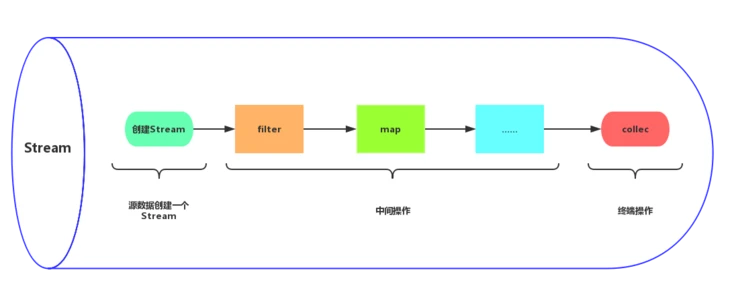
Streaming programming
For the Java language, our most commonly used object-oriented programming belongs to imperative programming. In Java 8, functional programming was introduced.
Before Java 8, it was troublesome to process and sort the set, operate the set many times, and return some specific sets that met the requirements after processing the set. We usually need to traverse the set and write a lot of redundant code. Therefore, Java 8 introduces Stream based on Stream programming to perform a series of operations on collections.
Stream is neither a collection element nor a data structure. It is equivalent to an advanced version of Iterator. You can't repeatedly traverse the data in it. Like water, it flows and never returns. It is different from ordinary iterators in that it can traverse in parallel. Ordinary iterators can only be serial and execute in one thread.
Stream
Stream is not a container. It just enhances the function of the container and adds many convenient operations, such as finding, filtering, grouping, sorting and so on. There are two execution modes: serial and parallel. The parallel mode makes full use of the advantages of multi-core processor, uses fork/join framework to split tasks, and improves the execution speed at the same time. In short, stream provides an efficient and easy-to-use way to process data.
- The serial stream operation is completed successively in one thread;
- Parallel flow is completed in multiple threads.
Stream characteristics
- Stream itself does not store elements.
- The operation of Stream does not change the source object. Instead, they return a new Stream that holds the result.
- Stream operations are deferred. It waits until the results are needed. That is, when performing terminal operation.
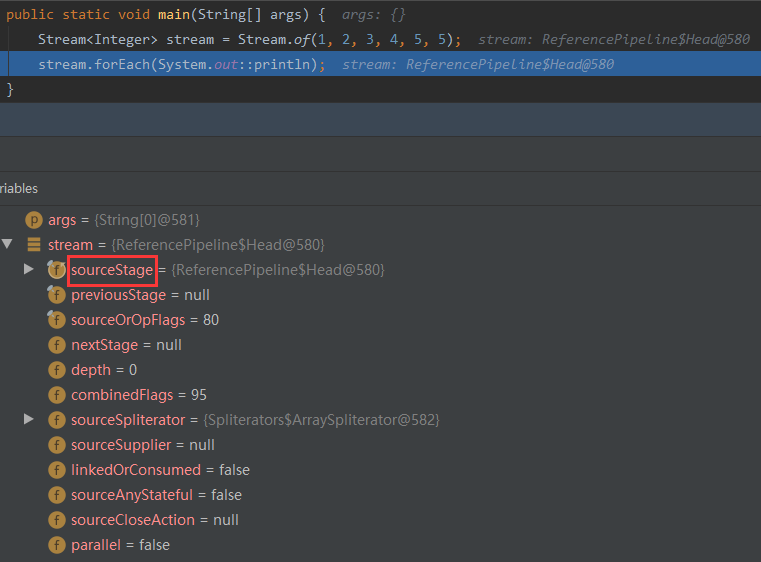
Stream operation mechanism
-
All operations are chain calls, and an element is iterated only once;
-
Each intermediate operation returns a new stream;
-
Each stream has an attribute sourceStage that points to the same place - the Head of the linked list.
