1 Nosql overview
1.1 why use Nosql
1.1.1 the age of single machine MySQL!

In the 1990s, the number of visits to a basic website is generally not too large, and a single database is completely enough! At that time, more use of static web ~ servers didn't have much pressure at all! In this case: what is the bottleneck of the whole website?
- If the amount of data is too large for one machine.
- The data index (B+ Tree) can't fit into a single machine memory.
- The number of accesses (mixed reading and writing) can't be borne by one server.
1.1.2 Memcached + MySQL + vertical split (read write separation)
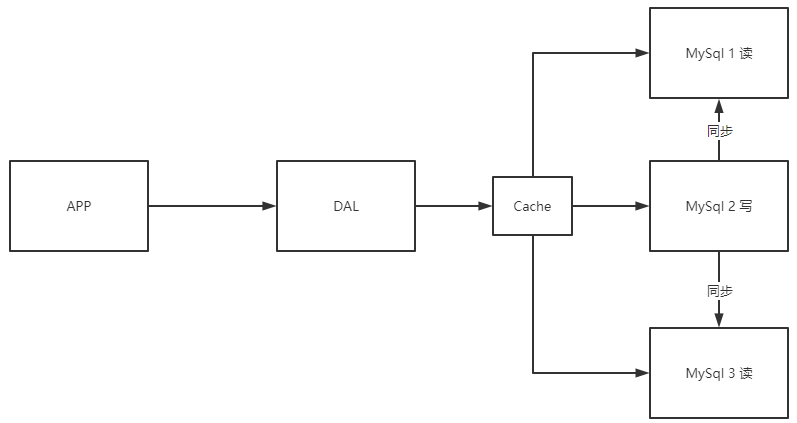
80% of the website is reading. It's very troublesome to query the database every time! So we want to reduce the pressure on data. We can use cache to ensure efficiency!
Development process: optimize data structure and index - > file cache (IO) - > memcached.
1.1.3 database and table splitting + horizontal splitting + MySQL Cluster
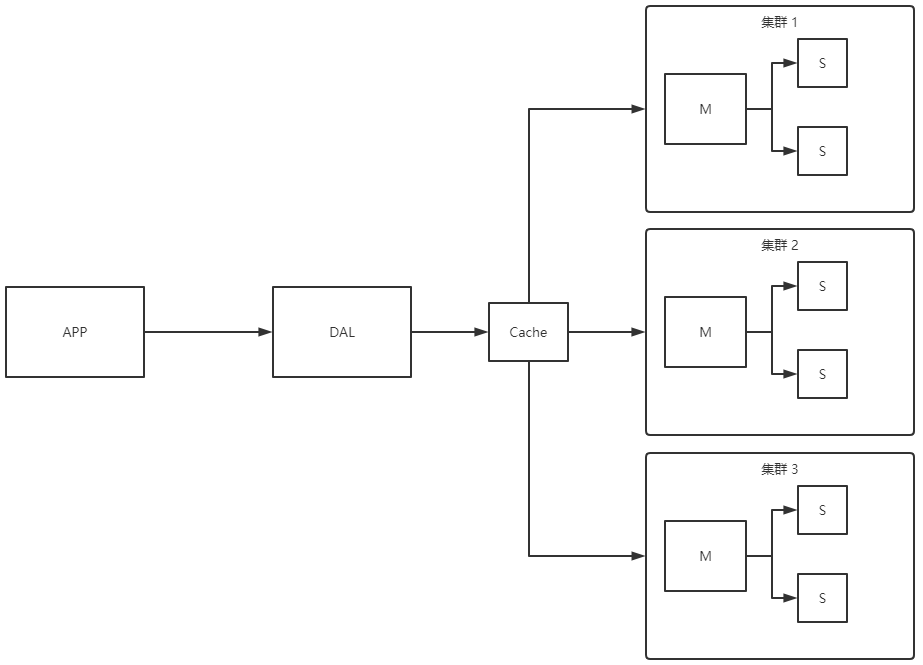
- Early years MyISAM: watch lock, very affect efficiency! A serious lock problem will occur when you send high and low.
- Use Innodb: row lock.
- Slowly start using sub database and sub table to solve the pressure of writing! When did MySQL introduce table partitioning! There are not many companies in this
use. - MySQL Cluster can well meet all the needs of that era.
1.1.4 today's era
- MySQL and other relational databases are not enough! There is a lot of data and changes quickly ~!
- Some MySQL use it to store some large files, blogs and pictures! The database table is very large, so the efficiency is low! If there is a number
According to the database, this data is specially processed. MySQL pressure becomes very small.
At present, there is a basic Internet Project:

User's personal information, social networks, geographical location. User generated data, user logs and so on are growing explosively! At this time, we need to use Nosql database. Nosql can handle the above situations well!
1.2 what is NoSQL
NoSQL = Not Only SQL (not just SQL) is relative to relational database and generally refers to non relational database. With web2 0 the birth of the Internet! The traditional relational database is difficult to deal with web2 0 era! NoSQL is developing rapidly in today's big data environment. Redis is the fastest growing technology, and it is a technology we must master at present!
1.2.1 NoSQL features
- Easy to expand (there is no relationship between data, so it is easy to expand).
