java Concurrent Programming Practice

 77
77
java Concurrent Programming Practice
catalogue
java Concurrent Programming Practice
2 avoid passing some parameters
Principle of ThreadLocal implementation
Summary of ThreadLocal principle
2.4 parallelism and concurrency
2.5.1 inherit Thread and rewrite run method
2.5.2 implement the Runnable interface and rewrite the run method
2.6 details of Java multithreading
4 the first four chapters of the book "Java Concurrent Programming Practice"
1, Problems encountered using multithreading
2, Publishing and escaping of objects
3, Solve problems encountered by multithreading
3.1 briefly describe the solution to thread safety
1.1 what is a synchronized lock?
1.2 what is the use of synchronized?
2.1 brief introduction to lock explicit lock
2.2 which is used for synchronized Lock or Lock lock
2.1 reentrantreadwritelock internal class
2.2 status indication of read lock and write lock
1.2 dynamic lock sequence deadlock
1.3 deadlock between collaboration objects
2.1 fixed lock sequence to avoid deadlock
2.2 open call to avoid deadlock
9 synchronization tools (auxiliary)
1.1 introduction to countdownlatch

1 ThreadLocal is that simple
Implementation of database connection pool
jdbc connects to the database as follows:
Class.forName("com.mysql.jdbc.Driver");
java.sql.Connection conn = DriverManager.getConnection(jdbcUrl);Note: a drivermanager Getconnection (JDBC URL) is only a connection, which can not meet the high concurrency situation. Because a connection is not thread safe, a connection corresponds to a thing.
Every time you get a connection, you need to waste cpu resources and memory resources, which is a waste of resources. So the database connection pool was born. The implementation principle of database connection pool is as follows:
pool.getConnection(),All from threadlocal Inside, if threadlocal If there is, use it, Ensure multiple in the thread dao Operation, using the same connection,To ensure business. If a new thread, The new connection Put on threadlocal Inside, again get To the thread.
Put the connection into the threadlocal to ensure that each thread obtains its own connection from the connection pool.
Suppose there is such a database link management class. There is no problem in using this code in a single thread, but what if it is used in multiple threads? Obviously, there will be thread safety problems when used in multithreading: first, the two methods are not synchronized, and it is likely that connect will be created many times in the openConnection method; Second, since connect is a shared variable, synchronization must be used where connect is called to ensure thread safety, because it is likely that one thread is using connect for database operations and another thread calls closeConnection to close the link.
Therefore, for the sake of thread safety, the two methods of this code must be synchronized, and synchronization is required where connect is called.
This will greatly affect the efficiency of program execution, because when one thread uses connect for database operation, other threads have to wait.
So let's carefully analyze this problem. Does this place need to share the connect variable? In fact, it is unnecessary. If there is a connect variable in each thread, the access to the connect variable between threads actually has no dependency, that is, a thread does not need to care whether other threads have modified the connect.
1, What is ThreadLocal
First, let's take a look at the document introduction of JDK:
/**
* This class provides thread-local variables. These variables differ from
* their normal counterparts in that each thread that accesses one (via its
* {@code get} or {@code set} method) has its own, independently initialized
* copy of the variable. {@code ThreadLocal} instances are typically private
* static fields in classes that wish to associate state with a thread (e.g.,
* a user ID or Transaction ID).
*
* <p>For example, the class below generates unique identifiers local to each
* thread.
* A thread's id is assigned the first time it invokes {@code ThreadId.get()}
* and remains unchanged on subsequent calls.
*/ Combined with my summary, it can be understood as follows: ThreadLocal provides thread local variables. Each thread can operate on this local variable through set() and get(), but it will not conflict with the local variables of other threads, realizing thread data isolation ~.
In short: the variable filled into ThreadLocal belongs to the current thread and is isolated from other threads.
2, Why learn ThreadLocal?
It can be concluded from the above: ThreadLocal can let us have the variables of the current thread. What's the use of this function???
1 Manage Connection s
The most typical is the Connection to manage the database: when learning JDBC at that time, a simple database Connection pool was written for convenient operation. The reason why the database Connection pool is needed is also very simple. Frequently creating and closing connections is a very resource-consuming operation, so it is necessary to create a database Connection pool ~
Then, how to manage the Connection of database Connection pool?? We leave it to ThreadLocal for management. Why leave it to it to manage?? ThreadLocal can realize that the operation of the current thread uses the same Connection to ensure the transaction!
public class DBUtil {
//Database connection pool
private static BasicDataSource source;
//Manage connections for different threads
private static ThreadLocal<Connection> local;
static {
try {
//Load profile
Properties properties = new Properties();
//Get read stream
InputStream stream = DBUtil.class.getClassLoader().getResourceAsStream("Connection pool/config.properties");
//Read data from configuration file
properties.load(stream);
//Flow closure
stream.close();
//Initialize connection pool
source = new BasicDataSource();
//Set drive
source.setDriverClassName(properties.getProperty("driver"));
//Set url
source.setUrl(properties.getProperty("url"));
//Set user name
source.setUsername(properties.getProperty("user"));
//Set password
source.setPassword(properties.getProperty("pwd"));
//Set the number of initial connections
source.setInitialSize(Integer.parseInt(properties.getProperty("initsize")));
//Set the maximum number of connections
source.setMaxActive(Integer.parseInt(properties.getProperty("maxactive")));
//Set the maximum waiting time
source.setMaxWait(Integer.parseInt(properties.getProperty("maxwait")));
//Set minimum idle number
source.setMinIdle(Integer.parseInt(properties.getProperty("minidle")));
//Initialize thread local
local = new ThreadLocal<>();
} catch (IOException e) {
e.printStackTrace();
}
}
public static Connection getConnection() throws SQLException {
//Get Connection object
Connection connection = source.getConnection();
//Put the Connection into ThreadLocal
local.set(connection);
//Return Connection object
return connection;
}
//Close database connection
public static void closeConnection() {
//Get the Connection object from the thread
Connection connection = local.get();
try {
if (connection != null) {
//Restore connection to auto commit
connection.setAutoCommit(true);
//The connection is not really closed here, but returned to the connection pool
connection.close();
//Now that the connection has been returned to the connection pool, the connection object saved by ThreadLocal is useless
local.remove();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
2 avoid passing some parameters
For the understanding of avoiding the transmission of some parameters, please refer to Cookie and Session:
-
Whenever I visit a page, the browser will help us find the corresponding Cookie from the hard disk and send it.
-
The browser is very smart. It will not send cookies from other websites in the past, but only take the cookies published by the current website in the past
The browser is equivalent to our ThreadLocal. It will only send cookies (local variables of ThreadLocal) that exist in our current browser. Different browsers are isolated from cookies (cookies of Chrome, opera and ie are isolated [log in in in Chrome, and you have to log in again in IE]). Similarly, ThreadLocal variables between threads are also isolated
Does it avoid the transfer of parameters?? It's actually avoided. Cookies are not passed manually. We don't need to write < input name = Cookie / > to pass parameters
It's the same in writing the program: in our daily business, we may use ID cards and all kinds of certificates in many places. It's very troublesome for us to take them out every time
// When consulting, you should use ID card, student card, real estate card, etc
public void consult(IdCard idCard,StudentCard studentCard,HourseCard hourseCard){
}
// You should also use your ID card , Student ID , House property certificate, etc
public void manage(IdCard idCard,StudentCard studentCard,HourseCard hourseCard) {
}
//......</code></pre>
If ThreadLocal is used, ThreadLocal is equivalent to an organization. ThreadLocal organization makes records and you have so many certificates. You don't have to pay yourself when you use it. Just ask the organization to get it.
When consulting, I told the organization: come on, give him my ID card, real estate card and student card. When handling, he told the organization: come on, give him my ID card, real estate card and student card
// When consulting, you should use ID card, student card, real estate card, etc
public void consult(){
threadLocal.get();
}
// You should also use your ID card , Student ID , House property certificate, etc
public void takePlane() {
threadLocal.get();
}</code></pre>
Principle of ThreadLocal implementation
First, let's take a look at the set() method of ThreadLocal, because we usually use the new object to set the object inside
public void set(T value) {
// Get the current thread object
Thread t = Thread.currentThread();
// Get ThreadLocalMap here
ThreadLocalMap map = getMap(t);
// If map exists , Then take the current thread object t as the key, The object to be stored is stored in the map as value
if (map != null)
map.set(this, value);
else
createMap(t, value);
}</code></pre>
There is a ThreadLocalMap on it. Let's go and see what it is?
static class ThreadLocalMap {
/**
* The entries in this hash map extend WeakReference, using
* its main ref field as the key (which is always a
* ThreadLocal object). Note that null keys (i.e. entry.get()
* == null) mean that the key is no longer referenced, so the
* entry can be expunged from table. Such entries are referred to
* as "stale entries" in the code that follows.
*/
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
//.... Very long
}
From the above, we can find that ThreadLocalMap is an internal class of ThreadLocal. Use the Entry class for storage
Our values are stored in this Map, and the key is the current ThreadLocal object!
If the Map does not exist, initialize a:
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
If the Map exists, get it from Thread!
/**
* Get the map associated with a ThreadLocal. Overridden in
* InheritableThreadLocal.
*
* @param t the current thread
* @return the map
*/
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
Thread maintains the ThreadLocalMap variable
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = nullIt can be seen from the above that ThreadLocalMap is written in ThreadLocal using internal classes, but the reference of the object is in Thread!
So we can conclude that Thread maintains ThreadLocalMap for each Thread, and the key of ThreadLocalMap is the LocalThread object itself, and the value is the object to be stored
With the above foundation, it is not difficult to understand the get() method:
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}Summary of ThreadLocal principle
-
Each Thread maintains a reference to ThreadLocalMap
-
ThreadLocalMap is the internal class of ThreadLocal, which is stored with Entry
-
When calling the set() method of ThreadLocal, you actually set the value to ThreadLocalMap. The key is the ThreadLocal object and the value is the object passed in
-
When you call the get() method of ThreadLocal, you actually get the value from ThreadLocalMap. The key is the ThreadLocal object
-
The thread itself is not a local value, but a thread value.
4, Avoid memory leaks
Let's take a look at the object relationship reference diagram of ThreadLocal:
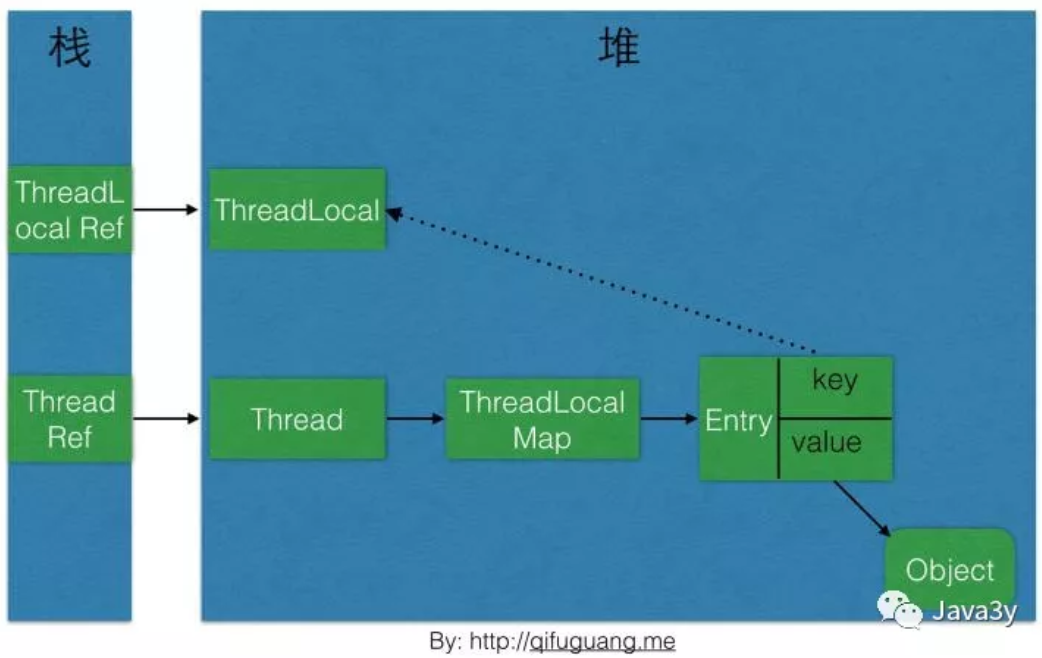
The root cause of ThreadLocal memory leak is: because the life cycle of ThreadLocalMap is as long as Thread, if the corresponding key is not manually deleted, it will lead to memory leak, not weak reference.
If you want to avoid memory leakage, you need to manually remove()!
5, Summary
ThreadLocal is designed to have its own variables in the current thread, not to solve the problem of concurrency or shared variables
Reference blog:
-
http://blog.xiaohansong.com/2016/08/06/ThreadLocal-memory-leak/
-
https://www.cnblogs.com/zhangjk1993/archive/2017/03/29/6641745.html#_label2
-
http://www.cnblogs.com/dolphin0520/p/3920407.html
-
http://www.cnblogs.com/dolphin0520/p/3920407.html
-
http://www.iteye.com/topic/103804
-
https://www.cnblogs.com/xzwblog/p/7227509.html
-
https://blog.csdn.net/u012834750/article/details/71646700
-
https://blog.csdn.net/winwill2012/article/details/71625570
-
https://juejin.im/post/5a64a581f265da3e3b7aa02d
2 multithreading
2.1 introduction process
When it comes to threads, I have to mention processes again~
We probably know the process very well. When we open the task manager under windows, we can find that the programs running on the operating system are all processes:
Definition of process:
A process is an execution of a program. A process is an activity that occurs when a program and its data are executed sequentially on the processor. A process is a process in which a program with independent functions runs on a data set. It is an independent unit of the system for resource allocation and scheduling.
