1, Bert introduction
bert is a language model technology applied in NLP field, and Transformer, Encoder and Decoder are its core technologies. The purpose of this blog is to teach you to get started bert quickly.
1.1 what problems can Bert solve
1. Combined with the context understanding semantics, it extracts all the referential relationships of a single word in the sentence in no order, and solves the problem of one-way information flow, which RNN\LSTM can't do.
2. Its advantage is to solve the problems of network bloated and slow calculation caused by stacking multi-layer LSTM.
Example:
The newly harvested millet this year is particularly delicious.
The new Xiaomi mobile phone released today is great.
Bert's essence is to help understand the specific meaning of "Xiaomi" in the sentence combined with contextual semantics.
1.2 Bert's pre knowledge
WORDTO NEC: text vectorization -- an expression of words and sentences that can be understood by the computer.
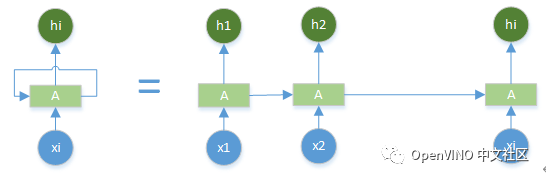
RNN\LSTM: basic network model, which can understand the semantics of text
2, Bert's architecture diagram
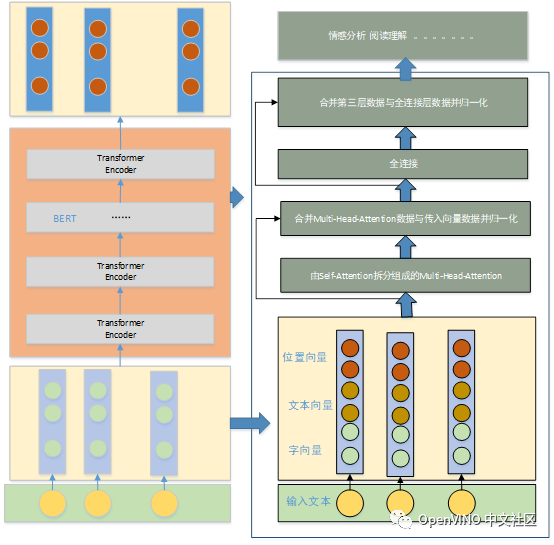
2.1 vector representation
The vector representation unit includes: word vector, text vector and position vector. The function of position vector is to solve the timing problem.
2.2 Bert structure
(1) Multi head attention composed of self attention split
Attention solves the problem that it cannot be executed in parallel, and achieves the effect of semantic expression at different levels through multi head mechanism. It is the core of transformer encoder.
(2) Merge incoming data with multi attention vector
The merging is completed by residual operation. Its purpose is to ensure that the network training effect will not deteriorate with the deepening of the network.
The purpose of normalization is to enhance the data,
Normalization is to normalize the data of hidden layer into standard normal distribution, which can accelerate the training speed and convergence.
(3) Full connection
The whole connection layer is used for data extraction. Two layers of full connection are used. The first layer uses the activation function to activate and extract features. The second layer transforms the dimension of the characteristic data of the first layer so that it can have the same dimension as the layerNorm of the first layer, which is convenient for residual calculation.
(4) Merge the third layer data and the full connection layer data and normalize them
The purpose of data merging by residual connection is to ensure that the main semantics are not lost after multi-layer feature extraction, so that the effect is better and better.
2.3 Application Layer
The application layer is mainly the specific application of feature data. The main scenes include: emotion analysis, reading comprehension, sequence annotation and so on.
3, BERT training
3.1 pre training tasks
1 Masked LM
Randomly cover up a certain proportion of words (tokens) in a sentence. The specific rules are as follows:
(1) Replace 80% of token s with "mask"
(2) 10% as is
(3) 10% were randomly replaced with other words and sentences.
2 NextSentence Prediction
The mechanism of predicting whether the two sentences are context is to give the correct and wrong sentences respectively, and let the model compare and learn.
Through the joint training of Masked LM task and next sense prediction task, Bert model makes the vector representation of each word / word output by the model describe the overall information of the input text (single sentence or sentence pair) as comprehensively and accurately as possible, so as to provide better initial values of model parameters for subsequent fine-tuning tasks.
3.2 training
BERT, which is represented by Transformer's bidirectional encoder. Unlike other recent language representation models, BERT aims to pre train deep bidirectional representation by jointly adjusting the context in all layers. Therefore, the pre trained BERT representation can be fine tuned through an additional output layer, which is suitable for the construction of state-of-the-art models for a wide range of tasks, such as question and answer tasks and language reasoning, without significant structural modifications for specific tasks.
