Introduction to ElasticSearch and its deployment, principle and use
Chapter 1: introduction to elastic search
Elasticsearch is a Lucene based search server. It provides a distributed multi-user full-text search engine based on RESTful web interface. Elasticsearch is developed in Java and released as an open source under the Apache license terms. It is a popular enterprise search engine.
Section 1 usage scenarios of elasticSearch
1. Provide users with full-text search function by keyword query.
2. It is a solution to realize the processing and analysis of enterprise massive data. It is an important part of the big data field, such as the famous ELK framework (ElasticSearch,Logstash,Kibana).
Section 2 Comparison of common database storage
| redis | mysql | elasticsearch | hbase | hadoop/hive | |
|---|---|---|---|---|---|
| Capacity / capacity expansion | low | in | more | Massive | Massive |
| Query timeliness | Extremely high | secondary | higher | secondary | low |
| Query flexibility | Poor k-v mode | Very good, support sql | Better, the association query is weak, but it can be full-text retrieval. DSL language can handle various operations such as filtering, matching, sorting, aggregation and so on | Poor performance, mainly due to rowkey and scan, or the establishment of secondary indexes | Very good, support sql |
| Write speed | Very fast | secondary | Faster | Faster | slow |
| Consistency, transaction | weak | strong | weak | weak | weak |
Section III characteristics of elastic search
1.3. 1 natural fragment, natural cluster
es divides the data into multiple shards, P0-P2 in the figure below. Multiple shards can form a complete data, and these shards can be distributed in each machine node in the cluster. With the continuous increase of data, the cluster can add multiple partitions and put multiple partitions on multiple machines to achieve load balancing and horizontal expansion.
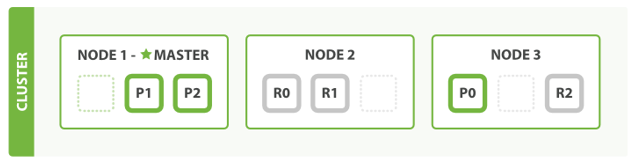
In the actual operation process, each query task is submitted to a node, which must be responsible for sorting and aggregating the data and returning it to the client, that is, Map calculation on a simple node, reduce on a fixed node, and the final result is returned to the client.
This cluster slicing machine makes elasticsearch powerful data capacity and operational scalability.
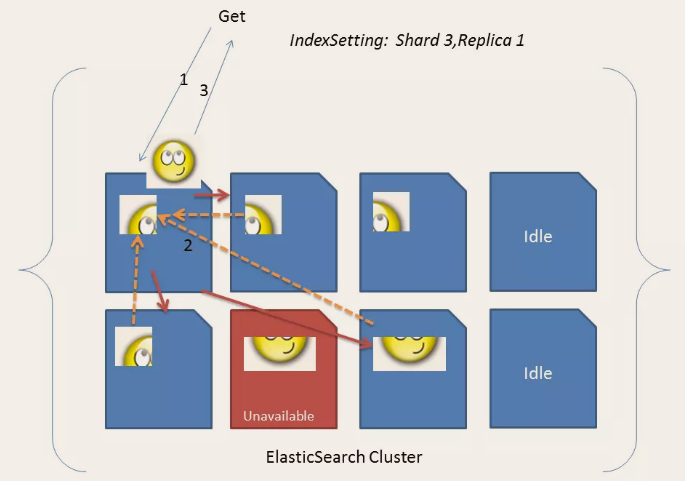
1.3. 2 natural index
All ES data is indexed by default, which is just the opposite of mysql. mysql does not add indexes by default. Special instructions must be given to add indexes. Only ES does not need to add indexes.
The ES uses inverted indexes, which are different from the B+Tree indexes of Mysql.
Section IV relationship between lucene and elastic search
lucene is just a core toolkit providing full-text search function class library, and the real use of it also needs an application built by a perfect service framework.
For example, lucene is similar to an engine, and search engine software (ES,Solr) is a car.
At present, there are two popular search engine software in the market, elastic search and solr. Both of them are built based on lucene and can deploy and start the search engine service software independently. Because the kernel is the same, except for server installation, deployment, management and cluster, the two are very similar in data operation, modification, addition, saving, query, etc. It's like two kinds of database software that support sql language. As long as you learn one, the other is easy to start.
From the actual use of enterprises, the market share of elasticSearch is gradually replacing solr. Domestic Baidu, JD and Sina all realize the search function based on elasticSearch. There are more abroad, such as Wikipedia, GitHub, Stack Overflow and so on, which are also based on ES.
Chapter 2: installation and deployment of elasticSearch (including kibana)
2.1 download address
https://www.elastic.co/cn/downloads/past-releases#elasticsearch
https://www.elastic.co/cn/downloads/past-releases#kibana
[note]:
- The download of es and kibana versions should be consistent
- At present, the production environment mostly adopts large version 6.0 x.x; 7.x. The X version is relatively new, but the deployment process is the same
2.2 machine planning
3 machines:
11.8.37.50 ops01
11.8.36.63 ops02
11.8.36.76 ops03
wangting@ops01:/home/wangting >cat /etc/hosts 127.0.0.1 ydt-cisp-ops01 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 # elasticsearch 11.8.37.50 ops01 11.8.36.63 ops02 11.8.36.76 ops03
[note]: if the node's ip resolution is configured in / etc/hosts of each node, the relevant ip configuration can be replaced by the resolution name in the subsequent configuration file;
For example: network host: 11.8. 37.50 is equivalent to network host: ops01
2.3 download installation package
wangting@ops01:/opt/software >ll | grep 6.6.0 -rw-r--r-- 1 wangting wangting 114106988 Aug 4 14:40 elasticsearch-6.6.0.tar.gz -rw-r--r-- 1 wangting wangting 180704352 Aug 4 14:40 kibana-6.6.0-linux-x86_64.tar.gz
2.4 environmental optimization
2.4. 1 optimization 1
The maximum number of files that the system allows Elasticsearch to open needs to be modified to 65536