Process is an independent unit for system resource allocation and scheduling. Each process has its own memory space and system resources.
2.2 back to thread
The system has the concept of process. The process can allocate and schedule resources. Why do you need threads?
In order to make the program execute concurrently, the system must carry out the following series of operations:
-
(1) Create a process. When the system creates a process, it must allocate all the necessary resources except the processor, such as memory space, I/O equipment, and establish the corresponding PCB;
-
(2) Undo the process. When the system cancels the process, it must first recycle the resources it occupies, and then undo the PCB;
-
(3) Process switching: when switching the context of a process, you need to keep the CPU environment of the current process and set the CPU environment of the newly selected process, so it takes a lot of processor time.
It can be seen that the process scheduling, dispatching and switching in the multiprocessor environment need to spend a lot of time and space
The introduction of threads is mainly to improve the execution efficiency of the system, reduce the idle time of the processor and the time of scheduling switching, and facilitate system management. Make the OS have better concurrency
-
To put it simply: the implementation of multiprocessing in a process consumes CPU resources, and we introduce threads as the basic unit of scheduling and dispatching (replacing some of the basic functions of the process [scheduling]).
So where is the thread?? for instance:
In other words, multiple tasks can be executed in the same process, and I can see that each task is a thread.
-
So: a process will have one or more threads!
2.3 process and thread
So we can conclude:
-
Process is the basic unit of resource allocation
-
As the basic unit of resource scheduling, thread is the execution unit and execution path of the program (single thread: one execution path, multi thread: multiple execution paths). It is the most basic unit of CPU used by programs.
Threads have three basic states:
-
Execute, ready, blocked
Threads have five basic operations:
-
Derive, block, activate, schedule, end
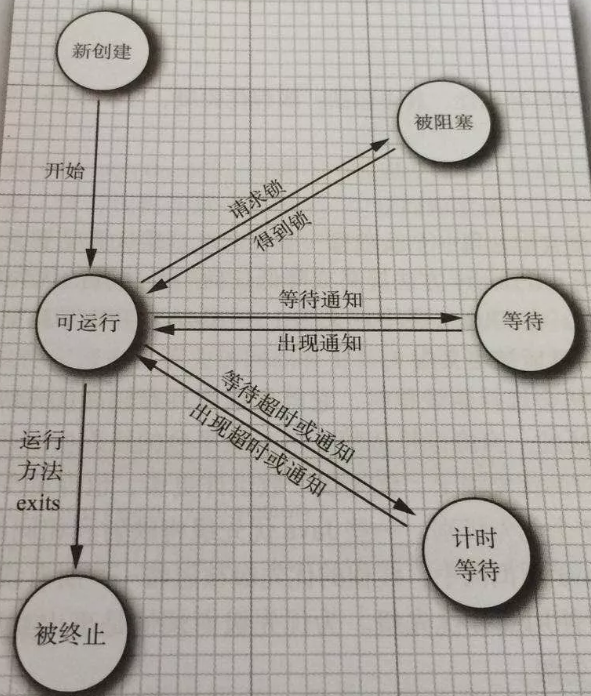
Scheduling: process is the smallest unit of resource allocation, and thread is the smallest unit of program execution. In the same process, thread switching will not cause process switching. Thread switching in different processes will cause process switching.
Owning resources: the process is the basic unit of owning resources. Threads do not own resources (there are also some essential resources), but threads can share the system resources of their subordinate processes.
System overhead: when the operating system creates or cancels a process, the system must allocate or recycle resources for it, such as memory resources, I/O devices, etc., which is much greater than the overhead of creating or canceling threads.
Address space and other resources: the address space of the process is independent of each other. The resources of the process are shared among the threads of the same process. The threads in a process are not accessible to other processes.
Communication: interprocess communication needs the help of the operating system, and threads can directly read / write process data segments.
Thread properties:
-
1) Light entities;
-
2) Basic unit of independent dispatching and dispatch;
-
3) Executable concurrently;
-
4) Share process resources.
There are two basic types of threads:
-
1) User level thread: the management process is completed by the user program, and the core of the operating system only manages the process.
-
2) Thread level: managed by the kernel operating system. The operating system kernel provides the corresponding system call and application program interface API to the application program, so that the user program can create, execute and undo threads.
It is worth noting that the existence of multithreading is not to improve the execution speed of the program. In fact, it is to improve the utilization rate of the application. The execution of the program is actually robbing the CPU resources and the execution right of the CPU. Multiple processes are grabbing this resource, and if one of them has more execution paths, it will have a higher chance to grab the execution right of the CPU.
2.4 parallelism and concurrency
Parallel:
-
Parallelism refers to the occurrence of two or more events at the same time.
-
Parallelism is multiple events on different entities
Concurrency:
-
Concurrency refers to the occurrence of two or more events within the same time interval.
-
Concurrency is multiple events on the same entity
It can be seen that parallelism is for processes and concurrency is for threads.
2.5 multithreading in Java
It says a lot of basic and understood words. Let's go back to Java and see how Java implements multithreading~
The Thread class is used to implement multithreading in Java. Let's take a look at the top annotation of the Thread class:
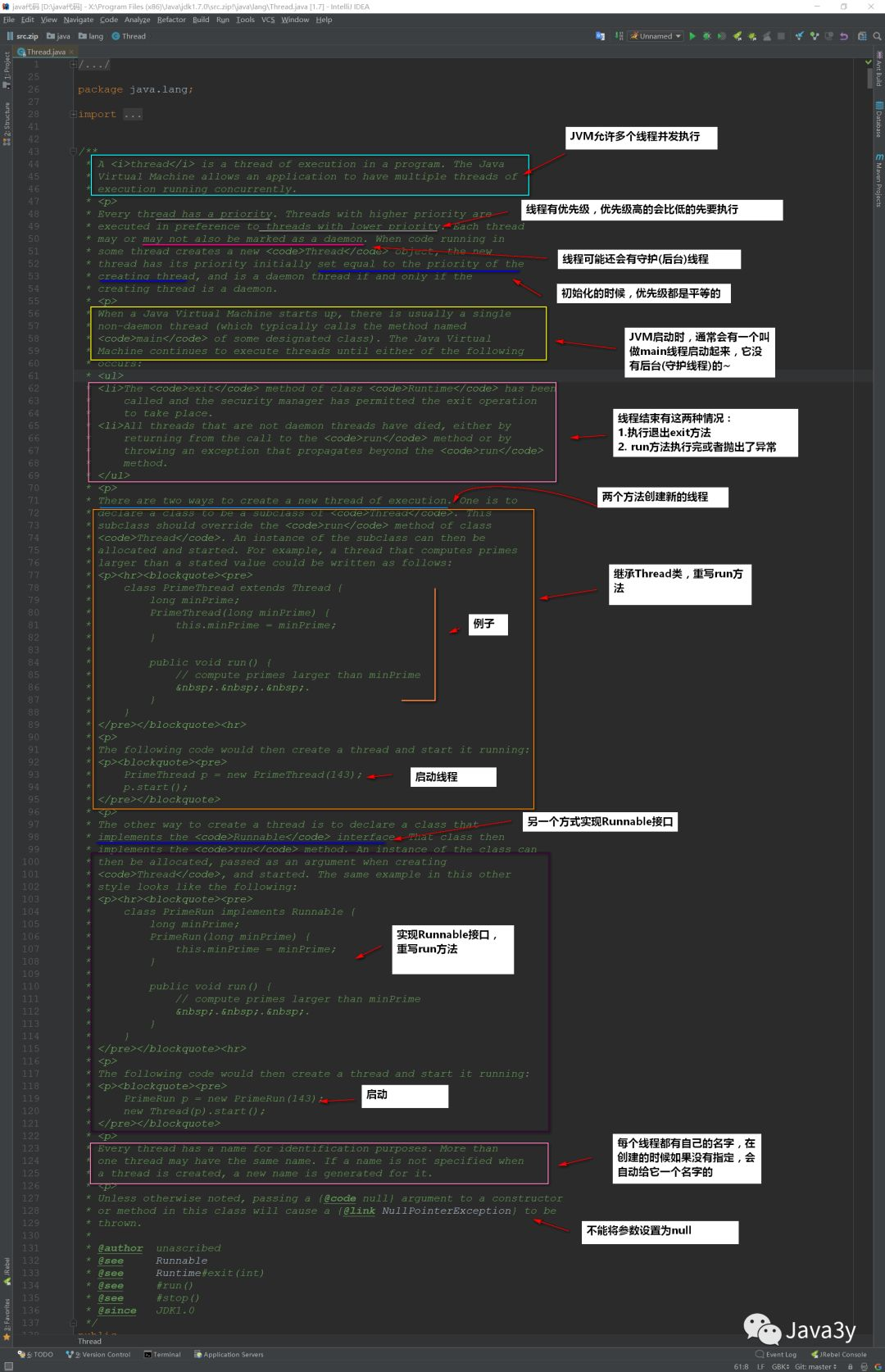
From the top note above, we can see that there are two ways to create multithreading:
-
Inherit Thread and override run method
-
Implement the Runnable interface and rewrite the run method
2.5.1 inherit Thread and rewrite run method
Create a class, inherit Thread and override run method
public class MyThread extends Thread {
@Override
public void run() {
for (int x = 0; x < 200; x++) {
System.out.println(x);
}
}
}
Let's call the test to see:
public class MyThreadDemo {
public static void main(String[] args) {
// Create two thread objects
MyThread my1 = new MyThread();
MyThread my2 = new MyThread();
my1.start();
my2.start();
}
}

2.5.2 implement the Runnable interface and rewrite the run method
Implement the Runnable interface and rewrite the run method
public class MyRunnable implements Runnable {
@Override
public void run() {
for (int x = 0; x < 100; x++) {
System.out.println(x);
}
}
}
Let's call the test to see:
public class MyRunnableDemo {
public static void main(String[] args) {
// Create an object of the MyRunnable class
MyRunnable my = new MyRunnable();
Thread t1 = new Thread(my);
Thread t2 = new Thread(my);
t1.start();
t2.start();
}
}
The result is the same as above
https://blog.csdn.net/weixin_41563161/article/details/104812379 difference
2.6 details of Java multithreading
Don't confuse run() with start()~
The differences between run() and start() methods are as follows:
-
run(): it just encapsulates the code executed by the thread. Direct call is a common method
-
start(): the thread is started first, and then the jvm calls the run() method of the thread.
Is the startup of jvm virtual machine single threaded or multi-threaded?
-
Is multithreaded. Not only start the main thread, but also at least start the garbage collection thread. Who else can help you recycle unused memory~
So, since there are two ways to implement multithreading, which one do we use???
Generally, we use the Runnable interface
-
It can avoid the limitation of singleton inheritance in java
-
Concurrent running tasks should be decoupled from the running mechanism, so we choose to implement the Runnable interface!
3 Thread source code analysis
1, Thread thread class API
Multithreading is essentially operated by thread class ~ let's take a look at some important knowledge points of thread class. Thread is a very large class. It's impossible to see it all. We can only see some common and important methods.
1.1 setting thread name
When using multithreading, it is very simple to check the thread name and call thread currentThread(). Getname().
If no settings are made, we will find that the name of the thread is like this: the main thread is called main, and other threads are Thread-x
Let me show you how it is named:

The method implementation of nextThreadNum() is as follows:

Based on such a variable -- > the number of thread initializations

Click in and see the init method to determine:

See here, if we want to give a name to the thread, it is also very simple. Thread provides us with a construction method!
Let's test:
-
The method of Runnable is implemented to realize multithreading:
Test:
result:
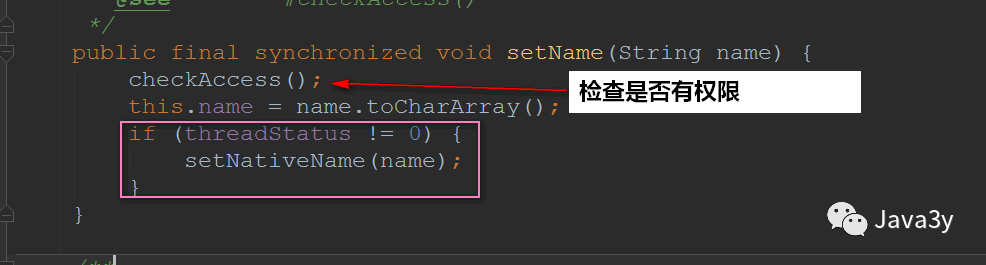
Of course, we can also change the name of the thread through the method of setName(String name). Let's look at the method implementation;
Check whether you have permission to modify:
1.2 daemon thread
Daemon threads serve other threads
-
Garbage collection threads are daemon threads~
Daemon threads have one feature:
-
When other user threads finish executing, the virtual machine will exit and the daemon thread will be stopped.
-
In other words, as a service thread, the daemon thread does not need to continue running without a service object
What to pay attention to when using threads
-
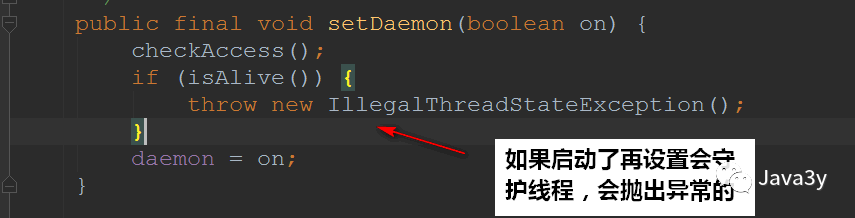
Set the thread as a daemon thread before starting. The method is setDaemon(boolean on)
-
Using a daemon thread, do not access shared resources (databases, files, etc.) because it may hang up at any time.
