review
Last time we talked about the register and memory access related contents involved in the assembly. Let's sort it out first:
- Registers are super small temporary memories that store the data that the CPU will use immediately or the results just processed in the CPU
- There's too much data to process, so the registers can't fit. You need more registers, but it's expensive
- Memory can solve the above problems, but memory is slower than registers. The advantage is that it is relatively cheap and has large capacity
Episode: the relationship between C language and assembly language
There are still some doubts. Let's explain them for the time being. First, in C programming, we never care about registers. It's hard to learn that such a thing suddenly appears in assembly language. Next, let's unify the knowledge of C language and assembly language to help understand.
First, let's look at a C language program:
int x, y, z;
int main() {
x = 2;
y = 3;
z = x + y;
return z;
}Considering that our compilation tutorial has just begun, I'll try to simplify the C program as much as possible, so that the knowledge required when dealing with the equivalent compilation content later is introduced earlier.
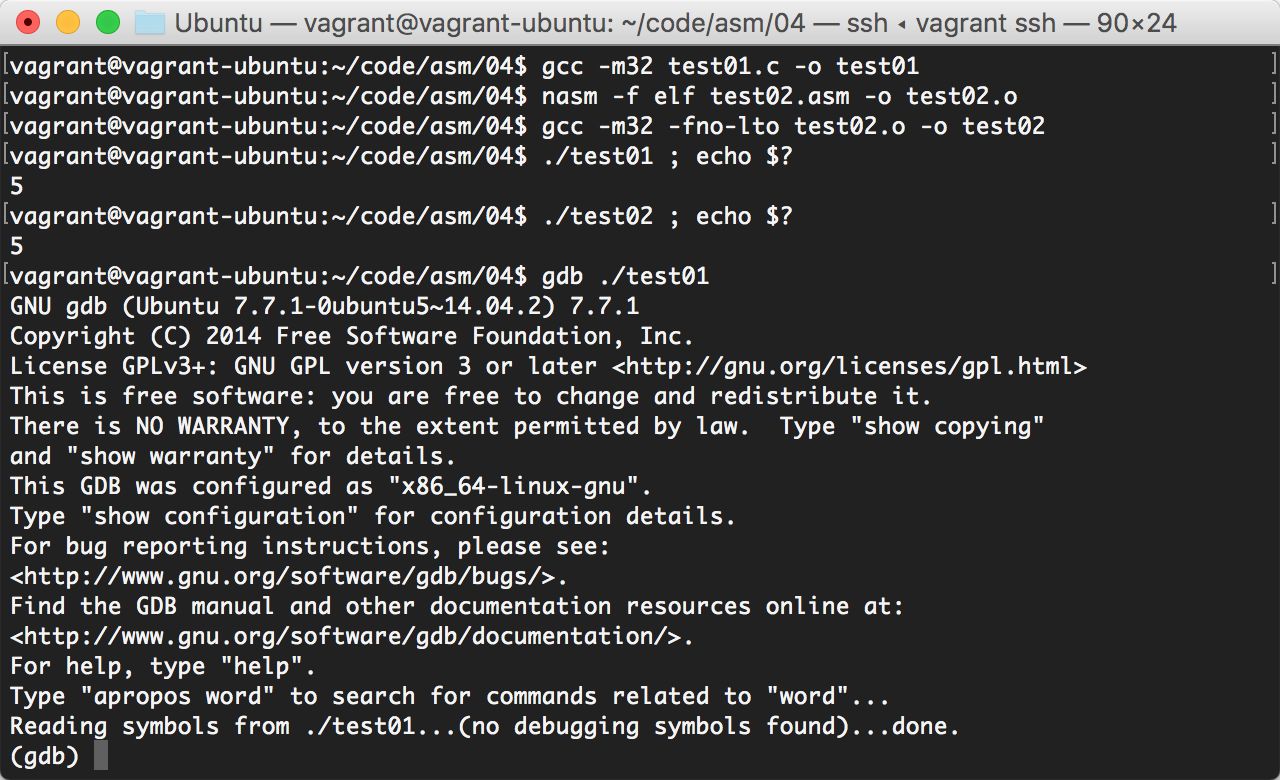
Save as test01 C file, compile and run the program first:
(note that gcc here takes a parameter - m32, because we need to compile a 32-bit (x86) executable)
$ gcc -m32 test01.c -o test01 $ ./test01 ; echo $? 5
Well, here, our program returns a value: 5.
