Catalogue
1, Implementation principle of hashmap
Relationship between hashcode and equals
4, put and get methods of hashmap
5, The difference between hashmap and hashtable
1, Implementation principle of hashmap
Hash table is an array + linked list structure, which can ensure that if there is no hash collision in the process of traversal, addition and deletion, it can be completed only once, and the time complexity can be guaranteed at O(1). In jdk1 7 is just a simple array + linked list structure, but if there are too many hash collisions in the hash table, the efficiency will be reduced, so in jkd1 This situation is controlled in 8. When the length of the linked list on a hash value is greater than 8, the data on the node is no longer stored in the linked list, but transformed into a red black tree.
Linked list:
How is the new Entry node inserted into the linked list?
Java 8 used to be a header insertion method, which means that the new value will replace the original value, and the original value will be pushed to the linked list
After java8, the used tail is inserted, because there is a red black tree in the linked list after java8. You can see that there are many more logical judgments of if else in the code. The introduction of red black tree cleverly reduces the time complexity of original O(n) to O(logn). Using header insertion will change the order of the elements in the linked list, but if tail insertion is used, the original order of the elements in the linked list will be maintained during capacity expansion, and the problem of link formation will not occur.
That is to say, it was originally a - > B. after capacity expansion, the linked list is still a - > B
Java 7 may cause an endless loop when multithreading HashMap. The reason is that the order of the front and rear linked lists is inverted after capacity expansion and transfer, and the reference relationship of the nodes in the original linked list is modified during the transfer process.
Under the same premise, Java 8 will not cause an endless loop because the sequence of the front and rear linked lists remains unchanged after the capacity expansion and transfer, and the reference relationship of the previous nodes is maintained.
Does that mean that Java 8 can use HashMap in multithreading?
I think even if there is no dead loop, I can see from the source code that the put/get methods do not add synchronization lock. The most common case of multithreading is that the value of put in the last second cannot be guaranteed and the original value is still obtained in the next second, so thread safety cannot be guaranteed.
2, Extension mechanism
The capacity of the array is limited. If the data is inserted many times, it will be expanded when it reaches a certain number, that is, resize.
The source code is as follows:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}The specific process is as follows
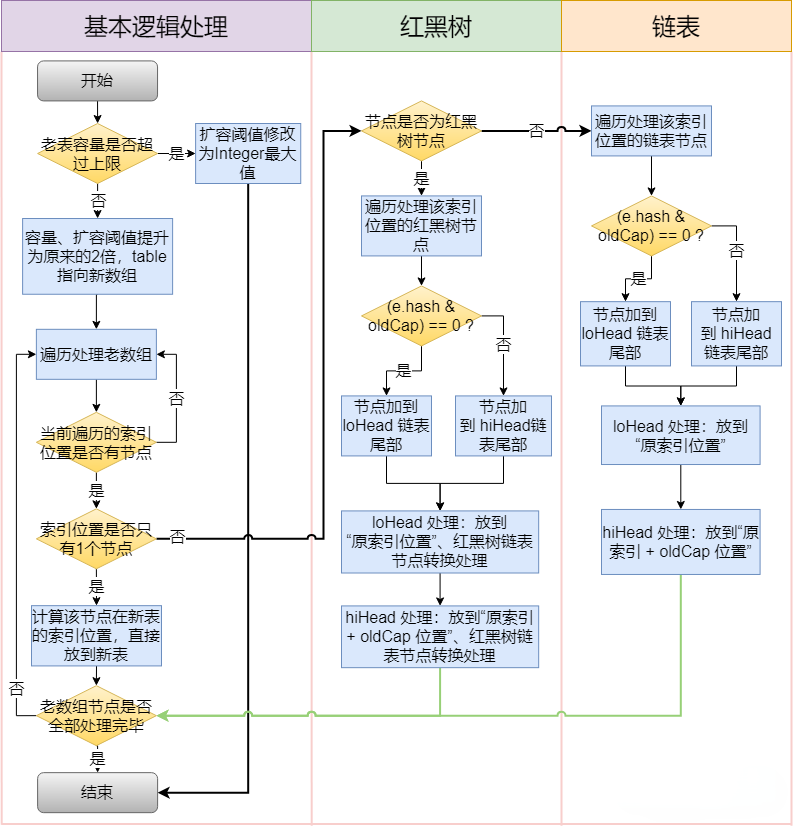
2.1 When to expand capacity
Two important factors:
Capacity: current length of HashMap
LoadFactory: load factor. The default value is 0.75f
How to understand it? For example, the current capacity is 100. When you save the 76th one, you judge that it needs to be resize d, then expand the capacity. However, the capacity expansion of HashMap is not as simple as expanding the point capacity
2.2 how to expand capacity
① Create a new empty Entry array, which is twice as long as the original one
② ReHash: traverse the original Entry array and ReHash all entries to the new array
Why re hash?