-
The new thread generated in the daemon thread is also a daemon thread
Test wave:
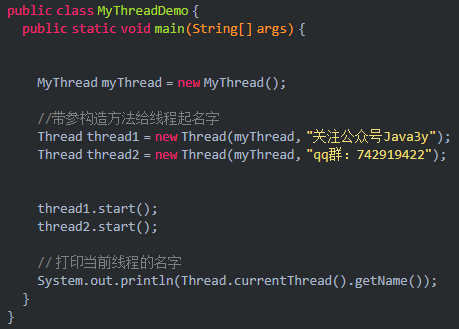
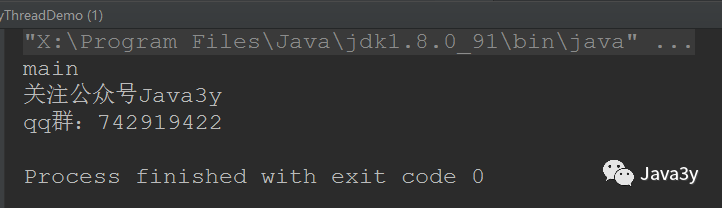
public class MyThreadDemo {
public static void main(String[] args) {
MyThread myThread = new MyThread();
//The parameter constructor names the thread
Thread thread1 = new Thread(myThread, "Official account Java3y");
Thread thread2 = new Thread(myThread, "qq group:742919422");
// Set as daemon thread
thread2.setDaemon(true);
thread1.start();
thread2.start();
System.out.println(Thread.currentThread().getName());
}
}
The above code can appear many times (students with good computer performance may not be able to test it): after thread 1 and the main thread are executed, our guard thread will not be executed~
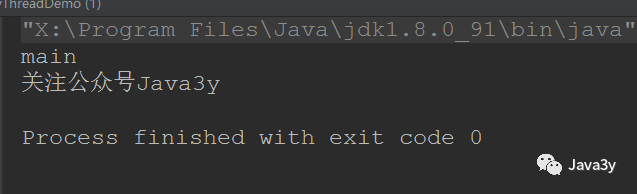
Principle: that's why we need to set the daemon thread before starting.
1.3 priority thread
High thread priority only means that the thread has a high probability of obtaining CPU time slices, but this is not a definite factor!
The priority of threads is highly dependent on the operating system. There is a difference between Windows and Linux (the priority under Linux may be ignored)~
It can be seen that the priority provided by Java is 5 by default, the lowest is 1 and the highest is 10:
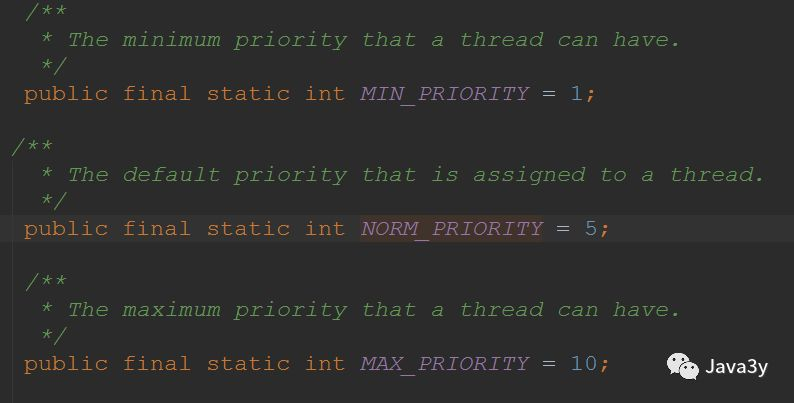
realization:
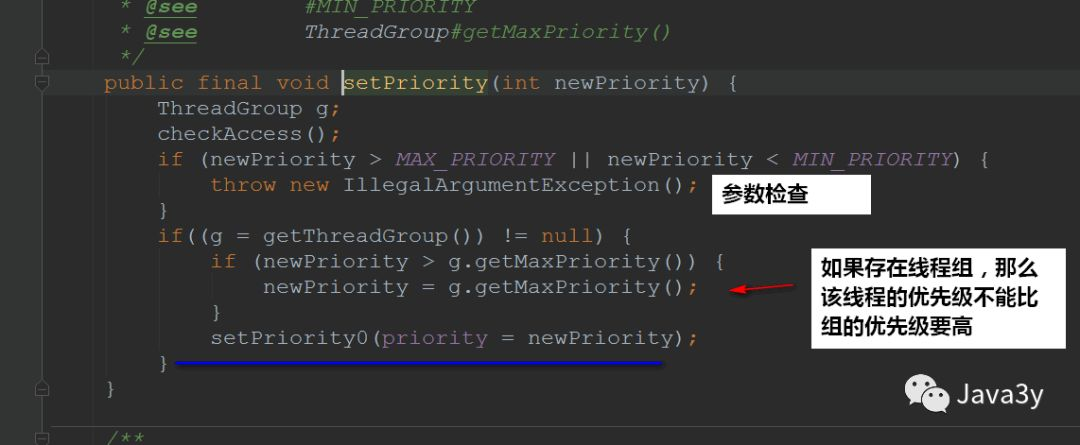
setPriority0 is a Navite method:
private native void setPriority0(int newPriority);
sleep method
Calling the sleep method will enter the timing waiting state. When the time comes, it will enter the ready state rather than the running state!
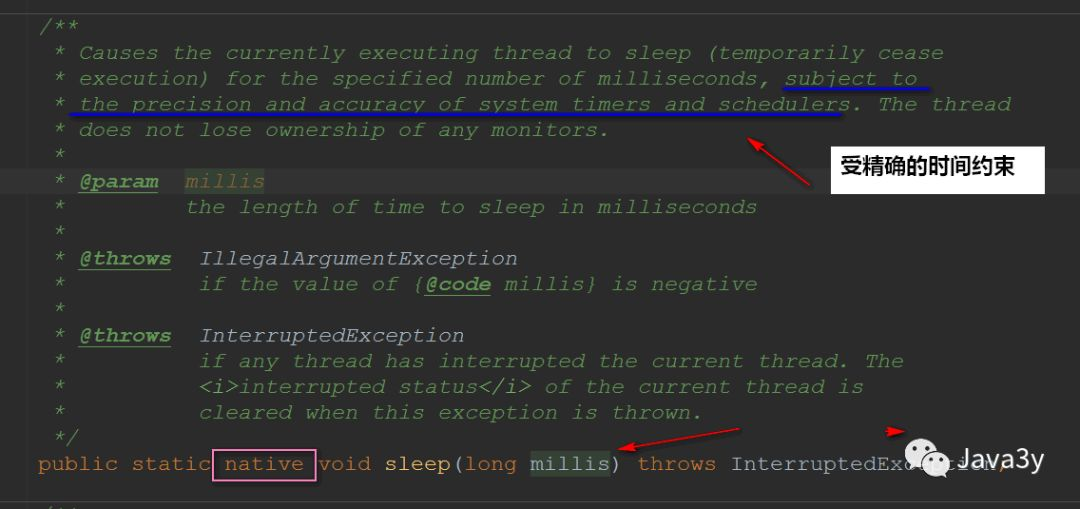
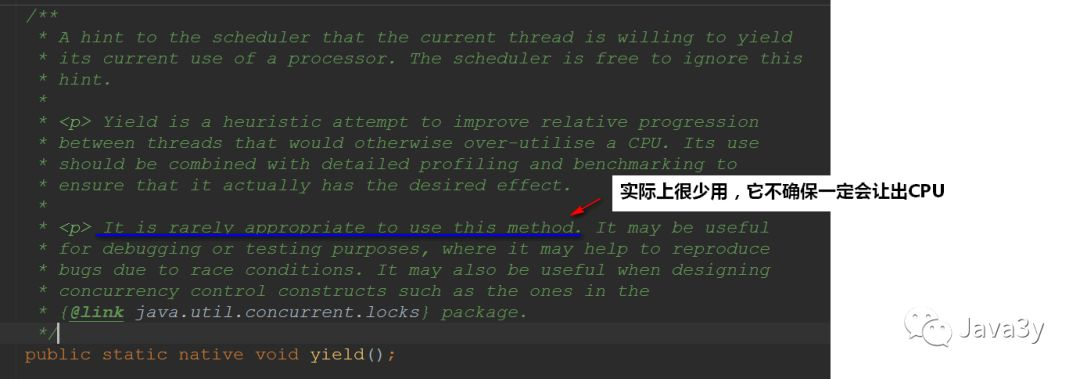
yield method
Calling the yield method will let other threads execute first, but it does not ensure that it is really surrendered
-
I'm free. If I can, I'll let you do it first
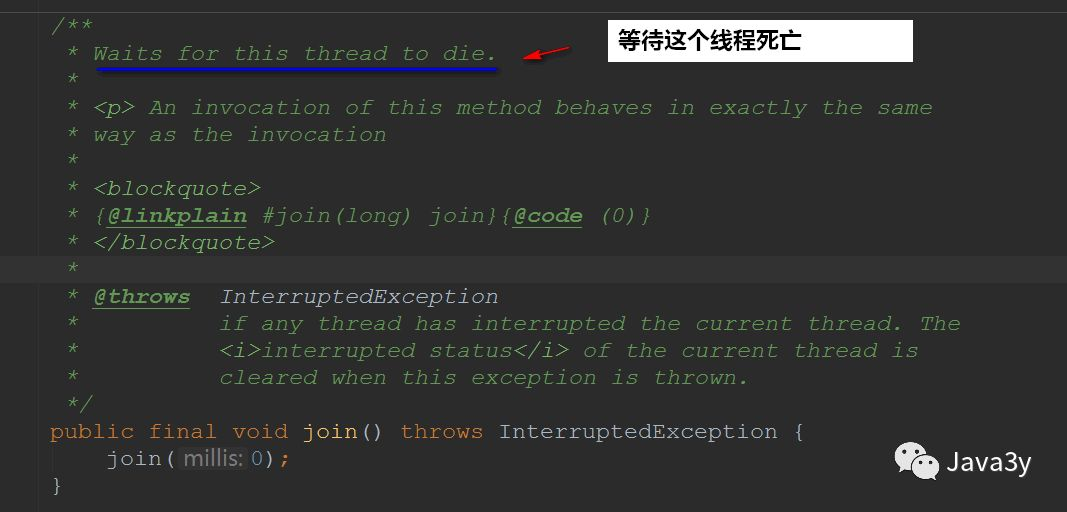
join method
When you call the join method, you will wait for the thread to execute before executing other threads~
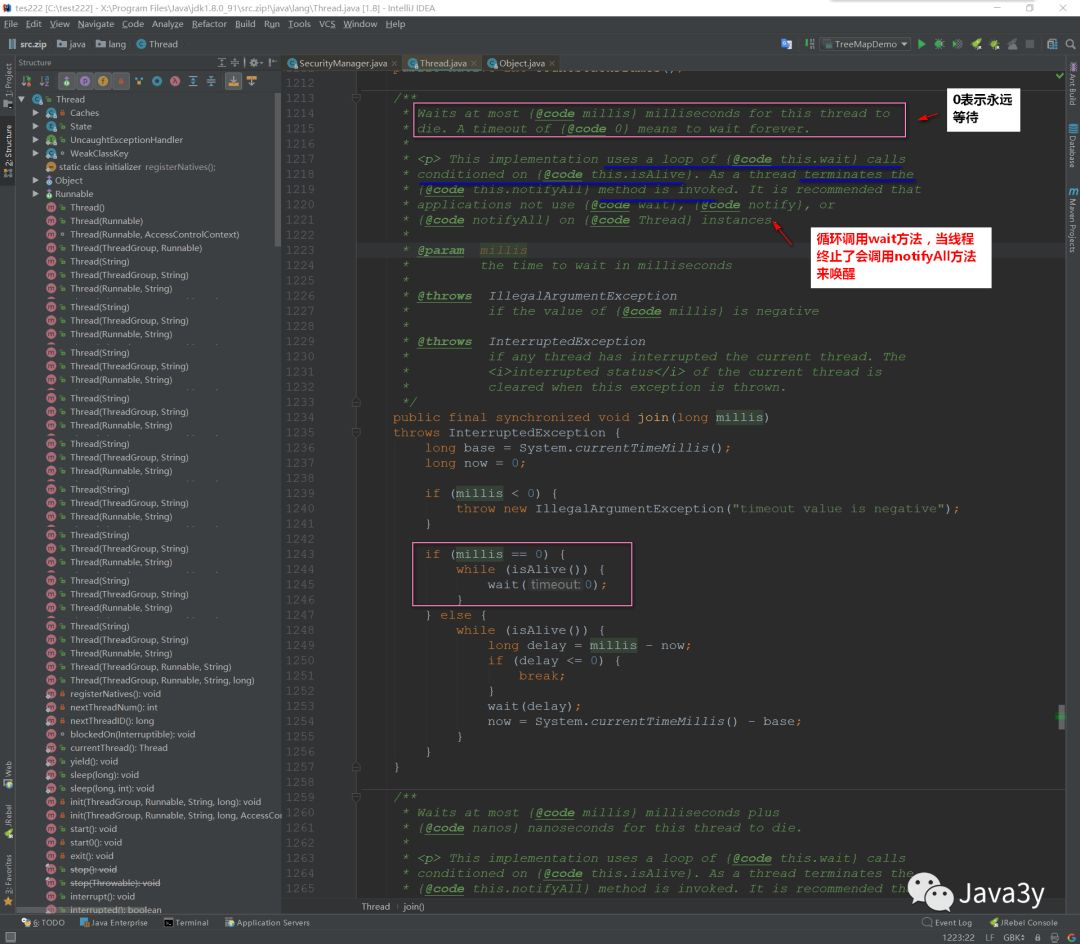
Let's go in and see the specific implementation:
Let's go in and see the specific implementation:
The wait method is defined on the Object. It is a native method, so you can't see it:

interrupt method
reference resources https://blog.csdn.net/weixin_41563161/article/details/104942044
Thread interrupt has a stop method in previous versions, but it is set out of date. There is no way to force thread termination now!
