1, Introduction to LDA theme model
LDA topic model is mainly used to infer the topic distribution of documents. The topic of each document in the document set can be given in the form of probability distribution, and topic clustering or text classification can be carried out according to the topic.
LDA topic model does not care about the order of words in the document, and usually uses bag of word feature to represent the document. For the introduction of word bag model, please refer to this article: Text vectorization -- word bag model -- Zhihu
To understand the LDA model, we need to first understand the generation model of LDA. How does LDA think an article is formed?
LDA model holds that topics can be represented by a lexical distribution, while articles can be represented by topic distribution.
For example, there are two themes, food and beauty. LDA said that two topics can be represented by word distribution, they are:
{bread: 0.4, hot pot: 0.5, eyebrow pencil: 0.03, blush: 0.07}
Eyebrow pencil: 0.4, blush: 0.5, bread: 0.03, hot pot: 0.07}
Similarly, for the two articles, LDA believes that the articles can be represented by topic distribution:
Beauty diary {beauty: 0.8, food: 0.1, others: 0.1}
Food exploration {food: 0.8, beauty: 0.1, others: 0.1}
Therefore, if you want to generate an article, you can first select one of the above topics with a certain probability, and then select a word under that topic with a certain probability. Repeat these two steps continuously to generate the final article.
In LDA model, a document is generated as follows:

Among them, the Beta like distribution is the conjugate prior probability distribution of binomial distribution, and the Dirichlet distribution is the conjugate prior probability distribution of polynomial distribution.
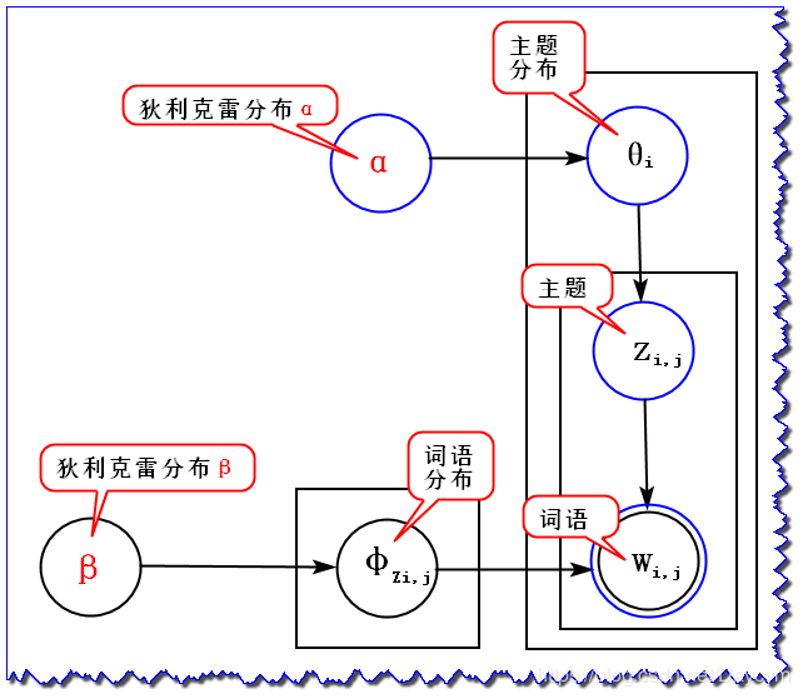
If we want to generate a document, the probability of each word in it is:
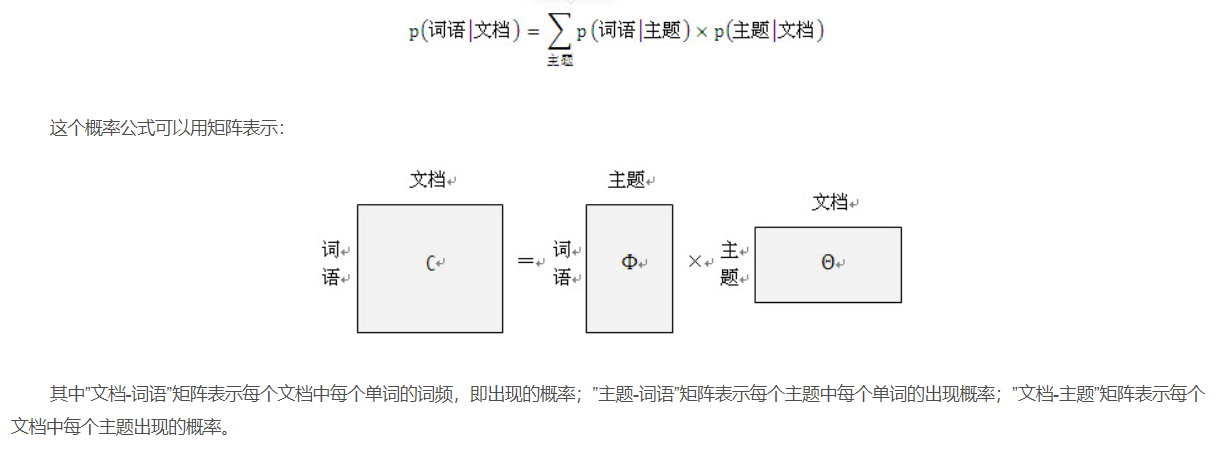
For more detailed mathematical derivation, see: Popular understanding of lda topic model_ The method of structure and the way of algorithm - CSDN blog_ lda model
The purpose of modeling is to infer the hidden topic distribution. In other words, human beings write all kinds of articles according to the document generation model, and then throw them to the computer, which is equivalent to the computer seeing the written articles. Now the computer needs to sum up the theme of the article according to a series of words seen in an article, and then get the different occurrence probability of each theme: theme distribution.
