4, Shared model memory
1. Java Memory Model (JMM)
5, Lock free of shared model
In this chapter, we will implement concurrency control through non blocking optimistic locks
1. Solving thread safety problems without locks
The following code solves the thread safety problem through synchronized.
public class Code_04_UnsafeTest {
public static void main(String[] args) {
Account acount = new AccountUnsafe(10000);
Account.demo(acount);
}
}
class AccountUnsafe implements Account {
private Integer balance;
public AccountUnsafe(Integer balance) {
this.balance = balance;
}
@Override
public Integer getBalance() {
return this.balance;
}
@Override
public void withdraw(Integer amount) {
synchronized (this) { // Lock.
this.balance -= amount;
}
}
}
interface Account {
// How to get the amount
Integer getBalance();
// Withdrawal method
void withdraw(Integer amount);
static void demo(Account account) {
List<Thread> list = new ArrayList<>();
long start = System.nanoTime();
for(int i = 0; i < 1000; i++) {
list.add(new Thread(() -> {
account.withdraw(10);
}));
}
list.forEach(Thread::start);
list.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
long end = System.nanoTime();
System.out.println(account.getBalance()
+ " cost: " + (end-start)/1000_000 + " ms");
}
}
Locking the above code will cause thread blocking. The blocking time depends on the code execution time in the critical area. The performance of locking is not high. We can use no lock to solve this problem.
class AccountSafe implements Account{
AtomicInteger atomicInteger ;
public AccountSafe(Integer balance){
this.atomicInteger = new AtomicInteger(balance);
}
@Override
public Integer getBalance() {
return atomicInteger.get();
}
@Override
public void withdraw(Integer amount) {
// Core code
while (true){
int pre = getBalance();
int next = pre - amount;
if (atomicInteger.compareAndSet(pre,next)){
break;
}
}
}
}
2. CAS and volatile
1)cas
The AtomicInteger solution seen earlier does not use locks internally to protect the thread safety of shared variables. So how is it implemented?
The key is compareAndSwap (compare and set values). Its short name is CAS (also known as Compare And Swap). It must be an atomic operation.
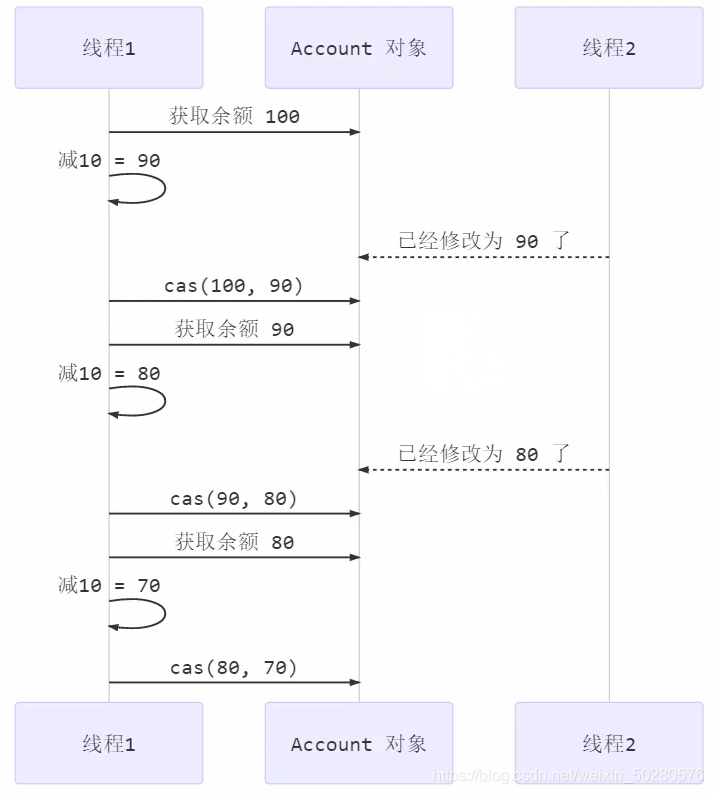 As shown in the figure, its workflow is as follows:
As shown in the figure, its workflow is as follows:
When a thread wants to modify the value in the Account object, first obtain the value preVal (call the get method), and then set it to the new value nextVal (call the cas method). When the cas method is called, the pre is compared with the balance in the Account.
If the two are equal, it means that the value has not been modified by other threads. You can modify it at this time. If the two are not equal, the value is not set and the value is retrieved preVal(call get Method), and then set it to the new value nextVal(call cas Method) until the modification is successful.
be careful:
actually CAS The bottom layer is lock cmpxchg Instruction( X86 Architecture), in single core CPU And multicore CPU It can ensure [comparison] under all conditions-Exchange atomicity. In the multi-core state, a core executes to the band lock When you give instructions, CPU It will lock the bus. When the core completes the execution of this instruction, turn on the bus. This process will not be interrupted by the thread scheduling mechanism, which ensures the accuracy of memory operation by multiple threads. It is atomic.
2)volatile
When obtaining a shared variable, in order to ensure the visibility of the variable, you need to use volatile decoration.