wangting@ops01:/opt/software >sudo vim /etc/security/limits.conf # End of file * soft nofile 65536 * hard nofile 131072 * soft nproc 2048 * hard nproc 65536 # Disconnect reconnection session wangting@ops01:/home/wangting >ulimit -n 65536
If this configuration is not optimized, starting the service will appear:
[error] max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536] elasticsearch
2.4. 2 optimization 2
The maximum number of processes allowed is modified to 4096; If it is not 4096, the optimization needs to be modified
wangting@ops01:/home/wangting >sudo vim /etc/security/limits.d/20-nproc.conf # Default limit for number of user's processes to prevent # accidental fork bombs. # See rhbz #432903 for reasoning. * soft nproc 4096 root soft nproc unlimited
If this configuration is not optimized, starting the service will appear:
[error]max number of threads [1024] for user [judy2] likely too low, increase to at least [4096]
2.4. 3 optimization 3
Set the number of virtual memory areas that a process can have
wangting@ops01:/home/wangting >sudo vim /etc/sysctl.conf vm.max_map_count=262144 # Overload configuration wangting@ops01:/home/wangting >sudo sysctl -p
If this configuration is not optimized, starting the service will appear:
[error]max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
2.5 decompression and installation
wangting@ops01:/opt/software >tar -xf elasticsearch-6.6.0.tar.gz -C /opt/module/ wangting@ops01:/opt/software >cd /opt/module/elasticsearch-6.6.0/ wangting@ops01:/opt/module/elasticsearch-6.6.0 >ll total 448 drwxr-xr-x 3 wangting wangting 4096 Aug 4 15:13 bin drwxr-xr-x 2 wangting wangting 4096 Jan 24 2019 config drwxr-xr-x 3 wangting wangting 4096 Jan 24 2019 lib -rw-r--r-- 1 wangting wangting 13675 Jan 24 2019 LICENSE.txt drwxr-xr-x 2 wangting wangting 4096 Jan 24 2019 logs drwxr-xr-x 29 wangting wangting 4096 Jan 24 2019 modules -rw-r--r-- 1 wangting wangting 403816 Jan 24 2019 NOTICE.txt drwxr-xr-x 2 wangting wangting 4096 Jan 24 2019 plugins -rw-r--r-- 1 wangting wangting 8519 Jan 24 2019 README.textile
2.6 modifying configuration files
wangting@ops01:/opt/module/elasticsearch-6.6.0 >cd config/ wangting@ops01:/opt/module/elasticsearch-6.6.0/config >cat elasticsearch.yml | grep -vE "^#|^$" cluster.name: my-es node.name: node-ops01 bootstrap.memory_lock: false network.host: 11.8.37.50 http.port: 9200 discovery.zen.ping.unicast.hosts: ["11.8.37.50", "11.8.36.63", "11.8.36.76"]
Configuration Item Description:
cluster. Name: my es # cluster name; All nodes in the same cluster must have the same name
node.name: node-ops01 # current node name; It can be understood that each cluster is distinguished by this name
bootstrap.memory_lock: false # bootstrap self-test program
network.host: 11.8.37.50 # current node host
http.port: 9200 # es boot port
discovery.zen.ping.unicast.hosts: ["11.8.37.50", "11.8.36.63", "11.8.36.76"] # self discovery configuration: the host name of the new node reporting to the cluster
[note]: These are conventional configurations. Others, such as data storage path and log storage path, can be customized and configured according to the situation
2.7 distribution and installation directory
wangting@ops01:/opt/module >scp -r elasticsearch-6.6.0 ops02:/opt/module/ wangting@ops01:/opt/module >scp -r elasticsearch-6.6.0 ops03:/opt/module/
2.8 modifying other node configuration files
# Node ops02 wangting@ops02:/opt/module/elasticsearch-6.6.0/config >cat elasticsearch.yml | grep -vE "^#|^$" cluster.name: my-es node.name: node-ops02 bootstrap.memory_lock: false network.host: 11.8.36.63 http.port: 9200 discovery.zen.ping.unicast.hosts: ["11.8.37.50", "11.8.36.63", "11.8.36.76"] # Node ops03 wangting@ops03:/opt/module/elasticsearch-6.6.0/config >cat elasticsearch.yml | grep -vE "^#|^$" cluster.name: my-es node.name: node-ops03 bootstrap.memory_lock: false network.host: 11.8.36.76 http.port: 9200 discovery.zen.ping.unicast.hosts: ["11.8.37.50", "11.8.36.63", "11.8.36.76"]
2.9 service startup
# Start three nodes es in sequence with the same command wangting@ops01:/opt/module >cd /opt/module/elasticsearch-6.6.0/bin/ wangting@ops01:/opt/module/elasticsearch-6.6.0/bin >./elasticsearch -d wangting@ops01:/opt/module/elasticsearch-6.6.0/bin >
[note]:
- -d is running in the background. You can only run in the foreground without - d. if the session window is closed, the service will be terminated at the same time
- elasticsearch needs to be started for all three machines
- There is no configuration definition for the operation log, which is in the service directory by default: elasticsearch-6.6 0 / logs /, if there is an exception, you can check the log first
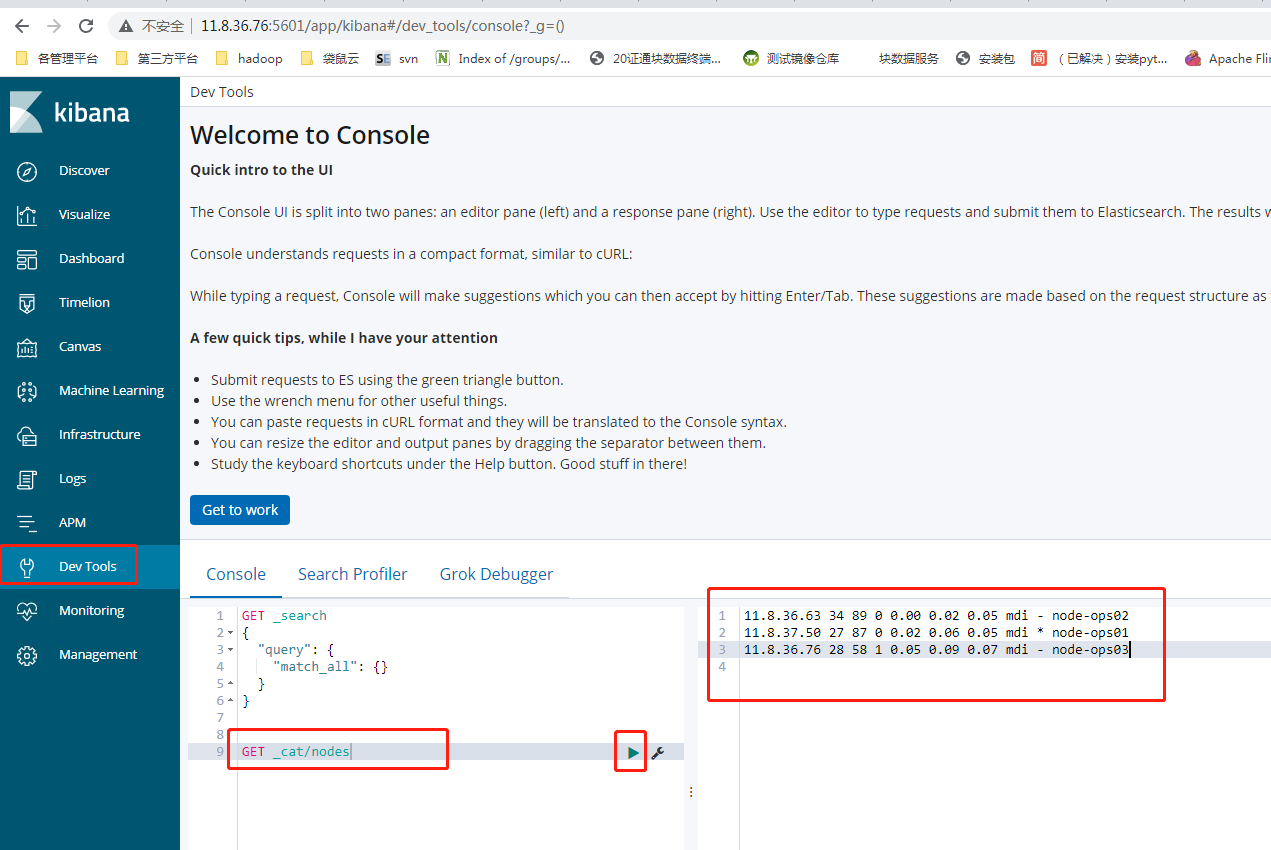
2.10 command validation es
wangting@ops01:/opt/module/elasticsearch-6.6.0/logs >curl http://11.8.37.50:9200/_cat/nodes?v ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name 11.8.36.63 26 88 0 0.05 0.13 0.10 mdi - node-ops02 11.8.37.50 28 87 0 0.06 0.10 0.08 mdi * node-ops01 11.8.36.76 26 53 0 0.06 0.07 0.06 mdi - node-ops03
[note]: for the es cluster in normal operation, the nodes status of all nodes in curl can return results
2.11 installation of kibana
