Today, we will explore the basic principles and source code implementation of HashSet, TreeSet and LinkedHashSet. Since these three set s are based on the three maps in the previous article, we recommend that you take a look at the previous article on map first, and use them together better.
Specific code can be found in my GitHub
https://github.com/h2pl/MyTech
The article was first published on my personal blog:
https://h2pl.github.io/2018/05/12/collection7
More about Java back-end learning can be found on my CSDN blog:
My personal blog is mainly original articles, also welcome to browse. https://h2pl.github.io/
Reference in this article http://cmsblogs.com/?p=599
HashSet
Definition
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
HashSet inherits the AbstractSet class and implements Set, Cloneable, Serializable interfaces. AbstractSet provides the backbone implementation of Set interface Of, which minimizes the Of work required to implement this interface. == The Set interface is a Collection that does not duplicate elements. It maintains its own internal sort, so random access is meaniNgless. = =
This paper is based on 1.8jdk for source code analysis.
Basic attributes
Based on HashMap implementation, the underlying layer uses HashMap to save all elements
private transient HashMap<E,Object> map; //Define an Object object as the value of HashMap private static final Object PRESENT = new Object();
Constructor
/**
* Default constructor
* Initialize an empty HashMap with default initial capacity of 16 and load factor of 0.75.
*/
public HashSet() {
map = new HashMap<>();
}
/**
* Construct a new set containing elements in the specified collection.
*/
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
/**
* Construct a new empty set whose underlying HashMap instance has the specified initial capacity and the specified load factor
*/
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
/**
* Construct a new empty set whose underlying HashMap instance has the specified initial capacity and default load factor (0.75).
*/
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
/**
* I didn't see this constructor in the API, but I found it today when I looked at the source code (the original access rights are package rights, not public)
* Construct a new empty link hash set with the specified initial Capacity and loadFactor.
* dummy The main purpose of identifying this constructor is to support LinkedHashSet.
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
//It can be seen from the constructor that all constructs of HashSet construct a new HashMap, the last constructor of which is that the access rights to packages are not disclosed to the public, only when LinkedHashSet is used.
Method
Since HashSet is based on HashMap, the implementation of its method is very simple for HashSet.
public Iterator<E> iterator() {
return map.keySet().iterator();
}
The iterator() method returns an iterator that iterates over the elements in this set. The order in which elements are returned is not specific.
The bottom layer calls the keySet of HashMap to return all keys, which reflects that all elements in HashSet are stored in the key of HashMap, and value is the PRESENT object used, which is static final.
public int size() {
return map.size();
}
size()Return to this set Number of elements in( set Capacity). Bottom call HashMap Of size Method, return HashMap The size of the container.
public boolean isEmpty() {
return map.isEmpty();
}
isEmpty(),judge HashSet()Whether the collection is empty or not, it returns empty true,Otherwise return false.
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}
//Finally, this method is invoked for node lookup
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//First check whether the end node of the bucket exists.
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//If it is not a header node, it traverses the list. If it is a tree node, it traverses the list using the tree node method until it is found, or null.
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
contains(), which determines whether an element exists in HashSet(), returns true or false. More precisely, this relationship should be satisfied before returning true:(o==null?E==null:o.equals(e)). The underlying call containsKey determines whether the key value of HashMap is empty.
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
map Of put Method:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//Confirmation initialization
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//If the bucket is empty, insert the new element directly, that is entry.
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//If there is a conflict, there are three situations.
//If the key is equal, let the old entry be equal to the new entry.
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//The situation of mangrove and black trees
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//If key s are not equal, they are linked into linked lists
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
Note here that hashset simply does not allow duplicate elements to be added, rather than linking elements into linked lists, because as long as the equals method of key judges that they are equal when true, value substitution occurs because all entries have the same value, so they are the same as when no entry is inserted.
When two entries with the same hashcode but different key s are inserted, they will still be linked into a linked list. When the length exceeds 8, they will still expand into red and black trees like hashmap. After reading the source code, the author realizes that he misunderstood before. So it's good to see the source code. hashset is basically implemented again using hashmap, except that values are all the same object, which makes you think that the same element is not inserted, in fact, value is replaced by the same value.
When the add method conflicts, if the key is the same, replace the value, and if the key is different, link it into a linked list.
add() If the set does not contain the specified element, add the specified element. If this Set does not contain E2 that satisfies (e= null? E2= null: E. equals (e2)), then E2 is added to the Set, otherwise it is not added and returns false.
Since the underlying use of HashMap's put method to construct key = e, value=PRESENT into key-value pairs, when the e exists in HashMap's key, the value will override the original value, but the key remains unchanged, so if an existing e element is added to HashSet, the newly added element will not be saved to HashMap, so this satisfies whether the elements in HashSet will repeat. Characteristics.
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
remove removes the specified element if it exists in this set. The underlying layer uses the remote method of HashMap to delete the specified Entry.
public void clear() {
map.clear();
}
Clear removes all elements from this set. The underlying layer calls the clear method of HashMap to clear all Entries.
public Object clone() {
try {
HashSet<E> newSet = (HashSet<E>) super.clone();
newSet.map = (HashMap<E, Object>) map.clone();
return newSet;
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
}
clone returns a superficial copy of this HashSet instance: the elements themselves are not copied.
Postscript:
Because HashSet is implemented using HashMap at the bottom, the implementation process becomes very simple. If you know HashMap better, then HashSet is a piece of cake. There are two methods that are very important for HashMap and HashSet. The next section will explain hashcode and equals in detail.
TreeSet
As HashSet is implemented based on HashMap, TreeSet is also implemented based on TreeMap. LZ explains the implementation mechanism of TreeMap in detail in "Java Improvement Chapter (27) - - TreeMap". If the guest officers read this blog or have a more detailed understanding of multiple TreeMaps, then the implementation of TreeSet is as simple as drinking water for you.
TreeSet Definition
We know that TreeMap is an ordered binary tree, and so is TreeSet, which provides ordered set. We know from the source code that TreeSet is based on AbstractSet, which implements Navigable Set, Cloneable, Serializable interfaces.
AbstractSet provides the backbone implementation of Set interface, thus minimizing the work required to implement this interface.
Navigable Set is an extended SortedSet with a navigation method that reports the closest matches for a given search target, which means that it supports a series of navigation methods. For example, find the best match with the specified target. Cloneable supports cloning and Serializable supports serialization.
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
At the same time, the following variables are defined in TreeSet.
private transient NavigableMap<E,Object> m;
//PRESENT is constructed as a key-value pair for Map
private static final Object PRESENT = new Object();
Its construction method is as follows:
//Default constructor, sorting according to the natural order of its elements
public TreeSet() {
this(new TreeMap<E,Object>());
}
//Construct a new TreeSet containing the specified collection elements, which are sorted in the natural order of their elements.
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
//Construct a new empty TreeSet, which sorts according to the specified comparator.
public TreeSet(Collection<? extends E> c) {
this();
addAll(c);
}
//Construct a new TreeSet that has the same mapping relationship and the same sort as the specified ordered set.
public TreeSet(SortedSet<E> s) {
this(s.comparator());
addAll(s);
}
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
II. Main Methods of TreeSet
1. add: Adds the specified element to this set if it does not already exist in the set.
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
//Whether the node is empty or not is judged when the tree is empty
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
//Non-empty tree, insertion location of node is searched according to incoming comparator
if (cpr != null) {
do {
parent = t;
//If the node is smaller than the root node, the left subtree will be found, otherwise the right subtree will be found.
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
//If the comparison return value of key is equal, update the value directly (the equals method is equal when general comparison is equal)
else
return t.setValue(value);
} while (t != null);
}
else {
//If there is no incoming comparator, it is sorted naturally
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
//Find the node is empty, insert directly, default is red node
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
//Adjustment of red-black tree after insertion
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
2. get: Get elements
public V get(Object key) {
Entry<K,V> p = getEntry(key);
return (p==null ? null : p.value);
}
This method is similar to the put process, except that insertion is replaced by lookup.
3. ceiling: Returns the smallest element in this set greater than or equal to the given element; if no such element exists, returns null.
public E ceiling(E e) {
return m.ceilingKey(e);
}
4. clear: Remove all elements in this set.
public void clear() {
m.clear();
}
5. clone: Returns a shallow copy of the TreeSet instance. It belongs to shallow copy.
public Object clone() {
TreeSet<E> clone = null;
try {
clone = (TreeSet<E>) super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
clone.m = new TreeMap<>(m);
return clone;
}
6. comparator: Returns a comparator that sorts the elements in this set; if the set uses the natural order of its elements, it returns null.
public Comparator<? super E> comparator() {
return m.comparator();
}
7. contains: If this set contains the specified element, it returns true.
public boolean contains(Object o) {
return m.containsKey(o);
}
8. descendingIterator: Returns an iterator that iterates in descending order on this set element.
public Iterator<E> descendingIterator() {
return m.descendingKeySet().iterator();
}
9. descendingSet: Returns the reverse view of the elements contained in this set.
public NavigableSet<E> descendingSet() {
return new TreeSet<>(m.descendingMap());
}
10, first: Returns the current first (lowest) element in this set.
public E first() {
return m.firstKey();
}
11. floor: Returns the largest element in this set less than or equal to the given element; if no such element exists, returns null.
public E floor(E e) {
return m.floorKey(e);
}
12. headSet: Returns a partial view of this set whose elements are strictly smaller than toElement.
public SortedSet<E> headSet(E toElement) {
return headSet(toElement, false);
}
13, higher: Returns the smallest element in this set that is strictly larger than the given element; if no such element exists, returns null.
public E higher(E e) {
return m.higherKey(e);
}
isEmpty: If this set does not contain any elements, return true.
public boolean isEmpty() {
return m.isEmpty();
}
Iterator: Returns an iterator that iterates in ascending order on the elements in this set.
public Iterator<E> iterator() {
return m.navigableKeySet().iterator();
}
16, last: Returns the last (highest) element currently in this set.
public E last() {
return m.lastKey();
}
17, lower: Returns the largest element in this set that is strictly smaller than the given element; if no such element exists, returns null.
public E lower(E e) {
return m.lowerKey(e);
}
pollFirst: Gets and removes the first (lowest) element; if this set is empty, returns null.
public E pollFirst() {
Map.Entry<E,?> e = m.pollFirstEntry();
return (e == null) ? null : e.getKey();
}
pollLast: Gets and removes the last (highest) element; if this set is empty, returns null.
public E pollLast() {
Map.Entry<E,?> e = m.pollLastEntry();
return (e == null) ? null : e.getKey();
}
20, remove: Remove the specified element from the set if it exists in the set.
public boolean remove(Object o) {
return m.remove(o)==PRESENT;
}
This method is similar to put, except that insertion is replaced by deletion and adjusted after deletion.
21, size: Returns the number of elements in the set (the capacity of the set).
public int size() {
return m.size();
}
22,subSet: Returns a partial view of this set
/**
* Returns a partial view of this set with elements ranging from fromElement to toElement.
*/
public NavigableSet<E> subSet(E fromElement, boolean fromInclusive,
E toElement, boolean toInclusive) {
return new TreeSet<>(m.subMap(fromElement, fromInclusive,
toElement, toInclusive));
}
/**
* Returns a partial view of this set whose elements range from fromElement (including) to toElement (excluding).
*/
public SortedSet<E> subSet(E fromElement, E toElement) {
return subSet(fromElement, true, toElement, false);
}
tailSet: Returns a partial view of this set
/**
* Returns a partial view of this set whose elements are greater than (or equal to, if inclusive is true) from Element.
*/
public NavigableSet<E> tailSet(E fromElement, boolean inclusive) {
return new TreeSet<>(m.tailMap(fromElement, inclusive));
}
/**
* Returns a partial view of this set whose elements are greater than or equal to fromElement.
*/
public SortedSet<E> tailSet(E fromElement) {
return tailSet(fromElement, true);
}
Last
Because TreeSet is based on TreeMap, if we have a certain understanding of TreeMap, TreeSet is a piece of cake, we can see from the source code in TreeSet that its implementation process is very simple, almost all methods are based on TreeMap.
LinkedHashSet
How LinkedHashSet works internally
LinkedHashSet is an "extended version" of HashSet. HashSet does not care what order it is. The difference is that LinkedHashSet maintains "insertion order". HashSet uses HashMap objects to store its elements, while LinkedHashSet uses LinkedHashMap objects to store and process its elements. In this article, we'll see how LinkedHashSet works internally and how insertion order is maintained.
Let's first look at the constructor of LinkedHashSet. There are four constructors in the LinkedHashSet class. These constructors simply call the parent constructor (such as the constructor of the HashSet class). Let's look at how the constructor of LinkedHashSet is defined.
//Constructor - 1
public LinkedHashSet(int initialCapacity, float loadFactor)
{
super(initialCapacity, loadFactor, true); //Calling super class constructor
}
//Constructor - 2
public LinkedHashSet(int initialCapacity)
{
super(initialCapacity, .75f, true); //Calling super class constructor
}
//Constructor - 3
public LinkedHashSet()
{
super(16, .75f, true); //Calling super class constructor
}
//Constructor - 4
public LinkedHashSet(Collection<? extends E> c)
{
super(Math.max(2*c.size(), 11), .75f, true); //Calling super class constructor
addAll(c);
}
In the code snippet above, you may notice that four constructors call the same parent constructor. This constructor (parent class, translator's note) is a private constructor in a package (see the code below, HashSet's constructor is not public, translator's note), it can only be used by LinkedHashSet.
This constructor requires parameters such as initial capacity, load factor and a boolean type dumb value. This dumb parameter is only used to distinguish this constructor from other constructors with initial capacity and load factor parameters in HashSet. Here is the definition of this constructor.
HashSet(int initialCapacity, float loadFactor, boolean dummy)
{
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
Obviously, inside the constructor, a LinkedHashMap object is initialized, which happens to be used by the LinkedHashSet to store its elements.
LinkedHashSet does not have its own methods, all of which inherit from its parent HashSet, so all operations on LinkedHashSet are like operations on HashSet.
The only difference is that different objects are used internally to store elements. In HashSet, the inserted elements are saved as keys of HashMap, while in LinkedHashSet, they are considered keys of LinkedHashMap.
These keys correspond to the constant PRESENT (PRESENT is the static member variable of HashSet).
How LinkedHashSet Maintains Insertion Order
LinkedHashSet uses LinkedHashMap objects to store its elements, and the elements inserted into LinkedHashSet are actually saved as keys to LinkedHashMap.
Each key-value pair of LinkedHashMap is instantiated through the internal static class Entry < K, V>. This Entry < K, V > class inherits the HashMap.Entry class.
This static class adds two member variables, before and after, to maintain the insertion order of LinkedHasMap elements. These two member variables point to the former and the latter elements respectively, which makes LinkedHashMap behave like a two-way linked list.
private static class Entry<K,V> extends HashMap.Entry<K,V>
{
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
}
The first two member variables of the LinkedHashMap inner class, before and after, as seen from the above code, are responsible for maintaining the insertion order of LinkedHashSet. The member variable header defined by LinkedHashMap holds the header node of this two-way linked list. Header is defined as follows.
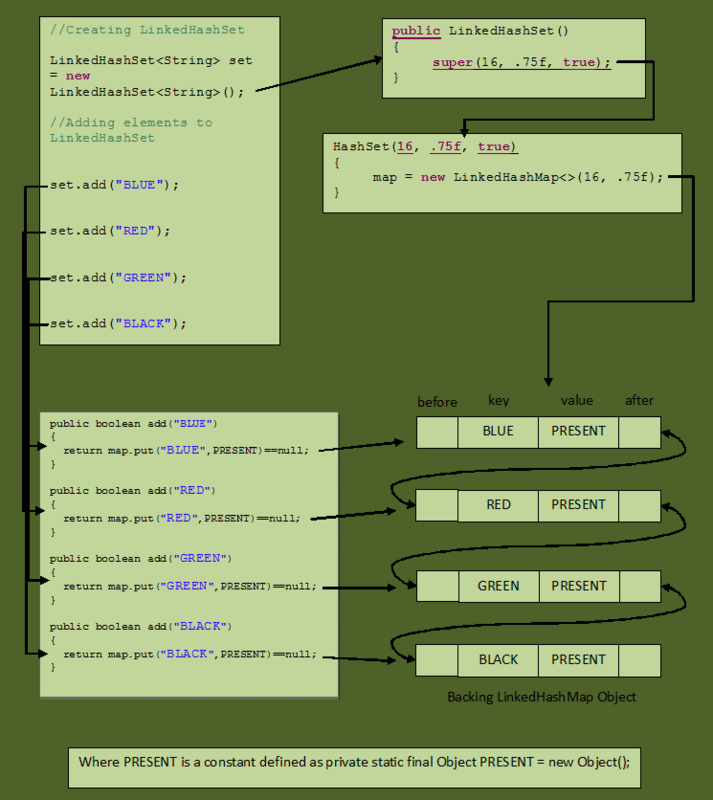
Next, look at an example to see how LinkedHashSet works internally.
public class LinkedHashSetExample
{
public static void main(String[] args)
{
//Creating LinkedHashSet
LinkedHashSet<String> set = new LinkedHashSet<String>();
//Adding elements to LinkedHashSet
set.add("BLUE");
set.add("RED");
set.add("GREEN");
set.add("BLACK");
}
}
The following picture shows how the program works.