As for how the LDA topic model is implemented in the computer, we don't have to study it in detail. Now there are many packages that can be directly used for LDA topic analysis. We can use them directly. (that's right, I'm the switchman)
2, Python implementation
Before using Python for LDA topic model analysis, I first processed the document with word segmentation and de stop words (for details, see my previous article: Word segmentation of single microblog document in python -- jieba word segmentation (with reserved words and stop words)_ A lost heart blog - CSDN blog_ jieba stop word)
My input file below is also a file that has been divided into words
1. Import algorithm package
import gensim
from gensim import corpora
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
import warnings
warnings.filterwarnings('ignore') # To ignore all warnings that arise here to enhance clarity
from gensim.models.coherencemodel import CoherenceModel
from gensim.models.ldamodel import LdaModel
2. Load data
First, convert the document into a binary list, in which each sub list represents a microblog:
PATH = "E:/data/output.csv"
file_object2=open(PATH,encoding = 'utf-8',errors = 'ignore').read().split('\n') #Read content line by line
data_set=[] #Create a list of stored participles
for i in range(len(file_object2)):
result=[]
seg_list = file_object2[i].split()
for w in seg_list : #Read each line participle
result.append(w)
data_set.append(result)
print(data_set)
Construct a dictionary and quantify the corpus:
dictionary = corpora.Dictionary(data_set) # Build dictionary corpus = [dictionary.doc2bow(text) for text in data_set] #Indicates the number of times the word appears
3. Build LDA model
ldamodel = LdaModel(corpus, num_topics=10, id2word = dictionary, passes=30,random_state = 1) #Divided into 10 themes print(ldamodel.print_topics(num_topics=num_topics, num_words=15)) #Each topic outputs 15 words
This is the construction method of LDA model when determining the number of topics. Generally, we can use indicators to evaluate the quality of the model, or use these indicators to determine the optimal number of topics. Generally, the indicators used to evaluate LDA topic model are perplexity and topic consistency. The lower the perplexity or the higher the consistency, the better the model. Some studies show that perfectivity is not a good indicator, so I generally use coherence to evaluate the model and select the optimal topic, but I use both methods in the following code.
#Computational confusion
def perplexity(num_topics):
ldamodel = LdaModel(corpus, num_topics=num_topics, id2word = dictionary, passes=30)
