This is an analysis of the underlying principles of queue creation, synchronous/asynchronous functions, singletons, semaphores, and scheduling groups
Queue Creation
Here we are at libdispatch.dylib explores how queues are created
Bottom Source Analysis
-
Search dispatch_in source code Queue_ Create
dispatch_queue_t
dispatch_queue_create(const char *label, dispatch_queue_attr_t attr)
{
return _dispatch_lane_create_with_target(label, attr, DISPATCH_TARGET_QUEUE_DEFAULT, true);
}
-
Enter _ dispatch_lane_create_with_target(
DISPATCH_NOINLINE
static dispatch_queue_t
_dispatch_lane_create_with_target(const char *label, dispatch_queue_attr_t dqa,
dispatch_queue_t tq, bool legacy)
{
// dqai creation-
dispatch_queue_attr_info_t dqai = _dispatch_queue_attr_to_info(dqa);
//Step 1: Normalize parameters such as qos, overcommit, tq
...
//Split Queue Name
const void *vtable;
dispatch_queue_flags_t dqf = legacy ? DQF_MUTABLE : 0;
if (dqai.dqai_concurrent) { //vtable represents the type of class
// OS_dispatch_queue_concurrent
vtable = DISPATCH_VTABLE(queue_concurrent);
} else {
vtable = DISPATCH_VTABLE(queue_serial);
}
....
//Create queue and initialize
dispatch_lane_t dq = _dispatch_object_alloc(vtable,
sizeof(struct dispatch_lane_s)); // alloc
//According to dqai. Dqai_ The concurrent value determines whether the queue is serial or concurrent
_dispatch_queue_init(dq, dqf, dqai.dqai_concurrent ?
DISPATCH_QUEUE_WIDTH_MAX : 1, DISPATCH_QUEUE_ROLE_INNER |
(dqai.dqai_inactive ? DISPATCH_QUEUE_INACTIVE : 0)); // init
//Set queue label identifier
dq->dq_label = label;//label assignment
dq->dq_priority = _dispatch_priority_make((dispatch_qos_t)dqai.dqai_qos, dqai.dqai_relpri);//Priority Processing
...
//Similar to the binding of a class to a metaclass, not a direct inheritance relationship, but a model to a template relationship
dq->do_targetq = tq;
_dispatch_object_debug(dq, "%s", __func__);
return _dispatch_trace_queue_create(dq)._dq;//Study dq
}
_ dispatch_lane_create_with_target analysis
-
[Step 1] Create a dispatch_queue_attr_info object dqai of type dispatch_queue_attr_info_t by passing in dqa (i.e. queue type, serial, concurrent, etc.) via the _dispatch_queue_attr_to_info method to store the relevant attribute information of the queue
-
[Step 2] Set properties associated with the queue, such as quality of service qos, etc.
-
[Step 3] Splice the queue name, vtable, by DISPATCH_VTABLE, where DISPATCH_VTABLE is a macro definition, as shown below, so the type of queue is spliced by OS_dispatch_+queue type queue_concurrent
-
Serial Queue Type: OS_dispatch_queue_serial
-
Concurrent queue type: OS_dispatch_queue_concurrent, verify as follows
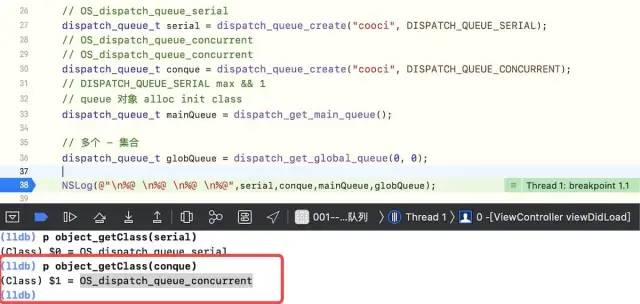
-
#define DISPATCH_VTABLE(name) DISPATCH_OBJC_CLASS(name) 👇 #define DISPATCH_OBJC_CLASS(name) (&DISPATCH_CLASS_SYMBOL(name)) 👇 #define DISPATCH_CLASS(name) OS_dispatch_##name
-
[Step 4] Initialize the queue, dq, by alloc+init, where in the _dispatch_queue_init parameter, the queue can be determined whether it is serial or concurrent based on the Boolean value of dqai.dqai_concurrent, and vtable indicates the type of queue, indicating that the queue is also an object
-
Enter _ Dispatch_ Object_ Alloc -> _ Os_ Object_ Alloc_ The realized method sets the direction of isa, from which you can verify that the queue is also an object
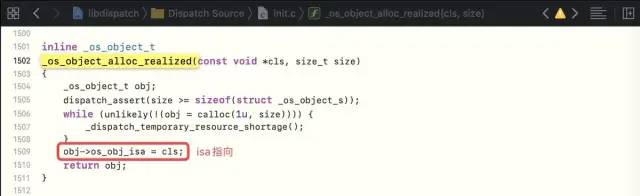
-
Enter _ dispatch_queue_init method, queue type is dispatch_queue_t, and set the related properties of the queue
-
-
[Step 5] Process the queue created by _dispatch_trace_queue_create, where _dispatch_trace_queue_create is a macro definition encapsulated by _dispatch_introspection_queue_create and returns the processed _dq
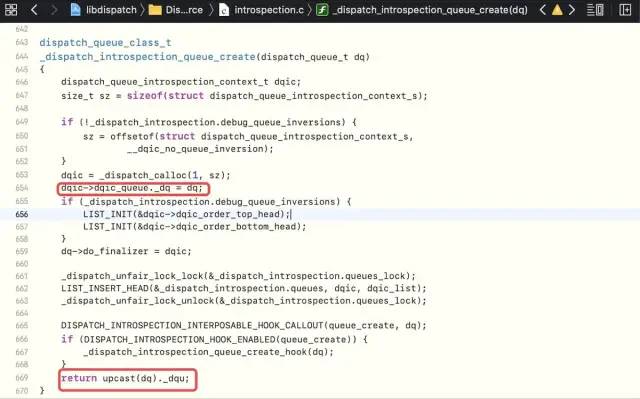
-
Enter _ Dispatch_ Introspection_ Queue_ Create_ Hook -> dispatch_ Introspection_ Queue_ Get_ Info -> _ Dispatch_ Introspection_ Lane_ Get_ As you can see in info, unlike our custom classes, the underlying implementation of the Create Queue is created using templates
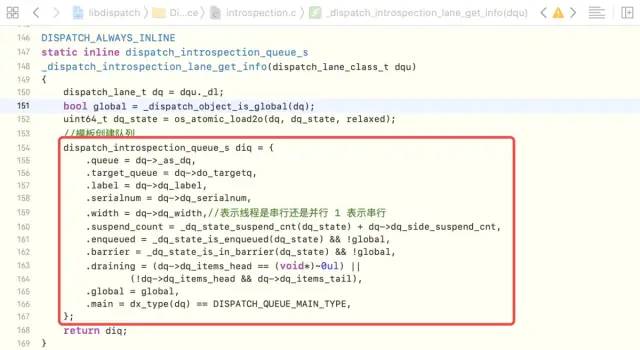
dispatch_queue_create Bottom Level Analysis-7
-
summary
-
Queue creation method dispatch_ Queue_ The second parameter in create, the queue type, determines the Max & 1 (used to distinguish between serial and concurrent) in the lower layer, where 1 represents serial
-
queue is also an object that requires the underlying layer to be created by alloc + init, and there is also a class in alloc that is stitched together by macro definitions and specifies the direction of isa
-
The process of creating the queue at the bottom is created by a template of type dispatch_introspection_queue_s Structures
Analysis of the underlying principle of functions
Mainly analyze the asynchronous function dispatch_async and synchronization function dispatch_sync
Asynchronous function
Enter dispatch_ Source implementation of async, mainly analyzing two functions
-
_ dispatch_continuation_init: Task wrapper function
-
_ dispatch_continuation_async: concurrent processing function
void
dispatch_async(dispatch_queue_t dq, dispatch_block_t work)//work task
{
