Learning focus
Don't think back! Don't think back! Don't think about reciting!: Gradually understand along the process and ideas.
Unity of knowledge and practice! Unity of knowledge and practice! Unity of knowledge and practice!: After learning each stage of knowledge, be sure to document output or practice.
OK, finish the point, let's start!
What is IOC?
IOC (Inversion Of Control): it is to hand over the code that needs to be manually created and relied on in the project to the container created by Spring for implementation and unified management, so as to realize the Inversion Of Control.
According to this explanation, we must think that there must be many object instances in this container (Spring defines BeanDefinition objects to wrap native objects), so we can get them directly when we need them.
Here's a question: what exactly does the container for storing objects look like? Or what data structure is used to define the storage, Map or List or others?
preparation
First of all, we already know that the container stores the objects created by Spring for us, so we certainly need a description to let the container know the relationship between the objects to be created and the objects, that is, the configuration metadata.
So before we really understand the container initialization process, we need to do some preparatory work.
Step 1: configure metadata
There are three ways to configure metadata in Spring:
- XML: the traditional configuration method is simple, intuitive and easy to manage
<beans>
<bean id="" class=""/>
</beans>
- Java code: define bean s outside the application class
@Configuration
public class ConfigA {
@Bean
public A a() {
return new A();
}
}
- Note: the configuration is simplified, but the dispersion is difficult to control. Use class level annotations @ Controller, @ Service, @ Component, etc., and class internal annotations @ Autowire, @ Value, @ Resource, etc.
At present, the most commonly used method in daily development may be annotation based to simplify configuration. Of course, Spring allows these three methods to be mixed together, which depends on the actual development situation.
Step 2: configure resolution
After configuring the metadata, you need to parse the configuration. Obviously, the syntax and data description of different configuration methods are different.
Therefore, Spring encapsulates parsers with different configuration methods, such as:
- XML: use ClasspathXmlApplicationContext as the entry and XmlBeanDefinitionReader to parse the metadata of the Bean
- Java code and annotation: use AnnotationConfigApplicationContext as the entry, and AnnotatedBeanDefinitionReader to parse the metadata of the Bean
Step 3: key classes
Here, let's familiarize ourselves with several key classes in IOC in advance, namely:
-
BeanFactory: it is the top-level interface. See the name and meaning. It is a typical factory mode.
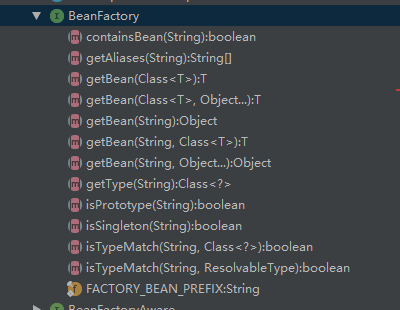 Through its source code, we can find that BeanFactory only defines the basic behavior of IOC container and obtains beans and various properties of beans. Next, let's look at its subclass diagram
Through its source code, we can find that BeanFactory only defines the basic behavior of IOC container and obtains beans and various properties of beans. Next, let's look at its subclass diagram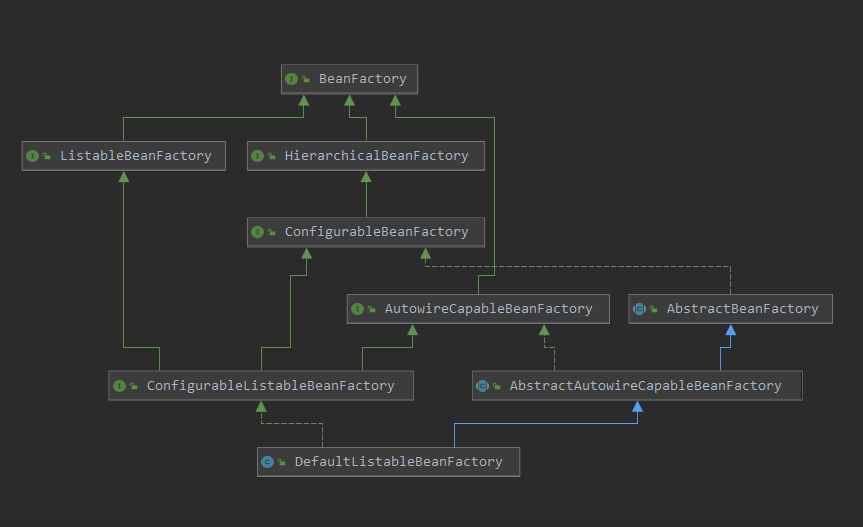
It has three important subclasses below: listablebeanfactory < < can enumerate all bean instances >, hierarchalbeanfactory < < can configure the bean's parent class with inheritance relationship >, and autowirecapablebeanfactory < < provide the implementation of automatic assembly of beans >. At the same time, it can be found that DefaultListableBeanFactory implements all interfaces, which means that it has all the above "big brother" functions and its own extension functions (crazy and familiar), so it is also the default implementation class.
-
ApplicationContext: the BeanFactory factory above helps us get objects. How the factory generates objects depends on it. It provides specific IOC implementation, GenericApplicationContext, ClasspathXmlApplicationContext, etc. it also provides the following additional services:
-
Support information source, internationalization < implement MessageSource interface >
-
Access resources < implement ResourcePatternResolver interface >
-
Support application events < implement ApplicationEventPublisher interface >
-
-
BeanDefinition: the description and definition of Bean objects in Spring. It can be understood that each Bean object in the container is saved in BeanDefinition.
-
BeanDefinitionReader: a parser that configures the metadata of a Bean, such as XmlBeanDefinitionReader and AnnotatedBeanDefinitionReader
Initialization of IOC (from scratch)
TIPS
It is very difficult to read the source code of a mature framework. Almost 100% will be "carsick", In particular, don't be curious (obsessive-compulsive disorder) to understand the call of each method (the call chain will make you feel like infinite recursion), and the details of each line of code (believe me, it will be forgotten after reading). That will really kill the cat! We must explore the architecture, not the details, and gradually check some details according to the actual situation after understanding the whole idea process.