The number of layers (i.e. the number of Transformer blocks) is expressed as L, the hidden size is expressed as H, and the number of self attention heads is expressed as A. In all experiments, the feedforward / filter size was set to 4H, i.e. 3072 at H=768 and 4096 at H=1024.
For comparison, the model size of BERTBASE is the same as that of OpenAI GPT. However, it is important that BERT Transformer uses bidirectional self attention, while GPT Transformer uses restricted self attention, where each token can only focus on the context to its left. It should be noted that in the literature, the bidirectional Transformer is usually called "Transformer encoder" in the literature, while the version focusing only on the left context is called "Transformer decoder" because it can be used for text generation. The comparison between BERT, OpenAI GPT and ELMo is shown in Figure 1 below.
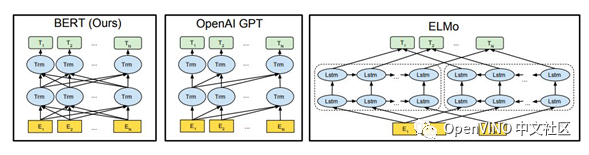
Figure 1: differences in pre training model architecture
BERT uses a bidirectional Transformer. OpenAI GPT uses a left to right Transformer. ELMo uses independently trained from left to right
And concatenation from right to left LSTM to generate the characteristics of downstream tasks. In the three models, only the BERT representation depends on the left and right context in all layers.
4, TinyBERT
4.1 TinyBERT introduction
Large models such as BERT have powerful performance, but it is difficult to deploy to devices with limited computing power and memory. Therefore, researchers from Huazhong University of science and technology and Huawei Noah's Ark laboratory proposed TinyBERT, a knowledge distillation method specially designed for transformer based models. The size of the model is less than 1 / 7 of that of BERT, but the speed is more than 9 times that of BERT, and the performance has not decreased significantly. At present, the paper has been submitted to machine learning summit ICLR 2020.
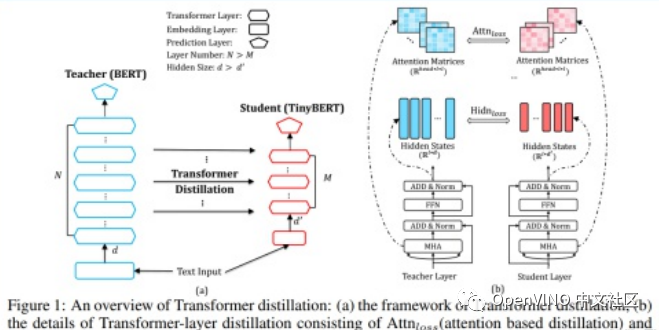
The above figure describes the process of bert knowledge distillation. The figure on the left summarizes the process of knowledge distillation as a whole: Teacher BERT on the left and Student TinyBERT on the right. The purpose of this paper is to transfer the knowledge learned by Teacher BERT to TinyBERT; The figure on the right describes the details of knowledge transfer. In the training process, the attention matrix and output of each transformer layer in Teacher BERT are selected as supervision information.
4.2 bertiny source code
Use the source code of bertiny to realize the NER (named entity recognition) task. Here, briefly record the ideas and methods. Here is only the source code of BERT. You can change the changed code according to your ideas, and you should also clarify your ideas.
The first step is to clarify the task: we regard the NER task as a sequence annotation task, and the annotation method adopts BIOES annotation. There are many annotation methods here, such as the most common BIO annotation, BMEOS annotation and so on. Generally speaking, B (Begin) represents the first token of entity, E (End) represents the last token of entity, I (Inside) represents the token in the middle of entity, O (Outside) represents the token of non entity, and S (Single) represents the entity with only one token.
For example: silly (B) big (I) sister (E) lend (O) mouth (O) to (O) second (B) sister (E) send (O) money (S)
The reason for adopting the BIOES annotation method is that the BIO annotation only focuses on the starting position of the entity boundary and the ending position is not clearly marked. The information marked by BIOES is richer and has the information of the complete entity boundary, which is more convenient for subsequent tasks.
