Introduction: This paper introduces the paper "entire space multi task model: an e" effective approach for estimating post click conversion rate "published by Alibaba team in SIGIR '2018. Based on the idea of multi task learning (MTL), this paper proposes a CVR prediction model called ESMM, which effectively solves the two key problems of data sparsity and sample selection deviation faced by CVR prediction in real scenes. In the future, multi task learning models such as MMoE, PLE and DBMTL will be introduced.
Multitasking learning background
At present, the recommendation algorithms used in industry are not only limited to single target (ctr) tasks, but also need to pay attention to the subsequent conversion links, such as whether to comment, collect, add purchase, purchase, viewing time and so on.
This paper introduces the paper "entire space multi task model: an e" effective approach for estimating post click conversion rate "published by Alibaba team in SIGIR '2018. Based on the idea of multi task learning (MTL), this paper proposes a CVR prediction model called ESMM, which effectively solves the two key problems of data sparsity and sample selection deviation faced by CVR prediction in real scenes. In the future, multi task learning models such as MMoE, PLE and DBMTL will be introduced.
Paper introduction
CVR estimation faces two key problems:
1. Sample Selection Bias (SSB)
Conversion is a "possible" action after clicking. The traditional CVR model usually takes the click data as the training set, in which the click is not converted into a negative example, and the click is converted into a positive example. However, when the trained model is actually used, it estimates the samples in the whole space, not just the click samples. That is, the training data and the actual data to be predicted come from different distributions. This deviation poses a great challenge to the generalization ability of the model, resulting in the general effect of online business after the model is online.
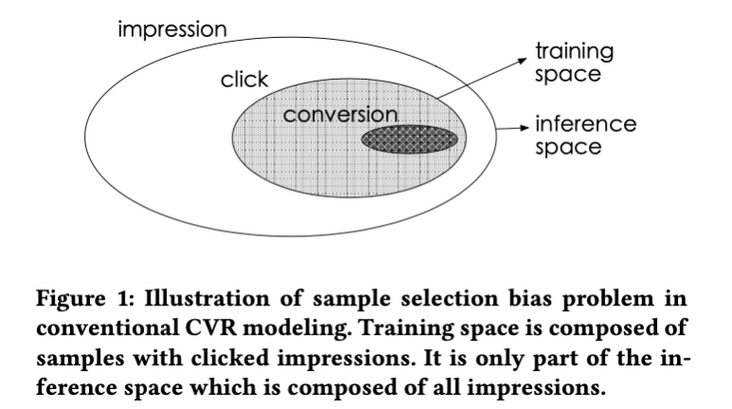
2. Data Sparsity (DS)
The training data (i.e. click samples) used in CVR prediction task is much smaller than the exposure samples used in CTR prediction training. Only a small number of samples are used for training, which will lead to the difficulty of depth model fitting.
Some strategies can alleviate these two problems, such as negative samples from the exposure set to mitigate SSB, oversampling transformed samples to mitigate DS, etc. But no matter which method, it does not substantially solve any of the above problems.
Because Click = > transformation itself is two strongly related continuous behaviors, the author hopes to show and consider this "behavior chain relationship" in the model structure, so that it can be trained and predicted in the whole space. This involves two tasks: CTR and CVR, so using multi task learning (MTL) is a natural choice. The key highlight of this paper is "how to build" this MTL.
First of all, it is necessary to distinguish CVR prediction task from CTCVR prediction task.
CVR = number of conversions / hits. Is to predict the probability that "if an item is clicked, it will be transformed". CVR estimation task has no absolute relationship with CTR. If the CTR of an item is high, the CVR may not be the same. For example, the browsing time of the title party article is often low. This is also the reason why it is impossible to directly use all samples to train the CVR model, because it is impossible to determine whether those exposed samples that are not clicked will be transformed if they are clicked. If 0 is directly used as their label, it will mislead the learning of CVR model to a great extent.
CTCVR = number of conversions / number of exposures. Is to predict the probability of "item being clicked and then converted".
