Introduction to Alibaba canal and its deployment, principle and use
Introduction to canal
What is canal
Alibaba B2B company, because of the characteristics of its business, sellers are mainly concentrated in China and buyers are mainly concentrated in foreign countries, so it has derived the demand for remote computer rooms in Hangzhou and the United States. Since 2010, Alibaba company has gradually tried to analyze logs based on database, obtain incremental changes and synchronize them, thus deriving the business of incremental subscription & consumption.
Canal is a middleware based on database incremental log parsing developed in java, which provides incremental data subscription and consumption. At present, canal mainly supports MySQL binlog parsing. After parsing, canal client is used to process the obtained relevant data. (database synchronization requires Alibaba's otter middleware, which is based on canal).
Here, we can simply understand canal as a tool for synchronizing incremental data:
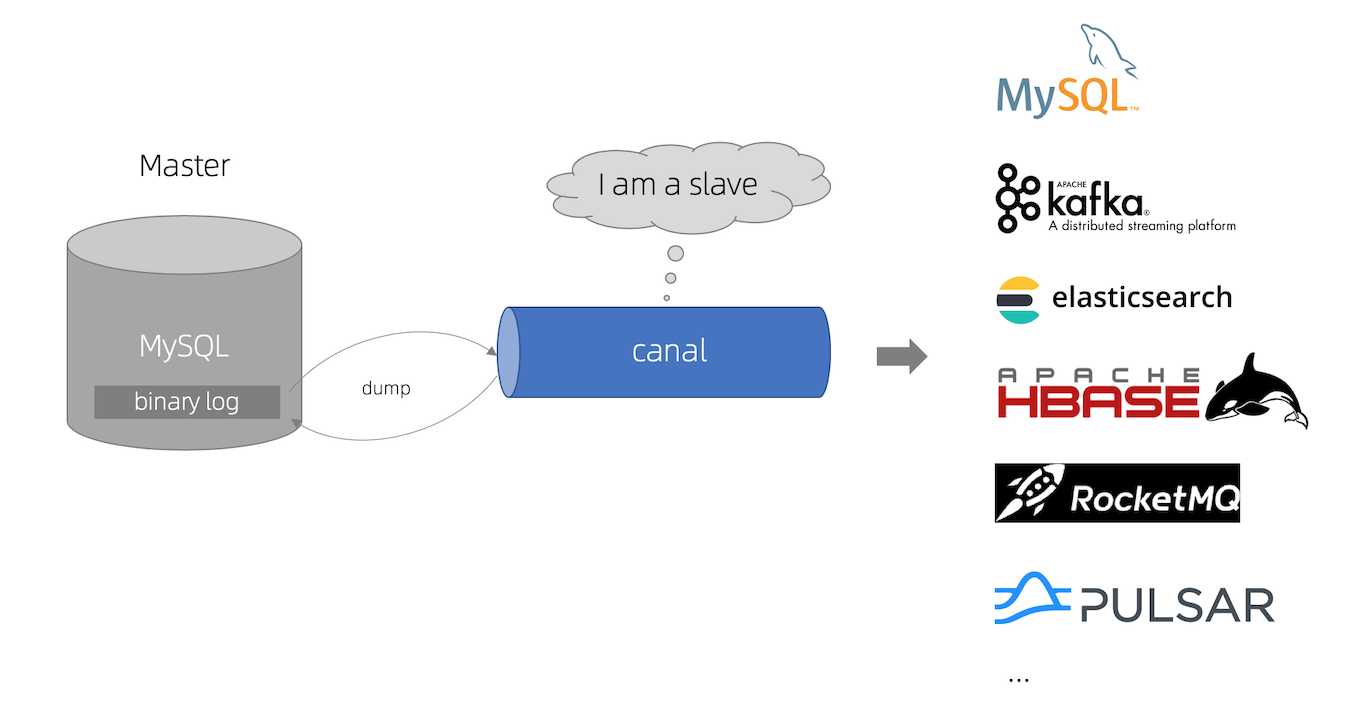
canal gets the changed data through binlog synchronization and sends it to the storage destination, such as MySQL, Kafka, Elastic Search and other multi-source synchronization.
