Although I met such a problem once when I started to learn JAVA, I didn't pay attention to recording the problem at that time, and after talking with the teacher, I couldn't get over it. This time I encountered such a problem, which is still very scary. After all, if we can't even trust the debug tool, who should we trust. JAVA version is 11, IDE is the community version of IDEA2019.3.1, and the operating system is win10 professional version. The problem to be solved by the program is a simple algorithm class assignment: Double cycle, iteration variables I and j conform to 0<i<N and 0<j<N, and the content of the cycle is arbitrary, such as s=s+i-j; please record the running time and output N. when the running time of double cycle is 0.1s, 1s and 10s The idea is to record the cycle time every time and use dichotomy to let the program find these three N's by itself. Here is the source code: A widget class to output results to text:
import java.io.File; import java.io.FileWriter; import java.io.IOException; public class OutData { public OutData(Integer n1,//N closest to 0.1s Integer n2,//N closest to 1s Integer n3,//N closest to 10s StringBuffer useTime1,//Specific time of n1 StringBuffer useTime2,//Specific time of n2 StringBuffer useTime3//Specific time of n3 ) throws IOException { File fileOfDataIn = new File("Result.txt"); FileWriter fileWriter; if (!fileOfDataIn.exists()) { fileOfDataIn.createNewFile(); fileWriter = new FileWriter(fileOfDataIn.getName(), true); } else { fileWriter = new FileWriter(fileOfDataIn.getName(), false); fileWriter.write(""); } fileWriter.write("N For:" + n1.toString() + "The time used is:" + useTime1.toString() + "Millisecond" +"\n"+"N For:" + n2.toString() + "The time used is:" + useTime2.toString() + "Millisecond" +"\n"+"N For:" + n3.toString() + "The time used is:" + useTime3.toString() + "Millisecond"); fileWriter.close(); } }
Next is the main class. In order to save running time, note out the two times of 1s and 10s
import java.io.IOException; //Later, my solution is to add another random function to the loop body, which will be commented out first //import java.util.Random; public class DoubleCirculationMain { public static void main(String[] args) throws IOException { int startN = 1000; StringBuffer useTime1 = new StringBuffer(), useTime2 = new StringBuffer(), useTime3 = new StringBuffer(); //Use dichotomy to automatically find N value with time close to 0.1s, 1s and 10s respectively and output int n1 = getClosestValue(100, startN, useTime1); int n2=0;//Save test time //int n2 = getClosestValue(1000, n1, useTime2); int n3=0;//Save test time //int n3 = getClosestValue(10000, n2, useTime3); new OutData(n1, n2, n3, useTime1, useTime2, useTime3); } private static int getClosestValue(int timeToApproach, int startN, StringBuffer useTimeBuffer) { int nLower = startN, increment = 10000, nHeigher = nLower + increment, nMedian = (nHeigher + nLower) / 2, forCaculate = 0; long startTime, endTime, costime = 0, costime2 = 0; //Later, my solution is to add another random function to the loop body, which will be commented out first //Random random = new Random(); while (true) {//Cycle to target in upper and lower range nMedian = (nHeigher + nLower) / 2;//Refresh median forCaculate = 0; startTime = System.currentTimeMillis();//Start timing for (int i1 = 0; i1 < nHeigher; i1++) { for (int i2 = 0; i2 < nHeigher; i2++) { forCaculate = forCaculate + i1 - i2; //Later, my solution is to add another random function to the loop body, which will be commented out first //forCaculate = forCaculate + i1 - i2+random.nextInt(100); } } endTime = System.currentTimeMillis();//Closing time //The JAVA virtual machine is prevented from automatically optimizing the code at the beginning, so the run result is called intentionally System.out.println(forCaculate); costime = endTime - startTime; if (costime < timeToApproach) {//If the upper limit is less than the target, the lower limit takes the value, and then the upper limit increases. nHeigher += increment; nLower = nHeigher; } else {//If the upper limit is greater than the target, exit the cycle, and the time spent value is the upper limit time break; } } while (costime >= 1.01 * timeToApproach && nHeigher - nLower > 1) {//When the time spent exceeds 1.01 times the target and the difference between the upper and lower limits is greater than 1, continue to approach nMedian = (nHeigher + nLower) / 2;//Refresh median. startTime = System.currentTimeMillis();//Start timing for (int i1 = 0; i1 < nMedian; i1++) { for (int i2 = 0; i2 < nMedian; i2++) { forCaculate = forCaculate + i1 - i2; //Later, my solution is to add another random function to the loop body, which will be commented out first //forCaculate = forCaculate + i1 - i2+random.nextInt(100); } } endTime = System.currentTimeMillis();//Closing time //Or to prevent the JAVA virtual machine from automatically optimizing the code, so it deliberately calls the run results System.out.println(forCaculate); costime2 = endTime - startTime; if (costime2 > timeToApproach) {//If the median is also greater than the target, the median becomes the new upper limit, which takes time to update nHeigher = nMedian; costime = costime2; } else {//If the median is less than the target, the median becomes the new lower limit nLower = nMedian; } } useTimeBuffer.append(costime);//Upper limit time after output approximation processing return nHeigher; } }
The text content of run output is:
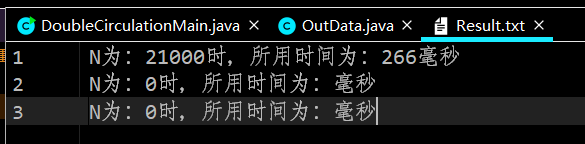
The text output after adding a breakpoint to getClosestValue() method is as follows:
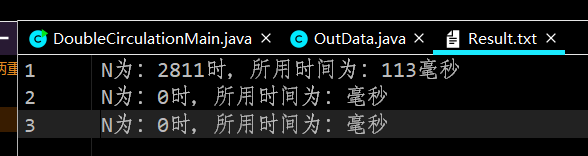
First of all, I have repeatedly confirmed that this problem does exist. Whether rebuild, restart IDEA completely, restart windows, the results of run and debug are different.
Secondly, if you add breakpoints to the main method, the result of debugging will be the same as that of run, but if you add breakpoints to the dichotomy method getClosestValue(), the result of debugging will be different from that of run. The result of debugging is the result that should be obtained in theory.
My intuition tells me to add a random process in the loop body, because I suspect that when interpreting the run time, the compiler judges two duplicate code segments, so it directly calls the run results to optimize the running efficiency of the program. Maybe this is the secret that JAVA can catch up with C + + when executing the repeated code segments. However, if it is true, it obviously ignores my verification requirements on the running time of the program, which results in the output results different from the theory, so the problem will be solved as soon as I add random processes to the loop body.
Another strange phenomenon worth mentioning is that after I test this code every time, if I close the idea at this time, the next time I open the idea, it will be stuck at the beginning, but after I restart windows, the idea can be opened normally, so the problem may be related to the idea?
As a little white, I don't want to go too deep at present, because there may be too many problems, and I don't understand them at present, so let's remember here first. If a passing friend is interested in this problem, he can say his own opinion in the comment area, or he can reproduce it on his own computer, change an IDE and try again. There are only two categories and dozens of lines Code.