dispatch_continuation_t dc = _dispatch_continuation_alloc();
uintptr_t dc_flags = DC_FLAG_CONSUME;
dispatch_qos_t qos;
// Task wrapper (work only works here) - Accept work - Save work - and Functional programming
// Save block
qos = _dispatch_continuation_init(dc, dq, work, 0, dc_flags);
//Concurrent Processing
_dispatch_continuation_async(dq, dc, qos, dc->dc_flags);
}
_ dispatch_continuation_init task wrapper
Enter _ Dispatch_ Continuation_ The init source implementation, primarily wrapping tasks and setting the thread's return function, is equivalent to initialization
DISPATCH_ALWAYS_INLINE
static inline dispatch_qos_t
_dispatch_continuation_init(dispatch_continuation_t dc,
dispatch_queue_class_t dqu, dispatch_block_t work,
dispatch_block_flags_t flags, uintptr_t dc_flags)
{
void *ctxt = _dispatch_Block_copy(work);//Copy Task
dc_flags |= DC_FLAG_BLOCK | DC_FLAG_ALLOCATED;
if (unlikely(_dispatch_block_has_private_data(work))) {
dc->dc_flags = dc_flags;
dc->dc_ctxt = ctxt;//assignment
// will initialize all fields but requires dc_flags & dc_ctxt to be set
return _dispatch_continuation_init_slow(dc, dqu, flags);
}
dispatch_function_t func = _dispatch_Block_invoke(work);//Encapsulate work - Asynchronous callback
if (dc_flags & DC_FLAG_CONSUME) {
func = _dispatch_call_block_and_release;//Callback function assignment-synchronous callback
}
return _dispatch_continuation_init_f(dc, dqu, ctxt, func, flags, dc_flags);
}
There are several main steps
-
Pass _ dispatch_Block_copy Copy Task
-
Pass _ dispatch_Block_invoke encapsulates the task, where _ dispatch_Block_invoke is a macro definition, and from the above analysis we know it's an asynchronous callback
#define _dispatch_Block_invoke(bb) \
((dispatch_function_t)((struct Block_layout *)bb)->invoke)
-
If synchronous, the callback function is assigned _ dispatch_call_block_and_release
-
Pass _ Dispatch_ Continuation_ Init_ The F method assigns a callback function, that is, f is a func, and stores it in an attribute
_ dispatch_continuation_async concurrent processing
In this function, the block callback is mainly executed
-
Enter _ Dispatch_ Continuation_ Source implementation of Async
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_continuation_async(dispatch_queue_class_t dqu,
dispatch_continuation_t dc, dispatch_qos_t qos, uintptr_t dc_flags)
{
#if DISPATCH_INTROSPECTION
if (!(dc_flags & DC_FLAG_NO_INTROSPECTION)) {
_dispatch_trace_item_push(dqu, dc);//Trace Log
}
#else
(void)dc_flags;
#endif
return dx_push(dqu._dq, dc, qos);//And dx_ Like invoke, they are macros
}
-
The key code is dx_push(dqu._dq, dc, qos), dx_push is a macro definition, as shown below
#define dx_push(x, y, z) dx_vtable(x)->dq_push(x, y, z)
-
And dq_among them Push needs to perform different functions depending on the type of queue
Symbol Breakpoint Debugging Execute Function
-
Run demo to determine which function is being executed by symbolic breakpoints, since it is a concurrent queue, by adding _ dispatch_lane_concurrent_push symbol breakpoint to see if you're going to get here
dispatch_queue_t conque = dispatch_queue_create("com.CJL.Queue", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(conque, ^{
NSLog(@"Asynchronous function");
});
-
Run discovery, walk really is _ dispatch_lane_concurrent_push
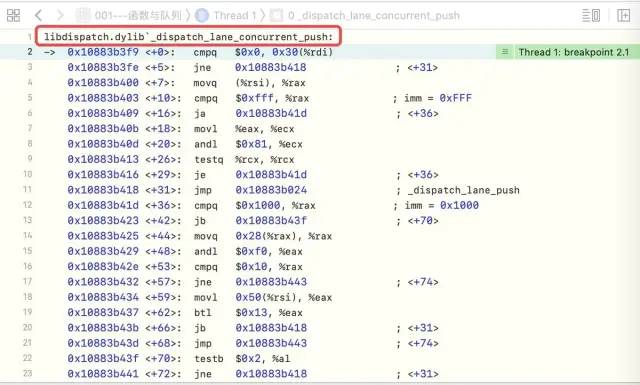
-
Enter _ dispatch_lane_concurrent_push source, found two steps, continue through the symbol breakpoint_ dispatch_continuation_redirect_push and _ dispatch_lane_push debugging, found that _ dispatch_continuation_redirect_push
-
Enter _ dispatch_continuation_redirect_push source, found again to dx_push, i.e. recursive, when synthesizing the previous queue creation, the queue is also an object, has a parent class, a root class, so it recursively executes the method to the root class
-
Next, through the _of the root class dispatch_root_queue_push symbol breakpoint to verify that the guess is correct, from the results of the operation, it is completely correct
-
Enter _ Dispatch_ Root_ Queue_ Push -> _ Dispatch_ Root_ Queue_ Push_ Inline ->_ Dispatch_ Root_ Queue_ Poke -> _ Dispatch_ Root_ Queue_ Poke_ Slow source code, after symbol breakpoint validation, is really here to see the source code implementation of this method, there are two main steps
-
Pass _ dispatch_root_queues_init method registration callback
-
Create threads through a do-while loop using pthread_create method
-
DISPATCH_NOINLINE
static void
_dispatch_root_queue_poke_slow(dispatch_queue_global_t dq, int n, int floor)
{
int remaining = n;
int r = ENOSYS;
_dispatch_root_queues_init();//A key
...
//do-while loop creates thread
do {
_dispatch_retain(dq); // released in _dispatch_worker_thread
while ((r = pthread_create(pthr, attr, _dispatch_worker_thread, dq))) {
if (r != EAGAIN) {
(void)dispatch_assume_zero(r);
}
_dispatch_temporary_resource_shortage();
}
} while (--remaining);
...
}
_dispatch_root_queues_init
-
Enter _ Dispatch_ Root_ Queues_ Init source implementation, found to be a dispatch_once_f singleton (see the underlying analysts for subsequent singletons, not explained here), where the func passed in is _dispatch_root_queues_init_once.
