\xe6\xb2\x90"
5) "user_email"
6) "2511221051@qq.com"
7) "user_desc"
8) "\xe6\x88\x91\xe6\x98\xaf\xe9\x98\xbf\xe6\xb2\x90"
Copy codeInterviewer: Uh huh, this is the most basic grammar usage scenario. There is no special emphasis. Can you talk about the use in other aspects?
Interviewer: Yes, I'll give a simple case. Let's use a small scene of hash ing in a small part of an activity.
3.1.2 lottery scene
Scene: the company is going to do a lucky draw. There are 8 items on the website that can be lucky drawn. The biggest one is a luxury Lamborghini 🚘, Limit quantity 2; Other props are limited to the number of lucky draw, one of which is unlimited, and all users must win the lucky draw.
How to consider: ① ensure that users must win; ② ensure that props are not limited to exceeding; ③ ensure atomic operation in case of concurrency
So how do most of the young partners who have just entered the cottage solve these three situations? There may be such operations: in order to ensure that there is no limit on the number of props, redis - > get (ID) the number of props first, and then compare the results with the limited number; This kind of operation is not impossible, but we should consider how to ensure atomic operation in the case of high concurrency.
Solution: ① when the probability distribution of props is ok, conduct a thorough operation on the limited number of props; ② detect the number of rewards in each user's lottery; ③ in case of Concurrency: 1 We can use hincrby atomic operation to record the number of times the prop is drawn 2 You can also use get and set, but redis+lua must be used to implement atomic operations to ensure that the data is ok
The following is a code case:
// Lottery props list props list can be expanded to store multiple hash es to facilitate unified data analysis
const DRAW_PROP_LIST = [
[
'prop_id' => 123,
'prop_name' => 'Selected class notes',
'limit' => 10,
'chance' => 15,
],
[
'prop_id' => 1234,
'prop_name' => 'Luxury Lamborghini',
'limit' => 2,
'chance' => 10,
],
[
'prop_id' => 12345,
'prop_name' => 'python Introductory practical tutorial',
'limit' => 3,
'chance' => 5,
],
[
'prop_id' => 123456,
'prop_name' => 'k8s Practical books',
'limit' => 1,
'chance' => 70,
],
];
//Random chance probability method
$reward = DRAW_PROP_LIST[randomChance(array_column(DRAW_PROP_LIST, 'chance'))];
$key = "prop:count:record";
for ($i = 1; $i < 10; $i ++) {
$count = $redis->hIncrBy($key, $reward['prop_id'], 1);
echo $count.'-';
if ($count > $reward['limit']) {
echo 'Current prop id by'.$reward['prop_id'].'The lottery has been completed. You can consider returning the bottom data to the user';
break;
}
}
// The item id is 1231-452, and the result is returned to the current user
Copy codeAdditionally, we can also use redis+lua to ensure atomic operation settings:
$redis = new Redis();
$redis->connect('127.0.0.1', 6379);
//echo "Server is running: " . $redis->ping();
$lua = <<<SCRIPT
local _key = KEYS[1]
local limit = ARGV[1]
local num = ARGV[2]
local current_num = redis.call('get', _key)
current_num = tonumber(current_num) or 0
num = tonumber(num)
limit = tonumber(limit)
if (current_num + num) <= limit then
local ret, err = redis.call('set', _key, current_num + num)
if ret then
redis.call('expire', _key, 120)
return 1
end
end
return 0
SCRIPT;
$prop_id = 123456;
$key = 'prop:count:record:'.$prop_id;
for ($i = 1; $i < 10; $i++) {
$result = $redis->eval($lua, array($key, 5, 1), 1);
if ($result == 0) {
echo 'Current prop id by'.$prop_id.'The lottery has been completed. You can consider returning the bottom data to the user';
break;
}
}
$redis->close();
Copy codeInterviewer: we can observe from the above code. Of course, it's best to run the test locally; Even if we run multiple concurrent requests 1w times, the current number of props will not exceed the limit, which means that the acquisition and setting are atomic operations.