# Installing kibana kibana is just a tool. Pick a server to install it wangting@ops01:/opt/software >scp kibana-6.6.0-linux-x86_64.tar.gz ops03:/opt/software/ wangting@ops03:/opt/module/elasticsearch-6.6.0/bin >cd /opt/software/ wangting@ops03:/opt/software >tar -xf kibana-6.6.0-linux-x86_64.tar.gz -C /opt/module/ wangting@ops03:/opt/software >cd /opt/module/kibana-6.6.0-linux-x86_64/config/ wangting@ops03:/opt/module/kibana-6.6.0-linux-x86_64/config >cat kibana.yml | grep -vE "^$|^#" server.host: "0.0.0.0" elasticsearch.hosts: ["http://11.8.37.50:9200"] wangting@ops03:/opt/module/kibana-6.6.0-linux-x86_64/config >cd .. wangting@ops03:/opt/module/kibana-6.6.0-linux-x86_64 >nohup bin/kibana &
2.12 interface verification kibana
In which node is deployed, the corresponding address + 5601 port is used for access
http://11.8.36.76:5601/
Chapter three: the basic concept of elastic search
Section I: keyword interpretation
| key word | interpretation |
|---|---|
| cluster | The whole elasticsearch defaults to the cluster status, and the whole cluster is a complete and mutually standby data. |
| node | Generally, only one process is a node in a cluster |
| shard | Fragmentation: even the data in a node will be stored in multiple slices through the hash algorithm. The default is 5 slices. (7.0 is changed to 1 by default) |
| index | database(5.x), which is equivalent to rdbms, is a logical database for users. Although it is physically stored in multiple shard s, it may also be stored in multiple node s. 6.x 7.x index is equivalent to table |
| type | Table is similar to rdbms, but it is more like class in object-oriented and data collection in the same Json format than table. (only one 6.x is allowed, and 7.0 is abandoned, resulting in the fact that the index is equivalent to the table level) |
| document | Similar to row in rdbms and object in object-oriented |
| field | Equivalent to fields and attributes |
Section 2: simple examples of syntax:
GET /_cat/nodes?v # query the status of each node
GET /_cat/indices?v # query the status of each index
GET /_cat/shards/xxxx # query the fragmentation of an index
Section 3: elasticsearch 9200 9300 port differences
When the es is started normally, there will be 9200 and 9300 ports
1. 9200, as an HTTP protocol, is mainly used for external communication; It is the RESTful interface of HTTP protocol
2. 9300 as TCP protocol, jar s communicate with each other through TCP protocol; Both the clusters and the TCPClient can use it
Chapter 4: elasticsearch restful api [DSL]
DSL: full name: Domain Specific language, i.e. Domain Specific language
Section 1 data structure saved in es
Generally, in java code, if two objects are stored in a relational database, such as mysql, they will be split into two tables. Movie corresponds to one MySQL table and Actor corresponds to another MySQL table;
package com.wangting.elasticsearch.test;
import java.util.List;
public interface Test {
public static void main(String[] args) {
public class Movie<Actor> {
String id;
String name;
Double doubanScore;
List<Actor> actorList;
}
public class Actor{
String id;
String name;
}
}
}
But elastic search uses a json to represent a document.
{
"id": "1",
"name": "operation red sea",
"doubanScore": "8.5",
"actorList": [
{
"id": "1",
"name": "zhangyi"
},
{
"id": "2",
"name": "haiqing"
},
{
"id": "3",
"name": "zhanghanyu"
}
]
}
For ease of understanding, it is simple to make a comparison with MySQL. The keywords are only similar, not exactly a concept, and the functions are almost the same
| MySQL | elasticsearch |
|---|---|
| databases | index |
| table | type |
| row | document |
| column | field |
Section 2 common data operations
4.2. 1 check which indexes are in es
It is similar to show tables in MySQL;
GET /_cat/indices?v
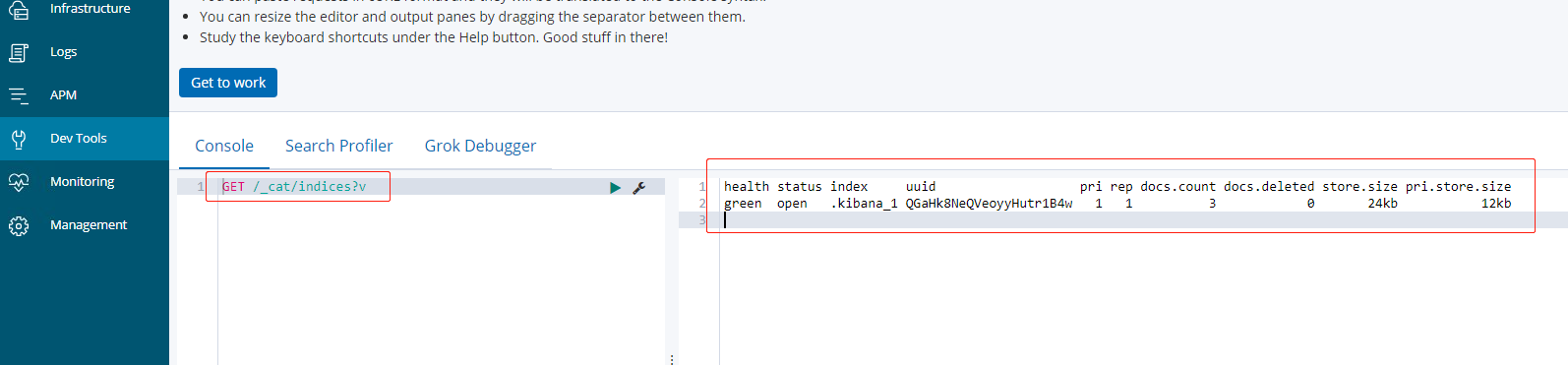
[note]:
- By default, there will be a file named kibana's index
- GET /_cat/indices?v is equivalent to curl on the command line http://11.8.37.50:9200/_cat/indices?v
- final? v can not be added, but it is not recommended, because the result has no header, and the query result is relatively messy and not easy to view
Query the definition of each keyword in the index header
| key word | interpretation |
|---|---|
| health | Green (cluster integrity) yellow (single point normal, cluster incomplete) red (single point abnormal) |
| status | Can it be used |
| index | Index name |
| uuid | Index unified number |
| pri | Several primary nodes |
| rep | Several slave nodes |
| docs.count | Number of documents |
| docs.deleted | How many documents have been deleted |
| store.size | Overall space occupied |
| pri.store.size | Space occupied by primary node |
4.2. 2 add index
It is similar to the create table in MySQL;
PUT /indexname

[note]:
#! Deprecation: the default number of shards will change from [5] to [1] in 7.0.0; if you wish to continue using the default of [5] shards, you must manage this on the create index request or with an index template
Tips in large version 7.0 After 0, the default number of partitions will be changed from 5 to 1. If you want to use the default 5 in the future, you must create an index request with an index template
Query index information again:

4.2. 3 delete index
It is similar to the drop table in MySQL;
DELETE /indexname
4.2. 4 new documents
Compare insert into similar to a table in MySQL;
Syntax: format PUT /index/type/id
If the movie in the above example_ The index index is deleted and rebuilt: PUT /movie_index
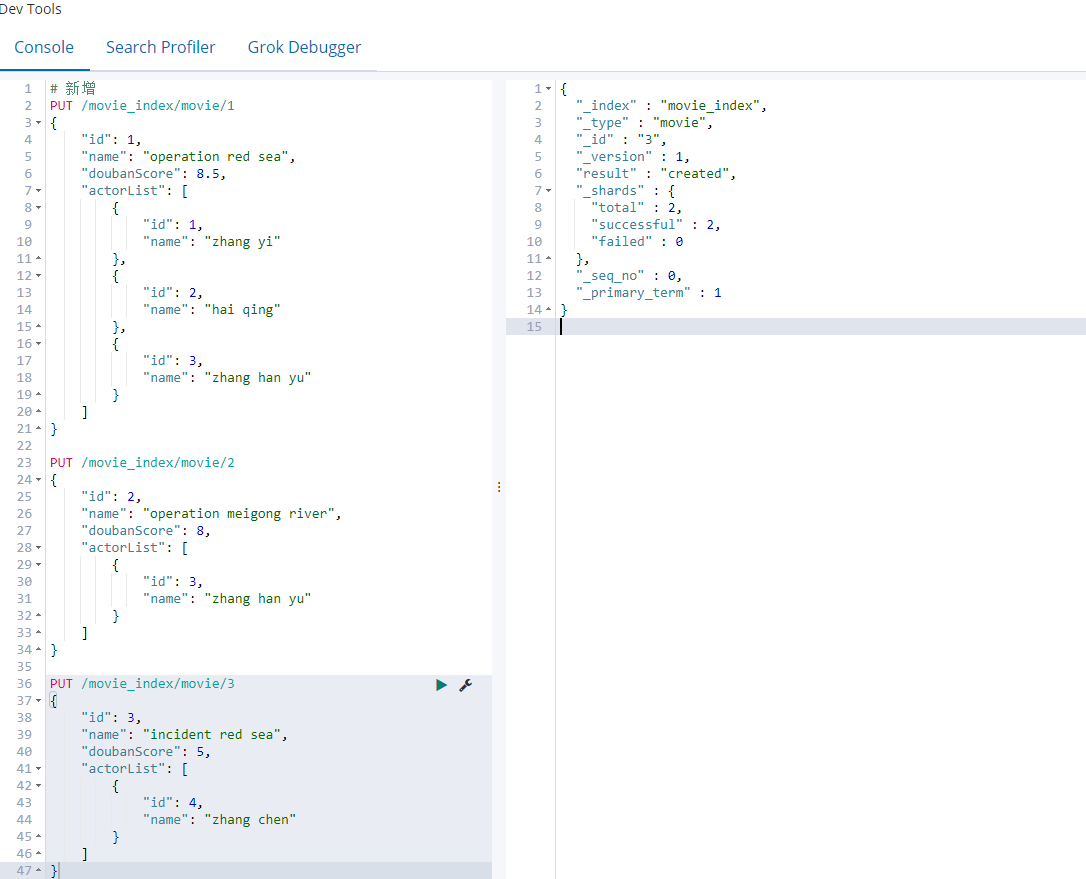