It can be used to modify member variables and static member variables. It can prevent threads from looking up the value of variables from their own work cache. They must get its value from main memory. Threads operate volatile variables directly in main memory. That is, the modification of volatile variable by one thread is visible to another thread.
be careful
volatile only ensures the visibility of shared variables so that other threads can see new values, but it cannot solve the problem of instruction interleaving (atomicity is not guaranteed)
CAS is an atomic operation to achieve the effect of [compare and exchange] by reading the new value of the shared variable with volatile
3) Why is lockless efficiency high
- In the case of no lock, even if the retry fails, the thread will always run at high speed without stopping, and synchronized will cause the thread to switch context and enter blocking when it does not obtain the lock. Let's make an analogy: threads are like a racing car on a high-speed track. When running at high speed, the speed is very fast. Once a context switch occurs, it's like a racing car needs to slow down and shut down. When it is awakened, it has to fire, start and accelerate again... It's expensive to return to high-speed operation
- However, in the case of no lock, the thread needs additional CPU support to keep running
Here, it is like a high-speed runway. Without an additional runway, it is impossible for threads to run at high speed. Although they will not enter blocking, they will still enter the runnable state due to the lack of time slice, which will still lead to context switching.
4) Characteristics of CAS
Combined with CAS and volatile, lock free concurrency can be realized, which is suitable for scenarios with few threads and multi-core CPU s.
CAS It is based on the idea of optimistic lock: the most optimistic estimate is that you are not afraid of other threads to modify shared variables. Even if you do, it doesn't matter. I'll try again at a loss.
synchronized It is based on the idea of pessimistic lock: the most pessimistic estimate is to prevent other threads from modifying shared variables. When I lock, you don't want to change it. Only when I know how to unlock it can you have a chance.
CAS It embodies lock free concurrency and non blocking concurrency. Please carefully understand the meaning of these two sentences
Because it's not used synchronized,Therefore, threads will not be blocked, which is one of the factors to improve efficiency
But if the competition is fierce(Multiple write operations),It is conceivable that retries must occur frequently, but the efficiency will be affected
3. Atomic integer
java.util.concurrent.atomic also provides some concurrency tool classes, which are divided into five categories:
Update base types atomically
AtomicInteger: Integer atomic class AtomicLong: Long integer atomic class AtomicBoolean : Boolean atomic class
The methods provided by the above three classes are almost the same, so we will take AtomicInteger as an example.
Atomic reference
Atomic array
Field Updater
Atomic accumulator
Let's first discuss the atomic integer class and take AtomicInteger as an example to discuss its api interface: by observing the source code, we can find that AtomicInteger is implemented internally through the principle of cas.
public static void main(String[] args) {
AtomicInteger i = new AtomicInteger(0);
// Get and auto increment (i = 0, result i = 1, return 0), similar to i++
System.out.println(i.getAndIncrement());
// Auto increment and get (i = 1, result i = 2, return 2), similar to + + i
System.out.println(i.incrementAndGet());
// Subtract and get (i = 2, result i = 1, return 1), similar to -- i
System.out.println(i.decrementAndGet());
// Gets and subtracts itself (i = 1, result i = 0, returns 1), similar to i--
System.out.println(i.getAndDecrement());
// Get and add value (i = 0, result i = 5, return 0)
System.out.println(i.getAndAdd(5));
// Add value and get (i = 5, result i = 0, return 0)
System.out.println(i.addAndGet(-5));
// Get and update (i = 0, p is the current value of i, result i = -2, return 0)
// Functional programming interface, in which the operation in the function can guarantee the atom, but the function needs no side effects
System.out.println(i.getAndUpdate(p -> p - 2));
// Update and get (i = -2, p is the current value of i, result i = 0, return 0)
// Functional programming interface, in which the operation in the function can guarantee the atom, but the function needs no side effects
System.out.println(i.updateAndGet(p -> p + 2));
// Get and calculate (i = 0, p is the current value of i, x is parameter 1, the result i = 10, returns 0)
// Functional programming interface, in which the operation in the function can guarantee the atom, but the function needs no side effects
// If getAndUpdate references an external local variable in lambda, ensure that the local variable is final
// getAndAccumulate can reference an external local variable through parameter 1, but it does not have to be final because it is not in lambda
System.out.println(i.getAndAccumulate(10, (p, x) -> p + x));
// Calculate and obtain (i = 10, p is the current value of i, x is the value of parameter 1, the result i = 0, return 0)
// Functional programming interface, in which the operation in the function can guarantee the atom, but the function needs no side effects
System.out.println(i.accumulateAndGet(-10, (p, x) -> p + x));
}
4. Atomic reference
Why do you need atomic reference types? Ensure that shared variables of reference type are thread safe (ensure that this atomic reference has not referenced others).
A basic type atomic class can only update one variable. If you need to update multiple variables, you need to use a reference type atomic class.
AtomicReference: Reference type atomic class AtomicStampedReference: Atomic updates reference types with version numbers. This class associates integer values with references, which can be used to solve atomic update data and data version number, and can be used to solve CAS Possible problems during atomic update ABA Question. AtomicMarkableReference : Atomic updates reference types with tags. This class will boolean Tags are associated with references.
