Combined with the use of ELK as a log management tool in the project, it has been integrated and introduced earlier Elasticsearch In the project, two Logstash nodes are deployed to consume messages from Kafka cluster and output them to Elasticsearch cluster for log data storage. Combined with project practice, official website and other network materials, this paper continues to integrate the Logstash related introduction, working process, installation and operation and related configuration in ELK technology stack. It is inevitable that there are omissions in this article. I hope readers can comment on it, explore its shortcomings, learn from it together and make continuous progress. Thank you very much!
1. Introduction to logstash
Logstash is an open source data collection engine with real-time pipeline processing capability. In ELK Stack, its main function is to collect the file data in the log, format and normalize the log data internally, and then send it to the specified receiver, usually Elasticsearch. Logstash mainly relies on rich internal plug-ins to process the collected data.
Logstash benefits
1.Scalability Beats It should be in a group Logstash For load balancing between nodes, it is recommended to use at least two Logstash Nodes for high availability. each Logstash Only one node is deployed Beats Input is common, but every Logstash Multiple nodes can also be deployed Beats Enter to expose separate endpoints for different data sources. 2.elastic Logstash Persistent queues provide protection against cross node failures. about Logstash It is very important to ensure disk redundancy. For on premises deployment, configuration is recommended RAID. When running in a cloud or containerized environment, it is recommended to use reflective data SLA Permanent disk for replication policy. 3.Filterable Perform general conversion on event fields. You can rename, delete, replace and modify fields in events. The extensible plug-in ecosystem provides more than 200 plug-ins, as well as the flexibility to create and contribute their own.
Logstash disadvantages
Logstash Large resource consumption and operation occupation CPU And high memory. In addition, there is no message queue cache, and there is a hidden danger of data loss.
2. Logstash working process
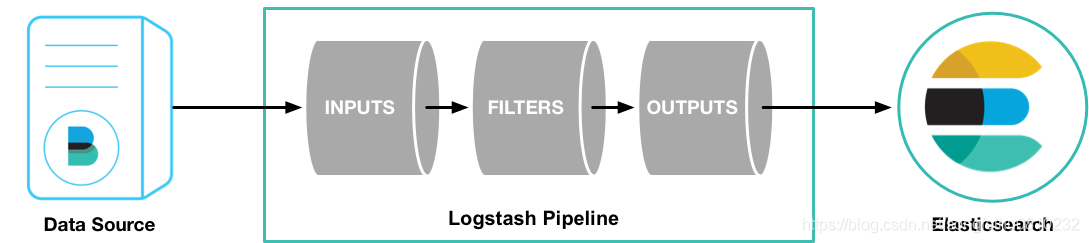
The Logstash event processing pipeline has three stages: input, filter and output. Inputs generate events, filters modify them, and outputs ship them elsewhere. Input and output support codecs (codecs), allowing you to encode or decode data when it enters or exits the pipeline without using a separate filter. These four parts exist in the form of plug-ins. Users can define the pipeline configuration file and set the input, filter, output and codec plug-ins to be used to realize specific functions such as data collection, data processing and data output.
Inputs: It is used to obtain data from data sources. Common plug-ins such as file, syslog, redis, beats etc. Filters: Used to process data, such as format conversion, data derivation, etc. common plug-ins such as grok, mutate, drop, clone, geoip etc. Outputs: For data output, common plug-ins such as elastcisearch,file, graphite, statsd etc. Codecs: Codecs(Coding plug-in)It is not a separate process, but a module for data conversion in plug-ins such as input and output, It is used to encode and process data. Common plug-ins such as json,multiline. Logstash Not just one input | filter | output Data flow, but a input | decode | filter | encode | output Data flow! codec Just for decode,encode Of the event.
3. Logstash installation and operation
-
Download installation package
https://artifacts.elastic.co/downloads/logstash/logstash-6.2.2.tar.gz
-
decompression
tar -zvxf logstash-6.2.2.tar.gz
-
Start operation
./logstash -f input_out.conf input_out.conf Is a configuration file where you can specify a data source input,filter Filtering and data export direction output Etc;
4. Logstash configuration
Examples of configuration files: standard input and output, file input to standard console output, standard console input to Elasticsearch output, kafka input to Elasticsearch output, etc
Standard console I / O configuration
input {
stdin{
}
}
output {
stdout{
}
}
File input to standard console output
input{
file{
path =>"/home/u-0/logstash/logstash-6.2.2/logs/logstash-plain.log"
start_position=>"beginning"
}
}
filter{
grok{
match=>{
"message"=>"%{DATA:clientIp} "
}
remove_field=>"message"
}
date{
match=>["accessTime","dd/MMM/yyyy:HH:mm:ss Z"]
}
}
output{
stdout{
codec=>rubydebug
}
}
Grok is the most important plug-in for Logstash. Its main function is to convert text format strings into specific structured data, which can be used with regular expressions.
input/file/path: Specifies the file to scan. Scanning multiple files can be used*Path wildcard; Or in the form of an array( path=>["outer-access.log","access.log"]); Or give a directory directly, logstash It scans all files in the path and listens for new files. filter/grok/match/message: Inside DATA yes grok Regular expressions built into syntax, DATA Match any character. filter/grok/match/date: Yes HTTPDATE Explanation of date format, joda It can support many complex date formats, It needs to be indicated here to match correctly. remove_field=>"message": The purpose is to remove the original entire log string and only keep it filter Parsed information. You can try to get rid of this sentence to see its usefulness.
Standard console input Elasticsearch output
input{
stdin {}
}
output {
elasticsearch {
hosts => ["192.168.65.146:9201","192.168.65.148:9202","192.168.65.149:9203"]
index => "test_index"
user => "elastic"
password => "pwd123"
}
stdout { codec => rubydebug}
}
kafka input Elasticsearch output
input{
kafka {
type => "log"
bootstrap_servers => ["http://192.168.65.146:9092","http://192.168.65.148:9092","http://192.168.65.149:9092"]
group_id => "log_consumer_group"
auto_offset_reset => "earliest"
consumer_threads => 1
decorate_events => true
topics => ["log1","log2"]
codec => "json"
}
}
filter {
mutate {
lowercase => ["service"]
}
}
output {
elasticsearch {
hosts => ["192.168.65.146:9201","192.168.65.148:9202","192.168.65.149:9203"]
index => "test_index"
user => "elastic"
password => "pwd123"
}
stdout { codec => rubydebug}
}
5. References
[1]. Logstash introduction.
[2]. Introduction and architecture of logstash.
[3]. Logstash detailed record.
[4]. Logstash best practices.
[4]. Logstash performance tuning under ELK.