newly added:
PUT /movie_index/movie/1
{
"id": 1,
"name": "operation red sea",
"doubanScore": 8.5,
"actorList": [
{
"id": 1,
"name": "zhang yi"
},
{
"id": 2,
"name": "hai qing"
},
{
"id": 3,
"name": "zhang han yu"
}
]
}
PUT /movie_index/movie/2
{
"id": 2,
"name": "operation meigong river",
"doubanScore": 8,
"actorList": [
{
"id": 3,
"name": "zhang han yu"
}
]
}
PUT /movie_index/movie/3
{
"id": 3,
"name": "incident red sea",
"doubanScore": 5,
"actorList": [
{
"id": 4,
"name": "zhang chen"
}
]
}
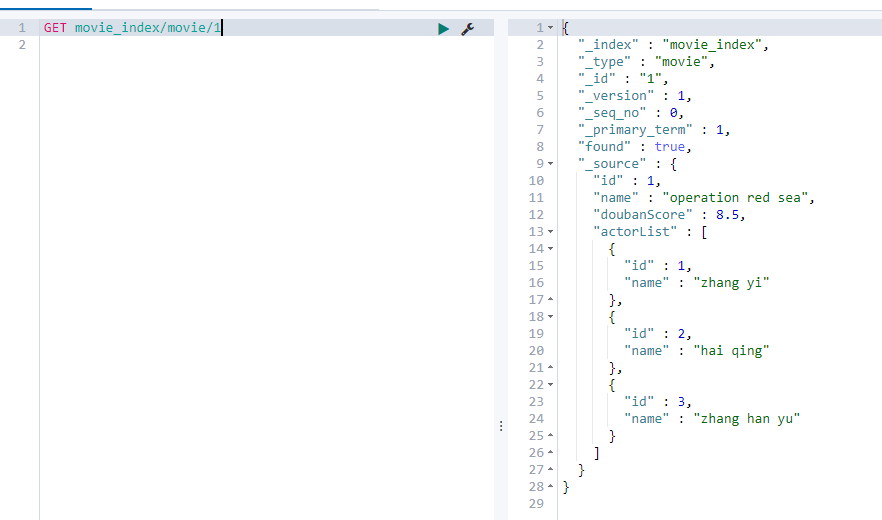
4.2. 5 directly use id to find data
Compare the select where condition similar to a table in MySQL;
GET movie_index/movie/1
4.2. 6. Modify - (modify overall replacement data)
Compare the alter table similar to a table in MySQL;
[note]: there is no difference between adding and adding. Requirements: all fields must be included
PUT /movie_index/movie/3
{
"id": "3",
"name": "incident red sea",
"doubanScore": "5.0",
"actorList": [
{
"id": "1",
"name": "zhang chen"
}
]
}
4.2. 7 modify - (modify a field)
Modify the value content of a field
Compare the alter table similar to a table in MySQL;
POST movie_index/movie/3/_update
{
"doc": {
"doubanScore":"7.0"
}
}
Close index for a field
"name":{
"type": "keyword",
"index": false
}
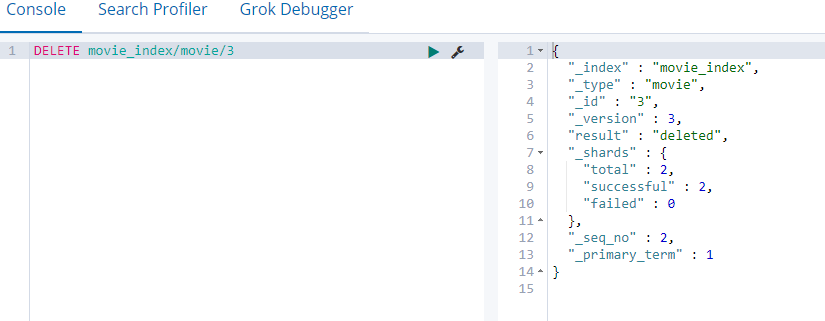
4.2. 8 delete a document
Compare delete from < table name > [where clause] similar to a table in MySQL
DELETE movie_index/movie/3
4.2. 9 search all data
It is similar to select * from a table in MySQL;
GET movie_index/movie/_search
4.2. 10 query by criteria (all)
GET movie_index/movie/_search
{
"query":{
"match_all": {}
}
}
[note]: when you query by criteria, if the criteria are empty, the effect is equivalent to getting movie_index / movie / _searchfor all data in the query type
4.2. 11 query by word segmentation
Compare a table similar to MySQL. Select * from like% XXX%; But just like the principle is different
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red"}
}
}
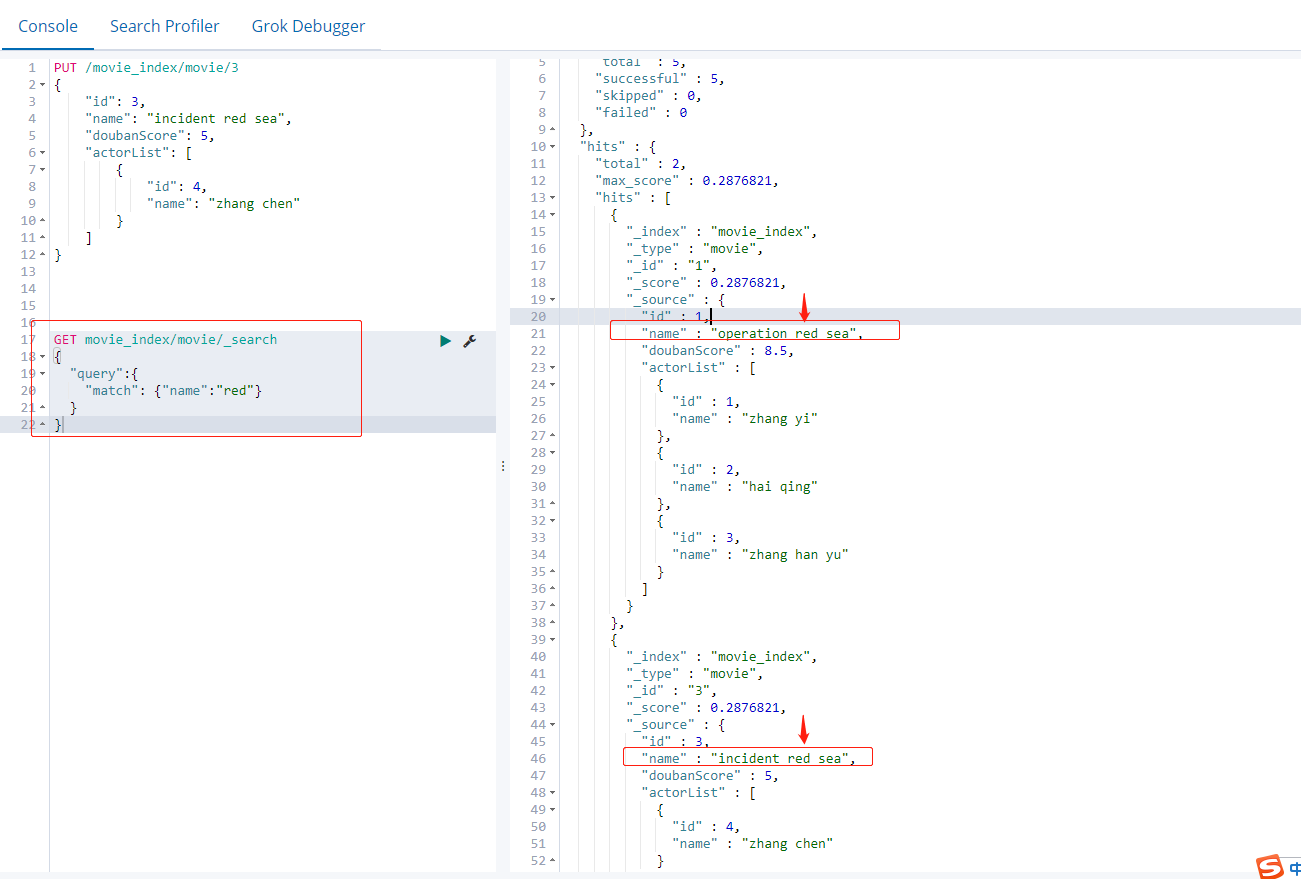
4.2. 12 query by word segmentation sub attribute
GET movie_index/movie/_search
{
"query":{
"match": {"actorList.name":"zhang"}
}
}
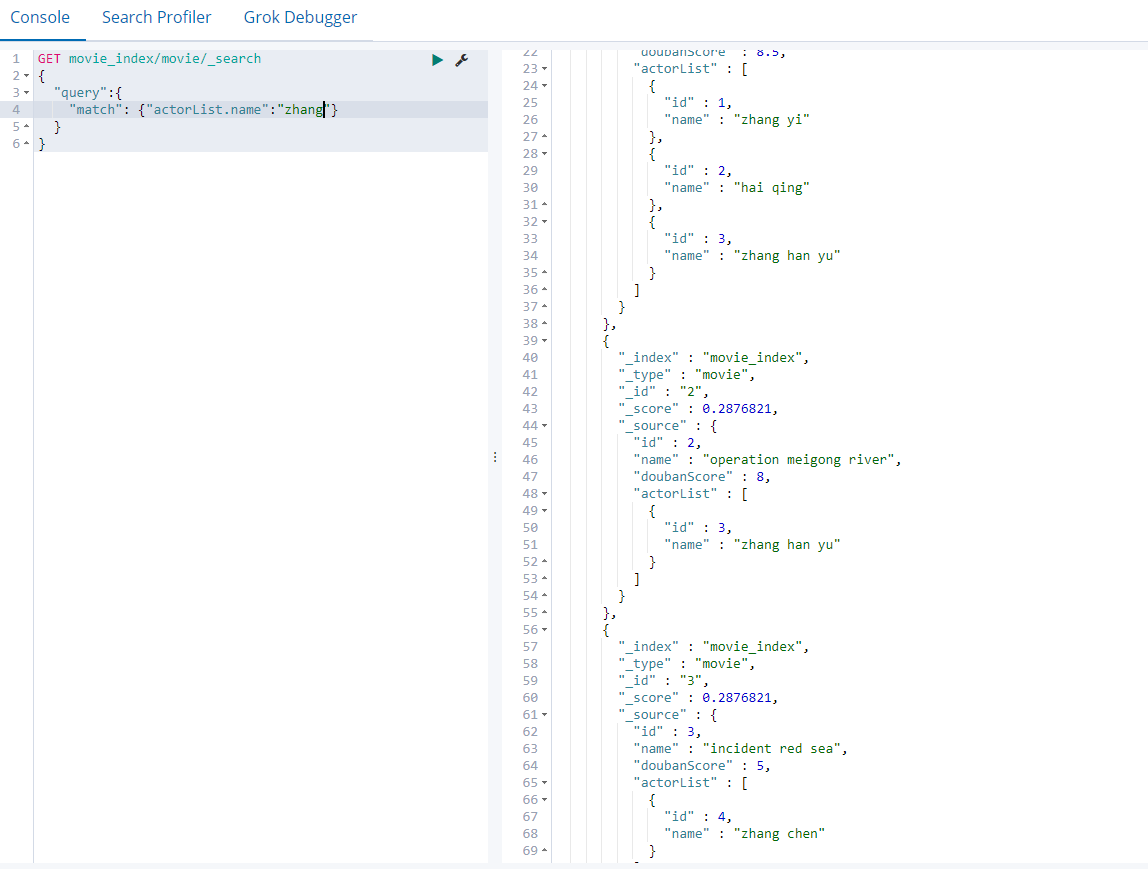
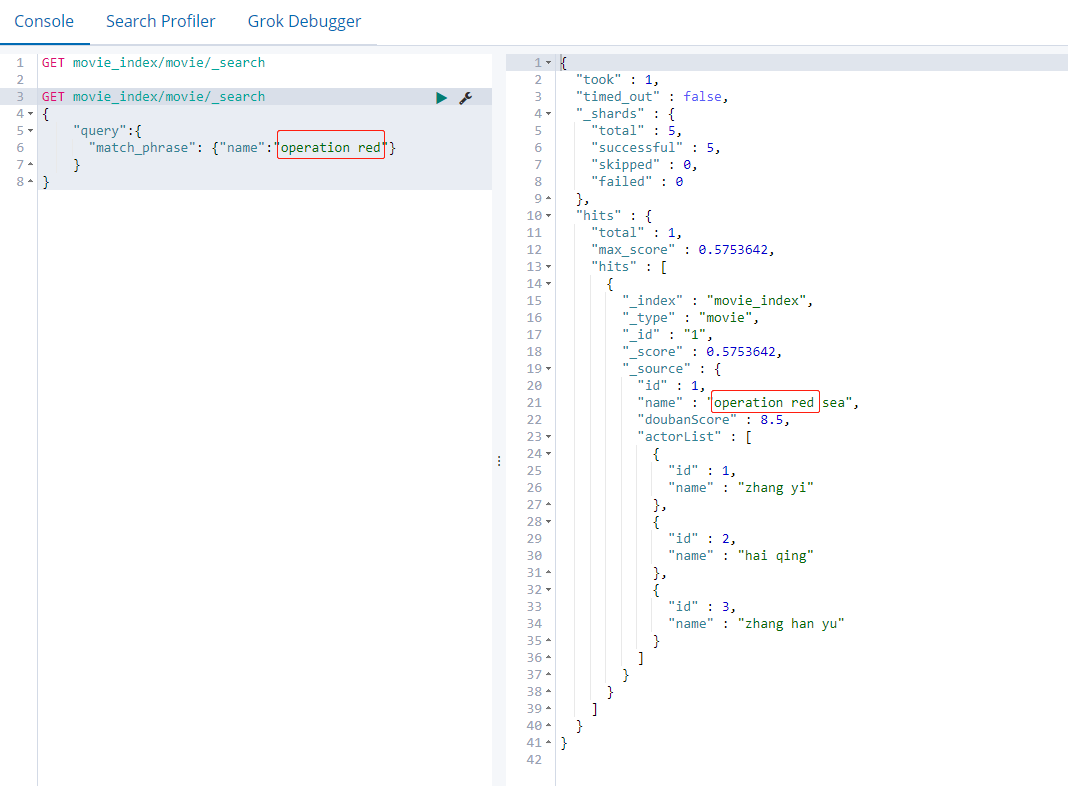
4.2. 13 "match phrase"
Query by phrase, instead of using word segmentation technology, directly use phrases to match in the original data
GET movie_index/movie/_search
{
"query":{
"match_phrase": {"name":"operation red"}
}
}
It is equivalent to querying the operation red as a whole. The red will not be queried after the operation is checked, and it will not be split to match one by one; The words operation and red in name alone do not meet the conditions
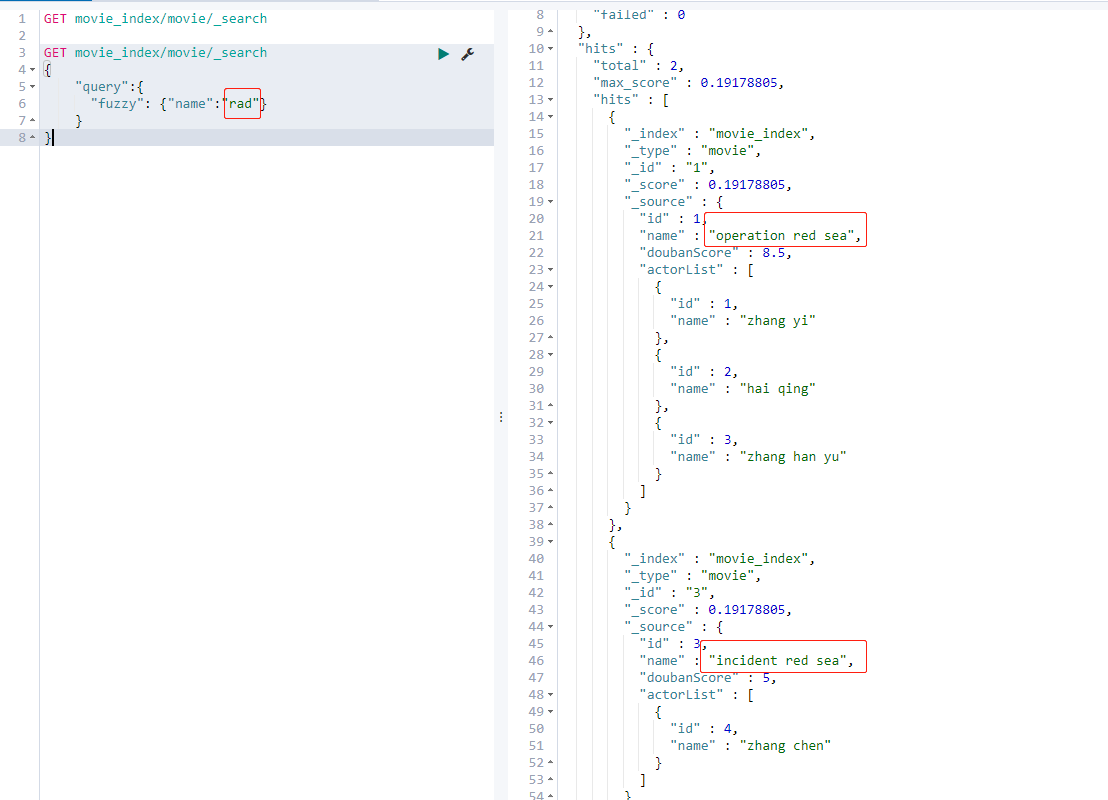
4.2.14 fuzzy query [correction matching]
fuzzy corrects the matching segmentation. When a word cannot be accurately matched, es gives a certain score to the very close words through an algorithm, which can be queried, but consumes more performance.
GET movie_index/movie/_search
{
"query":{
"fuzzy": {"name":"rad"}
}
}
This mechanism is equivalent to that when you search Baidu content at ordinary times, the input content may be wrong. The home page search content will prompt: do you want to search xxx, and then return the content of xxx
4.2. 15 filter - filter after query (query before filter)
post_ The filter filters the data that meets the conditions, and rejects the data that does not meet the conditions; Not in line with post_filter is removed.
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red"}
},
"post_filter":{
"term": {
"actorList.id": 3
}
}
}
First, query whether the name has red
id=1 -> "name": "operation red sea",
id=3 -> "name": "incident red sea",
The result with id 3 is returned after filtering
4.2. 16 filter - filter before query (filter before query)
Under the same requirements, filtering before querying is better than querying before filtering
GET movie_index/movie/_search
{
"query":{
"bool":{
"filter":[ {"term": { "actorList.id": "1" }},
{"term": { "actorList.id": "3" }}
],
"must":{"match":{"name":"red"}}
}
}
}
4.2. 17 filter – filter by range
"name": "operation red sea",
"doubanScore": 8.5,
"name": "operation meigong river",
"doubanScore": 8,
"name": "incident red sea",
"doubanScore": 5,
Find out the results of film score of 8 or above
GET movie_index/movie/_search
{
"query": {
"bool": {
"filter": {
"range": {
"doubanScore": {"gte": 8}
}
}
}
}
}
The result returns data with IDS 1 and 2
| key word | function |
|---|---|
| gt | greater than |
| lt | less than |
| gte | Greater than or equal |
| lte | Less than or equal |
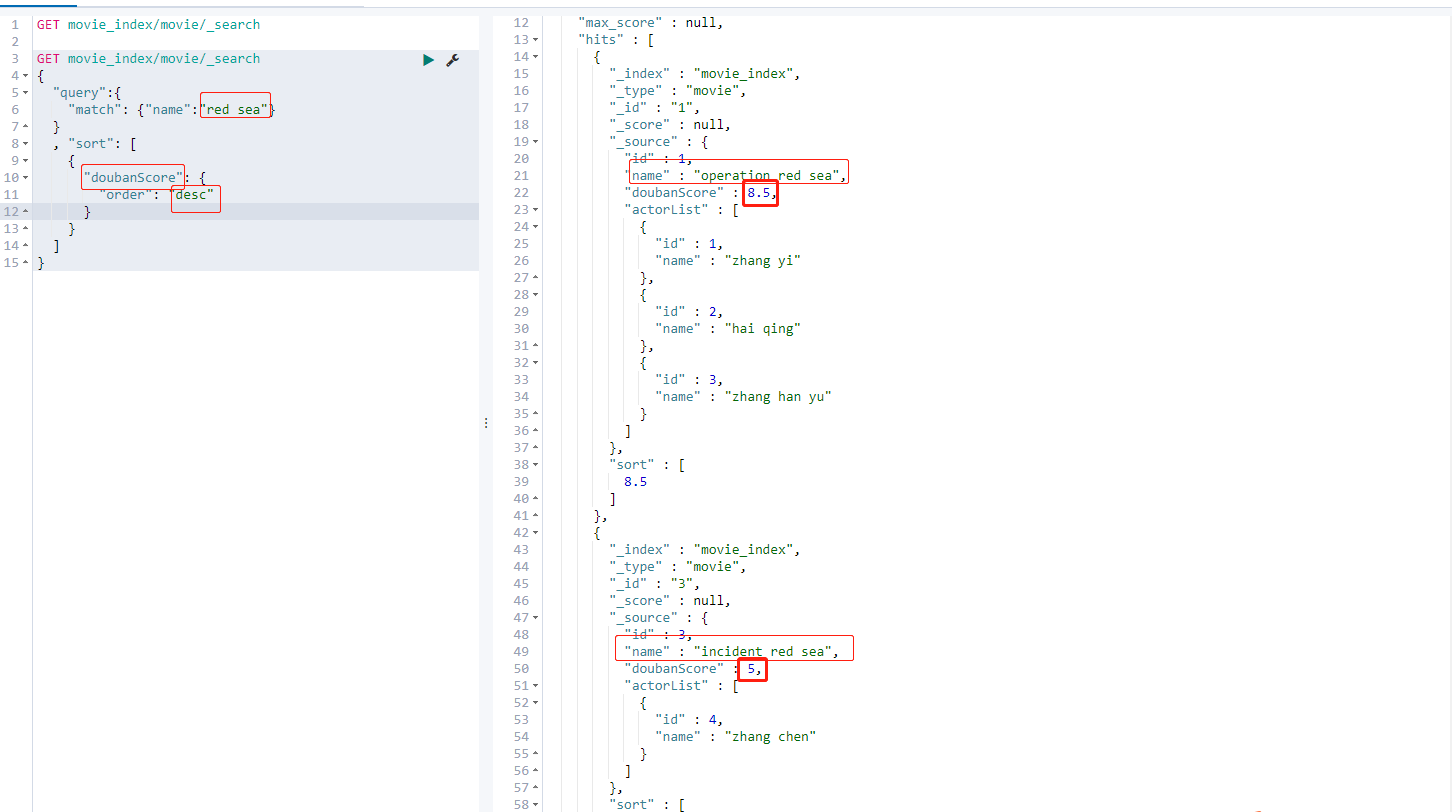
4.2. 18 sorting
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red sea"}
}
, "sort": [
{
"doubanScore": {
"order": "desc"
}
}
]
}
First find out the data whose name contains the red sea keyword, and then sort according to the query data results; asc from small to large desc from large to small
4.2. 19 paging query
GET movie_index/movie/_search
{
"query": { "match_all": {} },
"from": 1,
"size": 1
}
from defines the offset value of the target data
size defines the number of events currently returned.
If you do not customize the value, the default from is 0 and the size is 10, that is, all queries return only the first 10 data by default.
