Code piling is a common means of testing and locating problems. We can print or collect the data we need by inserting the corresponding code ("pile") at the corresponding position of the code.
Automatic pile insertion is to automatically insert one or more lines of code we need at a specific position of the code. Usually, we will insert stakes in the compiled code. The advantage of this is to avoid the invasion of the source code and shield the developers' different code styles to a certain extent. Here, we mainly introduce another way of inserting piles into the source code. If we do not consider the invasiveness of the code, it will be more intuitive to directly insert piles into the source code, which will be easier to control and debug, and have higher flexibility. Moreover, this method to be introduced in this paper does not need to consider different code styles.
Pile insertion requirements
Take a piece of java code with simple structure as an example. Suppose we have a source code file with Suffix ". java", we need to insert a line of code at the beginning of each method in it, print the name of the current method, and let us know which method has been called during code execution, so as to draw the call relationship diagram of the whole project. The source code in the file is as follows:
package com.ast.pkg;
public class ASTDemo {
int intData = 0;
double floatData = 0;
String strData = "";
//construction
public ASTDemo() {
this.intData = 123;
this.floatData = 3.14;
this.strData = "It's been a long time.";
}
public void setIntData(int data) {
this.intData = data;
}
public String getStrData() {
return this.strData;
}
public void methodDemo(String param1, String param2) {
if (null == param1 || null == param2) {
return;
}
if (param1.length() > param2.length()) {
strData = strData + param1;
} else {
strData = strData + param2;
}
}
}
Dear friends, I need you java Please like, collect and forward the interview documents and materials. After paying attention to me, click the private letter (555) in the upper right corner of my home page to get the free materials immediately or click: https://shimo.im/docs/aBAYVxlBX6IDge3jObviously, we can't directly insert piles, because even if you can accurately locate the first line of each method, it still doesn't have universality. If you change the writing method of the same code, or add some complex code structure, or change the writing habit, you can't recognize the first line of code, and even redevelopment is very complex. Next, let's change our thinking to insert piles.
Java code composition
Here we need to explore how java code is composed, or what statements and structures are contained in a file with the suffix ". Java". For example, in the above code, you can intuitively see that it includes:
-
Package name
-
Class name
-
There are three properties in the class
-
Class and the statements it contains
-
Class and the statements it contains
According to their inclusion relationship, a tree diagram can be drawn: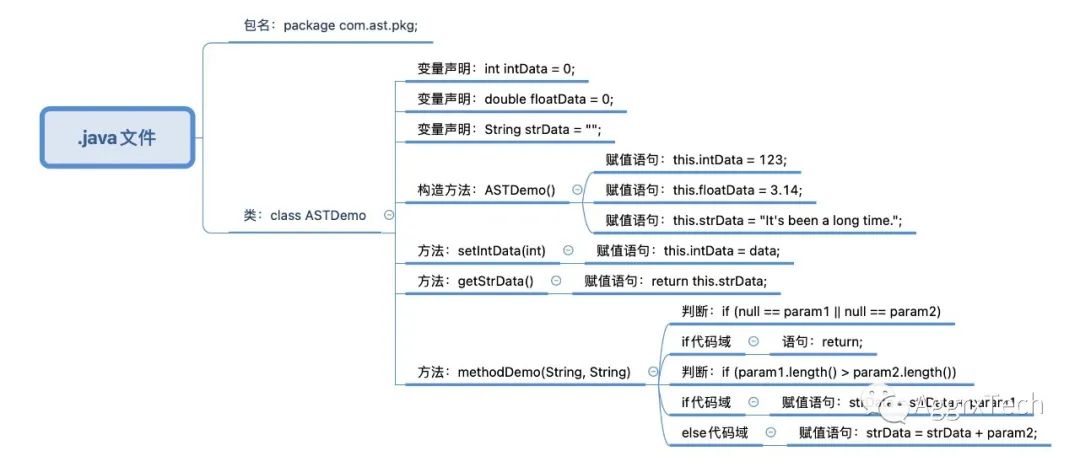
Start from the root node and include all the code layer by layer. It completely and clearly represents this part of the code and the relationship between them.
Abstract syntax tree
The above "tree" is a very intuitive way, but it also shows that the code can be abstracted into the form of a tree. Next, we draw the tree with finer granularity.
Abstract syntax tree (AST) is an abstract representation of the syntax structure of source code. It represents the structure of code in the form of tree. In fact, Eclipse has provided the ast representation of the source code to help developers analyze the structure and relationship of the code more completely and clearly.
What we want to achieve here is automatic stake insertion, that is, we need to analyze the code structure in real time, then insert the prepared code in the correct position, and ensure that the code after stake insertion can be compiled and executed.
JavaParser
We use JavaParser to process the source code. It is a general code analysis tool. Through the parsing of JavaParser, we will get an abstract syntax tree of ". java" file. Refer to the following steps:
1) Quote
After creating the project, JavaParser, Maven or Gradle can be introduced
- Maven
-
<dependency> <groupId>com.github.javaparser</groupId> <artifactId>javaparser-core-serialization</artifactId> <version>3.6.5</version> </dependency> <dependency> <groupId>com.github.javaparser</groupId> <artifactId>javaparser-core</artifactId> <version>3.6.5</version> </dependency>Gradle
implementation 'com.github.javaparser:javaparser-symbol-solver-core:3.6.5' implementation 'com.github.javaparser:javaparser-core:3.6.5'
Note that the reference version should not be lower than 3.6.4, otherwise various difficult and miscellaneous problems will occur.
2) Parsing Java source code
Relying on the JavaParser tool, we only need to pass in the input stream of ". java" file to complete the analysis of the source code.String javaFilePath = "ASTDemo.java"; FileInputStream in = null; try { in = new FileInputStream(javaFilePath); CompilationUnit compilationUnit = JavaParser.parse(in); } catch (FileNotFoundException e) { e.printStackTrace(); } finally { if (null != in) { try { in.close(); } catch (IOException e) { e.printStackTrace(); } } }The parse method in JavaParser will generate a code tree based on the source code and return it as CompilationUnit. The CompilationUnit class is located at com github. JavaParser. Under the ast package, the normal introduction of JavaParser can be used. The form of our observation point:
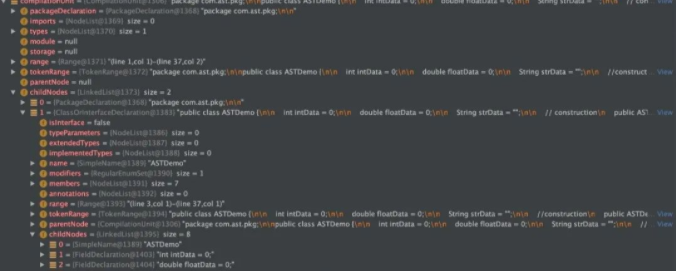
For the tree structure, the attribute we can easily understand is childNode. There are two child nodes on the root node compilationUnit, one is the package name and the other is the ASTDemo class. The class node contains seven child nodes. In addition to the class name node, the other six nodes represent three class attribute variables, one construction method and three common methods.
For a method, take methodDemo(String, String) as an example. It has five child nodes:
They are the method name, two parameters, return value and method body. As we all know, the code in the method body is:
if (null == param1 || null == param2) { return; } if (param1.length() > param2.length()) { strData = strData + param1; } else { strData = strData + param2; }Continue to track inward. There are two child nodes under the method body node, representing two if nodes respectively