- Large amount of data and high performance (Redis writes 80000 times and reads 110000 times a second). NoSQL's cache record level is a fine-grained cache with high performance
Can be higher). - Data types are diverse.
- Traditional RDBMS (relational database) and NoSQL
conventional RDBMS - Structured organization - SQL - Data and relationships exist in separate tables - Operation, data definition language - Strict consistency - Basic transaction - .....
Nosql - Not just data - There is no fixed query language - Key value pair storage, column storage, document storage, graphic database (social relationship) - Final consistency - CAP Theorem sum BASE (Remote (multi live) - High performance, high availability and high scalability - ....
1.2.2 3V + 3 high
3V in the era of big data: it mainly describes problems
- Massive Volume
- Diversity
- Real time Velocity
Three highs in the era of big data: mainly the requirements for procedures
- High concurrency
- Highly scalable
- High performance
1.3 four categories of NoSQL
KV key value pair:
- Redis
- Tair
- MemCache
Document database:
- MongoDB
- MongoDB is a database based on distributed file storage, written in C + +, which is mainly used to process a large number of documents!
- MongoDB is a product between relational database and non relational data! MongoDB is a non relational number
According to the library, it has the richest functions and is most like a relational database!
- ConthDB
Column storage database:
- HBase
- distributed file system
Figure relational database:
- Store relationships, such as social networks
- Neo4j
- InfoGrid
Comparison table of the four
| classification | give an example | data model | advantage | shortcoming | Typical application scenarios |
|---|---|---|---|---|---|
| Key value storage database | Redis | The Key Value pair from Key to Value is usually implemented by hash table | Fast search speed | Data is unstructured (usually only treated as string or binary data) | Content caching is mainly used to handle the high access load of a large amount of data, as well as some log systems |
| Document database | MongoDB | The key value pair corresponding to key value. Value is structured data | The data structure requirements are not strict, and the table structure is variable (the table structure does not need to be defined in advance like the relational database) | The query performance is not high, and there is a lack of unified query syntax | Web application |
| Column storage database | Hbase | It is stored in column clusters to store the same column of data together | Fast search speed, strong scalability and easier distributed expansion | Relatively limited functions | Distributed file system |
| Graph relational database | Neo4J | Figure structure | Using graph structure related algorithms (such as shortest path addressing, N-degree relationship search, etc.) | In many cases, it is necessary to calculate the whole graph to get the required information, and this structure is not good for distributed clustering scheme | Social networks, recommendation systems, etc |
2. Getting started with redis
2.1 general
- What is Redis
- Redis (Remote Dictionary Server), i.e. remote dictionary service. It is an open source log and key value database written in ANSI C language, supporting network, memory based and persistent, and provides API s in multiple languages.
- Redis will periodically write the updated data to the disk or write the modification operation to the additional record file, and on this basis, redis implements
Master slave synchronization.
- What can Redis do
- Memory storage and persistence. In memory, power is lost immediately, so persistence is very important (rdb, aof)
- Efficient and can be used for caching
- Publish subscribe system
- Map information analysis
- Timer, counter (views!)
- characteristic
- Diverse data types
- Persistence
- colony
- affair
- Red official website address
Official website: https://redis.io/
Chinese website: http://www.redis.cn/
2.2 Linux Installation
1. Download the installation package redis-6.2.4 tar. gz
2. Unzip the Redis installation package to / opt

3. After entering the extracted file, you can see our redis configuration file

4. Basic environmental installation
# Install c compilation environment yum install gcc-c++ # Start compilation make # Verify installation make install
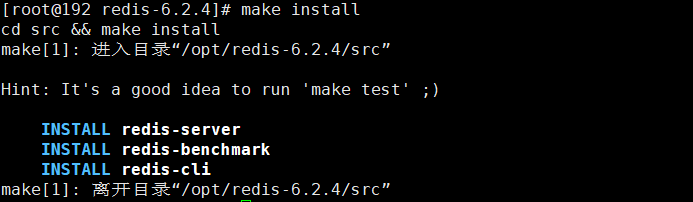
5. The default installation path of redis is / usr/local/bin

6. The redis configuration file. Copy to our current directory

7.redis is not started in the background by default. Modify the configuration file

8. Start Redis service

9. Use redis cli for connection test

10. Check whether the redis process is started

11. How to shut down Redis service

2.3 test performance
Use the official performance testing tool redis benchmark
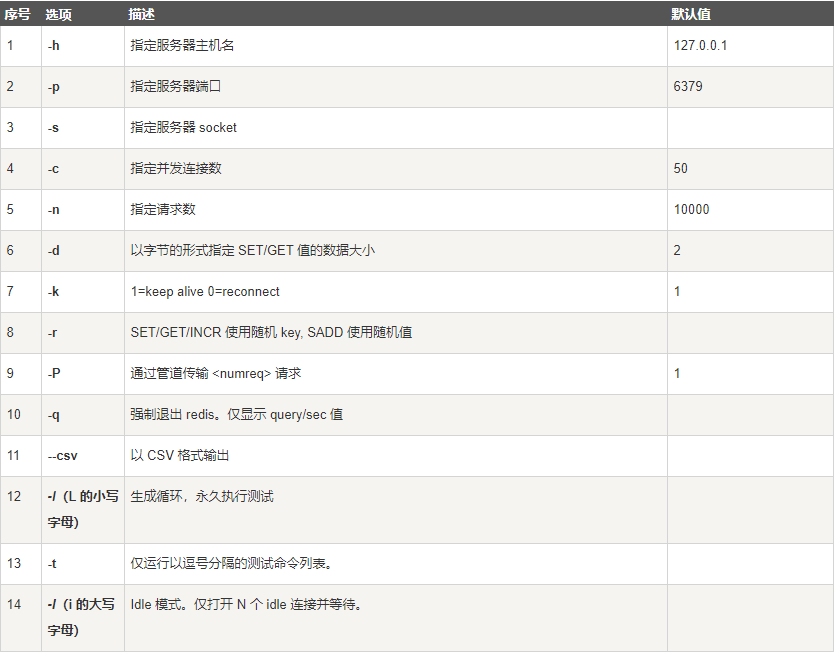
Let's simply test:
# Test: 100 concurrent connections 100000 requests redis-benchmark -h localhost -p 6379 -c 100 -n 100000

2.4 basic knowledge
redis has 16 databases by default.