Interviewer: "I didn't expect that the young man would use lua script. It seems that I underestimated you, but it's a good bonus.". So can you analyze the problems caused by different cache settings? For example, set stores the entire user information, set stores the user information separately, and hash stores the user information.
Interviewee: "I need to say this again. Can't I? It's so simple to ask?", I asked for three times in a row, and I was still scolding:
set aggregate storage:
Advantages: simple and convenient storage, reasonable design, memory utilization can be improved after serializing data.
Disadvantages: serialization and deserialization have performance overhead on the server, and the operation is inconvenient. If only one value is modified, all data needs to be updated and serialized into redis, which is troublesome and time-consuming. Not recommended
set distributed storage:
set user:info:1001:user_name Amu Copy code
Advantages: it is easy for users to update the information of each set field, and it is easy to update the information of each set field.
Disadvantages: how many fields need to occupy how many keys, poor maintainability, batch query of user information, increased consumption performance and large storage memory. Refuse to use
hash storage: each user attribute can be saved with only one key.
hmset user:info:1001 user_name amumu user_email 2511221051@qq.com Copy code
Advantages: transparent storage, simple operation, easy maintenance and less memory occupation (this depends on the amount of information, which is related to the storage code)
Disadvantages: if the stored field is too long, it will lead to the conversion of ziplist (compressed list) and hashtable (hash table) internal codes. If all hash tables are used for storage, it will lead to hash consumption and occupy more memory space.
Interviewer: Uh huh, the analysis is quite in place. I think you just mentioned the advantages and disadvantages of the two coding formats of hash. Can you say it in detail?
Interviewer: "well, it's a little too much to keep asking. There's a saying that goes to the end. The interviewer must be testing my skills, so I can't persuade my ability.". Hello, interviewer, let me talk about the two encoding formats of hash table storage!
3.1.3 ziplist (compressed list OBJ_ENCODING_ZIPLIST)
Redis is very tricky. It will automatically adapt which coding scheme is the best according to the amount of data. That is to say, this operation is completely transparent to users.
The default configuration of ziplist for redis is as follows (it can be modified according to business requirements):
hash-max-ziplist-entries = 512 // Number of hash elements hash-max-ziplist-value = 64 // Hash field, field value length Copy code
So how should we understand this configuration? How does hash decide which encoding format to use and when to use ziplost?
The following conditions must be met at the same time: 1,The number of key value pairs saved in the hash table cannot be greater than 512 num < 512 2,The length of all key value strings saved in the hash table cannot be greater than 64 bytes length < 64 Copy code
redis will use obj only when all the above conditions are met_ ENCODING_ Ziplist to store the key.
Interviewer: we only rely on oral language. As the saying goes, there is no evidence. We will verify it by actual operation.
localhost:6379> hmset test id 12345 name I'm amu OK localhost:6379> object encoding test //object encoding is used to view the encoding format "ziplist" localhost:6379> hset test test_name "I'm amu I'm amu I'm amu I'm amu I'm amu I'm amu I'm amu I'm amu I'm amu I'm amu I'm amu I'm amu I'm amu I'm amu I'm amu" // 132 bytes must be greater than 64 bytes (integer) 1 localhost:6379> object encoding test "hashtable" Copy code
The above terminal test has verified that when the length of a field in the hash table is greater than 64 bytes, the encoding format will be converted from ziplost to hashtable.
Interviewer: "it's still very detailed. Although it's not deep enough, the answer is still quite good. Lying in the slot, I suddenly want to ask if I have understood the implementation of the underlying source code of hash. What can I do? Ask and try? Well, that's it. Ask a little.". It's very good. You have a good understanding of ziplist compression and know how to check the encoding method. Can you try to talk about the underlying implementation of hash encoding conversion?
Interviewer: lying trough, lying trough, lying trough, so cruel, ask me the bottom c? It seems that I have forgotten almost, which is really going to kill me; I read it in my mouth. Try to look at the source code and explain it to the interviewer. Just fool around.