canal usage scenario
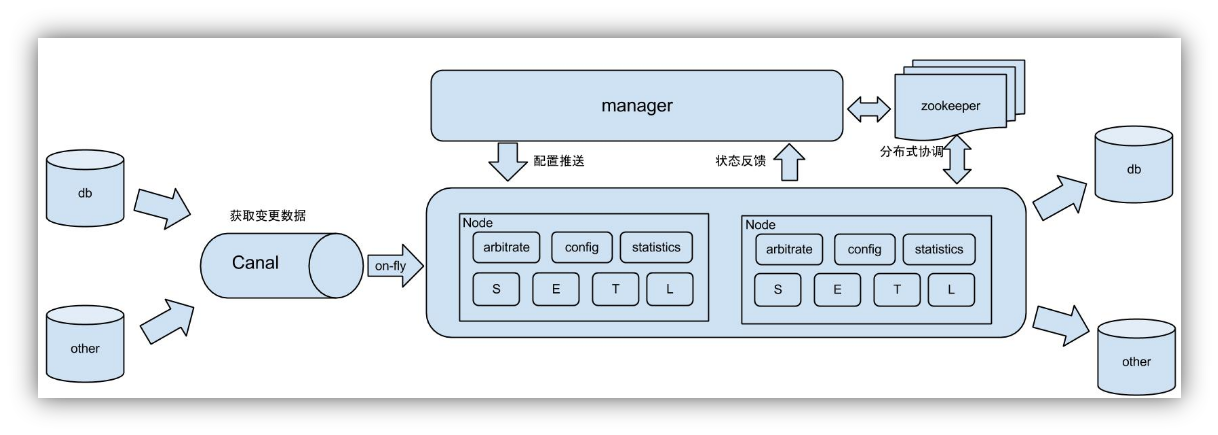
Scenario 1: original scenario, part of Alibaba otter Middleware
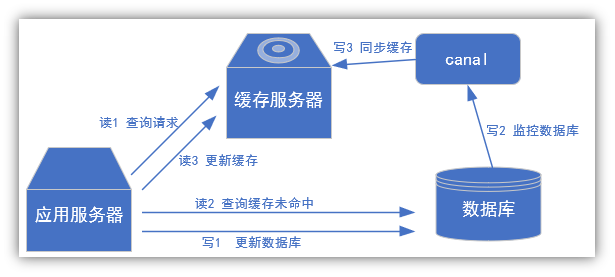
Scenario 2: update cache
Scenario 3: grab business data and add a change table to make a zipper table. (zipper table: records the life cycle of each information. Once the life cycle of a record ends, it is necessary to restart a new record and put the current date into the effective start date)
Scenario 4: capture the new change data in the business table for real-time statistics.