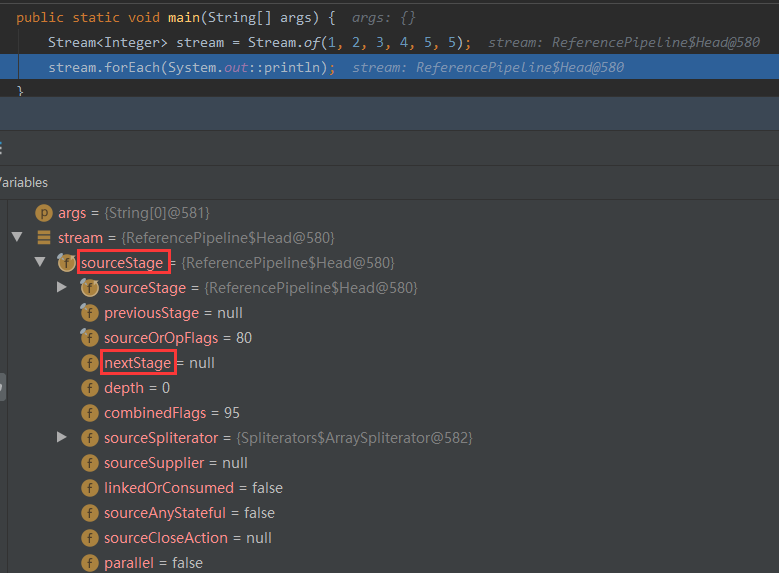
-
In the Head, it will point to nextStage, Head - > nextStage - > nextStage - > null
-
Stateful operations will truncate stateless operations and handle them separately.
-
When there is no stateless operation
Stream<Integer> stream = Stream.of(1, 2, 3); long count = stream.filter(integer -> true) .peek(integer -> System.out.println(integer + ": No first operation state")) // .sorted() // . Peek (integer - > system.out.println (integer + ": stateful operation") .filter(integer -> true) .peek(integer -> System.out.println(integer + ": Second stateless operation")) .count(); -
When a state operation is added in the middle
Stream<Integer> stream = Stream.of(1, 2, 3); long count = stream.filter(integer -> true) .peek(integer -> System.out.println(integer + ": First stateless operation")) .sorted() .peek(integer -> System.out.println(integer + ": Stateful operation")) .filter(integer -> true) .peek(integer -> System.out.println(integer + ": Second stateless operation")) .count();

-
-
In parallel links, stateful intermediate operations may not be able to operate in parallel, and the previous stateless operations separated by stateful operations may not be able to operate in parallel.
-
Parallel / sequential operations are also intermediate operations, but they do not create a stream. They only modify the parallel flag of the Head in the stream.
Iteration type
Stream is actually an advanced iterator. It is not a data structure or a collection and will not store data. It only focuses on how to process data efficiently and put the data into a pipeline for processing.
Iteration types can be divided into external iteration and internal iteration.
External iteration
External iteration is the traversal of sets and arrays we use.
Internal iteration
Use Stream programming or lambda expression to iterate.
Compared with external iteration, we don't need to pay attention to how it processes data. We just need to give it data and tell it the results we want.
The difference between the two
- External iteration is a serial operation. If the amount of data is too large, the performance may be affected.
- Internal iterations are relatively short and don't pay attention to so many details. Parallel flow can be used to achieve parallel operation, and developers don't have to consider threading.
Creation of flow
Array creation
Arrays.stream
The static method stream() of Arrays can get the array stream
String[] arr = { "a", "b", "c", "d", "e", "f", "g" };
Stream<String> stream = Stream.of(arr);
Stream<String> stream1 = Arrays.stream(arr);
Collection creation
The Collection interface provides two default methods to create streams: stream() and parallelStream()
List<String> list = new ArrayList<String>();
list.add("a");
list.add("b");
list.add("c");
Stream<String> stream = list.stream();
Value creation
Stream.of
Use the static method stream Of(), create a stream by displaying the value. It can receive any number of parameters.
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6);
Function creation
Stream.iterate
Stream.generate
Use the static method stream Iterate() and stream Generate() creates an infinite stream.
Stream<Double> stream = Stream.generate(Math::random).limit(5); Stream<Integer> stream1 = Stream.iterate(0, i -> i + 1).limit(5);
Note: when using infinite flow, it must be truncated with limit, otherwise it will be created without limit.
Intermediate operation of stream
If only the intermediate operation of the Stream will not be executed, the intermediate operation will be executed when the terminal operation is executed. This method is called delayed loading or lazy evaluation. Multiple intermediate operations form an intermediate operation chain. The intermediate operation chain will be executed only when the terminal operation is executed.