Let's take a simple look at the underlying code of hash switching coding:
In fact, I don't think I need to look at the source code, just know what's going on; Class C doesn't need to understand how to develop, or it doesn't need to understand how to develop. It must be a matter of the not understanding.
-- At present, I use redis5.0 Version source code path t_hash.c ,This case can be found everywhere on the Internet
-- About 45 lines
for (i = start; i <= end; i++) {
if (sdsEncodedObject(argv[i]) &&
// If the length of the field value in the hash table exceeds the configured 64 bytes, it will be converted to OBJ_ENCODING_HT coding
sdslen(argv[i]->ptr) > server.hash_max_ziplist_value)
{
hashTypeConvert(o, OBJ_ENCODING_HT); --Set storage encoding format
break;
}
}
-- 237 Line left and right when hash Field length(total)When it is greater than the 512 specified in the configuration, the internal will be converted to OBJ_ENCODING_HT(Hash dictionary)Coding format
if (hashTypeLength(o) > server.hash_max_ziplist_entries)
hashTypeConvert(o, OBJ_ENCODING_HT); --Set storage encoding format
} else if (o->encoding == OBJ_ENCODING_HT) {
dictEntry *de = dictFind(o->ptr,field);
Copy codeThe structure diagram of compressed list and hash table can be drawn to facilitate a better understanding:

The parameter analysis of the data is as follows:
- 1. Zlbytes: the amount of memory used to store the compressed list (four byte unsigned integers). You can set the memory size of the list through zlbytes.
- 2. zltail: record the offset from the entry to the starting address, accounting for 4 byte s.
- 3. zllen: the total number of entry nodes in the record list, occupying 2 byte s.
- 4. entry: list the nodes that store data. The type can be byte array or integer.
- 5. zlend: the end of the list, occupying 1 byte and constant 0xff (indicating binary 1111).
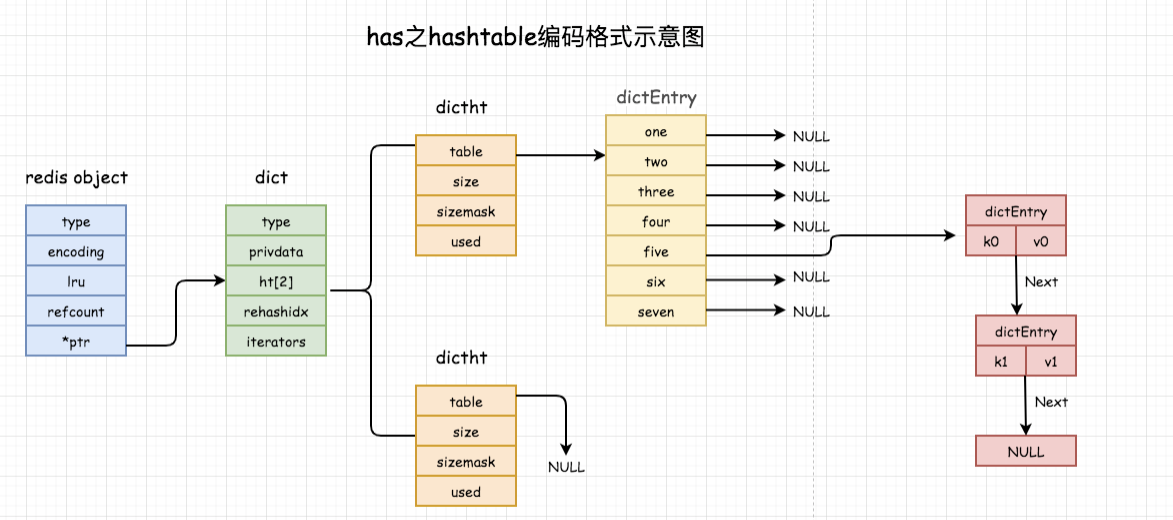
As can be seen from the above figure structure, hashtable is the real hash table structure or dictionary structure (nested layer by layer), so it can realize O(1) read and write operation, and the operation efficiency is very high. The relationship is as follows:
1,type: It's a point dictType Structure, which holds a series of functions used to operate specific types of key value pairs;
2,privdata: Save the optional parameters that need to be passed to the above specific function;
3,ht[2]: Are two hash tables. Generally, only two hash tables are used ht[0],Only when the number of key value pairs in the hash table exceeds the load(Too many elements)Key value pairs are migrated to ht[1],This step of migration is called rehash(Rehash);
4,rehashidx: Record current rehash Progress, rehash When finished, reset to-1
5,table: Is an array, and each element of the array is a pointer dictEntry Pointer to the structure;
6,size: Record the size of the hash table, i.e table The size of the array and must be a power of 2;
7,sizemask: Used to map hashed keys and the value is always equal to size-1. Mapping method: hash value and sizemask Perform bit and operation.