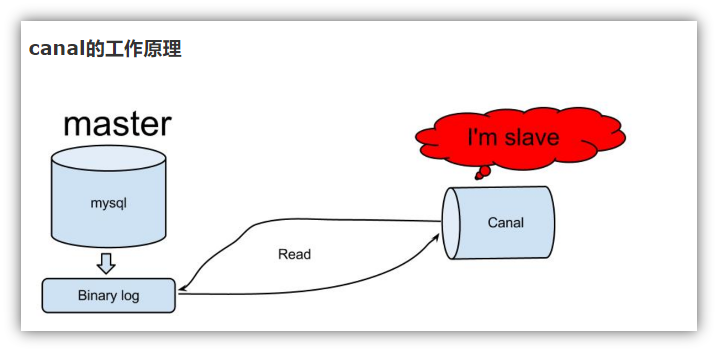
canal operating principle
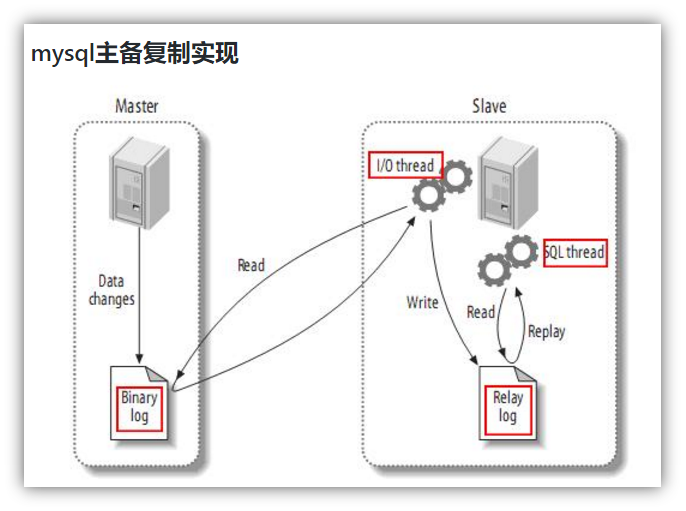
The replication process is divided into three steps:
-
The Master master database will change the record and write it to the binary log
-
Slave sends dump protocol from the database to mysql master, and copies the binary log events of master's main database to its relay log;
-
Slave reads and redoes the events in the relay log from the library and synchronizes the changed data to its own database.
canal works simply by pretending to be a slave and copying data from the master.
Introduction to MySQL binlog
What is binlog
MySQL binary log can be said to be the most important log of MySQL. It records all DDL and DML (except data query statements) statements in the form of events, as well as the time consumed by the execution of statements. MySQL binary log is transaction safe.
Generally speaking, opening binary logs will have a performance loss of about 1%. Binary has two most important usage scenarios:
First, MySQL Replication starts binlog on the Master side, and Mster passes its binary log to slaves to achieve the purpose of Master slave data consistency.
Second: recover data by using mysqlbinlog tool.
Binary log includes two types of files: binary log index file (file name suffix. Index) is used to record all binary files, and binary log file (file name suffix. 00000 *) records all DDL and DML (except data query statements) statement events in the database.
Open MySQL binlog
Start and restart MySQL in the MySQL configuration file to take effect. Generally, the path of MySQL configuration file under Linux system is basically / etc / my cnf ; log-bin=mysql-bin
This indicates that the prefix of binlog log is mysql bin, and the log file generated later is mysql bin The numbers after the 123456 file are generated in order. Each time mysql restarts or reaches the threshold of a single file size, a new file is created and numbered sequentially.
binlog classification settings
There are three formats of MySQL binlog: state, MIXED and ROW. In the configuration file, you can specify the configuration option: binlog_format=
Statement [statement level]
At the statement level, binlog records the statements that execute write operations each time.
Compared with row mode, it saves space, but may cause inconsistency, such as update table_name set create_date=now();
If the binlog log is used for recovery, the data may be different due to different execution time (the create_date is 2021-08-08 11:10:30 when the master drops the data, but the create_date may change to 2021-08-08 11:11:23 when the binlog drops the statement from the database, mainly because the statement execution time is asynchronous)
Advantages: space saving
Disadvantages: data inconsistency may occur
Row [row level]
At the row level, binlog will record the changes recorded in each row after each operation.
Advantages: maintain absolute consistency of data. Because no matter what the sql is or what function is referenced, it only records the effect after execution.
Disadvantages: it takes up a large space.
mixed [combines statement level and row level]
The upgraded version of statement solves the inconsistency of statement modes caused by some situations to a certain extent
In some cases, such as:
○ when UUID() is included in the function;
○ including auto_ When the table of the increment field is updated;
○ when the INSERT DELAYED statement is executed;
○ when using UDF;
It will be handled in the way of ROW
Advantages: save space while taking into account a certain degree of consistency.