-
Stateless operation
Statelessness is an operation that cannot save data and is thread safe.filter, map, flatMap, peek and unordered are stateless operations.
These operations just get each element from the input stream and get a result in the output stream. There is no dependency between elements and there is no need to store data.
-
Stateful operation
The so-called stateful means that there is data storage function, and the thread is not safe.distinct, sorted, limit and skip are stateful operations.
These operations need to know the previous historical data first, and need to store some data. There are dependencies between elements.
| method | describe |
|---|---|
| distinct | De duplication: returns a Stream after de duplication |
| filter | Filter: filter according to the specified Predicate and return the Stream of unfiltered elements |
| sorted | Sort: returns the sorted Stream |
| limit | Truncation: make its elements no more than the specified number to get a new Stream |
| skip | Skip: returns a Stream that throws away the first n specified number of elements. If the number of elements is less than the specified number, an empty Stream is returned |
| map | Conversion: receive a Function function as a parameter, which will be applied to each element and mapped to a new element to get a new one |
| flatMap | Transform and merge: receive a Function function Function as a parameter, convert each element in the original Stream into another Stream, and then connect all streams into a new Stream |
| peek | Consumption: after using the passed in Consumer object to consume all elements, a new Stream containing all original elements is returned, which is often used to print element information during debugging |
| parallel | Convert to parallel Stream: convert to a parallel Stream |
| sequential | Convert to serial Stream: convert to a serial Stream |
Distinct
Stream distinct()
De duplication: remove duplicate elements through hashCode() and equals() of the elements generated by the stream.
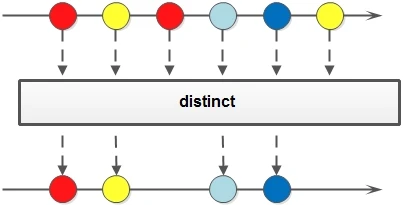
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 5);
Stream<Integer> stream1 = stream.distinct();
Filter
Stream filter(Predicate<? super T> predicate)
Filter: use the given filter function to filter the elements contained in the Stream. The newly generated Stream only contains qualified elements.
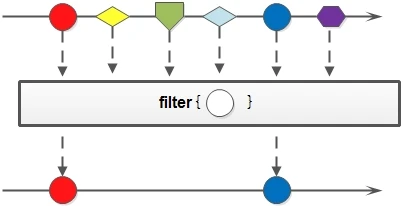
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 5); Stream<Integer> stream1 = stream.filter(integer -> integer == 1);
Sorted
Stream sorted(Comparator<? super T> comparator)
Sorting: specify comparison rules to sort.
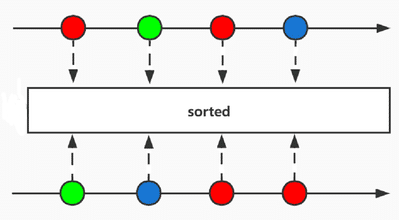
List<User> list = new ArrayList<>();
User user = new User();
user.setId("2");
list.add(user);
User user1 = new User();
user1.setId("1");
list.add(user1);
Stream<User> stream = list.stream().sorted(Comparator.comparing(User::getId));
Comparator<? super T> comparator
Specifies the sort field, which is arranged in ascending order by default
Comparator.reversed()
Sort reversal. If it is an ascending sort, it will become a descending sort after reversal
Limit (truncation)
Stream limit(long maxSize)
Truncate the stream so that its elements do not exceed the given number. If the number of elements is less than maxSize, all elements are obtained.
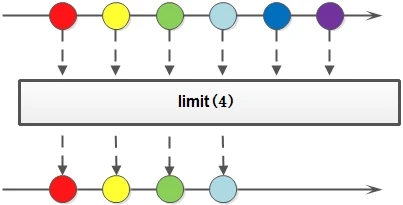
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 5); Stream<Integer> stream1 = stream.limit(2);
Skip
Stream skip(long n)
Skip elements and return a stream that throws away the first n elements. If there are less than n elements in the stream, an empty stream is returned. Complementary to limit(n).