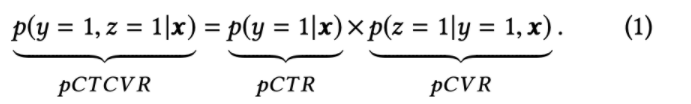
Where x, y and Z respectively represent exposure, click and conversion. Note that in all sample spaces, the label corresponding to CTR is click and the label corresponding to CTCVR is click & conversion. All samples can be used for these two tasks. Therefore, ESMM learns CTR and CTCVR tasks, and then implicitly learns CVR tasks according to the above formula. The specific structure is as follows:
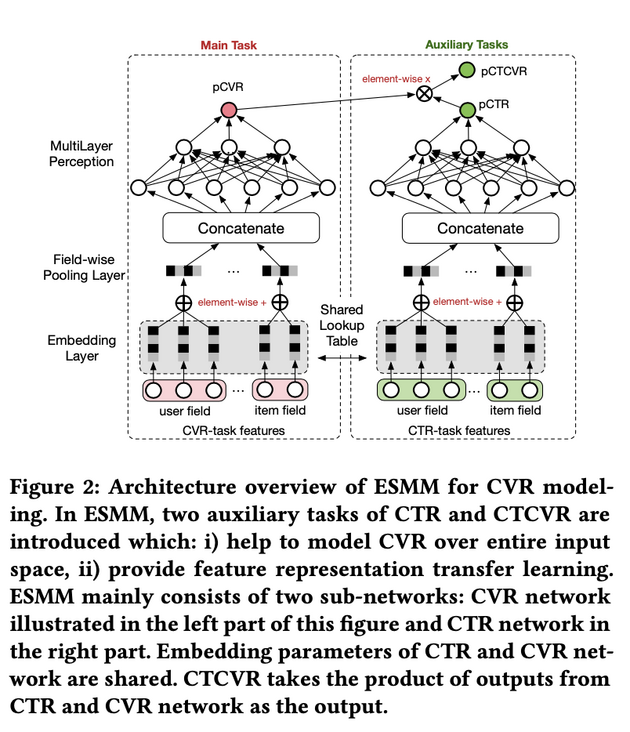
There are two points worth emphasizing on the network structure:
Share embedding. CVR task and CTR task use the same features and feature embedding, that is, they learn their own exclusive parameters after Concatenate;
Implicit learning pCVR. Here, pCVR is only a variable in the network, and there is no monitoring signal displayed.
Specifically, it is reflected in the objective function:
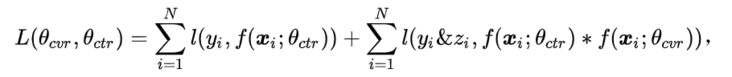
code implementation
Based on the EasyRec recommended algorithm framework, we implement the ESMM algorithm, which can be moved to github: EasyRec ESMM.
Introduction to EasyRec: EasyRec is an open-source large-scale distributed recommendation algorithm framework for the machine learning PAI team of Alibaba cloud computing platform. EasyRec, like its name, is simple and easy to use, integrates many excellent cutting-edge recommendation system ideas, and has feature engineering methods that have achieved excellent results in the actual industrial implementation, integrated training, evaluation and deployment, Seamlessly connected with Alibaba cloud products, EasyRec can build a cutting-edge recommendation system in a short time. As Alibaba cloud's flagship product, it has stably served hundreds of enterprise customers.
Model feedforward network:
def build_predict_graph(self):
"""Forward function.
Returns:
self._prediction_dict: Prediction result of two tasks.
"""
# Here, start with the tensor (all_fea) after Concatenate and omit its generation logic
cvr_tower_name = self._cvr_tower_cfg.tower_name
dnn_model = dnn.DNN(
self._cvr_tower_cfg.dnn,
self._l2_reg,
name=cvr_tower_name,
is_training=self._is_training)
cvr_tower_output = dnn_model(all_fea)
cvr_tower_output = tf.layers.dense(
inputs=cvr_tower_output,
units=1,
kernel_regularizer=self._l2_reg,
name='%s/dnn_output' % cvr_tower_name)
ctr_tower_name = self._ctr_tower_cfg.tower_name
dnn_model = dnn.DNN(
self._ctr_tower_cfg.dnn,
self._l2_reg,
name=ctr_tower_name,
is_training=self._is_training)
ctr_tower_output = dnn_model(all_fea)
ctr_tower_output = tf.layers.dense(
inputs=ctr_tower_output,
units=1,
kernel_regularizer=self._l2_reg,
name='%s/dnn_output' % ctr_tower_name)
tower_outputs = {
cvr_tower_name: cvr_tower_output,
ctr_tower_name: ctr_tower_output
}
self._add_to_prediction_dict(tower_outputs)
return self._prediction_dictloss calculation:
Note: the exposure data needs to be mask ed when calculating the index of CVR.
def build_loss_graph(self):
"""Build loss graph.
Returns:
self._loss_dict: Weighted loss of ctr and cvr.