Because the stop method can make one thread A terminate another thread B
-
The terminated thread B immediately releases the lock, which may leave the object in an inconsistent state.
-
Thread A does not know when thread B can be terminated. If thread B still handles the running calculation stage, thread A calls the stop method to terminate thread B, it will be very innocent~
In a word, the Stop method is too violent and unsafe, so it is set out of date.
We usually use interrupt to request thread termination~
-
Note that interrupt doesn't really stop a thread. It just sends a signal to the thread that it should end (it's important to understand this!)
-
In other words, Java designers actually want the thread to terminate by itself. Through the above signals, they can judge what business to deal with.
-
Whether to interrupt or continue running should be handled by the notified thread itself
Thread t1 = new Thread( new Runnable(){
public void run(){
// If there is no interruption, the task will be executed normally
while(!Thread.currentThread.isInterrupted()){
// Normal task code
}
// Interrupt handling code
doSomething();
}
} ).start();Again: calling interrupt() does not really terminate the current thread, but only sets an interrupt flag. This interrupt flag can be used to judge when to do what work! It's up to us to decide when to interrupt, so we can safely terminate the thread!
Let's see what the source code says:
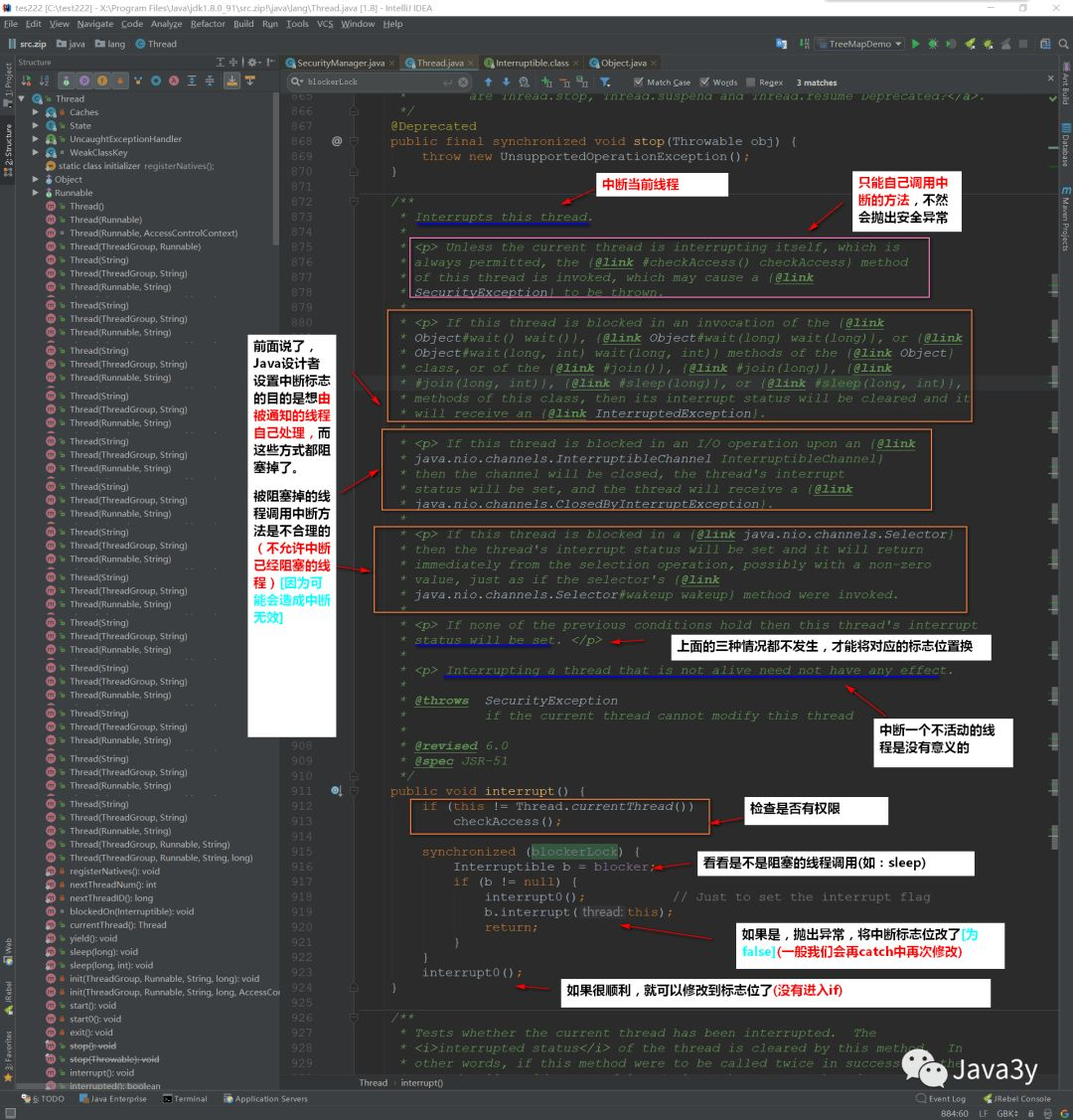
Let's take a look at the exception thrown just now:
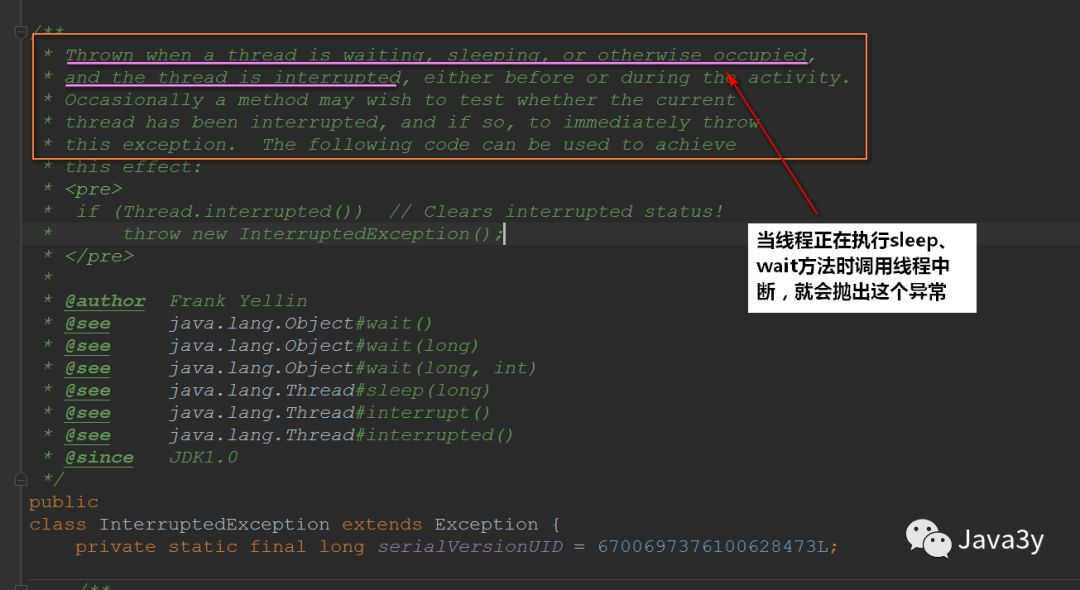
Therefore, the interrupt method will not affect the state of the thread at all. It only sets a flag bit
Interrupt thread interrupt has two other methods (check whether the thread is interrupted):
-
The static method interrupted() -- > clears the interrupt flag bit
-
The instance method isinterrupted() -- > does not clear the interrupt flag bit
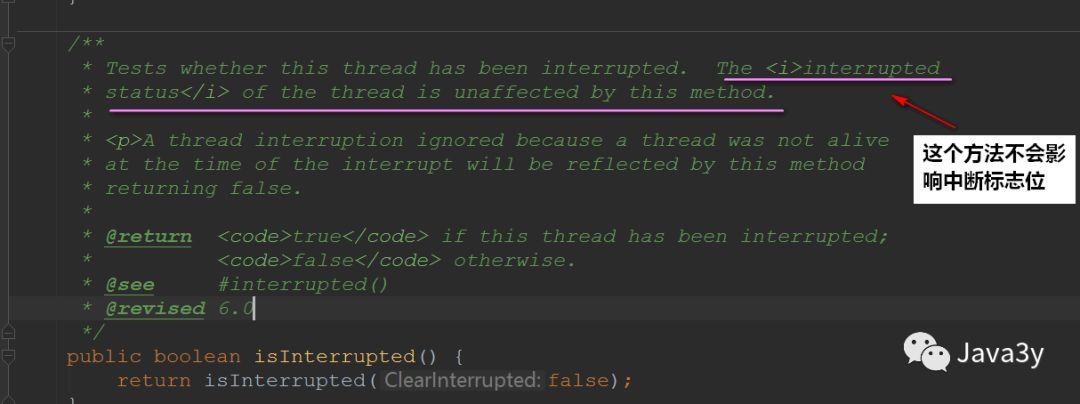
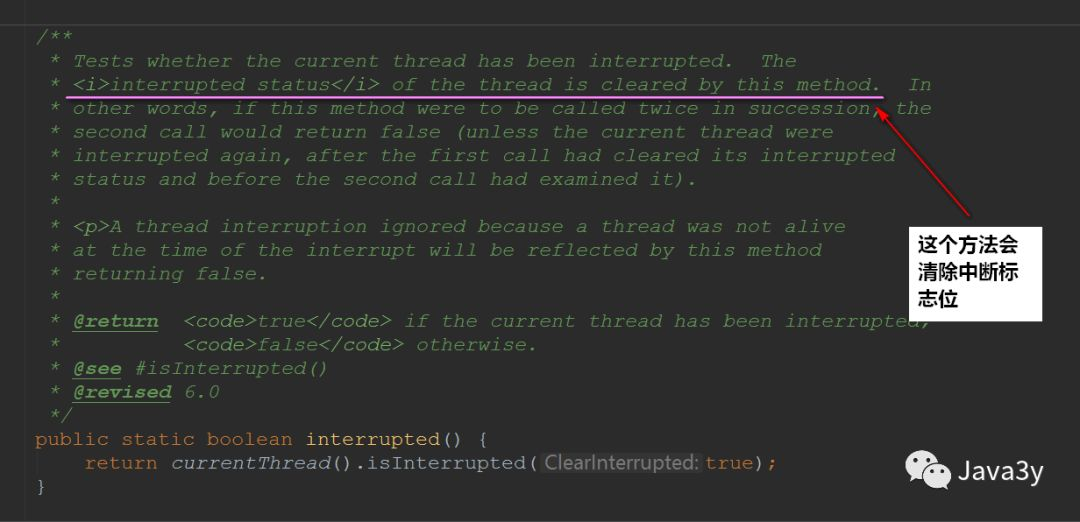
As mentioned above, if the blocking thread calls the interrupt() method, it will throw an exception, set the flag bit to false, and the thread will exit the blocking. Let's test a wave:
public class Main {
/**
* @param args
*/
public static void main(String[] args) {
Main main = new Main();
// Create thread and start
Thread t = new Thread(main.runnable);
System.out.println("This is main ");
t.start();
try {
// Sleep in the main thread for 3 seconds
Thread.sleep(3000);
} catch (InterruptedException e) {
System.out.println("In main");
e.printStackTrace();
}
// Interrupt settings
t.interrupt();
}
Runnable runnable = () -> {
int i = 0;
try {
while (i < 1000) {
// Sleep for half a second and we'll do it again
Thread.sleep(500);
System.out.println(i++);
}
} catch (InterruptedException e) {
// Determine whether the blocking thread is still in use
System.out.println(Thread.currentThread().isAlive());
// Judge the interrupt flag bit status of the thread
System.out.println(Thread.currentThread().isInterrupted());
System.out.println("In Runnable");
e.printStackTrace();
}
};
}
result:
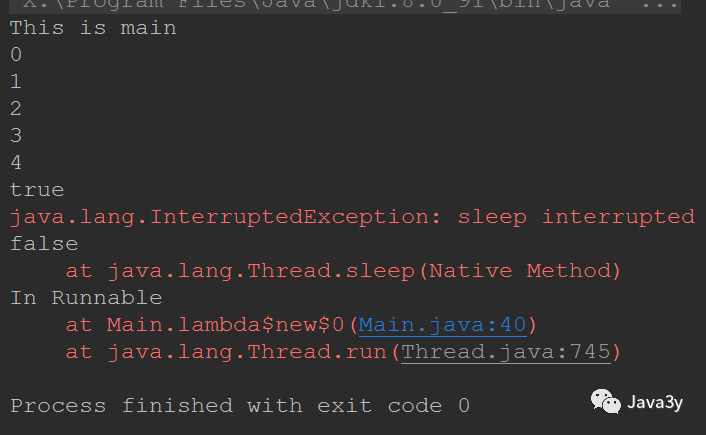
Next, let's analyze its execution process:
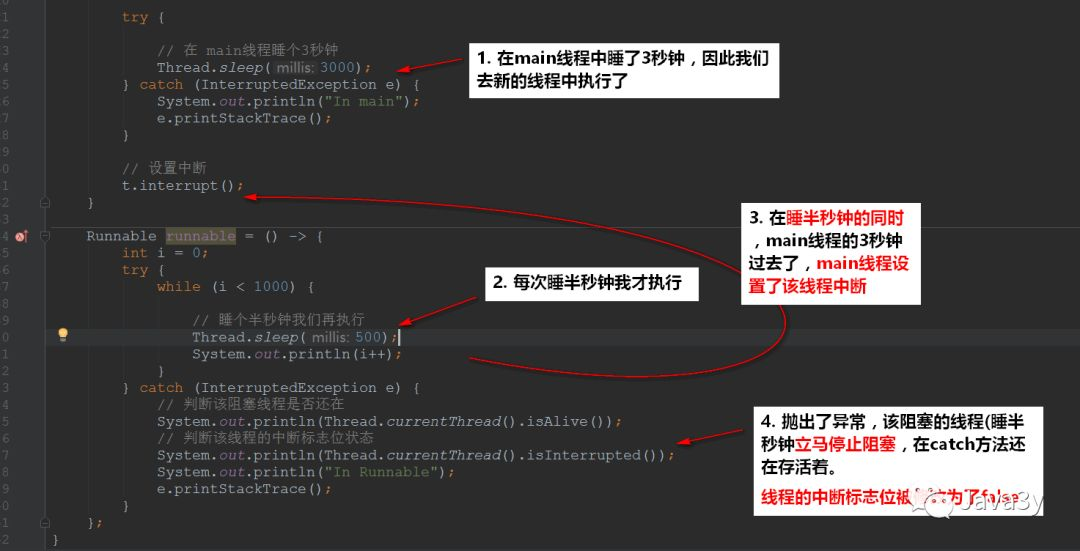
This reference:
-
https://www.cnblogs.com/w-wfy/p/6414801.html
-
https://www.cnblogs.com/carmanloneliness/p/3516405.html
-
https://www.zhihu.com/question/41048032/answer/89478427
-
https://www.zhihu.com/question/41048032/answer/89431513
4 the first four chapters of the book "Java Concurrent Programming Practice"
Chapter 1 Introduction
-
1.1 brief history of concurrent
-
1.2 advantages of threads
-
1.2.1 give full play to the powerful ability of multiprocessors
-
1.2.2 simplicity of modeling
-
1.2.3 simplified handling of asynchronous events
-
1.2.4 more responsive user interface
-
1.3 risks caused by threads
-
1.3.1 security issues
-
Activity issues
-
1.3.3 performance problems
-
1.4 threads everywhere
ps: I won't talk about this part. It mainly leads to our next knowledge points. Interested students can read the original book~
Chapter 2 thread safety
-
2.1 what is thread safety
-
2.2 atomicity
-
2.2.1 competitive conditions
-
2.2.2 example: race condition in delayed initialization
-
2.2.3 compound operation
-
2.3 locking mechanism
-
2.3.1 built in lock
-
2.3.2 reentry
-
2.4 protect the state with lock
-
2.5 activity and performance
Chapter 3 object sharing
-
3.1 visibility
-
3.1.1 failure data
-
3.1.2 non atomic 64 bit operation
-
3.1.3 locking and visibility
-
3.1.4 Volatile variable
-
3.2 release and escape
-
3.3 thread closure
-
3.3.1 ad hoc thread closure
-
3.3.2 stack closure
-
3.3.3 ThreadLocal class
-
3.4 invariance
-
3.4.1 Final domain
-
3.4.2 example: use Volatile type to publish immutable objects
-
3.5 safety release
-
3.5.1 incorrect release: the correct object is destroyed
-
3.5.2 immutable object and initialization security
-
3.5.3 common modes of safety release
-
3.5.4 fact immutable object
-
3.5.5 variable object
-
3.5.6 sharing objects safely
Chapter 4 combination of objects
-
4.1 design thread safe classes
-
4.1.1 collect synchronization requirements
-
4.1.2 operation of dependent state
-
4.1.3 ownership of status
-
4.2 case closure
-
4.2.1 Java monitor mode
-
4.2.2 example: Vehicle Tracking
-
4.3 delegation of thread safety
-
4.3.1 example: delegate based vehicle tracker
-
4.3.2 independent state variables
-
4.3.3 when the entrustment fails
-
4.3.4 publish the underlying state variables
-
4.3.5 example: vehicle tracker with release status
-
4.4 add functions to existing thread safety classes
-
4.4.1 client locking mechanism
-
4.4.2 combination
-
4.5 documenting synchronization policies
1, Problems encountered using multithreading
1.1 thread safety issues
If we execute code in a single thread in a "sequential" (serial -- > exclusive) manner, there is no problem. However, in the multithreaded environment (parallel), if it is not well designed and controlled, it will bring us many unexpected situations, that is, thread safety
For example:
-
The following program runs in a single thread. There is no problem.
public class UnsafeCountingServlet extends GenericServlet implements Servlet {
private long count = 0;
public long getCount() {
return count;
}
public void service(ServletRequest servletRequest, ServletResponse servletResponse) throws ServletException, IOException {
++count;
// To something else...
}
}
However, when running in a multithreaded environment, its count value is not calculated correctly!
First of all, it shares the variable count. Second, + + count; This is a combined operation (note that it is not atomic)
++count The actual operation is like this:
Read count value
Add value + 1
Write the calculation result to count
Therefore, when multithreading is executed, there is likely to be such a situation:
-
When thread A reads that the value of count is 8, thread B also goes into this method and reads that the value of count is 8
-
Both of them add 1 to the value
-
Write the calculation results to count. However, the result written to count is 9
-
In other words: two threads come in, but the correct result is that it should return 10 and it returns 9. This is abnormal!
