Network data collection refers to the automatic collection of data on the Internet through programs. The program used to collect data is also called Web crawler. This paper mainly records some common modules of online data collection and their simple related operations.
⚪ urllib module and its request sub module
It is an indispensable data collection module in Python. In Python 3 In X, the urllib module has urllib request,urllib.parse,urllib.error,urllib. The robot parser has four sub modules.
Official website description document reference → https://docs.python.org/zh-cn/3/library/urllib.html

Among them, urlib Request is the most important module, which is used to open and access the data on the URL. It includes urlopen(), urlretrieve and other functions and request and other classes.
Network data collection first sends a request to the network server through the URL, and then parses the returned data.
urllib. The urlopen function in the request module is used to open the URLs of HTTP, HTTPS and FTP protocols and receive the returned URL resources. The syntax is as follows:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
The parameter URL can be a string (URL address) or a Request object; Parameter data is used when submitting URL in post mode; Timeout is the timeout setting; The parameters starting with ca are related to authentication and are not commonly used.
The function returns the Response object. The Response object is a file like object that can be operated like a file object, such as read(). In addition, the Response object has several other methods, as shown in the following examples:
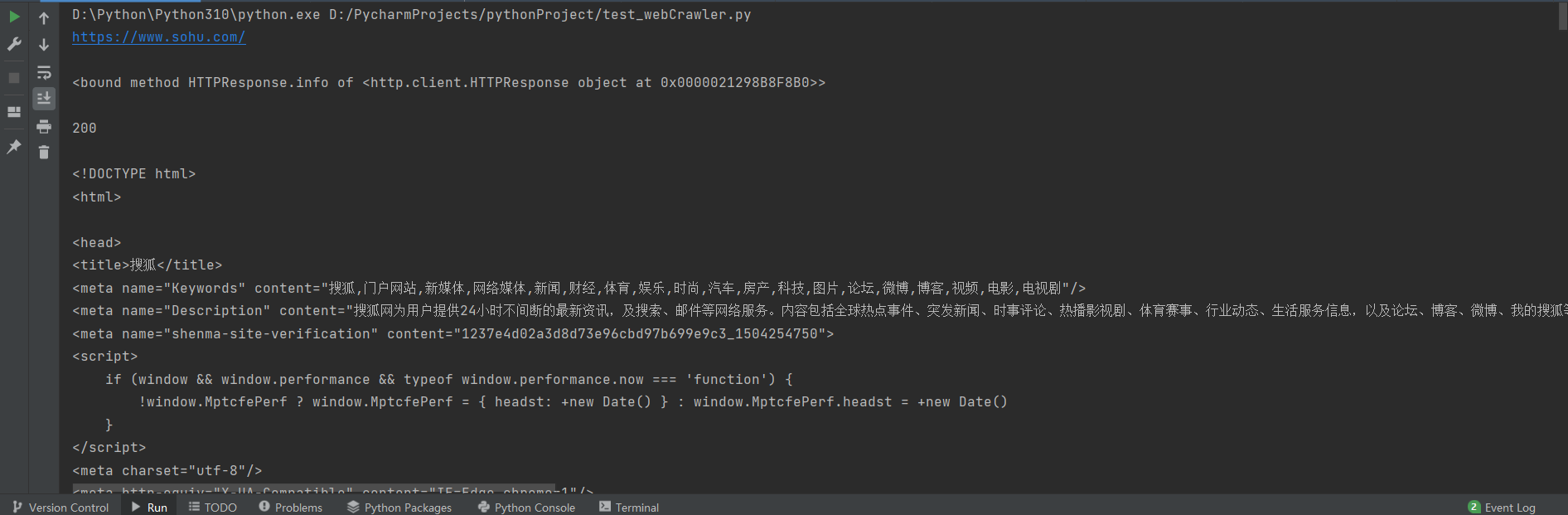
'''request Get basic information of the website'''
with request.urlopen('http://www.sohu.com') as f: # open the URL of the network protocol and return the Response object
print(f.geturl(), "\n") # Return the URL information of response, which is often used for URL redirection
print(f.info, "\n") # Return basic information of response
print(f.getcode(), "\n") # Return the status code of response, (200 indicates that the web page is returned successfully, 404 indicates that the requested web page does not exist, and 503 indicates that the server is temporarily unavailable)
data = f.read() # Read the response class file object
print(data.decode('utf-8')) # Decode and output the read information
The output is as follows:
The data file on the Internet can send a request to the network server through the URL. If the request is successful, the data can be downloaded. urllib. The retrieve function in the request module is used to download the file with the specified URL address. The syntax is as follows:
retrieve(url, filename-None, reporthook=None)
URL is the specified URL address; filename is the saved path and file name. If it is the default, the file name will be randomly generated and saved to the temporary directory; reporthook is used to call a function that displays the download progress.