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_root_queues_init(void)
{
dispatch_once_f(&_dispatch_root_queues_pred, NULL, _dispatch_root_queues_init_once);
}
-
Enter _ Dispatch_ Root_ Queues_ Init_ The source code of the once whose call handles to different transactions are _ dispatch_worker_thread2
Its block callback executes a call path of: _ Dispatch_ Root_ Queues_ Init_ Once ->_ Dispatch_ Worker_ Thread2 -> _ Dispatch_ Root_ Queue_ Drain -> _ Dispatch_ Root_ Queue_ Drain -> _ Dispatch_ Continuation_ Pop_ Inline -> _ Dispatch_ Continuation_ Invoke_ Inline -> _ Dispatch_ Client_ Callout -> dispatch_ Call_ Block_ And_ Release
This path can be derived from breakpoints, bt printing stack information
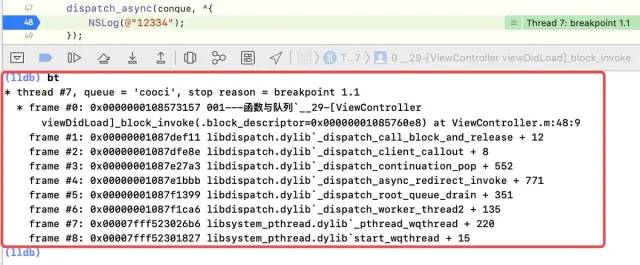
Explain
One thing to note here is that block callbacks for singletons are different from those for asynchronous functions
-
In the singleton, the func in the block callback is _ dispatch_Block_invoke(block)
-
In asynchronous functions, the func in the block callback is dispatch_call_block_and_release
summary
So, to sum up, the underlying analysis of asynchronous functions is as follows
-
[Preparations]: First, copy and encapsulate the asynchronous task and set the callback function func
-
[Block Callback]: The underlying layer, recursively through dx_push, redirects to the root queue, creates threads through pthread_creat e, and finally performs block callbacks through dx_invoke (note that dx_push and dx_invoke are paired)
Synchronization function
Enter dispatch_sync source implementation, the bottom of which is achieved through the raster function (see below for the bottom analysis of the raster function)
DISPATCH_NOINLINE
void
dispatch_sync(dispatch_queue_t dq, dispatch_block_t work)
{
uintptr_t dc_flags = DC_FLAG_BLOCK;
if (unlikely(_dispatch_block_has_private_data(work))) {
return _dispatch_sync_block_with_privdata(dq, work, dc_flags);
}
_dispatch_sync_f(dq, work, _dispatch_Block_invoke(work), dc_flags);
}
-
Enter _ dispatch_sync_f Source
-
View_ dispatch_sync_f_inline source, where width = 1 indicates a serial queue with two main points:
-
Fence: _ dispatch_barrier_sync_f (can be explained by the bottom analysis of the fence function below), it can be concluded that the bottom implementation of the synchronization function is actually a synchronization fence function
-
Deadlock:_ dispatch_sync_f_slow, deadlock if there is waiting for each other
-
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_sync_f_inline(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func, uintptr_t dc_flags)
{
if (likely(dq->dq_width == 1)) {//Represents a serial queue
return _dispatch_barrier_sync_f(dq, ctxt, func, dc_flags);//Fence
}
if (unlikely(dx_metatype(dq) != _DISPATCH_LANE_TYPE)) {
DISPATCH_CLIENT_CRASH(0, "Queue type doesn't support dispatch_sync");
}
dispatch_lane_t dl = upcast(dq)._dl;
// Global concurrent queues and queues bound to non-dispatch threads
// always fall into the slow case, see DISPATCH_ROOT_QUEUE_STATE_INIT_VALUE
if (unlikely(!_dispatch_queue_try_reserve_sync_width(dl))) {
return _dispatch_sync_f_slow(dl, ctxt, func, 0, dl, dc_flags);//deadlock
}
if (unlikely(dq->do_targetq->do_targetq)) {
return _dispatch_sync_recurse(dl, ctxt, func, dc_flags);
}
_dispatch_introspection_sync_begin(dl);//Processing current information
_dispatch_sync_invoke_and_complete(dl, ctxt, func DISPATCH_TRACE_ARG(
_dispatch_trace_item_sync_push_pop(dq, ctxt, func, dc_flags)));//block Execution and Release
}
_ dispatch_sync_f_slow deadlock
-
Enter _ dispatch_sync_f_slow, the current primary queue is suspended, blocked
-
Join a task to a queue, push joins the main queue, and _ dispatch_trace_item_push
-
Enter u DISPATCH_WAIT_FOR_QUEUE_u, Determines if dq is a waiting queue, gives a status state, and matches the status of dq to the queue on which the current task depends
-
Enter _ Dq_ State_ Drain_ Locked_ By -> _ Dispatch_ Lock_ Is_ Locked_ By source
DISPATCH_ALWAYS_INLINE
static inline bool
_dispatch_lock_is_locked_by(dispatch_lock lock_value, dispatch_tid tid)
{
// equivalent to _dispatch_lock_owner(lock_value) == tid
//XOR operation: same 0, different 1, if same, 0, 0 &any number is 0
//That is, to determine whether the current task to be waited for is the same as the task being executed, the common explanation is whether the task to be executed and waited is in the same queue
return ((lock_value ^ tid) & DLOCK_OWNER_MASK) == 0;
}
If the same queue is currently waiting and executing, that is, if the thread ID s are multiplied, a deadlock is created
Reasons why synchronous functions + concurrent queues execute sequentially
In _ Dispatch_ Sync_ Invoke_ And_ Complete -> _ Dispatch_ Sync_ Function_ Invoke_ There are three main steps in inline source code:
-
Push task into queue: _ dispatch_thread_frame_push
-
block callback for task execution: _ dispatch_client_callout
-
Queue tasks: _ dispatch_thread_frame_pop
As you can see from the implementation, tasks are first push ed in the queue, then block callbacks are performed, and tasks are pop ped, so the tasks are executed sequentially.
summary
The bottom level of the synchronization function is implemented as follows:
-
The bottom implementation of the synchronization function is actually the synchronization fence function
-
A deadlock can occur in a synchronization function if the queue currently being executed and the queue waiting are the same, creating a situation of waiting for each other
So, to sum up, the underlying implementation process for the synchronization function is shown in the figure.
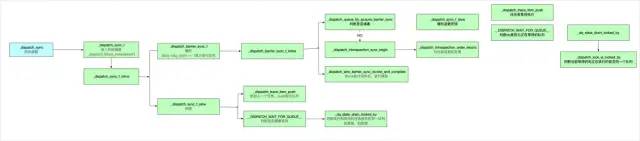
dispatch_sync Bottom Level Analysis-2
Singleton
In daily development, we typically use dispatch_from GCD Once to create the singleton, as shown below
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
NSLog(@"Single application");
});
First, for the singleton, we need to understand two things
-
[Reason for Execution Once] The process of a singleton is executed only once. How does the bottom level control it, that is, why can it only be executed once?
-
[Block Call Timing] When is a single block called?