Reading articles is the same. If you don't understand knowledge articles, read the outline first. If you don't, read and refine the outline first. After you have an understanding of the whole architecture, look at the detailed analysis under each outline.
Now that we understand the essence of the container and have made some preparations, we will start to explore how Spring completes the initialization of the container?
From scratch, we need to start with the entry, that is, ClasspathXmlApplicationContext and AnnotationConfigApplicationContext. The reason has been mentioned in the configuration analysis of the preparatory work just now.
Let's explore it respectively.
Initialization of IOC container based on XML
1. Positioning
First, let's think about the previous preparations. After the Bean resource file is defined, the < configuration metadata >, and then we will find a way to parse the defined data and register it in the container. The logic is correct, but before parsing, we need to consider how to find the parsing file, that is, the configuration path. Therefore, in the first step (in fact, this is the second step. The first step is to configure metadata, which has been implemented by defau lt here). We need to resolve the path, that is, location.
First, we will start through the main() method:
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("application.xml");
Let's briefly understand the class diagram of ClassPathXmlApplicationContext in advance:

Next, click to see the source code of the actually called ClassPathXmlApplicationContext:
public ClassPathXmlApplicationContext(String[] configLocations, boolean refresh, @Nullable ApplicationContext parent) throws BeansException {
// Set resource loader for Bean
super(parent);
// Resolve and set the path of the Bean's resource file
setConfigLocations(configLocations);
if (refresh) {
// Load Bean's configuration resources
refresh();
}
}
1. super(parent): call the construction method of the parent class to set the Bean's resource loader. Click to the end to know that the getResourcePatternResolver() method of the parent class AbstractApplicationcontext is called,
protected ResourcePatternResolver getResourcePatternResolver() {
//Because AbstractApplicationContext inherits DefaultResourceLoader, it is also a resource loader, and its getResource(String location) method is used to load resources
return new PathMatchingResourcePatternResolver(this);
}
2. setConfigLocations(configLocations): call the specific implementation of the parent class AbstractRefreshableConfigApplicationContext. You can understand the path of the resource file that parses and processes the Bean, and this path supports the incoming string array
public void setConfigLocations(@Nullable String... locations) {
if (locations != null) {
Assert.noNullElements(locations, "Config locations must not be null");
this.configLocations = new String[locations.length];
for (int i = 0; i < locations.length; i++) {
// Method to parse a string into a path
this.configLocations[i] = resolvePath(locations[i]).trim();
}
}
else {
this.configLocations = null;
}
}
3. refresh(): load the configuration resources of the Bean. Obviously, the specific implementation of this method is what we need to focus on, "Let we look look look" Click in and find that the refresh() method of the parent class AbstractApplicationContext is called. Here, it is found that refresh() is actually a template method. Let's take a look at the specific logical processing,
@Override
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
//1. Call the method that the container is ready to refresh, obtain the current time of the container, and set the synchronization ID for the container
prepareRefresh();
//2. Tell the subclass to start the refreshBeanFactory() method, and the loading of the Bean definition resource file starts from the refreshBeanFactory() method of the subclass
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
//3. Configure container features for BeanFactory, such as class loader, event handler, and so on
prepareBeanFactory(beanFactory);
try {
//4. Specify a special BeanPost event handler for some subclasses of the container
postProcessBeanFactory(beanFactory);
//5. Call all registered beanfactoryprocessor beans
invokeBeanFactoryPostProcessors(beanFactory);
//6. Register the BeanPost event handler for BeanFactory BeanPostProcessor is a Bean post processor, which is used to listen for events triggered by the container
registerBeanPostProcessors(beanFactory);
//7. Initialize the information source, which is related to internationalization
initMessageSource();
//8. Initialize the container event propagator
initApplicationEventMulticaster();
//9. Call some special Bean initialization methods of subclasses
onRefresh();
//10. Register event listeners for event propagators
registerListeners();
//11. Initialize all remaining singleton beans
finishBeanFactoryInitialization(beanFactory);
//12. Initialize the container's lifecycle event handler and publish the container's lifecycle events
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
//13. Destroy the created Bean
destroyBeans();
//14. Cancel the refresh operation and reset the synchronization ID of the container.
cancelRefresh(ex);
throw ex;
}
finally {
//15. Reset public cache
resetCommonCaches();
}
}
}
We mainly look at the obtainFreshBeanFactory() method, which implements the Bean loading registration. The subsequent code is the initialization information source of the container and some events in the life cycle. Here, the Bean resource file is located. Next, let's look at the specific code implementation loaded.
2. Loading
After setting the path of the configuration file, we also need to create a container before parsing the metadata, so that the parsed object can have a place to store the call. Let's take a look at the specific implementation of obtainFreshBeanFactory(),
protected ConfigurableListableBeanFactory obtainFreshBeanFactory() {
refreshBeanFactory();
ConfigurableListableBeanFactory beanFactory = getBeanFactory();
if (logger.isDebugEnabled()) {
logger.debug("Bean factory for " + getDisplayName() + ": " + beanFactory);
}
return beanFactory;
}
Here, the refreshBeanFactory() method uses the delegation design pattern and defines the abstract method in the parent class, but the specific implementation calls the method of the child class. Click in to see that the method actually called is overridden by AbstractRefreshableApplicationContext,
@Override
protected final void refreshBeanFactory() throws BeansException {
//If there is already a container, destroy the bean s in the container and close the container
if (hasBeanFactory()) {
destroyBeans();
closeBeanFactory();
}
try {
//Create IOC container
DefaultListableBeanFactory beanFactory = createBeanFactory();
beanFactory.setSerializationId(getId());
//Customize the container, such as setting to allow Bean override and Bean circular reference
customizeBeanFactory(beanFactory);
//Call the method defined by the load Bean. Here, a delegation mode is used. Only the abstract loadBeanDefinitions method is defined in the current class, and the specific implementation calls the subclass container
loadBeanDefinitions(beanFactory);
synchronized (this.beanFactoryMonitor) {
this.beanFactory = beanFactory;
}
}
catch (IOException ex) {
throw new ApplicationContextException("I/O error parsing bean definition source for " + getDisplayName(), ex);
}
}
From the implementation, we can know whether BeanFactory already exists before creating the container. If so, destroy all beans in the container < < clear() > the HashMap storing beans, and close BeanFactory < < set to null >., On the contrary, if it does not exist, create the IOC container DefaultListableBeanFactory. Is it very familiar here? Yes, it is the key class that we are crazy familiar with before, and the default implementation class that is more powerful than all "big brothers", In fact, it is the IOC container (tips: I may feel dizzy here. They are all containers. It seems that they are all different. Here, there are many containers in Spring. In addition to the subclasses of BeanFactory, we can call the inherited or implemented subclasses under ApplicationContext, such as those in the ClassPathXmlApplicationContext class diagram above, containers, Needless to say, the inherited subclasses have the attribute private ApplicationContext parent; in the implementation class;, So they can all be called containers). Before that, we left a question: what is the container for storing objects like? Here we know the specific appearance of the container, but in fact, the container that really stores Bean objects, or the data structure called the container, continue to explore, and we will know later.