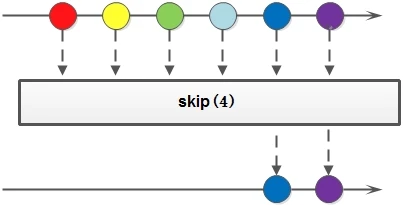
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 5); Stream<Integer> stream1 = stream.limit(3).skip(1);
Take the first three elements and skip one element.
Map (transformation flow)
Stream map(Function<? super T, ? extends R> mapper)
Convert Stream: convert the original Stream into a new Stream. Receive a Function function as an argument, which will be applied to each element and mapped to a new element.
Note: the meaning of map here is mapping, not the map object we often understand.
The map method has three extension methods:
- mapToInt: convert to IntStream
- mapToLong: convert to LongStream
- mapToDouble: convert to DoubleStream
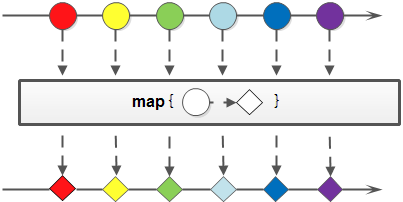
List<User> list = new ArrayList<>();
User user = new User();
user.setRoles(Arrays.asList("admin","test"));
list.add(user);
User user1 = new User();
user1.setRoles(Arrays.asList("admin"));
list.add(user1);
Stream<List<String>> stream = list.stream().map(User::getRoles);
Flatmap (transform streams and merge)
Stream flatMap(Function<? super T, ? extends Stream<? extends R>> mapper)
Convert the Stream, convert each element in the original Stream into another Stream, and then connect all streams into a new Stream. Receive a Function function as a parameter.
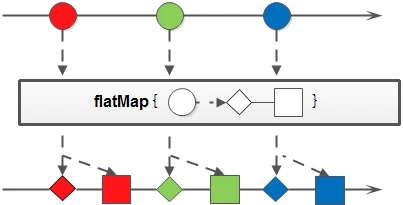
List<User> list = new ArrayList<>();
User user = new User();
user.setRoles(Arrays.asList("admin","test"));
list.add(user);
User user1 = new User();
user1.setRoles(Arrays.asList("admin"));
list.add(user1);
Stream<String> roleStream = list.stream().flatMap(u -> u.getRoles().stream());
Peek (print or modify)
Stream peek(Consumer<? super T> action)
Generate a new stream containing all elements of the source stream, and provide a consumption function (consumer instance). When each element of the new stream is consumed, it will execute the given consumption function.
peek is mainly used for debug ging purposes. It can be used to print the element information obtained after an intermediate operation.
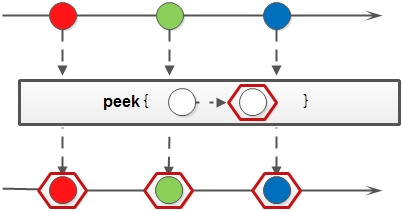
Stream<Integer> stream = Stream.of(5, 2, 1, 4, 5, 5); List<Integer> list = stream .filter(integer -> integer > 2) .peek(integer -> System.out.println(integer + "Greater than 2")) .filter(integer -> integer > 4) .peek(integer -> System.out.println(integer + "Greater than 4")) .collect(Collectors.toList());
Print results
5 Greater than 2 5 Greater than 4 4 Greater than 2 5 Greater than 2 5 Greater than 4 5 Greater than 2 5 Greater than 4
It can be seen that the operation sequence is: after each element completes all intermediate operations, the next element starts to complete all intermediate operations. In short, the processing elements come one by one. After the previous element is completed, the next element will continue.
Parallel (convert to parallel stream)
S parallel()
Convert a stream to a parallel stream.
The number of threads for parallel operation of the stream is the number of CPU s of the machine by default. The default thread pool is forkjoinpool Commonpool thread pool.
Sequential (to serial stream)
S sequential()
Convert a stream to a serial stream.
parallel() and sequential() are called multiple times, and the last one shall prevail.