Because after the length is expanded, the hash rules will also change
hash formula - > index = hashcode (key) & (length-1)
3, hash algorithm
At jdk1 In the implementation of 8, the algorithm of high-order operation is optimized. It is realized through the high 16 bit XOR low 16 bit of hashCode(): (H = k.hashCode()) ^ (H > > > 16), mainly considering speed, efficiency and quality. The hash value of int obtained by the above method, and then the location of the object saved in the data is obtained through H & (table. Length - 1).
hash source code:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}HashMap we know that the default initial capacity is 16, that is, there are 16 barrels. (when we create a HashMap, the Alibaba specification plug-in will remind us that it is best to assign an initial value, and preferably a power of 2. This is for the convenience of bit operation. Bit and operation is much more efficient than arithmetic calculation. The reason why 16 is selected is to serve the algorithm for mapping Key to index.)
Then why use 16 without anything else?
Because when using a number that is not a power of 2, the value of Length-1 is that all binary bits are 1. In this case, the result of index is equal to the value of the last few bits of HashCode.
As long as the input HashCode itself is evenly distributed, the result of the Hash algorithm is uniform.
This is to achieve uniform distribution.
What does hashmap use to calculate which bucket to put the put object into
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}Look at (n - 1) & hash, that is, hashmap calculates the array subscript through the hash value of the array length - 1 & key. The hash value here is the value calculated above (H = key. Hashcode()) ^ (H > > > 16)
Note: array length - 1, ^ operation, > > > 16, these three operations are to make the key s disperse in the hashmap bucket as much as possible
Using & instead of% is to improve computing performance
1. Why should the array length be - 1, direct the array length & key Can't hashcode?
subscript out of bounds
2. Why length-1 & key Hashcode calculates subscripts instead of using key hashCode%length?
① , in fact (length-1) & key Hashcode calculated value and key Hashcode% length is the same
② . only when length is to the nth power of 2, (length-1) & key Hashcode is equal to key hashCode%length
③ Using & instead of% is to improve the computing performance. For the processor, the efficiency of & operation is higher than% operation. It is so simple. In addition, the efficiency of division is not & high
3. Why do you need to perform ^ operation? Can't | operation and & operation?
XOR operator, the nth of the first operand is in the nth bit of the second operand, and the opposite is 1, otherwise it is 0
4. Why > > > 16, > > > 15?
This is an unsigned right shift of 16 bits. The number of bits is not enough. The high bit is supplemented by 0
Now, for the metaphysics in ^ operation, in fact > > > 16 and ^ operation complement each other. This set of operations is to retain the characteristics of high 16 bits and low 16 bits of hash value, because the low 16 bits of binary code after array length (calculated according to the default 16) minus 1 is always 1111. We are determined to make 1111 and hash value related as much as possible, but obviously, If it is only 1111 hash value, 1111 will only be associated with the lower four bits of the hash value, that is, the value generated by this algorithm only retains the characteristics of the lower four bits of the hash value, and all the previous 28 bits are lost;
Because the & operation is 11111 only when it is 1, we can't change it. We can only start with the hash value, so the author of hashMap adopts key Hashcode() ^ (key. Hashcode() > > > 16) is a clever perturbation algorithm. The hash value of the key is shifted to the right by 16 bits without symbols, and then ^ calculated with the original hash value of the key, which can well retain all the characteristics of the hash value. This discrete effect is what we want most.