With the following two questions, let's analyze the bottom of the case
-
Enter dispatch_once source implementation, bottom through dispatch_once_f implemented
-
Parameter 1:onceToken, which is a static variable, is unique because static variables defined at different locations are different
-
Parameter 2:block callback
-
void
dispatch_once(dispatch_once_t *val, dispatch_block_t block)
{
dispatch_once_f(val, block, _dispatch_Block_invoke(block));
}
-
Enter dispatch_once_f source, where val is an external onceToken static variable and func is _ dispatch_Block_invoke(block), where the bottom level of the singleton is divided into the following steps
-
If v equals DLOCK_ONCE_DONE, indicating that the task has been executed, return directly
-
If the lock fails after the task executes, go to _ dispatch_once_mark_done_if_quiesced function, stored again, sets the identifier to DLOCK_ONCE_DONE
-
Conversely, pass _ dispatch_once_gate_tryenter tries to enter the task, unlock it, and execute _ dispatch_once_callout performs a block callback
-
Convert val, also known as static variable, to dispatch_ Once_ Gate_ Variable l of type T
-
By os_atomic_load gets the identifier v of the task at this time
-
If a task is executing at this time, enter Task 2 again by _ Dispatch_ Once_ The wait function puts Task 2 into an infinite wait
-
DISPATCH_NOINLINE
void
dispatch_once_f(dispatch_once_t *val, void *ctxt, dispatch_function_t func)
{
dispatch_once_gate_t l = (dispatch_once_gate_t)val;
#if !DISPATCH_ONCE_INLINE_FASTPATH || DISPATCH_ONCE_USE_QUIESCENT_COUNTER
uintptr_t v = os_atomic_load(&l->dgo_once, acquire);//load
if (likely(v == DLOCK_ONCE_DONE)) {//Executed and returned directly
return;
}
#if DISPATCH_ONCE_USE_QUIESCENT_COUNTER
if (likely(DISPATCH_ONCE_IS_GEN(v))) {
return _dispatch_once_mark_done_if_quiesced(l, v);
}
#endif
#endif
if (_dispatch_once_gate_tryenter(l)) {//Try to enter
return _dispatch_once_callout(l, ctxt, func);
}
return _dispatch_once_wait(l);//Wait infinitely
}
_ dispatch_once_gate_tryenter unlock
View its source code, mainly through the underlying os_ Atomic_ The cmpxchg method is compared, and if the comparison is okay, the lock is made, that is, the task's identifier is set to DLOCK_ONCE_UNLOCKED
DISPATCH_ALWAYS_INLINE
static inline bool
_dispatch_once_gate_tryenter(dispatch_once_gate_t l)
{
return os_atomic_cmpxchg(&l->dgo_once, DLOCK_ONCE_UNLOCKED,
(uintptr_t)_dispatch_lock_value_for_self(), relaxed);//First compare, then change
}
_ dispatch_once_callout callback
Enter _ dispatch_once_callout source, mainly in two steps
-
_ dispatch_client_callout:block callback execution
-
_ dispatch_once_gate_broadcast: broadcast
DISPATCH_NOINLINE
static void
_dispatch_once_callout(dispatch_once_gate_t l, void *ctxt,
dispatch_function_t func)
{
_dispatch_client_callout(ctxt, func);//block call execution
_dispatch_once_gate_broadcast(l);//Broadcast: Tell people you belong, don't look for me
-
Enter _ dispatch_client_callout source code, which mainly performs a block callback, where f equals _ dispatch_Block_invoke(block), which is an asynchronous callback
#undef _dispatch_client_callout
void
_dispatch_client_callout(void *ctxt, dispatch_function_t f)
{
@try {
return f(ctxt);
}
@catch (...) {
objc_terminate();
}
}
-
Enter _ Dispatch_ Once_ Gate_ Broadcast -> _ Dispatch_ Once_ Mark_ Done source, mainly for dgo->dgo_ Once a value, and then the task's identifier is DLOCK_ONCE_DONE, that is, unlock
DISPATCH_ALWAYS_INLINE
static inline uintptr_t
_dispatch_once_mark_done(dispatch_once_gate_t dgo)
{
//If not, change directly to the same, then lock -- DLOCK_ONCE_DONE
return os_atomic_xchg(&dgo->dgo_once, DLOCK_ONCE_DONE, release);
}
summary
For the underlying implementation of the singleton, the main instructions are as follows:
-
[Principle of Single Execution Once]: In a GCD singleton, there are two important parameters, onceToken and block, where onceToken is a static variable with uniqueness and is encapsulated at the bottom as a variable l of type dispatch_once_gate_t. L is mainly used to obtain the correlation of the underlying atomic encapsulation, that is, the variable v, which queries the status of the task through v, if V is equal to DLOCK_ONCE_D ONE, indicating that the task has been processed once, directly return
-
[Block Call Timing]: If the task has not been executed at this time, the task will be locked by comparing C++ functions at the bottom level, that is, the task status is set to DLOCK_ONCE_UNLOCK, in order to ensure the uniqueness of the current task execution and prevent multiple definitions elsewhere. After the block callback function is executed, the current task will be unlocked when the execution is completed , set the current task status to DLOCK_ONCE_DONE, next time you come in, it will not execute, it will return directly
-
[Multithreaded impact]: If other tasks come in during the current task execution, they will enter an infinite number of waiting times because the current task has acquired a lock and is locked, and other tasks cannot acquire a lock
Fence function
There are two main types of raster functions commonly used in GCD
-
Synchronization Raster Function dispatch_barrier_sync (executed in the main thread): The previous task will not come here until it has been executed, but the synchronization fence function will block the thread and affect subsequent task execution
-
Asynchronous fence function dispatch_barrier_async: You won't be here until the previous tasks are done
The most direct function of a fence function is to control the order in which tasks are executed so that they are executed synchronously.
At the same time, there are a few points to note about the fence function
-
A fence function can only control the same concurrent queue
-
When a synchronization fence is added to the queue, the current thread is locked until the tasks preceding the synchronization fence and the synchronization fence task itself are executed before the current thread opens and proceeds with the next sentence of code.
-
When using the fence function. It makes sense to use a custom queue. If you are using a serial queue or a system-provided global concurrent queue, this raster function does the same thing as a synchronization function and has no meaning.
