Pre-environment
You need to set up a hadoop pseudo-distributed cluster platform, which you can see in this tutorial Quick Start Tutorial for Hadoop Big Data Technology and Pseudo-Distributed Clustering
Eclipse Environment Configuration
Eclipse(Windows Local System)
1. Install plug-ins:
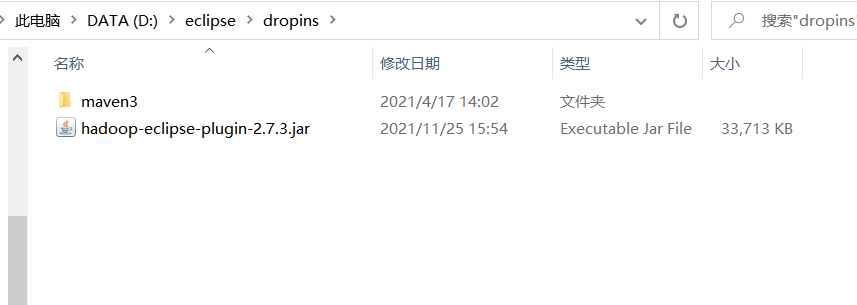
hadoop-eclipse-plugin-2.7.3.jar
Address: https://pan.baidu.com/s/1BaAOQkZaY4RvUPuBPVlgJg Extraction code: 067u
Copy the plug-in to the dropins directory in the eclipse directory
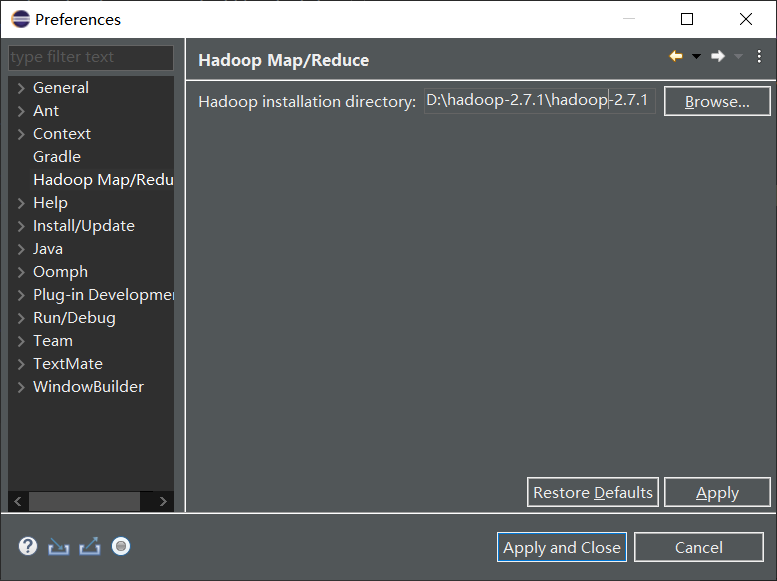
2. Configure the MapReduce environment:
After configuring the Hadoop plug-in, configure the development environment to connect to the Hadoop cluster as follows:
(1) Increase the Map/Reduce ribbon
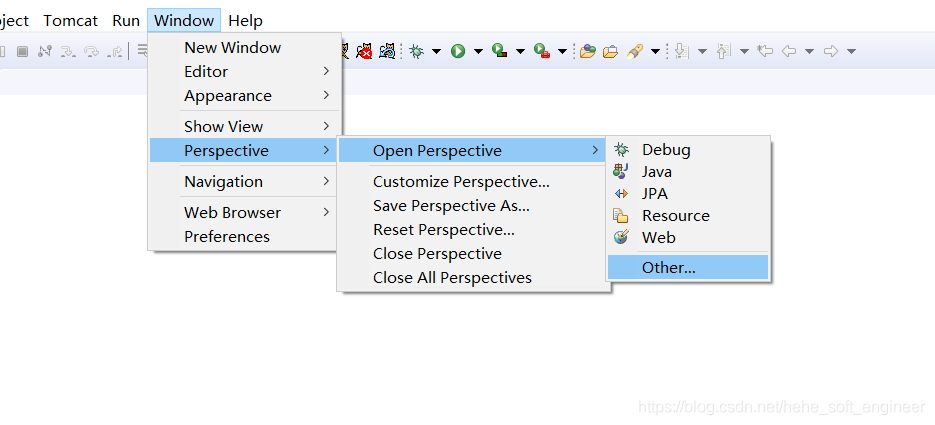
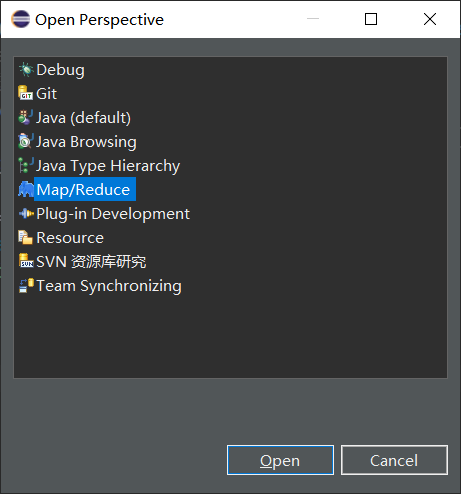
(2) Increase connectivity to the Hadoop cluster
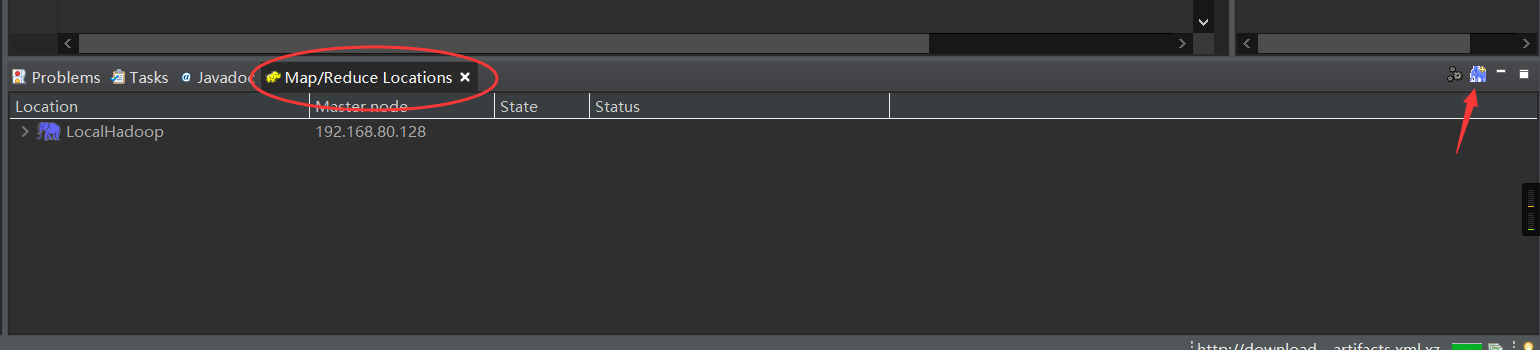
Point Blue Elephant creates a new Locations
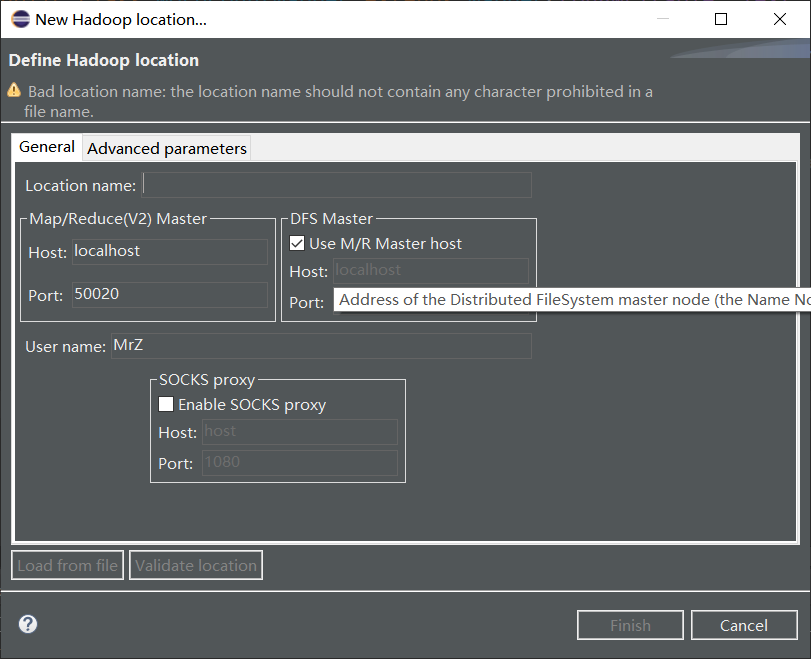
Here are the following:
Related connection configuration information is:
1 Location name: Name the new Haop connection and write it freely
Map/Reduce(V2)Master: Fill in the IP and port of ReurceManager for the Hadoop cluster, and look for yarn-site.xml that previously configured the Hadoop cluster
(3) DFS Master: Fill in the IP and port of Name Node of the Hadoop cluster and look for it from the previously configured core-site.xml
