summary
It is said that this tutorial focuses on application. I haven't understood the principle yet. I read the first six chapters when eating melons. It's also vague.....
sklearn is to switch packages. I hope I can learn.
The process is:
- Instantiate and establish the evaluation model object;
- Train the model through the model interface;
- Extract the required information through the model interface.
The corresponding code is:
from sklearn import tree clf = tree.DecisionTreeClassifier() clf = clf.fit(x_train,y_train) result = clf.score(x_test,y_test)
Important parameters
- criterion, you can take the information entropy and Gini coefficient, which are entropy and Gini impulse respectively.
- Random parameter: random_state sets a random number seed, randomly generates a decision tree, and selects the best; splitter="random" is also random processing.
import numpy as np import pandas as pd from sklearn import tree from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split import graphviz # pandas splice data df = pd.concat([pd.DataFrame(wine.data), pd.DataFrame(wine.target)],axis=1) # Divide training set and test set Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data, wine.target, test_size=0.3) # Instantiate a classifier clf = tree.DecisionTreeClassifier(criterion='entropy',random_state=3,splitter="random") # train clf = clf.fit(Xtrain, Ytrain) # Evaluation results score = clf.score(Xtest, Ytest) # Draw the decision tree with graphviz dot_data = tree.export_graphviz(clf, feature_names=wine.feature_names, class_names=['0', '1', '2'], filled=True, rounded=True, special_characters=True) graph = graphviz.Source(dot_data) graph
Pruning parameter tuning
If the decision tree classifies the training set too thoroughly, it may cause over fitting to the test set. Pruning is an effective method to prevent over fitting.
-
max_depth
Limit the maximum depth of the tree and cut off all branches exceeding the set depth. It is very effective in high-dimensional sample size.
In actual use, you can try from 3 to see the fitting effect, and then decide whether to increase the depth. -
min_samples_leaf , min_samples_split
min_samples_leaf specifies that each child node of a node after branching must contain at least min_samples_leaf is a training sample, otherwise the branch will not occur or the branch will contain min towards each child node_ samples_ Leaf occurs in the direction of two samples.
General collocation max_depth works well in the regression tree and can make the model smoother. Generally, try from 5, and the tree can also be decimal. This parameter can also ensure the minimum size of each leaf, avoid low variance and over fitting leaf nodes in the regression problem. For multi category questions, 1 is usually the best choice.
min_samples_split defines that a node must contain at least min_samples_split samples, this node is allowed to branch, otherwise the branch will not occur. -
max_features and min_impurity_decrease
General and max_depth is used together to refine the tree
max_features limits the number of features considered when branching. Features exceeding the limit will be discarded, and max_depth is similar.
max_features is a pruning parameter used to limit the over fitting of high-dimensional data. The method is violent, which directly limits the number of features that can be used, and the parameter that forcibly stops the decision tree. Without knowing the importance of each feature in the decision tree, forcibly setting this parameter may lead to insufficient model learning. If you want to prevent overfitting by dimensionality reduction, you can use PCA,ICA or the dimensionality reduction algorithm in the feature selection module.
min_impurity_decrease limits the size of information gain. Branches with information gain less than the set value will not occur. -
class_weight and min_weight_fraction_leaf
Parameters to complete sample label balance.
That is, the sample label has a weight. After it has a weight, pruning should be based on the weight -
Determine the optimal pruning parameters
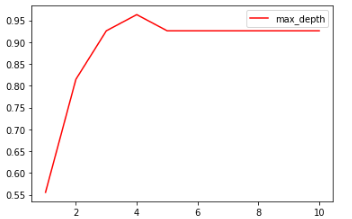
Use the curve to determine the superparameter for judgment. The hyperparametric learning curve is a curve with the value of the hyperparameter as the abscissa and the measurement index of the model as the ordinate, which is used to measure the performance of the model under different values of the hyperparameter. In the red wine dataset is the score obtained by training.
For example:
test = []
for i in range(10):
clf = tree.DecisionTreeClassifier(criterion='entropy',random_state=30,
splitter="random",
max_depth=i+1,
)
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest)
test.append(score)
plt.plot(range(1,11), test, color='red', label='max_depth')
plt.legend()
plt.show()
Important attributes and interfaces
sklearn does not accept one-dimensional data. If the sample data is one-dimensional, reshape(1,-1) needs to be used to increase the dimension.
- apply
clf.apply(Xtest)
Returns the index of the leaf node where each test sample is located - predict
clf.predict(Xtest)
Returns the classification / regression results for each test sample.