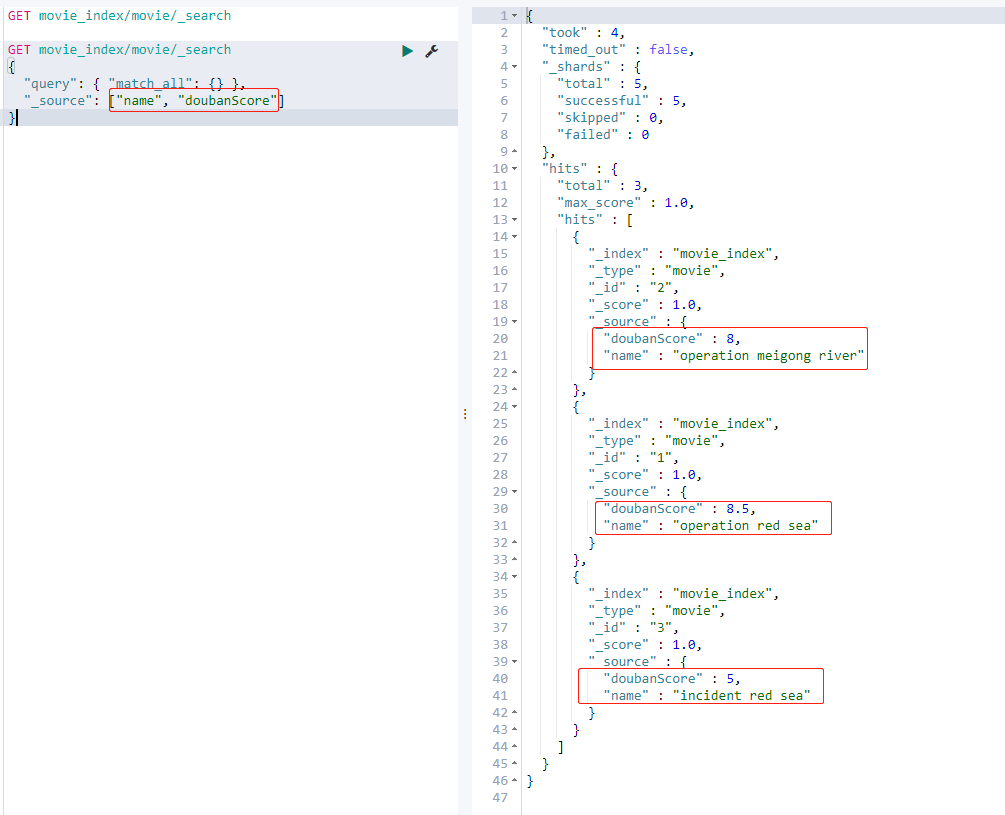
4.2. 20 specify the fields to query
GET movie_index/movie/_search
{
"query": { "match_all": {} },
"_source": ["name", "doubanScore"]
}
4.2. 21 highlight
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red sea"}
},
"highlight": {
"fields": {"name":{} }
}
}
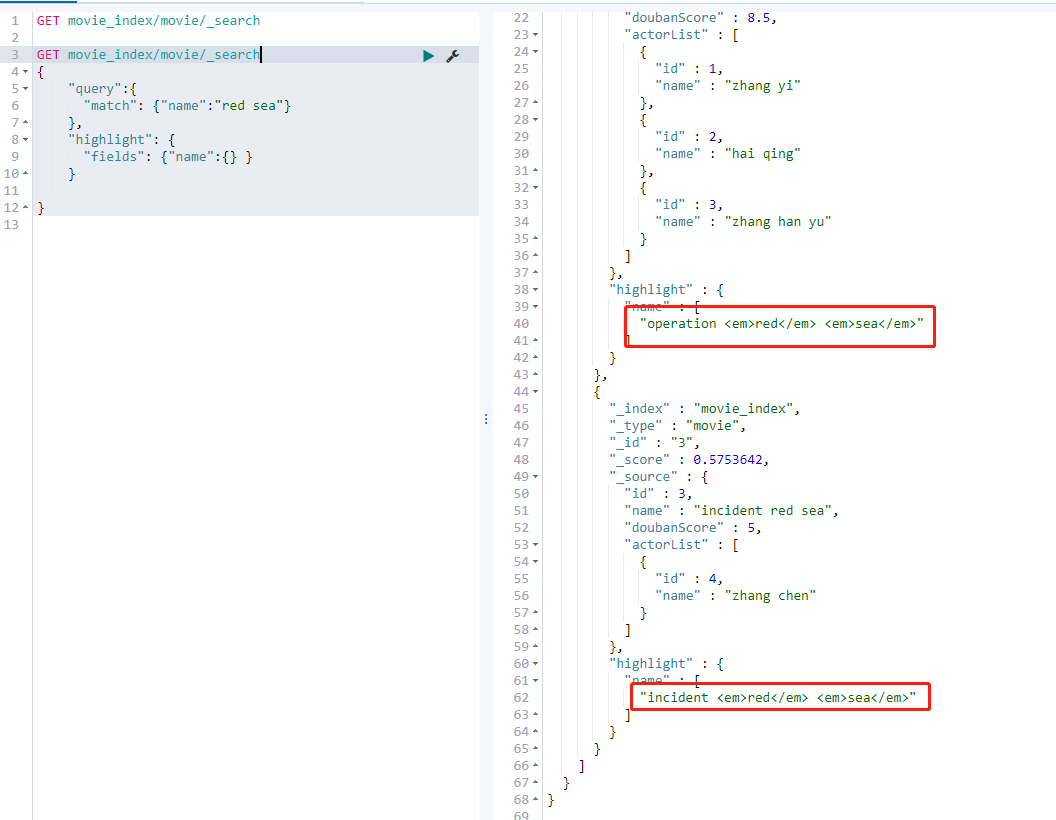
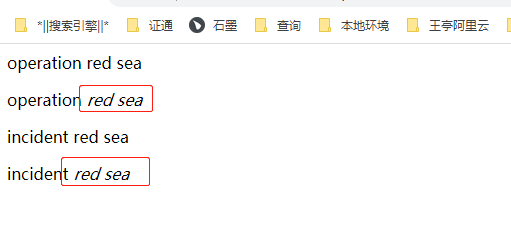
Here you can see that the result is wrapped with a layer of em label, that is, highlight and skew
You can create an html suffix file, enter the following code, save the html file, open it with a browser, and then observe and compare it
<p>operation red sea</p> <p>operation <em>red</em> <em>sea</em> </p> <p>incident red sea </p> <p>incident <em>red</em> <em>sea</em> </p>
4.2. 22 aggregate query
Example to illustrate 1: take out how many movies each actor has participated in
GET movie_index/movie/_search
{
"aggs": {
"groupby_actor": {
"terms": {
"field": "actorList.name.keyword"
}
}
}
}
# Query results:
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 1.0,
"hits" : [
{
"_index" : "movie_index",
"_type" : "movie",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"id" : 2,
"name" : "operation meigong river",
"doubanScore" : 8,
"actorList" : [
{
"id" : 3,
"name" : "zhang han yu"
}
]
}
},
{
"_index" : "movie_index",
"_type" : "movie",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"id" : 1,
"name" : "operation red sea",
"doubanScore" : 8.5,
"actorList" : [
{
"id" : 1,
"name" : "zhang yi"
},
{
"id" : 2,
"name" : "hai qing"
},
{
"id" : 3,
"name" : "zhang han yu"
}
]
}
},
{
"_index" : "movie_index",
"_type" : "movie",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"id" : 3,
"name" : "incident red sea",
"doubanScore" : 5,
"actorList" : [
{
"id" : 4,
"name" : "zhang chen"
}
]
}
}
]
},
"aggregations" : {
"groupby_actor" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "zhang han yu",
"doc_count" : 2
},
{
"key" : "hai qing",
"doc_count" : 1
},
{
"key" : "zhang chen",
"doc_count" : 1
},
{
"key" : "zhang yi",
"doc_count" : 1
}
]
}
}
}
Example 2: what is the average score of each actor in the film and sort it according to the score
GET movie_index/movie/_search
{
"aggs": {
"groupby_actor_id": {
"terms": {
"field": "actorList.name.keyword" ,
"order": {
"avg_score": "desc"
}
},
"aggs": {
"avg_score":{
"avg": {
"field": "doubanScore"
}
}
}
}
}
}
# Query results:
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 1.0,
"hits" : [
{
"_index" : "movie_index",
"_type" : "movie",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"id" : 2,
"name" : "operation meigong river",
"doubanScore" : 8,
"actorList" : [
{
"id" : 3,
"name" : "zhang han yu"
}
]
}
},
{
"_index" : "movie_index",
"_type" : "movie",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"id" : 1,
"name" : "operation red sea",
"doubanScore" : 8.5,
"actorList" : [
{
"id" : 1,
"name" : "zhang yi"
},
{
"id" : 2,
"name" : "hai qing"
},
{
"id" : 3,
"name" : "zhang han yu"
}
]
}
},
{
"_index" : "movie_index",
"_type" : "movie",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"id" : 3,
"name" : "incident red sea",
"doubanScore" : 5,
"actorList" : [
{
"id" : 4,
"name" : "zhang chen"
}
]
}
}
]
},
"aggregations" : {
"groupby_actor_id" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "hai qing",
"doc_count" : 1,
"avg_score" : {
"value" : 8.5
}
},
{
"key" : "zhang yi",
"doc_count" : 1,
"avg_score" : {
"value" : 8.5
}
},
{
"key" : "zhang han yu",
"doc_count" : 2,
"avg_score" : {
"value" : 8.25
}
},
{
"key" : "zhang chen",
"doc_count" : 1,
"avg_score" : {
"value" : 5.0
}
}
]
}
}
}
Keyword is a string field that specifically stores the copy of the non participle format. In some scenarios, only the non participle format is allowed, such as filter, aggregation aggs, so the field should be added Suffix of keyword
keyword function:
- Direct indexing without word segmentation
- Support fuzzy and accurate query
- Support aggregation
Section 3 Chinese word segmentation
The Chinese word segmentation provided by elastic search itself simply separates Chinese word by word, and there is no concept of vocabulary at all. However, in practical application, users query and match based on vocabulary. If articles can be cut and separated by vocabulary, they can match more appropriately with the user's query conditions, and the query speed is faster.
GET _analyze
{
"text": ["wang ting niubi","Awesome today"]
}
# The results are as follows:
{
"tokens" : [
{
"token" : "wang",
"start_offset" : 0,
"end_offset" : 4,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "ting",
"start_offset" : 5,
"end_offset" : 9,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "niubi",
"start_offset" : 10,
"end_offset" : 15,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "this",
"start_offset" : 16,
"end_offset" : 17,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "day",
"start_offset" : 17,
"end_offset" : 18,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "to",
"start_offset" : 18,
"end_offset" : 19,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "power",
"start_offset" : 19,
"end_offset" : 20,
"type" : "<IDEOGRAPHIC>",
"position" : 6
}
]
}
Through examples, it can be seen clearly that "wang ting niubi" is "awesome today". English participle is relatively reasonable according to the space word segmentation, but Chinese word segmentation is obviously not appropriate (today, awesome two words are not recognized).