The default is 0.
You can use select to switch databases.
127.0.0.1:6379> select 3 # Switch database OK 127.0.0.1:6379[3]> DBSIZE # View DB size (integer) 0

127.0.0.1:6379[3]> keys * # View the current database key 1) "key" 127.0.0.1:6379[3]> FLUSHDB # Empty the current database OK 127.0.0.1:6379[3]> keys * (empty array) 127.0.0.1:6379[3]> FLUSHALL # Empty all databases OK 127.0.0.1:6379[3]> SELECT 0 OK 127.0.0.1:6379> keys * (empty array)
2.5 Redis thread model
Redis4.0 was run by single thread;
Redis4. Multithreading is supported after 0. Redis4. Reason for using single thread before 0:
- Single thread mode is convenient for development and debugging;
- Redis uses epoll based multiplexing internally;
- The main performance bottleneck of Redis is memory or network bandwidth.
Redis introduced lazy deletion (also known as asynchronous deletion) in version 4.0 and later, which means that we can delete data in redis asynchronously, for example:
- unlink key: similar to del key, delete the specified key. If the key does not exist, the key will be skipped. But del blocks, and the unlink command reclaims memory in another thread, that is, it is non blocking. unlink key API;
- flushdb async: deletes all data in the current database flushdb API;
- Flush async: delete all data in the library flushall API.
The advantage of this processing is that the main process of Redis will not be stuck, and these operations will be handed over to the background thread for execution.
Since the Redis main thread is a single thread, why is it so fast?
- Memory based operation: all data of Redis exists in memory, so all operations are memory level, so its performance is relatively high.
- Simple data structure: Redis's data structure is relatively simple and specially designed for Redis, and the time complexity of finding and operating these simple data structures is O(1).
- Multiplexing and non blocking IO: Redis uses the IO multiplexing function to listen to clients connected by multiple socket s, so that one thread can be used to handle multiple situations, so as to reduce the overhead caused by thread switching and avoid IO blocking operation, which greatly improves the performance of Redis.
- Avoid context switching: because it is a single thread model, unnecessary context switching and multi-threaded competition are avoided, which saves the time and performance overhead caused by multi-threaded switching, and single thread will not lead to deadlock.
What is IO multiplexing?
- The socket read / write method is blocked by default. For example, when the read method is called and there is no data in the buffer, the thread will be stuck here. The read method will not return until there is data in the buffer or the connection is closed, and the thread can continue to process other services.
- Redis uses non blocking io. The IO read-write process is no longer blocked. The read-write methods are completed and returned instantly, that is, it will use the strategy of reading as much as it can read and writing as much as it can write, which is obviously more in line with our pursuit of performance.
- The simplest way to use IO multiplexing is to use the select function, which is the API interface provided by the operating system to the user program to monitor the readability and Writeability of multiple file descriptors (FD), so that the read and write events of file descriptors can be monitored. After monitoring the corresponding events, you can notify the thread to process the corresponding business, which ensures the normal execution of Redis read-write function.
Redis6. Multithreading in 0?
- Redis single thread has great advantages. It not only reduces the complexity of redis internal implementation, but also allows all operations to be carried out without lock, and there is no performance and time consumption caused by deadlock and thread switching; However, its disadvantages are also obvious. The single thread mechanism makes it difficult to effectively improve redis's QPS (Query Per Second).
- Although Redis introduces multithreading in version 4.0, multithreading in this version can only be used for asynchronous deletion of large amounts of data, which is not of great significance for non deletion operations.
- In Redis, although IO multiplexing is used and the operation is based on non blocking IO, the reading and writing of IO is blocked. For example, when there is data in the socket, Redis will first copy the data from the kernel space to the user space, and then carry out relevant operations. The copy process is blocked, and the larger the amount of data, the more time it takes to copy, and these operations are based on a single thread.