1)AtomicReference
Let's look at the following code first:
class DecimalAccountUnsafe implements DecimalAccount {
BigDecimal balance;
public DecimalAccountUnsafe(BigDecimal balance) {
this.balance = balance;
}
@Override
public BigDecimal getBalance() {
return balance;
}
// Withdrawal task
@Override
public void withdraw(BigDecimal amount) {
BigDecimal balance = this.getBalance();
this.balance = balance.subtract(amount);
}
}
When the withraw method is executed, there may be thread safety. We can solve it by locking or using CAS without lock. The solution is to use AtomicReference atomic reference.
The code is as follows:
class DecimalAccountCas implements DecimalAccount {
private AtomicReference<BigDecimal> balance;
public DecimalAccountCas(BigDecimal balance) {
this.balance = new AtomicReference<>(balance);
}
@Override
public BigDecimal getBalance() {
return balance.get();
}
@Override
public void withdraw(BigDecimal amount) {
while (true) {
BigDecimal preVal = balance.get();
BigDecimal nextVal = preVal.subtract(amount);
if(balance.compareAndSet(preVal, nextVal)) {
break;
}
}
}
}
2) ABA problem
See the following code:
public static AtomicReference<String> ref = new AtomicReference<>("A");
public static void main(String[] args) throws InterruptedException {
log.debug("main start...");
String preVal = ref.get();
other();
TimeUnit.SECONDS.sleep(1);
log.debug("change A->C {}", ref.compareAndSet(preVal, "C"));
}
private static void other() throws InterruptedException {
new Thread(() -> {
log.debug("change A->B {}", ref.compareAndSet(ref.get(), "B"));
}, "t1").start();
TimeUnit.SECONDS.sleep(1);
new Thread(() -> {
log.debug("change B->A {}", ref.compareAndSet(ref.get(), "A"));
}, "t2").start();
}
The main thread can only judge whether the value of the shared variable is the same as the initial value a, and cannot perceive the situation of changing from a to B and back to A. if the main thread wants to: as long as other threads [have moved] the shared variable, its cas will fail. At this time, it is not enough to compare the value, and it needs to add another version number. Use AtomicStampedReference to solve the problem.
3)AtomicStampedReference
Use AtomicStampedReference plus stamp (version number or timestamp) to solve ABA problems. The code is as follows:
// Two parameters, the first: the value of the variable, and the second: the initial value of the version number
public static AtomicStampedReference<String> ref = new AtomicStampedReference<>("A", 0);
public static void main(String[] args) throws InterruptedException {
log.debug("main start...");
String preVal = ref.getReference();
int stamp = ref.getStamp();
log.info("main Get the version number {}",stamp);
other();
TimeUnit.SECONDS.sleep(1);
log.info("Modified version number {}",ref.getStamp());
log.info("change A->C:{}", ref.compareAndSet(preVal, "C", stamp, stamp + 1));
}
private static void other() throws InterruptedException {
new Thread(() -> {
int stamp = ref.getStamp();
log.info("{}",stamp);
log.info("change A->B:{}", ref.compareAndSet(ref.getReference(), "B", stamp, stamp + 1));
}).start();
TimeUnit.SECONDS.sleep(1);
new Thread(() -> {
int stamp = ref.getStamp();
log.info("{}",stamp);
log.debug("change B->A:{}", ref.compareAndSet(ref.getReference(), "A",stamp,stamp + 1));
}).start();
}
4)AtomicMarkableReference
AtomicStampedReference can add the version number to the atomic reference and track the whole change process of atomic reference, such as a - > b - > A - > C. through AtomicStampedReference, we can know that the reference variable has been changed several times in the middle. However, sometimes, I don't care about how many times the reference variable has been changed, but just whether it has been changed. Therefore, there is an AtomicMarkableReference.