Word splitter download website: https://github.com/medcl/elasticsearch-analysis-ik
[note]: it is recommended to find the best ik version consistent with the es version; find the zip package to download
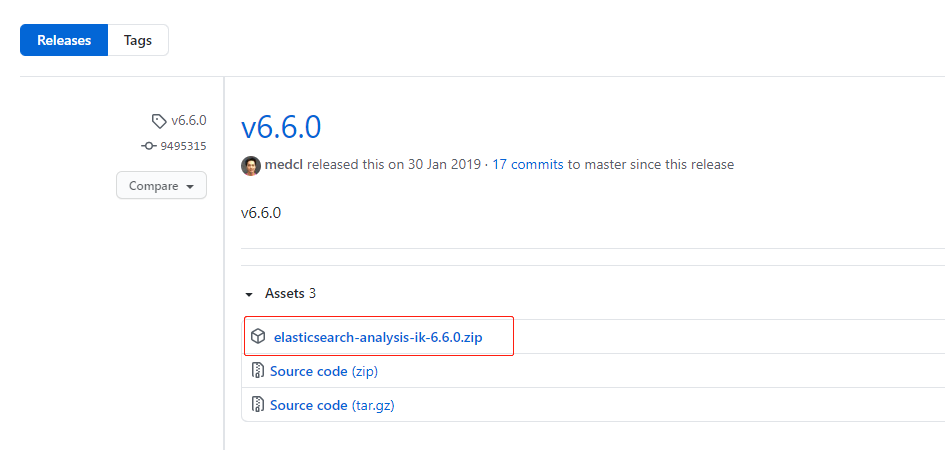
install
# Enter the plugins directory of es wangting@ops01:/home/wangting >cd /opt/module/elasticsearch-6.6.0/plugins/ # Create a plug-in directory (a plug-in corresponds to a subdirectory under plugins) wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins >mkdir ik # Download the ik plug-in zip package wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik >ls elasticsearch-analysis-ik-6.6.0.zip # Unzip the installation package and clean up the zip file wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik >unzip elasticsearch-analysis-ik-6.6.0.zip && rm elasticsearch-analysis-ik-6.6.0.zip # directory structure wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik >ll total 1432 -rw-r--r-- 1 wangting wangting 263965 May 6 2018 commons-codec-1.9.jar -rw-r--r-- 1 wangting wangting 61829 May 6 2018 commons-logging-1.2.jar drwxr-xr-x 2 wangting wangting 4096 Aug 26 2018 config -rw-r--r-- 1 wangting wangting 54693 Jan 30 2019 elasticsearch-analysis-ik-6.6.0.jar -rw-r--r-- 1 wangting wangting 736658 May 6 2018 httpclient-4.5.2.jar -rw-r--r-- 1 wangting wangting 326724 May 6 2018 httpcore-4.4.4.jar -rw-r--r-- 1 wangting wangting 1805 Jan 30 2019 plugin-descriptor.properties -rw-r--r-- 1 wangting wangting 125 Jan 30 2019 plugin-security.policy # Distribute plug-ins to other nodes wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik >cd .. wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins >scp -r ik ops02:/opt/module/elasticsearch-6.6.0/plugins/ wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins >scp -r ik ops03:/opt/module/elasticsearch-6.6.0/plugins/
[note]: the plug-in installation takes effect only after restarting es, otherwise the corresponding function cannot be used, as shown in the figure below
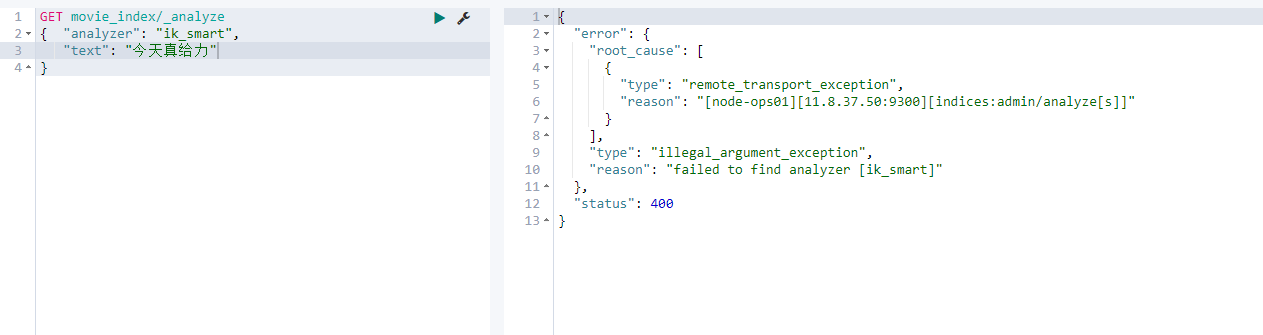
Restart es:
# Node ops01; Find es the corresponding process number
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins >jps | grep Elasticsearch|awk -F" " '{print $1}'
95973
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins >kill -9 95973
# Node ops02; Find es the corresponding process number
wangting@ops02:/opt/module/elasticsearch-6.6.0/plugins >jps | grep Elasticsearch|awk -F" " '{print $1}'
109175
wangting@ops02:/opt/module/elasticsearch-6.6.0/plugins >kill -9 109175
# Node ops03; Find es the corresponding process number
wangting@ops03:/opt/module/elasticsearch-6.6.0/plugins >jps | grep Elasticsearch|awk -F" " '{print $1}'
41777
wangting@ops03:/opt/module/elasticsearch-6.6.0/plugins >kill -9 41777
# Each node starts es again with the following command
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins >cd /opt/module/elasticsearch-6.6.0/bin/
wangting@ops01:/opt/module/elasticsearch-6.6.0/bin >./elasticsearch -d
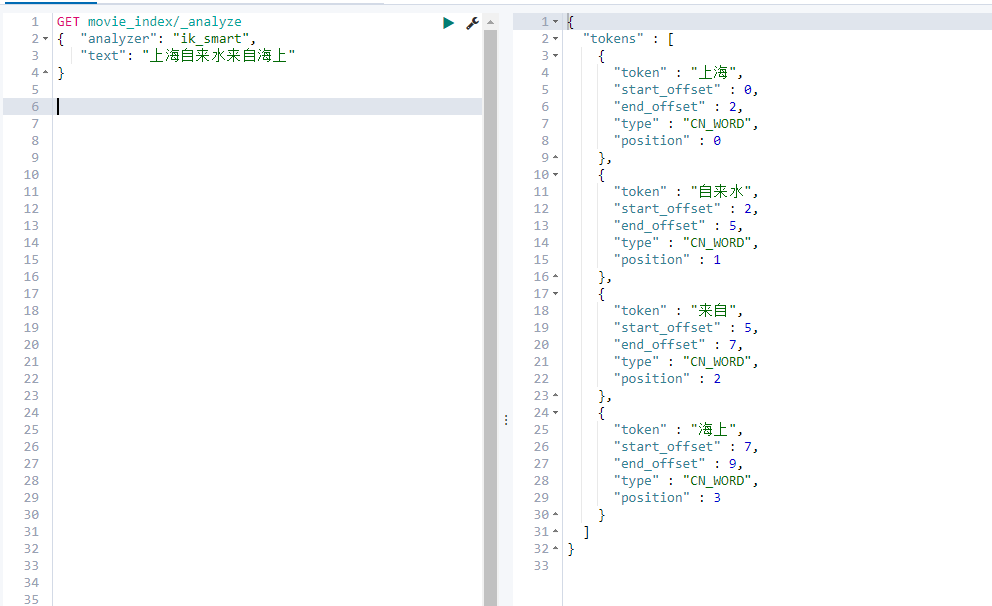
The test uses ik Chinese word segmentation
The common functions of ik word splitter are ik_smart and ik_max_word
ik_smart
Match one by one and use each word once
ik_max_word
Match one by one, and the words that can be connected before and after each word will be displayed, which is equivalent to forming as many relational words as possible
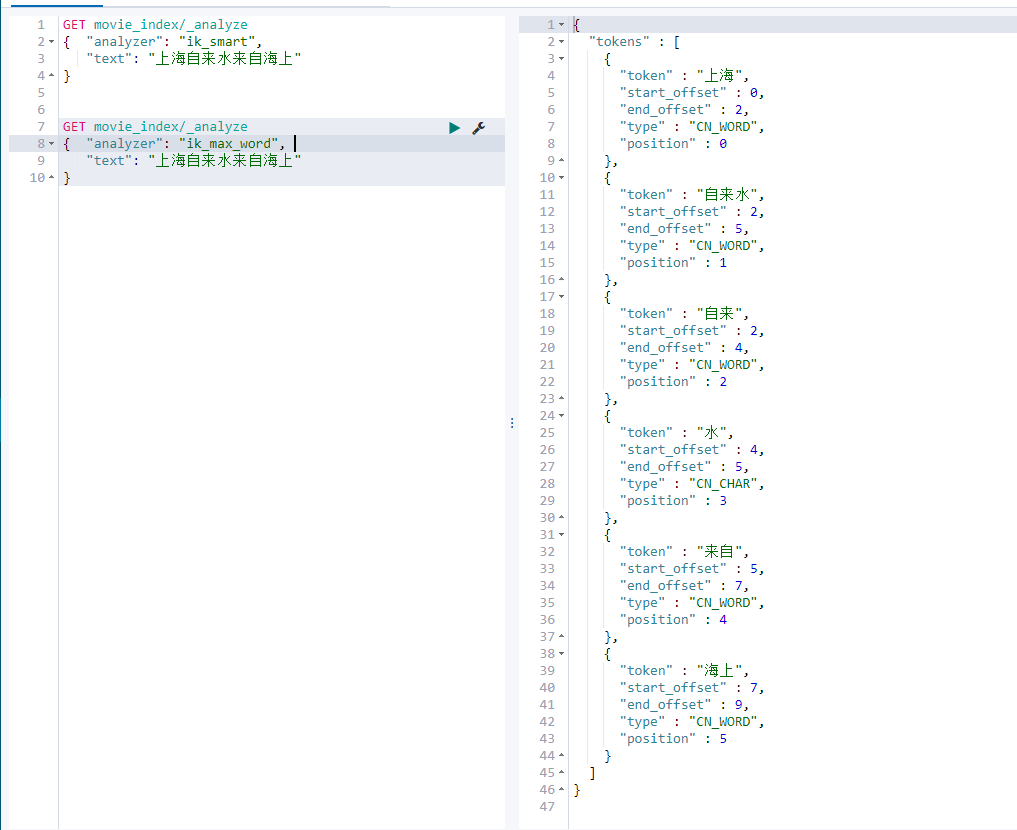
[note]: as can be seen from the above example, different word splitters have obvious differences. Therefore, the default mapping cannot be used for defining a type in the future. It is necessary to manually create mapping to specify the word splitter, because the appropriate word splitter should be selected according to the use scenario
Custom Chinese Thesaurus
In life, some new hot words often appear. For example, recently, the most contact I have with is yyds eternal God... If we always use the previous thesaurus, the eternal God may be divided into: forever, God, God, not what we think of as the eternal God as a whole.
In this case, it is necessary to maintain a set of user-defined Chinese Thesaurus.