Code Debugging
There are four tasks in total, of which the first two are dependent, that is, when Task 1 finishes executing and Task 2 executes, you can use the fence function
-
Asynchronous fence functions do not block the main thread, but queues are blocked asynchronously

-
Synchronization fence function blocks main thread, synchronization block is current thread
summary
-
Asynchronous fence functions block queues and must be custom concurrent queues without affecting the execution of main thread tasks
-
The Synchronization Barrier function blocks the thread and is the main thread, affecting the execution of other tasks on the main thread
Use scenarios
Raster functions can be used for data security as well as for task dependencies
The reason for the crash is that the data keeps retaining and releasing, and has started releasing before the data has been retained, which is equivalent to adding an empty data to release
modify
-
By adding a fence function
- (void)use041{
dispatch_queue_t concurrentQueue = dispatch_queue_create("com.CJL.Queue", DISPATCH_QUEUE_CONCURRENT);
NSMutableArray *array = [NSMutableArray array];
for (int i = 0; i<100000; i++) {
dispatch_async(concurrentQueue, ^{
dispatch_barrier_async(concurrentQueue, ^{
[array addObject:[NSString stringWithFormat:@"%d", i]];
});
});
}
}
-
Use mutex @synchronized (self) {}
- (void)use041{
dispatch_queue_t concurrentQueue = dispatch_queue_create("com.CJL.Queue", DISPATCH_QUEUE_CONCURRENT);
NSMutableArray *array = [NSMutableArray array];
for (int i = 0; i<100000; i++) {
dispatch_async(concurrentQueue, ^{
@synchronized (self) {
[array addObject:[NSString stringWithFormat:@"%d", i]];
};
});
}
}
Be careful
-
If a global queue is used in a fence function, the run crashes because the system is also using a global concurrent queue and the fence intercepts the system at the same time, so it crashes
-
If you change a custom concurrent queue to a serial queue, which is serial, the serial queue itself is synchronized sequentially, adding a fence would waste performance
-
Barrier functions can only be blocked once
Base analysis of asynchronous fence functions
Enter dispatch_barrier_async source implementation, its underlying implementation and dispatch_ Like async, there is no more analysis here and you can explore for yourself if you are interested
#ifdef __BLOCKS__
void
dispatch_barrier_async(dispatch_queue_t dq, dispatch_block_t work)
{
dispatch_continuation_t dc = _dispatch_continuation_alloc();
uintptr_t dc_flags = DC_FLAG_CONSUME | DC_FLAG_BARRIER;
dispatch_qos_t qos;
qos = _dispatch_continuation_init(dc, dq, work, 0, dc_flags);
_dispatch_continuation_async(dq, dc, qos, dc_flags);
}
#endif
Synchronized Bar Function Bottom Level Analysis
Enter dispatch_barrier_sync source, implemented as follows
void
dispatch_barrier_sync(dispatch_queue_t dq, dispatch_block_t work)
{
uintptr_t dc_flags = DC_FLAG_BARRIER | DC_FLAG_BLOCK;
if (unlikely(_dispatch_block_has_private_data(work))) {
return _dispatch_sync_block_with_privdata(dq, work, dc_flags);
}
_dispatch_barrier_sync_f(dq, work, _dispatch_Block_invoke(work), dc_flags);
}
_dispatch_barrier_sync_f_inline
Enter _ Dispatch_ Barrier_ Sync_ F -> _ Dispatch_ Barrier_ Sync_ F_ Inline source
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_barrier_sync_f_inline(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func, uintptr_t dc_flags)
{
dispatch_tid tid = _dispatch_tid_self();//Gets the id of the thread, which is the unique identity of the thread
...
//Determine thread state, need not wait, recycle
if (unlikely(!_dispatch_queue_try_acquire_barrier_sync(dl, tid))) {//Fence functions also deadlock
return _dispatch_sync_f_slow(dl, ctxt, func, DC_FLAG_BARRIER, dl,//No recycling
DC_FLAG_BARRIER | dc_flags);
}
//Verify that the target exists and, if so, add a recursive look-up of the fence function to wait
if (unlikely(dl->do_targetq->do_targetq)) {
return _dispatch_sync_recurse(dl, ctxt, func,
DC_FLAG_BARRIER | dc_flags);
}
_dispatch_introspection_sync_begin(dl);
_dispatch_lane_barrier_sync_invoke_and_complete(dl, ctxt, func
DISPATCH_TRACE_ARG(_dispatch_trace_item_sync_push_pop(
dq, ctxt, func, dc_flags | DC_FLAG_BARRIER)));//implement
}
The source code is mainly divided into the following parts
-
Pass _ dispatch_tid_self gets the thread ID
-
Pass _ dispatch_queue_try_acquire_barrier_sync Judges Thread State
dispatch_barrier_sync Bottom Level Analysis-1
-
Enter _ dispatch_queue_try_acquire_barrier_sync_and_suspend, release it here
-
-
Pass _ dispatch_sync_recurse recursively finds the target of a raster function
-
Pass _ dispatch_introspection_sync_begin processes forward information
-
Pass _ dispatch_lane_barrier_sync_invoke_and_complete Executes block and Releases
Semaphore
Semaphores are generally used to synchronize tasks, similar to mutexes, where the user can control the maximum number of concurrent GCD s as needed.
//Semaphore dispatch_semaphore_t sem = dispatch_semaphore_create(1); dispatch_semaphore_wait(sem, DISPATCH_TIME_FOREVER); dispatch_semaphore_signal(sem);
Let's analyze its underlying principles
dispatch_semaphore_create creation
The underlying implementation of this function is to initialize the semaphore and set the maximum concurrency of the GCD, which must be greater than 0
dispatch_semaphore_t
dispatch_semaphore_create(long value)
{
dispatch_semaphore_t dsema;
// If the internal value is negative, then the absolute of the value is
// equal to the number of waiting threads. Therefore it is bogus to
// initialize the semaphore with a negative value.
if (value < 0) {
return DISPATCH_BAD_INPUT;
}
dsema = _dispatch_object_alloc(DISPATCH_VTABLE(semaphore),
sizeof(struct dispatch_semaphore_s));
dsema->do_next = DISPATCH_OBJECT_LISTLESS;
dsema->do_targetq = _dispatch_get_default_queue(false);
dsema->dsema_value = value;
_dispatch_sema4_init(&dsema->dsema_sema, _DSEMA4_POLICY_FIFO);
dsema->dsema_orig = value;
return dsema;
}
dispatch_semaphore_wait locking
The source code for this function is implemented as follows, and its main purpose is to pass the semaphore dsema through os_atomic_dec2o does the--operation, which is internally atomic_of the C++ executed Fetch_ Sub_ Explicit method
-
If the value is greater than or equal to 0, the operation is invalid and the execution is successful
-
If value equals LONG_MIN, the system throws a crash
-
Long wait if value is less than 0
long
dispatch_semaphore_wait(dispatch_semaphore_t dsema, dispatch_time_t timeout)
{
// dsema_value proceeds--operation
long value = os_atomic_dec2o(dsema, dsema_value, acquire);
if (likely(value >= 0)) {//Indicates that the execution is invalid, that is, the execution was successful
return 0;
}
return _dispatch_semaphore_wait_slow(dsema, timeout);//Long wait
}
Where os_ Atomic_ The macro definition of dec2o is converted as follows
os_atomic_inc2o(p, f, m)
👇
os_atomic_sub2o(p, f, 1, m)
👇
_os_atomic_c11_op((p), (v), m, sub, -)
👇
_os_atomic_c11_op((p), (v), m, add, +)
👇
({ _os_atomic_basetypeof(p) _v = (v), _r = \
atomic_fetch_##o##_explicit(_os_atomic_c11_atomic(p), _v, \
memory_order_##m); (__typeof__(_r))(_r op _v); })
Substitute specific values as
os_atomic_dec2o(dsema, dsema_value, acquire); os_atomic_sub2o(dsema, dsema_value, 1, m) os_atomic_sub(dsema->dsema_value, 1, m) _os_atomic_c11_op(dsema->dsema_value, 1, m, sub, -) _r = atomic_fetch_sub_explicit(dsema->dsema_value, 1), Equivalent to dsema->dsema_value - 1
-
Enter _ Dispatch_ Semaphore_ Wait_ Source implementation of slow, which does different things depending on the timeout of the wait event when the value is less than 0
dispatch_semaphore_wait Bottom Level Analysis-1
dispatch_semaphore_signal unlock
The source code for this function is as follows, and its core is also through os_ Atomic_ The inc2o function performs a ++ operation on value, os_atomic_inc2o is internally atomic_via C++. Fetch_ Add_ Explicit
-
If the value is greater than 0, the operation is invalid and the execution is successful
-
If value equals 0, enter long wait
long
dispatch_semaphore_signal(dispatch_semaphore_t dsema)
{
//signal to value is +
long value = os_atomic_inc2o(dsema, dsema_value, release);
if (likely(value > 0)) {//Returns 0, indicating that the current execution is invalid, equivalent to successful execution
return 0;
}
if (unlikely(value == LONG_MIN)) {
DISPATCH_CLIENT_CRASH(value,
"Unbalanced call to dispatch_semaphore_signal()");
}
return _dispatch_semaphore_signal_slow(dsema);//Enter Long Wait
}
Where os_ Atomic_ The macro definition of dec2o is converted as follows
os_atomic_inc2o(p, f, m)
👇
os_atomic_add2o(p, f, 1, m)
👇
os_atomic_add(&(p)->f, (v), m)
👇
_os_atomic_c11_op((p), (v), m, add, +)
👇
({ _os_atomic_basetypeof(p) _v = (v), _r = \
atomic_fetch_##o##_explicit(_os_atomic_c11_atomic(p), _v, \
memory_order_##m); (__typeof__(_r))(_r op _v); })
Substitute specific values as
os_atomic_inc2o(dsema, dsema_value, release); os_atomic_add2o(dsema, dsema_value, 1, m) os_atomic_add(&(dsema)->dsema_value, (1), m) _os_atomic_c11_op((dsema->dsema_value), (1), m, add, +) _r = atomic_fetch_add_explicit(dsema->dsema_value, 1), Equivalent to dsema->dsema_value + 1
summary
-
dispatch_semaphore_create is essentially the initialization limit
-
dispatch_semaphore_wait is the value of a semaphore -- that is, the lock operation
-
dispatch_semaphore_signal is a ++, or unlock, operation on the value of a semaphore
So, to sum up, the underlying operation of the semaphore correlation function is shown in the figure.
