The SK used to manage and store network packets was introduced earlier_ Buff, as well as the socket and socket structure describing the communication protocol, now it's finally the turn to communicate with the remote computer! In terms of common sense, a connection must be established before communication. For example, when a wired keyboard sends a signal to the computer, the keyboard needs to be connected to the computer through the usb interface first. Otherwise, how can the computer accept the electrical signal of the keyboard? Similarly: if I want to use the mouse, for example, insert the mouse into the usb interface of the computer first. After moving the mouse, the mouse will send an electrical signal to the computer. Both of them need to establish a physical connection first! So how can the connection be established when two hosts with a distance of 18000 miles communicate with each other? Of course, the physical connection is completed through switches, routers, cables and optical fibers. How is the logical connection established? This paper takes tcp protocol as an example!
1. tcp protocol has been used in the industry for so many years and is very mature. I won't repeat the principle of three handshakes! The process of three handshakes is shown in the figure below:
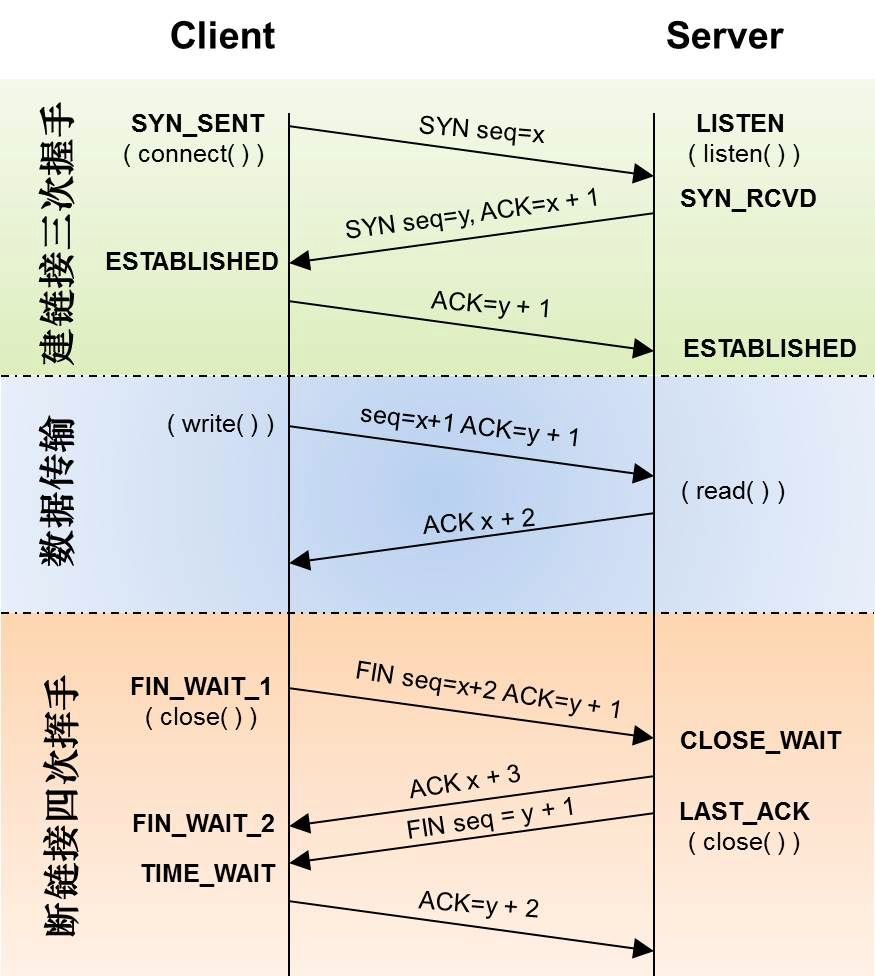
As can be seen from the above figure, the client calls connect and the server calls listen to complete three handshakes. app developers do not need to care about how these three handshakes are completed! The first time, the client sends a message to the server, indicating that I want to communicate with you, and gives a number M; The second time, the server replied to the client, indicating that I agreed to communicate with you. The reply included M+1, indicating that this reply was the SYN package you sent last time, and attached your own N! The third time, the client sends a message to the server, attaching M+1, indicating that the reply is the SYN package of the server! So far, the two sides have communicated back and forth for a total of 3 times, and the connection is established! Next, let's disassemble one by one to see what we have done in each step!
