This article briefly introduces Python Natural Language Processing (NLP), which uses Python's NLTK library. NLTK is Python's natural language processing toolkit. In the field of NLP, a Python library is most commonly used.
What is NLP?
In short, natural language processing (NLP) is the development of applications or services that understand human languages.
This paper discusses some practical examples of natural language processing (NLP), such as speech recognition, speech translation, understanding complete sentences, understanding synonyms of matching words, and generating grammatically correct and complete sentences and paragraphs.
This is not everything NLP can do.
NLP implementation
Search engines: Google, Yahoo, etc. Google search engine knows you're a technician, so it displays technology-related results.
Social networking push: Facebook News Feed, for example. If the News Feed algorithm knows that your interest is natural language processing, it will display related advertisements and posts.
Voice Engine: For example, Apple's Siri.
Spam filtering: e.g. Google Spam Filter. Unlike ordinary spam filtering, it judges whether spam is spam by understanding the deep meaning of its content.
NLP Library
Here are some open source natural language processing libraries (NLPs):
- Natural language toolkit (NLTK);
- Apache OpenNLP;
- Stanford NLP suite;
- Gate NLP library
Natural Language Toolkit (NLTK) is the most popular natural language processing library (NLP), which is written in Python and has very strong community support behind it.
NLTK is also easy to get started. In fact, it is the simplest natural language processing (NLP) library.
In this NLP tutorial, we will use the Python NLTK library.
Install NLTK
If you are using Windows/Linux/Mac, you can install NLTK using pip:
pip install nltk
Open the python terminal and import NLTK to check that NLTK is installed correctly:
import mltk
If everything goes well, this means that you have successfully installed the NLTK library. For the first time, NLTK is installed. You need to install the NLTK extension package by running the following code:
import nltk
nltk.download()
This will pop up the NLTK download window to select which packages to install: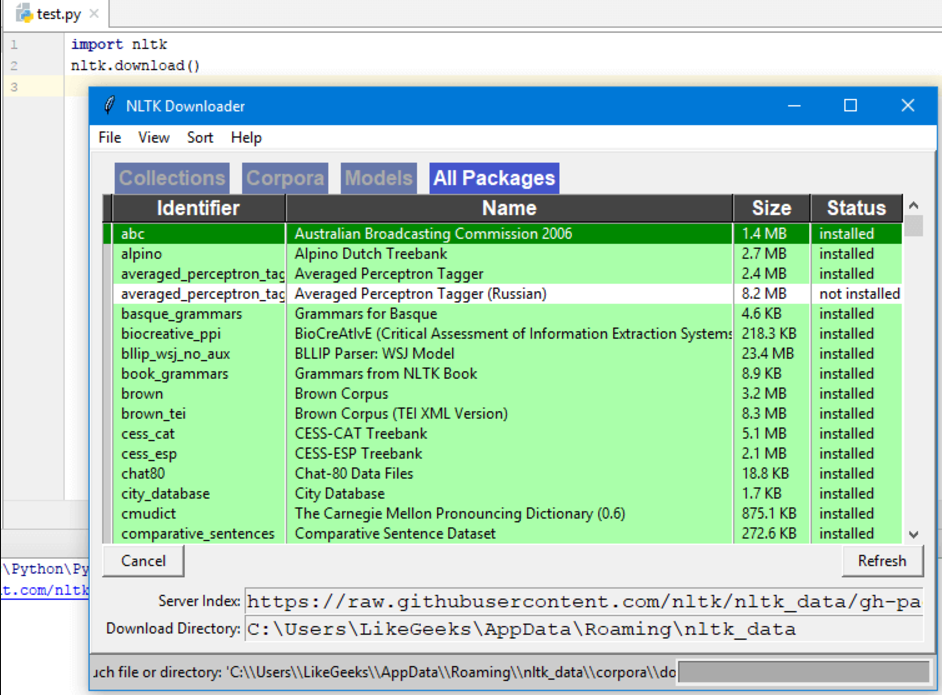
You can install all packages, because they are small in size, so there is no problem.
Use Python Tokenize text
First, we will grab the content of a web page, and then analyze the text to understand the content of the page.
We will use urllib module to grab web pages:
import urllib.request
response = urllib.request.urlopen('http://php.net/')
html = response.read()
print (html)
As you can see from the printed results, the results contain many HTML tags that need to be cleaned up.