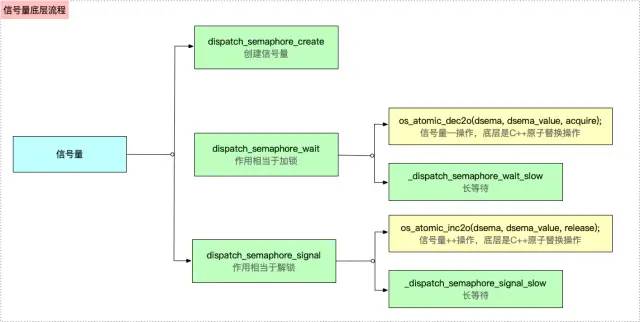
Underlying semaphore analysis process
Dispatch Group
The most direct role of a scheduling group is to control the order in which tasks are executed, as follows
dispatch_group_create Create Group dispatch_group_async Group Entry Task dispatch_group_notify Entry Task Execution Completion Notification dispatch_group_wait Task Entry Wait Time //Inbound and outbound groups are usually used in pairs dispatch_group_enter Enter Group dispatch_group_leave Out of Group
Use
Assuming you have two tasks, you need to wait for both to complete before updating the UI, and you can use a dispatch group
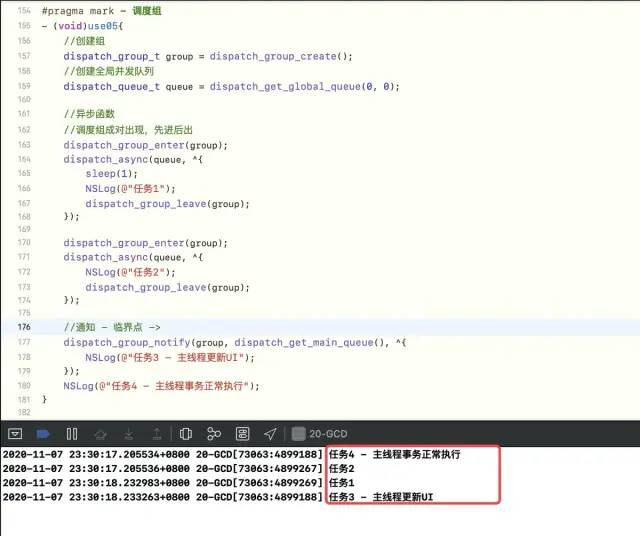
Use
-
[Modify 1] If dispatch_group_notify is moved to the front, can it be executed?
Yes, but notify will execute as long as there are enter-leave pairwise matches, not until both groups are executed. This means that as long as enter-leaves are paired, they can be executed
-
[Modify 2] Add another entry, that is, enter:wait is 3:2. Can you execute notify?
No, it will wait for a leave before notify is executed
-
[Modify 3] If enter:wait is 2:3, can notify be executed?
Crash, because enter-leave is not right, crash is inside because async is delayed
dispatch_group_create Create Group
The main thing is to create the group and set the property, where the value of the group is 0
-
Enter dispatch_group_create Source
dispatch_group_t
dispatch_group_create(void)
{
return _dispatch_group_create_with_count(0);
}
-
Enter _ dispatch_group_create_with_count source code, where the group object property is assigned a value and the group object is returned, where n equals 0
DISPATCH_ALWAYS_INLINE
static inline dispatch_group_t
_dispatch_group_create_with_count(uint32_t n)
{
//Create a group object of type OS_dispatch_group
dispatch_group_t dg = _dispatch_object_alloc(DISPATCH_VTABLE(group),
sizeof(struct dispatch_group_s));
//group object assignment
dg->do_next = DISPATCH_OBJECT_LISTLESS;
dg->do_targetq = _dispatch_get_default_queue(false);
if (n) {
os_atomic_store2o(dg, dg_bits,
(uint32_t)-n * DISPATCH_GROUP_VALUE_INTERVAL, relaxed);
os_atomic_store2o(dg, do_ref_cnt, 1, relaxed); // <rdar://22318411>
}
return dg;
}
dispatch_group_enter into group
Enter dispatch_group_enter source, via os_atomic_sub_orig2o to dg->dg. Bits do -- operate on, process numbers
void
dispatch_group_enter(dispatch_group_t dg)
{
// The value is decremented on a 32bits wide atomic so that the carry
// for the 0 -> -1 transition is not propagated to the upper 32bits.
uint32_t old_bits = os_atomic_sub_orig2o(dg, dg_bits,//Atomic Decrease 0->-1
DISPATCH_GROUP_VALUE_INTERVAL, acquire);
uint32_t old_value = old_bits & DISPATCH_GROUP_VALUE_MASK;
if (unlikely(old_value == 0)) {//If old_value
_dispatch_retain(dg); // <rdar://problem/22318411>
}
if (unlikely(old_value == DISPATCH_GROUP_VALUE_MAX)) {//When the critical value is reached, crash will be reported
DISPATCH_CLIENT_CRASH(old_bits,
"Too many nested calls to dispatch_group_enter()");
}
}
dispatch_group_leave out of group
-
Enter dispatch_group_leave source
-
-1 to 0, i.e. ++ operation
-
Depending on the state, do-while loops, waking up to perform block tasks
-
If 0 + 1 = 1, enter-leave is unbalanced, that is, leave calls more than once, crash
-
void
dispatch_group_leave(dispatch_group_t dg)
{
// The value is incremented on a 64bits wide atomic so that the carry for
// the -1 -> 0 transition increments the generation atomically.