Examples are as follows:
'''Network data file download, retrieve function''' # Download html file of web page url = "http://baidu.com" request.urlretrieve(url, "D:/tmp/baidu.html") # Download pictures, videos and other files as long as you find the corresponding website and write the file suffix of the saved path as the corresponding one url = "https://gimg3.baidu.com/***/*****.jpeg" request.urlretrieve(url, "D:/tmp/baidup.jpg")
⚪ requests module
Requests is a third-party module written in Python, which is good at handling complex HTTP requests, cookie s, headers (response headers and request headers), etc.
Description document reference → (English) https://docs.python-requests.org/en/master/
(Chinese) https://docs.python-requests.org/zh_CN/latest/user/quickstart.html
👆 The description document is very concise and easy to understand. Here is a simple example:
'''requests Module to obtain website information'''
import requests
user_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' \
'Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.12151 SLBChan/30' # User agent for request header
headers = {'User-Agent': user_agent} # Set request header parameters
response = requests.get('https://www.baidu.com/', headers=headers)
print(response.status_code) # Return status code
print(response.headers) # The response header returns a dictionary
print(response.encoding) # The encoding type of the response content obtained according to the response header information
print(response.text) # Response content in string form
print(response.content) # Response content in binary form
print(response.cookies) # Get all cookie information
⚪ Beautiful soup package
get ready:
Beautiful soup is a Python package commonly used in web page data parsing. It uses the existing HTML/XML parsers (HTML parser, lxml, html5lib, etc.) to parse HTML or XML documents. For details, please refer to its instruction document - ① https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
②https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
You can use pip install bs4 on the command line to download and install the latest version of the beautiful soup package.
Beautiful Soup supports HTML parsers in Python standard library and some third-party parsers, one of which is lxml. You can also download and install this interpreter through pip install lxml.
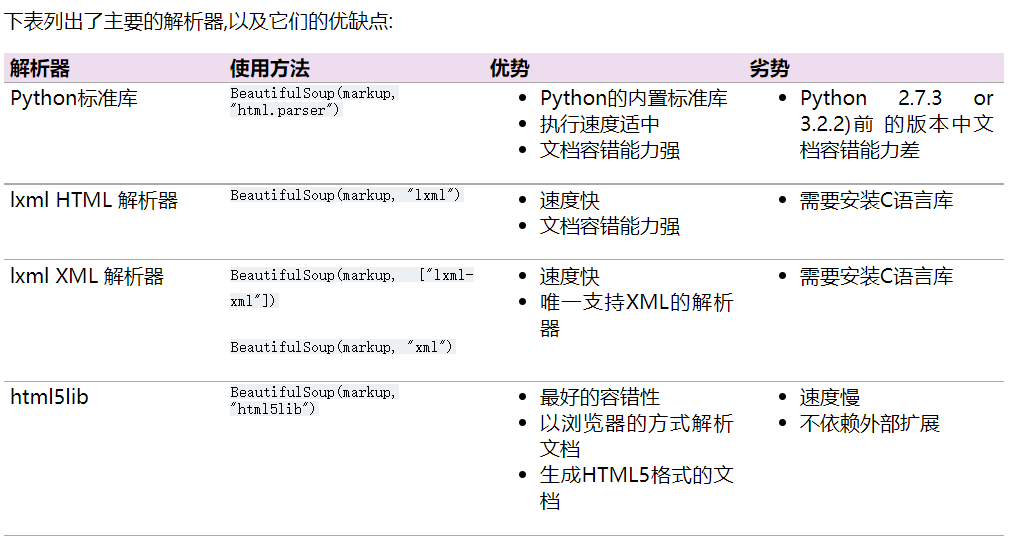
use:
Pass a string or document of HTML code into the construction method of BeautifulSoup, you can get an object of BeautifulSoup, and then use its relevant methods to carry out relevant operations.