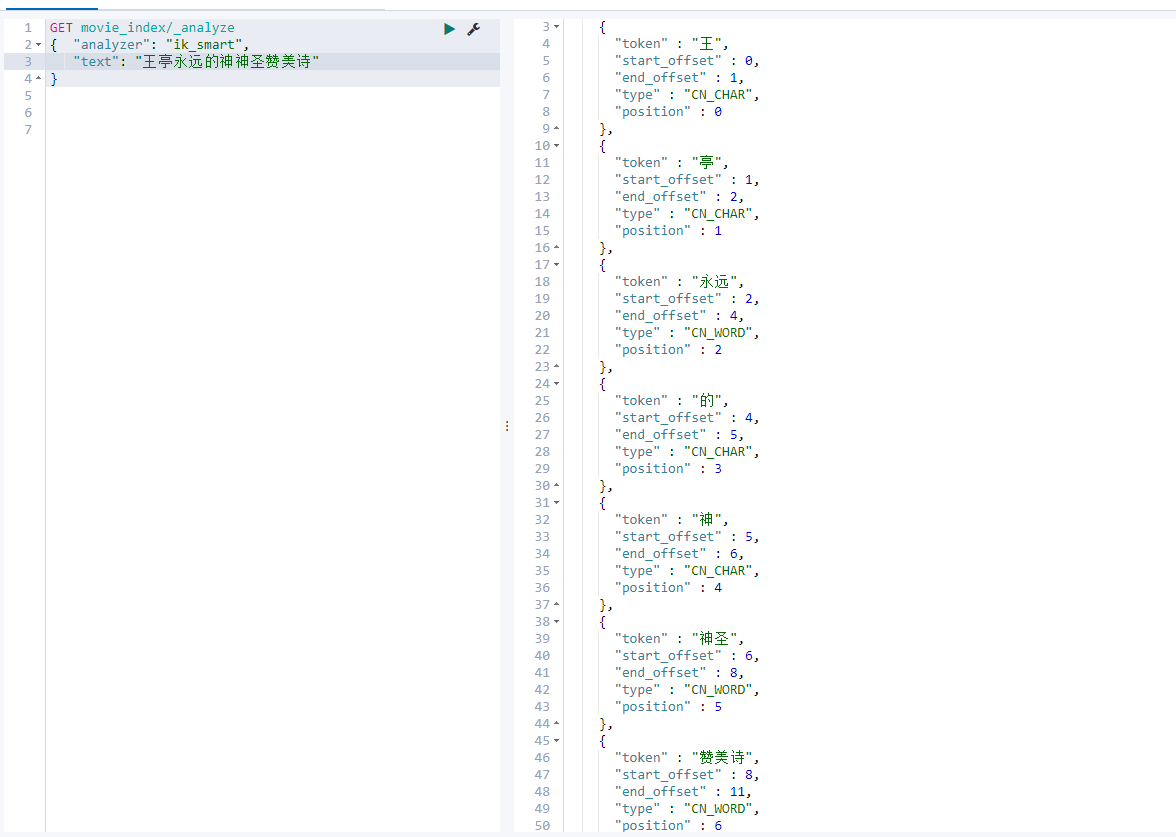
Before there is no custom Chinese Thesaurus, let's check an example and leave the results for comparison after installing the custom Thesaurus:
Before installation:
Install and deploy custom Thesaurus:
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik/config >pwd
/opt/module/elasticsearch-6.6.0/plugins/ik/config
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik/config >ls
extra_main.dic extra_single_word.dic extra_single_word_full.dic extra_single_word_low_freq.dic extra_stopword.dic IKAnalyzer.cfg.xml main.dic preposition.dic quantifier.dic stopword.dic suffix.dic surname.dic
# Modify ik plug-in config / ikanalyzer cfg. XML configuration
# <entry key="remote_ext_dict"> http://11.8.38.86/fenci/esword.txt < / entry > this line configures an nginx proxy address
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik/config >vim IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer Extended configuration</comment>
<!--Users can configure their own extended dictionary here -->
<entry key="ext_dict"></entry>
<!--Users can configure their own extended stop word dictionary here-->
<entry key="ext_stopwords"></entry>
<!--Users can configure the remote extension dictionary here -->
<entry key="remote_ext_dict">http://11.8.38.86/fenci/esword.txt</entry>
<!--Users can configure the remote extended stop word dictionary here-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
# Switch to a machine with nginx service (if there is no nginx, you need to deploy and install it yourself)
root@ops04:/usr/local/nginx-1.10/conf #cd /usr/local/nginx-1.10/
root@ops04:/usr/local/nginx-1.10 #mkdir ik
root@ops04:/usr/local/nginx-1.10 #cd ik
root@ops04:/usr/local/nginx-1.10/ik #mkdir fenci
root@ops04:/usr/local/nginx-1.10/ik #cd fenci
root@ops04:/usr/local/nginx-1.10/ik/fenci #echo "Wang Ting" > > esword txt
root@ops04:/usr/local/nginx-1.10/ik/fenci #echo "eternal God" > > esword txt
root@ops04:/usr/local/nginx-1.10/ik/fenci #echo "sacred hymn" > > esword txt
root@ops04:/usr/local/nginx-1.10/ik/fenci #cat esword.txt
Wang Ting
Eternal God
Sacred Hymn
root@ops04:/usr/local/nginx-1.10/ik/fenci #vim /usr/local/nginx-1.10/conf/nginx.conf
listen 80;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
# Add the following configuration:
location /fenci/ {
root ik;
}
root@ops04:/usr/local/nginx-1.10/ik/fenci #/usr/local/nginx-1.10/sbin/nginx -s reload
# The address must be the same as ikanalyzer cfg. XML configuration item correspondence; You can also finish nginx before configuring ikanalyzer cfg. XML is more reasonable
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik/config >curl http://11.8.38.86/fenci/esword.txt
Wang Ting
Eternal God
Sacred Hymn
# Modify the xml configuration and distribute it to other nodes
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik/config >scp IKAnalyzer.cfg.xml ops02:/opt/module/elasticsearch-6.6.0/plugins/ik/config/
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik/config >scp IKAnalyzer.cfg.xml ops03:/opt/module/elasticsearch-6.6.0/plugins/ik/config/
# Restart es (each node)
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik/config >jps | grep Elasticsearch|awk -F" " '{print $1}'
13077
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik/config >kill -9 13077
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik/config >cd /opt/module/elasticsearch-6.6.0/bin/
wangting@ops01:/opt/module/elasticsearch-6.6.0/bin >./elasticsearch -d
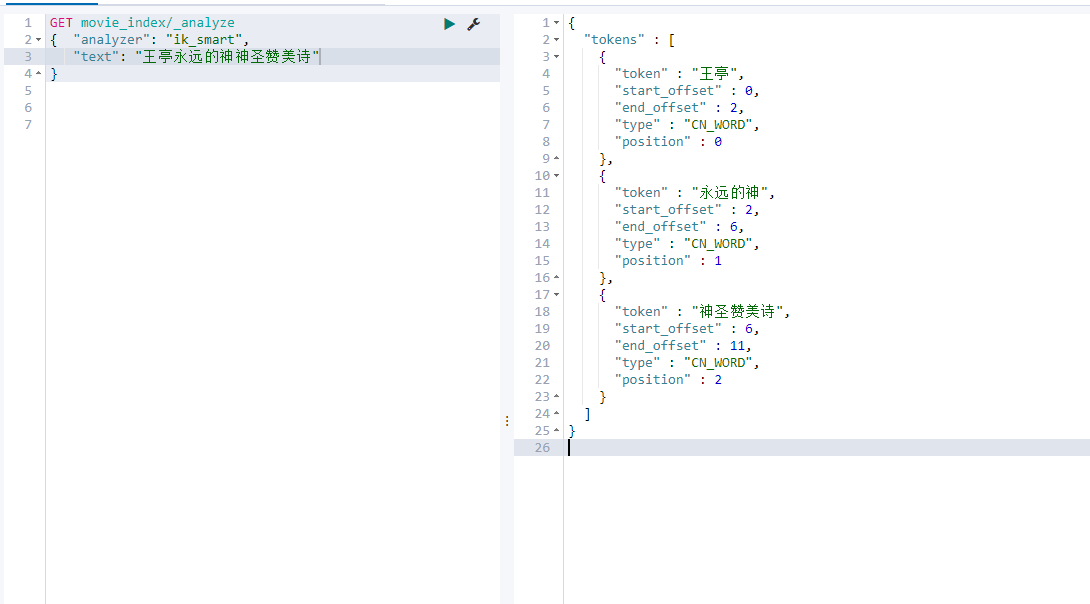
Restart es and retest: (the newly defined words can be recognized successfully)
Section 4 about mapping
Type can be analogized to table. MySQL defines the field type constraint of each field when creating table; The data type of es each field can also be defined; In fact, the data type of the field in each type is defined by the mapping of es.
[note]: if mapping is not set, the system will automatically infer the corresponding data format according to the format of a piece of data
4.4. 1 view the mapping of type
GET movie_index/_mapping/movie
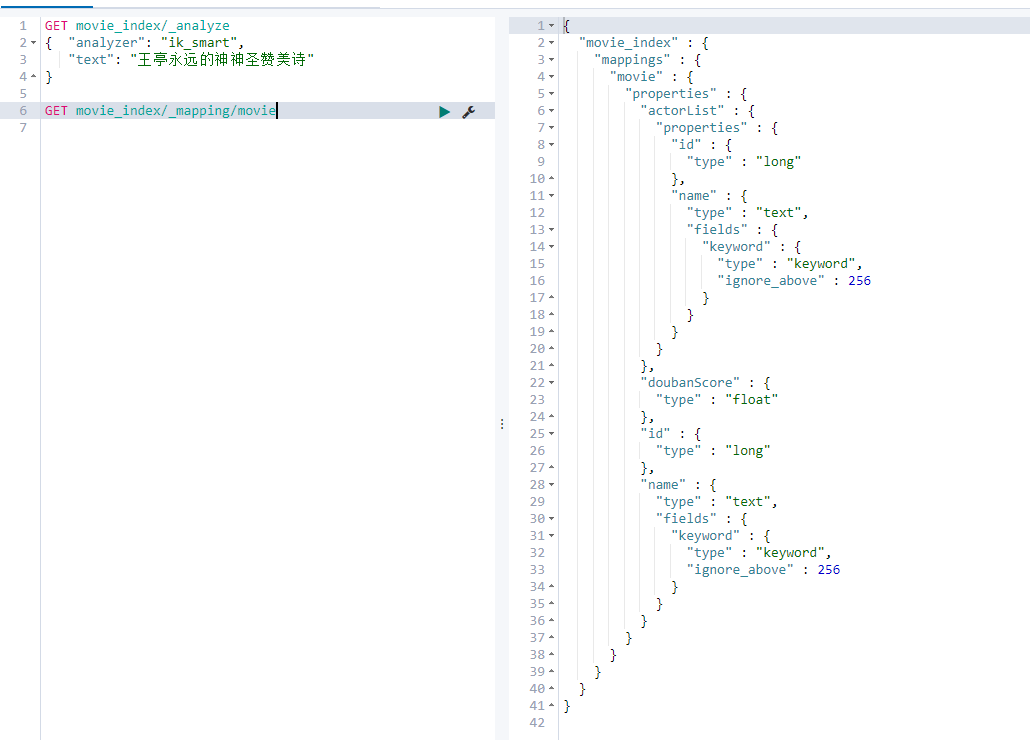
Common types:
true/false → boolean
1020 → long
20.1 → double
"2018-02-01" → date
"hello world" → text + keyword
[note]:
-
By default, only text type can be segmented, and keyword is a string that will not be segmented.
-
In addition to automatic definition, mapping can also be defined manually, but it can only be defined for newly added fields without data. Once you have the data, you can't modify it.
-
Although the data of each Field is placed under different type s, fields with the same name can only have one mapping definition under one index.