8,used: The number of existing records in the hash table;
9,key: Is the key in the key value pair;
10,v Is the value in the key value pair. It is a joint type, which is convenient for storing various structures;
11,next Is a linked list pointer that points to the next hash table node. It concatenates multiple key value pairs with the same hash value to solve key conflicts.
Copy codeInterviewer: "well, I don't know much about the underlying code logic. The young man is hiding a little deep! I can't let him see that I don't understand these. I must calm down and stabilize the war situation, perfunctory and pass by." 10000 people ran away in my heart. I didn't expect a little guy with less than a year of experience to know the underlying code principle, explain it and mutter in his mouth.
Why should we use ziplost instead of hashtable in our daily development? So how does ziplist implement hash storage? Two consecutive questions from the interviewer:
Why use ziplist?
1. Compared with hashtable, the overall structure of compressed list reduces the use of pointers and memory. 2. Ziplost uses a more compact structure, with continuous storage between elements, which is much better than hashtable in saving memory.
How does ziplist implement hash storage?
It compactly saves two nodes of the same key value pair, with the key in front of the node and the value behind the node; If a new key value pair is inserted, it will be placed at the end of the ziplost table.
Interviewer: ok, ok, ok, ok; Then come here first and have a rest.
Interviewer: Here you are 🖕 From my own experience, it's really hard for me to find a small development for a year. Fortunately, I didn't continue to ask the knowledge points such as hash algorithm, hash collision, hash expansion and contraction and progressive hash, otherwise it would be useless and I won't be able to answer. If you want to know, you can go down to have a private look at this information and understand the context; I won't elaborate here. We have plenty of time to discuss drawing analysis together.
Final summary
This article specifically describes some hash related questions that the interviewer will ask in the actual interview. Of course, the object of our exposition is: just graduated, junior and intermediate engineers, and even some fake advanced developers, who can only use it, but do not look at some relevant use principles, they are likely to be pass ed out in the interview stage.
Redis's dictionary data structure is a commonly used cache command, and it is also a problem that occurs frequently in interviews. We use scenarios to guide and think about some characteristics of hash and the principle of storage coding selection. So you have different views, you can leave a message!
The above are my personal understanding of the use, scenario, principle and encoding conversion of redis hash structure. If there are any errors, please correct them in the comment area.
reference
Design and implementation of Redis (Second Edition)
Hayao Miyazaki once said, "what you meet is God's will, and what you have is luck. What's wrong with imperfection? Everything has cracks. That's where the light comes in."
Finally, welcome to my blog
The official account is "amah", which updates the knowledge and learning notes from time to time. I also welcome direct official account or personal mail or email to contact me. We can learn together and make progress together.
Well, I'm a mu, a migrant worker who doesn't want to be eliminated at the age of 30 ⛽ ️ ⛽ ️ ⛽ ️ . It's not easy to think that the words written by "a Mu" are somewhat material: 👍 Seeking attention 💖 For sharing. Thank you. I'll see you next time.