Next, look at the loadBeanDefinitions() method, which is also an abstract method. The real implementation is implemented by its subclass AbstractXmlApplicationContext. The specific implementation is as follows:
@Override
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException {
//Create a Bean configuration data parser and set it into the container through callback
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
//Set resource environment and resource loader
beanDefinitionReader.setEnvironment(this.getEnvironment());
beanDefinitionReader.setResourceLoader(this);
//Set up SAX xml parser
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
//Enables the verification mechanism when parsing Xml resource files
initBeanDefinitionReader(beanDefinitionReader);
//Load Bean
loadBeanDefinitions(beanDefinitionReader);
}
Next, continue to explore the loadBeanDefinitions() method,
protected void loadBeanDefinitions(XmlBeanDefinitionReader reader) throws BeansException, IOException {
//Get the location of Bean configuration data
Resource[] configResources = getConfigResources();
if (configResources != null) {
reader.loadBeanDefinitions(configResources);
}
//When the location of obtaining Bean configuration data in the subclass is empty, obtain the resource set by setConfigLocations method in FileSystemXmlApplicationContext constructor
String[] configLocations = getConfigLocations();
if (configLocations != null) {
reader.loadBeanDefinitions(configLocations);
}
}
@Nullable
protected Resource[] getConfigResources() {
return null;
}
Here, getConfigResources() also uses the delegate mode, which is really implemented in ClassPathXmlApplicationContext, reader Loadbean definitions (configresources) actually calls the parent class AbstractBeanDefinitionReader to parse the Bean's configuration data,
@Override
public int loadBeanDefinitions(Resource... resources) throws BeanDefinitionStoreException {
Assert.notNull(resources, "Resource array must not be null");
int counter = 0;
for (Resource resource : resources) {
counter += loadBeanDefinitions(resource);
}
return counter;
}
@Override
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
//The parsed XML resources are specially encoded
return loadBeanDefinitions(new EncodedResource(resource));
}
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isInfoEnabled()) {
logger.info("Loading XML bean definitions from " + encodedResource.getResource());
}
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
currentResources = new HashSet<>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
try {
//Convert resource file to IO stream of InputStream
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
//Get the parsing source of XML
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
//Specific analysis process
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
finally {
//Close IO stream
inputStream.close();
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
}
finally {
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}
We continue along the reader The loadBeanDefinitions (configResources) method looks down and finds that the last loadBeanDefinitions is called the loadBeanDefinitions() method, which is the xml parser that we are going to talk about. The concrete parsing process is in the doLoadBeanDefinitions() method.
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
//Converting XML files to DOM objects
Document doc = doLoadDocument(inputSource, resource);
//Parsing Bean data
return registerBeanDefinitions(doc, resource);
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (SAXParseException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"Line " + ex.getLineNumber() + " in XML document from " + resource + " is invalid", ex);
}
catch (SAXException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"XML document from " + resource + " is invalid", ex);
}
catch (ParserConfigurationException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Parser configuration exception parsing XML from " + resource, ex);
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"IOException parsing XML document from " + resource, ex);
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Unexpected exception parsing XML document from " + resource, ex);
}
}
Through analysis, the configuration data of the Bean is loaded. Finally, the xml is converted into a Document object and then parsed. We first look at the doLoadDocument() method and know that the loadDocument() method of DefaultDocumentLoder will be called,
@Override
public Document loadDocument(InputSource inputSource, EntityResolver entityResolver,
ErrorHandler errorHandler, int validationMode, boolean namespaceAware) throws Exception {
//Create a file parser factory
DocumentBuilderFactory factory = createDocumentBuilderFactory(validationMode, namespaceAware);
if (logger.isDebugEnabled()) {
logger.debug("Using JAXP provider [" + factory.getClass().getName() + "]");
}
//Create document parser
DocumentBuilder builder = createDocumentBuilder(factory, entityResolver, errorHandler);
//Parsing resource data
return builder.parse(inputSource);
}
The above parsing process calls the JAXP standard of the Java EE standard for processing. Next, we continue to analyze how to parse the Bean object managed in the IOC container and register it in the container after converting the bit to a Document object. Let's continue to look at the registerBeanDefinition() method,
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
//Create BeanDefinitionDocumentReader
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
//Get the number of registered beans in the container
int countBefore = getRegistry().getBeanDefinitionCount();
//Specific analysis process
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
//Returns the number of parsed beans
return getRegistry().getBeanDefinitionCount() - countBefore;
}
In the introduction to the key classes in the previous preparatory work, we know that the actual storage in the IOC container is the BeanDefinition object, which encapsulates the Bean object, so here we first create the BeanDefinitionDocumentReader to complete the parsing and encapsulation of the Bean object in xml. The main parsing process is in documentreader It is completed in registerbeandefinitions (DOC, createreadercontext (resource)). Let's continue,
@Override
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
logger.debug("Loading bean definitions");
//Get the root element of the Document
Element root = doc.getDocumentElement();
doRegisterBeanDefinitions(root);
}
protected void doRegisterBeanDefinitions(Element root) {
//The specific parsing process is implemented by BeanDefinitionParserDelegate,
//Various elements of the Spring Bean definition XML file are defined in BeanDefinitionParserDelegate
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
if (this.delegate.isDefaultNamespace(root)) {
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
if (logger.isInfoEnabled()) {