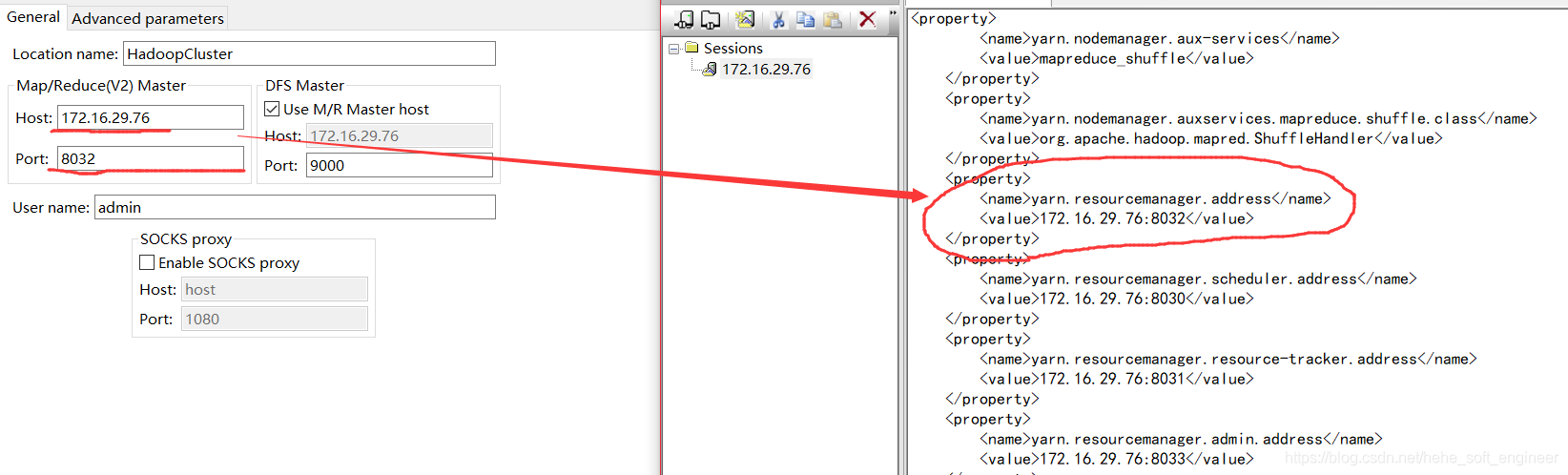
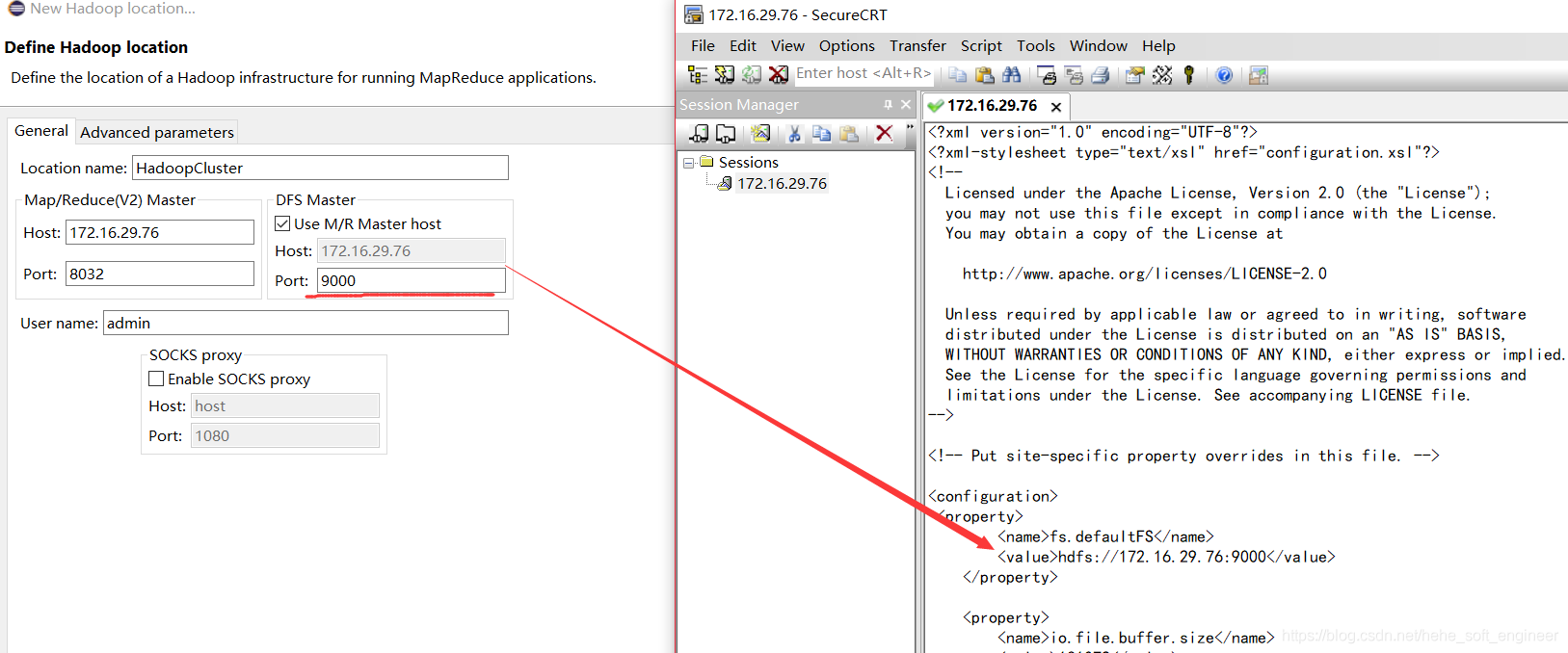
If you do not configure the port, you can use the default settings and finish the configuration.
There's a hole here. Clicking on Locations you've created may cause an error, but if it's set up correctly, it doesn't matter to him
(3) Browse directories and files on HDFS
After configuring the connection information for the Hadoop cluster, you can browse the directories and files on HDFS from the Eclipse interface, and also use the mouse to perform file operations.
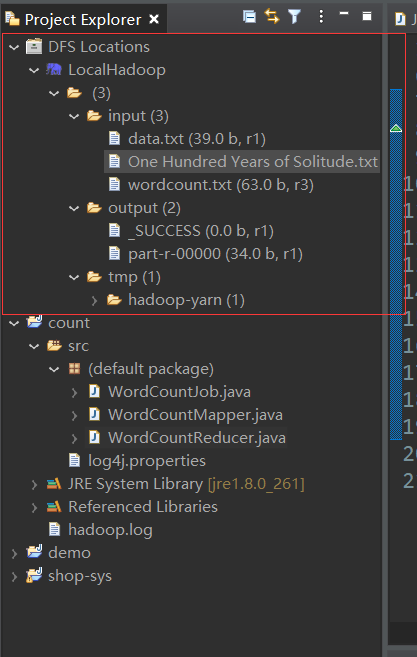
It is important to note that after performing the operation, the HDFS list needs to be refreshed to get the latest status of the file directory.