If: when multiple threads access a class, this class can always show the correct behavior, then this class is thread safe!
There is a principle: if you can use the thread safety mechanism provided by JDK, use JDK.
Of course, this part is actually the most important part for us to learn multithreading. I won't talk about it in detail here. Here is just an overview. These knowledge points will be encountered in later learning~~~
1.2 performance issues
The purpose of using multithreading is to improve the utilization of applications, but if the multithreaded code is not well designed, it may not improve efficiency. Instead, it reduces efficiency and even causes deadlock!
For example, in our Servlet, a Servlet object can handle multiple requests. Obviously, a Servlet naturally supports multithreading.
Let's take the following example:
public class UnsafeCountingServlet extends GenericServlet implements Servlet {
private long count = 0;
public long getCount() {
return count;
}
public void service(ServletRequest servletRequest, ServletResponse servletResponse) throws ServletException, IOException {
++count;
// To something else...
}
}
As we have said above, the above class is thread unsafe. The simplest way: if we add the built-in lock synchronized provided by JDK to the service method, we can achieve thread safety.
public class UnsafeCountingServlet extends GenericServlet implements Servlet {
private long count = 0;
public long getCount() {
return count;
}
public void synchronized service(ServletRequest servletRequest, ServletResponse servletResponse) throws ServletException, IOException {
++count;
// To something else...
}
}
Although thread safety is realized, it will bring serious performance problems:
-
Each request must wait for the service method of the previous request to process before completing the corresponding operation
This leads to: we complete a small function and use multithreading to improve efficiency, but now we are not sure, but it brings serious performance problems!
When using multithreading: even more serious, there are deadlocks (the program is stuck).
These are what we need to learn next: learn which synchronization mechanism to use to achieve thread safety, and the performance is improved rather than reduced~
2, Publishing and escaping of objects
https://blog.csdn.net/weixin_41563161/article/details/105329368
3, Solve problems encountered by multithreading
3.1 briefly describe the solution to thread safety
When using multithreading, we must ensure that our threads are safe, which is the most important place!
In Java, we generally have the following methods to realize thread safety:
-
Stateless (no shared variables)
-
Use final to make the reference variable immutable (if the object reference also references other objects, it needs to be locked whether it is published or used)
-
Lock (built-in lock, display lock)
-
Use the classes provided by JDK to realize thread safety (there are many classes in this part)
-
Atomicity (for example, in the count + + operation above, AtomicLong can be used to realize atomicity, so there will be no error when adding!)
-
Containers (ConcurrentHashMap, etc...)
-
......
-
-
... wait
3.2 atomicity and visibility
3.2.1 atomicity
In multithreading, it is often because an operation is not atomic, which makes data confusion and errors. If the data of the operation is atomic, the thread safety problem can be avoided to a great extent!
count + +, read first, then increase automatically, and then assign value. If the operation is atomic, it can be said to be thread safe (because there are no three intermediate links, one step in place [atomic]~
Atomicity means that the execution of an operation is inseparable,
-For example, the count + + operation mentioned above is not an atomic operation. It is divided into three steps to realize this operation~
-There is an atomic package in JDK to provide us with atomic operations~
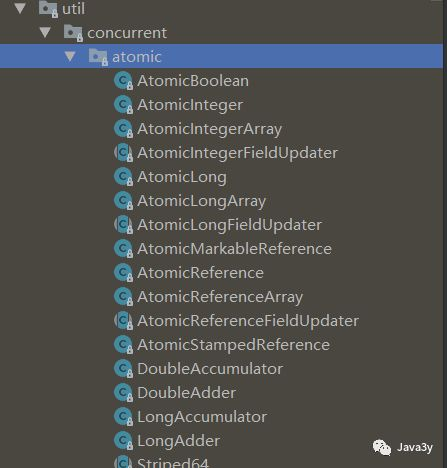
Some people also made it into a table to classify it. Let's take a look:

The operations related to using these classes can also be viewed in his blog:
-
https://blog.csdn.net/eson_15/article/details/51553338
3.2.2 visibility
For visibility, Java provides a keyword: volatile for us to use~
-
We can simply think that volatile is a lightweight synchronization mechanism
Classic summary of volatile: volatile is only used to ensure the visibility of the variable to all threads, but it does not guarantee atomicity
Let's take it apart and explain:
-
Ensure the visibility of this variable to all threads
-
In a multithreaded environment: when this variable is modified, all threads will know that the variable has been modified, which is the so-called "visibility"
-
-
Atomicity is not guaranteed
-
Modifying variables (assignment) is essentially divided into several steps in the JVM, and in these steps (from loading variables to modifying), it is not safe.
-
Variables decorated with volatile ensure three points:
-
Once you finish writing, any thread accessing this field will get the latest value
-
Before you write, you will ensure that all the previous events have happened, and any updated data values are also visible, because the memory barrier will flush the previous write values to the cache.
-
Volatile can prevent reordering (reordering means that the CPU and compiler may adjust the execution order when the program is executed, resulting in the execution order is not from top to bottom, resulting in some unexpected effects). If volatile is declared, the CPU and compiler will know that this variable is shared and will not be cached in registers or other invisible places.
Generally speaking, volatile is mostly used in the flag bit (judgment operation). Volatile should be used to modify variables only when the following conditions are met:
-
When modifying a variable, it does not depend on the current value of the variable (because volatile does not guarantee atomicity)
-
The variable is not included in the invariance condition (the variable is variable)
-
This locking mechanism is unnecessary when using volatile variables
reference material:
-
http://www.cnblogs.com/Mainz/p/3556430.html
-
https://www.cnblogs.com/Mainz/p/3546347.html
-
http://www.dataguru.cn/java-865024-1-1.html
3.3 thread closure
In a multithreaded environment, as long as we do not use member variables (do not share data), there will be no thread safety problem.
Take the Servlet we are familiar with as an example. After writing so many servlets, have you seen us say to lock it?? All our data is operated on methods (stack closure). Each thread has its own variables and does not interfere with each other!
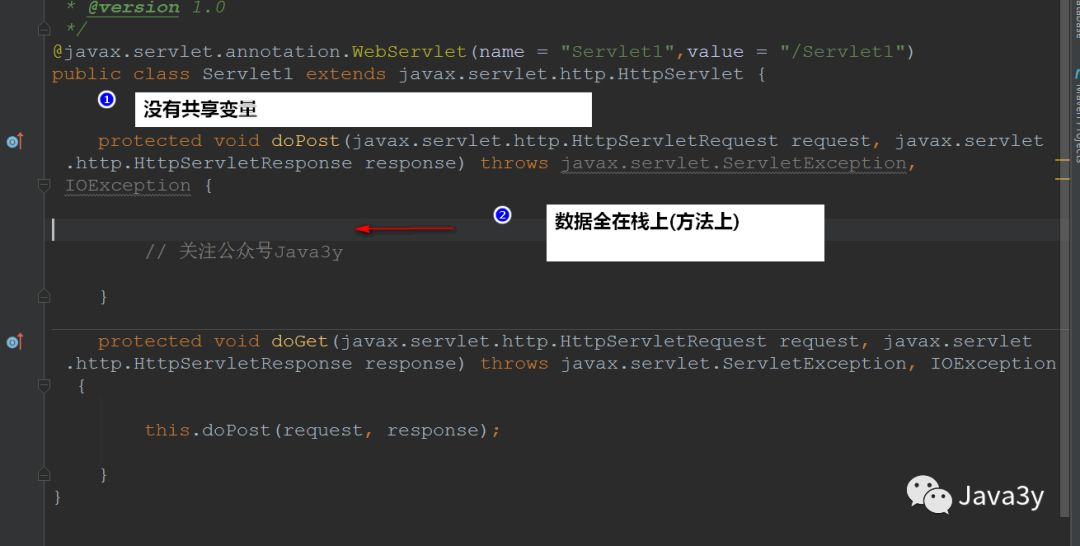
As long as we guarantee not to publish objects on the stack (method) (the scope of each variable only stays on the current method), our thread is safe
There is another method for thread closure, which I wrote before: ThreadLocal is that simple
Using the API of this class can ensure that each thread has its own exclusive variable. (read the above article for details)~
3.4 invariance
Immutable objects must be thread safe.