Then the Beautiful Soup module cleans the text:
from bs4 import BeautifulSoup
import urllib.request
response = urllib.request.urlopen('http://php.net/')
html = response.read()
soup = BeautifulSoup(html,"html5lib")
# This requires installing the HTML 5lIb module
text = soup.get_text(strip=True)
print (text)
Now we get a clean text from the crawled page.
Next, convert the text to tokens, like this:
from bs4 import BeautifulSoup
import urllib.request
response = urllib.request.urlopen('http://php.net/')
html = response.read()
soup = BeautifulSoup(html,"html5lib")
text = soup.get_text(strip=True)
tokens = [t for t in text.split()]
print (tokens)
Statistical word frequency
text has been processed, and now Python NLTK is used to calculate the frequency distribution of token.
This can be achieved by calling the FreqDist() method in NLTK:
from bs4 import BeautifulSoup
import urllib.request
import nltk
response = urllib.request.urlopen('http://php.net/')
html = response.read()
soup = BeautifulSoup(html,"html5lib")
text = soup.get_text(strip=True)
tokens = [t for t in text.split()]
freq = nltk.FreqDist(tokens)
for key,val in freq.items():
print (str(key) + ':' + str(val))
If you search for the output, you can see that the most common token is PHP.
You can call plot function to make frequency distribution map:
freq.plot(20, cumulative=False)
# You need to install the matplotlib Library
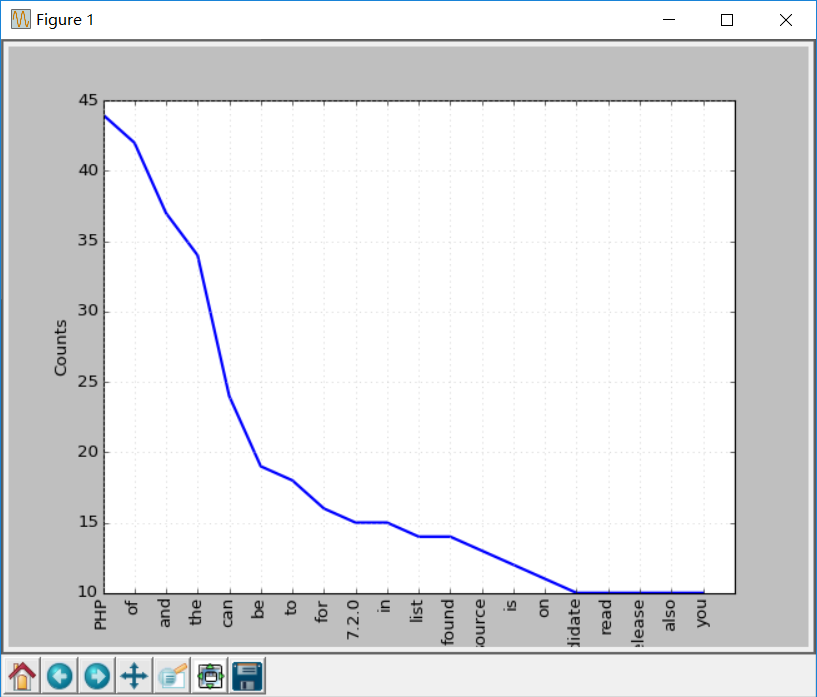
Here are the words above. For example, of,a,an and so on, these words belong to stop words.
Generally speaking, stop words should be deleted to prevent them from influencing the results.