(1) the client sends the SYN M packet to the server. You can see the contents of the SYN packet by capturing the packet with wireshark, as follows:
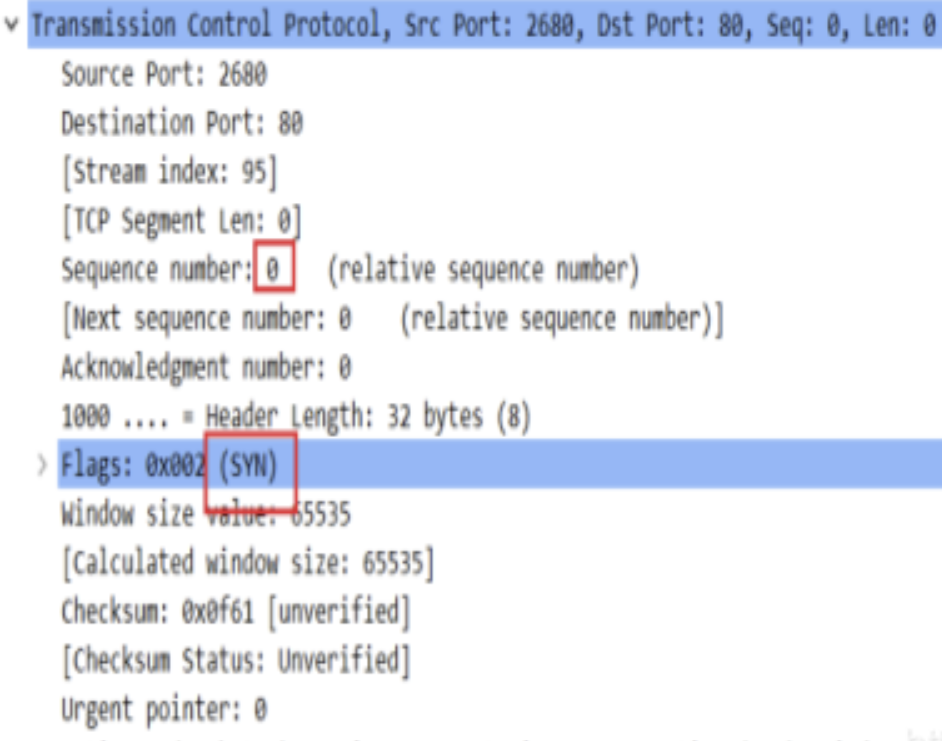
The function that the linux kernel constructs and sends SYN packets is called tcp_v4_connect, the code is as follows: there are not many codes, and the important parts are annotated in Chinese
/* This will initiate an outgoing connection. */ int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len) { struct sockaddr_in *usin = (struct sockaddr_in *)uaddr; struct inet_sock *inet = inet_sk(sk); struct tcp_sock *tp = tcp_sk(sk); __be16 orig_sport, orig_dport; __be32 daddr, nexthop; struct flowi4 *fl4; struct rtable *rt; int err; struct ip_options_rcu *inet_opt; if (addr_len < sizeof(struct sockaddr_in)) return -EINVAL; /*AF_INET Is the parameter passed in when the user calls the socket function to create a socket, Address length and protocol cluster are checked here*/ if (usin->sin_family != AF_INET) return -EAFNOSUPPORT; /*Temporarily set the temporary variables of the next hop address and destination address as the address submitted by the user*/ nexthop = daddr = usin->sin_addr.s_addr; inet_opt = rcu_dereference_protected(inet->inet_opt, lockdep_sock_is_held(sk)); /* If source address routing is used, select an appropriate next hop address.*/ if (inet_opt && inet_opt->opt.srr) { if (!daddr) return -EINVAL; nexthop = inet_opt->opt.faddr; } /*Get the ip layer routing information of the packet*/ orig_sport = inet->inet_sport; orig_dport = usin->sin_port; fl4 = &inet->cork.fl.u.ip4; /*A host may have multiple ip addresses. Which ip address is used to send packets? Check the routing table according to the nexthop parameter (i.e. the server IP passed by connect), The hit routing table entry contains the local ip address*/ rt = ip_route_connect(fl4, nexthop, inet->inet_saddr, RT_CONN_FLAGS(sk), sk->sk_bound_dev_if, IPPROTO_TCP, orig_sport, orig_dport, sk); if (IS_ERR(rt)) { err = PTR_ERR(rt); if (err == -ENETUNREACH) IP_INC_STATS(sock_net(sk), IPSTATS_MIB_OUTNOROUTES); return err; } /* Find the route and verify the type of route returned, TCP Multicast and broadcasting are not allowed.*/ if (rt->rt_flags & (RTCF_MULTICAST | RTCF_BROADCAST)) { ip_rt_put(rt); return -ENETUNREACH; } if (!inet_opt || !inet_opt->opt.srr) daddr = fl4->daddr; /*If the user has no previous bind source, INET - > INET_ Will be saddr.0 It is judged here that if the saddr is 0, the fl4 - > saddr returned from the route lookup is assigned to INET - > INET_ saddr. inet->inet_saddr The value of will be used as the source ip of syn message in the future; 1,If you change the source ip here, fill it with random numbers and send it to the server, Will the server keep sending ack packets, resulting in the effect of DDOS? 2,If you change the source ip here to the address of the victim server, and then randomly send it to the third-party server, the third-party server will receive it SYN The packet is then distributed to the victim server to send ack packets. Does it achieve the effect of reflecting DDOS? */ if (!inet->inet_saddr) inet->inet_saddr = fl4->saddr; sk_rcv_saddr_set(sk, inet->inet_saddr); if (tp->rx_opt.ts_recent_stamp && inet->inet_daddr != daddr) { /* Reset inherited state */ tp->rx_opt.ts_recent = 0; tp->rx_opt.ts_recent_stamp = 0; if (likely(!tp->repair)) tp->write_seq = 0; } if (tcp_death_row.sysctl_tw_recycle && !tp->rx_opt.ts_recent_stamp && fl4->daddr == daddr) tcp_fetch_timewait_stamp(sk, &rt->dst); inet->inet_dport = usin->sin_port; sk_daddr_set(sk, daddr); inet_csk(sk)->icsk_ext_hdr_len = 0; if (inet_opt) inet_csk(sk)->icsk_ext_hdr_len = inet_opt->opt.optlen; tp->rx_opt.mss_clamp = TCP_MSS_DEFAULT; /* Socket identity is still unknown (sport may be zero). * However we set state to SYN-SENT and not releasing socket * lock select source port, enter ourselves into the hash tables and * complete initialization after this. Set the state of TCP to TCP_ SYN_ Send, dynamically bind a local port */ tcp_set_state(sk, TCP_SYN_SENT); err = inet_hash_connect(&tcp_death_row, sk); if (err) goto failure; sk_set_txhash(sk); /*The final call is fib_ table_ The lookup function looks up the longest matching ip address from the trie tree*/ rt = ip_route_newports(fl4, rt, orig_sport, orig_dport, inet->inet_sport, inet->inet_dport, sk); if (IS_ERR(rt)) { err = PTR_ERR(rt); rt = NULL; goto failure; } /* OK, now commit destination to socket. */ sk->sk_gso_type = SKB_GSO_TCPV4; sk_setup_caps(sk, &rt->dst); if (!tp->write_seq && likely(!tp->repair)) tp->write_seq = secure_tcp_sequence_number(inet->inet_saddr, inet->inet_daddr, inet->inet_sport, usin->sin_port); inet->inet_id = tp->write_seq ^ jiffies; /*Generate SYN packet and send*/ err = tcp_connect(sk); rt = NULL; if (err) goto failure; return 0; failure: /* * This unhashes the socket and releases the local port, * if necessary. */ tcp_set_state(sk, TCP_CLOSE); ip_rt_put(rt); sk->sk_route_caps = 0; inet->inet_dport = 0; return err; }
Note: these two lines of code are used to construct the source ip address, which can be changed to reflect DDOS attacks!
if (!inet->inet_saddr) inet->inet_saddr = fl4->saddr;
This function is preceded by various pre condition checks, fault tolerance, etc. the function that really constructs syn packets and sends them is TCP_ TCP in connect function_ send_ syn_ Data and tcp_transmit_skb function! Since the two are calling relationships, the focus here is on parsing the transmit function, as follows:
/* This routine actually transmits TCP packets queued in by * tcp_do_sendmsg(). This is used by both the initial * transmission and possible later retransmissions. * All SKB's seen here are completely headerless. It is our * job to build the TCP header, and pass the packet down to * IP so it can do the same plus pass the packet off to the * device. * * We are working here with either a clone of the original * SKB, or a fresh unique copy made by the retransmit engine. Copy or copy the skb, construct the tcp header in the skb, and send the calling network layer sending function to the skb; Before sending, you need to clone or copy the skb, because the skb will be released after it is successfully sent to the network device, The tcp layer can't really release, because it needs to wait for the ack of the data segment; Then construct tcp header and options; Finally, the sending callback function provided by the network layer is sent to skb, and the callback function of the IP layer is ip_. queue_ xmit */ static int tcp_transmit_skb(struct sock *sk, struct sk_buff *skb, int clone_it, gfp_t gfp_mask) { const struct inet_connection_sock *icsk = inet_csk(sk); struct inet_sock *inet; struct tcp_sock *tp; struct tcp_skb_cb *tcb; struct tcp_out_options