Termination of stream
| method | describe |
|---|---|
| forEach | Traversal: the forEach of the serial stream will be executed in sequence, but the parallel stream will not be executed in sequence |
| forEachOrdered | Sequential traversal: make sure to execute in the order of the original stream (even parallel streams) |
| toArray | Convert to array: convert the stream into an array of appropriate type |
| findFirst | Take the first element: return an object of Optional type containing the first stream element. If the stream is empty, return Optional empty. Whether a parallel stream or a serial stream, the first element in the stream (sequential) is always selected |
| findAny | Take any element: return the object of Optional type containing any stream element. If the stream is empty, return Optional empty. The serial stream removes the first element, and the parallel stream may take any element |
| allMatch | Match all: all elements in the Stream conform to the incoming Predicate and return true. As long as one element is not satisfied, return false. |
| anyMatch | Arbitrary match: as long as one element in the Stream matches the incoming Predicate, it returns true. Otherwise, false is returned |
| noneMatch | No match: none of the elements in the Stream match the incoming Predicate and return true. As long as one is satisfied, it returns false |
| reduce | Combined flow element: it provides a starting value (seed), and then combines with the first, second and Nth elements of the previous Stream according to the operation rules (BinaryOperator). String splicing, sum, min, max and average are special reduce |
| max | Maximum value of element: if the stream is empty, it returns optional empty |
| min | Minimum value of element: optional if the stream is empty empty |
| count | Number of elements: the number of elements in the stream. long type is returned |
| sum | Element summation: sum all flow elements |
| average | Element average: calculate the average value of stream elements |
| collect | Collecting: collecting flow elements into result sets |
Foreach (traversal)
ergodic
forEach(Consumer)
Accept a Consumer function.
forEach of serial stream will be executed in sequence, but it will not be executed in sequence when parallel stream is used
Stream.of(1, 2, 3, 4, 5, 6).parallel().forEach(a -> System.out.print(a));
Print log
426135
Parallel streams are not traversed in order (serial streams are traversed in order)
Foreachordered (sequential traversal)
forEachOrdered(Consumer)
Ensure that the execution is in the order of the original flow (even parallel flow)
Stream.of(1, 2, 3, 4, 5, 6).parallel().forEachOrdered(a -> System.out.println(a));
Print log
123456
Parallel streams are also traversed in order
ToArray (convert to array)
Convert to array
- toArray()
Convert the stream to an array of the appropriate type. - toArray(generator)
In special cases, the generator is used to allocate custom array storage.
Object[] array = Stream.of(1, 2, 3, 4, 5, 6).toArray(); Integer[] array1 = Stream.of(1, 2, 3, 4, 5, 6).toArray(Integer[]::new);
Findfirst (take the first element)
findFirst()
Returns an object of Optional type containing the first stream element. If the stream is empty, it returns Optional empty.
findFirst() always selects the first element (in order) in the stream, whether the stream is serial or parallel.
Optional<Integer> first = Stream.of(1, 2, 3, 4, 5, 6).findFirst(); Optional<Integer> first1 = Stream.of(1, 2, 3, 4, 5, 6).parallel().findFirst(); System.out.println(first.get()); System.out.println(first1.get());
1 1
Findany (take any element)
Returns an object of Optional type containing any stream element. If the stream is empty, it returns Optional empty.
For a serial stream, findAny() and findFirst() have the same effect. Select the first element in the stream.
For parallel streams, findAny() will also select the first element in the stream (but because it is a parallel stream, by definition, it selects any element).
Optional<Integer> any = Stream.of(1, 2, 3, 4, 5, 6).findAny(); Optional<Integer> any1 = Stream.of(1, 2, 3, 4, 5, 6).parallel().findAny(); System.out.println(any.get()); System.out.println(any1.get());
1 4
Allmatch (all match)
allMatch(Predicate)
All match
All elements in the Stream conform to the incoming Predicate and return true. As long as one element is not satisfied, return false.
boolean b = Stream.of(1, 2, 3, 4, 5, 6).allMatch(a -> a <= 6);
Anymatch
anyMatch(Predicate)
Arbitrary matching
As long as one element in the Stream matches the incoming Predicate, it returns true. Otherwise, false is returned
boolean b1 = Stream.of(1, 2, 3, 4, 5, 6).anyMatch(a -> a == 6);
boolean b2 = Stream.of(1, 2, 3, 4, 5, 6).anyMatch(a -> a > 6);
System.out.println(b1);
System.out.println(b2);
true false
None match
noneMatch(Predicate)
They don't match
None of the elements in the Stream match the incoming Predicate and return true. As long as one is satisfied, it returns false.