5. Atomic array
Update an element in an array in an atomic way
AtomicIntegerArray: Shaping array atomic class AtomicLongArray: Long integer array atomic class AtomicReferenceArray : Reference type array atomic class
The methods provided by the above three classes are almost the same, so let's take AtomicIntegerArray as an example. The code is as follows:
public class Code_10_AtomicArrayTest {
public static void main(String[] args) throws InterruptedException {
/**
* The results are as follows:
* [9934, 9938, 9940, 9931, 9935, 9933, 9944, 9942, 9939, 9940]
* [10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000]
*/
demo(
() -> new int[10],
(array) -> array.length,
(array, index) -> array[index]++,
(array) -> System.out.println(Arrays.toString(array))
);
TimeUnit.SECONDS.sleep(1);
demo(
() -> new AtomicIntegerArray(10),
(array) -> array.length(),
(array, index) -> array.getAndIncrement(index),
(array) -> System.out.println(array)
);
}
private static <T> void demo(
Supplier<T> arraySupplier,
Function<T, Integer> lengthFun,
BiConsumer<T, Integer> putConsumer,
Consumer<T> printConsumer) {
ArrayList<Thread> ts = new ArrayList<>(); // Create collection
T array = arraySupplier.get(); // Get array
int length = lengthFun.apply(array); // Gets the length of the array
for(int i = 0; i < length; i++) {
ts.add(new Thread(() -> {
for (int j = 0; j < 10000; j++) {
putConsumer.accept(array, j % length);
}
}));
}
ts.forEach(Thread::start);
ts.forEach((thread) -> {
try {
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
printConsumer.accept(array);
}
}
6. Field Updater
AtomicReferenceFieldUpdater // Domain field AtomicIntegerFieldUpdater AtomicLongFieldUpdater
Note: using the Field updater, you can perform atomic operations on a Field of the object. It can only be used with volatile modified fields, otherwise exceptions will occur
Exception in thread "main" java.lang.IllegalArgumentException: Must be volatile type
The code is as follows:
public class Code_11_AtomicReferenceFieldUpdaterTest {
public static AtomicReferenceFieldUpdater ref =
AtomicReferenceFieldUpdater.newUpdater(Student.class, String.class, "name");
public static void main(String[] args) throws InterruptedException {
Student student = new Student();
new Thread(() -> {
System.out.println(ref.compareAndSet(student, null, "list"));
}).start();
System.out.println(ref.compareAndSet(student, null, "Zhang San"));
System.out.println(student);
}
}
class Student {
public volatile String name;
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
'}';
}
}
The field updater is to ensure the thread safety of a property in the class.
7. Atomic accumulator
1)AtomicLong Vs LongAdder
public static void main(String[] args) {
for(int i = 0; i < 5; i++) {
demo(() -> new AtomicLong(0), (ref) -> ref.getAndIncrement());
}
for(int i = 0; i < 5; i++) {
demo(() -> new LongAdder(), (ref) -> ref.increment());
}
}
private static <T> void demo(Supplier<T> supplier, Consumer<T> consumer) {
ArrayList<Thread> list = new ArrayList<>();
T adder = supplier.get();
// 4 threads, each accumulating 500000
for (int i = 0; i < 4; i++) {
list.add(new Thread(() -> {
for (int j = 0; j < 500000; j++) {
consumer.accept(adder);
}
}));
}
long start = System.nanoTime();
list.forEach(t -> t.start());
list.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
long end = System.nanoTime();
System.out.println(adder + " cost:" + (end - start)/1000_000);
}
After executing the code, it is found that using LongAdder is 2 or 3 times faster than AtomicLong. The reason for improving the performance of using LongAdder is very simple. When there is competition, set multiple accumulation units (but not exceeding the number of cpu cores), Therad-0 accumulates Cell[0], and Thread-1 accumulates Cell[1]... Finally summarize the results. In this way, they operate on different Cell variables when accumulating, thus reducing CAS retry failures and improving performance.
8. LongAdder principle
The LongAdder class has several key fields
public class LongAdder extends Striped64 implements Serializable {}
The following variables belong to Striped64 and are inherited by LongAdder.