Disadvantages: inconsistencies still occur in some rare cases. In addition, statement and mixed are inconvenient for monitoring binlog.
Environmental preparation
Machine planning
I use four machines here:
Machine planning: ops01, ops02 and ops03 are used to install kafka + zookeeper + canal clusters; ops04 is used to deploy MySQL services. During the test, MySQL can be deployed in one of the three clusters
11.8.37.50 ops01
11.8.36.63 ops02
11.8.36.76 ops03
11.8.36.86 ops04
All four machines configure host name hosts resolution in / etc/hosts
Installing and configuring MySQL
Create new databases and tables for business simulation. The installation steps are not introduced here. If MySQL has not been installed, you can refer to the previous article "Introduction to hive and hive deployment, principle and use" for detailed installation steps of MySQL;
After installing MySQL, make basic settings and configurations
# Login to mysql root@ops04:/root #mysql -uroot -p123456 mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 442523 Server version: 5.7.29 MySQL Community Server (GPL) Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. # Add canal user and configure permissions mysql> GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal'; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> quit; Bye # Modify MySQL configuration file and add binlog related configuration items root@ops04:/root #vim /etc/my.cnf # binlog server-id=1 log-bin=mysql-bin binlog_format=row binlog-do-db=gmall
Create a new gmall library. In fact, all libraries can be created as long as they correspond to the configuration file above
Restart MySQL:
root@ops04:/root #mysql -V
mysql Ver 14.14 Distrib 5.7.29, for Linux (x86_64) using EditLine wrapper
root@ops04:/root #systemctl status mysqld
● mysqld.service - MySQL Server
Loaded: loaded (/usr/lib/systemd/system/mysqld.service; enabled; vendor preset: disabled)
Active: active (running) since Wed 2021-05-26 09:30:25 CST; 2 months 22 days ago
Docs: man:mysqld(8)
http://dev.mysql.com/doc/refman/en/using-systemd.html
Main PID: 32911 (mysqld)
Memory: 530.6M
CGroup: /system.slice/mysqld.service
└─32911 /usr/sbin/mysqld --daemonize --pid-file=/var/run/mysqld/mysqld.pid
May 26 09:30:18 ops04 systemd[1]: Starting MySQL Server...
May 26 09:30:25 ops04 systemd[1]: Started MySQL Server.
root@ops04:/root #
root@ops04:/root #systemctl restart mysqld
root@ops04:/root #
[note]: after the binlog configuration is added and the MySQL service is restarted, there will be relevant binlog files in the storage directory. The format is as follows
root@ops04:/var/lib/mysql #ll | grep mysql-bin -rw-r----- 1 mysql mysql 1741 Aug 17 14:27 mysql-bin.000001 -rw-r----- 1 mysql mysql 19 Aug 17 11:18 mysql-bin.index
Verify the canal user login:
root@ops04:/root #mysql -ucanal -pcanal -e "show databases" mysql: [Warning] Using a password on the command line interface can be insecure. +--------------------+ | Database | +--------------------+ | information_schema | | gmall | | mysql | | performance_schema | | sys | +--------------------+ root@ops04:/root #
Create a new table in the gmall library and insert some sample data for testing:
CREATE TABLE `canal_test` (