Example:
html_doc = request.urlopen('http://www.baidu.com ') # get the object of an html document
soup = BeautifulSoup(html_doc, "html.parser") # Use the interpreter HTML in Python standard library Parse html_doc object
print(soup.prettify()) # Output in standard format
print(soup.html.head.title) # Return to the title tag, and the output is: < title > Baidu. You will know < / Title >
print(soup.html.body.div) # Return div tag
Find of BeautifulSoup object_ All() [find()] method is used to find all qualified elements under the current node. Its syntax is: find_all( name , attrs , recursive , string , **kwargs )
Example:
soup.find_all("a") # Returns a list of elements with tag name a
soup.find_all("p", {"class": ["text-color", "lh"]}) # Returns the contents of the P tag with class values of "text color" and "lh"
Using find_ Get of tag object returned by all() function_ The text method will return the string of the label content. The attrs attribute of the label object returns the dictionary of all attributes. The corresponding attribute value can be returned through the key of the dictionary.
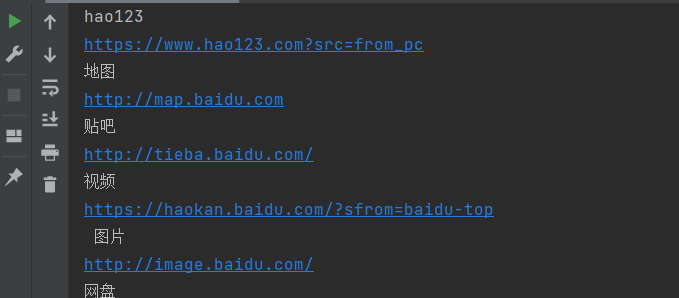
Example (get the hyperlink address on Baidu website):
links = soup.find_all("a")
for link in links: # Output the attribute value corresponding to the label content one by one through a loop
print(link.get_text())
print(link.attrs["href"])
The output results are as follows:
⚪ You get package
The function of you get: download pictures, audio and video from popular websites, such as YouTube, Youku, bilibili bili, and more.
Use you get to download videos and other resources on the cmd interface. Please refer to these two blog posts ① https://blog.csdn.net/qq_45176548/article/details/113379829
②https://www.cnblogs.com/mq0036/p/14917172.html
Enter the command (- h) to get the help manual of you get 👆:
you-get -h
Enter the command to download the video directly: you get https://www.bilibili.com/video/ ... (web address of video storage)
Enter the command (- i) to view the video details: you get - I https://www.bilibili.com/video/ ... (web address of video storage)
Enter the command (- o) to download the video to the specified path (Note: - O set the name of the downloaded file):
you-get -o D:/tmp https://www.bilibili.com/video/ ... (web address of video storage)
You can also write python code to execute:
import sys import you_get cookies = "cookies.sqlite" # You need to get cookie s when downloading member videos path = "D:/tmp/video" # Save path after download url = "https://www.bilibili.com/... "# download video URL sys.argv = ["you-get", "--playlist", "-o", path, url] # Pass the list into the command line for execution (add "-- playlist" to download multiple videos at one time) # Here, sys Argv is a list object that can contain command line arguments passed to Python scripts. you_get.main()
Finish 😀!