- So in Redis6 0 adds the function of multithreading to improve the read-write performance of Io. Its main implementation idea is to split the IO read-write task of the main thread into a group of independent threads for execution, so that the read-write parallelism of multiple socket s can be used, but Redis commands are still executed in series by the main thread.
- Note: Redis6 0 is multithreading disabled by default, but you can use Redis. 0 in the configuration file The IO threads do reads in conf is equal to true to enable. However, it is not enough. In addition, we also need to set the number of threads to correctly enable the multi-threaded function. The same is to modify the Redis configuration. For example, setting IO threads 4 means that four threads are enabled.
- Regarding the setting of the number of threads, the official suggestion is to set the number of threads to 2 or 3 if it is a 4-core CPU; If it is an 8-core CPU, set the number of threads to 6. In short, the number of threads must be less than the number of CPU cores of the machine. The larger the number of threads, the better.
3 five data types
3.1 Redis-Key
127.0.0.1:6379> keys # View all key s in the current database (empty array) 127.0.0.1:6379> set name zhangsan # set key OK 127.0.0.1:6379> keys * 1) "name" 127.0.0.1:6379> set age 2 OK 127.0.0.1:6379> keys * 1) "name" 2) "age" 127.0.0.1:6379> EXISTS name # Judge whether the current key exists (integer) 1 127.0.0.1:6379> MOVE name 1 # Remove current key (integer) 1 127.0.0.1:6379> KEYS * 1) "age" 127.0.0.1:6379> set name lisi OK 127.0.0.1:6379> KEYS * 1) "name" 2) "age" 127.0.0.1:6379> get name "lisi" 127.0.0.1:6379> EXPIRE name 10 # Set the expiration time of the key, in seconds (integer) 1 127.0.0.1:6379> TTL name # View the remaining time of the current key (integer) 5 127.0.0.1:6379> TTL name (integer) 1 127.0.0.1:6379> get name (nil) 127.0.0.1:6379> type name # View a type of current key none 127.0.0.1:6379> type age string
You can view the help documents on the official website: http://www.redis.cn/commands.html
3.2 string
#############################################################
127.0.0.1:6379> set key1 v1 # set up
OK
127.0.0.1:6379> get key1
"v1"
127.0.0.1:6379> keys *
1) "key1"
127.0.0.1:6379> EXISTS key1
(integer) 1
127.0.0.1:6379> APPEND key1 "hello" # Add
(integer) 7
127.0.0.1:6379> get key1
"v1hello"
127.0.0.1:6379> STRLEN key1 # String length
(integer) 7
127.0.0.1:6379> APPEND key1 ",zhangsan"
(integer) 16
127.0.0.1:6379> STRLEN key1
(integer) 16
127.0.0.1:6379> get key1
"v1hello,zhangsan"
#############################################################
# i++
# Step i+=
127.0.0.1:6379> SET views 0 # Initial views 0
OK
127.0.0.1:6379> GET views
"0"
127.0.0.1:6379> INCR views # Increase the browsing volume by 1 to + 1
(integer) 1
127.0.0.1:6379> INCR views
(integer) 2
127.0.0.1:6379> DECR views # From minus 1, the browsing amount becomes - 1
(integer) 1
127.0.0.1:6379> DECR views
(integer) 0
127.0.0.1:6379> DECR views
(integer) -1
127.0.0.1:6379> GET views
"-1"
127.0.0.1:6379> INCRBY views 10 # You can set the step size to specify the increment
(integer) 9
127.0.0.1:6379> INCRBY views 10
(integer) 19
127.0.0.1:6379> DECRBY views 5
(integer) 14
#############################################################
# String range
127.0.0.1:6379> SET key1 "hello,zhangsan"
OK
127.0.0.1:6379> get key1
"hello,zhangsan"
127.0.0.1:6379> GETRANGE key1 0 3
"hell"
127.0.0.1:6379> GETRANGE key1 0 -1
"hello,zhangsan"
127.0.0.1:6379> SET key2 abcdefg
OK
# Replace character
127.0.0.1:6379> get key2
"abcdefg"
127.0.0.1:6379> SETRANGE key2 1 xx
(integer) 7
127.0.0.1:6379> get key2
"axxdefg"