The second step is to clarify the method: we know that the BERT model proposed by Google is the baseline of all NLP tasks, almost sweeping all previous methods. Sequence annotation task and BERT source code( https://github.com/google-research/bert )The text categorization task (run_classifier.py) in is similar. So I decided to make changes based on this code to adapt it to the sequence annotation task.
with open("train_data","rb") as f:
data = f.read().decode("utf-8")
train_data = data.split("\n\n")
train_data = [token.split("\n") for token in train_data]
train_data = [[j.split() for j in i ] for i in train_data]
train_data.pop()Load bert section
from kashgari.embeddings import BERTEmbeddingfrom kashgari.tasks.seq_labeling import BLSTMCRFModel
embedding = BERTEmbedding("bert-base-chinese", 200)Building training model
model = BLSTMCRFModel(embedding) model.fit(train_x,train_y,epochs=1,batch_size=100)
View network structure
__________________
Layer (type) Output Shape Param # Connected to ==================================================================================================
Input-Token (InputLayer) (None, 200)
__________________________________________________________________________________________________
Input-Segment (InputLayer) (None, 200) 0
(None, 200, 10) 1410 dense_3[0][0] ==================================================================================================
Total params: 103,603,714
Trainable params: 2,166,274
Non-trainable params: 101,437,440
__________________________________________________________________________________________________
Epoch 1/1506/506 [==============================] - 960s 2s/step - loss: 0.0377 - crf_accuracy: 0.2892 - acc: 0.2759
4.3 OpenVINO} model deployment
Using OpenVINO to deploy the model requires two tool suites: model optimizer and information engine Model optimizer is used to optimize the deep neural network model and convert it into a unified IR format model file that can be read, loaded and executed by the information engine. Information engine is a model inference function library that provides C++/python API. It is used to read, load, set model parameters and obtain inference results.
4.3.1 model transformation
First, we download the source code of OpenVINO from github. Enter the source code and use the following code to convert our onnx model into IR model
python3 <INSTALL_DIR>/deployment_tools/model_optimizer/mo.py \
--input_model INPUT_MODEL \
--output_dir <OUTPUT_MODEL_DIR>OUTPUT
Model Optimizer arguments:
Common parameters:
- Path to the Input Model: /root/autodl-tmp/uer_py_ner_part.onnx
- Path for generated IR: /root/autodl-tmp/uer_py_ner_part.xml
- IR output name: uer_py_ner_part
- Log level: ERROR
- Batch: Not specified, inherited from the model
- Input layers: Not specified, inherited from the model
- Output layers: Not specified, inherited from the model
- Input shapes: Not specified, inherited from the model
- Mean values: Not specified
- Scale values: Not specified
- Scale factor: Not specified
- Precision of IR: FP32
- Enable fusing: True
- Enable grouped convolutions fusing: True
- Move mean values to preprocess section: None
- Reverse input channels: False
ONNX specific parameters:
- Inference Engine found in: /usr/local/lib/python3.6/dist-packages/openvino
Inference Engine version: 2021.4.1-3926-14e67d86634-releases/2021/4
Model Optimizer version: custom_master_1ffeb24a419c8b9c328a4d6735f41c946ee8bae3
[ WARNING ] Model Optimizer and Inference Engine versions do no match.
[ WARNING ] Consider building the Inference Engine Python API from sources or reinstall OpenVINO (TM) toolkit using "pip install openvino" (may be incompatible with the current Model Optimizer version)
[ WARNING ] Convert data type of Parameter "input.1" to int32
[ WARNING ] Convert data type of Parameter "1" to int32
[ WARNING ] Convert data type of Parameter "input.5" to int32
[ SUCCESS ] Generated IR version 10 model.
[ SUCCESS ] XML file: /root/autodl-tmp/uer_py_ner_part.xml/uer_py_ner_part.xml
[ SUCCESS ] BIN file: /root/autodl-tmp/uer_py_ner_part.xml/uer_py_ner_part.bin
[ SUCCESS ] Total execution time: 1235.61 seconds.
[ SUCCESS ] Memory consumed: 1506 MB.
It's been a while, check for a new version of Intel(R) Distribution of OpenVINO(TM) toolkit here https://software.intel.com/content/www/us/en/develop/tools/openvino-toolkit/download.html?cid=other&source=prod&campid=ww_2021_bu_IOTG_OpenVINO-2021-3&content=upg_all&medium=organic or on the GitHub*Then we transformed the model into the IR model of OpenVINO. Let's do an experiment. Will this improve our reasoning speed.