`temperature` varchar(255) DEFAULT NULL,
`height` varchar(255) DEFAULT NULL,
`weight` varchar(255) DEFAULT NULL,
`article` varchar(255) DEFAULT NULL,
`date` date DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO `canal_test`(`temperature`, `height`, `weight`, `article`, `date`) VALUES ('36.5', '1.70', '180', '4', '2021-06-01');
INSERT INTO `canal_test`(`temperature`, `height`, `weight`, `article`, `date`) VALUES ('36.4', '1.70', '160', '8', '2021-06-02');
INSERT INTO `canal_test`(`temperature`, `height`, `weight`, `article`, `date`) VALUES ('36.1', '1.90', '134', '1', '2021-06-03');
INSERT INTO `canal_test`(`temperature`, `height`, `weight`, `article`, `date`) VALUES ('37.3', '1.70', '110', '14', '2021-06-04');
INSERT INTO `canal_test`(`temperature`, `height`, `weight`, `article`, `date`) VALUES ('35.7', '1.70', '133', '0', '2021-06-05');
INSERT INTO `canal_test`(`temperature`, `height`, `weight`, `article`, `date`) VALUES ('36.8', '1.90', '200', '6', '2021-06-06');
INSERT INTO `canal_test`(`temperature`, `height`, `weight`, `article`, `date`) VALUES ('37.5', '1.70', '132', '25', '2021-06-07');
INSERT INTO `canal_test`(`temperature`, `height`, `weight`, `article`, `date`) VALUES ('35.7', '1.70', '160', '2', '2021-06-08');
INSERT INTO `canal_test`(`temperature`, `height`, `weight`, `article`, `date`) VALUES ('36.3', '1.80', '131.4', '9', '2021-06-09');
INSERT INTO `canal_test`(`temperature`, `height`, `weight`, `article`, `date`) VALUES ('37.3', '1.70', '98.8', '4', '2021-06-10');
Install kafka + zookeeper
In order to realize the high availability of canal, the specific installation steps are not introduced here to reduce the length. You can refer to the previous article "Introduction to Kafka and introduction to Kafka deployment, principle and use" for the detailed installation steps of Kafka;
Query the cluster running status of kafka and zookeeper ports:
wangting@ops03:/opt/module >ssh ops01 'sudo netstat -tnlpu| grep -E "9092|2181"' tcp6 0 0 :::9092 :::* LISTEN 42305/java tcp6 0 0 :::2181 :::* LISTEN 41773/java wangting@ops03:/opt/module >ssh ops02 'sudo netstat -tnlpu| grep -E "9092|2181"' tcp6 0 0 :::9092 :::* LISTEN 33518/java tcp6 0 0 :::2181 :::* LISTEN 33012/java wangting@ops03:/opt/module >ssh ops03 'sudo netstat -tnlpu| grep -E "9092|2181"' tcp6 0 0 :::9092 :::* LISTEN 102886/java tcp6 0 0 :::2181 :::* LISTEN 102422/java
Installing and deploying canal
Ali's canal project address is: https://github.com/alibaba/canal , you can click release on the right side of the GitHub page to view the download of various versions. It is recommended that you have the energy to check more popular items on the Alibaba home page. Many items are becoming more and more popular.
Download installation package
# Download installation package wangting@ops03:/opt/software >wget https://github.com/alibaba/canal/releases/download/canal-1.1.5/canal.deployer-1.1.5.tar.gz wangting@ops03:/opt/software >ll | grep canal -rw-r--r-- 1 wangting wangting 60205298 Aug 17 11:23 canal.deployer-1.1.5.tar.gz
Decompression installation
# Create a new canal decompression directory [note]: there is no top-level canal directory extracted from the official project, so create a new directory for decompressing components wangting@ops03:/opt/software >mkdir -p /opt/module/canal wangting@ops03:/opt/software >tar -xf canal.deployer-1.1.5.tar.gz -C /opt/module/canal/
Modify canal master configuration
# Modify canal Master profile wangting@ops03:/opt/module/canal >cd conf/ wangting@ops03:/opt/module/canal/conf >ll total 28 -rwxrwxr-x 1 wangting wangting 319 Apr 19 15:48 canal_local.properties -rwxrwxr-x 1 wangting wangting 6277 Apr 19 15:48 canal.properties drwxrwxr-x 2 wangting wangting 4096 Aug 17 13:49 example -rwxrwxr-x 1 wangting wangting 3437 Apr 19 15:48 logback.xml drwxrwxr-x 2 wangting wangting 4096 Aug 17 13:49 metrics drwxrwxr-x 3 wangting wangting 4096 Aug 17 13:49 spring # Change the following configuration: zk | synchronization policy target mode | kafka wangting@ops03:/opt/module/canal/conf >vim canal.properties canal.zkServers =ops01:2181,ops02:2181,ops03:2181 canal.serverMode = kafka kafka.bootstrap.servers = ops01:9092,ops02:9092,ops03:9092
Modify the instance configuration of canal - (mysql to kafka)
# Configure instance related configuration: canal can enable multiple instances. One instance corresponds to one directory configuration. For example, copy the example directory to xxx and start the configuration change under xxx directory, which is a new instance wangting@ops03:/opt/module/canal/conf >cd example/ wangting@ops03:/opt/module/canal/conf/example >ll total 4 -rwxrwxr-x 1 wangting wangting 2106 Apr 19 15:48 instance.properties # Note 11.8 38.86:3306 you need to change the mysql address and port of your own environment. Secondly, change the user name and password to your own environment, and customize a topic wangting@ops03:/opt/module/canal/conf/example >vim instance.properties canal.instance.master.address=11.8.38.86:3306 canal.instance.dbUsername=canal canal.instance.dbPassword=canal canal.mq.topic=wangting_test_canal canal.mq.partitionsNum=12
Distribute installation directory
# Distribute the modified canal directory to two other servers: wangting@ops03:/opt/module >scp -r /opt/module/canal ops01:/opt/module/ wangting@ops03:/opt/module >scp -r /opt/module/canal ops02:/opt/module/
Start canal cluster
# Each server starts the cluster canal in turn wangting@ops03:/opt/module >cd /opt/module/canal/bin/ wangting@ops03:/opt/module/canal/bin >./startup.sh wangting@ops02:/home/wangting >cd /opt/module/canal/bin/ wangting@ops02:/opt/module/canal/bin >./startup.sh wangting@ops01:/home/wangting >cd /opt/module/canal/bin/ wangting@ops01:/opt/module/canal/bin >./startup.sh
Verification results
# Monitor kafka on a server
wangting@ops03:/opt/module/canal/bin >kafka-console-consumer.sh --bootstrap-server ops01:9092,ops02:9092,ops03:9092 --topic wangting_test_canal
[2021-08-17 14:21:29,924] WARN [Consumer clientId=consumer-console-consumer-17754-1, groupId=console-consumer-17754] Error while fetching metadata with correlation id 2 : {wangting_test_canal=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
As expected, if the gmall database in MySQL on ops04 is successfully monitored, if there is any data change in the table in gmall database, the console will output information and update it to the foreground synchronously in real time
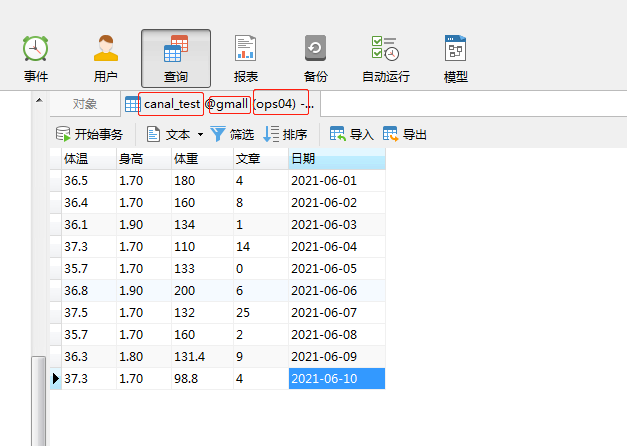
Data in current table:
Change the data observation console output in the table:
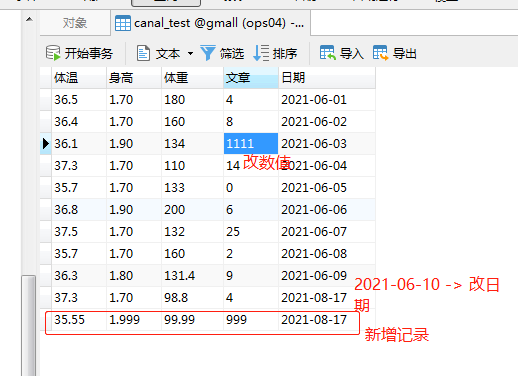
1. Set 2021-06-10 - > 2021-08-17
2. Add a new piece of data
3. Change a value to 1 - > 1111
wangting@ops03:/opt/module/canal/bin >kafka-console-consumer.sh --bootstrap-server ops01:9092,ops02:9092,ops03:9092 --topic wangting_test_canal
[2021-08-17 14:21:29,924] WARN [Consumer clientId=consumer-console-consumer-17754-1, groupId=console-consumer-17754] Error while fetching metadata with correlation id 2 : {wangting_test_canal=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
{"data":[{"temperature":"37.3","height":"1.70","weight":"98.8","article":"4","date":"2021-08-17"}],"database":"gmall","es":1629185045000,"id":6,"isDdl":false,"mysqlType":{"temperature":"varchar(255)","height":"varchar(255)","weight":"varchar(255)","article":"varchar(255)","date":"date"},"old":[{"date":"2021-06-10"}],"pkNames":null,"sql":"","sqlType":{"temperature":12,"height":12,"weight":12,"article":12,"date":91},"table":"canal_test","ts":1629185063194,"type":"UPDATE"}
{"data":[{"temperature":"35.55","height":"1.999","weight":"99.99","article":"999","date":"2021-08-17"}],"database":"gmall","es":1629185086000,"id":7,"isDdl":false,"mysqlType":{"temperature":"varchar(255)","height":"varchar(255)","weight":"varchar(255)","article":"varchar(255)","date":"date"},"old":null,"pkNames":null,"sql":"","sqlType":{"temperature":12,"height":12,"weight":12,"article":12,"date":91},"table":"canal_test","ts":1629185104967,"type":"INSERT"}
{"data":[{"temperature":"36.1","height":"1.90","weight":"134","article":"1111","date":"2021-06-03"}],"database":"gmall","es":1629185104000,"id":8,"isDdl":false,"mysqlType":{"temperature":"varchar(255)","height":"varchar(255)","weight":"varchar(255)","article":"varchar(255)","date":"date"},"old":[{"article":"1"}],"pkNames":null,"sql":"","sqlType":{"temperature":12,"height":12,"weight":12,"article":12,"date":91},"table":"canal_test","ts":1629185122499,"type":"UPDATE"}
It can be clearly seen that each change can be presented in the record, and the old data can correspond to the current data one by one. Up to now, the whole process chain of canal is all through, and the methods of synchronizing canal to different storage media are basically the same.
Extension:
You can view the canal information on the zookeeper command line:
wangting@ops01:/opt/module/canal/bin >zkCli.sh Connecting to localhost:2181 [zk: localhost:2181(CONNECTED) 0] ls -w / [hbase, kafka, otter, wangting, zookeeper] [zk: localhost:2181(CONNECTED) 1] ls -w /otter [canal] [zk: localhost:2181(CONNECTED) 2] ls -w /otter/canal [cluster, destinations]
The process chain is all inclusive, and the methods of synchronizing canal to different storage media are basically the same.
Extension:
You can view the canal information on the zookeeper command line:
wangting@ops01:/opt/module/canal/bin >zkCli.sh Connecting to localhost:2181 [zk: localhost:2181(CONNECTED) 0] ls -w / [hbase, kafka, otter, wangting, zookeeper] [zk: localhost:2181(CONNECTED) 1] ls -w /otter [canal] [zk: localhost:2181(CONNECTED) 2] ls -w /otter/canal [cluster, destinations]