#############################################################
# setex (set with expire) sets the expiration time
# setnx (set if not exist) does not exist in settings (it is often used in distributed locks!)
127.0.0.1:6379> SETEX key3 30 "hello" # Set the value of key3 to hello and expire in 30 seconds
OK
127.0.0.1:6379> ttl key3
(integer) 22
127.0.0.1:6379> get key3
"hello"
127.0.0.1:6379> setnx key4 "redis" # Create if key4 does not exist
OK
127.0.0.1:6379> keys *
1) "key1"
2) "key4"
3) "key2"
127.0.0.1:6379> ttl key3 # -2 indicates that it has failed
(integer) -2
127.0.0.1:6379> setnx key4 "MongoDB" # key4 creation failed
(integer) 0
127.0.0.1:6379> get key4
"redis"
#############################################################
# mset sets multiple values at the same time
# mget gets multiple values at the same time
127.0.0.1:6379> MSET k1 v1 k2 v2 k3 v3 # Set multiple values at the same time
OK
127.0.0.1:6379> keys *
1) "k3"
2) "k2"
3) "k1"
127.0.0.1:6379> mget k1 k2 k3 # Get multiple values at the same time
1) "v1"
2) "v2"
3) "v3"
127.0.0.1:6379> msetnx k1 v1 k4 v4 # At the same time, set a non-existent value, atomic operation, and all of them fail
(integer) 0
127.0.0.1:6379> get key4
(nil)
#############################################################
# object
127.0.0.1:6379> set user:1 {name:zhangsan,age:3} # Set a user:1 object value to json character to save an object
OK
127.0.0.1:6379> mset user:1:name zhangsan user:1:age 2 # key: user:{id}:{filed}
OK
127.0.0.1:6379> mget user:1:name user:1:age
1) "zhangsan"
2) "2"
#############################################################
# getset first get, then set
127.0.0.1:6379> getset db redis # If no value exists, nil is returned and the value is set
(nil)
127.0.0.1:6379> get db
"redis"
127.0.0.1:6379> getset db mongodb # If a value exists, get the original value and set a new value
"redis"
127.0.0.1:6379> get db
"mongodb"
String usage scenario: value can be not only our string, but also our number.
- Counter
- Count multi unit quantity
- Number of fans
- Object cache storage
3.3 list
In redis, we can play list as stack, queue and blocking queue.
All list commands start with l. Redis is not case sensitive.
# LPUSH # RPUSH 127.0.0.1:6379> LPUSH list one # Insert one or more values to the left (integer) 1 127.0.0.1:6379> LPUSH list two (integer) 2 127.0.0.1:6379> LPUSH list tree (integer) 3 127.0.0.1:6379> LRANGE list 0 -1 # Get the value in the list 1) "tree" 2) "two" 3) "one" 127.0.0.1:6379> LRANGE list 0 1 # Get the value of the specified range of list, [start, end] 1) "tree" 2) "two" 127.0.0.1:6379> RPUSH list right # Trailing, inserting one or more values to the right (integer) 4 127.0.0.1:6379> LRANGE list 0 -1 1) "tree" 2) "two" 3) "one" 4) "right" ############################################################# # LPOP remove header element # RPOP remove tail element 127.0.0.1:6379> LRANGE list 0 -1 1) "tree" 2) "two" 3) "one" 4) "right" 127.0.0.1:6379> LPOP list # Remove the first element of the header "tree" 127.0.0.1:6379> RPOP list # Remove the first element of the tail "right" 127.0.0.1:6379> LRANGE list 0 -1 1) "two" 2) "one" 127.0.0.1:6379> ############################################################# # LINDEX gets the value of the specified index 127.0.0.1:6379> LRANGE list 0 -1 1) "two" 2) "one" 127.0.0.1:6379> LINDEX list 1 "one" 127.0.0.1:6379> LINDEX list 0 "two" ############################################################# # LLEN get set size 127.0.0.1:6379> LRANGE list 0 -1 1) "two" 2) "one" 127.0.0.1:6379> LLEN list # List length (integer) 2 ############################################################# # LREM removes the specified value! Take off uid 127.0.0.1:6379> lpush list one two three three (integer) 4 127.0.0.1:6379> 127.0.0.1:6379> 127.0.0.1:6379> LRANGE list 0 -1 1) "three" 2) "three" 3) "two" 4) "one" 127.0.0.1:6379> LREM list 1 one # Remove the specified number of value s in the list collection and match them exactly (integer) 1 127.0.0.1:6379> LRANGE list 0 -1 1) "three" 2) "three" 3) "two" 127.0.0.1:6379> LREM list 2 three (integer) 2 127.0.0.1:6379> LRANGE list 0 -1 1) "two" ############################################################# # LTRIM truncation 127.0.0.1:6379> RPUSH list hello hello1 hello2 hello3 (integer) 4 127.0.0.1:6379> LRANGE list 0 -1 1) "hello" 2) "hello1" 3) "hello2" 4) "hello3" 127.0.0.1:6379> LTRIM list 1 2 # By intercepting the specified length through the subscript, the list has been changed and only the intercepted elements are truncated! OK 127.0.0.1:6379> LRANGE list 0 -1 1) "hello1" 2) "hello2" ############################################################# # Rpop lpush removes the last element of the list and moves it to the new list 127.0.0.1:6379> RPUSH list hello hello1 hello2 (integer) 3 127.0.0.1:6379> LRANGE list 0 -1 1) "hello" 2) "hello1" 3) "hello2" 127.0.0.1:6379> RPOPLPUSH list list2 # Remove the last element of the list and move it to the new list list2 "hello2" 127.0.0.1:6379> LRANGE list 0 -1 1) "hello" 2) "hello1" 127.0.0.1:6379> LRANGE list2 0 -1 1) "hello2" ############################################################# # LSET replaces the value of the specified subscript in the list with another value to update the operation 127.0.0.1:6379> EXISTS list (integer) 0 127.0.0.1:6379> LSET list 0 item # If there is no list, we will report an error if we update it (error) ERR no such key 127.0.0.1:6379> LPUSH list one (integer) 1 127.0.0.1:6379> LRANGE list 0 -1 1) "one" 127.0.0.1:6379> LSET list 0 item # If present, update the value of the current subscript OK 127.0.0.1:6379> LRANGE list 0 0 1) "item" 127.0.0.1:6379> LSET list 1 two # Index out of bounds (error) ERR index out of range ############################################################# # LINSERT inserts a specific value before or after an element in your column 127.0.0.1:6379> RPUSH list hello world (integer) 2 127.0.0.1:6379> LRANGE list 0 -1 1) "hello" 2) "world" 127.0.0.1:6379> LINSERT list before world other # Insert other before world (integer) 3 127.0.0.1:6379> LRANGE list 0 -1 1) "hello" 2) "other" 3) "world" 127.0.0.1:6379> LINSERT list after world new # Insert new after world (integer) 4 127.0.0.1:6379> LRANGE list 0 -1 1) "hello" 2) "other" 3) "world" 4) "new"
It is actually a linked list. Values can be inserted into before node, after, left and right. If the key does not exist, create a new linked list. If the key exists, add content. If all values are removed, the empty linked list also means that it does not exist. Inserting or changing values on both sides is the most efficient. Intermediate elements are relatively inefficient.