OK, let's see what we should do if we want to implement almost the same process with assembly?
First, there are three global variables:
int x, y, z;
There must be. (the reason why global variables are used here is that the assembly knowledge related to local variables has not been introduced. I will deal with them first, and then I will talk about the content of local variables later)
First of all, in C language, you can think that each variable will occupy a certain memory space, that is, x, y and z here occupy an "integer", that is, 4 bytes of storage space.
Last time, we introduced the knowledge of accessing memory in assembly. Of course, we also know how to set aside a certain space in the data area. This time, we will copy the methods mentioned above:
global main
main:
mov eax, 0
ret
section .data
x dw 0
y dw 0
z dw 0This program is equivalent to the following C code:
int x, y, z;
int main() {
return 0;
}That is, now there are three global variables, but now the assembler does nothing, only returns 0.
The C code here is completely equivalent to the above assembly code to some extent. Even, our c language compiler can directly translate the C code into the above assembly code. The rest of the work is handed over to nasm to compile again. By converting the assembly into an executable file, we can get the final program. Of course, this can be done in theory. In fact, some compilers do this, but the assembly format generated by others is not nasm, but other types, but the truth is the same.
In other words, a sufficiently concise C compiler only needs to be able to translate C code into assembly code and hand over the rest to the assembler to complete, so as to realize the complete C language compiler and get the final executable file. In fact, the C compiler can do this, and some even do it.
Well, let's not talk about these first. Let's complete the previous program until it is equivalent to the first C code. Next, let's focus on this:
x = 2; y = 3;
That is to put the numbers 2 and 3 into the memory area corresponding to x and y respectively. Quite simply, we can do this:
mov eax, 2 mov [x], eax mov eax, 3 mov [y], eax
That is, first throw 2 into register eax, and then put the contents of eax back into the memory corresponding to x. In the same way, y deals with it.
OK, the next addition statement:
z = x + y;
You can also do:
mov eax, [x] mov ebx, [y] add eax, ebx mov [z], eax
Well, this code should be understandable. Let's briefly explain the idea:
- Put the contents of the memory corresponding to x and y into eax and ebx respectively
- Add the shape of eax = eax + ebx, and the final sum is stored in eax
- Then store the contents of eax in the memory corresponding to z
Finally, we have another thing to deal with, that is, the return statement:
return z;
This is also easy to do. According to the Convention, the value in eax is the return value of the function:
mov eax, [z] ret
Even if the whole program is finished, we have completely written the assembly language equivalent form of C code. The final code is as follows:
global main
main:
mov eax, 2
mov [x], eax
mov eax, 3
mov [y], eax
mov eax, [x]
mov ebx, [y]
add eax, ebx
mov [z], eax
mov eax, [z]
ret
section .data
x dw 0
y dw 0
z dw 0First save it as a file TEST02 ASM, compile and run to see the effect:
$ nasm -f elf test02.asm -o test02.o $ gcc -m32 test02.o -o test02 $ ./test02 ; echo $? 5
Done. The result is completely consistent with the previous C code.
Uncover the true face of C program
Do you think you'll be finished with the equivalent assembly code of YY? Next, let's continue to use tools to find out and play it really.