print(ldamodel.print_topics(num_topics=num_topics, num_words=15))
print(ldamodel.log_perplexity(corpus))
return ldamodel.log_perplexity(corpus)
#Calculate coherence
def coherence(num_topics):
ldamodel = LdaModel(corpus, num_topics=num_topics, id2word = dictionary, passes=30,random_state = 1)
print(ldamodel.print_topics(num_topics=num_topics, num_words=10))
ldacm = CoherenceModel(model=ldamodel, texts=data_set, dictionary=dictionary, coherence='c_v')
print(ldacm.get_coherence())
return ldacm.get_coherence()4. Draw the theme coherence curve and select the best number of themes
x = range(1,15)
# z = [perplexity(i) for i in x] #If you want to use confusion, choose this
y = [coherence(i) for i in x]
plt.plot(x, y)
plt.xlabel('Number of topics')
plt.ylabel('coherence size')
plt.rcParams['font.sans-serif']=['SimHei']
matplotlib.rcParams['axes.unicode_minus']=False
plt.title('theme-coherence Changes')
plt.show()Finally, the word distribution of each topic and such graphics can be obtained:
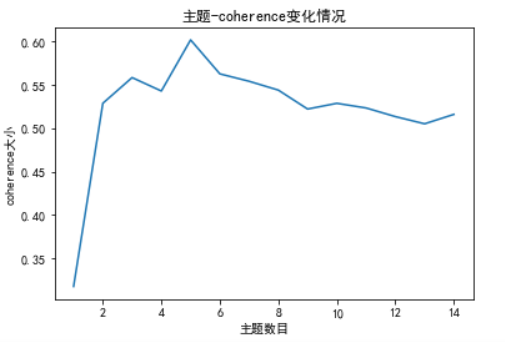
5. Result output and visualization
Through the above topic evaluation, we found that we can select 5 as the number of topics. Next, we can run the model again, set the number of topics to 5, and output the most likely corresponding topics of each document
from gensim.models import LdaModel
import pandas as pd
from gensim.corpora import Dictionary
from gensim import corpora, models
import csv
# Prepare data
PATH = "E:/data/output1.csv"
file_object2=open(PATH,encoding = 'utf-8',errors = 'ignore').read().split('\n') #Read content line by line
data_set=[] #Create a list of stored participles
for i in range(len(file_object2)):
result=[]
seg_list = file_object2[i].split()
for w in seg_list :#Read each line participle
result.append(w)
data_set.append(result)
dictionary = corpora.Dictionary(data_set) # Build dictionary
corpus = [dictionary.doc2bow(text) for text in data_set]
lda = LdaModel(corpus=corpus, id2word=dictionary, num_topics=5, passes = 30,random_state=1)
topic_list=lda.print_topics()
print(topic_list)
for i in lda.get_document_topics(corpus)[:]:
listj=[]
for j in i:
listj.append(j[1])
bz=listj.index(max(listj))
print(i[bz][0])At the same time, we can use pyLDAvis to visualize the results of LDA model:
import pyLDAvis.gensim pyLDAvis.enable_notebook() data = pyLDAvis.gensim.prepare(lda, corpus, dictionary) pyLDAvis.save_html(data, 'E:/data/3topic.html')
We can probably get the following results:
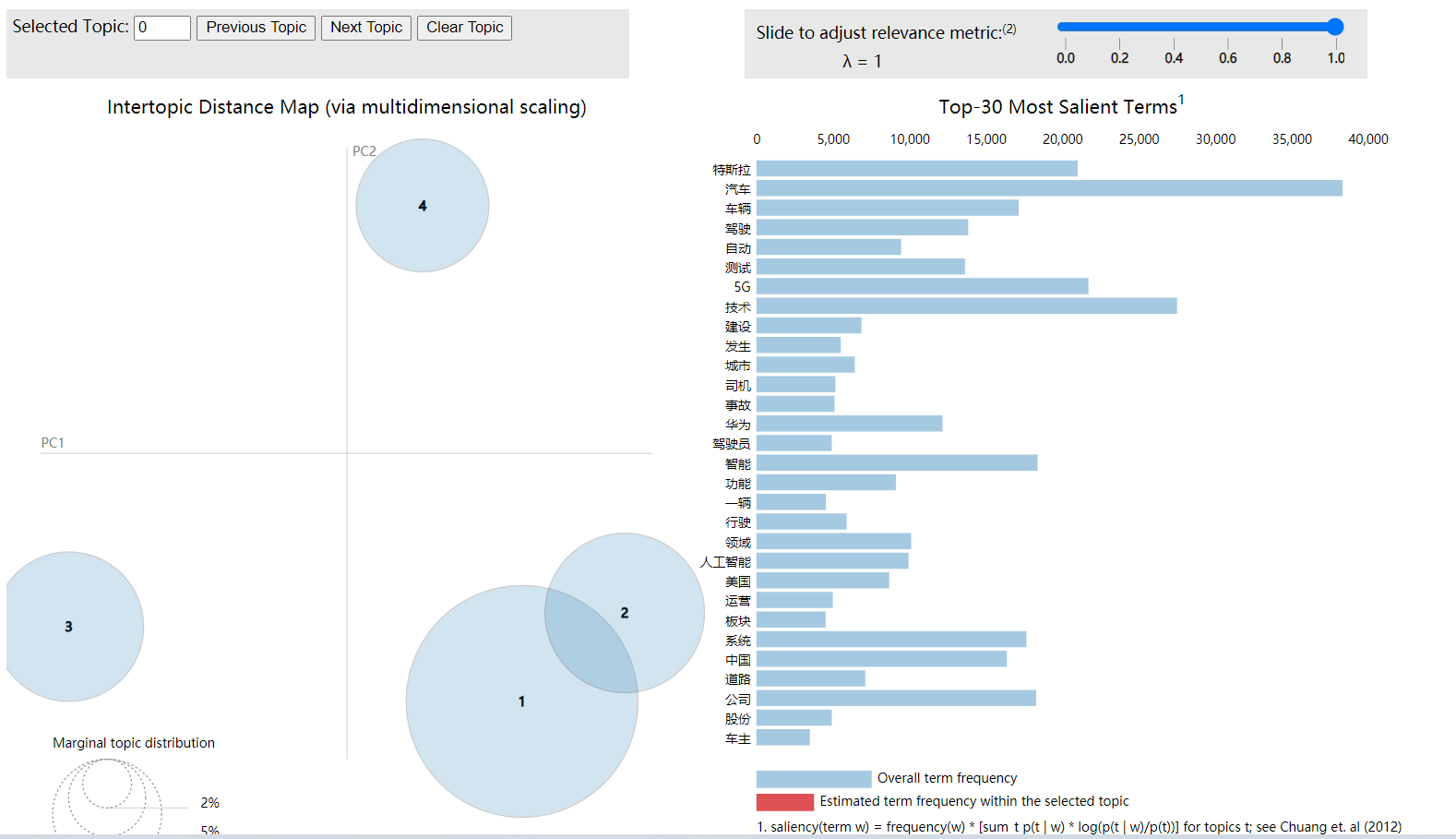
The circle on the left represents the theme, and the right represents the contribution of each word to the theme.