// Accumulation cell array, lazy initialization transient volatile Cell[] cells; // Base value. If there is no competition, cas is used to accumulate this field transient volatile long base; // When cells are created or expanded, it is set to 1, indicating locking transient volatile int cellsBusy;
1) Using cas to implement a spin lock
public class Code_13_LockCas {
public AtomicInteger state = new AtomicInteger(0); // If the state value is 0, it means no lock, and 1 means lock
public void lock() {
while (true) {
if(state.compareAndSet(0, 1)) {
break;
}
}
}
public void unlock() {
log.debug("unlock...");
state.set(0);
}
public static void main(String[] args) {
Code_13_LockCas lock = new Code_13_LockCas();
new Thread(() -> {
log.info("begin...");
lock.lock();
try {
log.info("Lock successful");
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}, "t1").start();
new Thread(() -> {
log.info("begin...");
lock.lock();
try {
log.info("Lock successful");
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}, "t2").start();
}
}
2) Principle of pseudo sharing
Where Cell is the accumulation unit
// Prevent cache line pseudo sharing
@sun.misc.Contended
static final class Cell {
volatile long value;
Cell(long x) { value = x; }
// The most important method is used for cas accumulation. prev represents the old value and next represents the new value
final boolean cas(long prev, long next) {
return UNSAFE.compareAndSwapLong(this, valueOffset, prev, next);
}
// Omit unimportant code
}
Let's discuss @ sun misc. Significance of contented annotation
Let's start with cache. The speed of cache and memory is compared
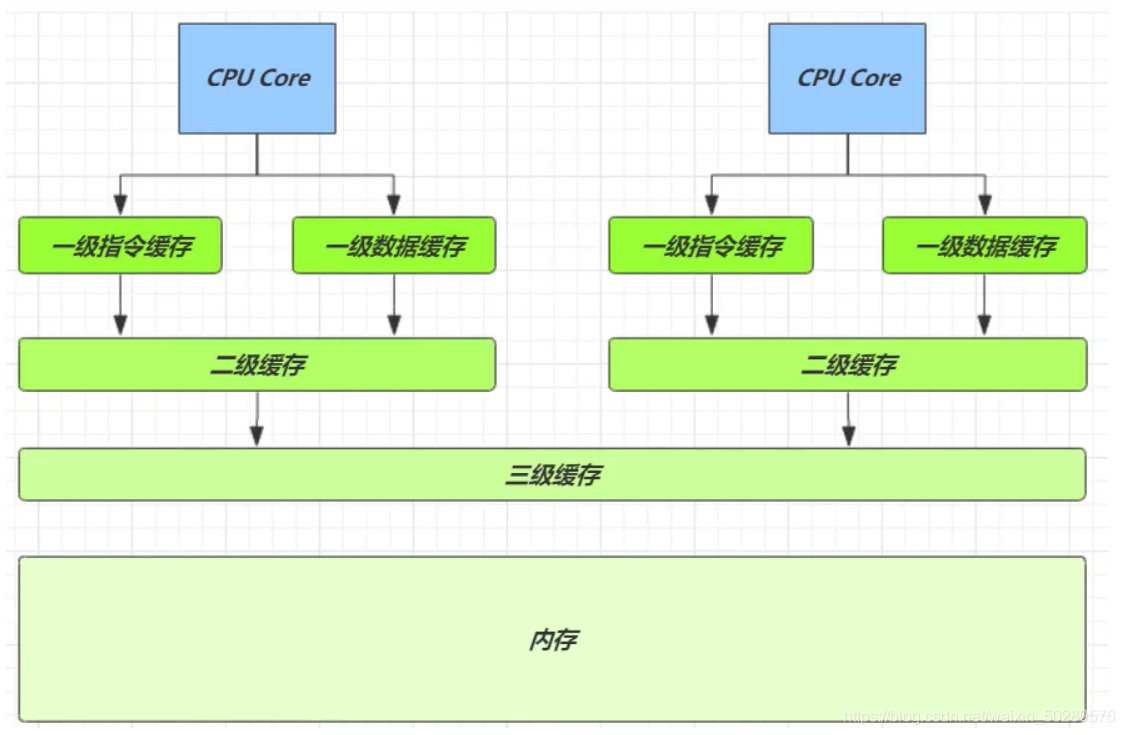 Because the speed of CPU and memory is very different, we need to read data to cache to improve efficiency. The closer the cache is to the CPU, the faster it will be. The cache is based on the cache behavior unit, and each cache line corresponds to a piece of memory, generally 64 byte s (8 long). The addition of cache will cause the generation of data copies, that is, the same data will be cached in cache lines of different cores. The CPU should ensure the consistency of data. If a CPU core changes data, the whole cache line corresponding to other CPU cores must be invalidated.
Because the speed of CPU and memory is very different, we need to read data to cache to improve efficiency. The closer the cache is to the CPU, the faster it will be. The cache is based on the cache behavior unit, and each cache line corresponds to a piece of memory, generally 64 byte s (8 long). The addition of cache will cause the generation of data copies, that is, the same data will be cached in cache lines of different cores. The CPU should ensure the consistency of data. If a CPU core changes data, the whole cache line corresponding to other CPU cores must be invalidated.
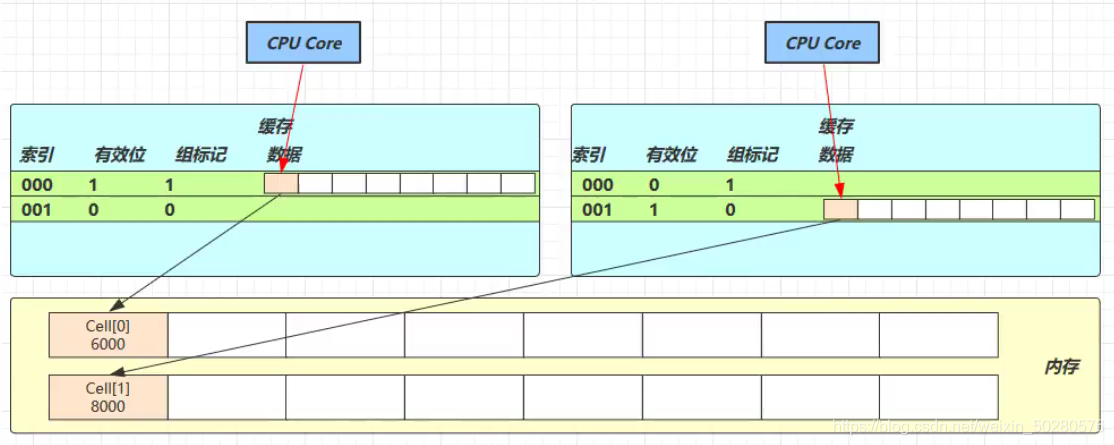
 Because cells are in array form and stored continuously in memory, one Cell is 24 bytes (16 bytes of object header and 8 bytes of value), so two Cell objects can be stored in the cache line. Here comes the problem: Core-0 needs to modify Cell[0], and Core-1 needs to modify Cell[1]
Because cells are in array form and stored continuously in memory, one Cell is 24 bytes (16 bytes of object header and 8 bytes of value), so two Cell objects can be stored in the cache line. Here comes the problem: Core-0 needs to modify Cell[0], and Core-1 needs to modify Cell[1]
No matter who modifies successfully, the cache line of the other Core will be invalidated. For example, in Core-0, cell [0] = 6000 and cell [1] = 8000 will accumulate cell [0] = 6001 and cell [1] = 8000. At this time, the cache line of Core-1 will be invalidated, @ sun misc. Contented is used to solve this problem. Its principle is to add 128 byte padding before and after the object or field using this annotation, so that the CPU can occupy different cache lines when pre reading the object to the cache. In this way, the cache lines of the other party will not be invalidated
3) add method analysis
The accumulation operation of LongAdder is to call the increment method, which in turn calls the add method.
