Introduction: NoSql, non relational database; Single thread + multiplex IO multiplexing technology
Atomicity of Redis
Because redis is single threaded, the execution of all single commands is atomic
Applicable scenarios:
- Highly concurrent reading and writing of data
- Massive data reading and writing
- For high data scalability
Key points: redis and Memcache
- Redis
- It covers almost most functions of Memcached
- The data is in memory and supports persistence. It is mainly used for backup and recovery
- In addition to supporting the simple key value mode, it also supports the storage of a variety of data structures, such as list, set, hash, zset, etc.
- Generally, it is a database that is secondary persistent as a cache database
- Memcache
- Early NoSql database
- The data is in memory and is generally not persistent
- It supports simple key value mode and single type
- Generally, it is a database that is secondary persistent as a cache database
1. Profile common configuration
- Bind: default bind = 127.0 0.1 only accepts local access. If you want remote access, you need to note it out
- Protected mode: the default is yes. When the bind ip switch is not set and there is no password, only the local response is accepted. It needs to be changed to no for remote access
- Port: port. The default value is 6379, and there is no need to change it
- Daemon: whether it is a background process. If it is set to yes, it can be started in the background
- requirepass: setting requires a password, followed by the password you want to set
2. redis startup and shutdown
First, back up redis Conf to / myredis directory, CP / opt / redis-6.2 6/redis.conf /myredis
#Start with redis server redis-server/myredis/redis.conf #Accessing redis cli with client redis-cli #Multi port boot redis-cli -p6379 #Login password verification auth [password] #After the password verification is completed, the test can ping and respond to the pong successfully ping #Single instance shutdown redis-cli shutdown #Multi instance shutdown, specify port z redis-cli -p 6379 shutdown
3. Five common data types
Basic commands:
#View all keys in the current library (matching: keys *1) keys * #Determine whether a key exists exists key #Check the type of your key type key #Delete the specified key data del key #Select non blocking deletion according to value (only delete keys from the keyspace metadata, and the real deletion will be performed in subsequent asynchronous operations). unlink key #10 seconds: set the expiration time for the given key expire key 10 #Check how many seconds are left to expire, - 1 means it will never expire, - 2 means it has expired ttl key select Command switch database dbsize View the current database key Number of flushdb Empty current library flushall Kill all libraries
3.1. String
The string type is binary safe. This means that the Redis string can contain any data. For example, jpg images or serialized objects.
String type is the most basic data type of Redis. The string value in a Redis can be 512M at most
3.1. 1 common commands
set <key><value> #Add key value pair get <key> #Query corresponding key value append <key><value> #Append the given < value > to the end of the original value strlen <key> #Gets the length of the value setnx <key><value> #The key value can only be set when the key does not exist incr <key> #Increase the digital value stored in the key by 1; You can only operate on numeric values. If it is blank, the new increment is 1 decr <key> #Subtract 1 from the numeric value stored in the key; You can only operate on numeric values. If it is blank, the new increment is - 1 incrby/decrby <key><step> #Increase or decrease the numeric value stored in the key. Custom step size. mset <key1><value1><key2><value2> #Set one or more key value pairs at the same time mget <key1><key2><key3> #Get one or more value s at the same time msetnx <key1><value1><key2><value2> #Set one or more key value pairs at the same time if and only if all given keys do not exist. getrange <key><Starting position><End position> #Obtain the range of values, similar to substring in java, pre package and post package setrange <key><Starting position><value> #Overwrite the string value stored in < key > with < value >, starting from < start position > (the index starts from 0). setex <key><Expiration time><value> #Set the expiration time in seconds while setting the key value. getset <key><value> #Replace the old with the new, set the new value and obtain the old value at the same time.
Atomicity, if one fails, all fail
3.1. 2 data structure
The data structure of String is Simple Dynamic String (abbreviated as SDS). It is a String that can be modified. Its internal structure is similar to the ArrayList of Java. It uses pre allocation of redundant space to reduce frequent memory allocation

Capacity expansion mechanism:
As shown in the figure, the space capacity actually allocated internally for the current string is generally higher than the actual string length len.
When the string length is less than 1M, the expansion is to double the existing space;
If it exceeds 1M, only 1M more space will be expanded at one time.
Note that the maximum length of the string is 512M.