4.4. 2 build index based on Chinese words
Creating mapping
PUT movie_chn
{
"mappings": {
"movie":{
"properties": {
"id":{
"type": "long"
},
"name":{
"type": "text"
, "analyzer": "ik_smart"
},
"doubanScore":{
"type": "double"
},
"actorList":{
"properties": {
"id":{
"type":"long"
},
"name":{
"type":"keyword"
}
}
}
}
}
}
}
Name - > define as text type and use ik Chinese word segmentation ik_smart
Execution results:
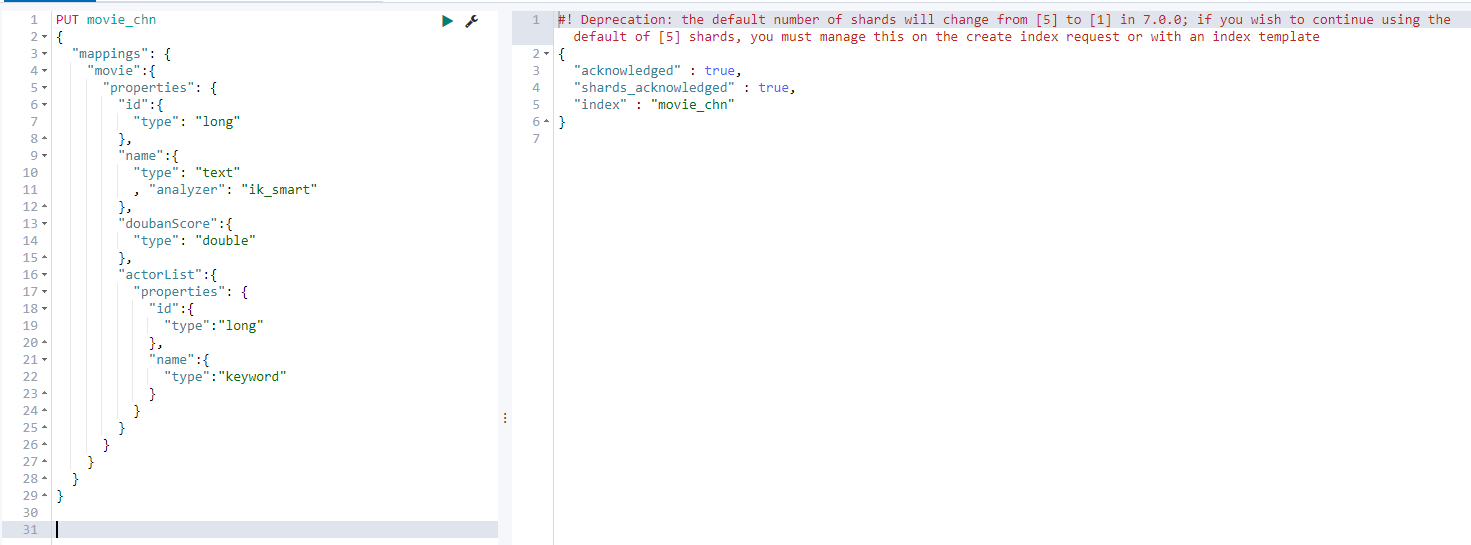
After creation
PUT insert data:
# Data 1
PUT /movie_chn/movie/1
{ "id":1,
"name":"Operation Red Sea",
"doubanScore":8.5,
"actorList":[
{"id":1,"name":"Zhang Yi"},
{"id":2,"name":"Haiqing"},
{"id":3,"name":"Zhang Hanyu"}
]
}
# Data 2
PUT /movie_chn/movie/2
{
"id":2,
"name":"Mekong action",
"doubanScore":8.0,
"actorList":[
{"id":3,"name":"Zhang Hanyu"}
]
}
# Data 3
PUT /movie_chn/movie/3
{
"id":3,
"name":"Red Sea event",
"doubanScore":5.0,
"actorList":[
{"id":4,"name":"Zhang Chen"}
]
}
name: Red sea operation, Mekong operation, Red Sea incident
Test query effect:
Query the results of the movie named Red Sea Battle:
GET /movie_chn/movie/_search
{
"query": {
"match": {
"name": "Red Sea campaign"
}
}
}
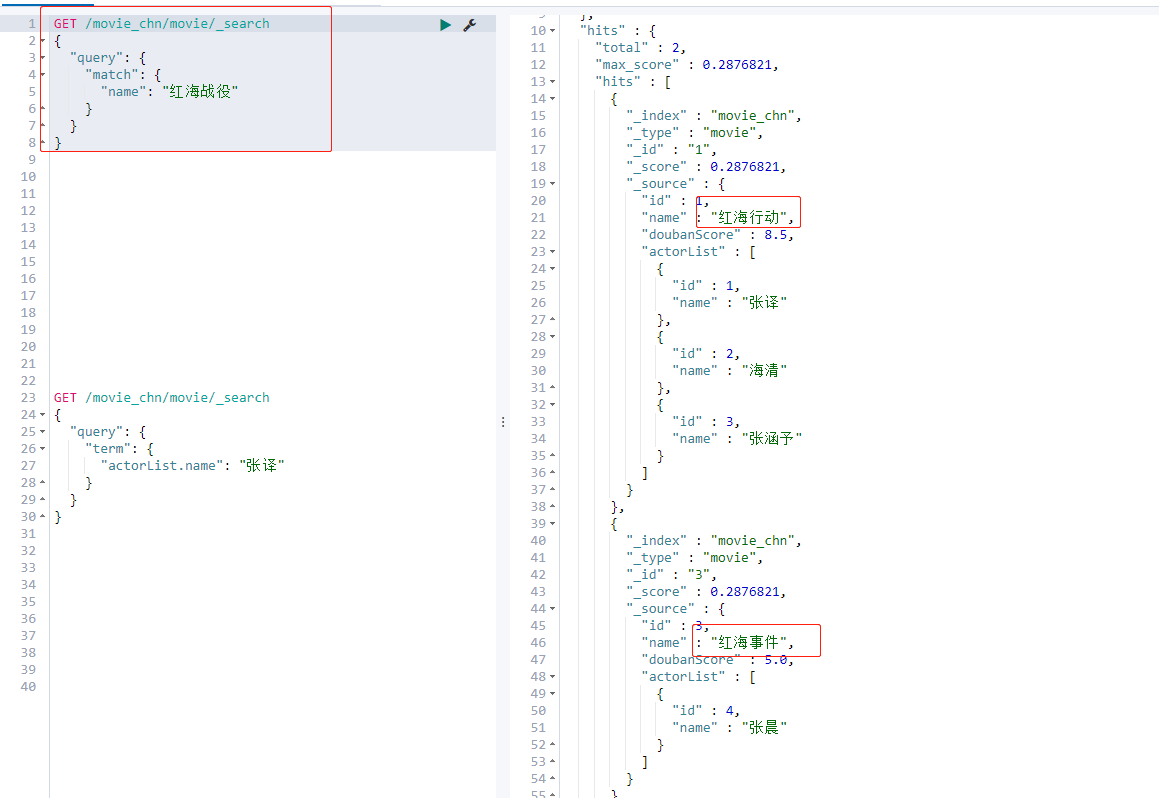
The query results of Zhang's Translation:
GET /movie_chn/movie/_search
{
"query": {
"term": {
"actorList.name": "Zhang Yi"
}
}
}
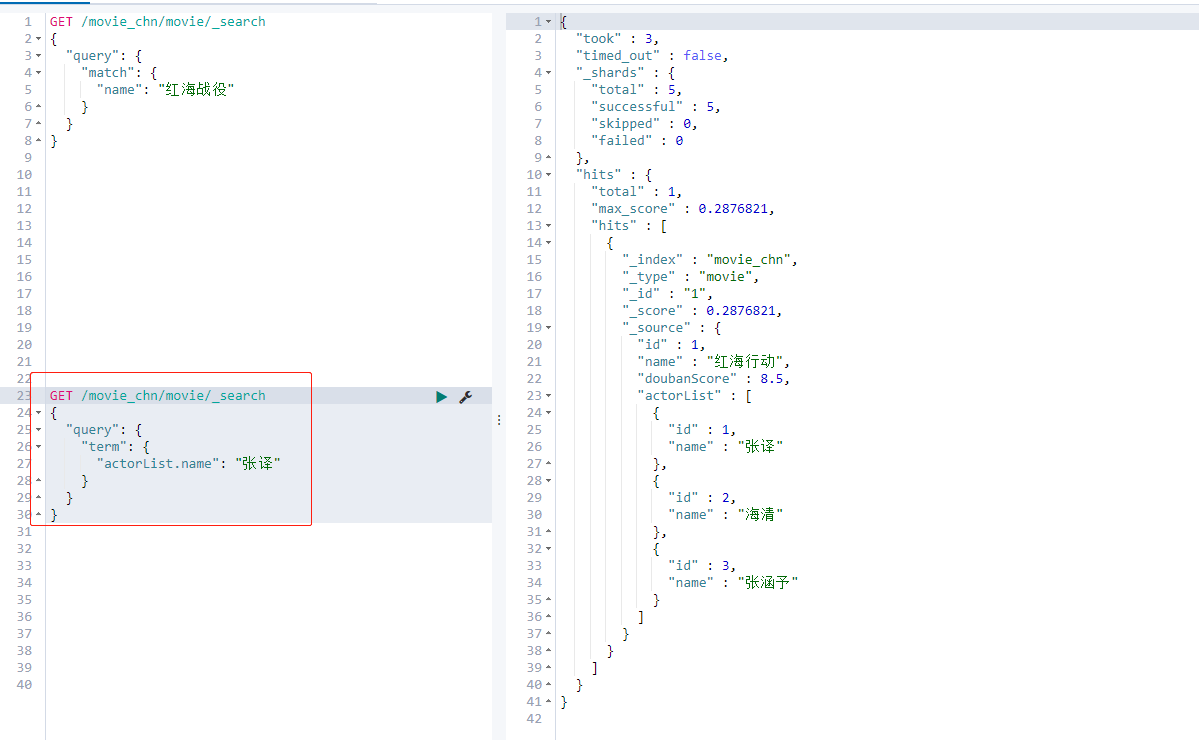
Section 5 index alias_ aliases
Index alias is like a shortcut or soft connection. It can point to one or more indexes or be used by any API that needs index name. Aliases give us great flexibility and allow us to do the following:
1. Group multiple indexes (for example, last_three_months - > can point to multiple indexes)
2. Create a view for a subset of the index
3. In the running cluster, you can seamlessly switch from one index to another
4.5. 1 create index alias
PUT movie_chn_2
{ "aliases": {
"movie_chn_2020-query": {}
},
"mappings": {
"movie":{
"properties": {
"id":{
"type": "long"
},
"name":{
"type": "text"
, "analyzer": "ik_smart"
},
"doubanScore":{
"type": "double"
},
"actorList":{
"properties": {
"id":{
"type":"long"
},
"name":{
"type":"keyword"
}
}
}
}
}
}
}
Define alias:
"aliases": {
"movie_chn_2020-query": {}
}
Add alias to existing index
POST _aliases
{
"actions": [
{ "add": { "index": "movie_chn_2", "alias": "movie_chn_2020-query" }}
]
}
# Can continue to increase
POST _aliases
{
"actions": [
{ "add": { "index": "movie_chn_2", "alias": "movie_chn_2020-query" }}
]
}
You can also narrow the query range by adding filter conditions to create a subset view
POST _aliases
{
"actions": [
{ "add":
{ "index": "movie_chn_2",
"alias": "movie_chn0919-query-zhhy",
"filter": {
"term": { "actorList.id": "3"
}
}
}
}
]
}
4.5. 2 query alias
GET movie_chn_2020-query/_search
4.5. 3 delete an index alias
POST _aliases
{
"actions": [
{ "remove": { "index": "movie_chn_2", "alias": "movie_chn_2020-query" }}
]
}
4.5. 4 is alias switching
POST /_aliases
{
"actions": [
{ "remove": { "index": "movie_chn_2", "alias": "movie_chn_2021-query" }},
{ "add": { "index": "movie_chn", "alias": "movie_chn_2021-query" }}
]
}
4.5. 5 query alias list
GET _cat/aliases?v

Section VI index template
The Index Template index template is a template for creating an index. It can define a series of rules to help us build the mappings and settings of the index that meet specific business needs. By using the Index Template, we can make our index have predictable consistency.
The index template can make it easier to build an index. For example, when the index has not been built, ES obtains the first piece of data and needs to save it. If the index prefix in the data can match the index pattern of the index template, es will directly generate the index according to the template
4.6. 1 split index
Split index is to divide a business index into multiple indexes according to time interval.
give an example:
Put order_info becomes order_info_0801,order_info_0802,order_info_0803,…
There are two benefits:
- Flexibility of structure change: because elastic search does not allow modification of data structure. However, in actual use, the structure and configuration of the index will inevitably change. As long as the index in the next interval is modified, the original index position will remain the same. In this way, there is a certain degree of flexibility.
- Query range optimization: generally, the data of all time cycles will not be queried, so the range of scanned data is physically reduced through segmentation index, which is also an optimization of performance.
4.6. 2 create index template
PUT _template/template_movie
{
"index_patterns": ["movie_test*"],
"settings": {
"number_of_shards": 1
},
"aliases" : {
"{index}-query": {},
"movie_test-query":{}
},
"mappings": {
"_doc": {
"properties": {
"id": {
"type": "keyword"
},
"movie_name": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
}
Among them, "index_patterns": ["movie_test *"], which means going to the movie_ When writing data to the index beginning with test, for example, to movie_test_001 index write data, if index movie_test_001 does not exist, then es will be based on movie_ The test template is automatically indexed.
shard quantity setting:
"settings": {
"number_of_shards": 1
},
Use {index} in "aliases" to obtain the real created index name.
POST movie_test_20210801/_doc
{
"id":"100",
"name":"aaa"
}
POST movie_test_20210801/_doc
{
"id":"101",
"name":"bbb"
}
POST movie_test_20210802/_doc
{
"id":"102",
"name":"ccc"
}
POST movie_test_20210801/_doc
{
"id":"103",
"name":"ddd"
}
4.6. 3. Query existing template list
GET _cat/templates
4.6. 4 view the details of a template
GET _template/template_movie*
When the first piece of data needs to be saved, if the index prefix in the data can match the index pattern of the index template, es will directly generate the index according to the template
4.6. 1 split index
Split index is to divide a business index into multiple indexes according to time interval.
give an example:
Put order_info becomes order_info_0801,order_info_0802,order_info_0803,…
There are two benefits:
- Flexibility of structure change: because elastic search does not allow modification of data structure. However, in actual use, the structure and configuration of the index will inevitably change. As long as the index in the next interval is modified, the original index position will remain the same. In this way, there is a certain degree of flexibility.
- Query range optimization: generally, the data of all time cycles will not be queried, so the range of scanned data is physically reduced through segmentation index, which is also an optimization of performance.
4.6. 2 create index template
PUT _template/template_movie
{
"index_patterns": ["movie_test*"],
"settings": {
"number_of_shards": 1
},
"aliases" : {
"{index}-query": {},
"movie_test-query":{}
},
"mappings": {
"_doc": {
"properties": {
"id": {
"type": "keyword"
},
"movie_name": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
}
Among them, "index_patterns": ["movie_test *"], which means going to the movie_ When writing data to the index beginning with test, for example, to movie_test_001 index write data, if index movie_test_001 does not exist, then es will be based on movie_ The test template is automatically indexed.
shard quantity setting:
"settings": {
"number_of_shards": 1
},
Use {index} in "aliases" to obtain the real created index name.
POST movie_test_20210801/_doc
{
"id":"100",
"name":"aaa"
}
POST movie_test_20210801/_doc
{
"id":"101",
"name":"bbb"
}
POST movie_test_20210802/_doc
{
"id":"102",
"name":"ccc"
}
POST movie_test_20210801/_doc
{
"id":"103",
"name":"ddd"
}
4.6. 3. Query existing template list
GET _cat/templates
4.6. 4 view the details of a template
GET _template/template_movie*