The variables we share above are all variable. Because they are variable, thread safety problems occur. If the state is immutable, there is no problem for any multiple threads to access!
Java provides the final modifier for us to use. We may see more of the figure of final, but it is worth noting that:
-
final is only the reference of the variable that cannot be modified, but the data in the reference can be changed!
Like the HashMap below, it is decorated with final. However, it only ensures that the object referenced by the HashMap variable is immutable, but the data inside the HashMap is variable, that is, you can add, remove and other operations into the collection~~~
Therefore, it can only explain that hashMap is an immutable object reference
final HashMap<Person> hashMap = new HashMap<>();
Immutable object references still need to be locked when used
-
Or design Person as a thread safe class~
-
Because the internal state is variable, without lock or Person is not thread safe, the operation is dangerous!
To design an object as an immutable object, the following three conditions must be met:
-
Once an object is created, its state cannot be modified
-
All fields of the object are final decorated
-
The object was created correctly (no this reference escaped)
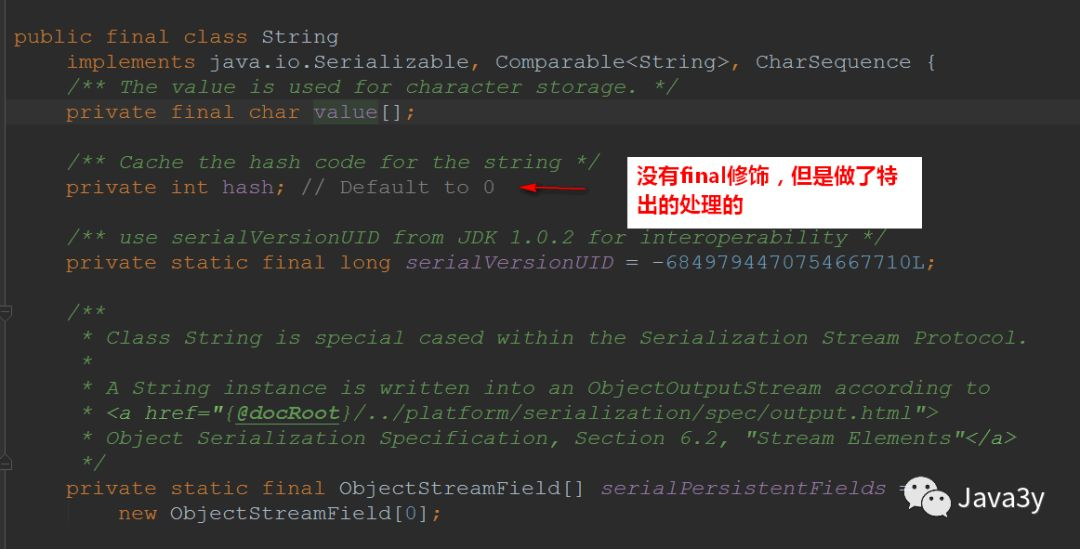
In the process of learning String, we know it is an immutable object, but it does not follow the second point (all domains of the object are final decorated), because the JVM is optimized internally. However, if we want to design immutable objects ourselves, we need to meet three conditions.
3.5 thread safety delegation
Many times we need to lock ourselves and design ourselves to achieve thread safety.
We can use the objects provided by JDK to complete thread safety design:
Using multithreading correctly can improve the efficiency of our application and bring us many problems. These are what we need to pay attention to before using multithreading.
Whether invariance, visibility, atomicity, thread closure, delegation, these are a means to achieve thread safety. To use these means reasonably, our program can be more robust!
5 Java lock mechanism
There are two locking mechanisms for Java multithreading:
-
Synchronized
-
Explicit Lock
I have to nag:
-
In Java core technology Volume 1, we first talk about the more difficult explicit Lock, and then talk about the relatively simple Synchronized
-
In the first four chapters of the practical battle of Java Concurrent Programming, Synchronized is explained in a scattered way, and explicit Lock is put into Chapter 13
1, synchronized lock
1.1 what is a synchronized lock?
synchronized is a keyword in Java, which can lock code blocks (Methods)
-
It is very simple to use. As long as the keyword synchronized is added to the code block (method), the function of synchronization can be realized~
public synchronized void test() {
// Pay attention to the official account Java3y
// doSomething
}synchronized is a mutex
-
Only one thread can be allowed to enter a locked block of code at a time
synchronized is a built-in lock / monitor lock
-
Every object in Java has a built-in lock (monitor, which can also be understood as lock mark), and synchronized uses the built-in lock (monitor) of the object to lock the code block (method)!
1.2 what is the use of synchronized?
-
synchronized ensures the atomicity of threads. (the protected code block is executed at one time, and no thread will access it at the same time)
-
Synchronized also ensures visibility. (after synchronized is executed, the modified variable is visible to other threads)
synchronized in Java realizes the synchronous operation of variables by using the built-in lock, and then realizes the atomicity of variable operation and the visibility of other threads to variables, so as to ensure thread safety in the case of concurrency.
1.3 principle of synchronized
Let's first look at a piece of code of synchronized modification method and code block:
public class Main {
//Modification method
public synchronized void test1(){
}
public void test2(){
// Decorated code block
synchronized (this){
}
}
}
Let's decompile:
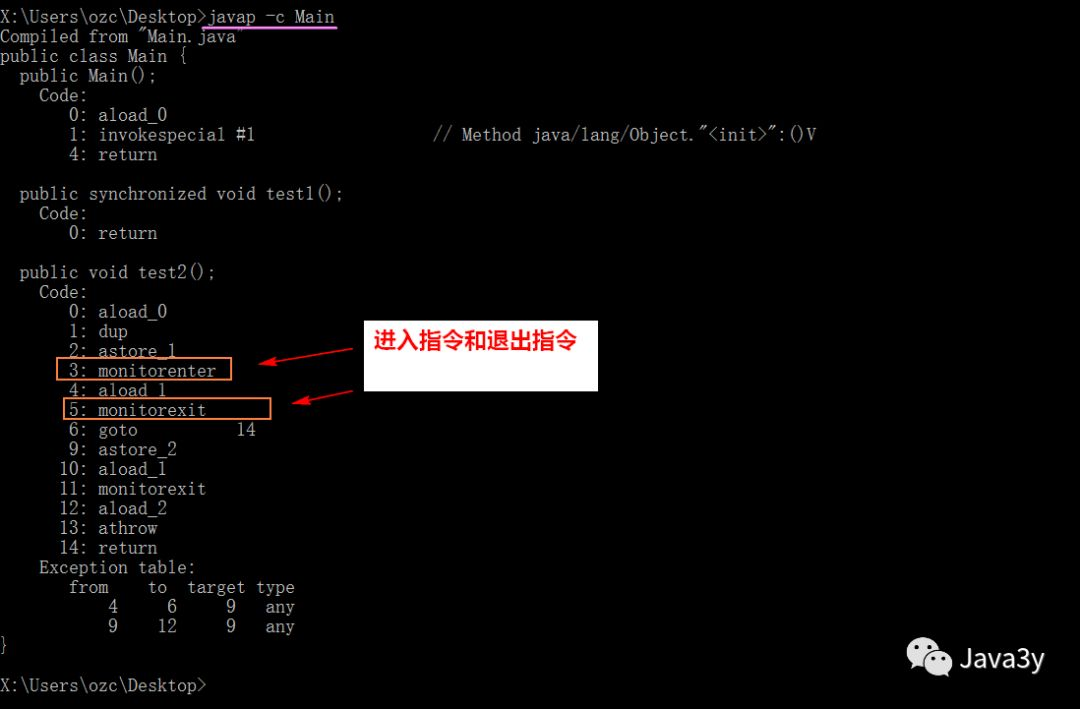
Sync code block:
-
Implementation of monitorenter and monitorexit instructions
Synchronization method (I can't see it here. I need to see the underlying implementation of the JVM)
-
ACC on method modifier_ Synchronized implementation.
The bottom layer of synchronized is through the monitor object. The object has its own object header and stores a lot of information, one of which indicates which thread holds it.
For details, please refer to:
-
https://blog.csdn.net/chenssy/article/details/54883355
-
https://blog.csdn.net/u012465296/article/details/53022317
1.4 how to use synchronized
synchronized is generally used to modify three things:
-
Common methods of modification
-
Decorated code block
-
Modified static method
1.4.1 general methods of modification:
The lock used is a Java 3Y object (built-in lock)
public class Java3y {
// Modifying common methods , The lock used at this time is a Java 3Y object (built-in lock)
public synchronized void test() {
// Pay attention to the official account Java3y
// doSomething
}
}
1.4.2 modifier code block:
The lock used is Java3y object (built-in lock) - > this
public class Java3y {
public void test() {
// Modifier code block , The lock used at this time is Java3y object (built-in lock) - & gt; this
synchronized (this){
// Pay attention to the official account Java3y
// doSomething
}
}
}
Of course, when we use synchronized to decorate code blocks, we don't necessarily use this. We can also use other objects (any object has a built-in lock)
public class Java3y {
// Use object as lock (any object has corresponding lock mark , object is no exception)
private Object object = new Object();
public void test() {
// Modifier code block , The lock used at this time is the lock Object created by yourself
synchronized (object){
// Pay attention to the official account Java3y
// doSomething
}
}
}
1.4.3 modification static method
What is obtained is the class lock (bytecode file object of the class): java3y class
public class Java3y {
// Modify static method code block , Static methods belong to class methods , It belongs to this class , The acquired lock is a lock belonging to class (bytecode file object of class) - & gt; Java3y. class
public synchronized void test() {
// Pay attention to the official account Java3y
// doSomething
}
}
1.4.4 class lock and object lock
Synchronized modifies the static method to obtain the class lock (bytecode file object of the class), and synchronized modifies the ordinary method or code block to obtain the object lock.
-
The two do not conflict, that is, the thread that obtains the class lock and the thread that obtains the object lock do not conflict!
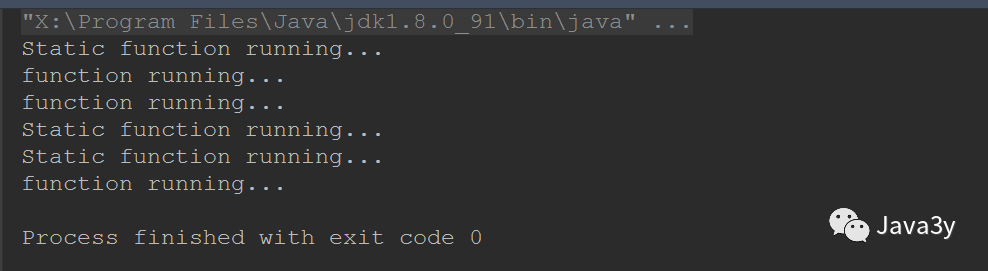
public class SynchoronizedDemo {
//synchronized modifies non static methods
public synchronized void function() throws InterruptedException {
for (int i = 0; i <3; i++) {
Thread.sleep(1000);
System.out.println("function running...");
}
}
//synchronized modified static method
public static synchronized void staticFunction()
throws InterruptedException {
for (int i = 0; i < 3; i++) {
Thread.sleep(1000);
System.out.println("Static function running...");
}
}
public static void main(String[] args) {
final SynchoronizedDemo demo = new SynchoronizedDemo();
// Create thread to execute static method
Thread t1 = new Thread(() -> {
try {
staticFunction();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
// Create thread execution instance method
Thread t2 = new Thread(() -> {
try {
demo.function();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
// start-up
t1.start();
t2.start();
}
}
The results show that class lock and object lock will not conflict!
1.5 re-entry lock
Let's look at the following code:
public class Widget {
// Locked
public synchronized void doSomething() {
...
}
}
public class LoggingWidget extends Widget {
// Locked
public synchronized void doSomething() {
System.out.println(toString() + ": calling doSomething");
super.doSomething();
}
}
-
When thread A enters the doSomething() method of LoggingWidget, it gets the lock of the LoggingWidget instance object.
-
Then, the doSomething() method of the parent Widget is called on the method, which is modified by synchronized.
-
Now that the lock of the LoggingWidget instance object has not been released, do we need a lock to enter the doSomething() method of the parent Widget?
No need!
Because the lock holder is "thread", not "call". Thread A already has the lock of the LoggingWidget instance object. When it is needed again, it can continue to "unlock" it!
This is the reentrancy of the built-in lock.
1.6 timing of releasing lock
-
When the method (code block) is executed, the lock will be released automatically without any operation.
-
When an exception occurs in the code executed by a thread, the lock held by it will be released automatically.
-
No deadlock due to exceptions~
2, Lock explicit lock
2.1 brief introduction to lock explicit lock
Lock explicit lock is jdk1 Only after 5. Before, we used Synchronized locks to make threads safe~
Lock explicit lock is an interface. Let's see:
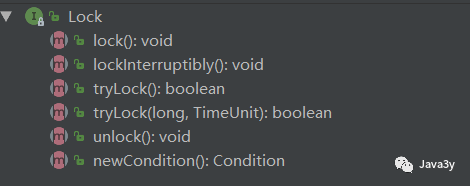
Translate his top notes casually to see what they are used for:
It can be summarized as follows:
-
Lock mode to obtain locks. It supports interrupt, timeout, no acquisition and non blocking
-
Improved semantics. You have to write out where to lock and unlock
-
Lock explicit lock can give us good flexibility, but at the same time, we must release the lock manually
-
Support Condition object
-
Allow multiple read threads to access shared resources at the same time
2.2 which is used for synchronized Lock or Lock lock
As mentioned earlier, Lock explicit Lock brings a lot of flexibility to our program, and many features are not available in Synchronized Lock. Is it necessary for the Synchronized Lock to exist??