uint64_t new_state, old_state = os_atomic_add_orig2o(dg, dg_state,//Atomic Increment+
DISPATCH_GROUP_VALUE_INTERVAL, release);
uint32_t old_value = (uint32_t)(old_state & DISPATCH_GROUP_VALUE_MASK);
//Wake up according to status
if (unlikely(old_value == DISPATCH_GROUP_VALUE_1)) {
old_state += DISPATCH_GROUP_VALUE_INTERVAL;
do {
new_state = old_state;
if ((old_state & DISPATCH_GROUP_VALUE_MASK) == 0) {
new_state &= ~DISPATCH_GROUP_HAS_WAITERS;
new_state &= ~DISPATCH_GROUP_HAS_NOTIFS;
} else {
// If the group was entered again since the atomic_add above,
// we can't clear the waiters bit anymore as we don't know for
// which generation the waiters are for
new_state &= ~DISPATCH_GROUP_HAS_NOTIFS;
}
if (old_state == new_state) break;
} while (unlikely(!os_atomic_cmpxchgv2o(dg, dg_state,
old_state, new_state, &old_state, relaxed)));
return _dispatch_group_wake(dg, old_state, true);//awaken
}
//-1 -> 0, 0+1 -> 1, i.e. multiple leave, crash is reported, simply enter-leave imbalance
if (unlikely(old_value == 0)) {
DISPATCH_CLIENT_CRASH((uintptr_t)old_value,
"Unbalanced call to dispatch_group_leave()");
}
}
-
Enter _ dispatch_group_wake source, do-while loop asynchronous hit, call _ dispatch_continuation_async execution
DISPATCH_NOINLINE
static void
_dispatch_group_wake(dispatch_group_t dg, uint64_t dg_state, bool needs_release)
{
uint16_t refs = needs_release ? 1 : 0; // <rdar://problem/22318411>
if (dg_state & DISPATCH_GROUP_HAS_NOTIFS) {
dispatch_continuation_t dc, next_dc, tail;
// Snapshot before anything is notified/woken <rdar://problem/8554546>
dc = os_mpsc_capture_snapshot(os_mpsc(dg, dg_notify), &tail);
do {
dispatch_queue_t dsn_queue = (dispatch_queue_t)dc->dc_data;
next_dc = os_mpsc_pop_snapshot_head(dc, tail, do_next);
_dispatch_continuation_async(dsn_queue, dc,
_dispatch_qos_from_pp(dc->dc_priority), dc->dc_flags);//block task execution
_dispatch_release(dsn_queue);
} while ((dc = next_dc));//do-while loop, hit asynchronous task
refs++;
}
if (dg_state & DISPATCH_GROUP_HAS_WAITERS) {
_dispatch_wake_by_address(&dg->dg_gen);//Address Release
}
if (refs) _dispatch_release_n(dg, refs);//Reference Release
}
-
Enter _ dispatch_continuation_async source
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_continuation_async(dispatch_queue_class_t dqu,
dispatch_continuation_t dc, dispatch_qos_t qos, uintptr_t dc_flags)
{
#if DISPATCH_INTROSPECTION
if (!(dc_flags & DC_FLAG_NO_INTROSPECTION)) {
_dispatch_trace_item_push(dqu, dc);//Trace Log
}
#else
(void)dc_flags;
#endif
return dx_push(dqu._dq, dc, qos);//And dx_ Like invoke, they are macros
}
This step is consistent with the block callback execution of the asynchronous function and is not explained here
dispatch_group_notify notification
-
Enter dispatch_group_notify source if old_ The state is equal to 0 and is ready to be released
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_group_notify(dispatch_group_t dg, dispatch_queue_t dq,
dispatch_continuation_t dsn)
{
uint64_t old_state, new_state;
dispatch_continuation_t prev;
dsn->dc_data = dq;
_dispatch_retain(dq);
//Get the state identification code of the underlying dg by os_ Atomic_ Stor2o gets the value from the dg status code to the OS underlying state
prev = os_mpsc_push_update_tail(os_mpsc(dg, dg_notify), dsn, do_next);
if (os_mpsc_push_was_empty(prev)) _dispatch_retain(dg);
os_mpsc_push_update_prev(os_mpsc(dg, dg_notify), prev, dsn, do_next);
if (os_mpsc_push_was_empty(prev)) {
os_atomic_rmw_loop2o(dg, dg_state, old_state, new_state, release, {
new_state = old_state | DISPATCH_GROUP_HAS_NOTIFS;
if ((uint32_t)old_state == 0) { //If equal to 0, it can be released
os_atomic_rmw_loop_give_up({
return _dispatch_group_wake(dg, new_state, false);//awaken
});
}
});
}
}
Except that leave can pass through _ dispatch_group_wake up, where dispatch_ Group_ Notfy can also wake up
-
Where os_mpsc_push_update_tail is a macro definition used to get the status code of dg
#define os_mpsc_push_update_tail(Q, tail, _o_next) ({ \
os_mpsc_node_type(Q) _tl = (tail); \
os_atomic_store2o(_tl, _o_next, NULL, relaxed); \
os_atomic_xchg(_os_mpsc_tail Q, _tl, release); \
})
dispatch_group_async
-
Enter dispatch_group_async source code, mainly wrapping and asynchronous processing tasks
#ifdef __BLOCKS__
void
dispatch_group_async(dispatch_group_t dg, dispatch_queue_t dq,
dispatch_block_t db)
{
dispatch_continuation_t dc = _dispatch_continuation_alloc();
uintptr_t dc_flags = DC_FLAG_CONSUME | DC_FLAG_GROUP_ASYNC;
dispatch_qos_t qos;
//Task wrapper
qos = _dispatch_continuation_init(dc, dq, db, 0, dc_flags);
//Processing Tasks
_dispatch_continuation_group_async(dg, dq, dc, qos);
}
#endif
-
Enter _ dispatch_continuation_group_async source, mainly encapsulated dispatch_group_enter into group operation
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_continuation_group_async(dispatch_group_t dg, dispatch_queue_t dq,
dispatch_continuation_t dc, dispatch_qos_t qos)
{
dispatch_group_enter(dg);//Enter Group
dc->dc_data = dg;
_dispatch_continuation_async(dq, dc, qos, dc->dc_flags);//Asynchronous operation
}
-
Enter _ dispatch_continuation_async source code that performs the general underlying operation of an asynchronous function. Now that there is enter, there must be leave, we guess that after the block executes, it implicitly executes leave, printing stack information through breakpoint debugging
-
Search_ dispatch_client_callout, in _ Dispatch_ Continuation_ With_ Group_ In invoke
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_continuation_with_group_invoke(dispatch_continuation_t dc)
{
struct dispatch_object_s *dou = dc->dc_data;
unsigned long type = dx_type(dou);
if (type == DISPATCH_GROUP_TYPE) {//If it is a dispatch group type
_dispatch_client_callout(dc->dc_ctxt, dc->dc_func);//block callback
_dispatch_trace_item_complete(dc);
dispatch_group_leave((dispatch_group_t)dou);//Out of Group
} else {
DISPATCH_INTERNAL_CRASH(dx_type(dou), "Unexpected object type");
}
So the perfect proof of dispatch_ Group_ The bottom layer of async encapsulates enter-leave
summary
-
enter-leave can be paired, far or near
-
Dispatch_ Group_ At the bottom level, enter performs a -- operation on the group's value through a C++ function (that is, 0 -> -1)
-
Dispatch_ Group_ At the bottom level, leave uses the C++ function to ++ operate on the group value (i.e. -1 -> 0)
-
Dispatch_ Group_ Notfy at the bottom is primarily to determine if the group's state is equal to 0 and notify when it is equal to 0
-
Wake-up of a block task, via dispatch_group_leave, or dispatch_group_notify
-
dispatch_group_async is equivalent to enter-leave, and its underlying implementation is enter-leave
The underlying analysis process of the dispatch group
dispatch_source
Sketch
Dispatch_ Sorce is the underlying data type used to coordinate the processing of specific underlying system events.