boolean b1 = Stream.of(1, 2, 3, 4, 5, 6).noneMatch(a -> a == 6);
boolean b2 = Stream.of(1, 2, 3, 4, 5, 6).noneMatch(a -> a > 6);
System.out.println(b1);
System.out.println(b2);
false true
Reduce (composite flow element)
Combine the Stream elements.
It provides a starting value (seed), and then combines it with the first, second and Nth elements of the previous Stream according to the operation rules (BinaryOperator).
String splicing, sum, min, max and average are special reduce.
Method format:
-
Optional reduce(BinaryOperator accumulator)
Optional<Integer> sum = Stream.of(1, 2, 3, 4, 5, 6).reduce((a1, a2) -> a1 + a2);
Sum
-
T reduce(T identity, BinaryOperator accumulator)
T identity provides an initial value identity of the same type as the data in the StreamInteger sum1 = Stream.of(1, 2, 3, 4, 5, 6).reduce(1, (a1, a2) -> a1 + a2); Integer sum2 = Stream.of(1, 2, 3, 4, 5, 6).parallel().reduce(1, (a1, a2) -> a1 + a2); System.out.println(sum1); System.out.println(sum2);22 27
Sum, initial value 0.
In the case of parallel flow, the statistical data of this method will have problems. Take summation as an example: the initial value is a and the number of flow elements is b. in the summation of parallel flow, each element is summated with the initial value once, and then these results are summated. Therefore, the final sum will be greater than the correct value (b-1)*a -
<U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner)
Binaryoperator < U > combiner this parameter is translated into "combiner" in English. It is only effective in parallel flow, and it does not work in serial flow. The main function is to merge the results after processing the second parameter accumulator.
Integer reduce1 = Stream.of(1, 2, 3, 4).reduce(1, (sum, a) -> { Integer aa = sum + a; System.out.println(sum+"+"+a+"="+aa+"-----accumulator"); return aa; }, (sum1, sum2) -> { Integer sumsum = sum1 + sum2; System.out.println(sum1+"+"+sum2+"="+sumsum+"-----combiner"); return sumsum; }); System.out.println(reduce1); System.out.println("============================"); Integer reduce2 = Stream.of(1, 2, 3, 4).parallel().reduce(1, (sum, a) -> { Integer aa = sum + a; System.out.println(sum+"+"+a+"="+aa+"-----accumulator"); return aa; }, (sum1, sum2) -> { Integer sumsum = sum1 + sum2; System.out.println(sum1+"+"+sum2+"="+sumsum+"-----combiner"); return sumsum; }); System.out.println(reduce2);Obviously, the correct summation result should be 11, and the result is correct in serial flow. But in parallel flow, the result is 17, which is wrong. And the third parameter combiner takes effect only when parallel streams are found.
Cause of error (personal understanding, not carefully studied):
- Serial stream summation: initial value + value 1 + value 2 + value 3
- Parallel flow summation: (initial value + value 1) + (initial value + value 2) + (initial value + value 3)
In the case of parallel flow, the statistical data of this method will have problems. Take summation as an example: the initial value is a and the number of flow elements is b. in the summation of parallel flow, each element is summated with the initial value once, and then these results are summated. Therefore, the final sum will be greater than the correct value (b-1)*a
Max (element maximum)
Find the maximum value of the element. If the stream is empty, return optional empty.
Optional<Integer> max = Stream.of(1, 2, 3, 4, 5, 6).max((a1,a2) -> a1.compareTo(a2));
Min (minimum value of element)
Find the minimum value of the element. If the stream is empty, return optional empty.
Optional<Integer> max = Stream.of(1, 2, 3, 4, 5, 6).min((a1,a2) -> a1.compareTo(a2));
Count (number of elements)
Number of elements in the stream.
long count = Stream.of(1, 2, 3, 4, 5, 6).count();
Sum (element summation)
Sum all flow elements.