3. New MapReduce Project
This section establishes the MapReduce project MemberCount in Eclipse, roughly in the following four steps:
(1) Import the jar package that MapReduce runs on
First import the hadoop package from the virtual environment into the local environment, following the process:
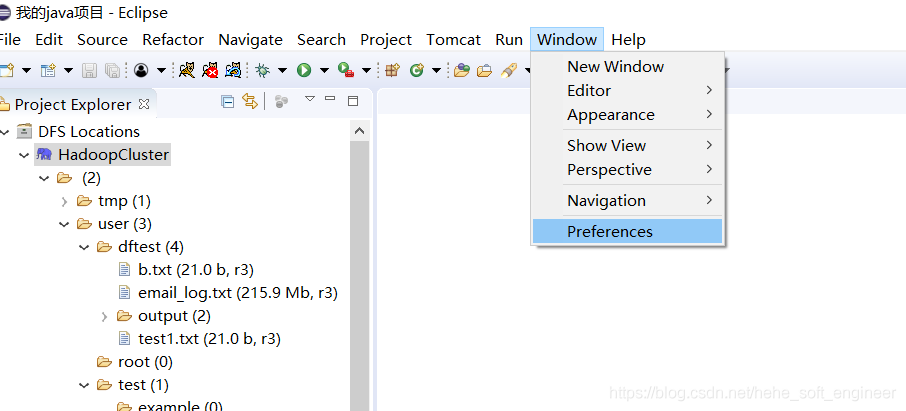
Here you need to unzip a hadoop under the local windows system and set the path.
(2) Create a MapReduce project
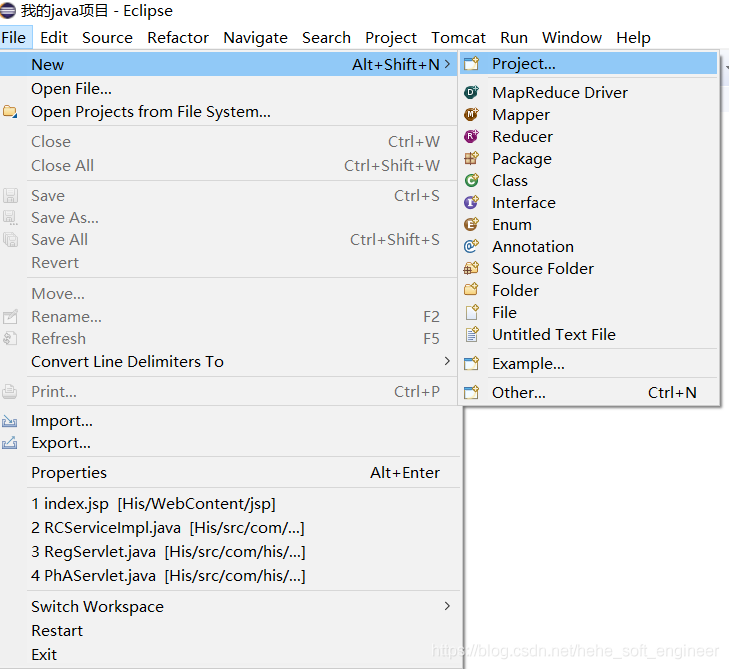
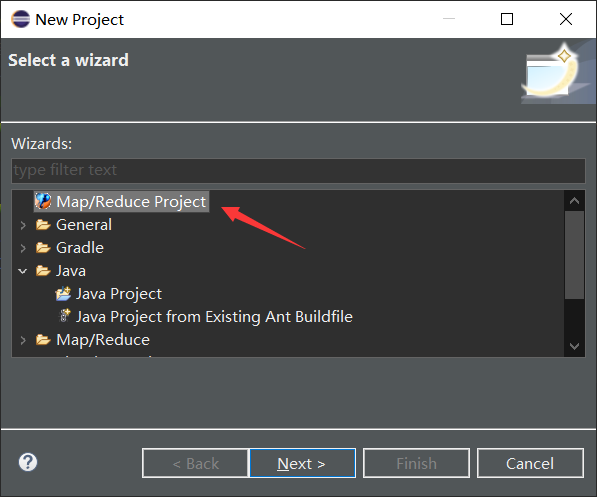
(3) Create a project on the interface of MapReduce Project
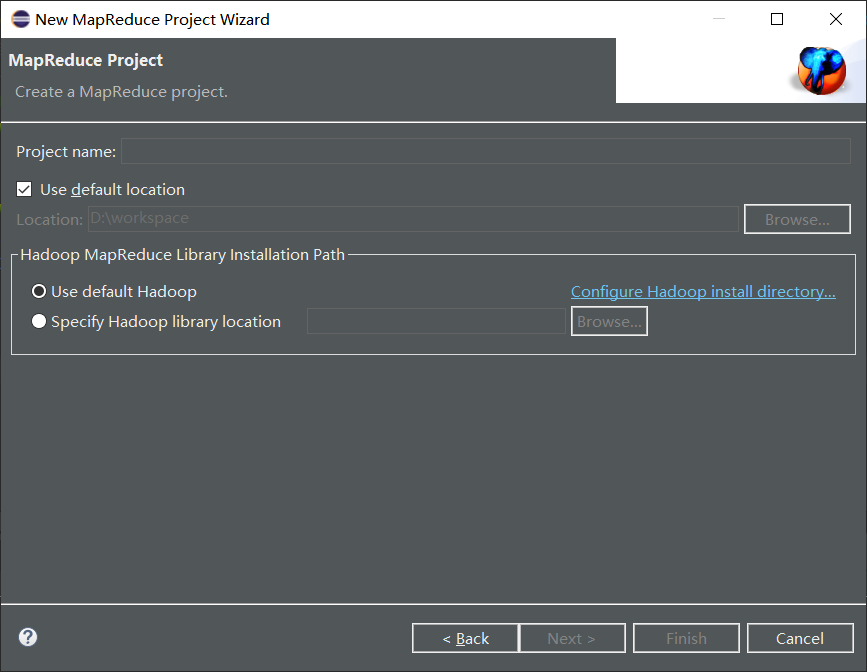
(4) Check whether the project has been created properly
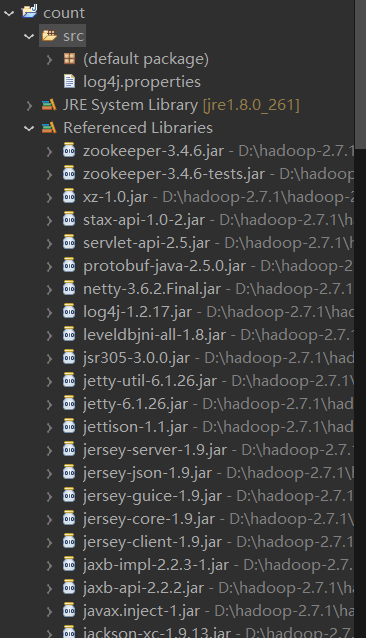