opts; unsigned int tcp_options_size, tcp_header_size; struct tcp_md5sig_key *md5; struct tcphdr *th; int err; BUG_ON(!skb || !tcp_skb_pcount(skb)); tp = tcp_sk(sk); //If there are other processes to use skb,You need to copy skb if (clone_it) { skb_mstamp_get(&skb->skb_mstamp); TCP_SKB_CB(skb)->tx.in_flight = TCP_SKB_CB(skb)->end_seq - tp->snd_una; tcp_rate_skb_sent(sk, skb); if (unlikely(skb_cloned(skb))) skb = pskb_copy(skb, gfp_mask); else skb = skb_clone(skb, gfp_mask); if (unlikely(!skb)) return -ENOBUFS; } inet = inet_sk(sk); tcb = TCP_SKB_CB(skb); memset(&opts, 0, sizeof(opts)); //Is it SYN Request packet if (unlikely(tcb->tcp_flags & TCPHDR_SYN)) //structure TCP Options include timestamp, window size, and select answer SACK tcp_options_size = tcp_syn_options(sk, skb, &opts, &md5); else//Build general TCP option tcp_options_size = tcp_established_options(sk, skb, &opts, &md5); //tCP The head length includes the selected length+ TCP head tcp_header_size = tcp_options_size + sizeof(struct tcphdr); /* if no packet is in qdisc/device queue, then allow XPS to select * another queue. We can be called from tcp_tsq_handler() * which holds one reference to sk_wmem_alloc. * * TODO: Ideally, in-flight pure ACK packets should not matter here. * One way to get this would be to set skb->truesize = 2 on them. */ skb->ooo_okay = sk_wmem_alloc_get(sk) < SKB_TRUESIZE(1); skb_push(skb, tcp_header_size); skb_reset_transport_header(skb); skb_orphan(skb); skb->sk = sk; skb->destructor = skb_is_tcp_pure_ack(skb) ? __sock_wfree : tcp_wfree; skb_set_hash_from_sk(skb, sk); atomic_add(skb->truesize, &sk->sk_wmem_alloc); /* Build TCP header and checksum it. A lot of preparatory work has been done, and the tcp header is finally constructed here */ th = (struct tcphdr *)skb->data; th->source = inet->inet_sport; th->dest = inet->inet_dport; th->seq = htonl(tcb->seq); th->ack_seq = htonl(tp->rcv_nxt); *(((__be16 *)th) + 6) = htons(((tcp_header_size >> 2) << 12) | tcb->tcp_flags); th->check = 0; th->urg_ptr = 0; /* The urg_mode check is necessary during a below snd_una win probe */ //SYN The package does not require a calculation window if (unlikely(tcp_urg_mode(tp) && before(tcb->seq, tp->snd_up))) { if (before(tp->snd_up, tcb->seq + 0x10000)) { th->urg_ptr = htons(tp->snd_up - tcb->seq); th->urg = 1; } else if (after(tcb->seq + 0xFFFF, tp->snd_nxt)) { th->urg_ptr = htons(0xFFFF); th->urg = 1; } } tcp_options_write((__be32 *)(th + 1), tp, &opts); skb_shinfo(skb)->gso_type = sk->sk_gso_type; if (likely(!(tcb->tcp_flags & TCPHDR_SYN))) { th->window = htons(tcp_select_window(sk)); tcp_ecn_send(sk, skb, th, tcp_header_size); } else { /* RFC1323: The window in SYN & SYN/ACK segments * is never scaled. */ th->window = htons(min(tp->rcv_wnd, 65535U)); } #ifdef CONFIG_TCP_MD5SIG /* Calculate the MD5 hash, as we have all we need now */ if (md5) { sk_nocaps_add(sk, NETIF_F_GSO_MASK); tp->af_specific->calc_md5_hash(opts.hash_location, md5, sk, skb); } #endif icsk->icsk_af_ops->send_check(sk, skb); if (likely(tcb->tcp_flags & TCPHDR_ACK)) tcp_event_ack_sent(sk, tcp_skb_pcount(skb));//Clear timer /* There is data to send */ if (skb->len != tcp_header_size) { tcp_event_data_sent(tp, sk); tp->data_segs_out += tcp_skb_pcount(skb); } /* Number of statistical segments */ if (after(tcb->end_seq, tp->snd_nxt) || tcb->seq == tcb->end_seq) TCP_ADD_STATS(sock_net(sk), TCP_MIB_OUTSEGS, tcp_skb_pcount(skb)); tp->segs_out += tcp_skb_pcount(skb); /* OK, its time to fill skb_shinfo(skb)->gso_{segs|size} */ /* skb Statistics of number of segments in */ skb_shinfo(skb)->gso_segs = tcp_skb_pcount(skb); skb_shinfo(skb)->gso_size = tcp_skb_mss(skb); /* Our usage of tstamp should remain private */ skb->tstamp.tv64 = 0; /* Cleanup our debris for IP stacks */ /* Clear the tcb and use the ip layer */ memset(skb->cb, 0, max(sizeof(struct inet_skb_parm), sizeof(struct inet6_skb_parm))); //Packet to ip Continue adding layers ip Address; Function pointer actually points to ip_queue_ximit,This is also the actual call ip Layer function err = icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl); if (likely(err <= 0)) return err; /* congestion control */ tcp_enter_cwr(sk); return net_xmit_eval(err); }
It is not difficult to find out that the skb is finally put through the ip layer of the ip layer_ queue_ Ximit continues to construct ip packets. The code is as follows:
/* Note: skb->sk can be different from sk, in case of tunnels */ int ip_queue_xmit(struct sock *sk, struct sk_buff *skb, struct flowi *fl) { struct inet_sock *inet = inet_sk(sk); struct net *net = sock_net(sk); struct ip_options_rcu *inet_opt; struct flowi4 *fl4; struct rtable *rt; struct iphdr *iph; int res; /* Skip all of this if the packet is already routed, * f.e. by something like SCTP. */ rcu_read_lock(); inet_opt = rcu_dereference(inet->inet_opt); fl4 = &fl->u.ip4; /* Get route cache in skb */ rt = skb_rtable(skb); if (rt) goto packet_routed; /* Make sure we can route this packet. */ /* Check the route cache in the control block */ rt = (struct rtable *)__sk_dst_check(sk, 0); /* Cache expiration */ if (!rt) { __be32 daddr; /* Use correct destination address if we have options. */ //Finally see the purpose ip address daddr = inet->inet_daddr; if (inet_opt && inet_opt->opt.srr) daddr = inet_opt->opt.faddr; /* If this fails, retransmit mechanism of transport layer will * keep trying until route appears or the connection times * itself out. Rediscover routing cache */ rt = ip_route_output_ports(net, fl4, sk, daddr, inet->inet_saddr, inet->inet_dport, inet->inet_sport, sk->sk_protocol, RT_CONN_FLAGS(sk), sk->sk_bound_dev_if); if (IS_ERR(rt)) goto no_route; /* Set the routing cache of the control block */ sk_setup_caps(sk, &rt->dst); } /* Set route to skb */ skb_dst_set_noref(skb, &rt->dst); packet_routed: if (inet_opt && inet_opt->opt.is_strictroute && rt->rt_uses_gateway) goto no_route; /* OK, we know where to send it, allocate and build IP header. */ /*After finding the target, start to construct ip packets based on tcp packets*/ /*Add ip header to skb*/ skb_push(skb, sizeof(struct iphdr) + (inet_opt ? inet_opt->opt.optlen : 0)); skb_reset_network_header(skb); iph = ip_hdr(skb); *((__be16 *)iph) = htons((4 << 12) | (5 << 8) | (inet->tos & 0xff)); if (ip_dont_fragment(sk, &rt->dst) && !skb->ignore_df) iph->frag_off = htons(IP_DF); else iph->frag_off = 0; iph->ttl = ip_select_ttl(inet, &rt->dst); iph->protocol = sk->sk_protocol; ip_copy_addrs(iph, fl4); /* Transport layer set skb->h.foo itself. */ /* Construct ip options */ if (inet_opt && inet_opt->opt.optlen) { iph->ihl += inet_opt->opt.optlen >> 2; ip_options_build(skb, &inet_opt->opt, inet->inet_daddr, rt, 0); } /* Set id */ ip_select_ident_segs(net, skb, sk, skb_shinfo(skb)->gso_segs ?: 1); /* TODO : should we use skb->sk here instead of sk ? */ skb->priority = sk->sk_priority; skb->mark = sk->sk_mark; //send out ip package res = ip_local_out(net, sk, skb); rcu_read_unlock(); return res; no_route://No routing processing rcu_read_unlock(); IP_INC_STATS(net, IPSTATS_MIB_OUTNOROUTES); kfree_skb(skb); return -EHOSTUNREACH; }