Applications: message queuing, message queuing (Lpush Rpop), stack (Lpush Rpop).
3.4 set
The value in set cannot be repeated!
127.0.0.1:6379> SADD myset hello # Add one or more elements to the set collection (integer) 1 127.0.0.1:6379> SADD myset hello1 hello2 (integer) 2 127.0.0.1:6379> SMEMBERS myset # View the value of set 1) "hello2" 2) "hello1" 3) "hello" 127.0.0.1:6379> SISMEMBER myset hello # Determine whether a value is in the set (integer) 1 127.0.0.1:6379> SISMEMBER myset world (integer) 0 ############################################################# 127.0.0.1:6379> SCARD myset # View the number of set elements (integer) 3 ############################################################# 127.0.0.1:6379> SREM myset hello # Removes the specified element from the set collection (integer) 1 127.0.0.1:6379> SCARD myset (integer) 2 127.0.0.1:6379> SMEMBERS myset 1) "hello2" 2) "hello1" ############################################################# # set is unordered and does not duplicate sets. Random sampling 127.0.0.1:6379> SADD myset one two three (integer) 3 127.0.0.1:6379> SMEMBERS myset 1) "three" 2) "two" 3) "one" 127.0.0.1:6379> SRANDMEMBER myset # Select an element at random "two" 127.0.0.1:6379> SRANDMEMBER myset "three" 127.0.0.1:6379> SRANDMEMBER myset 2 # Randomly select a specified number of elements 1) "three" 2) "one" 127.0.0.1:6379> SRANDMEMBER myset 2 1) "two" 2) "one" ############################################################# # Delete the specified key and the random key 127.0.0.1:6379> SMEMBERS myset 1) "four" 2) "three" 3) "two" 4) "one" 127.0.0.1:6379> SREM myset two # Deletes the specified element (integer) 1 127.0.0.1:6379> SMEMBERS myset 1) "four" 2) "three" 3) "one" 127.0.0.1:6379> SPOP myset # Randomly delete elements "one" 127.0.0.1:6379> SPOP myset "four" 127.0.0.1:6379> SMEMBERS myset 1) "three" ############################################################# # Moves a specified value to another set set 127.0.0.1:6379> SADD myset one two three (integer) 3 127.0.0.1:6379> SADD myset1 four (integer) 1 127.0.0.1:6379> SMOVE myset myset1 one # Moves a specified value to another set set (integer) 1 127.0.0.1:6379> SMEMBERS myset 1) "three" 2) "two" 127.0.0.1:6379> SMEMBERS myset1 1) "four" 2) "one" ########################################################################## # SDIFF difference set # SINTER intersection # Union of sun 127.0.0.1:6379> SADD key1 a b c d (integer) 4 127.0.0.1:6379> SMEMBERS key1 1) "d" 2) "c" 3) "b" 4) "a" 127.0.0.1:6379> SADD key2 b c (integer) 2 127.0.0.1:6379> SMEMBERS key2 1) "c" 2) "b" 127.0.0.1:6379> SDIFF key1 key2 1) "a" 2) "d" 127.0.0.1:6379> SINTER key1 key2 1) "c" 2) "b" 127.0.0.1:6379> SUNION key1 key2 1) "d" 2) "c" 3) "b" 4) "a"
3.5 hash
Map set, this value is a map set in key map! The essence is not much different from the String type, but a simple key - (key vlaue).