public void increment() {
add(1L);
}
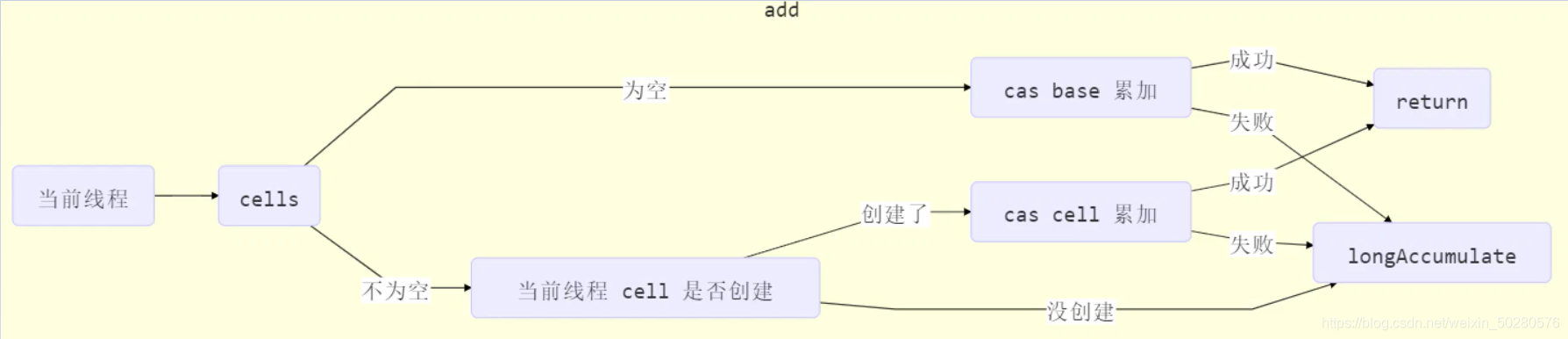
Step 1: add method analysis. The flow chart is as follows
 The source code is as follows:
The source code is as follows:
public void add(long x) {
// as is the accumulation cell array, b is the base value, and x is the accumulation value
Cell[] as; long b, v; int m; Cell a;
// Two conditions for entering if
// 1. as has a value, which indicates that competition has occurred and enters if
// 2. cas fails to accumulate base, which indicates that the base competes and enters if
// 3. If the as is not created, the cas is returned after successful accumulation, which is used when there is no thread competition in the base.
if ((as = cells) != null || !casBase(b = base, b + x)) {
// Uncompleted indicates whether there is competition in the cell. A value of true indicates there is competition
boolean uncontended = true;
if (
// as has not been created
as == null || (m = as.length - 1) < 0 ||
// The cell corresponding to the current thread has not been created. a is the cell of the current thread
(a = as[getProbe() & m]) == null ||
// Failed to accumulate the cells of the current thread. Uncontended = false (a is the cell of the current thread)
!(uncontended = a.cas(v = a.value, v + x))
) {
// When cells is empty, the method will be called if the accumulation operation fails,
// When the cells are not empty and the cells of the current thread are created, but the accumulation fails, the method will be called,
// This method will be called when the cells are not empty and the current thread cell is not created
// Enter the process of cell array creation and cell creation
longAccumulate(x, null, uncontended);
}
}
}
Step 2: analysis of longAccumulate method. The flow chart is as follows:

The source code is as follows:
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h;
// The current thread does not have a corresponding cell, so an h value needs to be randomly generated to bind the current thread to the cell
if ((h = getProbe()) == 0) {
// Initialize probe
ThreadLocalRandom.current();
// h corresponds to the new probe value, which is used to correspond to the cell
h = getProbe();
wasUncontended = true;
}
// If collapse is true, it means capacity expansion is required
boolean collide = false;
for (;;) {
Cell[] as; Cell a; int n; long v;
// There are already cells
if ((as = cells) != null && (n = as.length) > 0) {
// However, there is no cell corresponding to the current thread
if ((a = as[(n - 1) & h]) == null) {
// Lock cellsBusy and create a cell. The initial cumulative value of the cell is x
// break if successful, otherwise continue the continue cycle
if (cellsBusy == 0) { // Try to attach new Cell
Cell r = new Cell(x); // Optimistically create
if (cellsBusy == 0 && casCellsBusy()) {
boolean created = false;
try { // Recheck under lock
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
// Judge that the slot is indeed empty
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created)
break;
continue; // Slot is now non-empty
}
}
// If there is competition, change the cell corresponding to the thread to retry the cas
else if (!wasUncontended)
wasUncontended = true;
// cas tries to accumulate, fn with LongAccumulator is not null, and fn with LongAdder is null
else if (a.cas(v = a.value, ((fn == null) ? v + x : fn.applyAsLong(v, x))))
break;
// If the length of the cells has exceeded the maximum length or has been expanded, change the cell corresponding to the thread to retry the cas
else if (n >= NCPU || cells != as)
collide = false;
// Ensure that collapse is false. If you enter this branch, you will not enter the following else if for capacity expansion
else if (!collide)
collide = true;
// Lock
else if (cellsBusy == 0 && casCellsBusy()) {
// Successful locking, capacity expansion
continue;
}
// Change the cell corresponding to the thread
h = advanceProbe(h);
}
// There are no cells yet. Cells = = as means that no other thread modifies cells. As and cells refer to the same object. Use casCellsBusy() to try to lock cellsBusy
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
// Lock successfully, initialize cells, with the initial length of 2, and fill in a cell
// If successful, break;
boolean init = false;
try { // Initialize table
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
// The previous two cases failed. Try to use casBase accumulation for base
else if (casBase(v = base, ((fn == null) ? v + x : fn.applyAsLong(v, x))))
break;
}
}
4) sum method analysis
Get the final result. The sum method is used to add up the values of each accumulation unit to get the total result.