4.3.2 Benchmark test using Benchmark
Benchmark Tool is used to evaluate the performance of deep learning reasoning on supported devices. Here, the performance benchmark differences of different computing platforms are tested for CPU and GPU. The following is the operation of GPU to perform the test:
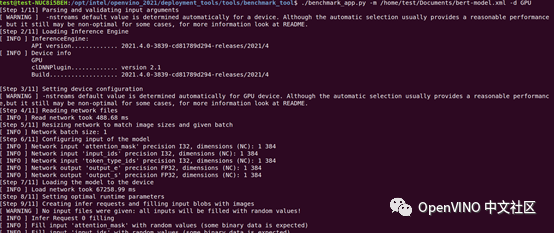
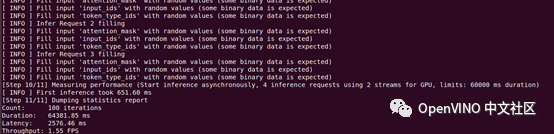
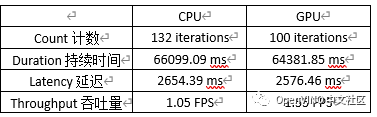
We found that the performance of the model on GPU is better. The specific data are shown in the table below:
4.3.3 model deployment
There are eight steps to model reasoning using OpenVINO's information engine, as shown in the figure:
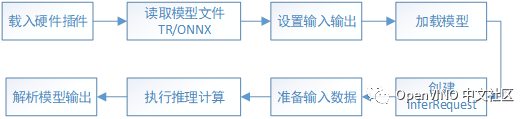
(1) Loading hardware plug-ins: create Core objects to manage all AI computing hardware;
(2) Read model: read the model file into the instance object of Network class;
(3) Set input / output: specify the accuracy and layout of model input / output;
(4) Load model: load the model with set parameters into the computing hardware with LoadNetwork() method;
(5) Create inferRequest: create an object for reasoning calculation;
(6) Prepare input data: prepare input data according to the input requirements of the model;
(7) Execute reasoning calculation: reasoning calculation is divided into synchronous reasoning and asynchronous reasoning;
(8) Analyze the output result: the output result is generally in tensor form, which is parsed into the desired format according to the coding rules.
It is very convenient to convert the trained pt model into onnx or IR format, which can be done in a few lines of code. Because the latest version of openvino is applicable to model reading in IR format and onnx format. Next, take onnx format as an example to illustrate the deployment process:
import os
import numpy as np
from openvino.inference_engine import IECore
from tqdm import tqdm
ie = IECore()
exec_net = ie.load_network(network=os.path.join(os.getcwd(), "uer_py_ner_part.onnx"), device_name="CPU")
print("loaded network")
ort_session_inputs = {}
ort_session_inputs["input.1"] = np.random.randint(2, size=(16, 128))
ort_session_inputs["1"] = np.random.randint(2, size=(16, 128))
result = exec_net.infer(ort_session_inputs)
print(result)
for i in tqdm(range(100)):
result = exec_net.infer(ort_session_inputs)
4.4 the reasoning code of onnx run time
import numpy as np
import onnx
import onnxruntime as ort
# Load the ONNX model
from tqdm import tqdm
model = onnx.load("./uer_py_ner_part.onnx")
# Check that the IR is well formed
onnx.checker.check_model(model)
# Print a human readable representation of the graph
# print(onnx.helper.printable_graph(model.graph))
def ort_session_test(ort_session):
outputs = ort_session.run(
[label_name],
ort_session_inputs,
)
# print(outputs)
# print(outputs[0])
if __name__ == '__main__':
ort_session = ort.InferenceSession("./uer_py_ner_part.onnx")
# print(ort_session)
label_name = ort_session.get_outputs()[0].name
# print(ort_session.get_inputs())
ort_session_inputs = {}
for input in ort_session.get_inputs():
# print(input)
# print(input.name)
# print(input.shape)
ort_session_inputs[str(input.name)] = np.random.randint(2, size=(16, 128))
# print(ort_session_inputs)
ort_session_test(ort_session)
for i in tqdm(range(100)):
ort_session_test(ort_session) 4.5 output comparison
There is no improvement in the corresponding speed of Microsoft's onnx run time. The following is the deployment effect of the same model.
100%|██████████| 100/100 [04:09<00:00, 2.49s/it]
It takes 4 minutes and 09 seconds
OpenVINO output
100%|██████████| 100/100 [03:21<00:00, 2.01s/it]
Now it only takes 3 minutes and 21 seconds. It has been greatly improved. You can still see the power of OpenVINO.
5, Summary
BERT is like Imagenet in the image field. It learns domain related knowledge in advance through difficult pre training tasks and strong network model, and then does downstream tasks. In terms of model deployment, as shown in the figure, there are only CPU machines. Through comparison, OpenVINO has superior performance and is a powerful tool for our engineering deployment.
 https://bss.csdn.net/m/topic/intel_openvino/index/2/0?utm_source=wenzhang2
https://bss.csdn.net/m/topic/intel_openvino/index/2/0?utm_source=wenzhang2