# hset key field value 127.0.0.1:6379> HSET myhash f1 v1 # set a specific key value (integer) 1 127.0.0.1:6379> HGET myhash f1 # Gets the value of a field "v1" 127.0.0.1:6379> HMSET myhash f2 v2 f3 v3 # set multiple specific key values OK 127.0.0.1:6379> HMGET myhash f2 f3 # Gets the value of multiple fields 1) "v2" 2) "v3" 127.0.0.1:6379> HGETALL myhash # Get all the data 1) "f1" 2) "v1" 3) "f2" 4) "v2" 5) "f3" 6) "v3" 127.0.0.1:6379> HDEL myhash f1 # Delete the key specified in the hash, and the corresponding value will also be deleted (integer) 1 127.0.0.1:6379> HGETALL myhash 1) "f2" 2) "v2" 3) "f3" 4) "v3" 127.0.0.1:6379> HLEN myhash # Get the number of hash fields (integer) 2 127.0.0.1:6379> HEXISTS myhash f2 # Judge whether the specified field in the hash exists (integer) 1 127.0.0.1:6379> HEXISTS myhash f1 (integer) 0 127.0.0.1:6379> HKEYS myhash # Get all field s of hash 1) "f2" 2) "f3" 127.0.0.1:6379> HVALS myhash # Get all hash value s 1) "v2" 2) "v3" ########################################################################## 127.0.0.1:6379> HSET myhash field1 5 (integer) 1 127.0.0.1:6379> HINCRBY myhash field1 1 # Specify increment (integer) 6 127.0.0.1:6379> HINCRBY myhash field1 -1 (integer) 5 127.0.0.1:6379> HSETNX myhash field2 hello # If it does not exist, it can be set (integer) 1 127.0.0.1:6379> HSETNX myhash field2 world # If it exists, it cannot be set (integer) 0
hash stores changed data, especially user information and other frequently changing information! hash is more suitable for object storage, and string is more suitable for string storage
3.6 zset (ordered set)
On the basis of set, a value is added, set k1 v1 zset k1 score1 v1
127.0.0.1:6379> zadd mzset 1 one # Add a value (integer) 1 127.0.0.1:6379> zadd mzset 2 two 3 three # Add multiple values (integer) 2 127.0.0.1:6379> zrange mzset 0 -1 1) "one" 2) "two" 3) "three" ########################################################################## # How to sort 127.0.0.1:6379> ZADD salary 2500 zhangsan (integer) 1 127.0.0.1:6379> ZADD salary 5000 lisi (integer) 1 127.0.0.1:6379> ZADD salary 4000 wangwu (integer) 1 127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf # Ascending order from negative infinity to positive infinity by score 1) "zhangsan" 2) "wangwu" 3) "lisi" 127.0.0.1:6379> ZREVRANGEBYSCORE salary +inf -inf # Positive infinity to negative infinity descending by score 1) "lisi" 2) "wangwu" 3) "zhangsan" 127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf # Show all users with scores 1) "zhangsan" 2) "2500" 3) "wangwu" 4) "4000" 5) "lisi" 6) "5000" 127.0.0.1:6379> ZRANGEBYSCORE salary -inf 4000 withscores # Displays the ascending sort of employees whose salary is less than or equal to 4000 1) "zhangsan" 2) "2500" 3) "wangwu" 4) "4000" ########################################################################## # zrem removal 127.0.0.1:6379> ZRANGE salary 0 -1 1) "zhangsan" 2) "wangwu" 3) "lisi" 127.0.0.1:6379> ZREM salary lisi # Removes the specified element from the ordered collection (integer) 1 127.0.0.1:6379> ZRANGE salary 0 -1 1) "zhangsan" 2) "wangwu" 127.0.0.1:6379> ZCARD salary # Gets the number of in the ordered collection (integer) 2 ########################################################################## 127.0.0.1:6379> ZADD myset 1 hello 2 world 3 lisi (integer) 3 127.0.0.1:6379> ZCOUNT myset 0 2 ## Gets the number of members in the specified interval (integer) 2 127.0.0.1:6379> ZCOUNT myset 1 3 (integer) 3 127.0.0.1:6379> ZCOUNT myset 1 2 (integer) 2 127.0.0.1:6379> ZADD myset 1 hello2 (integer) 1 127.0.0.1:6379> ZCOUNT myset 1 3 (integer) 4
Application scenario:
- set sorting stores class grade table and salary table sorting.
- Ordinary message, 1, important message, 2, judgment with weight.
- Leaderboard application implementation, take Top N.
4 three special data types
4.1 geospatial (geographical location)
This function can calculate the information of geographical location, the distance between the two places, and people within a few miles.
Official documents: https://www.redis.net.cn/order/3685.html
Related commands:
- GEOADD: add
- GEOPOS: get location
- GEODIST: distance between two locations
- GEORADIUS: find out the elements within a certain radius with the given longitude and latitude as the center
- GEORADIUSBYMEMBER: find other elements around the specified element
- Geohash: returns a Geohash representation of one or more location elements
####### GEOADD adds one or more address location information
# GEOADD key longitude latitude member []
# Rule: two levels cannot be added directly. We usually download city data and import it directly through java program at one time
# The effective longitude is from - 180 degrees to 180 degrees
# The effective latitude is from -85.05112878 degrees to 85.05112878 degrees
# When the coordinate position exceeds the above specified range, the command will return an error
127.0.0.1:6379> GEOADD china:city 120.19 30.26 hangzhou
(integer) 1
127.0.0.1:6379> GEOADD china:city 116.46 39.92 beijing
(integer) 1
127.0.0.1:6379> GEOADD china:city 121.48 31.22 shanghai
(integer) 1
127.0.0.1:6379> GEOADD china:city 113.23 23.16 guangzhou 102.73 25.04 kunming
(integer) 2
####### GEOPOS gets a geographic location information
# GEOPOS key member
127.0.0.1:6379> GEOPOS china:city beijing
1) 1) "116.45999997854232788"
2) "39.9199990416181052"
127.0.0.1:6379> GEOPOS china:city hangzhou
1) 1) "120.18999785184860229"
2) "30.25999927289620928"