3.2 List
Redis list is a simple string list, sorted by insertion order.
You can add an element to the head (left) or tail (right) of the list.
3.2. 1 common commands
lpush/rpush <key><value1><value2><value3> #Insert one or more values from left / right. lpop/rpop <key> #Spit out a value from the left / right. The value is in the key, and the light key dies. rpoplpush <key1><key2> #Spit out a value from the right side of the < key1 > list and insert it to the left side of the < key2 > list. lrange <key><start><stop> #Get elements by index subscript (left to right) lrange mylist 0 -1 #0 is the first on the left and - 1 is the first on the right, (0-1 means to get all) lindex <key><index> #Get elements by index subscript (left to right) llen <key> #Get list length linsert <key> before <value><newvalue> #Insert < newvalue > after < value > lrem <key><n><value> #Delete n values from the left (from left to right) lset<key><index><value> #Replace the value whose index is the index of the list key with value
3.2. 2 data structure
Its bottom layer is actually a * * * two-way linked list * * *, which has high performance on both ends. The performance of the middle node through the operation of index subscript will be poor.

-
When there are few list elements: use a continuous memory, zip list to compress the list, and all elements are stored next to each other
-
When there is a large amount of data: change to quicklist quick list and combine ziplost with linked list

Advantages: Redis combines the linked list and zipplist to form a quicklist. That is to string multiple ziplist s using bidirectional pointers. This not only meets the fast insertion and deletion performance, but also does not appear too much spatial redundancy.
3.3 Set
Redis set is an unordered set of string type. Set is similar to list, but set can automatically eliminate duplication
Its bottom layer is actually a hash table with null value, so the complexity of adding, deleting and searching is O(1).
3.3. 1 common commands
sadd <key><value1><value2> #Add one or more member elements to the set key, and the existing member elements will be ignored smembers <key> #Gets all the values of the collection. sismember <key><value> #Judge whether the set < key > contains the < value > value, with 1 and no 0 scard <key> #Returns the number of elements in the collection. srem <key><value1><value2> #Delete an element in the collection. spop <key> #Spit out a value randomly from the set. srandmember <key><n> #Randomly take n values from the set. Is not removed from the collection. smove <source><destination>value #Moves a value in a set from one set to another sinter <key1><key2> #Returns the intersection element of two collections. sunion <key1><key2> #Returns the union element of two collections. sdiff <key1><key2> #Returns the difference elements of two sets (those in key1, excluding those in key2)
3.3. 2 data structure
The Set data structure is * * dict dictionary * *, which is implemented by hash table.
The internal implementation of HashSet in Java uses HashMap, but all values point to the same object. The same is true for Redis's set structure. It also uses a hash structure internally. All values point to the same internal value.
3.4 Hash
3.4. 0 Introduction
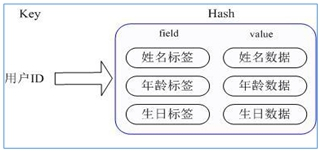
Redis hash is a collection of key value pairs. string type field and value mapping table, hash is particularly suitable for storing objects.
Similar to map < string, Object > in Java
For example, the user ID is the key to be searched, and the stored value user object contains name, age, birthday and other information. If it is stored in an ordinary key/value structure
There are two main storage methods:
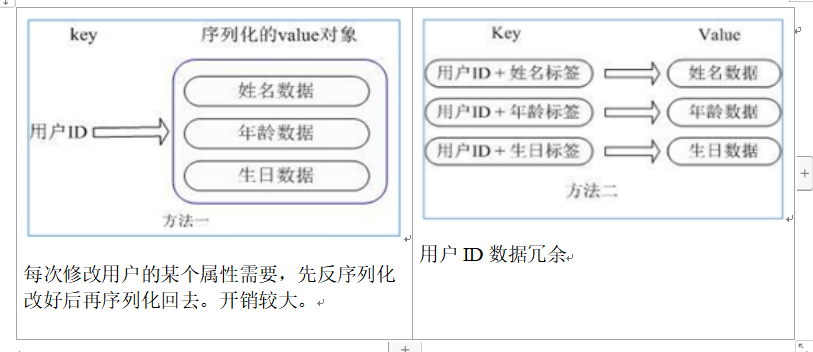
hash is through = = key (user ID) + field (attribute tag) = = operation
In this way, there is no need to store data repeatedly, and there is no problem of serialization and concurrent modification control
3.4. 1 common commands
hset <key><field><value> to<key>In the collection <field>Key assignment<value> hget <key1><field> from<key1>aggregate<field>take out value hmset <key1><field1><value1><field2><value2>... Batch settings hash Value of hexists<key1><field> View hash table key Given domain field Whether it exists. hkeys <key> List the hash All of the collection field hvals <key> List the hash All of the collection value hincrby <key><field><increment> Is a hash table key Domain in field Value of plus increment 1 -1 hsetnx <key><field><value> Hash table key Domain in field The value of is set to value ,If and only if domain field non-existent .