The ip layer calls ip_local_out, continue to the following, and finally call this function to send data to the network through the network card:
/* Output packet to network from transport. */ static inline int dst_output(struct net *net, struct sock *sk, struct sk_buff *skb) { return skb_dst(skb)->output(net, sk, skb); }
Throughout the whole process: the core is constructed layer by layer, and data packets are created by adding packet headers!
(2) ack packet of server:
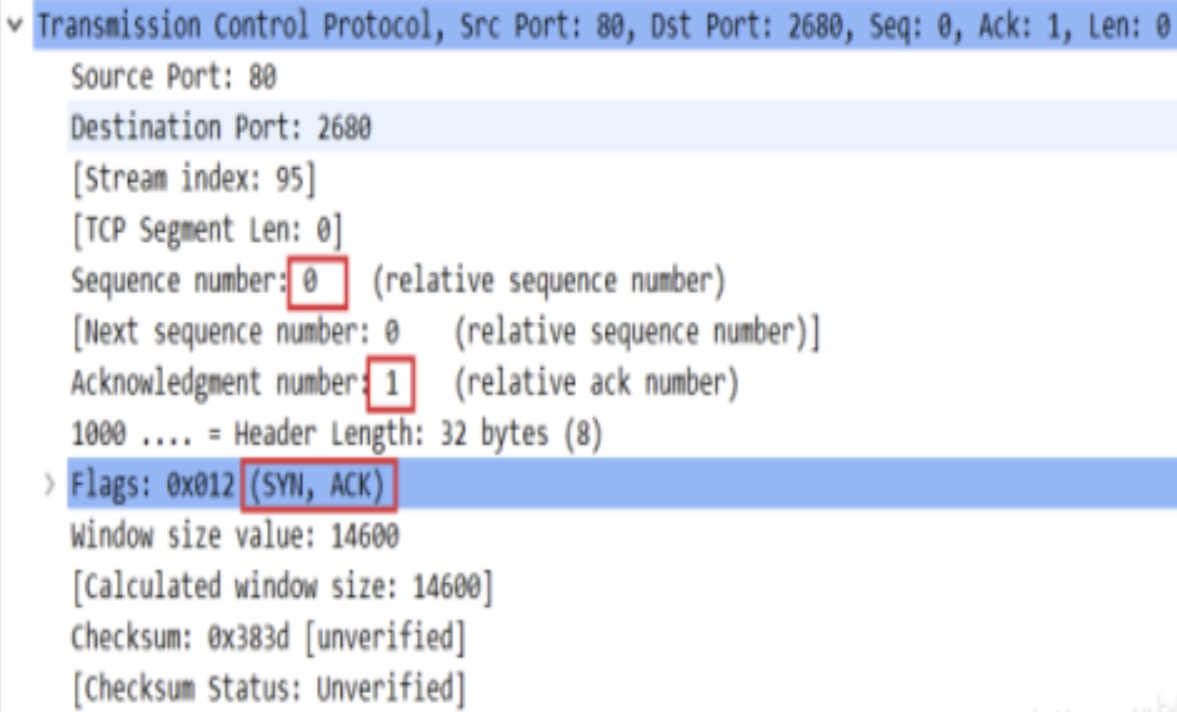
After receiving the SYN packet, the server needs to reply to the ACK packet. The contents of the packet are shown in the figure above; There is no difference between server and client in the process of constructing package. In essence, it adds package headers layer by layer (increasing the data and length of skb string)! The core functions are as follows:
/* * Send a SYN-ACK after having received a SYN. * This still operates on a request_sock only, not on a big * socket. */ static int tcp_v4_send_synack(const struct sock *sk, struct dst_entry *dst, struct flowi *fl, struct request_sock *req, struct tcp_fastopen_cookie *foc, enum tcp_synack_type synack_type) { const struct inet_request_sock *ireq = inet_rsk(req); struct flowi4 fl4; int err = -1; struct sk_buff *skb; /* First, grab a route. */ if (!dst && (dst = inet_csk_route_req(sk, &fl4, req)) == NULL) return -1; /*Construct the package of syn SCK and return skb*/ skb = tcp_make_synack(sk, dst, req, foc, synack_type); if (skb) { __tcp_v4_send_check(skb, ireq->ir_loc_addr, ireq->ir_rmt_addr); /*Add ip header and send*/ err = ip_build_and_send_pkt(skb, sk, ireq->ir_loc_addr, ireq->ir_rmt_addr, ireq->opt); err = net_xmit_eval(err); } return err; }
The functions of constructing and sending packets are tcp_make_synack and ip_build_and_send_pkt, the first function is to allocate skb and fill the tcp header. Here is one of the DDOS attack points:
/** * tcp_make_synack - Prepare a SYN-ACK. * sk: listener socket * dst: dst entry attached to the SYNACK * req: request_sock pointer * * Allocate one skb and build a SYNACK packet. * @dst is consumed : Caller should not use it again. Generate SYN-ACK packet */ struct sk_buff *tcp_make_synack(const struct sock *sk, struct dst_entry *dst, struct request_sock *req, struct tcp_fastopen_cookie *foc, enum tcp_synack_type synack_type) { struct inet_request_sock *ireq = inet_rsk(req); const struct tcp_sock *tp = tcp_sk(sk); struct tcp_md5sig_key *md5 = NULL; struct tcp_out_options opts; struct sk_buff *skb; int tcp_header_size; struct tcphdr *th; u16 user_mss; int mss; /*Allocate skb, which is one of the reasons why DDOS attacks take effect: If a client keeps changing the source ip and sending syn packets to the server, the server thinks there are many client Want to communicate with yourself and keep assigning skb as Preparing for the next communication may lead to memory depletion */ skb = alloc_skb(MAX_TCP_HEADER, GFP_ATOMIC); if (unlikely(!skb)) { dst_release(dst); return NULL; } /* Reserve space for headers. */ skb_reserve(skb, MAX_TCP_HEADER); switch (synack_type) { case TCP_SYNACK_NORMAL: skb_set_owner_w(skb, req_to_sk(req)); break; case TCP_SYNACK_COOKIE: /* Under synflood, we do not attach skb to a socket, * to avoid false sharing. */ break; case TCP_SYNACK_FASTOPEN: /* sk is a const pointer, because we want to express multiple * cpu might call us concurrently. * sk->sk_wmem_alloc in an atomic, we can promote to rw. */ skb_set_owner_w(skb, (struct sock *)sk); break; } skb_dst_set(skb, dst); mss = dst_metric_advmss(dst); user_mss = READ_ONCE(tp->rx_opt.user_mss); if (user_mss && user_mss < mss) mss = user_mss; memset(&opts, 0, sizeof(opts)); #ifdef CONFIG_SYN_COOKIES if (unlikely(req->cookie_ts)) skb->skb_mstamp.stamp_jiffies = cookie_init_timestamp(req); else #endif skb_mstamp_get(&skb->skb_mstamp); #ifdef CONFIG_TCP_MD5SIG rcu_read_lock(); md5 = tcp_rsk(req)->af_specific->req_md5_lookup(sk, req_to_sk(req)); #endif skb_set_hash(skb, tcp_rsk(req)->txhash, PKT_HASH_TYPE_L4); tcp_header_size = tcp_synack_options(req, mss, skb, &opts, md5, foc) + sizeof(*th); //Start filling tcp Head skb_push(skb, tcp_header_size); skb_reset_transport_header(skb); th = (struct tcphdr *)skb->data; memset(th, 0, sizeof(struct tcphdr)); th->syn = 1; th->ack = 1; tcp_ecn_make_synack(req, th); th->source = htons(ireq->ir_num); th->dest = ireq->ir_rmt_port; /* Setting of flags are superfluous here for callers (and ECE is * not even correctly set) */ tcp_init_nondata_skb(skb, tcp_rsk(req)->snt_isn, TCPHDR_SYN | TCPHDR_ACK); th->seq = htonl(TCP_SKB_CB(skb)->seq); /* XXX data is queued and acked as is. No buffer/window check */ th->ack_seq = htonl(tcp_rsk(req)->rcv_nxt); /* RFC1323: The window in SYN & SYN/ACK segments is never scaled. */ th->window = htons(min(req->rsk_rcv_wnd, 65535U)); tcp_options_write((__be32 *)(th + 1), NULL, &opts); th->doff = (tcp_header_size >> 2); __TCP_INC_STATS(sock_net(sk), TCP_MIB_OUTSEGS); #ifdef CONFIG_TCP_MD5SIG /* Okay, we have all we need - do the md5 hash if needed */ if (md5) tcp_rsk(req)->af_specific->calc_md5_hash(opts.hash_location, md5, req_to_sk(req), skb); rcu_read_unlock(); #endif /* Do not fool tcpdump (if any), clean our debris */ skb->tstamp.tv64 = 0; return skb; } EXPORT_SYMBOL(tcp_make_synack);
Finally, add ip header in skb and call ip_local_out sends the data packet. The code logic is very simple:
/* * Add an ip header to a skbuff and send it out. * */ int ip_build_and_send_pkt(struct sk_buff *skb, const struct sock *sk, __be32 saddr, __be32 daddr, struct ip_options_rcu *opt) { struct inet_sock *inet = inet_sk(sk); struct rtable *rt = skb_rtable(skb); struct net *net = sock_net(sk); struct iphdr *iph; /* Build the IP header. Construct ip header*/ skb_push(skb, sizeof(struct iphdr) + (opt ? opt->opt.optlen : 0)); skb_reset_network_header(skb); iph = ip_hdr(skb); iph->version = 4; iph->ihl = 5; iph->tos = inet->tos; iph->ttl = ip_select_ttl(inet, &rt->dst); iph->daddr = (opt && opt->opt.srr ? opt->opt.faddr : daddr); iph->saddr = saddr; iph->protocol = sk->sk_protocol; if (ip_dont_fragment(sk, &rt->dst)) { iph->frag_off = htons(IP_DF); iph->id = 0; } else { iph->frag_off = 0; __ip_select_ident(net, iph, 1); } if (opt && opt->opt.optlen) { iph->ihl += opt->opt.optlen>>2; ip_options_build(skb, &opt->opt, daddr, rt, 0); } skb->priority = sk->sk_priority; skb->mark = sk->sk_mark; /* Send it out. */ return ip_local_out(net, skb->sk, skb); }