Set log4j.properties
A new log4j.properties file needs to be created in the project's src directory, which contains the following
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
Other miscellaneous pits and environmental settings
1. Computer username cannot have spaces
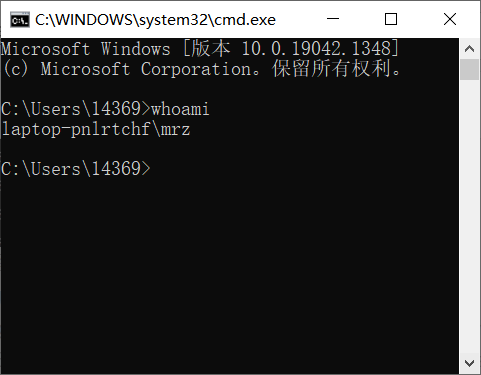
Use the following command in cmd to view user names
whoami
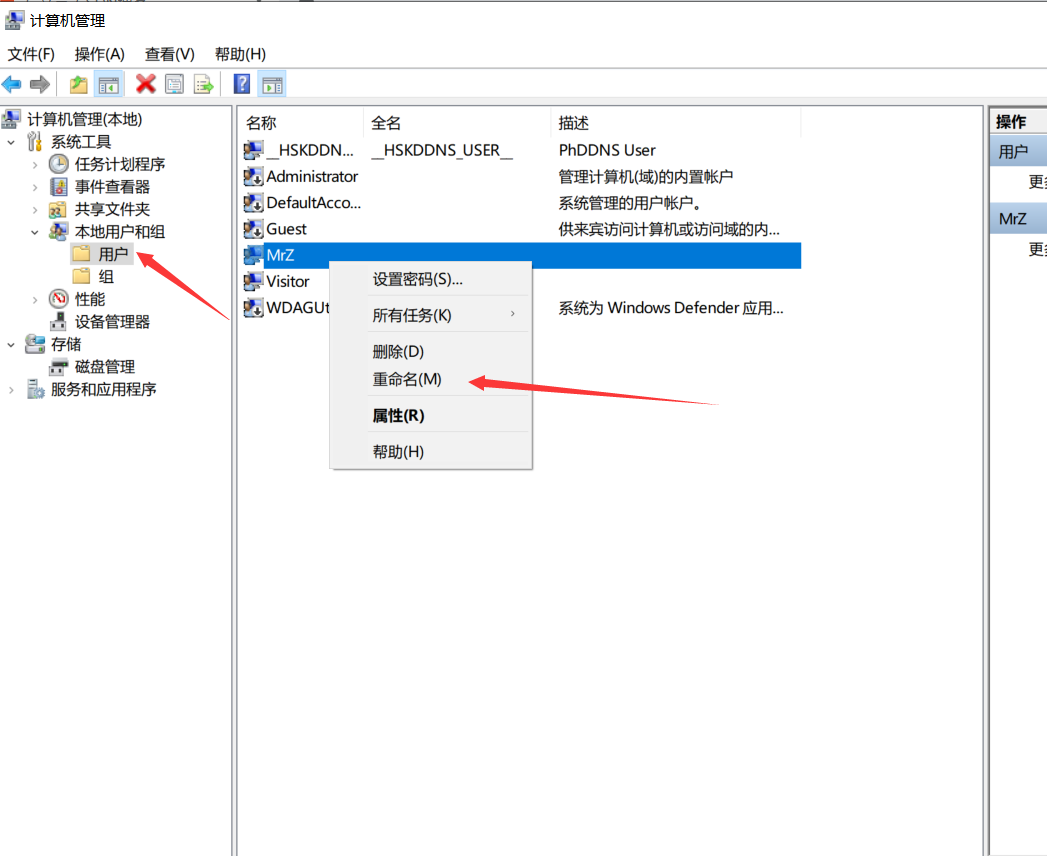
The modifications are as follows:
Right-click the Start button and select Computer Management. Make the changes as shown in the figure below. The changes need to be restarted before they take effect, but do not restart urgently because there are still others behind them.