logger.info("Skipped XML bean definition file due to specified profiles [" + profileSpec +
"] not matching: " + getReaderContext().getResource());
}
return;
}
}
}
//Preprocess xml and perform custom parsing before parsing Bean definitions to enhance the scalability of the parsing process
preProcessXml(root);
//The Document object defined by the Bean starts from the root element of the Document
parseBeanDefinitions(root, this.delegate);
//After the Bean definition is parsed, custom parsing is performed to increase the scalability of the parsing process
postProcessXml(root);
this.delegate = parent;
}
We found that registerBeanDefinitions() is actually implemented by the implementation class DefaultBeanDefinitionDocumentReader of BeanDefinitionDocumentReader. Through source code analysis, we can see that BeanDefinitionParserDelegate is a key class. Click in and find that it defines various elements in XML files, so we know that more specific parsing depends on it, Select preProcessXml(root); And postProcessXml(root); We can know the pre - and post-processing XML by name, and click it to find that it is a reserved empty implementation, mainly to enhance the scalability in the parsing process. We mainly look at the implementation of parseBeanDefinitions(),
//Use Spring's Bean rules to define the Document object of the Bean from the root element of the Document
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
//Is the Document object the default XML namespace
if (delegate.isDefaultNamespace(root)) {
//All child nodes of the root element of the Document object
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
//Is the Document node an element node of XML
if (node instanceof Element) {
Element ele = (Element) node;
//Is the element node of Document the default XML namespace
if (delegate.isDefaultNamespace(ele)) {
//Default element node resolution
parseDefaultElement(ele, delegate);
}
else {
//Custom element node resolution
delegate.parseCustomElement(ele);
}
}
}
}
else {
//Custom element node resolution
delegate.parseCustomElement(root);
}
}
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
// < import > Import resolution
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
importBeanDefinitionResource(ele);
}
// < alias > alias resolution
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
processAliasRegistration(ele);
}
// < bean > bean rule parsing
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
processBeanDefinition(ele, delegate);
}
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// recursion
doRegisterBeanDefinitions(ele);
}
}
We can see that Xml data can be parsed from here. At the same time, there are two parsing methods, namely parseDefaultElement() Default element parsing and parseCustomElement() custom element parsing. Customization requires additional implementation. We mainly look at the process of Default element parsing and find that there are three different parsing processes, namely import, alias For object parsing, let's look at their implementation respectively,
protected void importBeanDefinitionResource(Element ele) {
//Gets the location attribute of the configured import element
String location = ele.getAttribute(RESOURCE_ATTRIBUTE);
//If location is empty, it will end directly
if (!StringUtils.hasText(location)) {
getReaderContext().error("Resource location must not be empty", ele);
return;
}
//Resolve the location attribute value using the system variable value
location = getReaderContext().getEnvironment().resolveRequiredPlaceholders(location);
Set<Resource> actualResources = new LinkedHashSet<>(4);
//Identifies whether the configured location is an absolute path
boolean absoluteLocation = false;
try {
absoluteLocation = ResourcePatternUtils.isUrl(location) || ResourceUtils.toURI(location).isAbsolute();
}
catch (URISyntaxException ex) {
}
if (absoluteLocation) {
try {
//The parser loads the Bean configuration data of the location path
int importCount = getReaderContext().getReader().loadBeanDefinitions(location, actualResources);
if (logger.isDebugEnabled()) {
logger.debug("Imported " + importCount + " bean definitions from URL location [" + location + "]");
}
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error(
"Failed to import bean definitions from URL location [" + location + "]", ele, ex);
}
}
else {
//The configured location is a relative path
try {
int importCount;
//Convert location to relative path
Resource relativeResource = getReaderContext().getResource().createRelative(location);
//Does the path resource exist
if (relativeResource.exists()) {
//The parser loads the Bean configuration data of the location path
importCount = getReaderContext().getReader().loadBeanDefinitions(relativeResource);
actualResources.add(relativeResource);
}
else {
//Get the basic path of the parser
String baseLocation = getReaderContext().getResource().getURL().toString();
//The parser loads the Bean configuration data of the location path
importCount = getReaderContext().getReader().loadBeanDefinitions(
StringUtils.applyRelativePath(baseLocation, location), actualResources);
}
if (logger.isDebugEnabled()) {
logger.debug("Imported " + importCount + " bean definitions from relative location [" + location + "]");
}
}
catch (IOException ex) {
getReaderContext().error("Failed to resolve current resource location", ele, ex);
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to import bean definitions from relative location [" + location + "]",
ele, ex);
}
}
Resource[] actResArray = actualResources.toArray(new Resource[actualResources.size()]);
//After parsing the < import > element, send the import resource processing completion event
getReaderContext().fireImportProcessed(location, actResArray, extractSource(ele));
}
Here, the import elements are mainly parsed, and the Bean configuration resources are loaded into the IOC container according to the configured import path.
protected void processAliasRegistration(Element ele) {
//Get the property value of name
String name = ele.getAttribute(NAME_ATTRIBUTE);
//Get the attribute value of alias
String alias = ele.getAttribute(ALIAS_ATTRIBUTE);
boolean valid = true;
//The name attribute value is empty
if (!StringUtils.hasText(name)) {
getReaderContext().error("Name must not be empty", ele);
valid = false;
}
//The alias attribute value is null
if (!StringUtils.hasText(alias)) {
getReaderContext().error("Alias must not be empty", ele);
valid = false;
}
if (valid) {
try {
//Register alias with container
getReaderContext().getRegistry().registerAlias(name, alias);
}
catch (Exception ex) {
getReaderContext().error("Failed to register alias '" + alias +
"' for bean with name '" + name + "'", ele, ex);
}
//After resolving the < alias > element, send the alias processing completion event
getReaderContext().fireAliasRegistered(name, alias, extractSource(ele));
}
}
Here, the alias element is mainly resolved and the alias is registered in the IOC container for the Bean.