Let's talk about the preparatory work. First, there are the following two documents:
test01.c test02.asm
One is the complete C code mentioned above and the other is the complete assembly code mentioned above. Then compile them into executable files according to the previous instructions. After compilation, it is as follows:
$ gcc -m32 test01.c -o test01 $ nasm -f elf test02.asm -o test02.o $ gcc -m32 -fno-lto test02.o -o test02 $ ls test01 test01.c test02 test02.asm test02.o
(note that you should follow the compilation command here)
test01 is compiled from C code and test02 is compiled from assembly code.
Sacrifice gdb
OK, next, let's welcome our general gdb on the stage.
Let's take a look at what our C compiled program looks like after disassembly:
gdb ./test01
Then enter the command to view the disassembly Code:
(gdb) set disassembly-flavor intel (gdb) disas main Dump of assembler code for function main: 0x080483ed <+0>: push ebp 0x080483ee <+1>: mov ebp,esp 0x080483f0 <+3>: mov DWORD PTR ds:0x804a024,0x2 0x080483fa <+13>: mov DWORD PTR ds:0x804a028,0x3 0x08048404 <+23>: mov edx,DWORD PTR ds:0x804a024 0x0804840a <+29>: mov eax,ds:0x804a028 0x0804840f <+34>: add eax,edx 0x08048411 <+36>: mov ds:0x804a020,eax 0x08048416 <+41>: mov eax,ds:0x804a020 0x0804841b <+46>: pop ebp 0x0804841c <+47>: ret End of assembler dump. (gdb) quit $
OK, don't worry. Quit first. Let's look at the disassembly code of our assembler:
gdb ./test02 (gdb) set disassembly-flavor intel (gdb) disas main 0x080483f0 <+0>: mov eax,0x2 0x080483f5 <+5>: mov ds:0x804a01c,eax 0x080483fa <+10>: mov eax,0x3 0x080483ff <+15>: mov ds:0x804a01e,eax 0x08048404 <+20>: mov eax,ds:0x804a01c 0x08048409 <+25>: mov ebx,DWORD PTR ds:0x804a01e 0x0804840f <+31>: add eax,ebx 0x08048411 <+33>: mov ds:0x804a020,eax 0x08048416 <+38>: mov eax,ds:0x804a020 0x0804841b <+43>: ret 0x0804841c <+44>: xchg ax,ax 0x0804841e <+46>: xchg ax,ax End of assembler dump. (gdb) quit
Well, we've all seen the disassembly code. First, check whether the disassembly code of test02 here is consistent with the assembly code we wrote:
0x080483f0 <+0>: mov eax,0x2 0x080483f5 <+5>: mov ds:0x804a01c,eax 0x080483fa <+10>: mov eax,0x3 0x080483ff <+15>: mov ds:0x804a01e,eax 0x08048404 <+20>: mov eax,ds:0x804a01c 0x08048409 <+25>: mov ebx,DWORD PTR ds:0x804a01e 0x0804840f <+31>: add eax,ebx 0x08048411 <+33>: mov ds:0x804a020,eax 0x08048416 <+38>: mov eax,ds:0x804a020 0x0804841b <+43>: ret
The direct comparison with the compilation written above is that due to the format problem, some of the addresses and labels inside are beyond recognition, but as long as we can identify them, we don't need to make them all clear. This is the previous assembly code:
mov eax, 2
mov [x], eax
mov eax, 3
mov [y], eax
mov eax, [x]
mov ebx, [y]
add eax, ebx
mov [z], eax
mov eax, [z]
retAs soon as you count down, it's the same. Take a closer look at each instruction. It's basically the same. Of course, x, y and z have disappeared and become some strange symbols. I won't delve into them here for the time being.