"""
cvr_tower_name = self._cvr_tower_cfg.tower_name
ctr_tower_name = self._ctr_tower_cfg.tower_name
cvr_label_name = self._label_name_dict[cvr_tower_name]
ctr_label_name = self._label_name_dict[ctr_tower_name]
ctcvr_label = tf.cast(
self._labels[cvr_label_name] * self._labels[ctr_label_name],
tf.float32)
cvr_loss = tf.keras.backend.binary_crossentropy(
ctcvr_label, self._prediction_dict['probs_ctcvr'])
cvr_loss = tf.reduce_sum(cvr_losses, name="ctcvr_loss")
# The weight defaults to 1.
self._loss_dict['weighted_cross_entropy_loss_%s' %
cvr_tower_name] = self._cvr_tower_cfg.weight * cvr_loss
ctr_loss = tf.reduce_sum(tf.nn.sigmoid_cross_entropy_with_logits(
labels=tf.cast(self._labels[ctr_label_name], tf.float32),
logits=self._prediction_dict['logits_%s' % ctr_tower_name]
), name="ctr_loss")
self._loss_dict['weighted_cross_entropy_loss_%s' %
ctr_tower_name] = self._ctr_tower_cfg.weight * ctr_loss
return self._loss_dictnote: here loss is weighted_cross_entropy_loss_ctr + weighted_cross_entropy_loss_cvr, EasyRec framework will automatically self_ loss_ Add the contents of dict.
metric calculation:
Note: the exposure data needs to be mask ed when calculating the index of CVR.
def build_metric_graph(self, eval_config):
"""Build metric graph.
Args:
eval_config: Evaluation configuration.
Returns:
metric_dict: Calculate AUC of ctr, cvr and ctrvr.
"""
metric_dict = {}
cvr_tower_name = self._cvr_tower_cfg.tower_name
ctr_tower_name = self._ctr_tower_cfg.tower_name
cvr_label_name = self._label_name_dict[cvr_tower_name]
ctr_label_name = self._label_name_dict[ctr_tower_name]
for metric in self._cvr_tower_cfg.metrics_set:
# CTCVR metric
ctcvr_label_name = cvr_label_name + '_ctcvr'
cvr_dtype = self._labels[cvr_label_name].dtype
self._labels[ctcvr_label_name] = self._labels[cvr_label_name] * tf.cast(
self._labels[ctr_label_name], cvr_dtype)
metric_dict.update(
self._build_metric_impl(
metric,
loss_type=self._cvr_tower_cfg.loss_type,
label_name=ctcvr_label_name,
num_class=self._cvr_tower_cfg.num_class,
suffix='_ctcvr'))
# CVR metric
cvr_label_masked_name = cvr_label_name + '_masked'
ctr_mask = self._labels[ctr_label_name] > 0
self._labels[cvr_label_masked_name] = tf.boolean_mask(
self._labels[cvr_label_name], ctr_mask)
pred_prefix = 'probs' if self._cvr_tower_cfg.loss_type == LossType.CLASSIFICATION else 'y'
pred_name = '%s_%s' % (pred_prefix, cvr_tower_name)
self._prediction_dict[pred_name + '_masked'] = tf.boolean_mask(
self._prediction_dict[pred_name], ctr_mask)
metric_dict.update(
self._build_metric_impl(
metric,
loss_type=self._cvr_tower_cfg.loss_type,
label_name=cvr_label_masked_name,
num_class=self._cvr_tower_cfg.num_class,
suffix='_%s_masked' % cvr_tower_name))
for metric in self._ctr_tower_cfg.metrics_set:
# CTR metric
metric_dict.update(
self._build_metric_impl(
metric,
loss_type=self._ctr_tower_cfg.loss_type,
label_name=ctr_label_name,
num_class=self._ctr_tower_cfg.num_class,
suffix='_%s' % ctr_tower_name))
return metric_dictExperiment and deficiency
We have conducted a large number of experiments based on open source AliCCP data. Please look forward to the next article in the experimental part. It is found that the seesaw phenomenon of ESMM is obvious, and it is difficult to improve the effects of CTR and CVR tasks at the same time.
reference
Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate
ESMM of Ali CVR prediction model
Introduction and implementation of easyrec ESMM multi task learning model
Note: the pictures and publicity in this article are quoted from the paper: entire space multi task model: an effective approach for estimating post click conversion rate.
Original link
This article is the original content of Alibaba cloud and cannot be reproduced without permission.