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
// Encapsulation of BeanDefinition
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// Register the Bean into the IOC container
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to register bean definition with name '" +
bdHolder.getBeanName() + "'", ele, ex);
}
//After the registration is completed, the registration completion event is sent
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}
Here, we mainly resolve the object elements and register the Bean's encapsulated object BeanDefinition into the IOC container. We found that the object of BeanDefinitionHolder, which is the encapsulation of BeanDefinition, registers and passes parameters to the container. We can see how it is parsed and converted to BeanDefinitionHolder,
@Nullable
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele) {
return parseBeanDefinitionElement(ele, null);
}
@Nullable
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, @Nullable BeanDefinition containingBean) {
//Get id attribute value
String id = ele.getAttribute(ID_ATTRIBUTE);
//Get the value of the name attribute
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
//Get alias attribute value
List<String> aliases = new ArrayList<>();
//Adds all the name attribute values to the alias collection
if (StringUtils.hasLength(nameAttr)) {
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
aliases.addAll(Arrays.asList(nameArr));
}
String beanName = id;
//If the id property is not configured, beanName is assigned the first value in the alias
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
beanName = aliases.remove(0);
if (logger.isDebugEnabled()) {
logger.debug("No XML 'id' specified - using '" + beanName +
"' as bean name and " + aliases + " as aliases");
}
}
if (containingBean == null) {
//Check whether the configured id, name or alias are duplicate
checkNameUniqueness(beanName, aliases, ele);
}
//Where the Bean definition configured in the < Bean > element is parsed in detail
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);
if (beanDefinition != null) {
if (!StringUtils.hasText(beanName)) {
try {
if (containingBean != null) {
//Generate a unique beanName for the resolved Bean
beanName = BeanDefinitionReaderUtils.generateBeanName(
beanDefinition, this.readerContext.getRegistry(), true);
}
else {
//Generate a unique beanName for the resolved Bean
beanName = this.readerContext.generateBeanName(beanDefinition);
String beanClassName = beanDefinition.getBeanClassName();
if (beanClassName != null &&
beanName.startsWith(beanClassName) && beanName.length() > beanClassName.length() &&
!this.readerContext.getRegistry().isBeanNameInUse(beanClassName)) {
aliases.add(beanClassName);
}
}
if (logger.isDebugEnabled()) {
logger.debug("Neither XML 'id' nor 'name' specified - " +
"using generated bean name [" + beanName + "]");
}
}
catch (Exception ex) {
error(ex.getMessage(), ele);
return null;
}
}
String[] aliasesArray = StringUtils.toStringArray(aliases);
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
}
return null;
}
The above code mainly deals with resolving the id, name and alias attributes of the element. Looking down the parseBeanDefinitionElement() method, you will know that some configurations such as meta, qualifier and property will be resolved. We can see how the attributes of the Bean are set in the resolution. We won't take a closer look here.
Here, the configuration has been loaded into memory, that is, the Bean object has been loaded, but the more important actions have not been done. We need to register the prepared BeanDefinition object into the container.
3. Registration
From the initial configuration metadata to this step, do you feel that everything is ready and only registration is needed.
Let's look at the registerBeanDefinition() method,
//Register the resolved BeanDefinitionHold into the container
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
String beanName = definitionHolder.getBeanName();
//Register BeanDefinition with IOC container
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
//If the resolved BeanDefinition has an alias, register the alias with the container
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
registry.registerAlias(beanName, alias);
}
}
}
In the end, we found that the registration function is really completed by our familiar boss. The DefaultListableBeanFactory implemented by default is a registration policy assigned to Spring. Let's uncover the mystery of the real container,
//Register resolved BeanDefiniton with IOC container
@Override
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
Assert.hasText(beanName, "Bean name must not be empty");
Assert.notNull(beanDefinition, "BeanDefinition must not be null");
//Verify resolved BeanDefiniton
if (beanDefinition instanceof AbstractBeanDefinition) {
try {
((AbstractBeanDefinition) beanDefinition).validate();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Validation of bean definition failed", ex);
}
}
BeanDefinition oldBeanDefinition;
oldBeanDefinition = this.beanDefinitionMap.get(beanName);
if (oldBeanDefinition != null) {
if (!isAllowBeanDefinitionOverriding()) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Cannot register bean definition [" + beanDefinition + "] for bean '" + beanName +
"': There is already [" + oldBeanDefinition + "] bound.");
}
else if (oldBeanDefinition.getRole() < beanDefinition.getRole()) {
// e.g. was ROLE_APPLICATION, now overriding with ROLE_SUPPORT or ROLE_INFRASTRUCTURE
if (this.logger.isWarnEnabled()) {
this.logger.warn("Overriding user-defined bean definition for bean '" + beanName +
"' with a framework-generated bean definition: replacing [" +
oldBeanDefinition + "] with [" + beanDefinition + "]");
}
}
else if (!beanDefinition.equals(oldBeanDefinition)) {
if (this.logger.isInfoEnabled()) {
this.logger.info("Overriding bean definition for bean '" + beanName +
"' with a different definition: replacing [" + oldBeanDefinition +
"] with [" + beanDefinition + "]");
}
}
else {
if (this.logger.isDebugEnabled()) {
this.logger.debug("Overriding bean definition for bean '" + beanName +
"' with an equivalent definition: replacing [" + oldBeanDefinition +
"] with [" + beanDefinition + "]");
}
}
this.beanDefinitionMap.put(beanName, beanDefinition);
}
else {
if (hasBeanCreationStarted()) {
synchronized (this.beanDefinitionMap) {
this.beanDefinitionMap.put(beanName, beanDefinition);
List<String> updatedDefinitions = new ArrayList<>(this.beanDefinitionNames.size() + 1);
updatedDefinitions.addAll(this.beanDefinitionNames);
updatedDefinitions.add(beanName);
this.beanDefinitionNames = updatedDefinitions;
if (this.manualSingletonNames.contains(beanName)) {
Set<String> updatedSingletons = new LinkedHashSet<>(this.manualSingletonNames);
updatedSingletons.remove(beanName);
this.manualSingletonNames = updatedSingletons;
}
}
}
else {
this.beanDefinitionMap.put(beanName, beanDefinition);
this.beanDefinitionNames.add(beanName);
this.manualSingletonNames.remove(beanName);
}
this.frozenBeanDefinitionNames = null;
}
//Check whether a BeanDefinition with the same name has been registered in the IOC container
if (oldBeanDefinition != null || containsSingleton(beanName)) {
//Reset the cache of all registered beandefinitions
resetBeanDefinition(beanName);
}
}
Looking at the whole method, did you notice this beanDefinitionMap. put(beanName, beanDefinition); This code, and beandefinition is the Bean object that we have prepared for a long time. We know that beandefinitionmap is a ConcurrentHashMap, a thread safe Map. We recall our initial question, "what data structure is used to define the storage, Map or List or others?", Here is the answer. Beandefinitionmap is the real container. At the same time, we can also see that other ConcurrentHashMap, ArrayList and LinkedHashSet are defined in the class, as well as those inherited from the parent class. They store the relevant information of different objects in the container. When you contact and use them, you will naturally understand their corresponding uses.