Dispatch_ Sorce replaces the asynchronous callback function to process related events. When configuring a dispatch, you need to specify the monitored events, the dispatch queue, and the code (block or function) that handles the events. When an event occurs, dispatch source submits your block or function to the specified queue to execute
Use Dispatch Source instead of dispatch_ The only reason for async is to take advantage of joins.
The general flow of a join is to call a function dispatch_on any thread Source_ Merge_ After data, Dispatch Source executes a pre-defined handle, which can be simply understood as a block, called Custom event, a user event. This is an event that dispatch source supports.
Simply put: this event is what you call dispatch_ Source_ Merge_ The data function signals itself.
A handle is a pointer to a pointer. It points to a class or structure, which is closely related to the system. There is also a common handle, HANDLE.
-
Instance Handle HINSTANCE
-
Bitmap handle HBITMAP
-
Device Table Handle HDC
-
Icon Handle HICON
Characteristic
-
Its CPU load is very small, Jinling does not occupy resources
-
Advantages of joins
Use
-
Create dispatch source
dispatch_source_t source = dispatch_source_create(dispatch_source_type_t type, uintptr_t handle, unsigned long mask, dispatch_queue_t queue)
| parameter | Explain |
|---|---|
| type | Events handled by dispatch source |
| handle | It can be understood as a handle, index, or id, and if you want to listen on a process, you need to pass in the process ID |
| mask | Can be understood as a description, providing a more detailed description so that it knows exactly what to listen to |
| queue | A queue required by the custom source to handle all response handles |
Dispatch Source Kinds
There are several types of type
| type | Explain |
|---|---|
| DISPATCH_SOURCE_TYPE_DATA_ADD | Custom events, variable increments |
| DISPATCH_SOURCE_TYPE_DATA_OR | Custom Events, Variable OR |
| DISPATCH_SOURCE_TYPE_MACH_SEND | MACH Port Send |
| DISPATCH_SOURCE_TYPE_MACH_RECV | MACH Port Receive |
| DISPATCH_SOURCE_TYPE_MEMORYPRESSURE | Memory pressure (Note: Available after iOS8) |
| DISPATCH_SOURCE_TYPE_PROC | Process monitoring, such as process exit, creation of one or more sub-threads, process receiving UNIX signals |
| DISPATCH_SOURCE_TYPE_READ | IO operations, such as read responses to file operations, socket operations |
| DISPATCH_SOURCE_TYPE_SIGNAL | Response when a UNIX signal is received |
| DISPATCH_SOURCE_TYPE_TIMER | timer |
| DISPATCH_SOURCE_TYPE_VNODE | File status monitors, files are deleted, moved, renamed |
| DISPATCH_SOURCE_TYPE_WRITE | IO operations, such as write responses to file operations, socket operations |
Be careful:
-
DISPATCH_SOURCE_TYPE_DATA_ADD
When an event triggers frequently at the same time, Dispatch Source accumulates these responses as ADD s and waits until the system is idle for final processing. If the trigger frequency is scattered, Dispatch Source will respond to these events separately. -
DISPATCH_SOURCE_TYPE_DATA_OR, like above, is a custom event, but it is accumulated as an OR
Common Functions
//Suspend queue dispatch_suspend(queue) //Dispatch source creation is suspended by default and must be restored before dispatching source dispatch handler dispatch_resume(source) //When sending events to the dispatch source, it is important to note that you cannot pass a value of 0 (the event will not be triggered) or a negative number. dispatch_source_merge_data //Sets the block that responds to the dispatch source event and runs on the queue specified by the dispatch source dispatch_source_set_event_handler //Get data for the dispatch source dispatch_source_get_data //Get dispatch source creation, which calls dispatch_ Source_ The second parameter of create uintptr_t dispatch_source_get_handle(dispatch_source_t source); //Get dispatch source creation, which calls dispatch_ Source_ The third parameter of create unsigned long dispatch_source_get_mask(dispatch_source_t source); cancel dispatch Event Processing for Sources--That is, no longer called block. If called dispatch_suspend Just pause dispatch Source. void dispatch_source_cancel(dispatch_source_t source); //Detects whether the dispatch source has been cancelled and returns a non-zero value indicating that the dispatch source has been cancelled long dispatch_source_testcancel(dispatch_source_t source); //A block called when the dispatch source cancels, typically used to close files or socket s, etc., to release related resources void dispatch_source_set_cancel_handler(dispatch_source_t source, dispatch_block_t cancel_handler); //Can be used to set the dispatch source to call the block at startup and release it when the call is complete. This function can also be called whenever the dispatch source is running. void dispatch_source_set_registration_handler(dispatch_source_t source, dispatch_block_t registration_handler);
Use scenarios
Often used to count down Authentication Codes because dispatch_ Instead of relying on Runloop, source interacts directly with the underlying kernel for greater accuracy.
- (void)use033{
//Countdown time
__block int timeout = 3;
//Create Queue
dispatch_queue_t globalQueue = dispatch_get_global_queue(0, 0);
//Create timer
dispatch_source_t timer = dispatch_source_create(DISPATCH_SOURCE_TYPE_TIMER, 0, 0, globalQueue);
//Set 1s trigger once, 0s error
/*
- source Assignment Source
- start Control the time when the timer first triggers. The parameter type is dispatch_time_t, this is an opaque type, and we can't manipulate it directly. We need dispatch_time and dispatch_ The walltime function creates them. In addition, the constant DISPATCH_TIME_NOW and DISPATCH_TIME_FOREVER is often useful.
- interval Interval Time
- leeway Precision of timer trigger
*/
dispatch_source_set_timer(timer,dispatch_walltime(NULL, 0),1.0*NSEC_PER_SEC, 0);
//Triggered Events
dispatch_source_set_event_handler(timer, ^{
//End of countdown, close
if (timeout <= 0) {
//Cancel dispatch source
dispatch_source_cancel(timer);
}else{
timeout--;
dispatch_async(dispatch_get_main_queue(), ^{
//Operations to update the main interface
NSLog(@"Count down - %d", timeout);
});
}
});
//Start executing dispatch source
dispatch_resume(timer);
}