####### GEODIST distance between two locations
# GEODIST key member1 member2 unit
# The unit m is expressed in meters. km is expressed in kilometers. mi is in miles. ft is in feet.
127.0.0.1:6379> GEODIST china:city beijing shanghai km
"1068.4581"
# GEORADIUS takes the given latitude and longitude as the center to find out the elements within a certain radius
# GEORADIUS key longitude latitude radius unit [...]
127.0.0.1:6379> GEORADIUS china:city 120 30 500 km # Take this longitude and latitude as the center and look for cities within a radius of 500km
1) "hangzhou"
2) "shanghai"
127.0.0.1:6379> GEORADIUS china:city 120 30 500 km withdist # Display distance
1) 1) "hangzhou"
2) "34.2105"
2) 1) "shanghai"
2) "196.1728"
127.0.0.1:6379> GEORADIUS china:city 120 30 500 km withcoord # Show other people's location information
1) 1) "hangzhou"
2) 1) "120.18999785184860229"
2) "30.25999927289620928"
2) 1) "shanghai"
2) 1) "121.48000091314315796"
2) "31.21999956478423854"
127.0.0.1:6379> GEORADIUS china:city 120 30 500 km withcoord count 1 # Number of filters
1) 1) "hangzhou"
2) 1) "120.18999785184860229"
2) "30.25999927289620928"
# GEORADIUSBYMEMBER finds other elements around the specified element
# GEORADIUSBYMEMBER key member radius unit [...]
127.0.0.1:6379> GEORADIUSBYMEMBER china:city beijing 400 km
1) "beijing"
# Geohash returns a Geohash representation of one or more location elements and will return an 11 character Geohash string
# GEOHASH member [member]
# Convert the two-dimensional latitude and longitude into one-dimensional string. The closer the two strings are, the closer the distance is
127.0.0.1:6379> GEOHASH china:city beijing shanghai
1) "wx4g455wfe0"
2) "wtw3s77j9j0"
The underlying implementation principle of geo is actually zset! We can use the zset command to manipulate Geo.
127.0.0.1:6379> ZRANGE china:city 0 -1 1) "kunming" 2) "guangzhou" 3) "hangzhou" 4) "shanghai" 5) "beijing" 127.0.0.1:6379> ZREM china:city beijing (integer) 1 127.0.0.1:6379> ZRANGE china:city 0 -1 1) "kunming" 2) "guangzhou" 3) "hangzhou" 4) "shanghai"
4.2 hyperlogs (cardinality)
A {1,3,5,7,8,7}
B{1,3,5,7,8}
Cardinality (non repeating element) = 5, there is a certain error.
Advantages: the occupied memory is fixed. 2 ^ 64 different elements only need to waste 12KB of memory.
UV of a web page (a person visits a website many times, but still counts as a person): in the traditional way, set saves the user's id, and then you can count the number of elements in set as the standard judgment. If a large number of user IDs are saved in this way, memory will be wasted.
0.81% error rate, statistical UV tasks, negligible.
127.0.0.1:6379> PFADD key1 a b c d e f g h i j # Create the first set of elements key1 (integer) 1 127.0.0.1:6379> PFCOUNT key1 # Count the cardinality number of key1 elements (integer) 10 127.0.0.1:6379> PFADD key2 i j k l m n # Create a second set of elements key2 (integer) 1 127.0.0.1:6379> PFCOUNT key2 # Count the cardinality number of key2 elements (integer) 6 127.0.0.1:6379> PFMERGE key3 key1 key2 # Merge two groups of key1, key2 = > Key3 Union OK 127.0.0.1:6379> PFCOUNT key3 # # Look at the number of union sets (integer) 14
If fault tolerance is allowed, you can use hyperloglog to count the number
4.3 bitmaps (bitmap)
Statistics of user information, active or inactive; Login or not; Punch in and 365 punch in records; bitmaps can be used in both States.
Bitmap bitmap, data structure, operation binary bits to record, there are only two states: 0 and 1.
Use bitmap to record clock outs from Monday to Sunday!
Monday: 1 Tuesday: 0 Wednesday: 0 Thursday: 1
127.0.0.1:6379> SETBIT sign 0 1 (integer) 0 127.0.0.1:6379> SETBIT sign 1 0 (integer) 0 127.0.0.1:6379> SETBIT sign 2 0 (integer) 0 127.0.0.1:6379> SETBIT sign 3 1 (integer) 0 127.0.0.1:6379> SETBIT sign 4 1 (integer) 0 127.0.0.1:6379> SETBIT sign 5 0 (integer) 0 127.0.0.1:6379> SETBIT sign 6 0 (integer) 0 127.0.0.1:6379> GETBIT sign 3 # Check whether there is a clock in record on a certain day (integer) 1 127.0.0.1:6379> GETBIT sign 6 (integer) 0 127.0.0.1:6379> BITCOUNT sign # Statistics operation, counting clock in days (integer) 3