/** Map from dependency type to corresponding autowired value */ private final Map<Class<?>, Object> resolvableDependencies = new ConcurrentHashMap<>(16); /** Map of singleton and non-singleton bean names, keyed by dependency type */ private final Map<Class<?>, String[]> allBeanNamesByType = new ConcurrentHashMap<>(64); /** Map of singleton-only bean names, keyed by dependency type */ private final Map<Class<?>, String[]> singletonBeanNamesByType = new ConcurrentHashMap<>(64); /** List of bean definition names, in registration order */ private volatile List<String> beanDefinitionNames = new ArrayList<>(256); /** List of names of manually registered singletons, in registration order */ private volatile Set<String> manualSingletonNames = new LinkedHashSet<>(16);
At the same time, we see a synchronized modified code, because thread synchronization is required in the process of registering objects to ensure data consistency.
Here, the initialization process of IOC container based on Xml has been completed. After basically looking at the complete process, we also combed the initialization sequence diagram and flow chart to deepen the understanding of the whole container initialization process. At the same time, we know that the initialization of IOC container mainly consists of three steps: positioning, loading and registration.
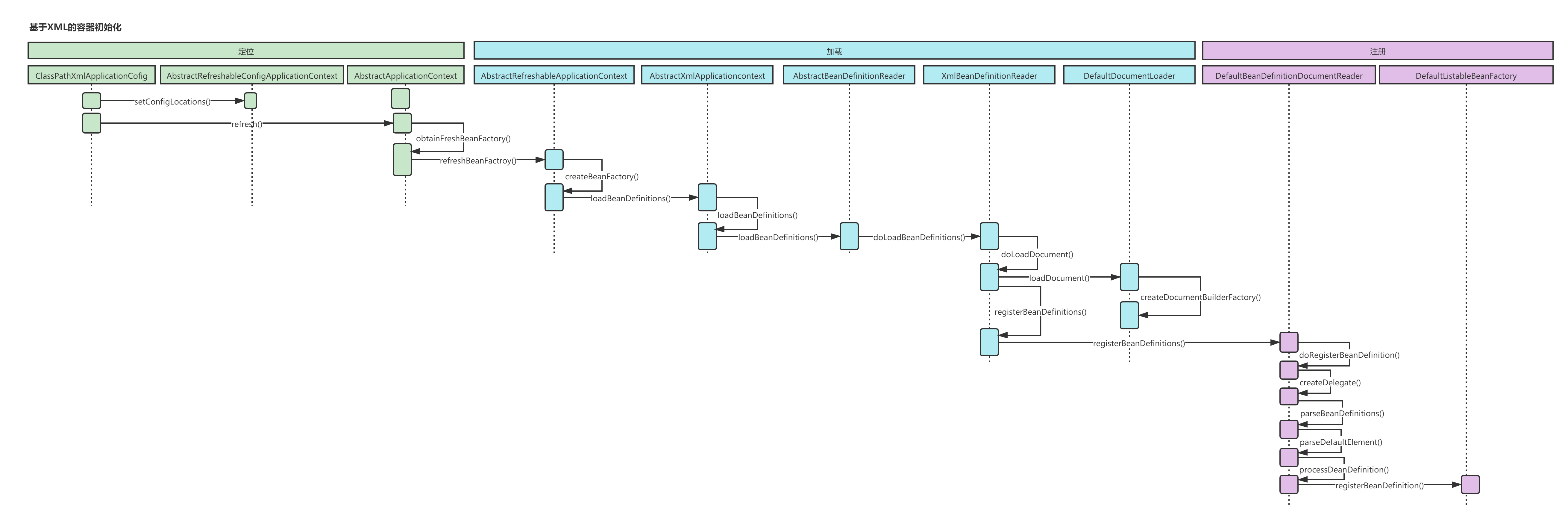
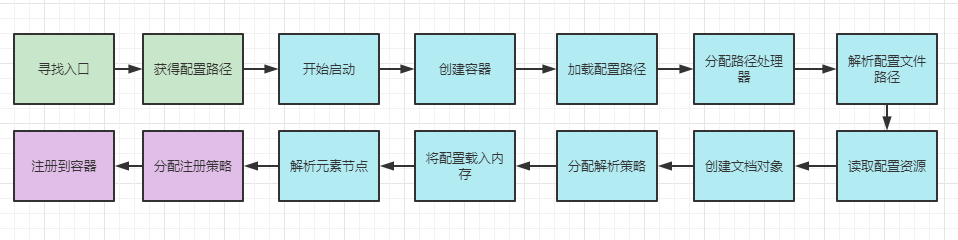
Next, we will explore another annotation based initialization method, which is basically the same. I believe it will be easier to understand.
Initialization of IOC container based on Annotation
Referring to the Spring version data, we know that the Annotation based configuration is introduced in the version after 2.0, which is mainly used to simplify the Bean configuration and improve the development efficiency. Up to now, SpringBoot has become popular. It also basically realizes zero configuration based on annotations. In actual development and use, it can only be a cool word. In the previous preparatory work, we learned that annotations can be divided into two types: class level and class internal annotations, and the Spring container has different processing strategies according to these two different methods. The class level Annotation scans and reads the definition class of the Annotation Bean according to the Annotation filtering rules, and the internal Annotation of the class parses the internal Annotation of the Bean through the post Annotation processor of the Bean.