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
9,Unsafe
1) Get Unsafe object
Unsafe objects provide very low-level methods for operating memory and threads. Unsafe objects cannot be called directly, but can only be obtained through reflection. The park method of LockSupport and the underlying method of cas are implemented through the unsafe class.
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException {
// Unsafe uses the singleton pattern. The unsafe object is a private variable in the class
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
Unsafe unsafe = (Unsafe)theUnsafe.get(null);
}
2) Unsafe simulation to realize cas operation
public class Code_14_UnsafeTest {
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException {
// Create unsafe object
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
Unsafe unsafe = (Unsafe)theUnsafe.get(null);
// Get offset
long idOffset = unsafe.objectFieldOffset(Teacher.class.getDeclaredField("id"));
long nameOffset = unsafe.objectFieldOffset(Teacher.class.getDeclaredField("name"));
// Perform cas operation
Teacher teacher = new Teacher();
unsafe.compareAndSwapLong(teacher, idOffset, 0, 100);
unsafe.compareAndSwapObject(teacher, nameOffset, null, "lisi");
System.out.println(teacher);
}
}
@Data
class Teacher {
private volatile int id;
private volatile String name;
}
3) Implementation of atomic integer by Unsafe simulation
public class Code_15_UnsafeAccessor {
public static void main(String[] args) {
Account.demo(new MyAtomicInteger(10000));
}
}
class MyAtomicInteger implements Account {
private volatile Integer value;
private static final Unsafe UNSAFE = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = UNSAFE.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
public MyAtomicInteger(Integer value) {
this.value = value;
}
public Integer get() {
return value;
}
public void decrement(Integer amount) {
while (true) {
Integer preVal = this.value;
Integer nextVal = preVal - amount;
if(UNSAFE.compareAndSwapObject(this, valueOffset, preVal, nextVal)) {
break;
}
}
}
@Override
public Integer getBalance() {
return get();
}
@Override
public void withdraw(Integer amount) {
decrement(amount);
}
}
conclusion
This chapter focuses on
CAS And volatile
juc Bao Xia API
Atomic integer
Atomic reference
Atomic array
Field Updater
Atomic accumulator
Unsafe
Principle aspect
LongAdder Source code
Pseudo sharing
6, Immutability of shared model
1. Date conversion problem
The problem is that when the following code is running, because SimpleDateFormat is not thread safe, there is a great chance of Java. Com Lang.numberformatexception or incorrect date resolution result.
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
for (int i = 0; i < 10; i++) {
new Thread(() -> {
try {
log.debug("{}", sdf.parse("1951-04-21"));
} catch (Exception e) {
log.error("{}", e);
}
}).start();
}
Idea - immutable object
If an object cannot modify its internal state (properties), it is thread safe, because there is no concurrent modification! There are many such objects in Java. For example, after Java 8, a new date formatting class DateTimeFormatter is provided
DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy-MM-dd");
for (int i = 0; i < 10; i++) {
new Thread(() -> {
LocalDate date = dtf.parse("2018-10-01", LocalDate::from);
log.debug("{}", date);
}).start();
}
2. Immutable design
Immutable representation in String class
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
// ...