Average (element average)
Average the stream elements.
Collect
Collect, collect stream elements and convert them into the final required results.
collect(Collector)
Use Collectors to collect stream elements into the result set, mainly using Collectors (Java. Util. Stream. Collector s).
The methods of Collectors are as follows:
| Method name | describe |
|---|---|
| toList | Put the elements in the flow into a list collection. This list defaults to ArrayList. |
| toSet | Put the elements in the stream into an unordered set. The default is HashSet. |
| toCollection | Put all the elements in the stream into a collection. Collection is used here, which generally refers to multiple collections. |
| toMap | According to the given key generator and value generator, the generated keys and values are saved and returned in a map. The generation of keys and values depends on the elements. You can specify the processing scheme when duplicate keys occur and the map to save the results. |
| toConcurrentMap | It is basically the same as toMap, except that the last map it uses is concurrent map: concurrent HashMap |
| joining | Connect all the elements in the stream in the form of character sequence, and you can specify the connector or even the pre suffix of the result. The new Java 8 class StringJoiner used for internal splicing can define connectors, prefixes and suffixes |
| mapping | First map each element in the stream, that is, type conversion, and then summarize the new element with a given Collector. Similar to stream toMap. |
| collectingAndThen | After the induction action is completed, the induction result is reprocessed. |
| counting | Element count |
| minBy | Minimum Optional |
| maxBy | Maximum Optional |
| summingInt | Sum, result type is int |
| summingLong | Sum, and the result type is long |
| summingDouble | The result type is double |
| averagingInt | Average, result type int |
| averagingLong | Average value, result type long |
| averagingDouble | Average, result type double |
| summarizingInt | Summary. The result includes the number of elements, maximum value, minimum value, summation value and average value. The value type is int |
| summarizingLong | Summary. The result includes the number of elements, maximum value, minimum value, summation value and average value. The value type is long |
| summarizingDouble | Summary. The result includes the number of elements, maximum value, minimum value, summation value and average value. The value type is |
| reducing | Statistics: the reducing method has three overloaded methods, which are actually corresponding to the three reduce methods in Stream. They can be used interchangeably and have exactly the same function. They are also used for statistical induction of elements in convection. Summation, average value, maximum value and minimum value belong to a special kind of statistics |
| groupingBy | Group and get a HashMap |
| groupingByConcurrent | Group and get a ConcurrentHashMap |
| partitioningBy | Divide the elements in the flow into two parts according to the results of the given verification rules and return them in a map. The key of the map is Boolean type and the value is the List of elements |
-
toList
List<Integer> list = Stream.of(1, 2, 3, 4, 5, 5).collect(Collectors.toList());
-
toSet
Set<Integer> set = Stream.of(1, 2, 3, 4, 5, 5).collect(Collectors.toSet());
-
toCollection
ArrayList<Integer> list = Stream.of(1, 2, 3, 4, 5, 5).collect(Collectors.toCollection(ArrayList::new));
-
toMap
Map<Integer, Integer> map1 = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.toMap(i -> i, i -> i)); Map<Integer, Integer> map2 = Stream.of(1, 2, 3, 4, 5, 5).collect(Collectors.toMap(i -> i, i -> i, (k1, k2) -> k1)); HashMap<Integer, Integer> map3 = Stream.of(1, 2, 3, 4, 5, 5).collect(Collectors.toMap(i -> i, i -> i, (k1, k2) -> k1, HashMap::new)); -
toConcurrentMap
ConcurrentMap<Integer, Integer> map1 = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.toConcurrentMap(i -> i, i -> i)); ConcurrentMap<Integer, Integer> map2 = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.toConcurrentMap(i -> i, i -> i, (k1, k2) -> k1)); ConcurrentReferenceHashMap<Integer, Integer> map3 = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.toConcurrentMap(i -> i, i -> i, (k1, k2) -> k1, ConcurrentReferenceHashMap::new)); -
joining
String s = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.joining("\",\"", "[\"", "\"]")); List<String> list = JSON.parseArray(s, String.class); -
mapping
List<Integer> list = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.mapping(Integer::valueOf, Collectors.toList())); -
collectingAndThen
Integer size = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.collectingAndThen(Collectors.toList(), List::size));
-
counting