There must be!! Lock lock is better than Synchronized lock in many performance aspects when it comes out, but from jdk1 6. Various optimizations have been made for the Synchronized lock since the beginning (after all, it's a son, a cow)
-
Optimized operation: adapt to spin lock, lock elimination, lock coarsening, lightweight lock and bias lock.
-
For details, please refer to: https://blog.csdn.net/chenssy/article/details/54883355
Therefore, up to now, the performance difference between lock lock and Synchronized lock is not very big! The Synchronized lock is particularly simple to use. Lock lock also has to worry about its features. You need to release the lock manually (if you forget to release it, this is a hidden danger)
Therefore, we will still use Synchronized locks most of the time. We will consider using Lock explicit locks for the flexibility brought by using the features mentioned in Lock locks~
2.3 fair lock
Fair lock is very simple to understand:
-
Threads will acquire locks in the order they make requests
Unfair locks are:
-
When a thread makes a request, it can "jump in line" to obtain the lock
Both Lock and synchronize use unfair locks by default. Do not use fair locks if not necessary
-
Fair lock will bring some performance consumption
reference material:
-
Java core technology Volume I
-
Java Concurrent Programming Practice
-
Computer operating system - Tang Xiaodan
-
https://blog.csdn.net/panweiwei1994/article/details/78483167
-
http://www.cnblogs.com/dolphin0520/category/602384.html
-
https://blog.csdn.net/chenssy/article/category/3145247
-
https://blog.csdn.net/u012465296/article/details/53022317
-
https://www.cnblogs.com/wxd0108/p/5479442.html
6 AQS
Originally, I intended to write the subclass implementation of Lock in this chapter, but I saw such a concept of AQS. It can be said that the subclass implementation of Lock is based on AQS.
1, What is AQS?
First, let's popularize what juc is: juc is actually the abbreviation of package (java.util.concurrnt)
-
Don't be fooled into thinking that juc is something awesome. Actually, it means a bag~
We can find that there are three abstract classes under the lock package:
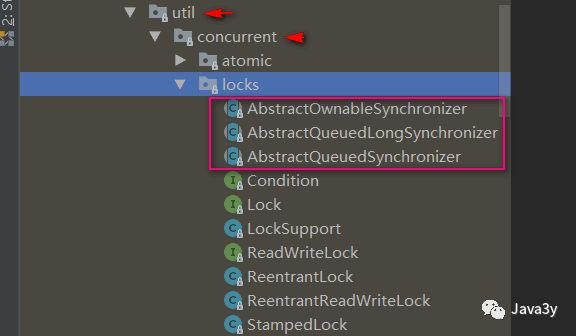
-
AbstractOwnableSynchronizer
-
AbstractQueuedLongSynchronizer
-
AbstractQueuedSynchronizer
Generally: AbstractQueuedSynchronizer is called AQS for short
Two common locks such as Lock are implemented based on it:
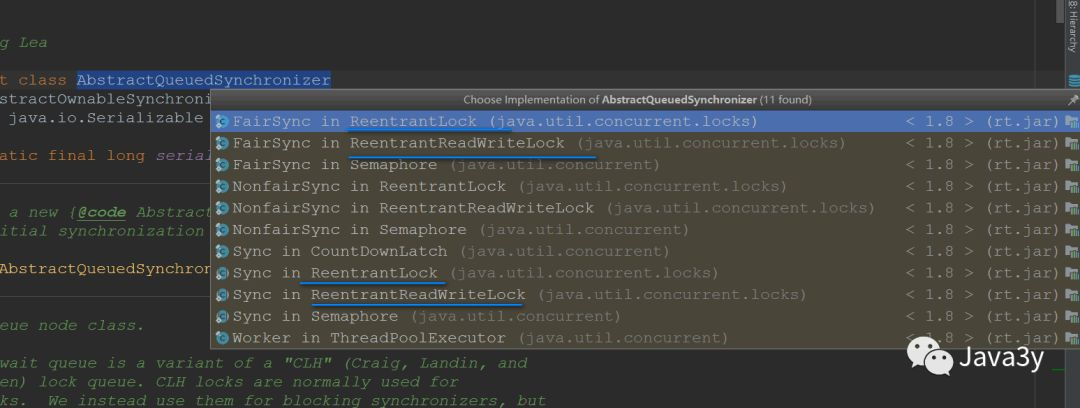
So let's see what AbstractQueuedSynchronizer is. The fastest way to see what a class does is to look at its top annotation
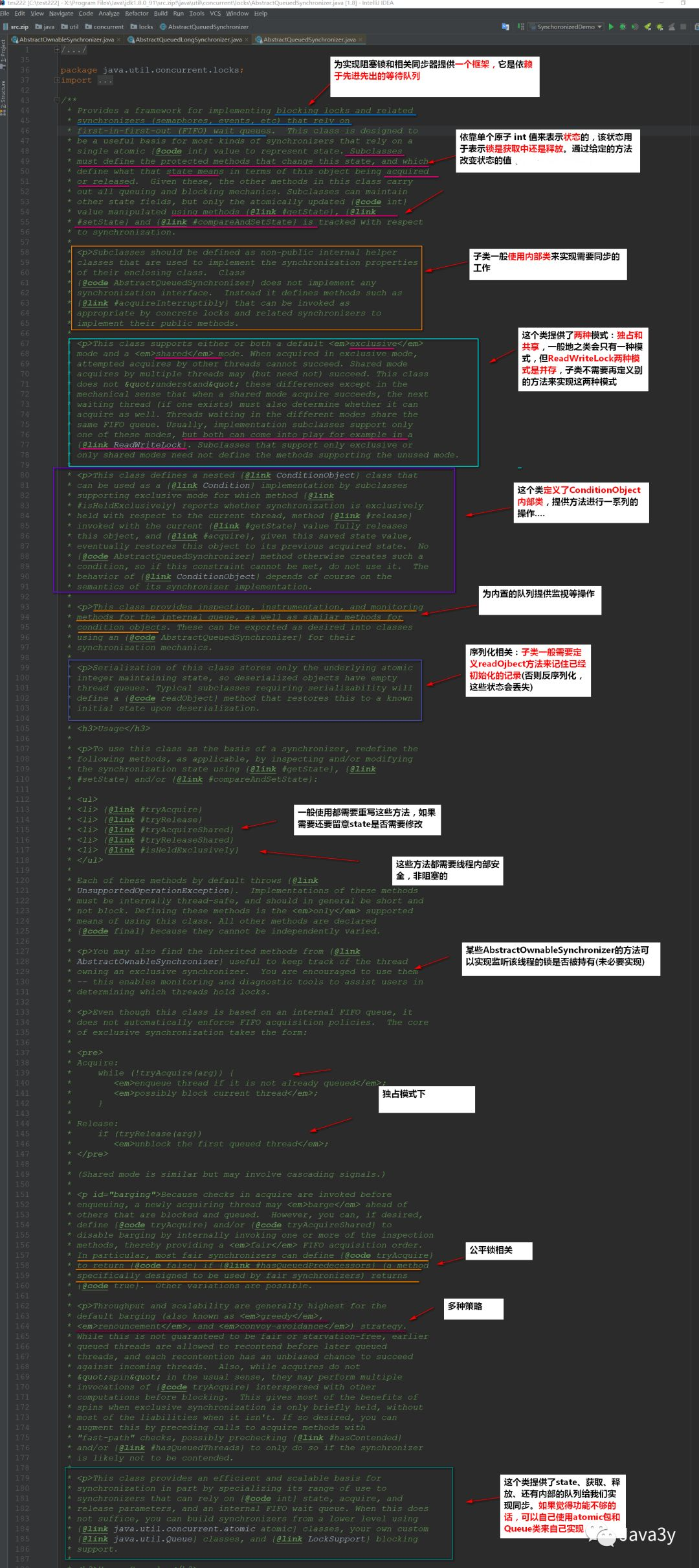
After reading through, you can summarize the following key information:
-
AQS is actually a framework that can give us the ability to implement locks
-
The key of internal implementation is: first in first out queue and state status
-
Defines the internal class ConditionObject
-
There are two threading modes
-
Exclusive Mode
-
Sharing mode
-
-
The related locks in the LOCK package (commonly used are ReentrantLock and ReadWriteLock) are built based on AQS
-
Generally, we call AQS as synchronizer
2, Take a brief look at AQS
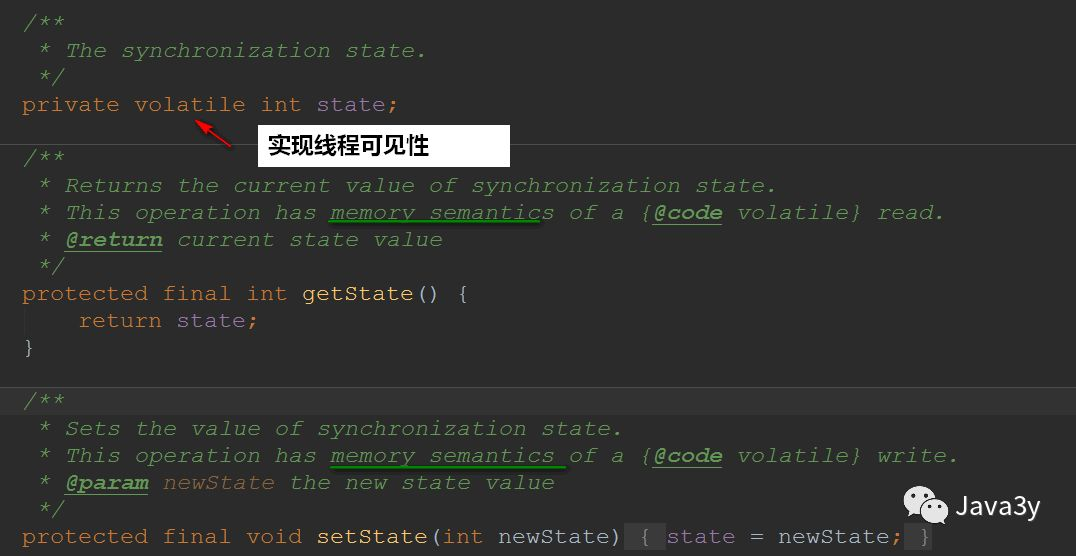
2.1 synchronization status
Use volatile decoration to achieve thread visibility:
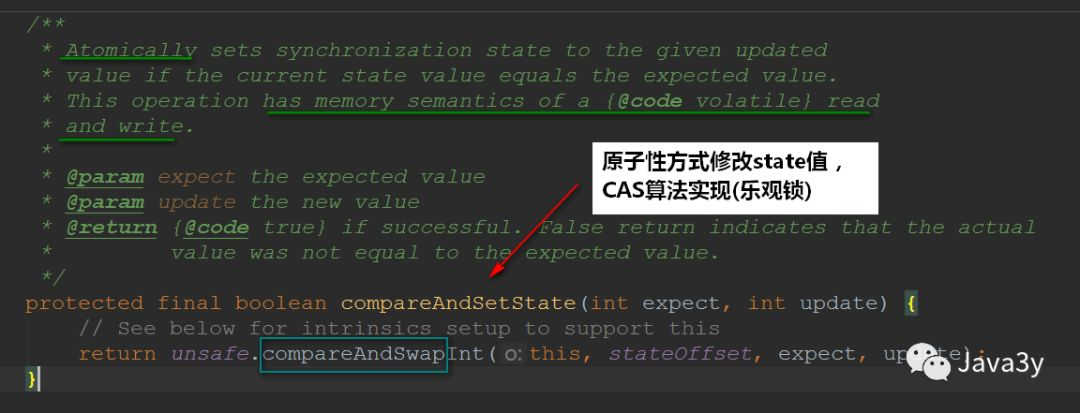
CAS algorithm is used to modify the state value:
2.2 first in first out queue
This queue is called CLH queue (composed of three names), which is a two-way queue
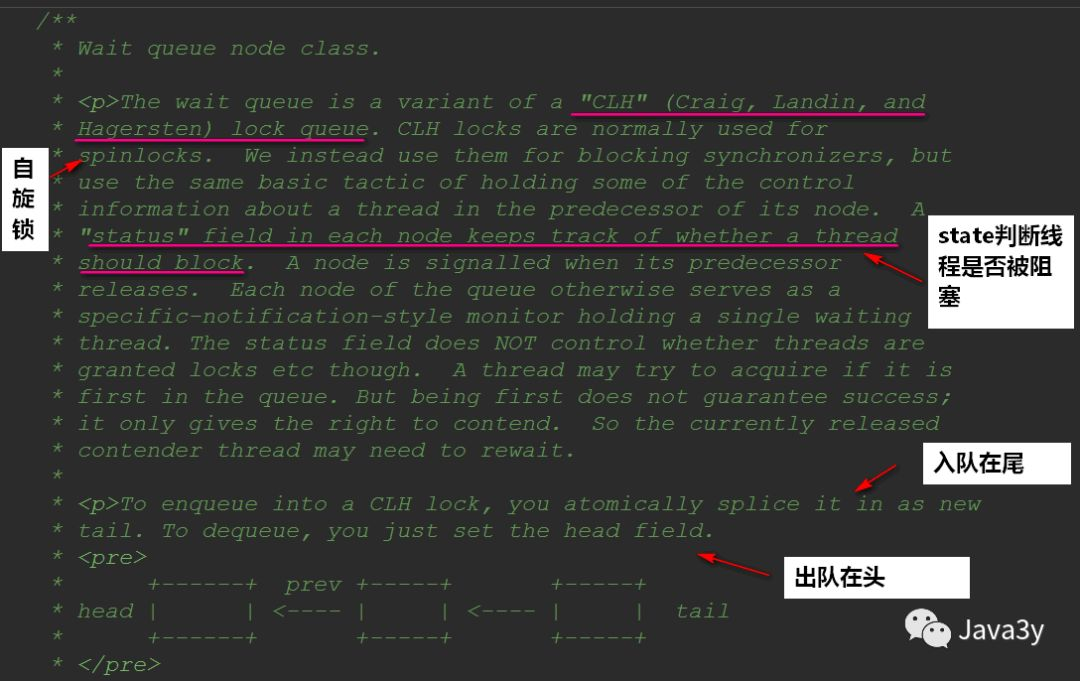
Look at the composition of its queue source code:
static final class Node {
// share
static final Node SHARED = new Node();
// monopoly
static final Node EXCLUSIVE = null;
// The thread was canceled
static final int CANCELLED = 1;
// Subsequent threads need to wake up
static final int SIGNAL = -1;
// Wait for condition to wake up
static final int CONDITION = -2;
// Shared synchronous state acquisition will be propagated unconditionally (I don't understand)
static final int PROPAGATE = -3;
// Initially 0, The states are the above
volatile int waitStatus;
// Front node
volatile Node prev;
// Successor node
volatile Node next;
volatile Thread thread;
Node nextWaiter;
final boolean isShared() {
return nextWaiter == SHARED;
}
final Node predecessor() throws NullPointerException {
Node p = prev;
if (p == null)
throw new NullPointerException();
else
return p;
}
Node() { // Used to establish initial head or SHARED marker
}
Node(Thread thread, Node mode) { // Used by addWaiter
this.nextWaiter = mode;
this.thread = thread;
}
Node(Thread thread, int waitStatus) { // Used by Condition
this.waitStatus = waitStatus;
this.thread = thread;
}
}</code></pre>
2.3acquire method
The process of obtaining exclusive lock is defined in acquire. This method uses the template design pattern and is implemented by subclasses~
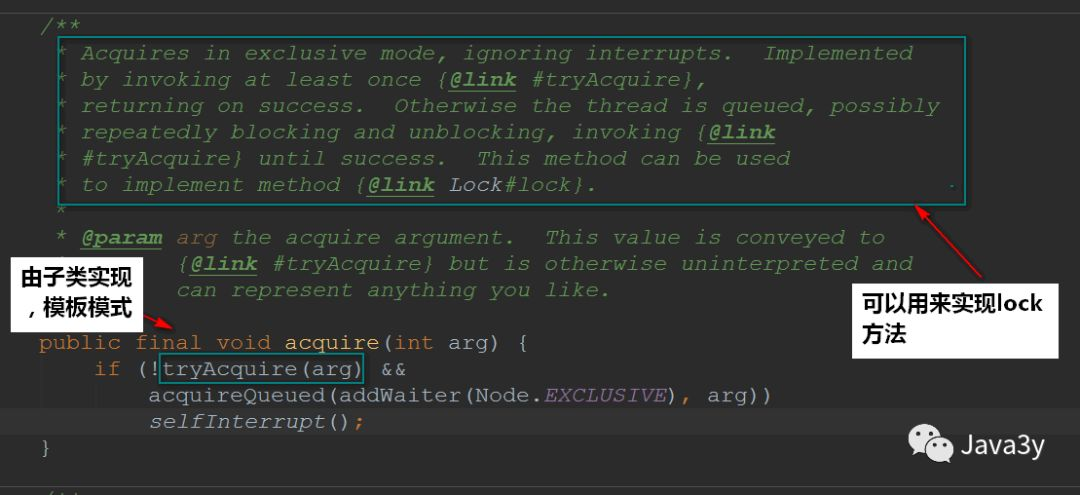
Procedure: acquire(int) attempts to acquire resources. If the acquisition fails, insert the thread into the waiting queue. After inserting the waiting queue, acquire(int) does not give up acquiring resources, but judges whether to continue acquiring resources according to the state of the front node. If the front node is the head node, continue to try to acquire resources. If the front node is in SIGNAL state, interrupt the current thread, otherwise continue to try to acquire resources. acquire(int) ends until the current thread is park() or gets the resource.