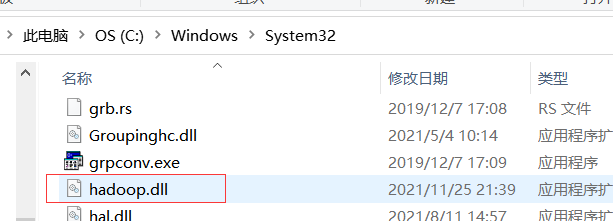
2. The hadoop.dll is missing
In this link https://github.com/4ttty/winutils Find the corresponding version of hadoop.dll Download
Then put it in the C:WindowsSystem32 directory
3. The winutils.exe file is also required under Windows
https://github.com/4ttty/winutils Find the appropriate version of winutils.exe Download
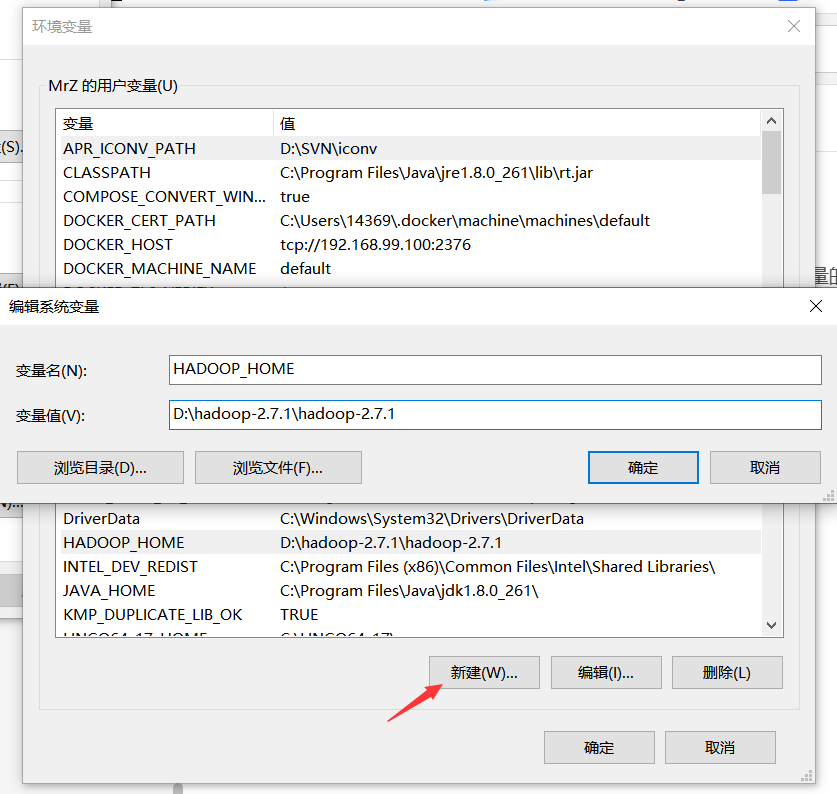
Then put it in the bin folder in the local hadoop directory and set the environment variable
Create the following new system variable HADOOP_HOME, installation directory with a value of hadoop
Then set the Path variable, adding one item as
%HADOOP_HOME%\bin
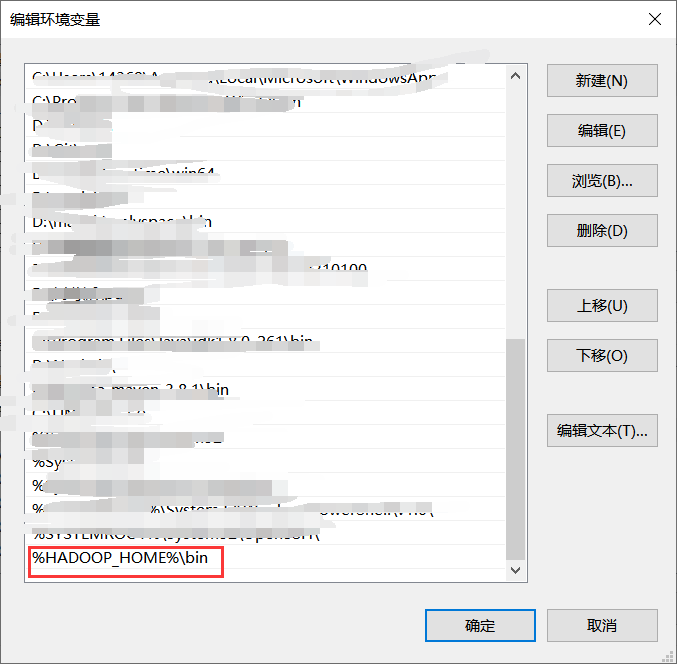
Effective after restart
4. Modify dfs.permissions to false
Switch to the path shown below
Add the following property using the command vim hdfs-site.xml and modify its value to false if it already exists
<property> <name>dfs.permissions</name> <value>false</value> </property>
MapReduce Program Case--Word Frequency Statistics Program
directory structure
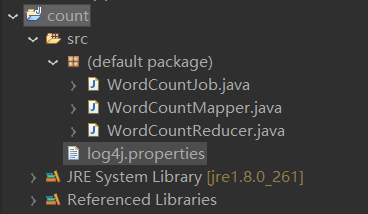
Code
WordCountMapper class, which inherits from Hadoop's Mapper:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// key offset value per line of text: I love Guiyang
// Separate each line of text by space: [I,love,Guiyang]
String line = value.toString(); // Conversion of data types