Long size = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.counting()); -
minBy
Optional<String> max = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.maxBy((a, b) -> a.compareTo(b))); -
maxBy
Optional<String> min= Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.minBy((a, b) -> a.compareTo(b))); -
summingInt
Integer sum = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.summingInt(Integer::valueOf)); -
summingLong
Long sum = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.summingLong(Long::valueOf)); -
summingDouble
Double sum = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.summingDouble(Double::valueOf)); -
averagingInt
Double average = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.averagingInt(Integer::valueOf)); -
averagingLong
Double average = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.averagingLong(Long::valueOf)); -
averagingDouble
Double average = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.averagingDouble(Double::valueOf)); -
summarizingInt
IntSummaryStatistics statistics = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.summarizingInt(a -> a));
-
summarizingLong
LongSummaryStatistics statistics = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.summarizingLong(a -> a));
-
summarizingDouble
DoubleSummaryStatistics statistics = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.summarizingDouble(a -> a));
-
reducing
Optional<Integer> sum1 = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.reducing(Integer::sum)); Integer sum2 = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.reducing(0, Integer::sum)); Integer sum3 = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.reducing(0, Function.identity(), Integer::sum));Note: in the case of parallel flow, there will be problems in the data statistics of 2 and 3 methods. Take the sum as an example: the initial value is a and the number of flow elements is b. when summing parallel flow, each element is summed with the initial value once, and then these results are summed. Therefore, the final sum will be greater than the correct value (b-1)*a
-
groupingBy
Map<Integer, List<String>> map1 = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.groupingBy(Integer::valueOf)); Map<Integer, Set<String>> map2 = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.groupingBy(Integer::valueOf, Collectors.toSet())); ConcurrentHashMap<Integer, Set<String>> map3 = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.groupingBy(Integer::valueOf, ConcurrentHashMap::new, Collectors.toSet())); -
groupingByConcurrent
ConcurrentMap<Integer, List<String>> map1 = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.groupingByConcurrent(Integer::valueOf)); ConcurrentMap<Integer, Set<String>> map2 = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.groupingByConcurrent(Integer::valueOf, Collectors.toSet())); ConcurrentHashMap<Integer, Set<String>> map3 = Stream.of("1", "2", "3", "4", "5", "6").collect(Collectors.groupingByConcurrent(Integer::valueOf, ConcurrentHashMap::new, Collectors.toSet())) -
partitioningBy
Map<Boolean, List<Integer>> map1 = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.partitioningBy(a -> a > 3)); Map<Boolean, Set<Integer>> map2 = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.partitioningBy(a -> a > 3, Collectors.toSet()));
collect(Supplier, BiConsumer, BiConsumer)
Collect stream elements into the result collection.
The first parameter is used to create a new result set, the second parameter is used to add the next element to the existing result set, the third parameter is used to merge the two result sets, and the third parameter is valid only when there is parallel flow.
// Method 1
Stream<Integer> stream1 = Stream.of(1, 2, 3, 4, 5, 6);
ArrayList<Integer> list3 = stream1.collect(ArrayList::new, (list, a) -> list.add(a), (list1, list2) -> list1.addAll(list2));
// Method 2
Stream<Integer> stream2 = Stream.of(1, 2, 3, 4, 5, 6);
ArrayList<Integer> list4 = stream2.parallel().collect(ArrayList::new, (list, a) -> list.add(a), (list1, list2) -> list1.addAll(list2));
- The third parameter of method 1 does not take effect.
- The third parameter of method 2 is mainly used to merge the results after the second parameter accumulator is processed.
Other methods of streaming
Concat (merge stream)
Merge two flows into a new flow
Stream<Integer> stream1 = Stream.of(1, 2, 3, 4, 5, 6);
Stream<Integer> stream2 = Stream.of(1, 2, 3, 4, 5, 6);
Stream<Integer> stream = Stream.concat(stream1, stream2);
Stream dependent functional interface
For stream related functional interfaces, please refer to the article: Java functional programming
Other related categories
Collectors
The Collectors class is explained in detail above, so I won't mention it here.
Optional
For now.
Relevant reference articles: "java8 series" streaming programming Stream