The above two paragraphs are the essence of understanding > > > 16 and ^ operations. If you don't understand them, I suggest you take a break and come back. In short, remember, the purpose is to make the array subscripts more scattered
To add a little more, in fact, you don't have to shift 16 bits to the right. As shown in the following test, shifting 8 bits to the right and 12 bits to the right can have a good disturbance effect, but the binary code of hash value is 32 bits, so the most ideal must be halved
Relationship between hashcode and equals
In java:
If hashcode() of two objects is equal, equals is not necessarily equal
If the equals() of two objects are equal, hashcode() must be equal
When overriding the equals() method, you must override hashcode. Why?
If we have a certain understanding of the principle of HashMap, this result is not difficult to understand. Although the keys used in the get and put operations are logically equivalent (they are equivalent through equals comparison), since the hashCode method is not rewritten, the key(hashcode1) – > hash – > indexfor – > final index position during the put operation, and the key(hashcode1) – > hash – > indexfor – > final index position when the value is retrieved through the key, Because hashcode1 is not equal to hashcode2, it does not locate an array position and returns a logically wrong value null (it may also happen to locate an array position, but it will also judge whether the hash value of its entry is equal, as mentioned in the get method above.)
Therefore, when rewriting the equals method, you must pay attention to rewriting the hashCode method. At the same time, you must ensure that two objects that are equal are judged by equals, and calling the hashCode method will return the same integer value. If equals judges that two objects are not equal, their hashcodes can be the same (but hash conflicts will occur, which should be avoided as far as possible).
4, put and get methods of hashmap
HashMap in JDK7 adopts the method of bit bucket + linked list, that is, we often say hash linked list, while JDK8 adopts bit bucket + linked list/ Red black tree , this is about the put method in JDK8.
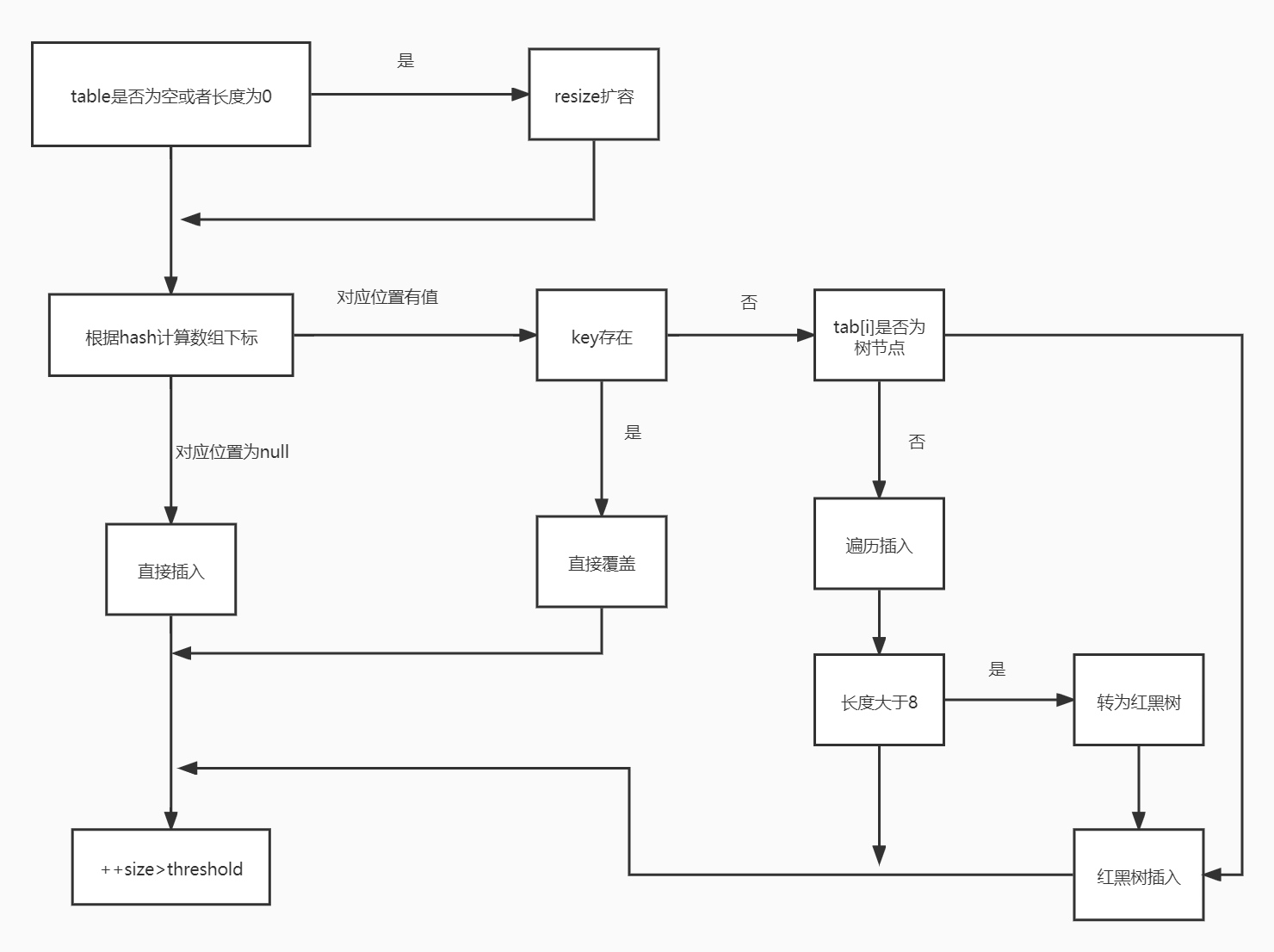
HashMap put source code:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}HashMap is in the put method, which uses hashCode() and equals() methods. When we call the put method by passing a key value pair, HashMap uses Key hashCode() and hash algorithm to find the index storing the key value pair. If the index is empty, it is directly inserted into the corresponding array. Otherwise, judge whether it is a red black tree. If so, it is inserted into the red black tree. Otherwise, traverse the linked list. If the length is not less than 8, turn the linked list into a red black tree, and insert it after successful conversion.
HashMap get method source code:
public V get(Object key) {
//If the key is null, you can directly go to table[0] to retrieve it.