Dealing with Discontinued Words
NLTK comes with a list of stop words in many languages, if you get English stop words:
from nltk.corpus import stopwords
stopwords.words('english')
Now, modify the code to clear some invalid token before drawing:
clean_tokens = list()
sr = stopwords.words('english')
for token in tokens:
if token not in sr:
clean_tokens.append(token)
The final code should be as follows:
from bs4 import BeautifulSoup
import urllib.request
import nltk
from nltk.corpus import stopwords
response = urllib.request.urlopen('http://php.net/')
html = response.read()
soup = BeautifulSoup(html,"html5lib")
text = soup.get_text(strip=True)
tokens = [t for t in text.split()]
clean_tokens = list()
sr = stopwords.words('english')
for token in tokens:
if not token in sr:
clean_tokens.append(token)
freq = nltk.FreqDist(clean_tokens)
for key,val in freq.items():
print (str(key) + ':' + str(val))
Now do the word frequency statistics again, the effect will be better than before, because stop words are removed:
freq.plot(20,cumulative=False)
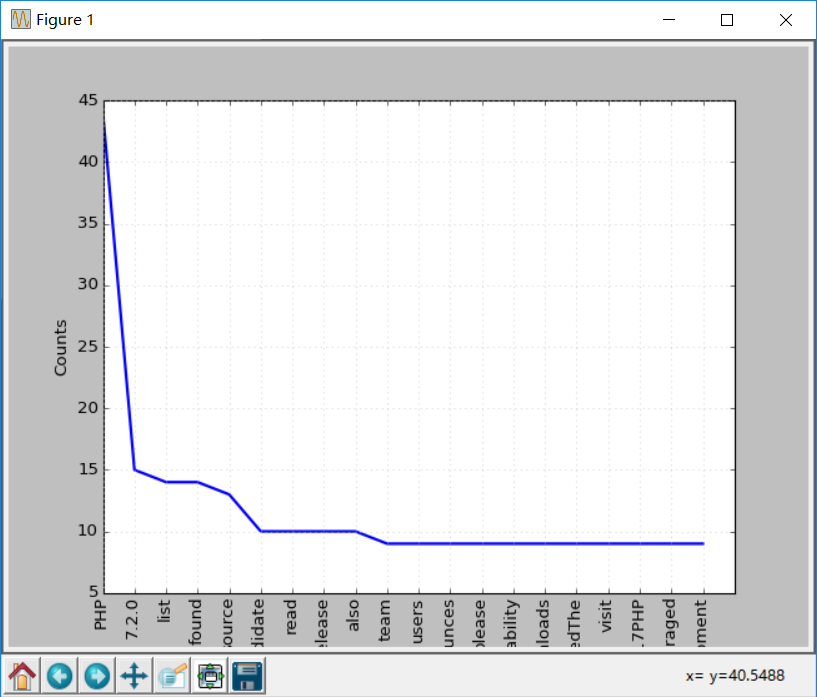
Using NLTK Tokenize text
In the past, we used split to split text into tokens, but now we use NLTK to Tokenize text.
Text can't be processed without Tokenize, so it's very important to Tokenize text. The token ization process means splitting large parts into widgets.
You can turn the paragraph tokenize into a sentence, the sentence tokenize into a single word, and NLTK provides the sentence tokenizer and the word tokenizer, respectively.
If there is such a passage:
Hello Adam, how are you? I hope everything is going well. Today is a good day, see you dude.
Use the sentence tokenizer to make the text tokenize into sentences:
from nltk.tokenize import sent_tokenize
mytext = "Hello Adam, how are you? I hope everything is going well. Today is a good day, see you dude."
print(sent_tokenize(mytext))
The output is as follows:
['Hello Adam, how are you?', 'I hope everything is going well.', 'Today is a good day, see you dude.']
You might think that this is too simple. You don't need to use NLTK's tokenizer. Just use regular expressions to split sentences, because every sentence has punctuation and blanks.
Then look at the following text:
Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude.
So if punctuation is used, Hello Mr s will be considered a sentence, if NLTK:
from nltk.tokenize import sent_tokenize
mytext = "Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude."
print(sent_tokenize(mytext))
The output is as follows:
['Hello Mr. Adam, how are you?', 'I hope everything is going well.', 'Today is a good day, see you dude.']
That's the right split.
Next try the word tokenizer:
from nltk.tokenize import word_tokenize
mytext = "Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude."
print(word_tokenize(mytext))
The output is as follows:
['Hello', 'Mr.', 'Adam', ',', 'how', 'are', 'you', '?', 'I', 'hope', 'everything', 'is', 'going', 'well', '.', 'Today', 'is', 'a', 'good', 'day', ',', 'see', 'you', 'dude', '.']
The word Mr. has not been separated. NLTK uses the punkt Sentence Tokenizer of the punkt module, which is part of NLTK.tokenize. And this tokenizer is trained to work in many languages.
Non-English Tokenize
Tokenize can specify a language:
from nltk.tokenize import sent_tokenize
mytext = "Bonjour M. Adam, comment allez-vous? J'espère que tout va bien. Aujourd'hui est un bon jour."
print(sent_tokenize(mytext,"french"))
The output results are as follows:
['Bonjour M. Adam, comment allez-vous?', "J'espère que tout va bien.", "Aujourd'hui est un bon jour."]
Synonym processing
Using nltk.download() to install the interface, one of the packages is WordNet.
WordNet is a database for natural language processing. It includes some synonyms and some short definitions.