All codes are as follows:
import gensim
from gensim import corpora
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
import warnings
warnings.filterwarnings('ignore') # To ignore all warnings that arise here to enhance clarity
from gensim.models.coherencemodel import CoherenceModel
from gensim.models.ldamodel import LdaModel
# Prepare data
PATH = "E:/data/output.csv"
file_object2=open(PATH,encoding = 'utf-8',errors = 'ignore').read().split('\n') #Read content line by line
data_set=[] #Create a list of stored participles
for i in range(len(file_object2)):
result=[]
seg_list = file_object2[i].split()
for w in seg_list :#Read each line participle
result.append(w)
data_set.append(result)
print(data_set)
dictionary = corpora.Dictionary(data_set) # Building a document term matrix
corpus = [dictionary.doc2bow(text) for text in data_set]
#Lda = gensim.models.ldamodel.LdaModel # Create LDA object
#Computational confusion
def perplexity(num_topics):
ldamodel = LdaModel(corpus, num_topics=num_topics, id2word = dictionary, passes=30)
print(ldamodel.print_topics(num_topics=num_topics, num_words=15))
print(ldamodel.log_perplexity(corpus))
return ldamodel.log_perplexity(corpus)
#Calculate coherence
def coherence(num_topics):
ldamodel = LdaModel(corpus, num_topics=num_topics, id2word = dictionary, passes=30,random_state = 1)
print(ldamodel.print_topics(num_topics=num_topics, num_words=10))
ldacm = CoherenceModel(model=ldamodel, texts=data_set, dictionary=dictionary, coherence='c_v')
print(ldacm.get_coherence())
return ldacm.get_coherence()
# Draw confusion line chart
x = range(1,15)
# z = [perplexity(i) for i in x]
y = [coherence(i) for i in x]
plt.plot(x, y)
plt.xlabel('Number of topics')
plt.ylabel('coherence size')
plt.rcParams['font.sans-serif']=['SimHei']
matplotlib.rcParams['axes.unicode_minus']=False
plt.title('theme-coherence Changes')
plt.show()from gensim.models import LdaModel
import pandas as pd
from gensim.corpora import Dictionary
from gensim import corpora, models
import csv
# Prepare data
PATH = "E:/data/output1.csv"
file_object2=open(PATH,encoding = 'utf-8',errors = 'ignore').read().split('\n') #Read content line by line
data_set=[] #Create a list of stored participles
for i in range(len(file_object2)):
result=[]
seg_list = file_object2[i].split()
for w in seg_list :#Read each line participle
result.append(w)
data_set.append(result)
dictionary = corpora.Dictionary(data_set) # Building a document term matrix
corpus = [dictionary.doc2bow(text) for text in data_set]
lda = LdaModel(corpus=corpus, id2word=dictionary, num_topics=5, passes = 30,random_state=1)
topic_list=lda.print_topics()
print(topic_list)
result_list =[]
for i in lda.get_document_topics(corpus)[:]:
listj=[]
for j in i:
listj.append(j[1])
bz=listj.index(max(listj))
result_list.append(i[bz][0])
print(result_list)import pyLDAvis.gensim pyLDAvis.enable_notebook() data = pyLDAvis.gensim.prepare(lda, corpus, dictionary) pyLDAvis.save_html(data, 'E:/data/topic.html')
Take it yourself if necessary~
You can also pay attention to me, and then I will send more dry articles on data analysis~