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}The get method returns the corresponding value through the key value. If the key is null, go directly to table[0] to retrieve it. Let's take another look at the getEntry method
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
//Calculate the hash value through the hashcode value of the key
int hash = (key == null) ? 0 : hash(key);
//Indexfor (hash & length-1) obtains the final array index, then traverses the linked list and finds the corresponding records through the equals method
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
} It can be seen that the implementation of the get method is relatively simple. Key (hashCode) - > hash -- > indexfor -- > the final index position, find the corresponding position table[i], then check whether there is a linked list, traverse the linked list, and compare and find the corresponding records through the equals method of key. It should be noted that some people think that it is unnecessary to judge e.hash == hash after locating the array position and then traversing the linked list. It can only be judged by equals. In fact, it is not. Imagine that if the passed in key Object rewrites the equals method but does not rewrite the hashCode, and the Object happens to be located in the array position. If only equals is used to judge, it may be equal, but its hashCode is inconsistent with the current Object. In this case, according to the hashCode convention of the Object, the current Object cannot be returned, but null should be returned.
5, The difference between hashmap and hashtable
① Both have the same storage structure and conflict resolution methods.
② The default capacity of Hashtable without specifying capacity is 11, while that of HashMap is 16. Hashtable does not require that the capacity of the underlying array must be an integer power of 2, while HashMap requires an integer power of 2.
③ Neither key nor value in Hashtable is allowed to be null, while both key and value in HashMap are allowed to be null (only one key can be null, while multiple values can be null). However, if there is a put (null, null) operation in the Hashtable, the compilation can also pass, because both key and value are Object types, but a NullPointerException exception will be thrown at runtime.
④ When Hashtable is expanded, the capacity will be doubled + 1, while when HashMap is expanded, the capacity will be doubled.
⑤ Hashtable calculates the hash value by directly using the hashCode() of the key, while HashMap recalculates the hash value of the key. Hashtable uses the% operation when calculating the location index corresponding to the hash value, while HashMap uses the & operation when calculating the location index
summary
HashMap source code, each line is very interesting, and it is worth taking time to study and deliberate.
By looking at its underlying source code and combining the relevant blogs written by others, I believe everyone can gain something
The above is my personal study note. If there is any deficiency, please add
Ao Bing said, "the more you know, the more you don't know."
Author: Xiao Li in the code world