String[] words = line.split(" "); // Split the string [I,love,Guiyang]
for (int i = 0; i < words.length; i++) {
// (I,1)
Text word = new Text(words[i]);
IntWritable value2 = new IntWritable(1);
context.write(word,value2);
}
}
}
WordCountReducer class, Reducer inherited from Hadoop:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable,Text, IntWritable> {
@Override
protected void reduce(Text k3, Iterable<IntWritable> v3, Context context) throws IOException, InterruptedException {
// To sum, you need to calculate the length of v3
// <I,[1,1]>
int count = 0;
for (IntWritable v: v3) {
int value = v.get();
count += value;
}
context.write(k3,new IntWritable(count));
}
}
WordCountJob class:
import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountJob {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { // Serialized Job
Job job = Job.getInstance();
job.setJarByClass(WordCountJob.class); // Set Mapper
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); // Set Reducer
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); // Indicates the path to the input file
FileInputFormat.setInputPaths(job,new Path("hdfs://192.168.80.128:8020/input/One Hundred Years of Solitude.txt "); //Indicates the path to the output file
FileOutputFormat.setOutputPath(job,new Path("d:/mr_result/wc01")); // Start running the task
boolean completion = job.waitForCompletion(true);
if (completion){
System.out.println("The program ran successfully~");