The server sends SYN-ACK!
(3) ack packet of client
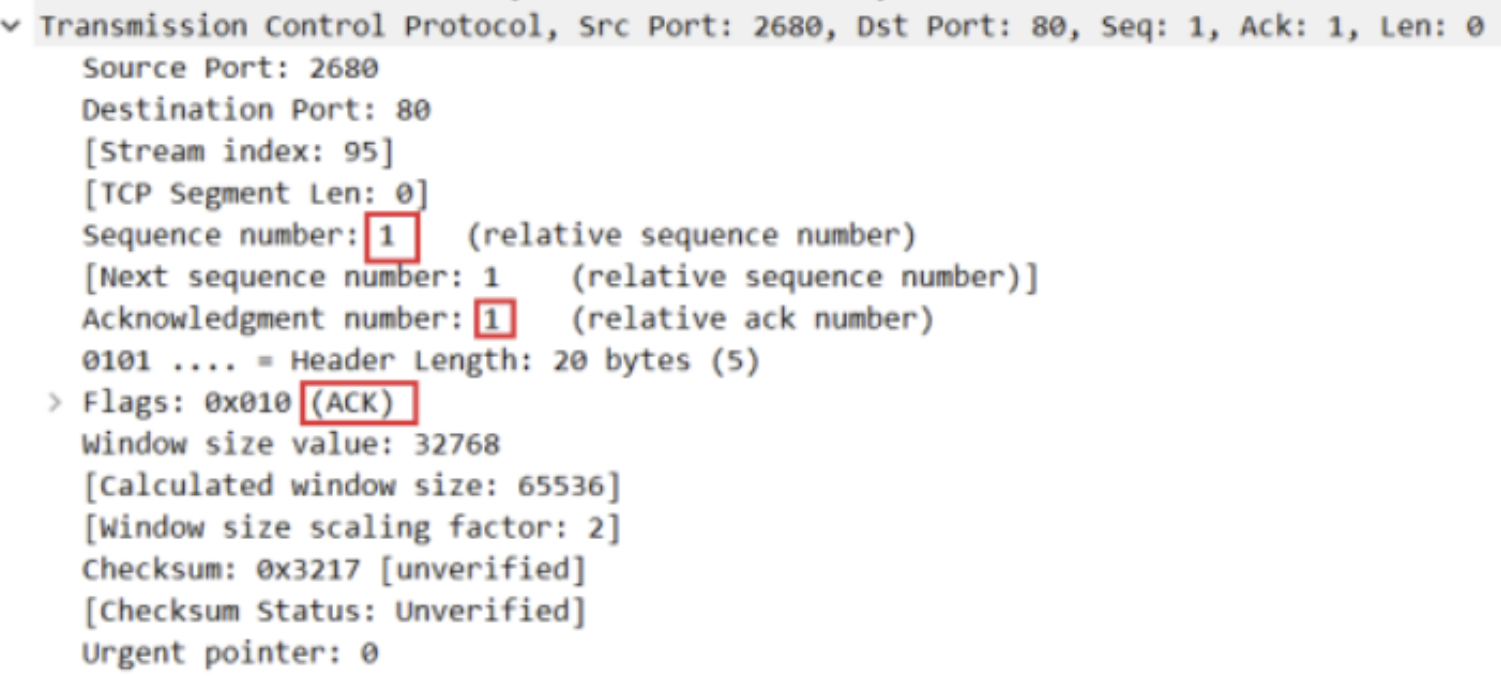
The ack is sent from the client to the server. It is still a string in essence. Just construct this string and send it. Therefore, the core is to call tcp_transmit_skb function, the whole function code is as follows:
/* This routine sends an ack and also updates the window. */ void tcp_send_ack(struct sock *sk) { struct sk_buff *buff; /* If we have been reset, we may not send again. */ /* If the current socket has been closed, return directly. */ if (sk->sk_state == TCP_CLOSE) return; /* congestion avoidance */ tcp_ca_event(sk, CA_EVENT_NON_DELAYED_ACK); /* We are not putting this on the write queue, so * tcp_transmit_skb() will set the ownership to this * sock. */ buff = alloc_skb(MAX_TCP_HEADER, sk_gfp_mask(sk, GFP_ATOMIC | __GFP_NOWARN)); if (unlikely(!buff)) { inet_csk_schedule_ack(sk); inet_csk(sk)->icsk_ack.ato = TCP_ATO_MIN; inet_csk_reset_xmit_timer(sk, ICSK_TIME_DACK, TCP_DELACK_MAX, TCP_RTO_MAX); return; } /* Reserve space for headers and prepare control bits. */ /* Initialize ACK package */ skb_reserve(buff, MAX_TCP_HEADER); tcp_init_nondata_skb(buff, tcp_acceptable_seq(sk), TCPHDR_ACK); /* We do not want pure acks influencing TCP Small Queues or fq/pacing * too much. * SKB_TRUESIZE(max(1 .. 66, MAX_TCP_HEADER)) is unfortunately ~784 * We also avoid tcp_wfree() overhead (cache line miss accessing * tp->tsq_flags) by using regular sock_wfree() */ skb_set_tcp_pure_ack(buff); /* Send it off, this clears delayed acks for us. */ /* Add timestamp and send ACK packet */ skb_mstamp_get(&buff->skb_mstamp); //Or is it constructed and sent from here ack Bao, old actor! tcp_transmit_skb(sk, buff, 0, (__force gfp_t)0); } EXPORT_SYMBOL_GPL(tcp_send_ack);
Summary:
1. The network card is only responsible for sending and receiving data simply and rudely (in other words, string). The protocol needs to be considered by the operating system. The hardware of the network card is not care!
2,socket,sock,sk_ The ultimate purpose of buff, tcphdr and other structures is to construct data packets at different levels of the protocol (in other words, different strings. In order to facilitate understanding and maintenance and avoid the problem of grasping by eyebrows and beard, different positions of strings are abstracted into different attributes or identifiers); Therefore, different operating systems must have different structures and methods to generate and parse data packets, as long as the sent string conforms to the format specified in the protocol!
3. The so-called connection establishment at the logical level: after both parties determine to communicate with each other through SYN and ACK, they will allocate skb to store the received and sent data! One of DDOS attacks is to find a way to make the server constantly allocate skb to receive the coming data! However, the memory of the server is limited. Allocating a large amount of skb will eventually lead to the depletion of memory!
reference resources:
1, https://network.51cto.com/article/648928.html?mobile tcp triple handshake connect
2, https://www.leviathan.vip/2018/08/09/Linux%E5%86%85%E6%A0%B8%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90-TCP%E5%8D%8F%E8%AE%AE-1 / tcp protocol analysis
3, http://45.76.5.96/opensource/tcp/tcp.pdf linux tcp source code analysis