}
1) Use of final
It is found that the class and all attributes in the class are "nal"
Attribute use final Modification ensures that the property is read-only and cannot be modified Class use final Modification ensures that the methods in this class cannot be overridden, preventing subclasses from inadvertently destroying immutability
2) Protective copy
However, some students will say that when using strings, there are also some methods related to modification, such as substring. Let's take substring as an example:
public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > value.length) {
throw new StringIndexOutOfBoundsException(endIndex);
}
int subLen = endIndex - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
// The above is some verification, and the following is the real creation of a new String object
return ((beginIndex == 0) && (endIndex == value.length)) ? this
: new String(value, beginIndex, subLen);
}
It is found that the constructor of String is called to create a new String
public String(char value[], int offset, int count) {
if (offset < 0) {
throw new StringIndexOutOfBoundsException(offset);
}
if (count <= 0) {
if (count < 0) {
throw new StringIndexOutOfBoundsException(count);
}
if (offset <= value.length) {
this.value = "".value;
return;
}
}
// Note: offset or count might be near -1>>>1.
if (offset > value.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
// The above is some security verification. The following is to assign a value to the String object. A new array is created to save the value of the String object
this.value = Arrays.copyOfRange(value, offset, offset+count);
}
When constructing a new string object, a new char[] value will be generated to copy the content. This method of avoiding sharing by creating replica objects is called [protective copy]
3. Mode sharing element
1) Introduction
English name of introduction definition: Flyweight pattern When a limited number of objects of the same class need to be reused, they are classified as structural patterns
2) Reflect
Packaging
In JDK, wrapper classes such as Boolean, Byte, Short, Integer, Long and Character provide valueOf methods.
For example, valueOf of Long caches Long objects between - 128 and 127, and reuses objects in this range. If the range is greater than this range, Long objects will be created:
public static Long valueOf(long l) {
final int offset = 128;
if (l >= -128 && l <= 127) { // will cache
return LongCache.cache[(int)l + offset];
}
return new Long(l);
}
The range of byte, short and long caches is - 128 ~ 127
The range of Character cache is 0 ~ 127
The default range of Integer is - 128 ~ 127. The minimum value cannot be changed, but the maximum value can be changed by adjusting the virtual machine parameter "- Djava.lang.Integer.IntegerCache.high"
Boolean caches TRUE and FALSE
3) DIY implements a simple database connection pool
For example, an online mall application has thousands of QPS. If the database connection is re created and closed every time, the performance will be greatly affected. At this time, create a batch of connections in advance and put them into the connection pool. After a request arrives, the connection is obtained from the connection pool and returned to the connection pool after use, which not only saves the creation and closing time of the connection, but also realizes the reuse of the connection, so as not to let the huge number of connections crush the database.
The code implementation is as follows:
public class Code_17_DatabaseConnectionPoolTest {
public static void main(String[] args) {
Pool pool = new Pool(2);
for(int i = 0; i < 5; i++) {
new Thread(() -> {
Connection connection = pool.borrow();
try {
Thread.sleep(new Random().nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
pool.free(connection);
}).start();
}
}
}
@Slf4j(topic = "c.Pool")
class Pool {
// The size of the connection pool. Because there is no expansion of the connection pool size, final indicates that the pool size is a fixed value.
private final int poolSize;
// Connection pool
private Connection[] connections;
// Indicates the connection status. If it is 0, it means there is no connection, and 1 means there is a connection
private AtomicIntegerArray status;
// Initialize connection pool
public Pool(int poolSize) {
this.poolSize = poolSize;
status = new AtomicIntegerArray(new int[poolSize]);
connections = new Connection[poolSize];
for(int i = 0; i < poolSize; i++) {
connections[i] = new MockConnection("connect" + (i + 1));
}
}
// Get connection from connection pool
public Connection borrow() {
while (true) {
for(int i = 0; i < poolSize; i++) {
if(0 == status.get(i)) {
if(status.compareAndSet(i,0, 1)) {
log.info("Get connection:{}", connections[i]);
return connections[i];
}
}
}
synchronized (this) {
try {
log.info("wait ...");
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
// Releases the specified connection from the connection pool
public void free(Connection connection) {
for (int i = 0; i < poolSize; i++) {
if(connections[i] == connection) {
status.set(i, 0);
log.info("Release connection:{}", connections[i]);
synchronized (this) {
notifyAll();
}
}
}
}
}
class MockConnection implements Connection {
private String name;
public MockConnection(String name) {
this.name = name;
}
@Override
public String toString() {
return "MockConnection{" +
"name='" + name + '\'' +
'}';
}
}
The above implementation does not consider:
Dynamic growth and contraction of connectivity Connection keep alive (availability test) Wait for timeout processing Distributed hash
For relational database, there is a mature implementation of connection pool, such as c3p0, druid, etc
For more general object pools, you can consider using apache commons pool. For example, redis connection pool, you can refer to the implementation of connection pool in jedis
4. Principle of final
1) How to set the final variable
After understanding the volatile principle, it is easier to compare the implementation of final
public class TestFinal {
final int a = 20;
}
Bytecode
0: aload_0 1: invokespecial #1 // Method java/lang/Object."<init>":()V 4: aload_0 5: bipush 20 7: putfield #2 // Field a:I <-- Write barrier 10: return
The assignment of the final variable must be initialized at the time of definition or in the constructor. It is found that the assignment of the final variable will also be completed through the putfield instruction. Similarly, a write barrier will be added after this instruction to ensure that it will not appear as 0 when other threads read its value.
2) How to get the final variable
conclusion
Use of immutable classes
Immutable class design
Principle: final
Mode aspect
Sharing element mode-> Set thread pool