}
else { System.out.println("Program failed to run~"); }
}
}
Execute locally
Create the input file wordcount.txt, which contains:
I love Guiyang I love Guizhou Guiyang is the capical of Guizhou
Set the local input file path in line 16 of the WordCountJob class
FileInputFormat.setInputPaths(job,new Path("d:/wordcount.txt"));
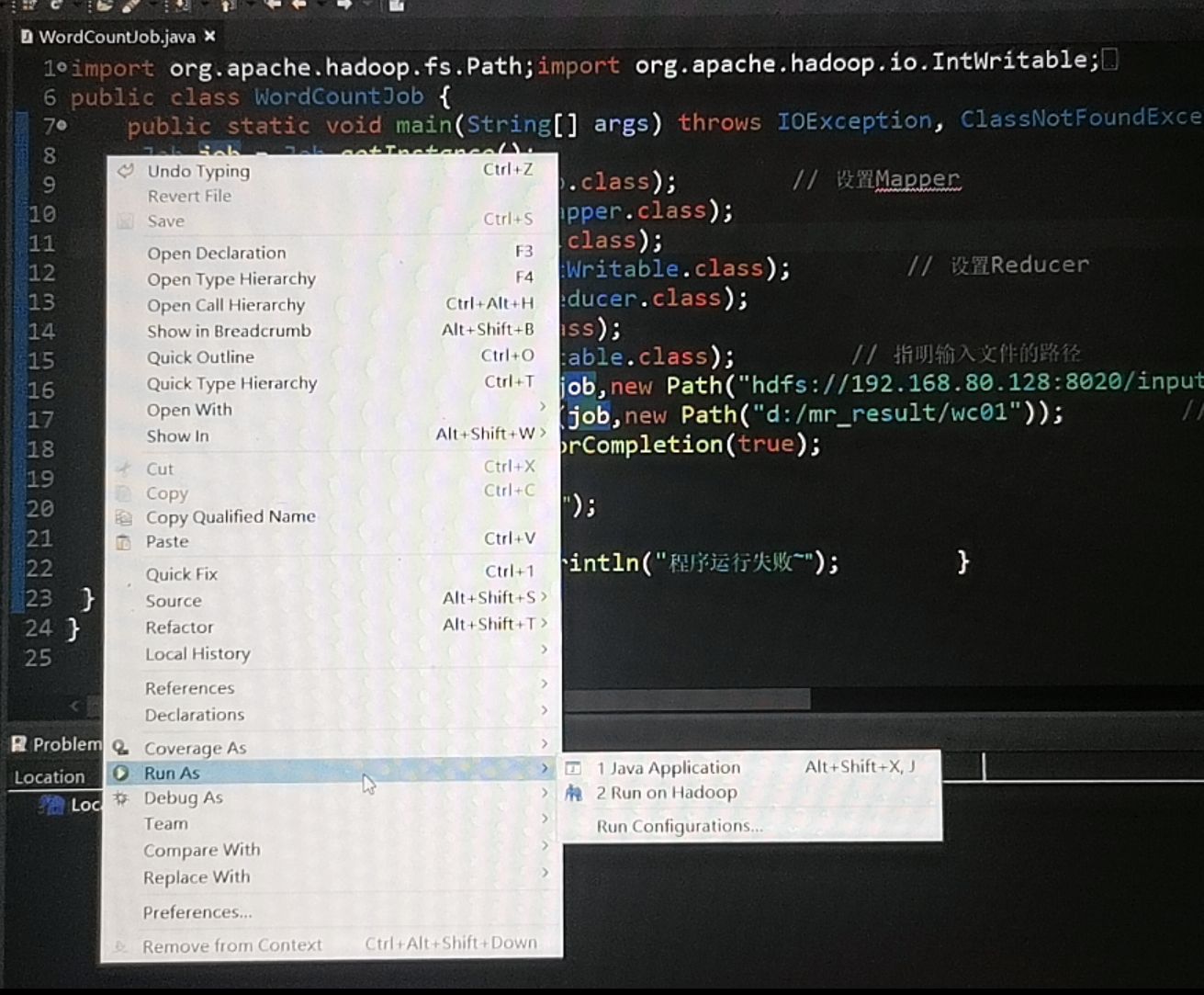
Right-click in the WordCountJob class and select Run As - [1 Java Application]
If the error is shown in the following figure, the output path already exists, delete it

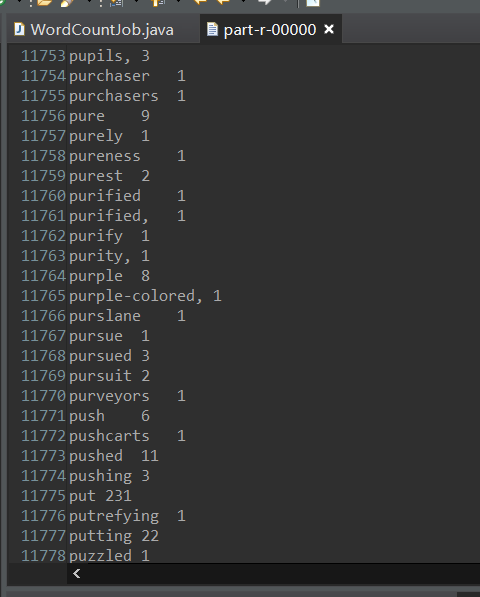
Successful runs are illustrated below
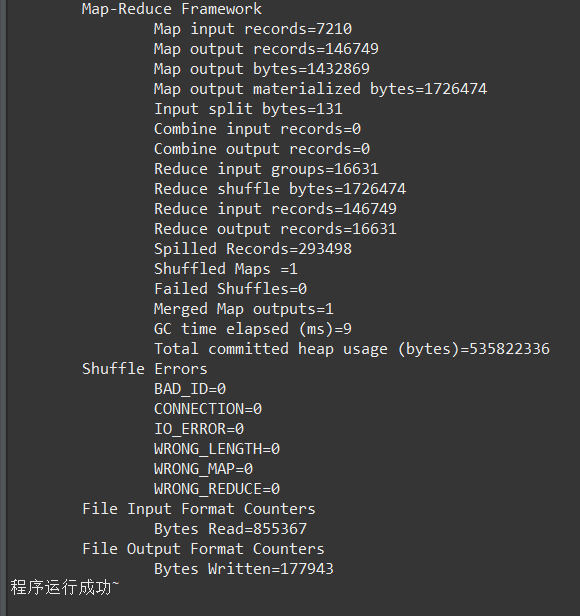
The results are as follows:
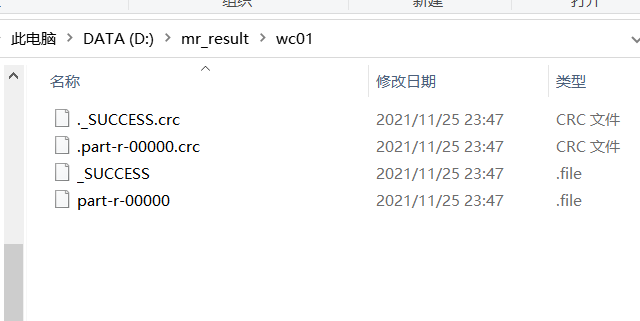
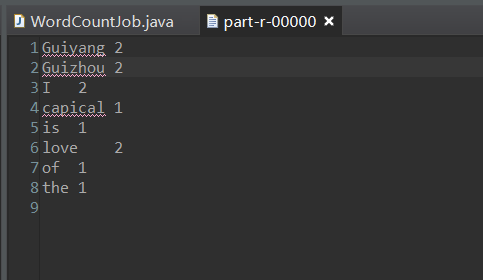
Executing on a Hadoop pseudo-distributed cluster
The service needs to be started first, and the command is:
start-all.sh
Right-click on the DFS Locations path and click Upload files to DFS
Upload the test file One Hundred Years of Solitude.txt to the HDFS file server
Set the cloud input file path in line 16 of the WordCountJob class
FileInputFormat.setInputPaths(job,new Path("hdfs://192.168.80.128:8020/input/One Hundred Years of Solitude.txt "); //Indicates the path to the output file
Right-click in the WordCountJob class and select [Run As] - [2 Run on Hadoop]
Successful runs are illustrated below
The results are as follows: