2, J.U.C

1. * AQS principle
1. General
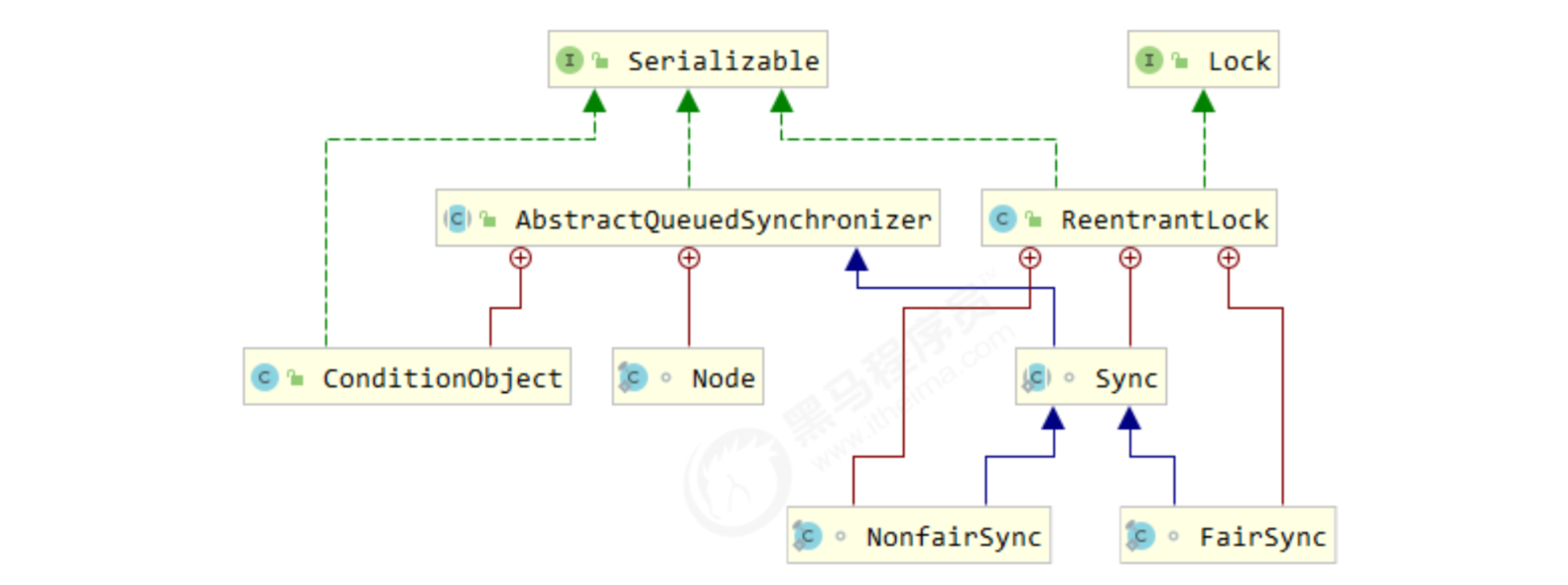
Its full name is AbstractQueuedSynchronizer, which is the framework of blocking locks and related synchronizer tools
characteristic:
- The state attribute is used to represent the state of resources (exclusive mode and shared mode). Subclasses need to define how to maintain this state and control how to obtain and release locks
- getState - get state
- setState - set state
- compareAndSetState - cas mechanism sets state state
- Exclusive mode allows only one thread to access resources, while shared mode allows multiple threads to access resources
- A FIFO based wait queue is provided, which is similar to the EntryList of Monitor
- Condition variables are used to implement the wait and wake-up mechanism. Multiple condition variables are supported, similar to the WaitSet of Monitor
Subclasses mainly implement such methods (UnsupportedOperationException is thrown by default)
- tryAcquire
- tryRelease
- tryAcquireShared
- tryReleaseShared
- isHeldExclusively
Get lock pose
// If lock acquisition fails
if (!tryAcquire(arg)) {
// After joining the queue, you can choose to block the current thread park unpark
}
Release lock posture
// If the lock is released successfully
if (tryRelease(arg)) {
// Let the blocked thread resume operation
}
2. Implement non reentrant lock
Custom synchronizer, custom lock
With a custom synchronizer, it is easy to reuse AQS and realize a fully functional custom lock
// Custom lock (non reentrant lock is implemented here)
class MyLock implements Lock {
// Synchronizer class - an exclusive lock is implemented here
class MySync extends AbstractQueuedSynchronizer {
// Attempt to acquire lock
@Override
protected boolean tryAcquire(int arg) {
if (compareAndSetState(0, 1)) {
// true, locking succeeded
// Set owner as the current thread
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
// Attempt to release the lock
@Override
protected boolean tryRelease(int arg) {
// Note the order here to prevent reordering of JVM instructions
setExclusiveOwnerThread(null);
setState(0); // Write barrier
return true;
}
// Do you hold an exclusive lock
@Override
protected boolean isHeldExclusively() {
return getState() == 1;
}
public Condition newCondition() {
return new ConditionObject();
}
}
private final MySync sync = new MySync();
// Lock - if unsuccessful, it will enter the waiting queue
@Override
public void lock() {
sync.acquire(1);
}
// Lock, interruptible
@Override
public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}
// Try locking - try once
@Override
public boolean tryLock() {
return sync.tryAcquire(1);
}
// Attempt to lock - with timeout
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
return sync.tryAcquireNanos(1, unit.toNanos(time));
}
// Unlock
@Override
public void unlock() {
sync.release(1);
}
// Create condition variable
@Override
public Condition newCondition() {
return sync.newCondition();
}
}
Test it
package top.onefine.test.c8;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.AbstractQueuedSynchronizer;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
@Slf4j(topic = "c.TestAqs")
public class TestAqs {
public static void main(String[] args) throws InterruptedException {
MyLock lock = new MyLock();
new Thread(() -> {
lock.lock();
// lock.lock(); // Cannot re-enter the lock. Locking failed here
try {
log.debug("locking...");
// TimeUnit.SECONDS.sleep(2);
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
log.debug("unlocking!");
lock.unlock();
}
}, "t1").start();
TimeUnit.MILLISECONDS.sleep(100);
new Thread(() -> {
lock.lock();
try {
log.debug("locking...");
} finally {
log.debug("unlocking!");
lock.unlock();
}
}, "t2").start();
}
}
output

Non reentrant test
If you change to the following code, you will find that you will also be blocked (locking will only be printed once)
lock.lock();
log.debug("locking...");
lock.lock();
log.debug("locking...");
3. Experience
origin
Early programmers would use one synchronizer to implement another similar synchronizer, such as using reentrant locks to implement semaphores, or vice versa. This is obviously not elegant enough, so AQS was created in JSR166 (java specification proposal) to provide this common synchronizer mechanism.
target
Functional objectives to be achieved by AQS
- The blocked version acquires the lock acquire and the non blocked version attempts to acquire the lock tryAcquire
- Get lock timeout mechanism
- By interrupting the cancellation mechanism
- Exclusive mechanism and sharing mechanism
- Waiting mechanism when conditions are not met
Performance goals to achieve
Instead, the primary performance goal here is scalability: to predictably maintain efficiency even, or especially, when synchronizers are contended.
Design
The basic idea of AQS is actually very simple
Logic for obtaining locks
while(state Status not allowed to get) {
if(This thread is not in the queue yet) {
Join the team and block
}
}
The current thread is dequeued
Logic for releasing locks
if(state Status allowed) {
Recover blocked threads(s)
}
main points
- Atomic maintenance state
- Blocking and resuming threads
- Maintenance queue
- state design
- state uses volatile with cas to ensure its atomicity during modification
- State uses 32bit int to maintain the synchronization state, because the test results using long on many platforms are not ideal
- Blocking recovery design
- The early APIs that control thread pause and resume include suspend and resume, but they are not available because suspend will not be aware if resume is called first
- The solution is to use Park & unpark to pause and resume threads. The specific principle has been mentioned before. There is no problem with unpark and then park
- Park & unpark is for the thread, not for the synchronizer, so the control granularity is more fine
- park threads can also be interrupted by interrupt
- Queue design
- FIFO first in first out queue is used, and priority queue is not supported
- CLH queue is a one-way lockless queue
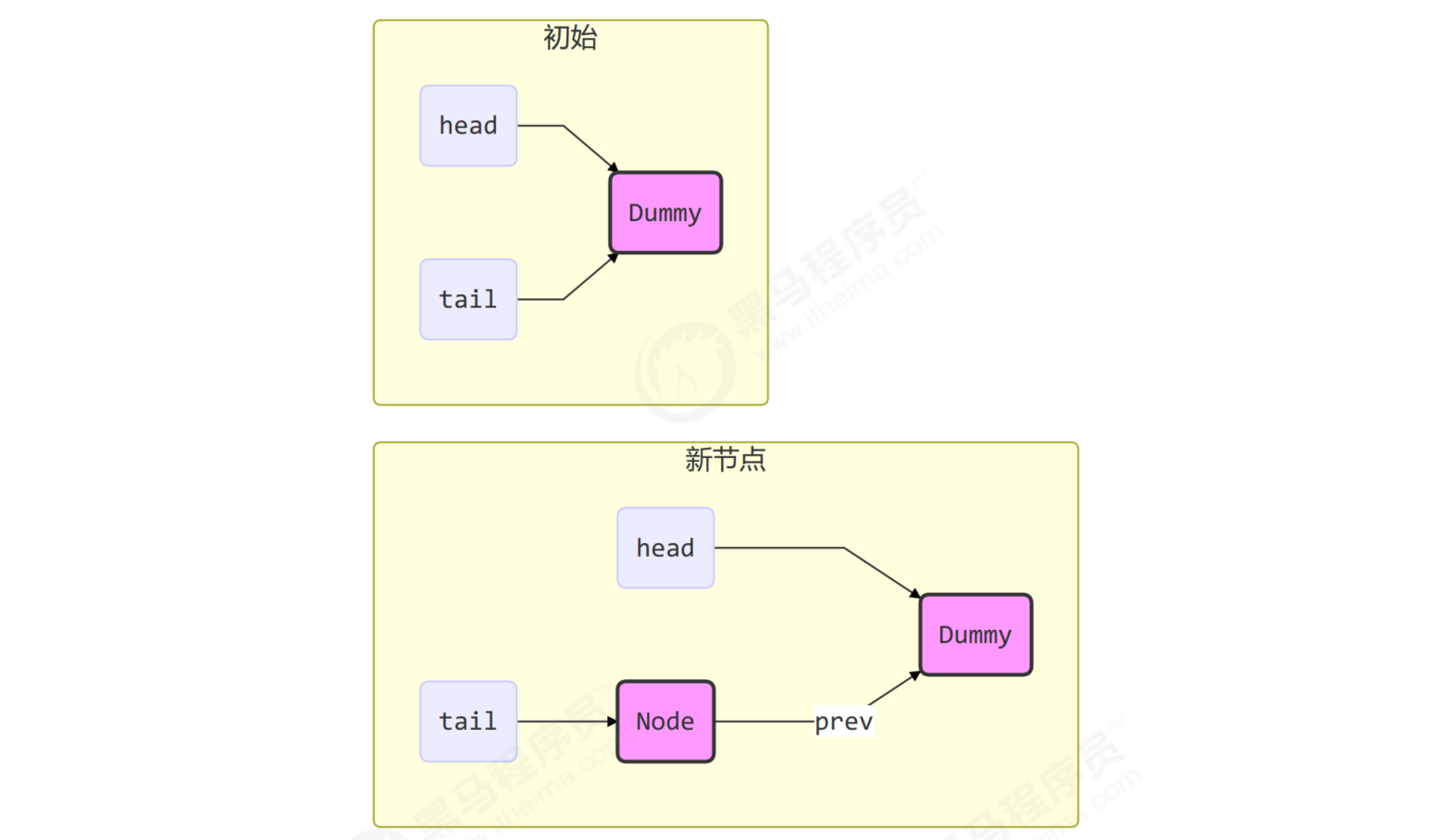
There are two pointer nodes in the queue, head and tail, which are decorated with volatile and used with cas. Each node has a state to maintain the node state
For the queued pseudo code, only the atomicity of tail assignment needs to be considered
do {
// Original tail
Node prev = tail;
// Use cas to change the original tail to node
} while(tail.compareAndSet(prev, node))
Outgoing pseudo code
// prev is the previous node
while((Node prev=node.prev).state != Wake up status) {
}
// Set header node
head = node;
CLH benefits:
- No lock, use spin
- Fast, non blocking
AQS improves CLH in some ways
private Node enq(final Node node) {
for (;;) {
Node t = tail;
// There is no element in the queue. tail is null
if (t == null) {
// Change head from null - > dummy
if (compareAndSetHead(new Node()))
tail = head;
} else {
// Set the prev of node to the original tail
node.prev = t;
// Set the tail from the original tail to node
if (compareAndSetTail(t, node)) {
// The next of the original tail is set to node
t.next = node;
return t;
}
}
}
}
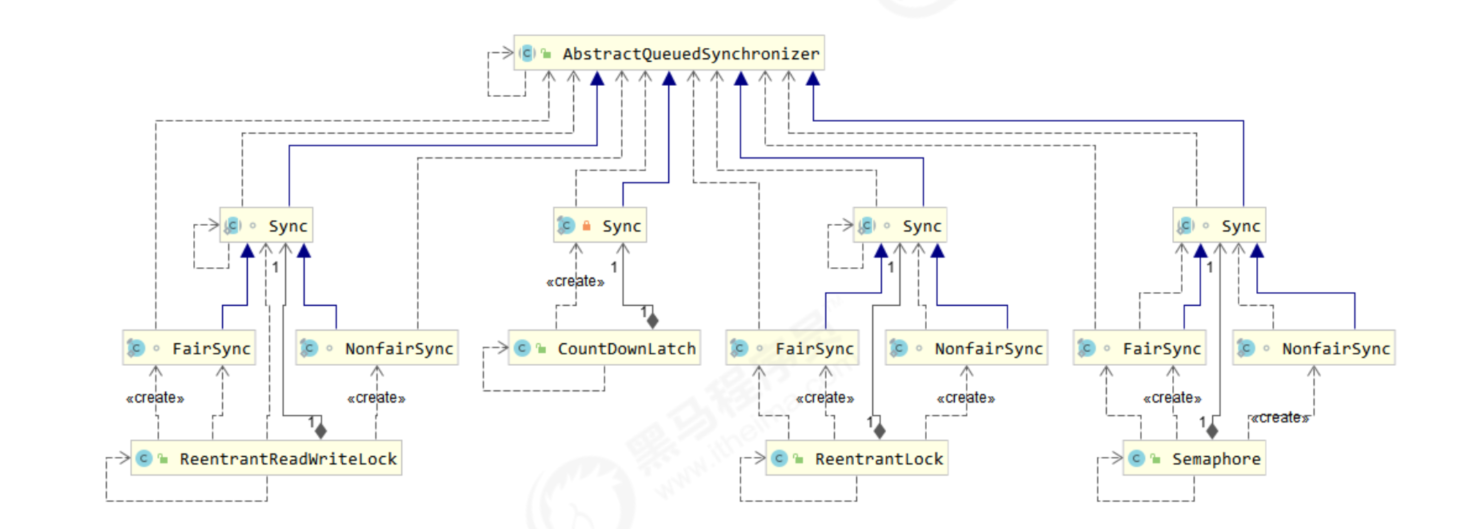
It mainly uses the concurrency tool class of AQS
2. * ReentrantLock principle
1. Implementation principle of unfair lock
Lock and unlock process
Starting from the constructor, the default is the implementation of unfair lock
public ReentrantLock() {
sync = new NonfairSync();
}
NonfairSync inherits from AQS
When there is no competition
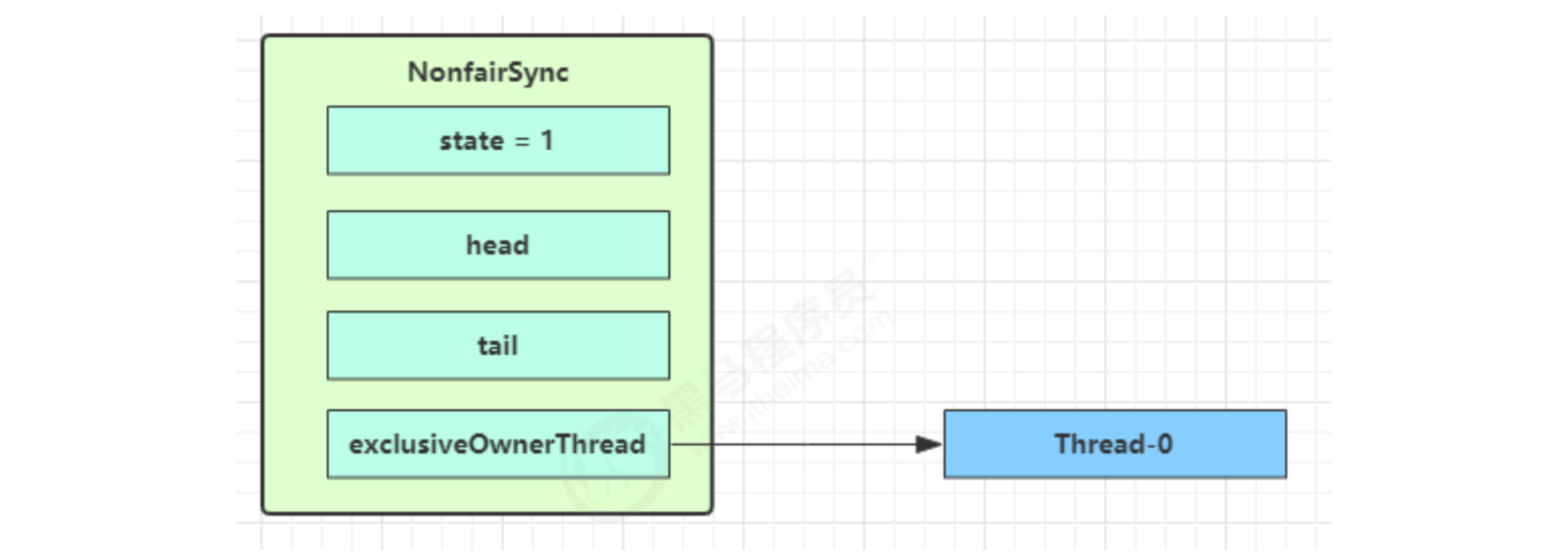
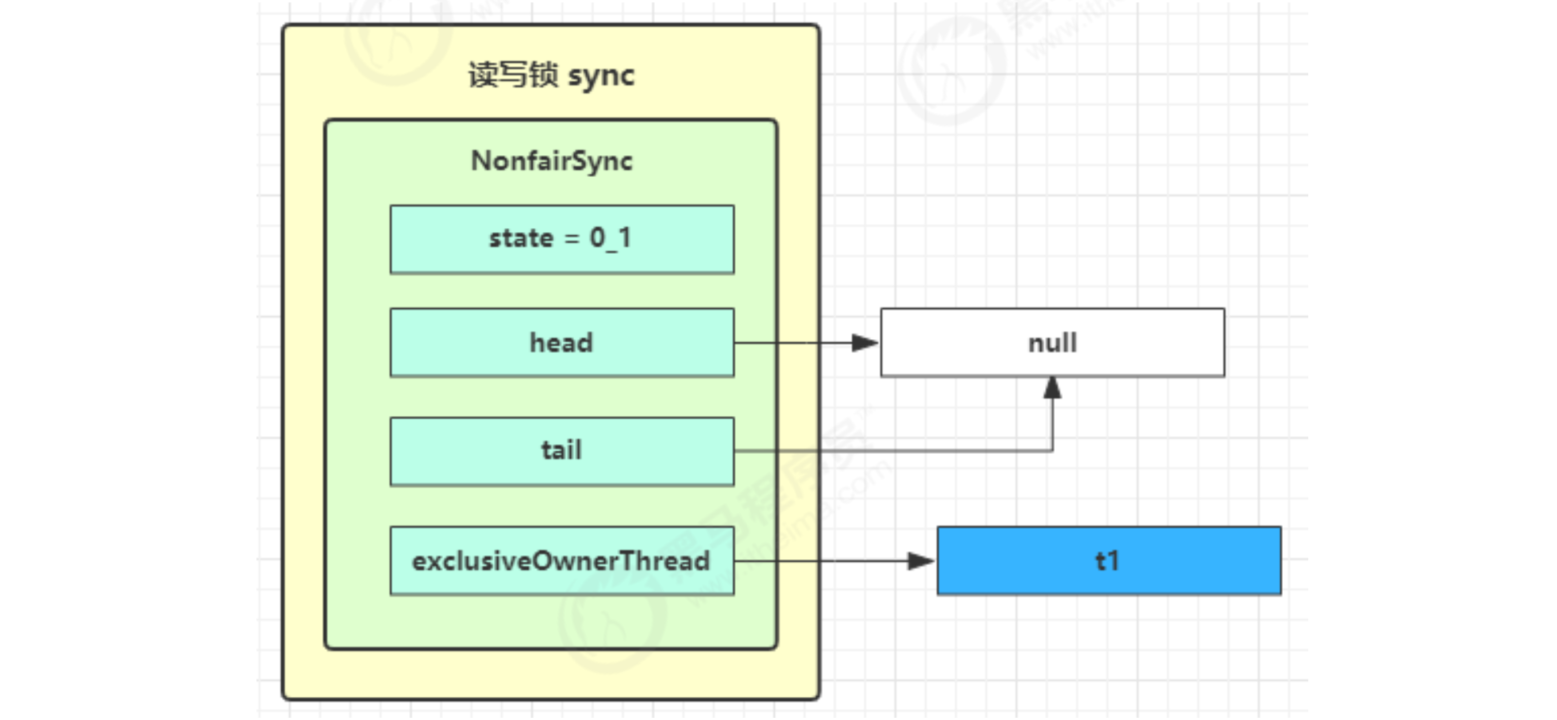
When the first competition appears
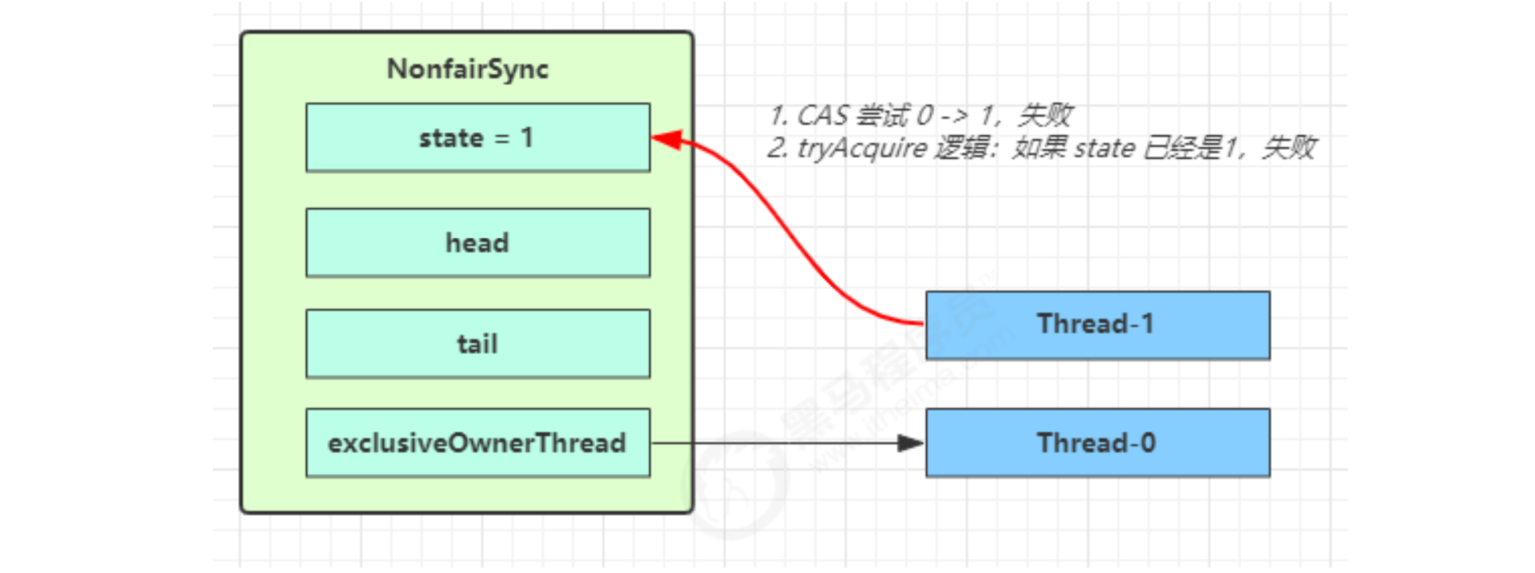
Thread-1 executed
- CAS tried to change state from 0 to 1, but failed
- Enter the tryAcquire logic. At this time, the state is already 1, and the result still fails
- Next, enter the addWaiter logic to construct the Node queue
- The yellow triangle in the figure indicates the waitStatus status of the Node, where 0 is the default normal status
- Node creation is lazy
- The first Node is called Dummy or sentinel. It is used to occupy bits and is not associated with threads
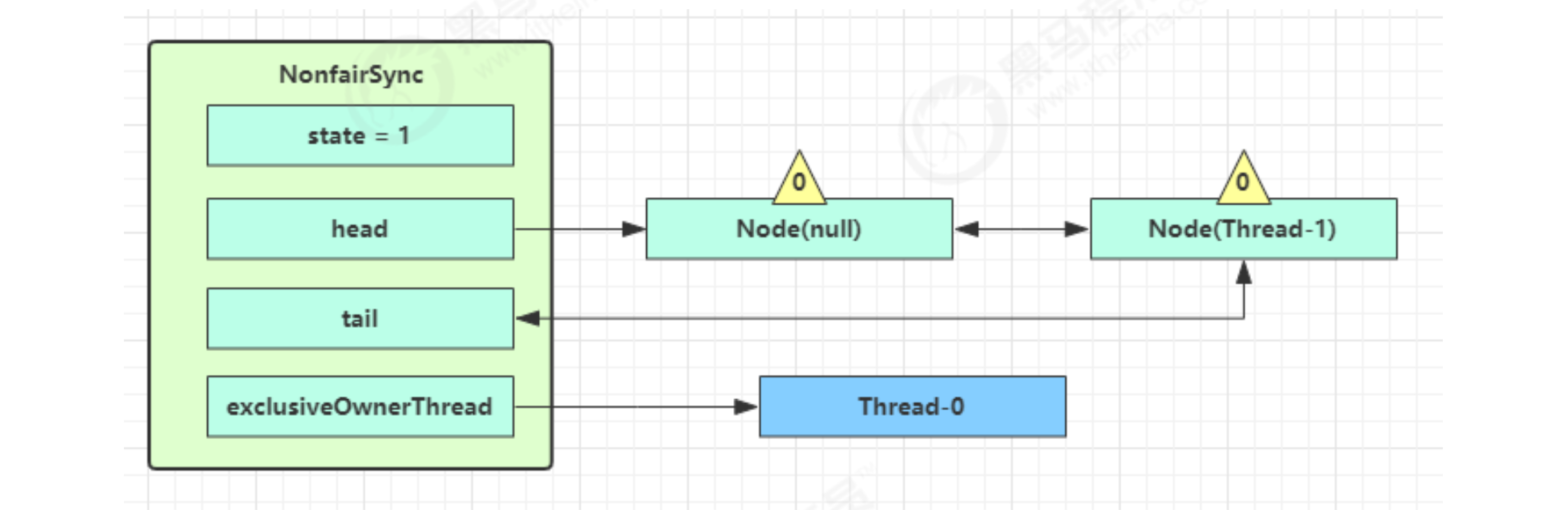
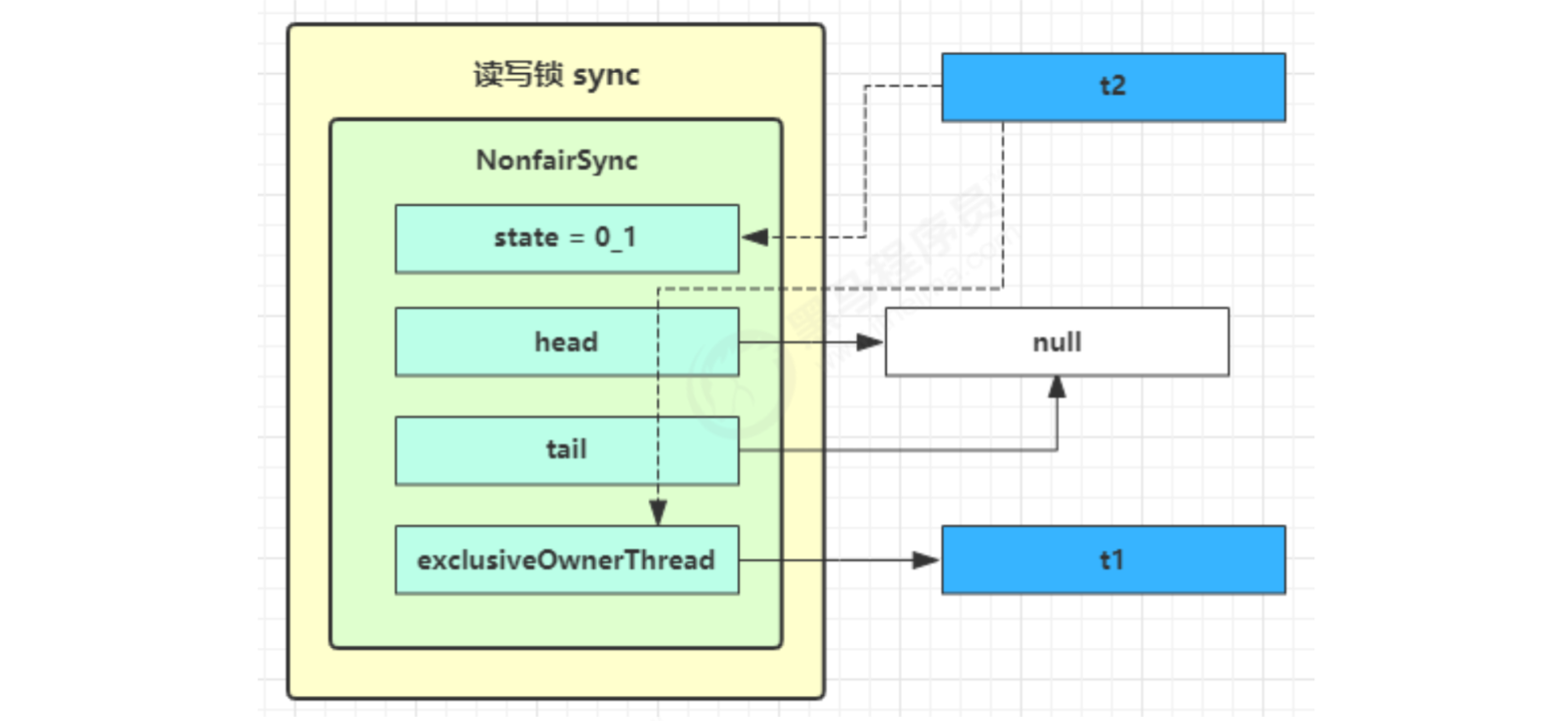
The current thread enters the acquirequeueueueueueueueued logic
- Acquirequeueueued will keep trying to obtain locks in an endless loop, and enter park blocking after failure
- If you are next to the head (second), try to acquire the lock again. Of course, the state is still 1 and fails
- Enter the shouldParkAfterFailedAcquire logic, change the waitStatus of the precursor node, that is, head, to - 1, and return false this time
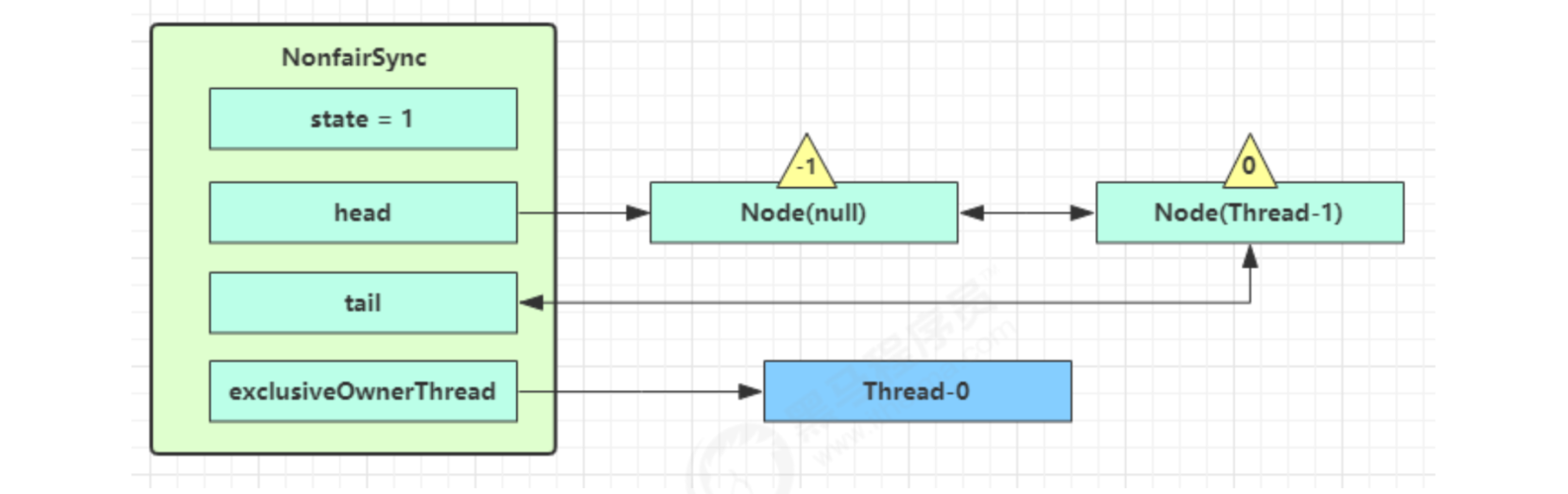
- shouldParkAfterFailedAcquire returns to acquirequeueueueued after execution. Try to acquire the lock again. Of course, the state is still 1 and fails
- When you enter shouldParkAfterFailedAcquire again, because the waitStatus of its precursor node is - 1, true is returned this time
- Enter parkAndCheckInterrupt, Thread-1 park (gray)
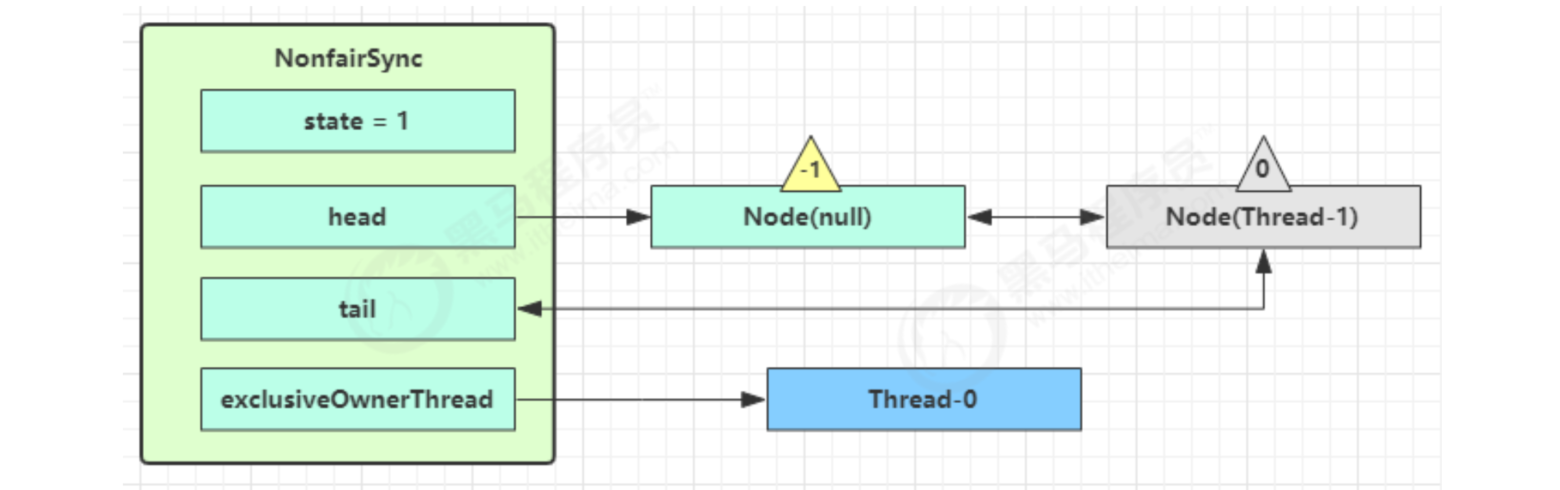
Again, multiple threads go through the above process, and the competition fails, which becomes like this
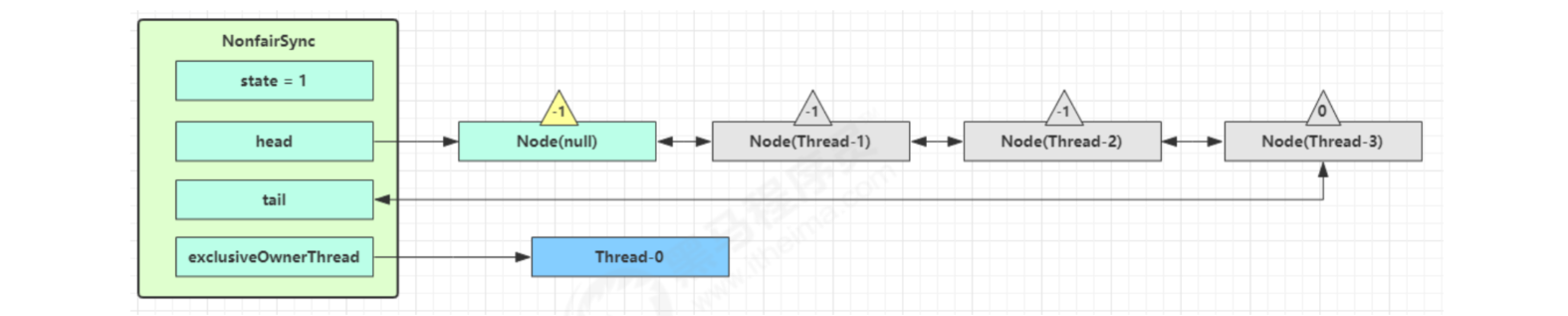
Thread-0 releases the lock and enters the tryRelease process. If successful
- Set exclusiveOwnerThread to null
- state = 0

The current queue is not null, and the waitstatus of head = - 1. Enter the unparksuccess process
Find the Node closest to the head in the queue (not cancelled), and unpark will resume its operation. In this case, it is Thread-1
Return to the acquirequeueueueueued process of Thread-1
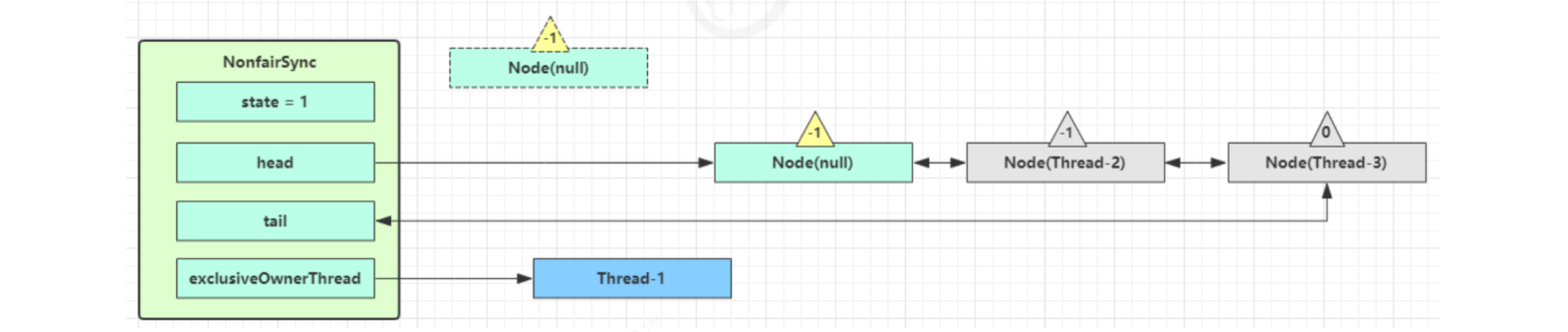
If the lock is successful (no competition), it will be set
- exclusiveOwnerThread is Thread-1, state = 1
- The head points to the Node where Thread-1 is just located, and the Node clears the Thread
- The original head can be garbage collected because it is disconnected from the linked list
- If there are other threads competing at this time (unfair embodiment), for example, Thread-4 comes at this time
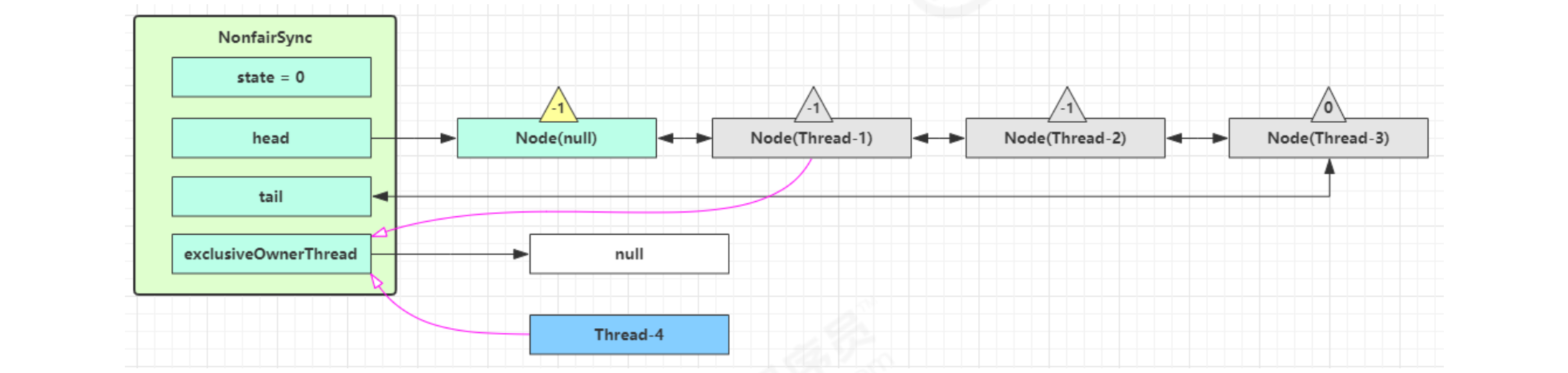
If Thread-4 takes the lead again
- Thread-4 is set to exclusiveOwnerThread, state = 1
- Thread-1 enters the acquirequeueueueueueueueued process again, fails to obtain the lock, and re enters the park block
Lock source code
// Sync inherited from AQS
static final class NonfairSync extends Sync {
private static final long serialVersionUID = 7316153563782823691L;
// Lock implementation
final void lock() {
// First, use cas to try (only once) to change the state from 0 to 1. If successful, it means that an exclusive lock has been obtained
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
// If the attempt fails, enter a
acquire(1);
}
// A method inherited from AQS, which is easy to read, is placed here
public final void acquire(int arg) {
// ㈡ tryAcquire
if (
!tryAcquire(arg) &&
// When tryAcquire returns false, addWaiter four is called first, followed by acquirequeueueueued five
acquireQueued(addWaiter(Node.EXCLUSIVE), arg)
) {
selfInterrupt();
}
}
// Two into three
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
// Three inherited methods are easy to read and placed here
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
// If the lock has not been obtained
if (c == 0) {
// Try to obtain with cas, which reflects the unfairness: do not check the AQS queue
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
// If the lock has been obtained and the thread is still the current thread, it indicates that lock reentry has occurred
else if (current == getExclusiveOwnerThread()) {
// state++
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
// Failed to get. Go back to calling
return false;
}
// IV. The method inherited from AQS is easy to read and placed here
private Node addWaiter(Node mode) {
// Associate the current thread to a Node object in exclusive mode
Node node = new Node(Thread.currentThread(), mode);
// If tail is not null, cas tries to add the Node object to the end of AQS queue
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
// Bidirectional linked list
pred.next = node;
return node;
}
}
// Try to add Node to AQS and enter six steps
enq(node);
return node;
}
// Six AQS inherited methods, easy to read, put here
private Node enq(final Node node) {
for (; ; ) {
Node t = tail;
if (t == null) {
// Not yet. Set the head as the sentinel node (no corresponding thread, status 0)
if (compareAndSetHead(new Node())) {
tail = head;
}
} else {
// cas tries to add the Node object to the end of AQS queue
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
// Five AQS inherited methods, easy to read, put here
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (; ; ) {
final Node p = node.predecessor();
// The previous node is head, which means it's your turn (the node corresponding to the current thread). Try to get it
if (p == head && tryAcquire(arg)) {
// Get success, set yourself (the node corresponding to the current thread) as head
setHead(node);
// Previous node
p.next = null;
failed = false;
// Return interrupt flag false
return interrupted;
}
if (
// Judge whether to park and enter seven
shouldParkAfterFailedAcquire(p, node) &&
// park and wait. At this time, the status of the Node is set to Node.SIGNAL
parkAndCheckInterrupt()
) {
interrupted = true;
}
}
} finally {
if (failed)
cancelAcquire(node);
}
}
// VII. The method inherited from AQS is easy to read and placed here
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
// Gets the status of the previous node
int ws = pred.waitStatus;
if (ws == Node.SIGNAL) {
// If the previous node is blocking, you can also block it yourself
return true;
}
// >0 indicates cancellation status
if (ws > 0) {
// If the previous node is cancelled, the refactoring deletes all previous cancelled nodes and returns to the outer loop for retry
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
// It's not blocked this time
// However, if the next retry is unsuccessful, blocking is required. At this time, the status of the previous node needs to be set to Node.SIGNAL
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
// Eight blocks the current thread
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
return Thread.interrupted();
}
}
be careful
Whether unpark is required is determined by the waitStatus == Node.SIGNAL of the predecessor node of the current node, not the waitStatus of the current node
Unlock source code
// Sync inherited from AQS
static final class NonfairSync extends Sync {
// Unlock implementation
public void unlock() {
sync.release(1);
}
// The method inherited from AQS is easy to read and placed here
public final boolean release(int arg) {
// Try to release the lock and enter a
if (tryRelease(arg)) {
// Queue header node unpark
Node h = head;
if (
// Queue is not null
h != null &&
// Only when waitStatus == Node.SIGNAL, unpark is required
h.waitStatus != 0
) {
// Unpark the thread waiting in AQS and enters the second stage
unparkSuccessor(h);
}
return true;
}
return false;
}
// An inherited method, easy to read, is placed here
protected final boolean tryRelease(int releases) {
// state--
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
// Lock reentry is supported. It can be released successfully only when the state is reduced to 0
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
// II. The method inherited from AQS is easy to read and placed here
private void unparkSuccessor(Node node) {
// If the status is Node.SIGNAL, try to reset the status to 0
// It's ok if you don't succeed
int ws = node.waitStatus;
if (ws < 0) {
compareAndSetWaitStatus(node, ws, 0);
}
// Find the node that needs unpark, but this node is separated from the AQS queue and is completed by the wake-up node
Node s = node.next;
// Regardless of the cancelled nodes, find the top node of the AQS queue that needs unpark from back to front
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
LockSupport.unpark(s.thread);
}
}
2. Reentrant principle
static final class NonfairSync extends Sync {
// ...
// Sync inherited method, easy to read, put here
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
// If the lock has been obtained and the thread is still the current thread, it indicates that lock reentry has occurred
else if (current == getExclusiveOwnerThread()) {
// state++
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
// Sync inherited method, easy to read, put here
protected final boolean tryRelease(int releases) {
// state--
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
// Lock reentry is supported. It can be released successfully only when the state is reduced to 0
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
}
3. Interruptible principle
Non interruptible mode
In this mode, even if it is interrupted, it will still reside in the AQS queue. You can't know that you are interrupted until you get the lock
// Sync inherited from AQS
static final class NonfairSync extends Sync {
// ...
private final boolean parkAndCheckInterrupt() {
// If the break flag is already true, the park will be invalidated
LockSupport.park(this);
// interrupted clears the break flag
return Thread.interrupted();
}
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (; ; ) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null;
failed = false;
// You still need to obtain the lock before you can return to the broken state
return interrupted;
}
if (
shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt()
) {
// If the interrupt is awakened, the interrupt status returned is true
interrupted = true;
}
}
} finally {
if (failed)
cancelAcquire(node);
}
}
public final void acquire(int arg) {
if (
!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg)
) {
// If the interrupt status is true
selfInterrupt();
}
}
static void selfInterrupt() {
// Regenerate an interrupt
Thread.currentThread().interrupt();
}
}
Interruptible mode
static final class NonfairSync extends Sync {
public final void acquireInterruptibly(int arg) throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
// If the lock is not obtained, enter one
if (!tryAcquire(arg))
doAcquireInterruptibly(arg);
}
// A interruptible lock acquisition process
private void doAcquireInterruptibly(int arg) throws InterruptedException {
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (; ; ) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt()) {
// In the process of park, if it is interrupt ed, it will enter this field
// At this time, an exception is thrown without entering for (;) again
throw new InterruptedException();
}
}
} finally {
if (failed)
cancelAcquire(node);
}
}
}
4. Implementation principle of fair lock
static final class FairSync extends Sync {
private static final long serialVersionUID = -3000897897090466540L;
final void lock() {
acquire(1);
}
// The method inherited from AQS is easy to read and placed here
public final void acquire(int arg) {
if (
!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg)
) {
selfInterrupt();
}
}
// The main difference from non fair lock is the implementation of tryAcquire method
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
// First check whether there are precursor nodes in the AQS queue. If not, compete
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
} else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
// A method inherited from AQS, which is easy to read, is placed here
public final boolean hasQueuedPredecessors() {
Node t = tail;
Node h = head;
Node s;
// h != t indicates that there are nodes in the queue
return h != t &&
(
// (s = h.next) == null indicates whether there is a dick in the queue
(s = h.next) == null ||
// Or the second thread in the queue is not this thread
s.thread != Thread.currentThread()
);
}
}
5. Realization principle of conditional variable
Each condition variable actually corresponds to a waiting queue, and its implementation class is ConditionObject
await process
Start Thread-0 to hold the lock, call await, and enter the addConditionWaiter process of ConditionObject
Create a new Node whose status is - 2 (Node.CONDITION), associate Thread-0, and add it to the tail of the waiting queue
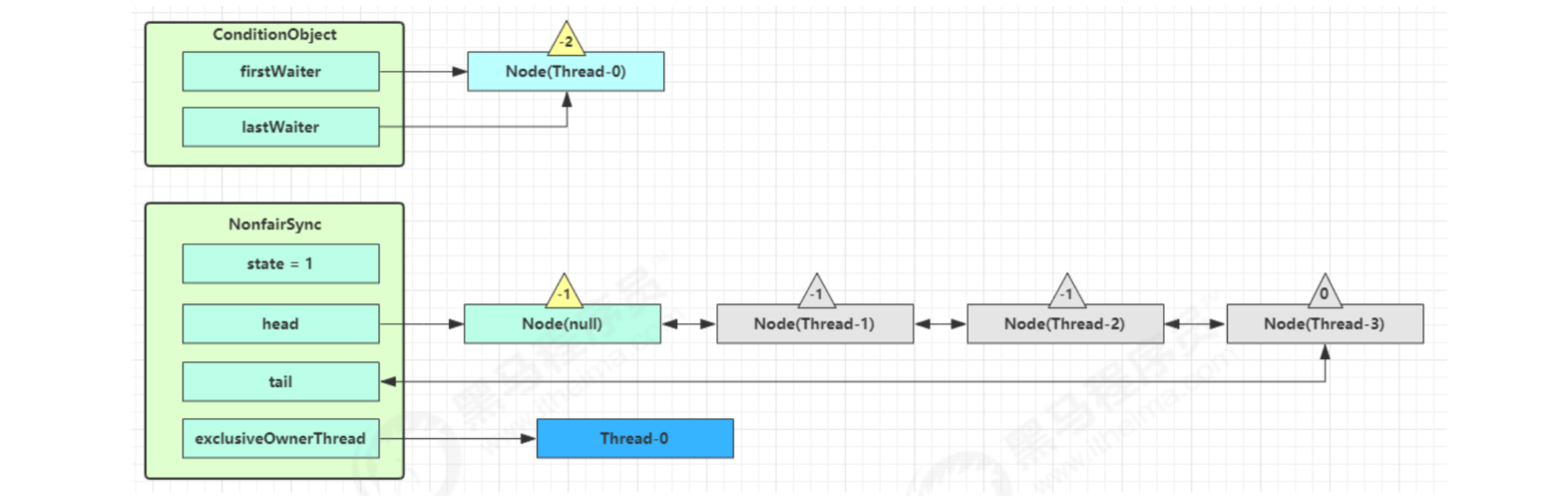
Next, enter the fully release process of AQS to release the lock on the synchronizer
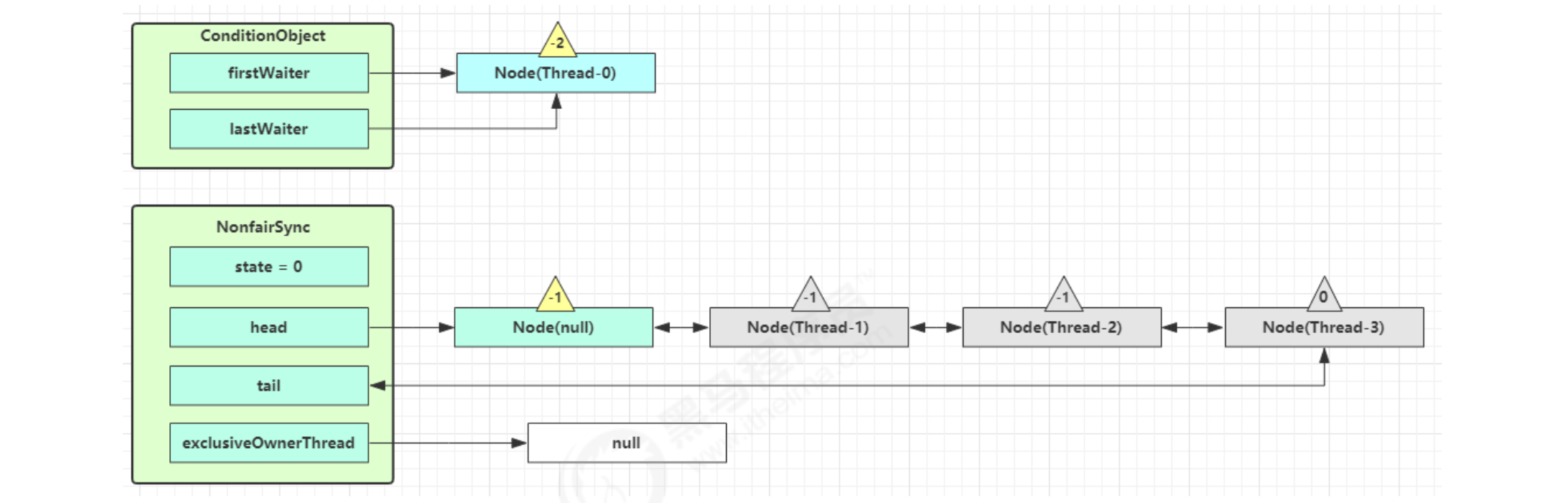
The next node in the unpark AQS queue competes for the lock. Assuming that there are no other competing threads, the Thread-1 competition succeeds
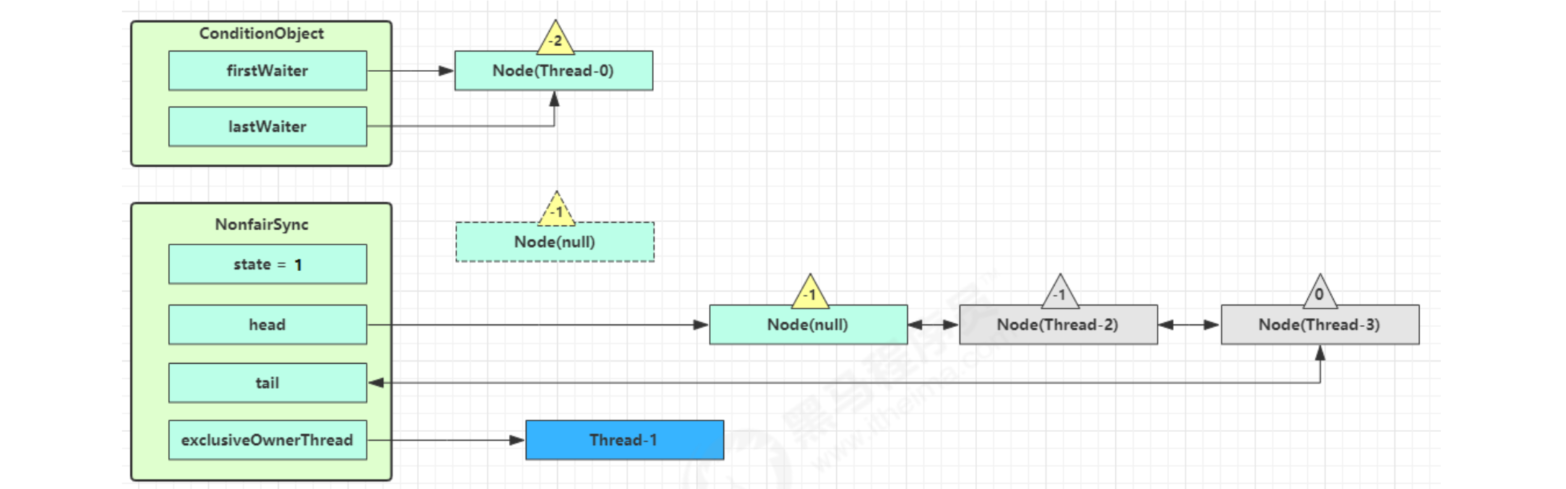
park blocking Thread-0
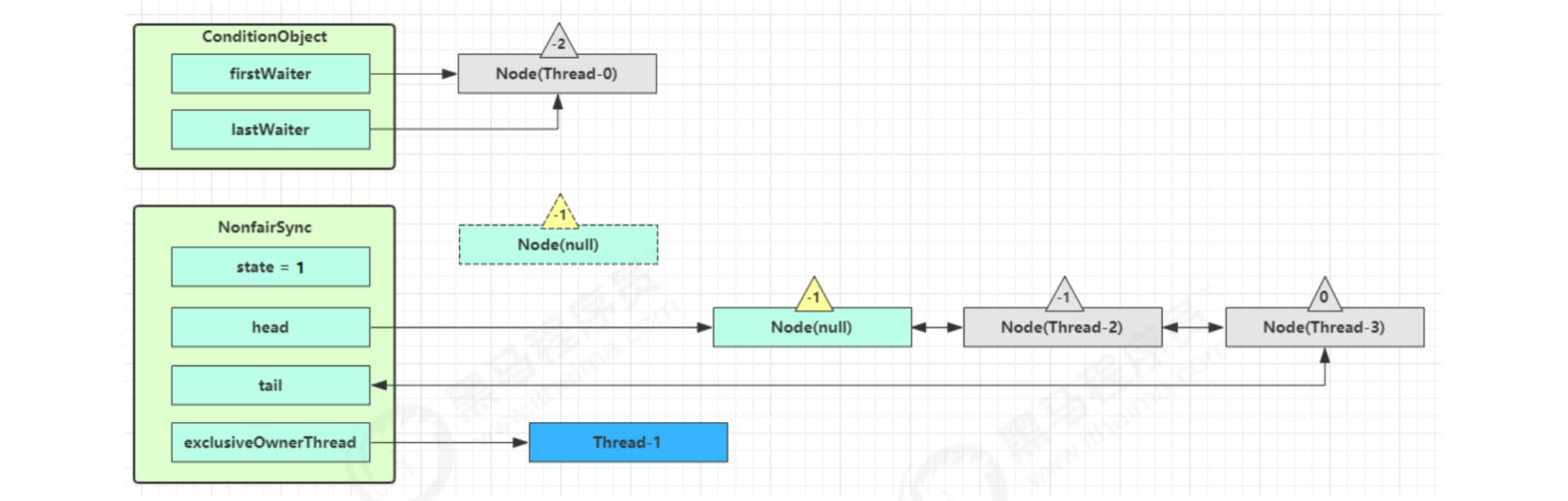
signal process
Suppose Thread-1 wants to wake up Thread-0
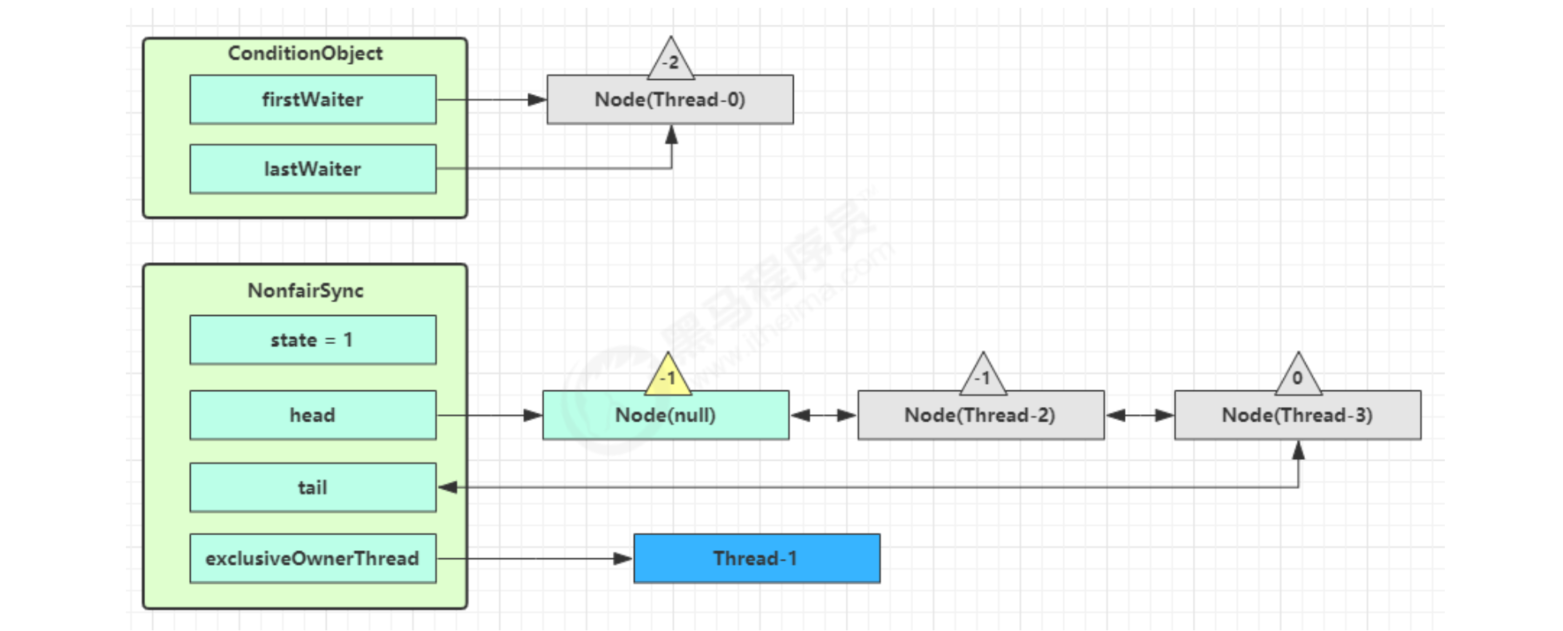
Enter the doSignal process of ConditionObject and obtain the first Node in the waiting queue, that is, the Node where Thread-0 is located
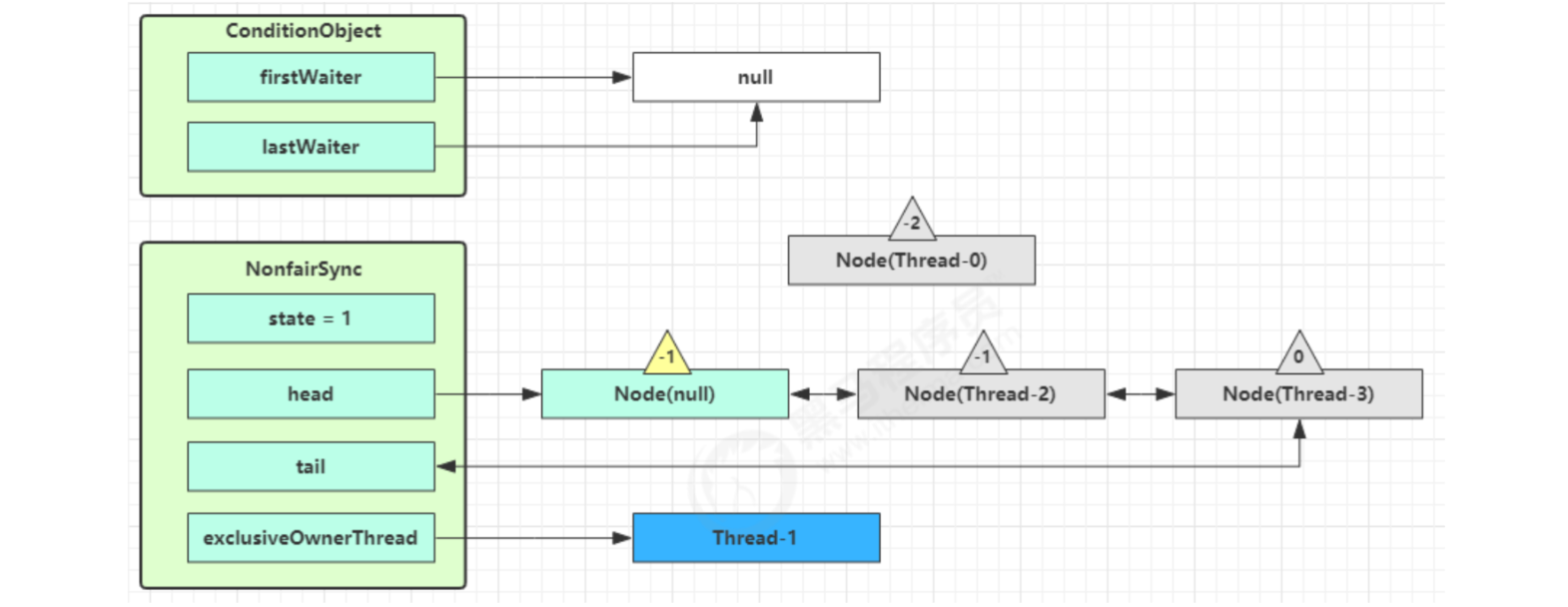
Execute the transferForSignal process, add the Node to the end of the AQS queue, change the waitStatus of Thread-0 to 0, and the waitStatus of Thread-3 to - 1
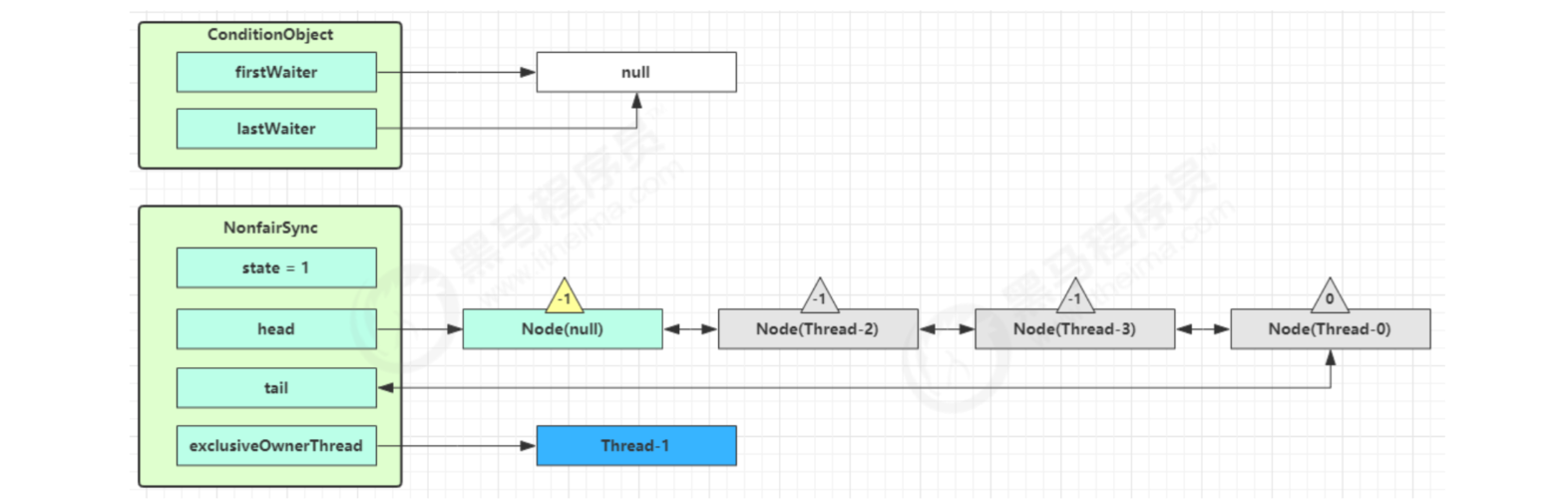
Thread-1 releases the lock and enters the unlock process
Source code
public class ConditionObject implements Condition, java.io.Serializable {
private static final long serialVersionUID = 1173984872572414699L;
// First waiting node
private transient Node firstWaiter;
// Last waiting node
private transient Node lastWaiter;
public ConditionObject() {
}
// Add a Node to the waiting queue
private Node addConditionWaiter() {
Node t = lastWaiter;
// All cancelled nodes are deleted from the queue linked list, as shown in Figure 2
if (t != null && t.waitStatus != Node.CONDITION) {
unlinkCancelledWaiters();
t = lastWaiter;
}
// Create a new Node associated with the current thread and add it to the end of the queue
Node node = new Node(Thread.currentThread(), Node.CONDITION);
if (t == null)
firstWaiter = node;
else
t.nextWaiter = node;
lastWaiter = node;
return node;
}
// Wake up - transfer the first node not cancelled to the AQS queue
private void doSignal(Node first) {
do {
// It's already the tail node
if ((firstWaiter = first.nextWaiter) == null) {
lastWaiter = null;
}
first.nextWaiter = null;
} while (
// Transfer the nodes in the waiting queue to the AQS queue. If it is unsuccessful and there are still nodes, continue to cycle for three times
!transferForSignal(first) &&
// Queue and node
(first = firstWaiter) != null
);
}
// External class methods are easy to read and placed here
// 3. If the node status is cancel, return false to indicate that the transfer failed, otherwise the transfer succeeded
final boolean transferForSignal(Node node) {
// If the status is no longer Node.CONDITION, it indicates that it has been cancelled
if (!compareAndSetWaitStatus(node, Node.CONDITION, 0))
return false;
// Join the end of AQS queue
Node p = enq(node);
int ws = p.waitStatus;
if (
// The previous node was cancelled
ws > 0 ||
// The status of the previous node cannot be set to Node.SIGNAL
!compareAndSetWaitStatus(p, ws, Node.SIGNAL)
) {
// unpark unblocks the thread to resynchronize the state
LockSupport.unpark(node.thread);
}
return true;
}
// Wake up all - wait for all nodes in the queue to transfer to the AQS queue
private void doSignalAll(Node first) {
lastWaiter = firstWaiter = null;
do {
Node next = first.nextWaiter;
first.nextWaiter = null;
transferForSignal(first);
first = next;
} while (first != null);
}
// ㈡
private void unlinkCancelledWaiters() {
// ...
}
// Wake up - you must hold a lock to wake up, so there is no need to consider locking in doSignal
public final void signal() {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
Node first = firstWaiter;
if (first != null)
doSignal(first);
}
// Wake up all - you must hold a lock to wake up, so there is no need to consider locking in dosignallall
public final void signalAll() {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
Node first = firstWaiter;
if (first != null)
doSignalAll(first);
}
// Non interruptible wait - until awakened
public final void awaitUninterruptibly() {
// Add a Node to the waiting queue, as shown in Figure 1
Node node = addConditionWaiter();
// Release the lock held by the node, see Figure 4
int savedState = fullyRelease(node);
boolean interrupted = false;
// If the node has not been transferred to the AQS queue, it will be blocked
while (!isOnSyncQueue(node)) {
// park blocking
LockSupport.park(this);
// If it is interrupted, only the interruption status is set
if (Thread.interrupted())
interrupted = true;
}
// After waking up, try to compete for the lock. If it fails, enter the AQS queue
if (acquireQueued(node, savedState) || interrupted)
selfInterrupt();
}
// External class methods are easy to read and placed here
// Fourth, because a thread may re-enter, it is necessary to release all States
final int fullyRelease(Node node) {
boolean failed = true;
try {
int savedState = getState();
if (release(savedState)) {
failed = false;
return savedState;
} else {
throw new IllegalMonitorStateException();
}
} finally {
if (failed)
node.waitStatus = Node.CANCELLED;
}
}
// Interrupt mode - resets the interrupt state when exiting the wait
private static final int REINTERRUPT = 1;
// Break mode - throw an exception when exiting the wait
private static final int THROW_IE = -1;
// Judge interrupt mode
private int checkInterruptWhileWaiting(Node node) {
return Thread.interrupted() ?
(transferAfterCancelledWait(node) ? THROW_IE : REINTERRUPT) :
0;
}
// V. application interrupt mode
private void reportInterruptAfterWait(int interruptMode)
throws InterruptedException {
if (interruptMode == THROW_IE)
throw new InterruptedException();
else if (interruptMode == REINTERRUPT)
selfInterrupt();
}
// Wait until awakened or interrupted
public final void await() throws InterruptedException {
if (Thread.interrupted()) {
throw new InterruptedException();
}
// Add a Node to the waiting queue, as shown in Figure 1
Node node = addConditionWaiter();
// Release the lock held by the node
int savedState = fullyRelease(node);
int interruptMode = 0;
// If the node has not been transferred to the AQS queue, it will be blocked
while (!isOnSyncQueue(node)) {
// park blocking
LockSupport.park(this);
// If interrupted, exit the waiting queue
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
// After exiting the waiting queue, you also need to obtain the lock of the AQS queue
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
// All cancelled nodes are deleted from the queue linked list, as shown in Figure 2
if (node.nextWaiter != null)
unlinkCancelledWaiters();
// Apply interrupt mode, see v
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
// Wait - until awakened or interrupted or timed out
public final long awaitNanos(long nanosTimeout) throws InterruptedException {
if (Thread.interrupted()) {
throw new InterruptedException();
}
// Add a Node to the waiting queue, as shown in Figure 1
Node node = addConditionWaiter();
// Release the lock held by the node
int savedState = fullyRelease(node);
// Get deadline
final long deadline = System.nanoTime() + nanosTimeout;
int interruptMode = 0;
// If the node has not been transferred to the AQS queue, it will be blocked
while (!isOnSyncQueue(node)) {
// Timed out, exiting the waiting queue
if (nanosTimeout <= 0L) {
transferAfterCancelledWait(node);
break;
}
// park blocks for a certain time, and spinForTimeoutThreshold is 1000 ns
if (nanosTimeout >= spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanosTimeout);
// If interrupted, exit the waiting queue
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
nanosTimeout = deadline - System.nanoTime();
}
// After exiting the waiting queue, you also need to obtain the lock of the AQS queue
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
// All cancelled nodes are deleted from the queue linked list, as shown in Figure 2
if (node.nextWaiter != null)
unlinkCancelledWaiters();
// Apply interrupt mode, see v
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
return deadline - System.nanoTime();
}
// Wait - until awakened or interrupted or timed out, the logic is similar to awaitNanos
public final boolean awaitUntil(Date deadline) throws InterruptedException {
// ...
}
// Wait - until awakened or interrupted or timed out, the logic is similar to awaitNanos
public final boolean await(long time, TimeUnit unit) throws InterruptedException {
// ...
}
// Tool method omitted
}
3. Read write lock
3.1 ReentrantReadWriteLock
When the read operation is much higher than the write operation, the read-write lock is used to make the read-read concurrent and improve the performance. Similar to select... From... Lock in share mode in the database
A data container class is provided, which uses the read() method for reading lock protection data and the write() method for writing lock protection data
@Slf4j(topic = "c.DataContainer")
class DataContainer {
private Object data;
private final ReentrantReadWriteLock rw = new ReentrantReadWriteLock();
private final ReentrantReadWriteLock.ReadLock r = rw.readLock();
private final ReentrantReadWriteLock.WriteLock w = rw.writeLock();
public Object read() {
log.debug("Acquire read lock...");
r.lock();
try {
log.debug("read");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
return data;
} finally {
log.debug("Release read lock...");
r.unlock();
}
}
public void write() {
log.debug("Get write lock...");
w.lock();
try {
log.debug("write in");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
} finally {
log.debug("Release write lock...");
w.unlock();
}
}
}
Test read locks - read locks can be concurrent
@Slf4j(topic = "c.TestReadWriteLock")
public class TestReadWriteLock {
public static void main(String[] args) {
DataContainer dataContainer = new DataContainer();
new Thread(() -> {
dataContainer.read();
}, "t1").start();
new Thread(() -> {
dataContainer.read();
}, "t2").start();
}
}
The output result shows that during Thread-0 locking, the read operation of Thread-1 is not affected

Test read lock write lock mutual blocking
@Slf4j(topic = "c.TestReadWriteLock")
public class TestReadWriteLock {
public static void main(String[] args) throws InterruptedException {
DataContainer dataContainer = new DataContainer();
new Thread(() -> {
dataContainer.read();
}, "t1").start();
Thread.sleep(100);
new Thread(() -> {
dataContainer.write();
}, "t2").start();
}
}
Output results
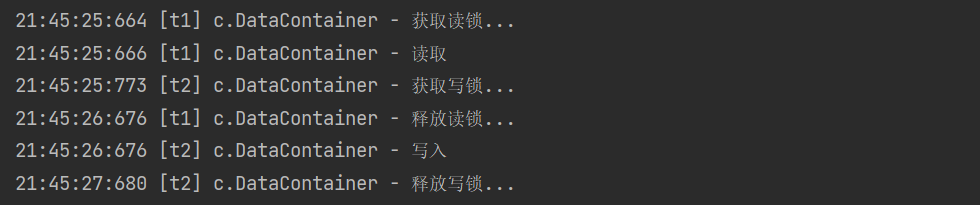
Write locks - write locks are also mutually blocking
@Slf4j(topic = "c.TestReadWriteLock")
public class TestReadWriteLock {
public static void main(String[] args) throws InterruptedException {
DataContainer dataContainer = new DataContainer();
new Thread(() -> {
dataContainer.write();
}, "t1").start();
new Thread(() -> {
dataContainer.write();
}, "t2").start();
}
}

matters needing attention
- Read lock does not support conditional variables
- Upgrade during reentry is not supported: that is, obtaining a write lock while holding a read lock will cause permanent waiting for obtaining a write lock
r.lock();
try {
// ...
w.lock();
try {
// ...
} finally{
w.unlock();
}
} finally{
r.unlock();
}
- Downgrade support on reentry: to obtain a read lock while holding a write lock
class CachedData {
Object data;
// Is it valid? If it fails, recalculate the data
volatile boolean cacheValid;
final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
void processCachedData() {
rwl.readLock().lock();
if (!cacheValid) {
// The read lock must be released before acquiring the write lock
rwl.readLock().unlock();
rwl.writeLock().lock();
try {
// Judge whether other threads have obtained the write lock and updated the cache to avoid repeated updates
if (!cacheValid) {
data = ...
cacheValid = true;
}
// Demote to read lock and release the write lock, so that other threads can read the cache
rwl.readLock().lock();
} finally {
rwl.writeLock().unlock();
}
}
// When you run out of data, release the read lock
try {
use(data);
} finally {
rwl.readLock().unlock();
}
}
}
*Application cache
1. Cache update strategy
When updating, clear the cache first or update the database first
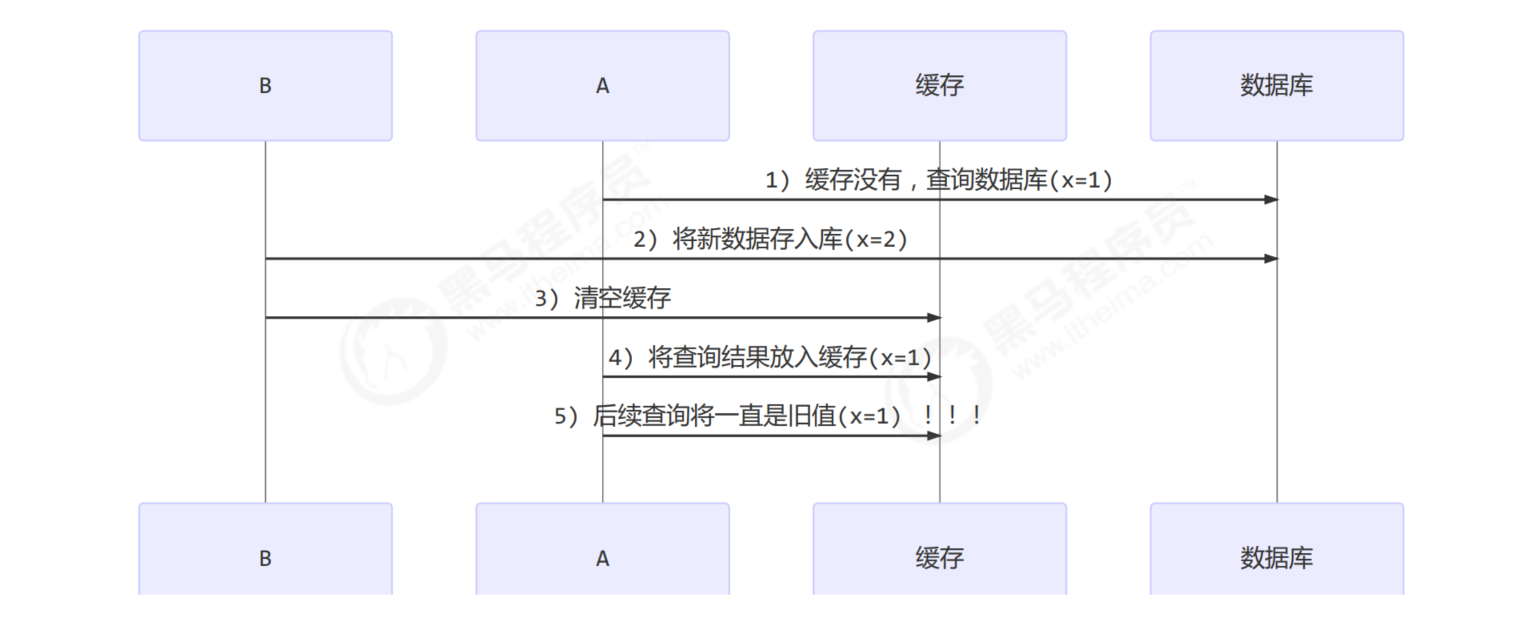
First clear cache
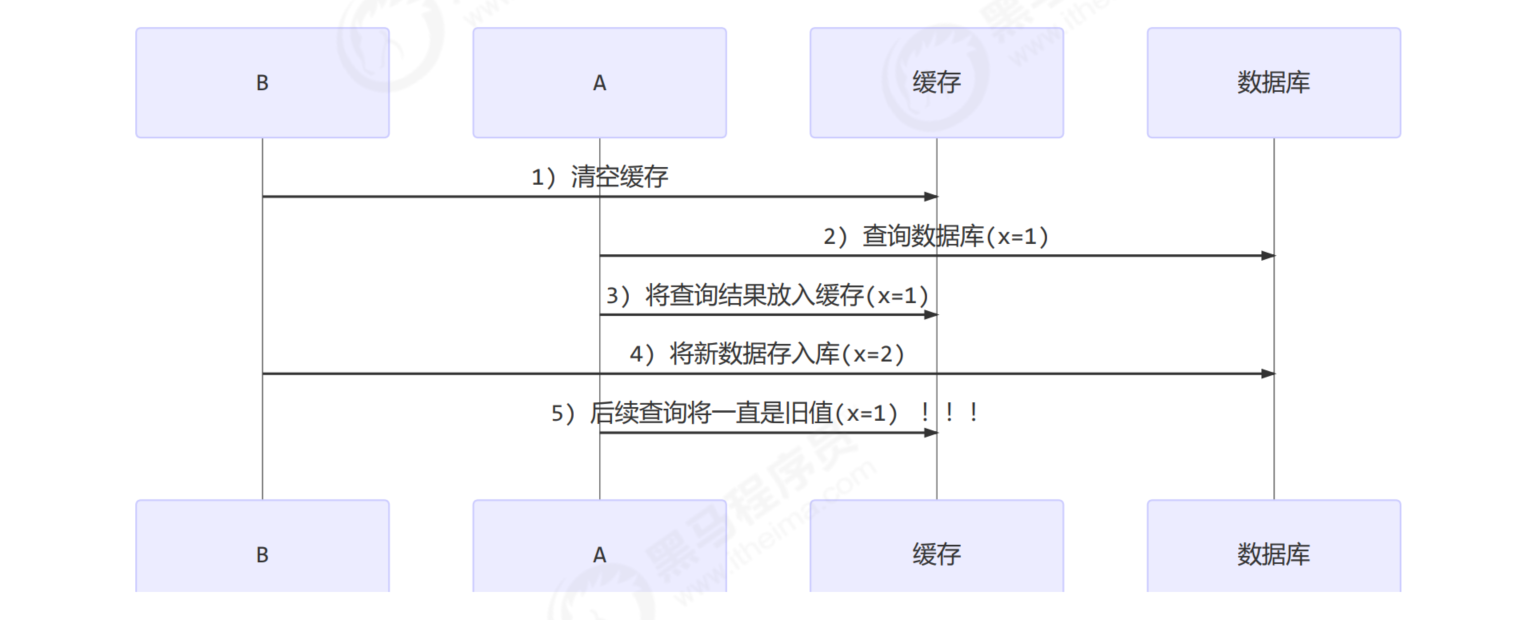
Update database first
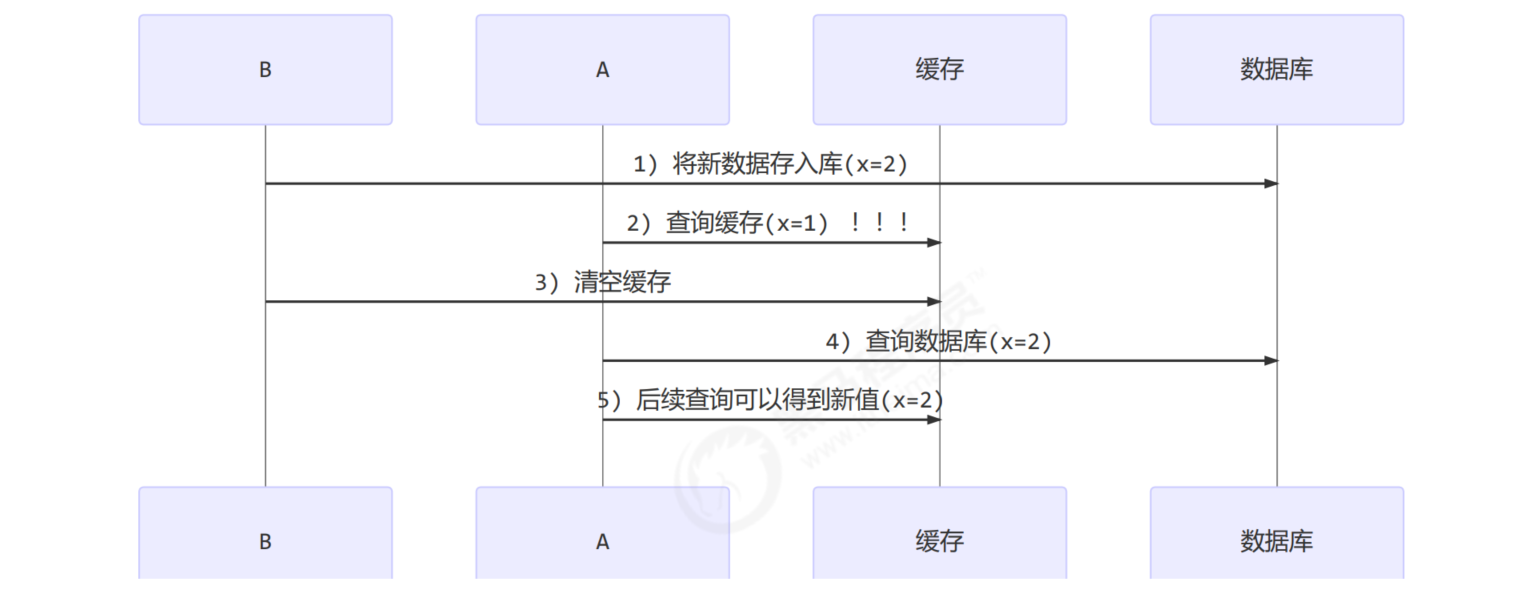
In addition, it is assumed that when query thread A queries the data, the cached data fails due to the expiration of time, or it is the first query
The chances of this happening are very small, see the facebook paper
2. Read / write locks implement consistent caching
Use read-write locks to implement a simple on-demand cache
package top.onefine.test.c8;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.EqualsAndHashCode;
import java.math.BigDecimal;
import java.util.*;
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class TestGenericDao {
public static void main(String[] args) {
GenericDao dao = new GenericDaoCached();
System.out.println("============> query");
String sql = "select * from emp where empno = ?";
int empno = 7369;
Emp emp = dao.queryOne(Emp.class, sql, empno);
System.out.println(emp);
emp = dao.queryOne(Emp.class, sql, empno);
System.out.println(emp);
emp = dao.queryOne(Emp.class, sql, empno);
System.out.println(emp);
System.out.println("============> to update");
dao.update("update emp set sal = ? where empno = ?", 800, empno);
emp = dao.queryOne(Emp.class, sql, empno);
System.out.println(emp);
}
}
// Decorator mode
// GenericDao implementation class is omitted to understand the idea
class GenericDaoCached extends GenericDao {
private final GenericDao dao = new GenericDao();
// Cache, key: sql statement, value: result
// As a cache, HashMap is not thread safe and needs to be protected
private final Map<SqlPair, Object> map = new HashMap<>();
private final ReentrantReadWriteLock rw = new ReentrantReadWriteLock();
@Override
public <T> T queryOne(Class<T> beanClass, String sql, Object... args) {
// Find it in the cache first and return it directly
SqlPair key = new SqlPair(sql, args);
// Add a read lock to prevent other threads from changing the cache
rw.readLock().lock(); // Read lock
try {
T value = (T) map.get(key);
if (value != null) {
return value;
}
} finally {
rw.readLock().unlock();
}
// Add a write lock to prevent other threads from reading and changing the cache
rw.writeLock().lock(); // Write lock
try {
// The upper part of the get method may be accessed by multiple threads, and the cache may have been filled with data
// To prevent repeated query of the database, verify again
T value = (T) map.get(key);
if (value == null) { // duplication check
// No in cache, query database
value = dao.queryOne(beanClass, sql, args);
map.put(key, value);
}
return value;
} finally {
rw.writeLock().unlock();
}
}
// Note the order: update db first and then cache
@Override
public int update(String sql, Object... args) {
// Add a write lock to prevent other threads from reading and changing the cache
rw.writeLock().lock(); // Write lock
try {
// Update library first
int update = dao.update(sql, args);
// wipe cache
map.clear();
return update;
} finally {
rw.writeLock().unlock();
}
}
}
// As a key, it is immutable
@AllArgsConstructor
@EqualsAndHashCode
class SqlPair {
private final String sql;
private final Object[] args;
}
@Data
class Emp {
private int empno;
private String ename;
private String job;
private BigDecimal sal;
}
be careful
The above implementation reflects the application of read-write lock to ensure the consistency between cache and database, but the following problems are not considered
- It is suitable for more reading and less writing. If writing operations are frequent, the performance of the above implementation is low
- Cache capacity is not considered
- Cache expiration is not considered
- Only for single machine
- The concurrency is still low. At present, only one lock is used (for example, different locks are used for different database tables)
- The update method is too simple and crude, clearing all keys (consider partitioning by type or redesigning keys)
Optimistic lock implementation: update with CAS
*Read write lock principle
1. Graphic process
The read-write lock uses the same Sycn synchronizer, so the waiting queue and state are also the same
t1 w.lock,t2 r.lock
1) t1 locks successfully. The process is no different from ReentrantLock locking. The difference is that the write lock status accounts for the lower 16 bits of state, while the read lock uses the upper 16 bits of state
2) t2 execute r.lock. At this time, enter the sync.acquiresshared (1) process of lock reading. First, enter the tryacquisresshared process. If a write lock is occupied, tryAcquireShared returns - 1, indicating failure
The return value of tryAcquireShared indicates
- -1 means failure
- 0 indicates success, but subsequent nodes will not continue to wake up
- A positive number indicates success, and the value is that several subsequent nodes need to wake up, and the read-write lock returns 1
3) At this time, the sync.doAcquireShared(1) process will be entered. First, addWaiter is called to add the node. The difference is that the node is set to Node.SHARED mode instead of Node.EXCLUSIVE mode. Note that t2 is still active at this time
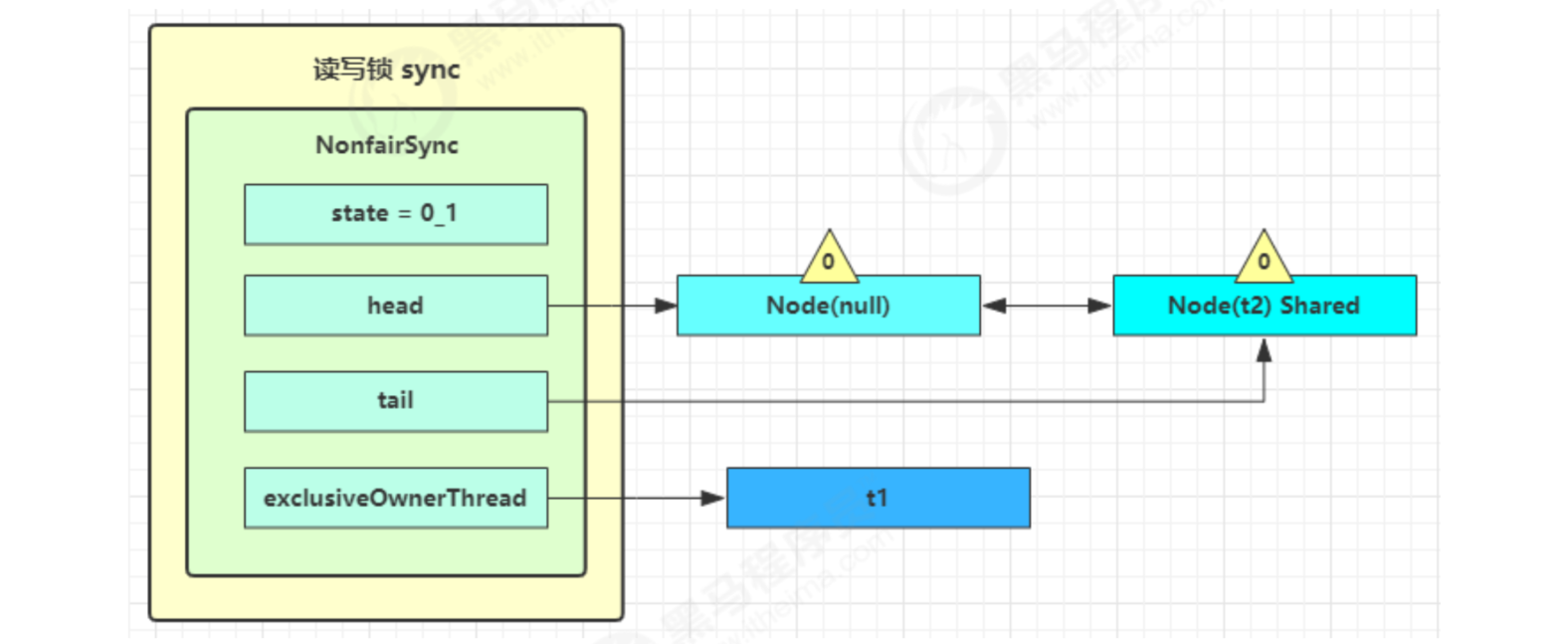
4) t2 will check whether its node is the second. If it is, it will call tryAcquireShared(1) again to try to obtain the lock
5) If it is not successful, cycle for (;;) in doAcquireShared, change the waitStatus of the precursor node to - 1, and then cycle for (;) to try tryAcquireShared(1). If it is not successful, park at parkAndCheckInterrupt()
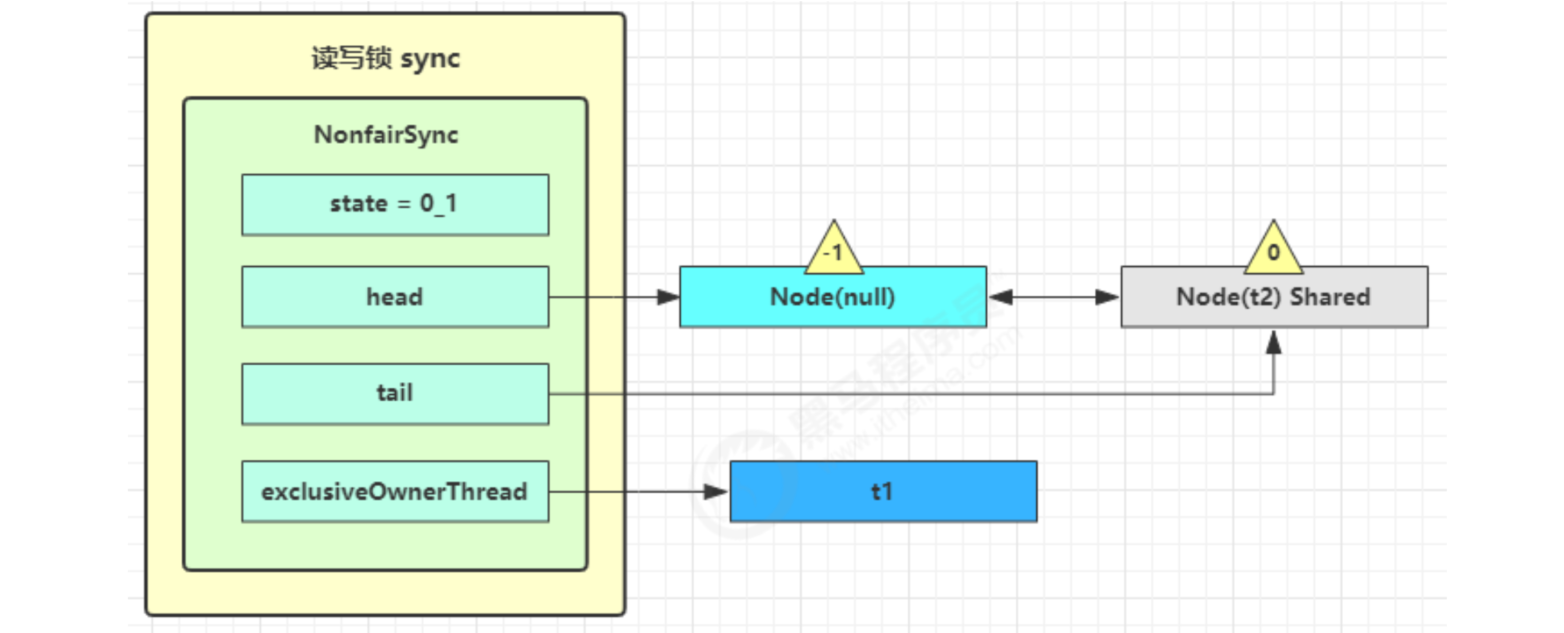
t3 r.lock,t4 w.lock
In this state, suppose t3 adds a read lock and t4 adds a write lock. During this period, t1 still holds the lock, which becomes the following
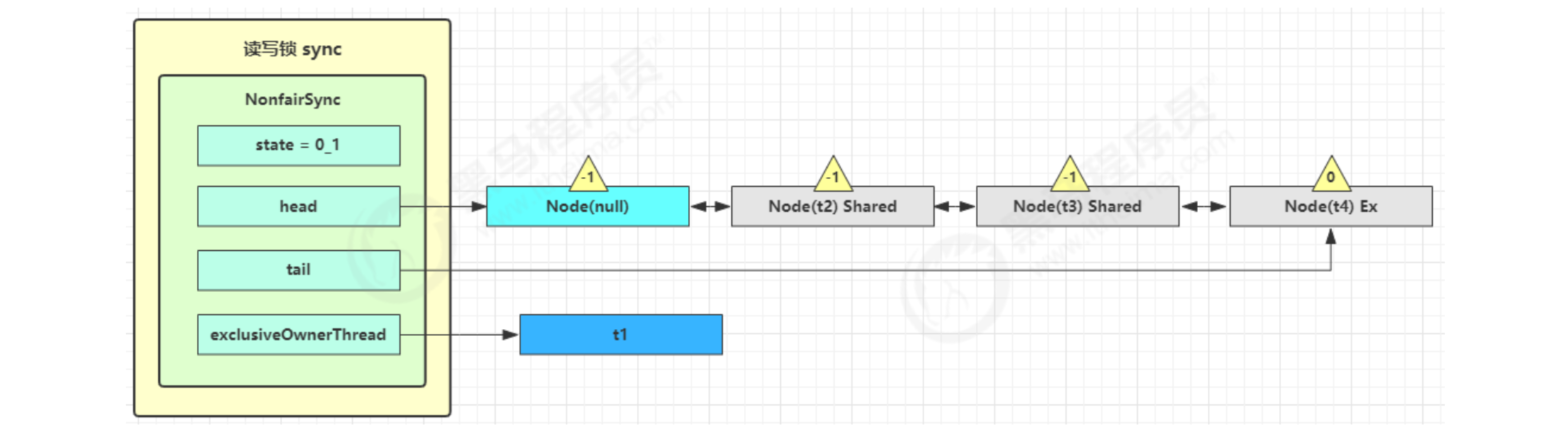
t1 w.unlock
At this time, you will go to the sync.release(1) process of writing locks, and call sync.tryRelease(1) successfully, as shown below
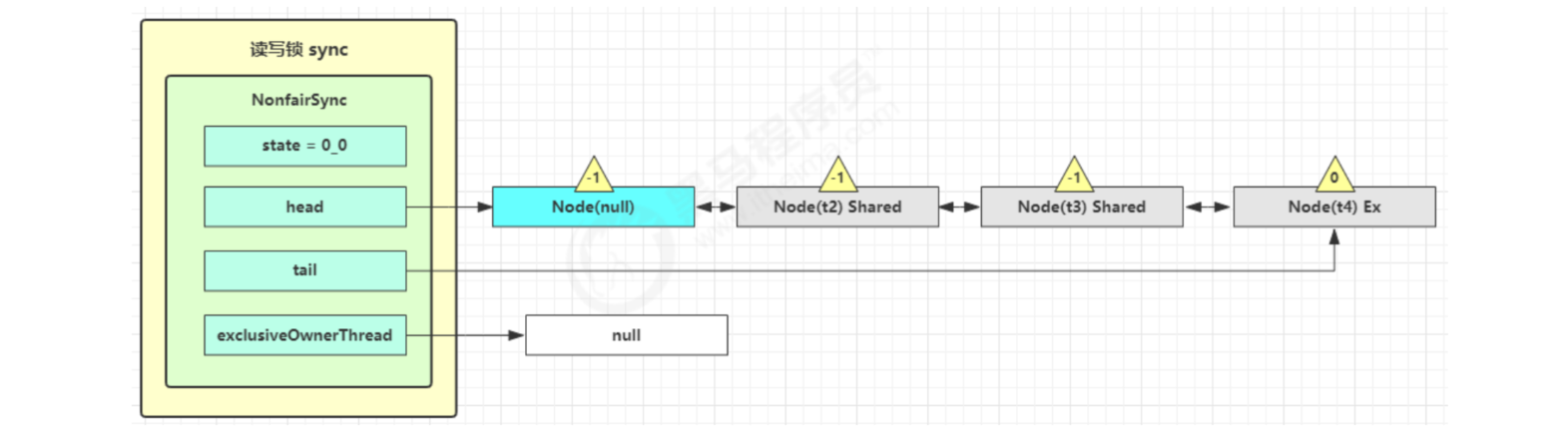
Next, execute the wake-up process sync.unparksuccess, that is, let the dick resume operation. At this time, t2 resumes operation at parkAndCheckInterrupt() in doAcquireShared
This time again, for (; 😉 If tryAcquireShared is executed successfully, the read lock count is incremented by one
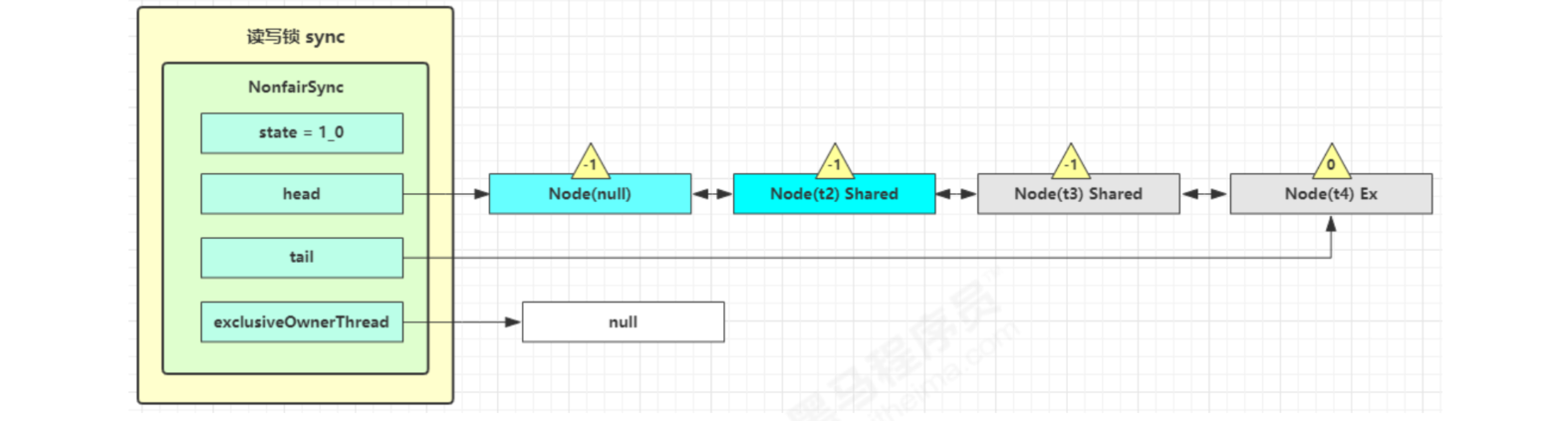
At this time, t2 has resumed operation. Next, t2 calls setHeadAndPropagate(node, 1), and its original node is set as the head node
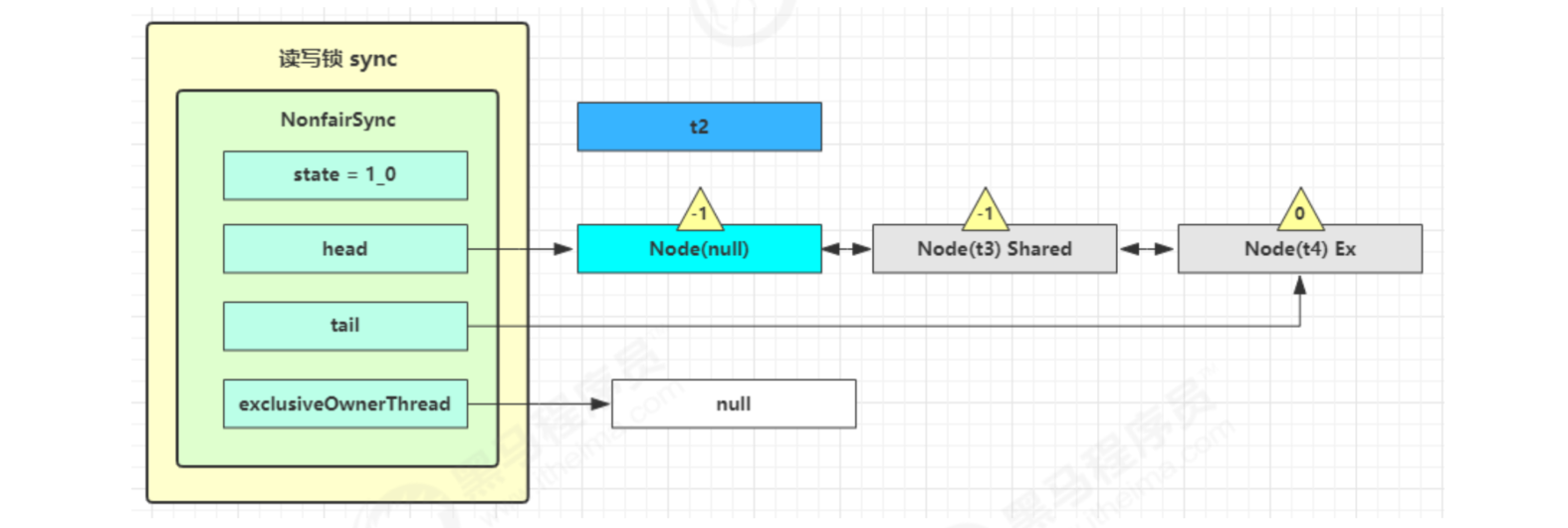
Before it's over, check whether the next node is shared in setHeadAndPropagate method. If so, call doReleaseShared() to change the state of head from - 1 to 0 and wake up the second. At this time, t3 resumes running at parkAndCheckInterrupt() in doacquishared
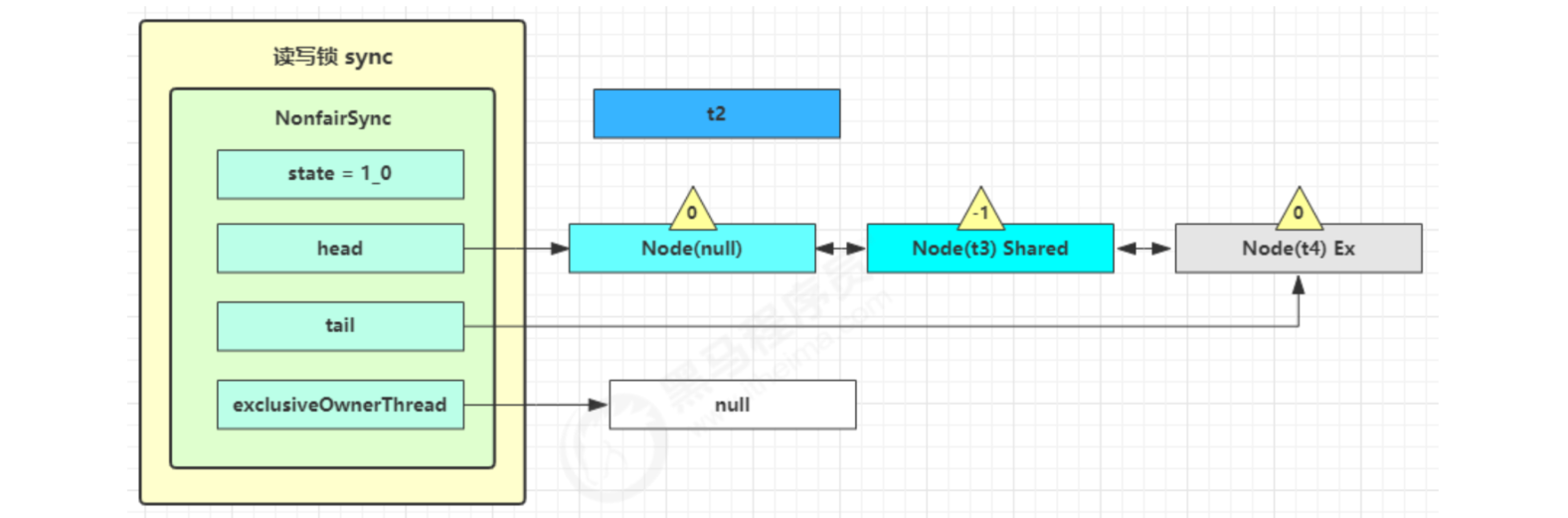
This time, for (;;) executes tryAcquireShared again. If it succeeds, the read lock count is incremented by one
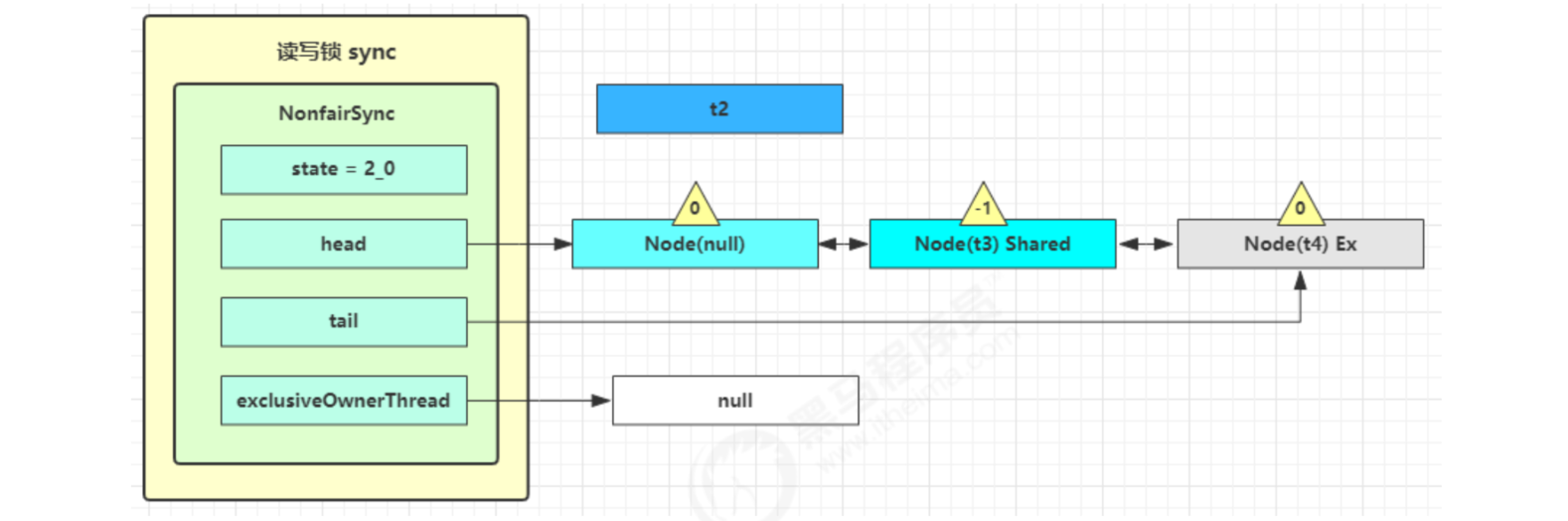
At this time, t3 has resumed operation. Next, t3 calls setHeadAndPropagate(node, 1), and its original node is set as the head node
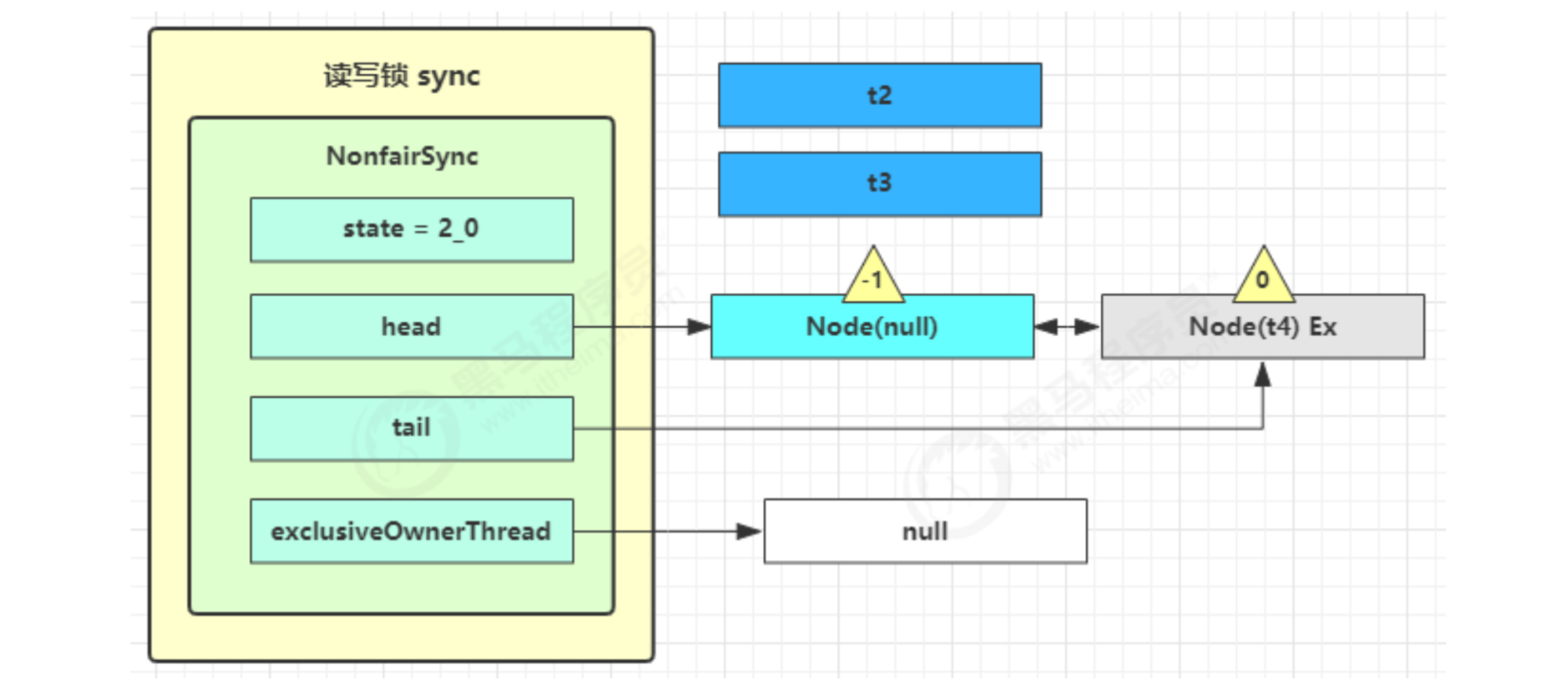
The next node is not shared, so it will not continue to wake up t4
t2 r.unlock,t3 r.unlock
t2 enters sync.releaseShared(1) and calls tryReleaseShared(1) to reduce the count by one, but the count is not zero.
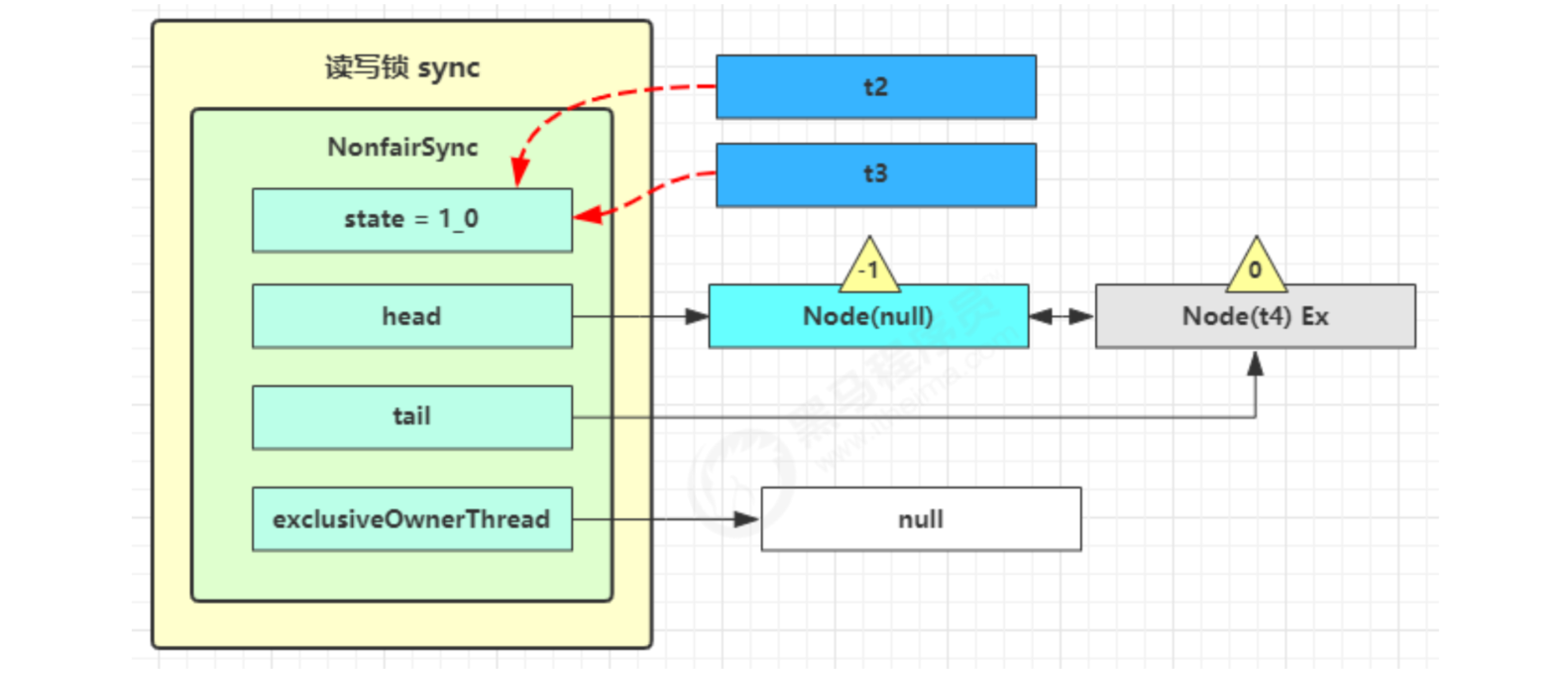
t3 enters sync.releaseShared(1), calls tryReleaseShared(1) to reduce count, this time count is zero, enters doReleaseShared(), changes the header node from -1 to 0, and wakes up the second.
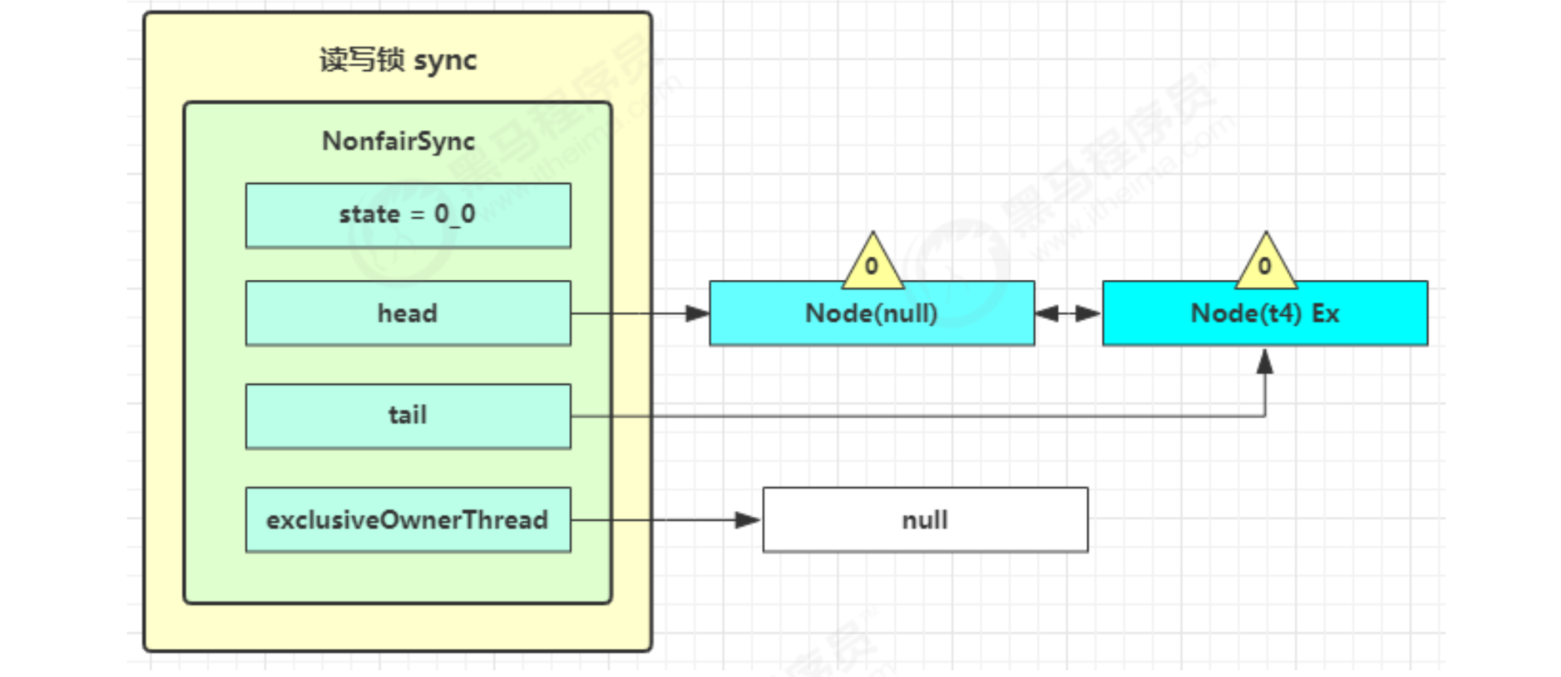
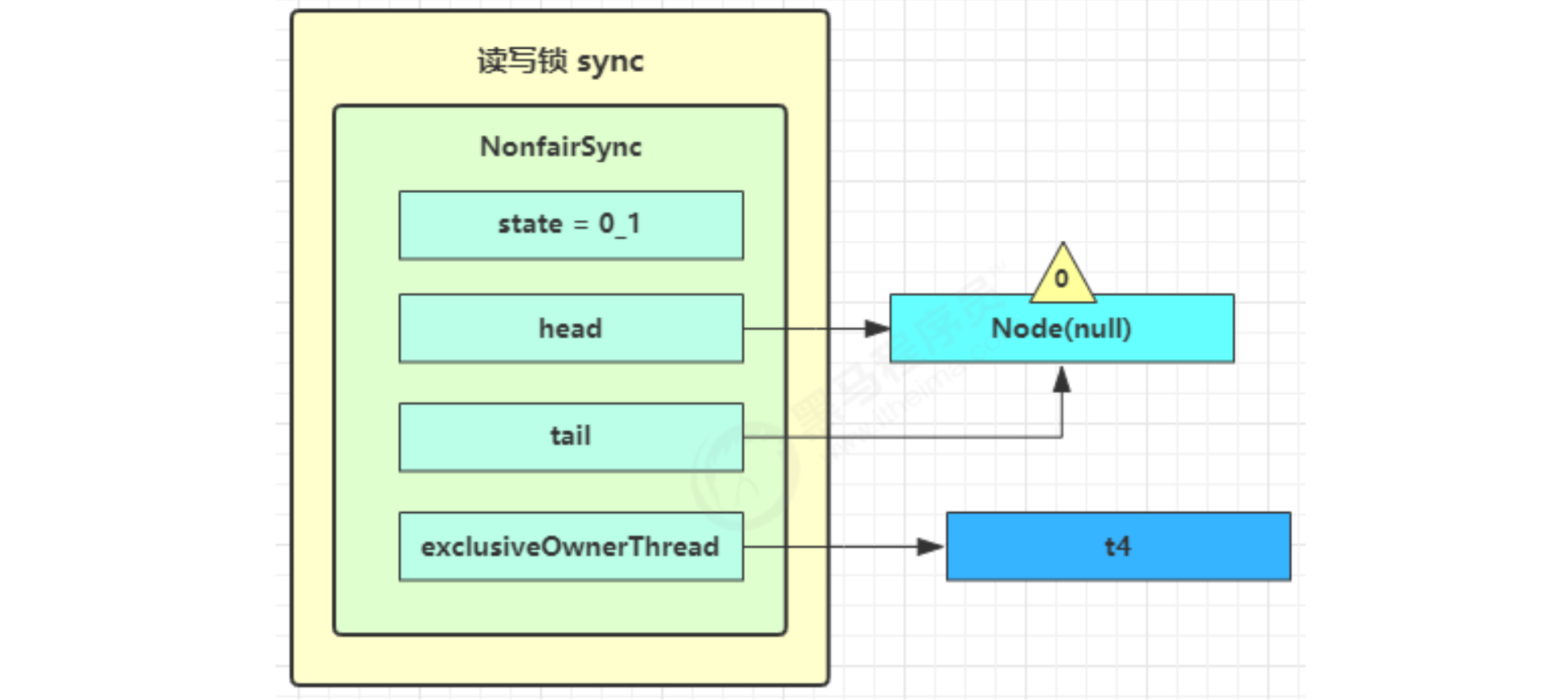
Then t4 resume running at parkAndCheckInterrupt in acquirequeueueued, and for() again; 😉 This time, you are the second and there is no other competition. tryAcquire(1) succeeds. Modify the header node and the process ends
2. Source code analysis
Write lock locking process
static final class NonfairSync extends Sync {
// ... omit irrelevant code
// The external class WriteLock method is easy to read and placed here
public void lock() {
sync.acquire(1);
}
// The method inherited from AQS is easy to read and placed here
public final void acquire(int arg) {
if (
// The attempt to obtain a write lock failed
!tryAcquire(arg) &&
// Associate the current thread to a Node object in exclusive mode
// Access to AQS queue blocked
acquireQueued(addWaiter(Node.EXCLUSIVE), arg)
) {
selfInterrupt();
}
}
// Sync inherited method, easy to read, put here
protected final boolean tryAcquire(int acquires) {
// Get the low 16 bits, representing the state count of the write lock
Thread current = Thread.currentThread();
int c = getState();
int w = exclusiveCount(c);
if (c != 0) {
if (
// C! = 0 and w = = 0 indicates that there is a read lock, or
w == 0 ||
// If exclusiveOwnerThread is not your own
current != getExclusiveOwnerThread()
) {
// Failed to acquire lock
return false;
}
// If the write lock count exceeds the lower 16 bits, an exception is reported
if (w + exclusiveCount(acquires) > MAX_COUNT)
throw new Error("Maximum lock count exceeded");
// Write lock reentry to obtain lock successfully
setState(c + acquires);
return true;
}
if (
// Determine whether the write lock should be blocked, or
writerShouldBlock() ||
// The attempt to change the count failed
!compareAndSetState(c, c + acquires)
) {
// Failed to acquire lock
return false;
}
// Lock obtained successfully
setExclusiveOwnerThread(current);
return true;
}
// Non fair lock writerShouldBlock always returns false without blocking
final boolean writerShouldBlock() {
return false;
}
}
Write lock release process
static final class NonfairSync extends Sync {
// ... omit irrelevant code
// WriteLock method, easy to read, put here
public void unlock() {
sync.release(1);
}
// The method inherited from AQS is easy to read and placed here
public final boolean release(int arg) {
// The attempt to release the write lock succeeded
if (tryRelease(arg)) {
// Unpark thread waiting in AQS
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
// Sync inherited method, easy to read, put here
protected final boolean tryRelease(int releases) {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
int nextc = getState() - releases;
// For reentrant reasons, the release is successful only when the write lock count is 0
boolean free = exclusiveCount(nextc) == 0;
if (free) {
setExclusiveOwnerThread(null);
}
setState(nextc);
return free;
}
}
Lock reading and locking process
static final class NonfairSync extends Sync {
// ReadLock method, easy to read, put here
public void lock() {
sync.acquireShared(1);
}
// The method inherited from AQS is easy to read and placed here
public final void acquireShared(int arg) {
// tryAcquireShared returns a negative number, indicating that the acquisition of read lock failed
if (tryAcquireShared(arg) < 0) {
doAcquireShared(arg);
}
}
// Sync inherited method, easy to read, put here
protected final int tryAcquireShared(int unused) {
Thread current = Thread.currentThread();
int c = getState();
// If another thread holds a write lock, obtaining a read lock fails
if (
exclusiveCount(c) != 0 &&
getExclusiveOwnerThread() != current
) {
return -1;
}
int r = sharedCount(c);
if (
// The read lock should not be blocked (if the second is a write lock, the read lock should be blocked), and
!readerShouldBlock() &&
// Less than the read lock count, and
r < MAX_COUNT &&
// Attempt to increase count succeeded
compareAndSetState(c, c + SHARED_UNIT)
) {
// ... omit unimportant code
return 1;
}
return fullTryAcquireShared(current);
}
// The unfair lock readerShouldBlock determines whether the first node in the AQS queue is a write lock
// true to block, false not to block
final boolean readerShouldBlock() {
return apparentlyFirstQueuedIsExclusive();
}
// The method inherited from AQS is easy to read and placed here
// The function is similar to tryAcquireShared, but it will keep trying for (;;) to obtain the read lock without blocking during execution
final int fullTryAcquireShared(Thread current) {
HoldCounter rh = null;
for (; ; ) {
int c = getState();
if (exclusiveCount(c) != 0) {
if (getExclusiveOwnerThread() != current)
return -1;
} else if (readerShouldBlock()) {
// ... omit unimportant code
}
if (sharedCount(c) == MAX_COUNT)
throw new Error("Maximum lock count exceeded");
if (compareAndSetState(c, c + SHARED_UNIT)) {
// ... omit unimportant code
return 1;
}
}
}
// The method inherited from AQS is easy to read and placed here
private void doAcquireShared(int arg) {
// Associate the current thread to a Node object. The mode is shared mode
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
boolean interrupted = false;
for (; ; ) {
final Node p = node.predecessor();
if (p == head) {
// Try to acquire the read lock again
int r = tryAcquireShared(arg);
// success
if (r >= 0) {
// ㈠
// r represents the number of available resources, where 1 is always allowed to propagate
//(wake up the next Share node in AQS)
setHeadAndPropagate(node, r);
p.next = null; // help GC
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
if (
// Whether to block when acquiring read lock fails (waitStatus == Node.SIGNAL in the previous stage)
shouldParkAfterFailedAcquire(p, node) &&
// park current thread
parkAndCheckInterrupt()
) {
interrupted = true;
}
}
} finally {
if (failed)
cancelAcquire(node);
}
}
// A method inherited from AQS, which is easy to read, is placed here
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head; // Record old head for check below
// Set yourself to head
setHead(node);
// propagate indicates that there are shared resources (such as shared read locks or semaphores)
// Original head waitStatus == Node.SIGNAL or Node.PROPAGATE
// Now head waitStatus == Node.SIGNAL or Node.PROPAGATE
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
// If it is the last node or the node waiting to share the read lock
if (s == null || s.isShared()) {
// Enter two
doReleaseShared();
}
}
}
// II. The method inherited from AQS is easy to read and placed here
private void doReleaseShared() {
// If head.waitstatus = = node. Signal = = > 0 succeeds, the next node is unpark
// If head.waitstatus = = 0 = = > node.propagate, to solve the bug, see the following analysis
for (; ; ) {
Node h = head;
// Queue and node
if (h != null && h != tail) {
int ws = h.waitStatus;
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
// If the next node unpark successfully obtains the read lock
// And the next node is still shared. Continue to do releaseshared
unparkSuccessor(h);
} else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
if (h == head) // loop if head changed
break;
}
}
}
Read lock release process
static final class NonfairSync extends Sync {
// ReadLock method, easy to read, put here
public void unlock() {
sync.releaseShared(1);
}
// The method inherited from AQS is easy to read and placed here
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
// Sync inherited method, easy to read, put here
protected final boolean tryReleaseShared(int unused) {
// ... omit unimportant code
for (; ; ) {
int c = getState();
int nextc = c - SHARED_UNIT;
if (compareAndSetState(c, nextc)) {
// The count of read locks will not affect other threads that acquire read locks, but will affect other threads that acquire write locks
// A count of 0 is the true release
return nextc == 0;
}
}
}
// The method inherited from AQS is easy to read and placed here
private void doReleaseShared() {
// If head.waitstatus = = node. Signal = = > 0 succeeds, the next node is unpark
// If head.waitstatus = = 0 = = > node.propagate
for (; ; ) {
Node h = head;
if (h != null && h != tail) {
int ws = h.waitStatus;
// If other threads are also releasing the read lock, you need to change the waitStatus to 0 first
// Prevent unparksuccess from being executed multiple times
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
unparkSuccessor(h);
}
// If it is already 0, change it to - 3 to solve the propagation. See semaphore bug analysis later
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
if (h == head) // loop if head changed
break;
}
}
}
3.2 StampedLock
This class is added from JDK 8 to further optimize the read performance. Its feature is that it must be used with the [stamp] when using the read lock and write lock
Add interpretation lock
long stamp = lock.readLock(); lock.unlockRead(stamp);
Add / remove write lock
long stamp = lock.writeLock(); lock.unlockWrite(stamp);
Optimistic reading. StampedLock supports the tryOptimisticRead() method (happy reading). After reading, a stamp verification needs to be done. If the verification passes, it means that there is no write operation during this period and the data can be used safely. If the verification fails, the read lock needs to be obtained again to ensure data security.
long stamp = lock.tryOptimisticRead();
// Check stamp
if(!lock.validate(stamp)){
// Lock upgrade
}
A data container class is provided, which uses the read() method for reading lock protection data and the write() method for writing lock protection data
@Slf4j(topic = "c.DataContainerStamped")
class DataContainerStamped {
private int data;
private final StampedLock lock = new StampedLock();
public DataContainerStamped(int data) {
this.data = data;
}
public int read(int readTime) {
long stamp = lock.tryOptimisticRead(); // Optimistic reading
log.debug("optimistic read locking...{}", stamp);
try {
TimeUnit.SECONDS.sleep(readTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (lock.validate(stamp)) {
log.debug("read finish...{}, data:{}", stamp, data);
return data;
}
// Lock upgrade - read lock
log.debug("updating to read lock... {}", stamp);
try {
stamp = lock.readLock(); // Read lock
log.debug("read lock {}", stamp);
try {
TimeUnit.SECONDS.sleep(readTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("read finish...{}, data:{}", stamp, data);
return data;
} finally {
log.debug("read unlock {}", stamp);
lock.unlockRead(stamp);
}
}
public void write(int newData) {
long stamp = lock.writeLock(); // Write lock
log.debug("write lock {}", stamp);
try {
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
this.data = newData;
} finally {
log.debug("write unlock {}", stamp);
lock.unlockWrite(stamp);
}
}
}
Test read can be optimized
@Slf4j(topic = "c.TestStampedLock")
public class TestStampedLock {
public static void main(String[] args) {
DataContainerStamped dataContainer = new DataContainerStamped(1);
new Thread(() -> {
dataContainer.read(1);
}, "t1").start();
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
new Thread(() -> {
dataContainer.read(0);
}, "t2").start();
}
}
The output result shows that there is no read lock

Optimize read complement and add read lock during test read-write
@Slf4j(topic = "c.TestStampedLock")
public class TestStampedLock {
public static void main(String[] args) {
DataContainerStamped dataContainer = new DataContainerStamped(1);
new Thread(() -> {
dataContainer.read(1);
}, "t1").start();
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
new Thread(() -> {
// dataContainer.read(0);
dataContainer.write(100);
}, "t2").start();
}
}
Output results

be careful
- StampedLock does not support conditional variables
- StampedLock does not support reentry
4. Semaphore
Basic use
[ ˈ s ɛ m əˌ f ɔ r] Semaphore used to limit the maximum number of threads that can access shared resources at the same time.
package top.onefine.test.c8;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.Semaphore;
import java.util.concurrent.TimeUnit;
@Slf4j(topic = "c.TestSemaphore")
public class TestSemaphore {
public static void main(String[] args) {
// 1. Create a semaphore object
Semaphore semaphore = new Semaphore(3); // The upper limit is 3
// 2. 10 threads running at the same time
for (int i = 0; i < 10; i++) {
new Thread(() -> {
// 3. Obtaining permits
try {
semaphore.acquire(); // Get this semaphore
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
log.debug("running...");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("end...");
} finally {
// 4. Release permit
semaphore.release(); // Release semaphore
}
}).start();
}
}
}
output
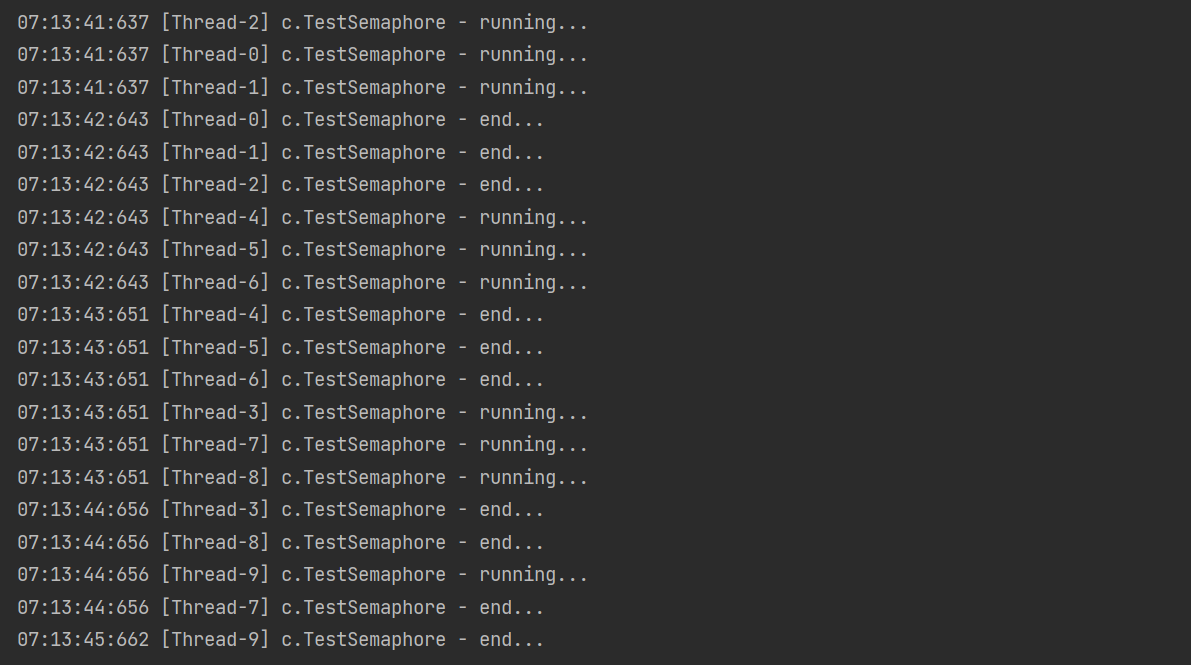
*Semaphore application – restrict the use of shared resources
- Using Semaphore flow restriction, the requesting thread is blocked during the peak period, and the license is released after the peak period. Of course, it is only suitable for limiting the number of stand-alone threads, and only the number of threads, not the number of resources (for example, the number of connections, please compare the implementation of Tomcat LimitLatch)
- The implementation of simple connection pool with Semaphore has better performance and readability than the implementation under "meta sharing mode" (using wait notify). Note that the number of threads and database connections in the following implementation are equal
package top.onefine.test.c8;
import lombok.AllArgsConstructor;
import lombok.ToString;
import lombok.extern.slf4j.Slf4j;
import java.sql.*;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.Executor;
import java.util.concurrent.Semaphore;
import java.util.concurrent.atomic.AtomicIntegerArray;
@Slf4j(topic = "c.TestPoolSemaphore")
public class TestPoolSemaphore {
// 1. Connection pool size
private final int poolSize;
// 2. Connection object array
private Connection[] connections;
// 3. The connection status array 0 indicates idle and 1 indicates busy
private AtomicIntegerArray states;
private Semaphore semaphore;
// 4. Initialization of construction method
public TestPoolSemaphore(int poolSize) {
this.poolSize = poolSize;
// Make the number of licenses consistent with the number of resources
this.semaphore = new Semaphore(poolSize);
this.connections = new Connection[poolSize];
this.states = new AtomicIntegerArray(new int[poolSize]);
for (int i = 0; i < poolSize; i++) {
connections[i] = new MockConnection2("connect" + (i + 1));
}
}
// 5. Borrow connection
public Connection borrow() {// t1, t2, t3
// Get permission
try {
semaphore.acquire(); // Thread without permission, wait here
} catch (InterruptedException e) {
e.printStackTrace();
}
for (int i = 0; i < poolSize; i++) {
// Get idle connection
if (states.get(i) == 0) {
if (states.compareAndSet(i, 0, 1)) {
log.debug("borrow {}", connections[i]);
return connections[i];
}
}
}
// Will not be executed here
return null;
}
// 6. Return the connection
public void free(Connection conn) {
for (int i = 0; i < poolSize; i++) {
if (connections[i] == conn) {
states.set(i, 0);
log.debug("free {}", conn);
semaphore.release(); // Release semaphore
break;
}
}
}
}
@AllArgsConstructor
@ToString
class MockConnection2 implements Connection {
private final String name;
// The following code ignores
// ...
}
*Semaphore principle
1. Lock and unlock process
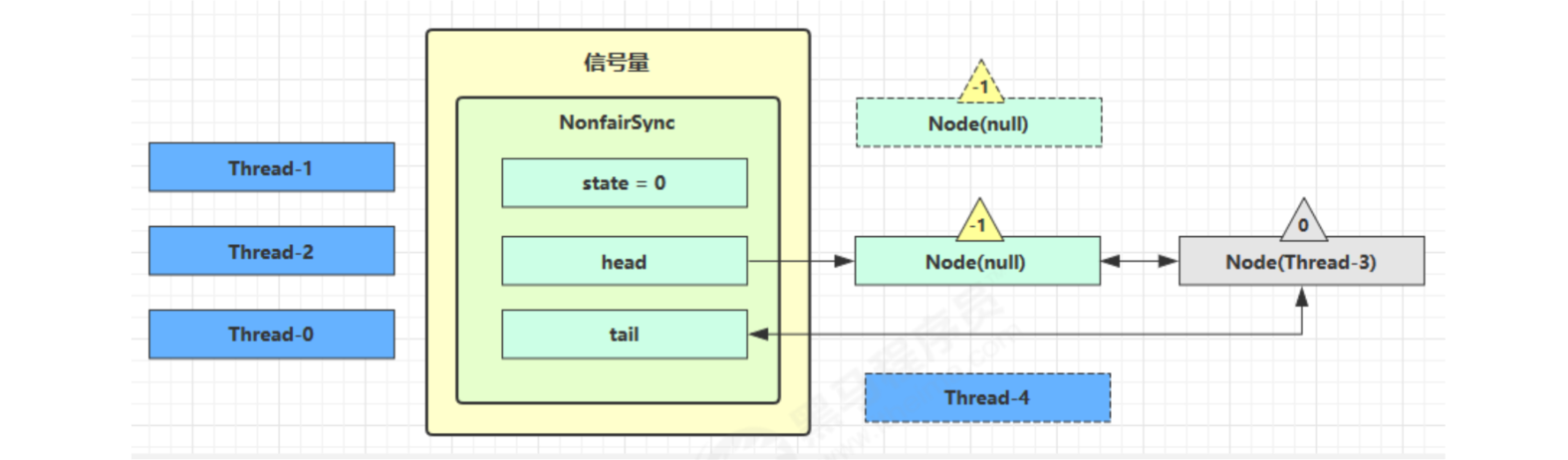
Semaphore is a bit like a parking lot. Permissions is like the number of parking spaces. When the thread obtains permissions, it is like obtaining parking spaces, and then the parking lot displays the empty parking spaces minus one.
At first, the permissions (state) is 3. At this time, there are five threads to obtain resources
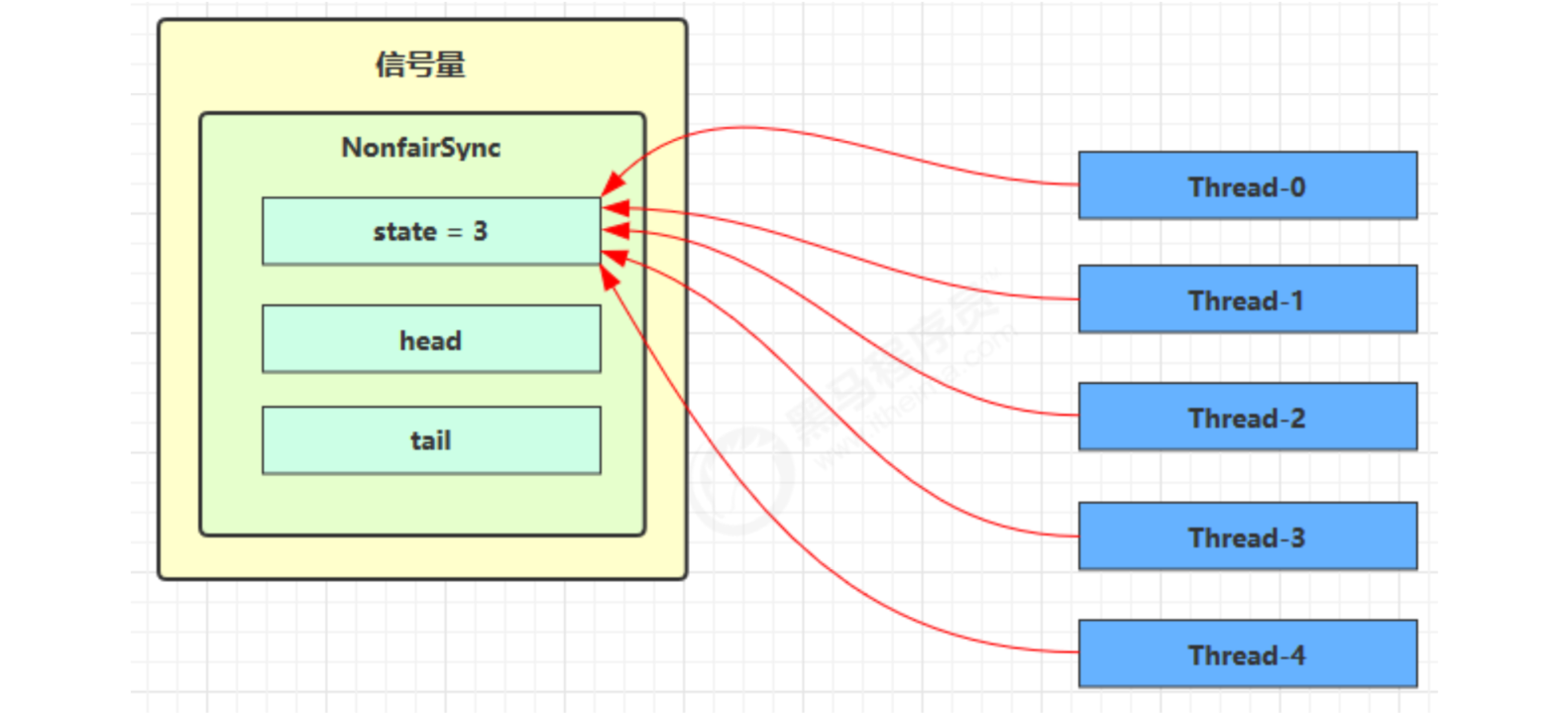
Suppose that Thread-1, Thread-2 and Thread-4 cas compete successfully, while Thread-0 and Thread-3 compete failed, and enter the AQS queue park to block
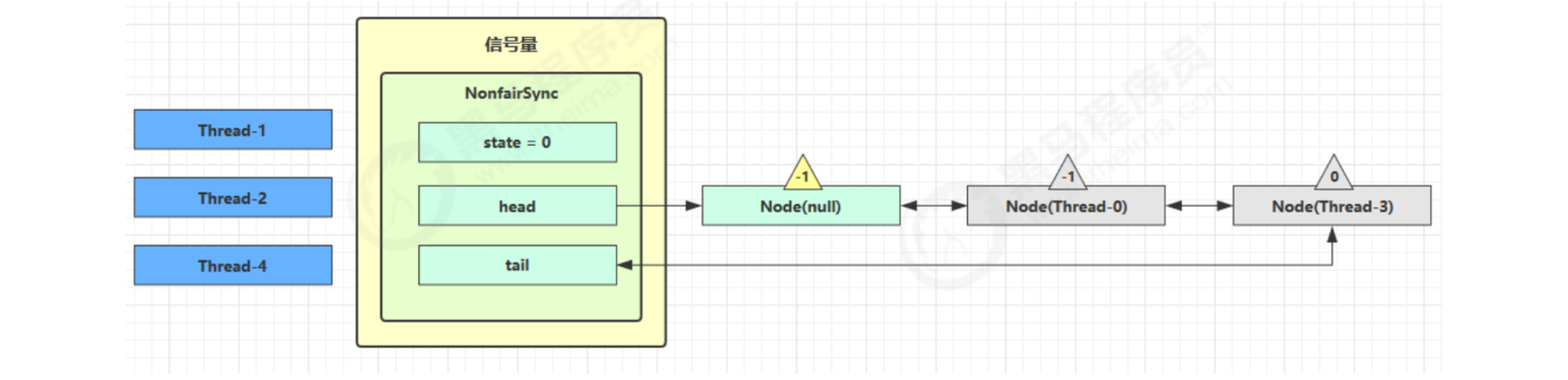
At this time, Thread-4 releases permissions, and the status is as follows
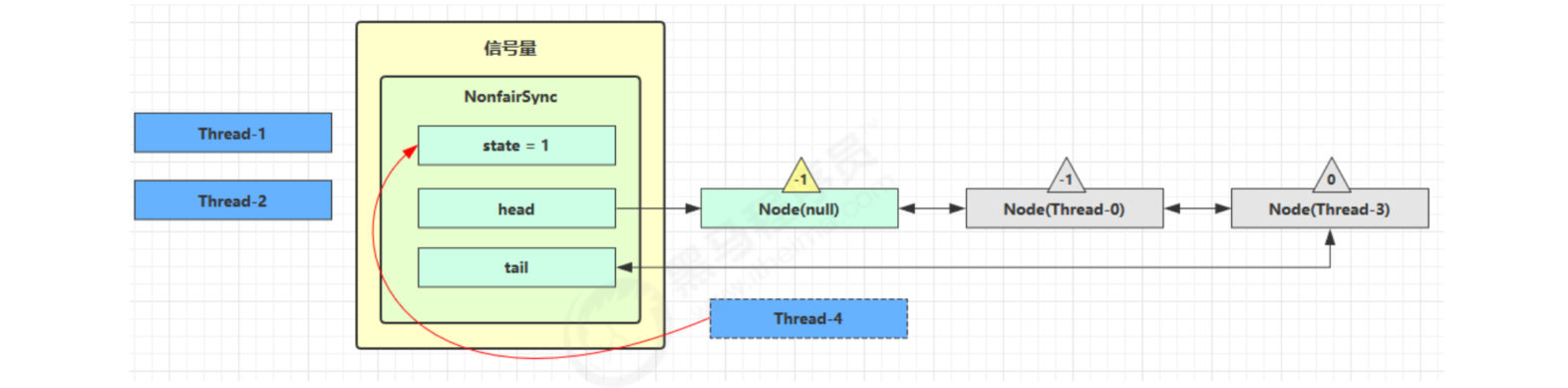
Next, the Thread-0 competition succeeds. The permissions are set to 0 again. Set yourself as the head node. Disconnect the original head node and unpark the next Thread-3 node. However, since the permissions are 0, Thread-3 enters the park state again after unsuccessful attempts
2. Source code analysis
static final class NonfairSync extends Sync {
private static final long serialVersionUID = -2694183684443567898L;
NonfairSync(int permits) {
// permits is state
super(permits);
}
// Semaphore method, easy to read, put here
public void acquire() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
// The method inherited from AQS is easy to read and placed here
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (tryAcquireShared(arg) < 0)
doAcquireSharedInterruptibly(arg);
}
// Trying to get a shared lock
protected int tryAcquireShared(int acquires) {
return nonfairTryAcquireShared(acquires);
}
// Sync inherited method, easy to read, put here
final int nonfairTryAcquireShared(int acquires) {
for (; ; ) {
int available = getState();
int remaining = available - acquires;
if (
// If the license has been used up, a negative number is returned, indicating that the acquisition failed. Enter doacquisuresharedinterruptible
remaining < 0 ||
// If cas retries successfully, a positive number is returned, indicating success
compareAndSetState(available, remaining)
) {
return remaining;
}
}
}
// The method inherited from AQS is easy to read and placed here
private void doAcquireSharedInterruptibly(int arg) throws InterruptedException {
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
for (; ; ) {
final Node p = node.predecessor();
if (p == head) {
// Try obtaining the license again
int r = tryAcquireShared(arg);
if (r >= 0) {
// After success, the thread goes out of the queue (AQS) and the Node is set to head
// If head.waitstatus = = node. Signal = = > 0 succeeds, the next node is unpark
// If head.waitstatus = = 0 = = > node.propagate
// r indicates the number of available resources. If it is 0, it will not continue to propagate
setHeadAndPropagate(node, r);
p.next = null; // help GC
failed = false;
return;
}
}
// Unsuccessful, set the previous node waitStatus = Node.SIGNAL, and the next round enters park blocking
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
// Semaphore method, easy to read, put here
public void release() {
sync.releaseShared(1);
}
// The method inherited from AQS is easy to read and placed here
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
// Sync inherited method, easy to read, put here
protected final boolean tryReleaseShared(int releases) {
for (; ; ) {
int current = getState();
int next = current + releases;
if (next < current) // overflow
throw new Error("Maximum permit count exceeded");
if (compareAndSetState(current, next))
return true;
}
}
}
3. Why is there PROPAGATE
Early bug
- releaseShared method
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
- doAcquireShared method
private void doAcquireShared(int arg) {
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
boolean interrupted = false;
for (; ; ) {
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0) {
// There will be a gap here
setHeadAndPropagate(node, r);
p.next = null; // help GC
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt()) interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
- setHeadAndPropagate method
private void setHeadAndPropagate(Node node, int propagate) {
setHead(node);
// There are free resources
if (propagate > 0 && node.waitStatus != 0) {
Node s = node.next;
// next
if (s == null || s.isShared())
unparkSuccessor(node);
}
}
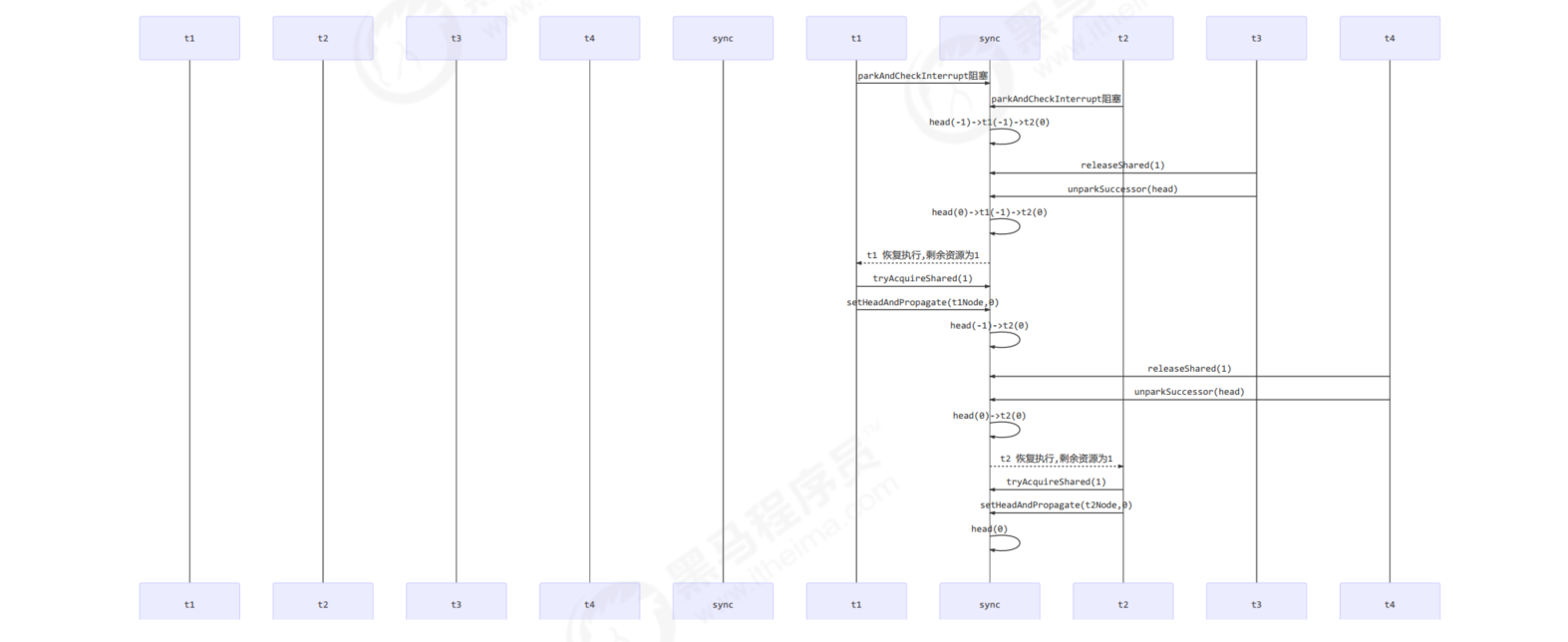
- Suppose there are nodes queued in the queue in a cycle, which is head (- 1) - > T1 (- 1) - > T2 (- 1)
- It is assumed that there are T3 and T4 semaphores to be released, and the release order is T3 first and then T4
Normal process
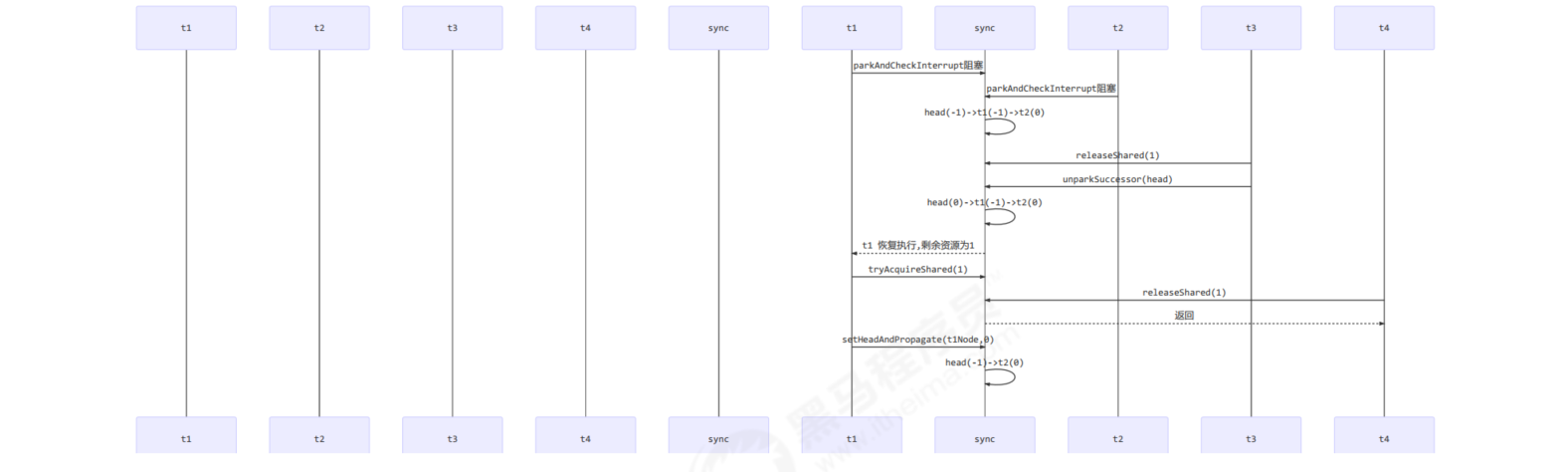
bug generation
Implementation process of version before repair
- T3 calls releaseShared(1) and directly calls unparksuccess (head). The waiting state of head changes from - 1 to 0
- T1 is awakened due to the T3 release semaphore, and calls tryAcquireShared. It is assumed that the return value is 0 (lock acquisition is successful, but there is no remaining resource)
- T4 calls releaseShared(1). At this time, the head.waitStatus is 0 (the read head and 1 are the same head), which does not meet the conditions. Therefore, unparksuccess (head) is not called
- T1 gets the semaphore successfully. When calling setHeadAndPropagate, because the return value of propagate > 0 (that is, propagate (remaining resources) = = 0) is not satisfied, the subsequent node will not wake up, and T2 thread cannot wake up
After bug repair
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head; // Record old head for check below
// Set yourself to head
setHead(node);
// propagate indicates that there are shared resources (such as shared read locks or semaphores)
// Original head waitStatus == Node.SIGNAL or Node.PROPAGATE
// Now head waitStatus == Node.SIGNAL or Node.PROPAGATE
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
// If it is the last node or the node waiting to share the read lock
if (s == null || s.isShared()) {
doReleaseShared();
}
}
}
private void doReleaseShared() {
// If head.waitstatus = = node. Signal = = > 0 succeeds, the next node is unpark
// If head.waitstatus = = 0 = = > node.propagate
for (; ; ) {
Node h = head;
if (h != null && h != tail) {
int ws = h.waitStatus;
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
unparkSuccessor(h);
} else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
if (h == head) // loop if head changed
break;
}
}
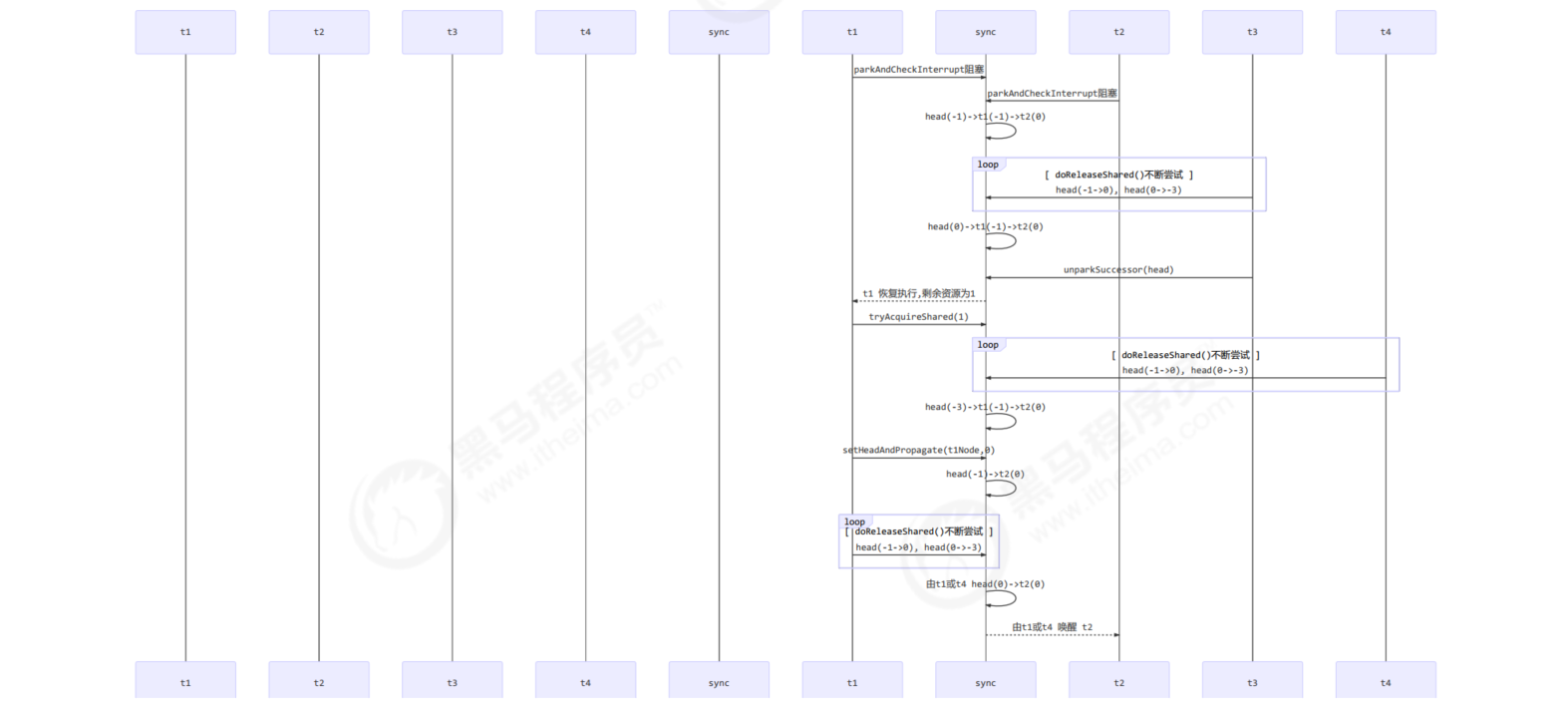
- T3 called releaseShared(), directly called unparksuccess (head), and the waiting state of head changed from - 1 to 0
- T1 is awakened due to the T3 release semaphore, and calls tryAcquireShared. It is assumed that the return value is 0 (lock acquisition is successful, but there is no remaining resource)
- T4 calls releaseShared(), and the head.waitStatus is 0 (the read head and 1 are the same head at this time), and calls doReleaseShared() to set the waiting state to PROPAGATE (- 3)
- T1 acquires semaphore successfully. When calling setHeadAndPropagate, it reads that h.waitstatus < 0, so it calls doReleaseShared() to wake up T2
5. CountdownLatch
Used for thread synchronization and cooperation, waiting for all threads to complete the countdown.
The construction parameter is used to initialize the waiting count value, await() is used to wait for the count to return to zero, and countDown() is used to reduce the count by one
package top.onefine.test.c8;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
@Slf4j(topic = "c.TestCountDownLatch")
public class TestCountDownLatch {
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(3);
new Thread(() -> {
log.debug("begin...");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
latch.countDown();
log.debug("end...{}", latch.getCount());
}).start();
new Thread(() -> {
log.debug("begin...");
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
latch.countDown();
log.debug("end...{}", latch.getCount());
}).start();
new Thread(() -> {
log.debug("begin...");
try {
TimeUnit.MILLISECONDS.sleep(1500);
} catch (InterruptedException e) {
e.printStackTrace();
}
latch.countDown();
log.debug("end...{}", latch.getCount());
}).start();
log.debug("waiting...");
latch.await();
log.debug("wait end...");
}
}
output
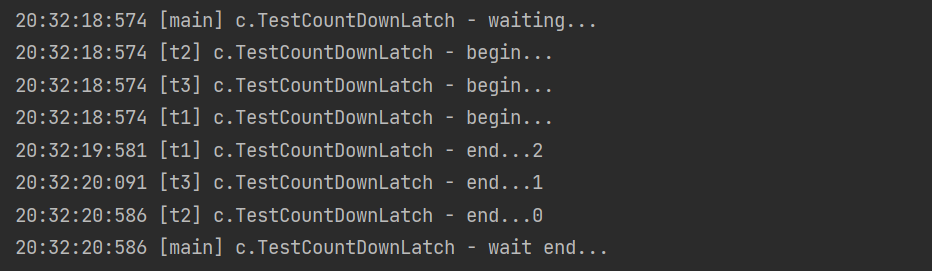
It can be used with thread pool. The improvements are as follows
package top.onefine.test.c8;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
@Slf4j(topic = "c.TestCountDownLatch2")
public class TestCountDownLatch2 {
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(3);
ExecutorService service = Executors.newFixedThreadPool(4);
service.submit(() -> {
log.debug("begin...");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
latch.countDown();
log.debug("end...{}", latch.getCount());
});
service.submit(() -> {
log.debug("begin...");
try {
TimeUnit.MILLISECONDS.sleep(1500);
} catch (InterruptedException e) {
e.printStackTrace();
}
latch.countDown();
log.debug("end...{}", latch.getCount());
});
service.submit(() -> {
log.debug("begin...");
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
latch.countDown();
log.debug("end...{}", latch.getCount());
});
service.submit(() -> {
try {
log.debug("waiting...");
latch.await();
log.debug("wait end...");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
}
output
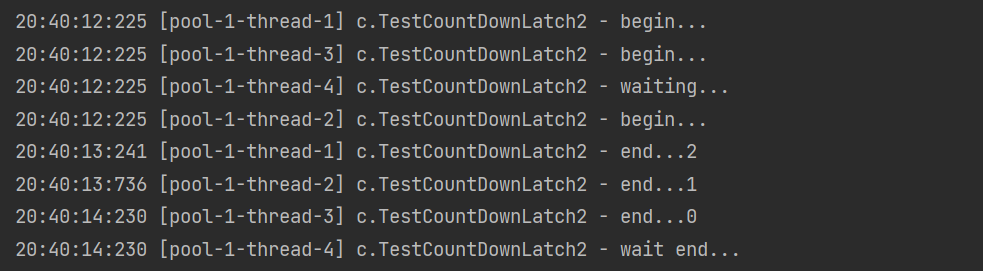
*Application synchronization waits for multithreading to be ready
package top.onefine.test.c8;
import lombok.extern.slf4j.Slf4j;
import java.util.Arrays;
import java.util.Random;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.AtomicInteger;
@Slf4j(topic = "c.TestCountDownLatch3")
public class TestCountDownLatch3 {
public static void main(String[] args) throws InterruptedException {
// AtomicInteger num = new AtomicInteger(0);
// ExecutorService service = Executors.newFixedThreadPool(10
// , r -> new Thread(r, "t" + num.getAndIncrement()));
ExecutorService service = Executors.newFixedThreadPool(10);
CountDownLatch latch = new CountDownLatch(10);
String[] all = new String[10]; // Loading results
Random r = new Random();
for (int j = 0; j < 10; j++) {
int x = j;
service.submit(() -> {
for (int i = 0; i <= 100; i++) {
try {
Thread.sleep(r.nextInt(100));
} catch (InterruptedException e) {
e.printStackTrace();
}
// all[x] = Thread.currentThread().getName() + "(" + (i + "%") + ")";
all[x] = i + "%";
System.out.print("\r" + Arrays.toString(all)); // Do not wrap lines, and each time you print, go back to the beginning of the line
}
latch.countDown();
});
}
latch.await();
System.out.println("\n The game begins...");
service.shutdown();
}
}
Intermediate output

Final output

*Application synchronization waits for multiple remote calls to end
No result returned - CountDownLatch:
package top.onefine.test.c8;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.*;
@Slf4j(topic = "c.TestCountDownLatch4")
public class TestCountDownLatch4 {
public static void main(String[] args) throws InterruptedException, ExecutionException {
log.debug("begin");
ExecutorService service = Executors.newCachedThreadPool();
CountDownLatch latch = new CountDownLatch(4);
MockController1 mockController = new MockController1();
service.submit(() -> {
try {
String r = mockController.request1(111);
log.debug("req1: {}", r);
} finally {
latch.countDown();
}
});
service.submit(() -> {
try {
String r = mockController.request2(222);
log.debug("req2: {}", r);
} finally {
latch.countDown();
}
});
service.submit(() -> {
try {
String r = mockController.request2(2020);
log.debug("req3: {}", r);
} finally {
latch.countDown();
}
});
service.submit(() -> {
try {
String r = mockController.request3(333);
log.debug("req4: {}", r);
} finally {
latch.countDown();
}
});
latch.await(); // Pay attention to distinguish between await and wait
log.debug("end");
service.shutdown();
}
}
class MockController1 {
public String request1(int id) {
sleep(2);
return "back1 - " + id;
}
public String request2(int id) {
sleep(3);
return "back2 - " + id;
}
public String request3(int id) {
sleep(1);
return "back3 - " + id;
}
private void sleep(int seconds) {
try {
TimeUnit.SECONDS.sleep(seconds);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
results of enforcement
Return results - Future:
package top.onefine.test.c8;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.*;
@Slf4j(topic = "c.TestCountDownLatch5")
public class TestCountDownLatch5 {
public static void main(String[] args) throws InterruptedException, ExecutionException {
log.debug("begin");
ExecutorService service = Executors.newCachedThreadPool();
MockController2 mockController = new MockController2();
Future<String> f1 = service.submit(() -> {
return mockController.request1(111);
});
Future<String> f2 = service.submit(() -> {
return mockController.request2(222);
});
Future<String> f3 = service.submit(() -> {
return mockController.request2(2020);
});
Future<String> f4 = service.submit(() -> {
return mockController.request3(333);
});
log.debug("block...");
log.info("r1: {}", f1.get());
log.info("r2: {}", f2.get());
log.info("r3: {}", f3.get());
log.info("r4: {}", f4.get());
log.debug("complete....");
service.shutdown();
}
}
class MockController2 {
public String request1(int id) {
sleep(2);
return "back1 - " + id;
}
public String request2(int id) {
sleep(3);
return "back2 - " + id;
}
public String request3(int id) {
sleep(1);
return "back3 - " + id;
}
private void sleep(int seconds) {
try {
TimeUnit.SECONDS.sleep(seconds);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
results of enforcement
6. CyclicBarrier
package top.onefine.test.c8;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
@Slf4j(topic = "c.TestCountDownLatch6")
public class TestCountDownLatch6 {
public static void main(String[] args) {
ExecutorService service = Executors.newFixedThreadPool(5);
for (int i = 0; i < 3; i++) {
CountDownLatch latch = new CountDownLatch(2);
service.submit(() -> {
log.debug("task1 start...");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
latch.countDown();
});
service.submit(() -> {
log.debug("task2 start...");
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
latch.countDown();
});
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("task1 task2 finish...");
}
service.shutdown();
}
}
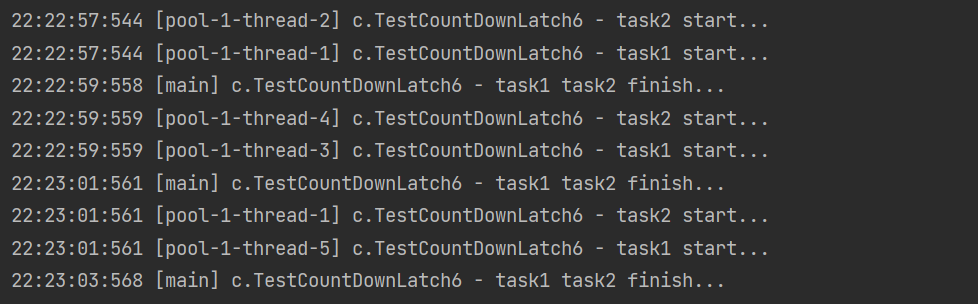
[ ˈ sa ɪ kl ɪ k ˈ bæri ɚ] The loop fence is used for thread cooperation and waiting for threads to meet a certain count. When constructing, set the count number. When each thread executes to a time when synchronization is required, call the await() method to wait. When the number of waiting threads meets the count number, continue to execute
package top.onefine.test.c8;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.*;
@Slf4j(topic = "c.TestCyclicBarrier")
public class TestCyclicBarrier {
public static void main(String[] args) {
// Note that the number of threads here is consistent with the number of tasks
ExecutorService service = Executors.newFixedThreadPool(2);
CyclicBarrier barrier = new CyclicBarrier(2, () -> {
// The second parameter is optional. It is used to summarize when all tasks are completed
log.debug("task1 task2 finish...");
});
for (int i = 0; i < 3; i++) {
service.submit(() -> {
log.debug("task1 start...");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("task1 end...");
try {
barrier.await(); // Blocking 2-1 = 1
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
});
service.submit(() -> {
log.debug("task2 start...");
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("task2 end...");
try {
barrier.await(); // Blocking 1-1 = 0
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
});
}
service.shutdown();
}
}
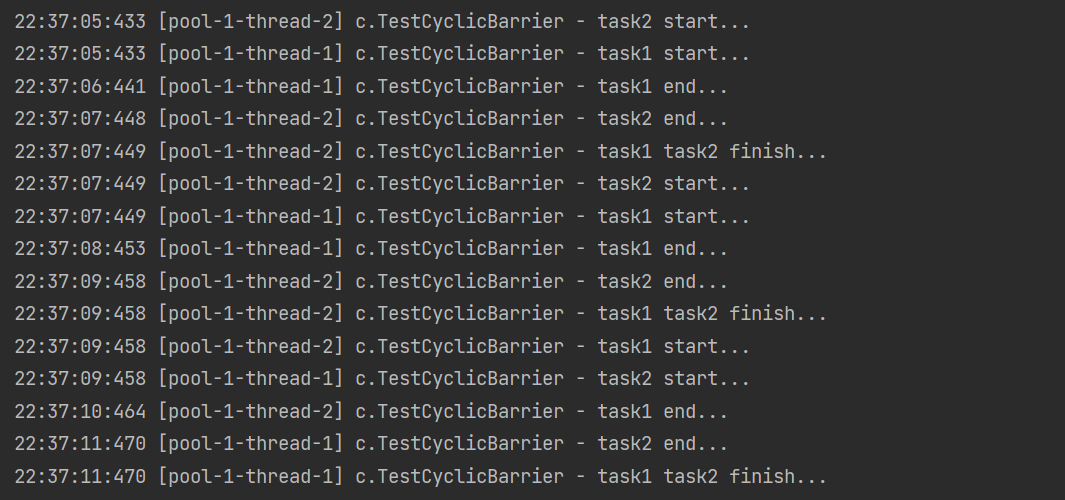
Note that the main difference between CyclicBarrier and CountDownLatch is that CyclicBarrier can be reused. CyclicBarrier can be compared to "driving with full capacity"
7. Overview of thread safe collection classes

Thread safe collection classes can be divided into three categories:
- Legacy thread safe collections such as Hashtable and Vector (not recommended)
- Thread safe Collections decorated with Collections, such as:
- Collections.synchronizedCollection
- Collections.synchronizedList
- Collections.synchronizedMap
- Collections.synchronizedSet
- Collections.synchronizedNavigableMap
- Collections.synchronizedNavigableSet
- Collections.synchronizedSortedMap
- Collections.synchronizedSortedSet
- java.util.concurrent. * (recommended)
Focus on the thread safe collection classes under java.util.concurrent. *. You can find that they are regular. They contain three types of keywords: Blocking, CopyOnWrite and concurrent
- Most implementations of Blocking are lock based and provide methods for Blocking
- Containers such as CopyOnWrite are relatively expensive to modify (suitable for scenarios with more reads and less writes)
- Container of type Concurrent
- Many internal operations use cas optimization, which can generally provide high throughput and weak consistency
- Weak consistency during traversal. For example, when traversing with an iterator, if the container is modified, the iterator can still continue to traverse, and the content is old
- For weak consistency of size, the size operation may not be 100% accurate
- Read weak consistency (disadvantages of these methods)
- Weak consistency during traversal. For example, when traversing with an iterator, if the container is modified, the iterator can still continue to traverse, and the content is old
- For weak consistency of size, the size operation may not be 100% accurate
- Read weak consistency
If the traversal is modified, for non secure containers, use the fail fast mechanism, that is, make the traversal fail immediately, throw a ConcurrentModificationException, and do not continue the traversal
8. ConcurrentHashMap
Exercise: word counting
Generate test data
static final String ALPHA = "abcedfghijklmnopqrstuvwxyz";
public static void main(String[] args) {
int length = ALPHA.length();
int count = 200;
List<String> list = new ArrayList<>(length * count);
for (int i = 0; i < length; i++) {
char ch = ALPHA.charAt(i);
for (int j = 0; j < count; j++) {
list.add(String.valueOf(ch));
}
}
Collections.shuffle(list);
for (int i = 0; i < 26; i++) {
try (PrintWriter out = new PrintWriter(
new OutputStreamWriter(
new FileOutputStream("tmp/" + (i + 1) + ".txt")))) {
String collect = list.subList(i * count, (i + 1) * count).stream()
.collect(Collectors.joining("\n"));
out.print(collect);
} catch (IOException e) {
}
}
}
Template code, which encapsulates the code of multi-threaded reading files
private static <V> void demo(Supplier<Map<String, V>> supplier,
BiConsumer<Map<String, V>, List<String>> consumer) {
Map<String, V> counterMap = supplier.get();
List<Thread> ts = new ArrayList<>();
for (int i = 1; i <= 26; i++) {
int idx = i;
Thread thread = new Thread(() -> {
List<String> words = readFromFile(idx);
consumer.accept(counterMap, words);
});
ts.add(thread);
}
ts.forEach(t -> t.start());
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
System.out.println(counterMap);
}
public static List<String> readFromFile(int i) {
ArrayList<String> words = new ArrayList<>();
try (BufferedReader in = new BufferedReader(new InputStreamReader(new FileInputStream("tmp/"
+ i + ".txt")))) {
while (true) {
String word = in.readLine();
if (word == null) {
break;
}
words.add(word);
}
return words;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
All you have to do is implement two parameters
- One is to provide a map set to store the counting results of each word. key is the word and value is the count
- The second is to provide a set of operations to ensure the security of counting, and pass the map set and the word List
The correct output should be 200 occurrences of each word
{a=200, b=200, c=200, d=200, e=200, f=200, g=200, h=200, i=200, j=200, k=200, l=200, m=200, n=200, o=200, p=200, q=200, r=200, s=200, t=200, u=200, v=200, w=200, x=200, y=200, z=200}
The following implementation is:
demo(
// Create map collection
// Create ConcurrentHashMap, right?
() -> new HashMap<String, Integer>(),
// Count
(map, words) -> {
for (String word : words) {
Integer counter = map.get(word);
int newValue = counter == null ? 1 : counter + 1;
map.put(word, newValue);
}
}
);

solve:
demo(
() -> new HashMap<String, Integer>(),
(map, words) -> {
synchronized (map) {
for (String word : words) {
Integer counter = map.get(word);
int newValue = counter == null ? 1 : counter + 1;
map.put(word, newValue);
}
}
}
);

Further:
demo(
() -> new HashMap<String, Integer>(),
(map, words) -> {
for (String word : words) {
// The following three lines should ensure atomicity
synchronized (map) {
Integer counter = map.get(word);
int newValue = counter == null ? 1 : counter + 1;
map.put(word, newValue);
}
}
}
);
Using thread safe classes and accumulators to improve
demo(
() -> new ConcurrentHashMap<String, LongAdder>(),
(map, words) -> {
for (String word : words) {
// If a key is missing, calculate and generate a value, and then put the key value into the map
LongAdder value = map.computeIfAbsent(word, (key) -> {
return new LongAdder();
});
// Execute accumulation
value.increment();
// equivalence
// Note that putIfAbsent cannot be used. This method returns the last value, and the first call returns null
// map.computeIfAbsent(word, (key) -> new LongAdder()).increment();
}
}
);
Use functional programming to improve:
demo(
() -> new ConcurrentHashMap<String, Integer>(),
(map, words) -> {
for (String word : words) {
// Functional programming without atomic variables
map.merge(word, 1, Integer::sum);
}
}
);
*Principle of ConcurrentHashMap
1. JDK 7 HashMap concurrent dead chain
Test code
be careful
- Run under JDK 7, or the capacity expansion mechanism and hash calculation method will change
- The following test code is carefully prepared and should not be changed
Note: in JDK7, in case of hash conflict, header interpolation is used (the later added elements are placed in the chain header)
public static void main(String[] args) {
// Test which numbers in java 7 have the same hash result
System.out.println("When the length is 16, the barrel subscript is 1 key");
for (int i = 0; i < 64; i++) {
if (hash(i) % 16 == 1) {
System.out.println(i);
}
}
System.out.println("When the length is 32, the bucket subscript is 1 key");
for (int i = 0; i < 64; i++) {
if (hash(i) % 32 == 1) {
System.out.println(i);
}
}
// 1, 35, 16, 50 when the size is 16, they are in a bucket
final HashMap<Integer, Integer> map = new HashMap<Integer, Integer>();
// Put 12 elements
map.put(2, null);
map.put(3, null);
map.put(4, null);
map.put(5, null);
map.put(6, null);
map.put(7, null);
map.put(8, null);
map.put(9, null);
map.put(10, null);
map.put(16, null);
map.put(35, null);
map.put(1, null);
System.out.println("Size before expansion[main]:" + map.size());
new Thread() {
@Override
public void run() {
// Put the 13th element and expand the capacity
map.put(50, null);
System.out.println("Size after capacity expansion[Thread-0]:" + map.size());
}
}.start();
new Thread() {
@Override
public void run() {
// Put the 13th element and expand the capacity
map.put(50, null);
System.out.println("Size after capacity expansion[Thread-1]:" + map.size());
}
}.start();
}
final static int hash(Object k) {
int h = 0;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
Dead chain recurrence
Debugging tools use idea
Add a breakpoint in line 590 of the HashMap source code
int newCapacity = newTable.length;
The breakpoint conditions are as follows. The purpose is to stop the HashMap when the capacity is expanded to 32 and the thread is Thread-0 or Thread-1
newTable.length==32 &&
(
Thread.currentThread().getName().equals("Thread-0")||
Thread.currentThread().getName().equals("Thread-1")
)
Thread is selected as the breakpoint pause mode, otherwise Thread-1 cannot resume running when debugging Thread-0
Run the code, the program stops at the expected breakpoint and outputs

Next, enter the capacity expansion process commissioning
Add a breakpoint in line 594 of the HashMap source code

This is to observe the status of the e node and the next node. Thread-0 is executed in a single step to line 594, and a breakpoint is added at line 594 (conditional Thread.currentThread().getName().equals("Thread-0"))
At this time, you can observe the e and next Variables on the Variables panel, and use view as - > object to view the node status
be careful:
- Here is 1 - > 35 - > 16, that is, the node status before capacity expansion
- Then add the chain setting header of the element

In the Threads panel, select Thread-1 to resume operation. You can see that the console outputs new contents as follows. The expansion of Thread-1 has been completed

At this time, Thread-0 still stops at 594, and the state of the Variables panel variable has changed to

Why? Because when Thread-1 is expanded, the linked list is also added later and put into the chain header, so the linked list is reversed. Although the result of Thread-1 is correct, Thread-0 will continue to run after it is completed
Next, you can step-by-step debugging (F8) to observe the generation of dead chain
The next cycle goes to 594 and moves e to the newTable chain header

The next cycle goes to 594 and moves e to the newTable chain header

Look at the source code
e.next = newTable[1]; // At this time e (1,35) // Newtable [1] (35,1) - > (1,35) is the same object newTable[1] = e; // Try again to take e as the chain header, and the dead chain has been formed e = next; // Although next is null and will enter the next linked list replication, the dead chain has been formed
Source code analysis
The concurrent dead chain of HashMap occurs during capacity expansion
// Migrate table to newTable
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K, V> e : table) {
while (null != e) {
Entry<K, V> next = e.next;
// 1 place
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
// 2 places
// Add the new element to newTable[i], and the original newTable[i] is the next of the new element
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
Suppose the initial element in the map is
Original linked list, format:[subscript] (key,next) [1] (1,35)->(35,16)->(16,null) thread a Execute to 1, where the local variable e by (1,35),Local variables next by (35,16) thread a Hang thread b Start execution First cycle [1] (1,null) Second cycle [1] (35,1)->(1,null) Third cycle [1] (35,1)->(1,null) [17] (16,null) Switch back to thread a,At this point, the local variable e and next Restored, the reference remains unchanged, but the content changes: e The content of is changed to (1,null),and next The content of is changed to (35,1) Parallel chain direction (1,null) First cycle [1] (1,null) The second cycle, pay attention to this time e yes (35,1) Parallel chain direction (1,null) therefore next again (1,null) [1] (35,1)->(1,null) The third cycle, e yes (1,null),and next yes null,but e Put into the chain header, so e.next Became 35 (2 places) [1] (1,35)->(35,1)->(1,35) It's a dead chain
Summary
- The reason is that non thread safe map sets are used in multi-threaded environment
- Although JDK 8 has adjusted the capacity expansion algorithm to no longer add elements to the chain header (but maintain the same order as before capacity expansion), it still does not mean that it can safely expand capacity in a multi-threaded environment, and there will be other problems (such as data loss during capacity expansion)
2. JDK 8 ConcurrentHashMap
Important properties and inner classes
// The default is 0
// - 1 when initialized
// In case of capacity expansion, it is - (1 + number of capacity expansion threads)
// After initialization or capacity expansion is completed, it is the threshold size of the next capacity expansion
private transient volatile int sizeCtl;
// The entire ConcurrentHashMap is a Node []
static class Node<K,V> implements Map.Entry<K,V> {}
// hash table
transient volatile Node<K,V>[] table;
// New hash table during capacity expansion
private transient volatile Node<K,V>[] nextTable;
// During capacity expansion, if a bin is migrated, ForwardingNode is used as the head node of the old table bin
static final class ForwardingNode<K,V> extends Node<K,V> {}
// It is used in compute and computeIfAbsent to occupy bits. After calculation, it is replaced with ordinary nodes
static final class ReservationNode<K,V> extends Node<K,V> {}
// As the head node of treebin, store root and first
static final class TreeBin<K,V> extends Node<K,V> {}
// As the node of treebin, store parent, left, right
static final class TreeNode<K,V> extends Node<K,V> {}
Important methods
// Get the ith Node in Node [] static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) // cas modifies the value of the ith Node in Node [], where c is the old value and v is the new value static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v) // Directly modify the value of the ith Node in Node [], and v is the new value static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v)
Constructor analysis
You can see that lazy initialization is implemented. In the construction method, only the size of the table is calculated, and it will be created when it is used for the first time
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long) (1.0 + (long) initialCapacity / loadFactor);
// tableSizeFor still guarantees that the calculated size is 2^n, that is, 16,32,64
int cap = (size >= (long) MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int) size);
this.sizeCtl = cap;
}
get process
public V get(Object key) {
Node<K, V>[] tab;
Node<K, V> e, p;
int n, eh;
K ek;
// The spread method ensures that the returned result is a positive number
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// If the header node is already the key to be found
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// A negative hash indicates that the bin is in capacity expansion or treebin. In this case, call the find method to find it
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
// Normally traverse the linked list and compare with equals
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
put process
The following is the abbreviation of array (table) and linked list (bin)
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// Among them, the spread method combines the high and low bits, which has better hash performance
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K, V>[] tab = table; ; ) {
// f is the chain header node
// fh is the hash of the chain header node
// i is the subscript of the linked list in table
Node<K, V> f;
int n, i, fh;
// To create a table
if (tab == null || (n = tab.length) == 0)
// cas is used to initialize the table. It does not need to be synchronized. It is successfully created and enters the next cycle
tab = initTable();
// To create a chain header node
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// cas is used to add the chain header, and synchronized is not required
if (casTabAt(tab, i, null,
new Node<K, V>(hash, key, value, null)))
break;
}
// Help expand capacity
else if ((fh = f.hash) == MOVED)
// After help, enter the next cycle
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// Lock chain header node
synchronized (f) {
// Confirm again that the chain header node has not been moved
if (tabAt(tab, i) == f) {
// Linked list
if (fh >= 0) {
binCount = 1;
// Traversal linked list
for (Node<K, V> e = f; ; ++binCount) {
K ek;
// The same key was found
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
// to update
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K, V> pred = e;
// It is already the last Node. Add a new Node and add it to the end of the linked list
if ((e = e.next) == null) {
pred.next = new Node<K, V>(hash, key,
value, null);
break;
}
}
}
// Red black tree
else if (f instanceof TreeBin) {
Node<K, V> p;
binCount = 2;
// putTreeVal will check whether the key is already in the tree. If yes, the corresponding TreeNode will be returned
if ((p = ((TreeBin<K, V>) f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
// Release the lock of the chain header node
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
// If the linked list len gt h > = treelization threshold (8), convert the linked list to red black tree
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// Increase size count
addCount(1L, binCount);
return null;
}
private final Node<K, V>[] initTable() {
Node<K, V>[] tab;
int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield();
// Try to set sizeCtl to - 1 (to initialize table)
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
// Obtain the lock and create the table. At this time, other threads will yield in the while() loop until the table is created
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
Node<K, V>[] nt = (Node<K, V>[]) new Node<?, ?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
// check is the number of previous bincounts
private final void addCount(long x, int check) {
CounterCell[] as;
long b, s;
if (
// There are already counter cells, which are accumulated to the cell
(as = counterCells) != null ||
// Not yet. Add up to baseCount
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)
) {
CounterCell a;
long v;
int m;
boolean uncontended = true;
if (
// No counterCells yet
as == null || (m = as.length - 1) < 0 ||
// No cell yet
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
// cell cas failed to increase count
!(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))
) {
// Create an accumulation cell array and cell, and retry accumulation
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
// Get the number of elements
s = sumCount();
}
if (check >= 0) {
Node<K, V>[] tab, nt;
int n, sc;
while (s >= (long) (sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
// newtable has been created to help expand the capacity
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
// The capacity needs to be expanded. At this time, the newtable is not created
else if (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
size calculation process
The size calculation actually occurs in the operation of put and remove to change the collection elements
- No contention occurs, and the count is accumulated to baseCount
- If there is competition, create counter cell s and add a count to one of them
- Counter cells initially has two cells
- If the counting competition is fierce, a new cell will be created to accumulate the counting
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long) Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int) n);
}
final long sumCount() {
CounterCell[] as = counterCells;
CounterCell a;
// Adds the baseCount count count to all cell counts
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
Java 8 array (Node) + (linked list Node | red black tree TreeNode) is hereinafter referred to as array (table) and linked list (bin)
- Initialize, use cas to ensure concurrency security, and lazy initialize table
- Tree. When table. Length < 64, try to expand the capacity first. When it exceeds 64 and bin. Length > 8, the linked list will be tree. The tree process will lock the chain header with synchronized
- Put, if the bin has not been created, you only need to use cas to create the bin; If it already exists, lock the chain header for subsequent put operations, and add the element to the tail of bin
- Get, the lock free operation only needs to ensure visibility. In the process of capacity expansion, the get operation gets the ForwardingNode, which will let the get operation search in the new table
- During capacity expansion, the bin is used as the unit, and the bin needs to be synchronized. However, the wonderful thing is that other competing threads do not have nothing to do. They will help to expand the capacity of other bin. During capacity expansion, only 1 / 6 of the nodes will copy to the new table
- size, the number of elements is saved in baseCount, and the number change during concurrency is saved in CounterCell []. Finally, the quantity can be accumulated during statistics
Source code analysis http://www.importnew.com/28263.html
Other implementations Cliff Click's high scale lib
3. JDK 7 ConcurrentHashMap
It maintains an array of segment s, each of which corresponds to a lock
- Advantages: if multiple threads access different segment s, there is actually no conflict, which is similar to that in jdk8
- Disadvantages: the default size of the Segments array is 16. This capacity cannot be changed after initialization is specified, and it is not lazy initialization
Constructor analysis
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Size must be 2^n, that is, 2, 4, 8, 16... Indicates the size of the segments array
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
// segmentShift defaults to 32 - 4 = 28
this.segmentShift = 32 - sshift;
// segmentMask defaults to 15, that is, 0000 1111
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// Create segments and segments[0]
Segment<K, V> s0 =
new Segment<K, V>(loadFactor, (int) (cap * loadFactor),
(HashEntry<K, V>[]) new HashEntry[cap]);
Segment<K, V>[] ss = (Segment<K, V>[]) new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
The construction is completed, as shown in the following figure
You can see that ConcurrentHashMap does not implement lazy initialization, and the space occupation is not friendly
this.segmentShift and this.segmentMask are used to determine which segment the hash result of the key is matched to
For example, to find the position of segment according to a hash value, first move the high bit to the low bit of this.segmentShift

The result is then located with this.segmentMask, and finally 1010 is obtained, that is, the segment with subscript 10

put process
public V put(K key, V value) {
Segment<K, V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
// Calculate the segment subscript
int j = (hash >>> segmentShift) & segmentMask;
// Obtain the segment object and judge whether it is null. If yes, create the segment
if ((s = (Segment<K, V>) UNSAFE.getObject
(segments, (j << SSHIFT) + SBASE)) == null) {
// At this time, it is uncertain whether it is really null, because other threads also find that the segment is null,
// Therefore, cas is used in ensuesegment to ensure the security of the segment
s = ensureSegment(j);
}
// Enter the put process of segment
return s.put(key, hash, value, false);
}
segment inherits ReentrantLock and its put method is
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// Try locking
HashEntry<K, V> node = tryLock() ? null :
// If not, enter the scanAndLockForPut process
// If it is a multi-core cpu, try lock 64 times at most, and enter the lock process
// During the trial, you can also check whether the node is in the linked list. If not, you can create it
scanAndLockForPut(key, hash, value);
// After execution, the segment has been locked successfully and can be executed safely
V oldValue;
try {
HashEntry<K, V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K, V> first = entryAt(tab, index);
for (HashEntry<K, V> e = first; ; ) {
if (e != null) {
// to update
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
} else {
// newly added
// 1) Before waiting for the lock, the node has been created, and the next points to the chain header
if (node != null)
node.setNext(first);
else
// 2) Create a new node
node = new HashEntry<K, V>(hash, key, value, first);
int c = count + 1;
// 3) Capacity expansion
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
// Use node as the chain header
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
rehash process
It occurs in the put, because the lock has been obtained at this time, so there is no need to consider thread safety when rehash
private void rehash(HashEntry<K, V> node) {
HashEntry<K, V>[] oldTable = table;
int oldCapacity = oldTable.length;
int newCapacity = oldCapacity << 1;
threshold = (int) (newCapacity * loadFactor);
HashEntry<K, V>[] newTable =
(HashEntry<K, V>[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity; i++) {
HashEntry<K, V> e = oldTable[i];
if (e != null) {
HashEntry<K, V> next = e.next;
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
HashEntry<K, V> lastRun = e;
int lastIdx = idx;
// Go through the linked list and reuse the idx unchanged nodes after rehash as much as possible
for (HashEntry<K, V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
newTable[lastIdx] = lastRun;
// The remaining nodes need to be created
for (HashEntry<K, V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K, V> n = newTable[k];
newTable[k] = new HashEntry<K, V>(h, p.key, v, n);
}
}
}
}
// New nodes are added only after capacity expansion is completed
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
// Replace with a new HashEntry table
table = newTable;
}
Attached, debugging code
public static void main(String[] args) {
ConcurrentHashMap<Integer, String> map = new ConcurrentHashMap<>();
for (int i = 0; i < 1000; i++) {
int hash = hash(i);
int segmentIndex = (hash >>> 28) & 15;
if (segmentIndex == 4 && hash % 8 == 2) {
System.out.println(i + "\t" + segmentIndex + "\t" + hash % 2 + "\t" + hash % 4 +
"\t" + hash % 8);
}
}
map.put(1, "value");
map.put(15, "value"); // 2. The hash%8 with capacity expansion of 4 15 is different from others
map.put(169, "value");
map.put(197, "value"); // 4 expansion to 8
map.put(341, "value");
map.put(484, "value");
map.put(545, "value"); // 8. Capacity expansion is 16
map.put(912, "value");
map.put(941, "value");
System.out.println("ok");
}
private static int hash(Object k) {
int h = 0;
if ((0 != h) && (k instanceof String)) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// Spread bits to regularize both segment and index locations,
// using variant of single-word Wang/Jenkins hash.
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
int v = h ^ (h >>> 16);
return v;
}
get process
Get is not locked, and the UNSAFE method is used to ensure visibility. In the process of capacity expansion, get takes the content from the old table first, and take the content from the new table after get
public V get(Object key) {
Segment<K, V> s; // manually integrate access methods to reduce overhead
HashEntry<K, V>[] tab;
int h = hash(key);
// u is the offset of the segment object in the array
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// s is segment
if ((s = (Segment<K, V>) UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K, V> e = (HashEntry<K, V>) UNSAFE.getObjectVolatile
(tab, ((long) (((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
size calculation process
- Before calculating the number of elements, calculate twice without locking. If the results are the same, it is considered that the number is returned correctly
- If not, retry. If the number of retries exceeds 3, lock all segment s, recalculate the number, and return
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment<K, V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (; ; ) {
if (retries++ == RETRIES_BEFORE_LOCK) {
// If the number of retries exceeds, all segment s need to be created and locked
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K, V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
9. BlockingQueue
*BlockingQueue principle - LinkedBlockingQueue
1. Basic entry and exit
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
static class Node<E> {
E item;
/**
* One of the following three situations
* - True successor node
* - Myself, it happened when I was out of the team
* - null, Indicates that there is no successor node, and it is the last
*/
Node<E> next;
Node(E x) {
item = x;
}
}
}
Initialize the linked list last = head = new node < E > (null); The dummy node is used to occupy the space, and the item is null
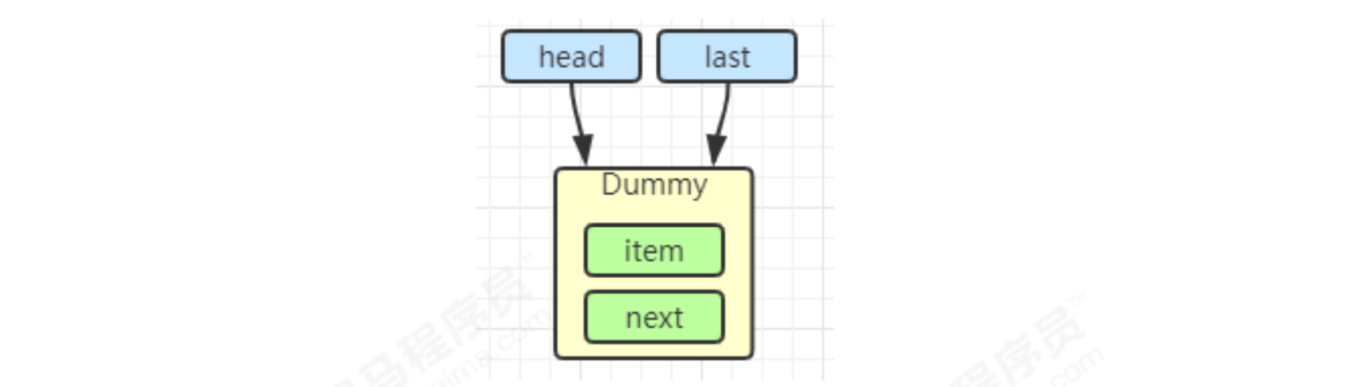
When a node joins the queue, last = last.next = node;
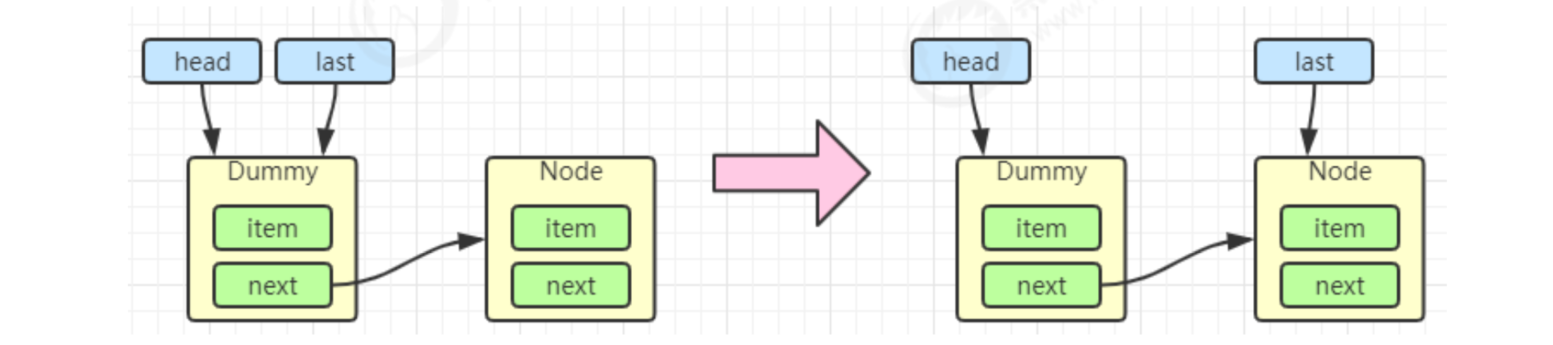
Another node joins the queue. last = last.next = node;
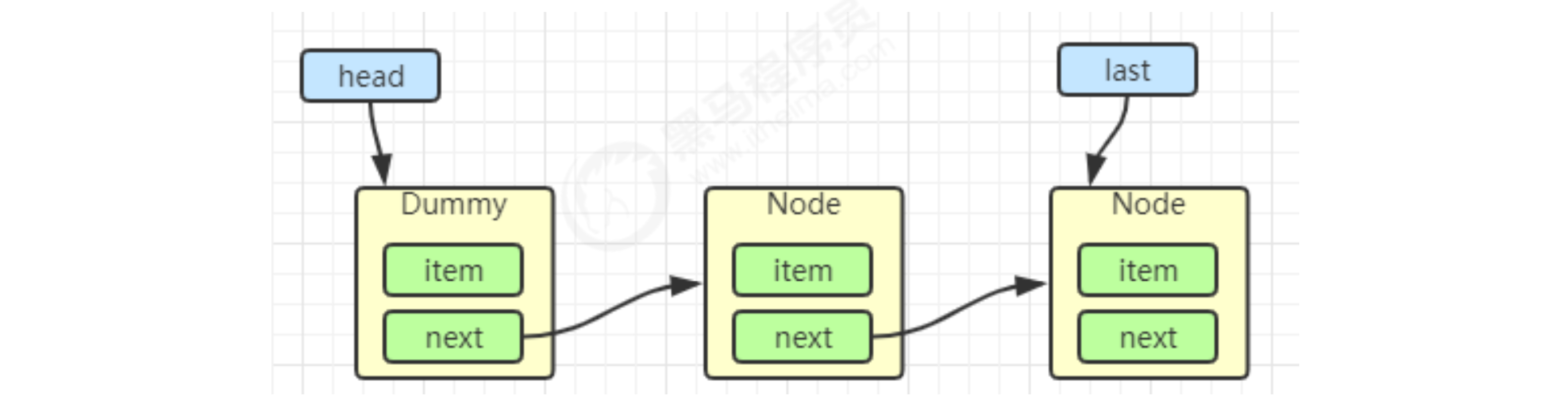
Out of the team
Node<E> h = head; Node<E> first = h.next; h.next = h; // help GC head = first; E x = first.item; first.item = null; return x;
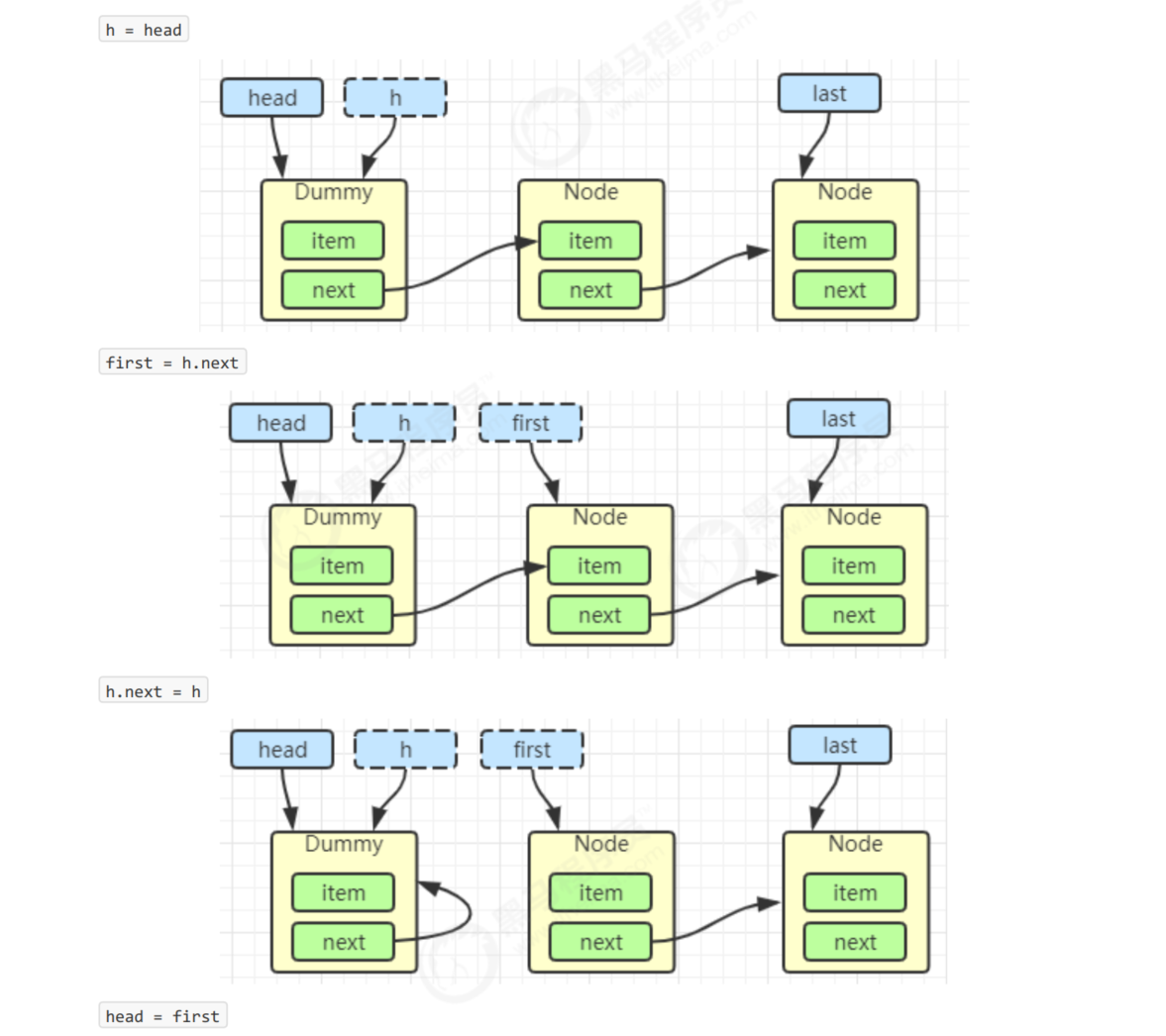
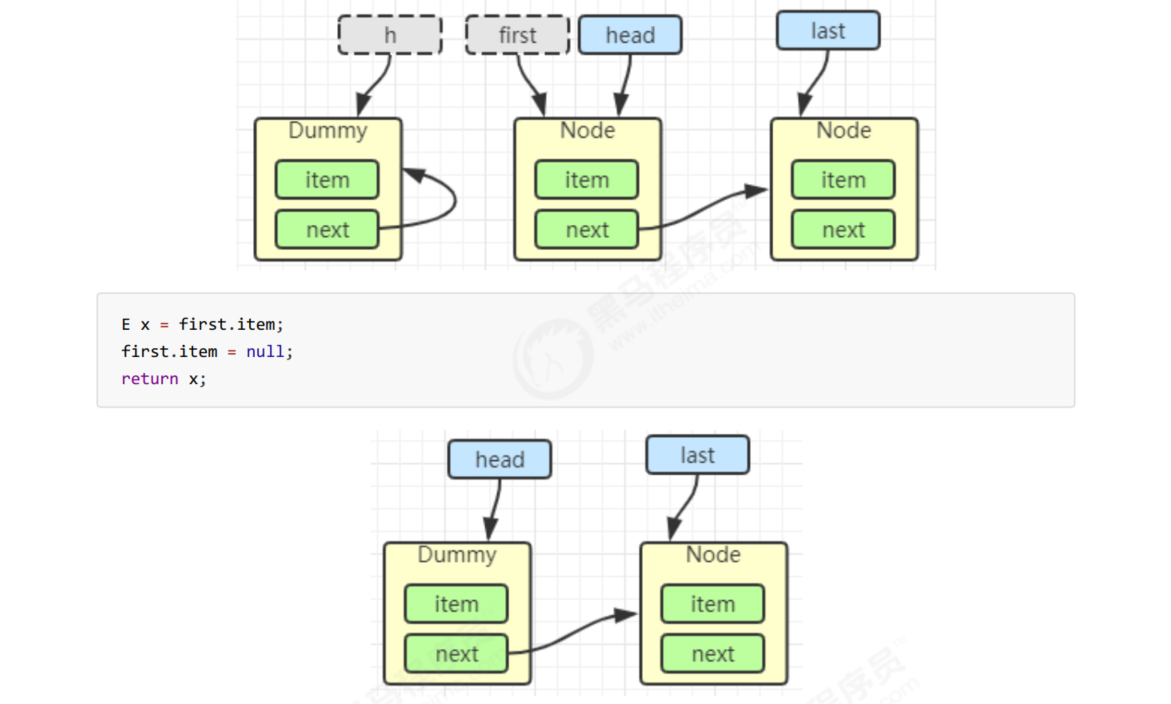
2. Locking analysis
The smart thing is that it uses two locks and dummy nodes
- With a lock, at most one thread (producer or consumer, one of two) is allowed to execute at the same time
- With two locks, two threads (one producer and one consumer) can be allowed to execute at the same time
+Consumer and consumer threads are still serial
+Producer and producer threads are still serial
Thread safety analysis
- When the total number of nodes is greater than 2 (including dummy nodes), putLock ensures the thread safety of the last node and takeLock ensures the thread safety of the head node. Two locks ensure that there is no competition between entering and leaving the team
- When the total number of nodes is equal to 2 (i.e. a dummy node and a normal node), there are still two locks and two objects, and there will be no competition
- When the total number of nodes is equal to 1 (just a dummy node), the take thread will be blocked by the notEmpty condition. If there is competition, it will be blocked
// For put offer private final ReentrantLock putLock = new ReentrantLock(); // User take poll private final ReentrantLock takeLock = new ReentrantLock();
put operation
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
// Count is used to maintain the element count
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
// Full waiting
while (count.get() == capacity) {
// Just read it backwards: wait for notFull
notFull.await();
}
// If there is space, join the team and add one to the count
enqueue(node);
c = count.getAndIncrement();
// In addition to their own put, the queue also has empty bits, and they wake up other put threads by themselves
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
// If there is an element in the queue, wake up the take thread
if (c == 0)
// notEmpty.signal() is called instead of notEmpty.signalAll() to reduce contention
signalNotEmpty();
}
take operation
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
while (count.get() == 0) {
notEmpty.await();
}
x = dequeue();
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
// If there is only one empty bit in the queue, wake up the put thread
// If multiple threads are dequeued, the first thread satisfies c == capacity, but the subsequent thread C < capacity
if (c == capacity)
// notFull.signal() is called instead of notFull.signalAll() to reduce contention
signalNotFull();
return x;
}
Wake up put by put to avoid signal shortage
3. Performance comparison
It mainly lists the performance comparison between LinkedBlockingQueue and ArrayBlockingQueue
- Linked supports bounded, and Array forces bounded
- The Linked implementation is a Linked list, and the Array implementation is an Array
- Linked is lazy, and Array needs to initialize the Node Array in advance
- Linked generates new nodes every time it joins the queue, and the nodes of Array are created in advance
- Linked two locks, Array one lock
10. ConcurrentLinkedQueue
The design of concurrent linkedqueue is very similar to LinkedBlockingQueue
- Two locks allow two threads (one producer and one consumer) to execute at the same time
- The introduction of dummy node enables two locks to lock different objects in the future to avoid competition
- Only cas is used for this [lock]
In fact, concurrent linkedqueue is widely used
For example, in the Connector structure of Tomcat mentioned earlier, when the Acceptor, as a producer, transmits event information to Poller consumers, it uses ConcurrentLinkedQueue to use SocketChannel to Poller
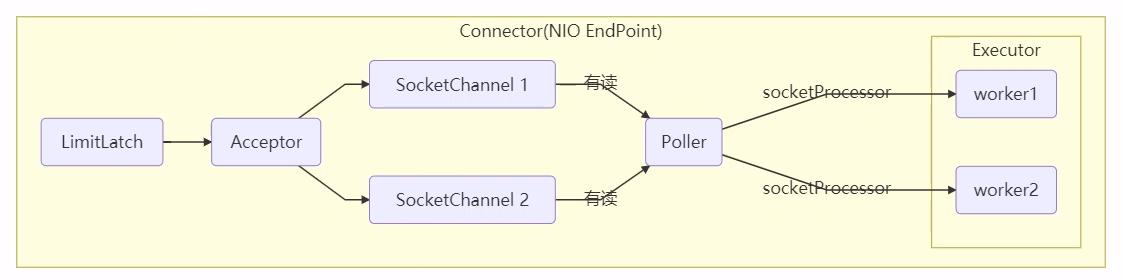
*Principle of ConcurrentLinkedQueue
A little
11. CopyOnWriteArrayList
CopyOnWriteArraySet is its vest
The bottom implementation adopts the idea of copy when writing. The addition, deletion and modification operation will copy a copy of the bottom array, and the change operation will be executed on the new array. At this time, it will not affect the concurrent reading of other threads and the separation of reading and writing.
Take the new as an example:
public boolean add(E e) {
synchronized (lock) {
// Get old array
Object[] es = getArray();
int len = es.length;
// Copy a new array (this is a time-consuming operation, but it does not affect other read threads)
es = Arrays.copyOf(es, len + 1);
// Add new element
es[len] = e;
// Replace old array
setArray(es);
return true;
}
}
The source code version here is Java 11. In Java 1.8, reentrant locks are used instead of synchronized
Other read operations are not locked, for example:
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
for (Object x : getArray()) {
@SuppressWarnings("unchecked") E e = (E) x;
action.accept(e);
}
}
It is suitable for the application scenario of "more reading and less writing"
get weak consistency

It's not easy to test, but the problem does exist
Iterator weak consistency
CopyOnWriteArrayList<Integer> list = new CopyOnWriteArrayList<>();
list.add(1);
list.add(2);
list.add(3);
Iterator<Integer> iter = list.iterator();
new Thread(() -> {
list.remove(0);
System.out.println(list);
}).start();
sleep1s();
while (iter.hasNext()) {
System.out.println(iter.next());
}
Don't think weak consistency is bad
- MVCC of database is the performance of weak consistency
- High concurrency and consistency are contradictory and need to be weighed