3.4. 2 data structure
-
When the field value length is short and the number is small: use a continuous memory, zip list to compress the list, and all elements are stored next to each other
-
Otherwise: change to hashtable (hash table)
3.5. Zset ordered set
Redis ordered set zset is very similar to unordered set, which is a string set without duplicate elements.
However, zset adds score: score is used to sort collection members from low score to high score
3.5. 1 common commands
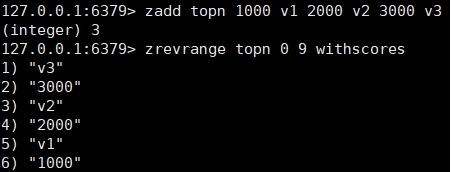
zadd <key><score1><value1><score2><value2> #Add one or more member elements and their score values to the ordered set key. zrange <key><start><stop> [withscores] #Returns the elements in the ordered set key with subscripts between < start > < stop > With cores, you can return scores and values to the result set. zrangebyscore key minmax [withscores] [limit offset count] #Returns all members in the ordered set key whose score value is between min and max (including those equal to min or max). Ordered set members are arranged in the order of increasing score value (from small to large). zrevrangebyscore key maxmin [withscores] [limit offset count] #Ditto, change to order from large to small. zincrby <key><increment><value> #Increment the score of the element zrem <key><value> #Delete the element with the specified value under the collection zcount <key><min><max> #Count the number of elements in the set and score interval zrank <key><value> #Returns the ranking of the value in the collection, starting from 0.
Case: implement a leaderboard
3.5. 2 data structure
SortedSet(zset) is a very special data structure provided by Redis
-
On the one hand, it is equivalent to the Java data structure map < string, double >, which can give each element value a weight score,
-
On the other hand, it is similar to TreeSet. The internal elements are sorted according to the weight score. You can get the ranking of each element, and you can also get the list of elements through the range of score.
The underlying zset uses two data structures
(1) hash is used to associate the element value with the weight score to ensure the uniqueness of the element value. The corresponding score value can be found through the element value.
(2) Jump table. The purpose of jump table is to sort the element value and obtain the element list according to the range of score.
What is a jump table?
Orderly collection is common in life, such as ranking students according to their grades, ranking players according to their scores, etc.
For the underlying implementation of ordered sets, arrays, balanced trees, linked lists, etc. can be used. ① Insertion and deletion of array elements; ② Balanced tree or red black tree has high efficiency but complex structure; ③ The linked list query needs to traverse all, which is inefficient.
Redis uses a jump table. The efficiency of jump table is comparable to that of red black tree, and the implementation is much simpler than that of red black tree.
Compare the ordered linked list and jump list, and query 51 from the linked list
Ordered linked list:

To find the element with the value of 51, you need to start from the first element and find it by searching and comparing in turn. A total of 6 comparisons are required.
Jump table:
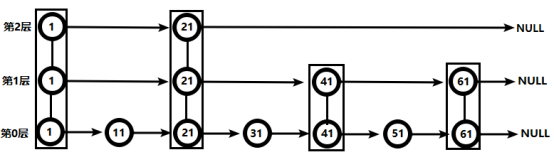 Starting from layer 2, node 1 is smaller than node 51, which is compared backward.
Starting from layer 2, node 1 is smaller than node 51, which is compared backward.
Node 21 is smaller than node 51. Continue to compare backward, followed by NULL, so go down from node 21 to layer 1
In layer 1, node 41 is smaller than node 51. Continue backward, and node 61 is larger than node 51, so it goes down from 41
In layer 0, node 51 is the node to be found. The node is found for 4 times.