You can get definitions and examples of a given word in this way:
from nltk.corpus import wordnet
syn = wordnet.synsets("pain")
print(syn[0].definition())
print(syn[0].examples())
The output is:
a symptom of some physical hurt or disorder
['the patient developed severe pain and distension']
WordNet contains many definitions:
from nltk.corpus import wordnet
syn = wordnet.synsets("NLP")
print(syn[0].definition())
syn = wordnet.synsets("Python")
print(syn[0].definition())
The results are as follows:
the branch of information science that deals with natural language information
large Old World boas
WordNet can be used to get synonyms like this:
from nltk.corpus import wordnet
synonyms = []
for syn in wordnet.synsets('Computer'):
for lemma in syn.lemmas():
synonyms.append(lemma.name())
print(synonyms)
Output:
['computer', 'computing_machine', 'computing_device', 'data_processor', 'electronic_computer', 'information_processing_system', 'calculator', 'reckoner', 'figurer', 'estimator', 'computer']
Antonym Processing
Antonyms can also be obtained in the same way:
from nltk.corpus import wordnet
antonyms = []
for syn in wordnet.synsets("small"):
for l in syn.lemmas():
if l.antonyms():
antonyms.append(l.antonyms()[0].name())
print(antonyms)
Output:
['large', 'big', 'big']
stemming
In language morphology and information retrieval, stem extraction is a process of removing affixes to get roots, such as working stem for work.
Search engines use this technology when indexing pages, so many people write different versions of the same word.
There are many algorithms to avoid this situation, the most common one is the Porter stemming algorithm. NLTK has a class named PorterStemmer, which is the implementation of this algorithm:
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
print(stemmer.stem('working'))
print(stemmer.stem('worked'))
The output is:
work work
There are other stemming algorithms, such as Lancaster stemming algorithm.
Non-English Stem Extraction
In addition to English, Snowball Stemmer supports 13 languages.
Supported languages:
from nltk.stem import SnowballStemmer
print(SnowballStemmer.languages)
'danish', 'dutch', 'english', 'finnish', 'french', 'german', 'hungarian', 'italian', 'norwegian', 'porter', 'portuguese', 'romanian', 'russian', 'spanish', 'swedish'
You can use the step function of the SnowballStemmer class to extract non-English words like this:
from nltk.stem import SnowballStemmer
french_stemmer = SnowballStemmer('french')
print(french_stemmer.stem("French word"))
Word variant reduction
Word variant reduction is similar to stemming, but the difference is that the result of variant reduction is a real word. Unlike stem, when you try to extract certain words, it produces similar words:
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
print(stemmer.stem('increases'))
Result:
increas
Now, if NLTK's WordNet is used to restore variants of the same word, it is the correct result:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('increases'))
Result:
increase
The result may be a synonym or a different word with the same meaning.
Sometimes when a word is reverted as a variant, it always gets the same word.
This is because the default part of the language is nouns. To get a verb, you can specify as follows:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('playing', pos="v"))
Result:
play
In fact, this is also a good way of text compression, and the final text is only 50% to 60% of the original.
The result can also be verb (v), NOUN (n), adjective (a) or adverb (r):
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('playing', pos="v"))
print(lemmatizer.lemmatize('playing', pos="n"))
print(lemmatizer.lemmatize('playing', pos="a"))
print(lemmatizer.lemmatize('playing', pos="r"))
Output:
play playing playing playing
The Difference between Stem and Variation
Look at the following examples:
from nltk.stem import WordNetLemmatizer
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
print(stemmer.stem('stones'))
print(stemmer.stem('speaking'))
print(stemmer.stem('bedroom'))
print(stemmer.stem('jokes'))
print(stemmer.stem('lisa'))
print(stemmer.stem('purple'))
print('----------------------')
print(lemmatizer.lemmatize('stones'))
print(lemmatizer.lemmatize('speaking'))
print(lemmatizer.lemmatize('bedroom'))
print(lemmatizer.lemmatize('jokes'))
print(lemmatizer.lemmatize('lisa'))
print(lemmatizer.lemmatize('purple'))
Output:
stone speak bedroom joke lisa purpl --------------------- stone speaking bedroom joke lisa purple
Stem extraction does not take context into account, which is why stem extraction is faster and less accurate than variant reduction.
Personally, variant reduction is better than stem extraction. The variant of a word returns a real word, even if it is not the same word, but also a synonym, but at least it is a real word.
If you only care about speed, not accuracy, then you can choose stem extraction.
All the steps discussed in this NLP tutorial are just text preprocessing. In future articles, Python NLTK will be used to implement text analysis.
I've tried to make the article easy to understand. I hope it will help you.
This article was first published in http://www.spiderpy.cn/blog/detail/30 Reprinted please note!