We already know that the entry is AnnotationConfigApplicationContext. In fact, it also has a brother called AnnotationConfigWebApplicationContext. It is the Web version of AnnotationConfigApplicationContext. Their functions and usage are basically the same. Next, we will take AnnotationConfigApplicationContext as an example to explore the initialization process of IOC container.
1. Entrance
First, we will start through the main() method:
ApplicationContext applicationContext = new AnnotationConfigApplicationContext(AppConfig.class);
perhaps
ApplicationContext applicationContext = new AnnotationConfigApplicationContext("Package path");
Let's look at the source code of AnnotationConfigApplicationContext:
// Directly resolve the class of configuration annotation
public AnnotationConfigApplicationContext(Class<?>... annotatedClasses) {
this();
register(annotatedClasses);
refresh();
}
// Scan all classes under the specified package path
public AnnotationConfigApplicationContext(String... basePackages) {
this();
scan(basePackages);
refresh();
}
From the above source code, we can see that there are two processing methods:
- Directly resolve the class of configuration annotation
- Scan all classes under the specified package path
At the same time, we can see that the refresh() method is called. It is the same method as the refresh() method in the previous XML parsing. The specific implementation is the same. It is to load the Bean's configuration resources. So here we mainly focus on register (annotated classes); And scan (base packages); These two methods, they are the unique implementation. Next, we will explore the specific implementation of these two processing methods.
2. Directly resolve the class of configuration annotation
Before we start, let's continue to look at the source code of the annotationconfigapplicationcontext we haven't finished reading just now,
// Parser
private final AnnotatedBeanDefinitionReader reader;
// Scanner
private final ClassPathBeanDefinitionScanner scanner;
public AnnotationConfigApplicationContext() {
this.reader = new AnnotatedBeanDefinitionReader(this);
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
OK, here we know that the annotationconfigapplicationcontext initializes the AnnotatedBeanDefinitionReader object when it is created, and we know that this object is the parser for parsing annotation beans, which will be used later.
Let's continue to look at the register() method implementation,
public void register(Class<?>... annotatedClasses) {
Assert.notEmpty(annotatedClasses, "At least one annotated class must be specified");
this.reader.register(annotatedClasses);
}
We know that the actual parsing is the responsibility of the reader parser just created. Let's go to AnnotatedBeanDefinitionReader to see its specific implementation process,
//It supports parsing multiple annotated classes
public void register(Class<?>... annotatedClasses) {
for (Class<?> annotatedClass : annotatedClasses) {
registerBean(annotatedClass);
}
}
public void registerBean(Class<?> annotatedClass) {
doRegisterBean(annotatedClass, null, null, null);
}
<T> void doRegisterBean(Class<T> annotatedClass, @Nullable Supplier<T> instanceSupplier, @Nullable String name,
@Nullable Class<? extends Annotation>[] qualifiers, BeanDefinitionCustomizer... definitionCustomizers) {
//The subclass under BeanDefinition encapsulates the Bean object
AnnotatedGenericBeanDefinition abd = new AnnotatedGenericBeanDefinition(annotatedClass);
if (this.conditionEvaluator.shouldSkip(abd.getMetadata())) {
return;
}
abd.setInstanceSupplier(instanceSupplier);
//Resolve the scope of the Bean, such as @ Scope("prototype"), prototype type@ Scope("singleton"), singleton type
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(abd);
//Set scope
abd.setScope(scopeMetadata.getScopeName());
//Generate unique beanName
String beanName = (name != null ? name : this.beanNameGenerator.generateBeanName(abd, this.registry));
//Parsing and processing general annotations
AnnotationConfigUtils.processCommonDefinitionAnnotations(abd);
//If qualifiers exist
if (qualifiers != null) {
for (Class<? extends Annotation> qualifier : qualifiers) {
//If the @ Primary annotation is configured, the Bean is the priority for automatic assembly
if (Primary.class == qualifier) {
abd.setPrimary(true);
}
//If @ Lazy annotation is configured, Bean initialization will be delayed, otherwise pre instantiation will be performed
else if (Lazy.class == qualifier) {
abd.setLazyInit(true);
}
//When assembling automatically, the Bean specified by the name assembly qualifier
else {
abd.addQualifier(new AutowireCandidateQualifier(qualifier));
}
}
}
for (BeanDefinitionCustomizer customizer : definitionCustomizers) {
customizer.customize(abd);
}
//Encapsulation of BeanDefinition
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(abd, beanName);
//Create the corresponding proxy object according to the scope
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
//Register Bean object
BeanDefinitionReaderUtils.registerBeanDefinition(definitionHolder, this.registry);
}
Let's briefly analyze the above source code. First, we will resolve the scope of the Bean through the resolveScopeMetadata() method. The default value is scopedproxymode No, which means that the proxy class will not be created later; Then, we will process the general annotations in the class through processCommonDefinitionAnnotations(), and resolve @ Lazy, @ prime, @ DependsOn, @ Role, @ Description annotation classes. If the @ DependsOn annotation is included, the container will ensure that the dependent Bean will be instantiated before instantiating the Bean; Next, create the proxy class applyscope dproxymode () according to the scope, which is mainly used in AOP aspect; Finally, register beans to the container through the registerBeanDefinition() method, and we are also familiar with the BeanDefinitionHolder object. Like in the initialization of XML container, we finally add BeanDefinition to ConcurrentHashMap.