Let's look at the assembly code of C program:
0x080483ed <+0>: push ebp 0x080483ee <+1>: mov ebp,esp 0x080483f0 <+3>: mov DWORD PTR ds:0x804a024,0x2 0x080483fa <+13>: mov DWORD PTR ds:0x804a028,0x3 0x08048404 <+23>: mov edx,DWORD PTR ds:0x804a024 0x0804840a <+29>: mov eax,ds:0x804a028 0x0804840f <+34>: add eax,edx 0x08048411 <+36>: mov ds:0x804a020,eax 0x08048416 <+41>: mov eax,ds:0x804a020 0x0804841b <+46>: pop ebp 0x0804841c <+47>: ret
Here, leave aside the following instructions (these instructions themselves are useful, but in this example, they can be removed for the time being. Specifically, what they do, later), and remove them:
push ebp mov ebp, esp .... pop ebp
So C program disassembly becomes like this:
0x080483f0 <+3>: mov DWORD PTR ds:0x804a024,0x2 0x080483fa <+13>: mov DWORD PTR ds:0x804a028,0x3 0x08048404 <+23>: mov edx,DWORD PTR ds:0x804a024 0x0804840a <+29>: mov eax,ds:0x804a028 0x0804840f <+34>: add eax,edx 0x08048411 <+36>: mov ds:0x804a020,eax 0x08048416 <+41>: mov eax,ds:0x804a020 0x0804841c <+47>: ret
Or does it look unclear? What should I do? We trace the numbers 2, 3 and add instructions inside, replace those strange symbols with the labels x, y and z we know, and then look at:
0x080483f0 <+3>: mov [x],0x2 0x080483fa <+13>: mov [y],0x3 0x08048404 <+23>: mov edx,[x] 0x0804840a <+29>: mov eax,[y] 0x0804840f <+34>: add eax,edx 0x08048411 <+36>: mov [z],eax 0x08048416 <+41>: mov eax,[z] 0x0804841c <+47>: ret
Compare the assembly code we wrote earlier? Is it basically eight, nine and ten? There are only two differences: 1 The order of registers used is different, but it doesn't hurt; 2. There are two assembly instructions, and the disassembly code compiled in C corresponds to one instruction.
Here we found that
mov eax, 2 mov [x], eax
Can be reduced to one statement:
mov [x], 2
OK, according to the information provided by the C compiler, our assembler can also be simplified as follows:
global main
main:
mov [x], 0x2
mov [y], 0x3
mov eax, [x]
mov ebx, [y]
add eax, ebx
mov [z], eax
mov eax, [z]
ret
section .data
x dw 0
y dw 0
z dw 0However, when we compile the assembly in this way, we make an error. It can't be completely written in this way. We have to make some minor modifications to change the first two instructions to:
mov dword [x], 0x2
mov dword [y], 0x3In this way, there will be no problem. Through research, we have written an assembler equivalent to the code compiled by the previous C program:
global main
main:
mov dword [x], 0x2
mov dword [y], 0x3
mov eax, [x]
mov ebx, [y]
add eax, ebx
mov [z], eax
mov eax, [z]
ret
section .data
x dw 0
y dw 0
z dw 0summary
Well, here, we have implemented a simple C program in assembly language through nasm, gcc and gdb.
Let's talk about the key points of this paragraph:
- C program in the compilation stage, logically, will be transformed into an equivalent assembler
- The assembler is compiled into machine instructions through the built-in (or external) assembler of the compiler (there is a link stage in the process of reaching the executable file, which will be mentioned later)
- We can know the assembly form of a C program through gdb disassembly
In fact, the purpose of learning assembly language is not to program in assembly language in the future, but to further understand some details of high-level language at the bottom, such as an assignment statement of C language and an addition expression of C language, with the help of the understanding of assembly language. That is to realize what the program is doing and what the CPU is doing in the computer through assembly, and understand the essence of the computer program in the eyes of the CPU.
Later, it will be a very good choice to learn assembly language by combining various materials. In the process of practicing and understanding assembly, we can also know more clearly the various writing methods in C language and what meaning they represent, so as to deepen our understanding of C language.
crap
There are more codes and operations involved in this section. Of course, it's best to finish it patiently. If it's not enough in two days a day, it's worth it.