By analogy, when a statement is refined, it still has a similar structure, such as the assignment statement strData = strData + param1; Taking this statement as a root node, it contains two child nodes, which are the left and right of the assignment character:

"=" as an "assign" operation is saved in the operator attribute of the root node:

Similarly, on the right side of "=", there are two nodes strData and param2, as well as the oprator attribute identifying the PLUS operation:
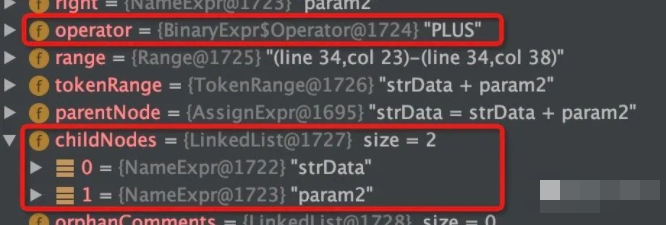
It can be seen that the abstract syntax tree contains all the information of the source code. On this tree, we can accurately locate any code structure we need to identify.
Traversal syntax tree
Recall our requirement: insert the statement to print the log in the first line of each method. So we need to find "every method" first. For the abstract syntax tree, that is to find all the method nodes. Naturally, we think of traversing the tree.
The JavaParser tool provides a method to traverse this tree. We need to create a VoidVisitorAdapter object and implement the visit(SomeType, Object) method as required. So how can we identify which node represents a method and which node represents a statement or attribute after traversing the syntax tree? If you carefully read the breakpoint screenshot above, you will notice that on this tree, different code structures have different types of nodes, such as:Code structure Node type Class attribute variable FieldDeclaration Construction method ConstructorDeclaration Common method MethodDeclaration Branch judgment IfStmt Assignment statement AssignExpr Method call MethodCallExpr The visit method of VoidVisitorAdapter defines each type. What we need to identify here are construction methods and ordinary methods, so we can implement two types: ConstructorDeclaration and MethodDeclaration.
VoidVisitorAdapter<Object> adapter = new VoidVisitorAdapter<Object>() { public void visit(MethodDeclaration methodDeclaration, Object obj) { ...... } public void visit(ConstructureDeclaration methodDeclaration, Object obj) { ...... } };In the visit method, the processing logic when the corresponding type of node is encountered. So we need to insert piles here.
The current code is a tree structure. To add a line of code, we need to create a node. In order to be as simple as possible, we insert a simple execution statement system out. println(...), The type of this statement is ExpressionStmt, so let's create a node first:
String pileContent = "System.out.println(...)"; ExpressionStmt expressionStmt = new ExpressionStmt(); expressionStmt.setExpression(pileContent);
Next, we need to hang this node in the correct position. The first line of each method code is required to be converted to the syntax tree, that is, we need to add this node before the first child node of the method body node:
methodDeclaration.getBody().get().getStatements().add(0, expressionStmt);
It should be noted here that if it is the construction method of a subclass, because it is called
super() needs to be performed in the first line, so it can be judged that if the first line of the construction method is a super method, this node should be inserted in the second position, otherwise an error will be reported during compilation.
We can call the visit method of adapter, pass in the syntax tree object generated before, and start traversing:adapter.visit(compilationUnit, null);
After traversal, the preset code is inserted under each method node.
Finally, we call the toString() method of CompilationUnit to convert the code tree into source code, print it to the same location ".java" file, and cover the original data, and automatically insert the piling.
If this article is helpful to you, don't forget to pay attention, like, comment, forward and collect!
Collection is equal to whoring for nothing. Praise is true love. Thank you 0.0