This completes the direct parsing process of the configuration class. We also sorted out the timing diagram of the initialization process
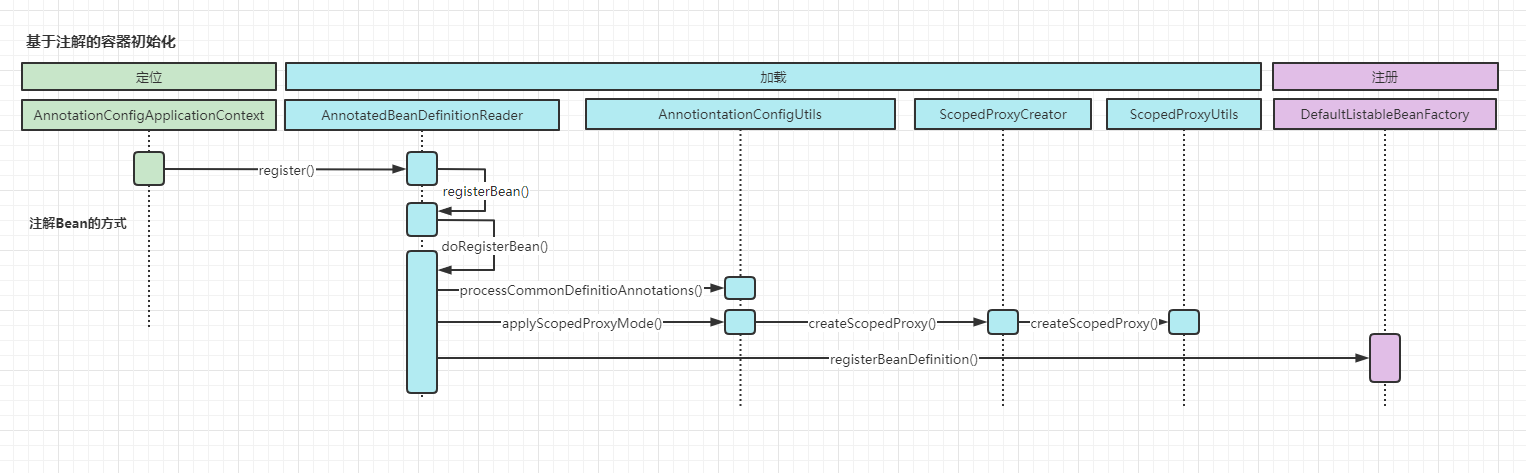
3. Scan all classes under the specified package path
Next, let's explore the analysis of scanning the specified package path. Let's take a look at scan (base packages); The specific implementation of the method,
public void scan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
this.scanner.scan(basePackages);
}
Here is this Scanner is the ClassPathBeanDefinitionScanner scanner initialized when annotationconfigapplicationcontext is created. The specific implementation is completed by it,
public int scan(String... basePackages) {
//Gets the number of registered beans in the container
int beanCountAtScanStart = this.registry.getBeanDefinitionCount();
//Scan specified packages
doScan(basePackages);
//Register annotation configuration processor
if (this.includeAnnotationConfig) {
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
//Returns the number of registered beans
return (this.registry.getBeanDefinitionCount() - beanCountAtScanStart);
}
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
//Traversal scan all specified packages
for (String basePackage : basePackages) {
//Call the method of the parent class ClassPathScanningCandidateComponentProvider
//Scan the given classpath to obtain the qualified Bean definition
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
//Traverse the scanned Bean
for (BeanDefinition candidate : candidates) {
//Gets the scope of the Bean
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
//Set scope
candidate.setScope(scopeMetadata.getScopeName());
//Generate unique Bean name
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
//Set the default value of the Bean's properties
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
//Parsing and processing general annotations
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
//Check whether the specified Bean needs to be registered in the container or conflicts in the container according to the Bean name
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
//Create the corresponding proxy object according to the scope
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
//Register Bean object
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
Through the source code, we know that the main processing logic is implemented in the doScan() method. We scan the specified package path to obtain all annotation classes under the package and return a Set set for temporary storage. Let's see how the findCandidateComponents() method parses and processes,
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
// Judge whether the filter rule contains @ Component annotation. In fact, @ Repository, @ Service, @ Controller, etc. contain @ component
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
return scanCandidateComponents(basePackage);
}
}
private Set<BeanDefinition> addCandidateComponentsFromIndex(CandidateComponentsIndex index, String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
Set<String> types = new HashSet<>();
for (TypeFilter filter : this.includeFilters) {
String stereotype = extractStereotype(filter);
if (stereotype == null) {
throw new IllegalArgumentException("Failed to extract stereotype from "+ filter);
}
types.addAll(index.getCandidateTypes(basePackage, stereotype));
}
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (String type : types) {
//Get metadata parser
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(type);
//Judge whether the configured filtering rules are met
if (isCandidateComponent(metadataReader)) {
AnnotatedGenericBeanDefinition sbd = new AnnotatedGenericBeanDefinition(
metadataReader.getAnnotationMetadata());
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Using candidate component class from index: " + type);
}
candidates.add(sbd);
}
else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + type);
}
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because matching an exclude filter: " + type);
}
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}
The code logic here is easy to understand, which is to judge whether the scanned class meets the parsing rules of annotation class. If so, it will be added to the Set collection and finally returned to the upper layer. In fact, this parsing rule is the default annotation rule of Spring initialized in the construction method of ClassPathBeanDefinitionScanner.
Deja vu as like as two peas, we also go back to the next level, and look at the code after findCandidateComponents(basePackage). We find that the next step is to traverse Bean in the Set set, and whether the logic hungry code is familiar or not is exactly the same as that in the class that we directly parsed and configured annotation. Finally, the registerBeanDefinition() method is called to register the bean object into the IOC container.
This completes the registration process of scanning all classes under the specified package path. We also sorted out the timing diagram of the initialization process

summary
After the source code analysis of the above long article and the sorting of sequence diagram and flow chart, we can know the initialization process of IOC container in detail, but we don't study some processing details too deeply. Those who are interested can find another opportunity to have a look. Finally, let's sort out the initialization process of the whole IOC from the level of top-level design:
- Locate the resource file location from classpath, file system, URL, etc. through ResourceLoader;
- The files for configuring Bean data will be abstracted into resources for processing;
- The container parses the Resource through the BeanDefinitionReader, and the actual processing process is entrusted to BeanDefinitionParserDelegate;
- Subclasses that implement the BeanDefinitionRegistry interface register BeanDefinition in the container;
- The essence of the container is to maintain a ConcurrentHashMap to save the BeanDefinition. Subsequent Bean operations are implemented around this ConcurrentHashMap;
- When using, we obtain these Bean objects through BeanFactory and ApplicaitonContext.
reference material:
- Spring official website documentation
- Tom's Spring notes
- Spring source code depth analysis book
To do one thing to the extreme is talent!