Source:
-
https://blog.csdn.net/panweiwei1994/article/details/78769703
2.4 release method
The process of releasing the exclusive lock is defined in acquire. This method also uses the template design pattern, which is implemented by subclasses~
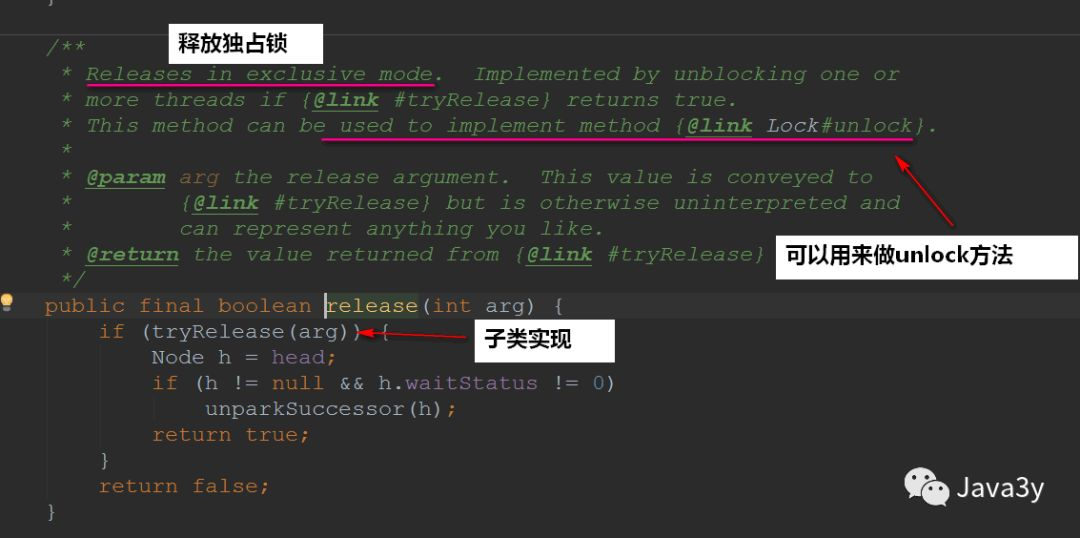
Procedure: first call the tryRelease() method of the subclass to release the lock, and then wake up the successor node. In the wake-up process, you need to judge whether the successor node meets the requirements. If the successor node is not in the invalid state, wake up the successor node. Otherwise, look for the appropriate node from the tail node. If it is found, wake up
Source:
-
https://zhuanlan.zhihu.com/p/27134110
3, Finally
Summarize what AQS is:
-
Many blocking classes in the juc package are built based on AQS
-
AQS can be said to be a framework for implementing synchronization locks and synchronizers. Many implementation classes are built on its basis
-
-
The default implementation of waiting queue is implemented in AQS, and subclasses can be implemented only by rewriting part of the code (a lot of template code is used)
reference material:
-
https://blog.csdn.net/panweiwei1994/article/details/78769703
-
https://zhuanlan.zhihu.com/p/27134110
-
http://cmsblogs.com/?page_id=111
Lock subclass
In the previous article, we briefly reviewed the basic AQS of Lock lock. Therefore, this article mainly explains the two main subclasses of Lock:
-
ReentrantLock
-
ReentrantReadWriteLock
1, ReentrantLock lock
First, let's take a look at the top note of ReentrantLock lock lock and its related features:
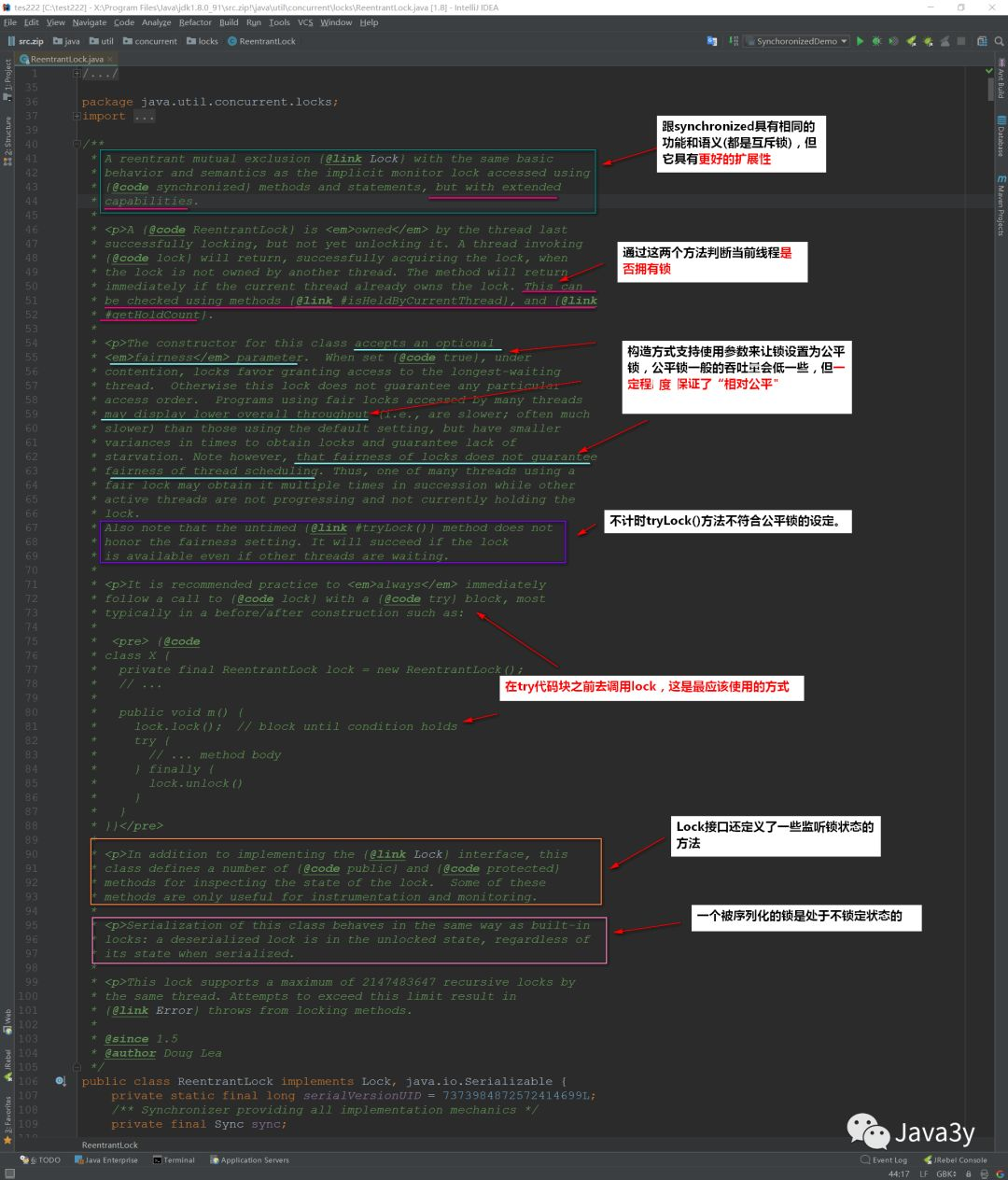
Let's summarize the main points:
-
More scalable (flexible) than synchronized
-
Support fair lock (relatively fair)
-
The most standard use is to call the lock method before try and release the lock in the finally code block.
class X {
private final ReentrantLock lock = new ReentrantLock();
// ...
public void m() {
lock.lock(); // block until condition holds
try {
// ... method body
} finally {
lock.unlock()
}
}
}
1.1 internal class
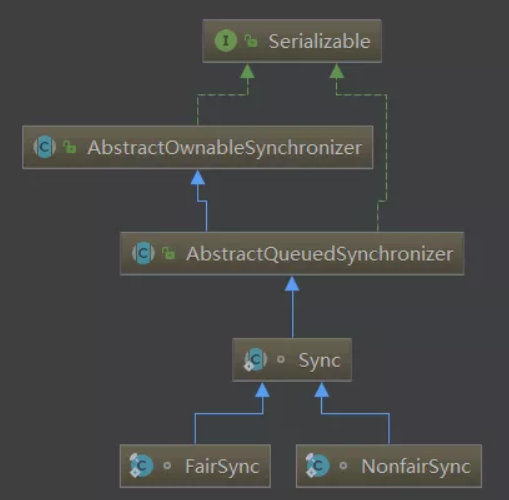
First, we can see that there are three internal classes:

These internal classes are subclasses of AQS, which confirms what we said before: AQS is the basis of ReentrantLock, and AQS is the framework for building locks and synchronizers
-
It can be clearly seen that our ReentrantLock lock supports fair locks and unfair locks~
1.2 construction method
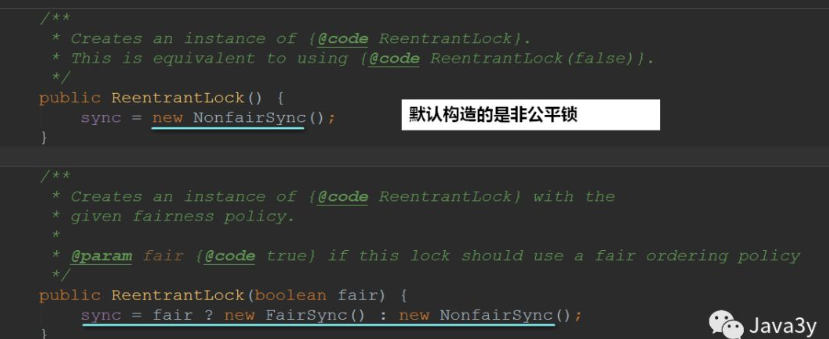
1.3 unfair lock method
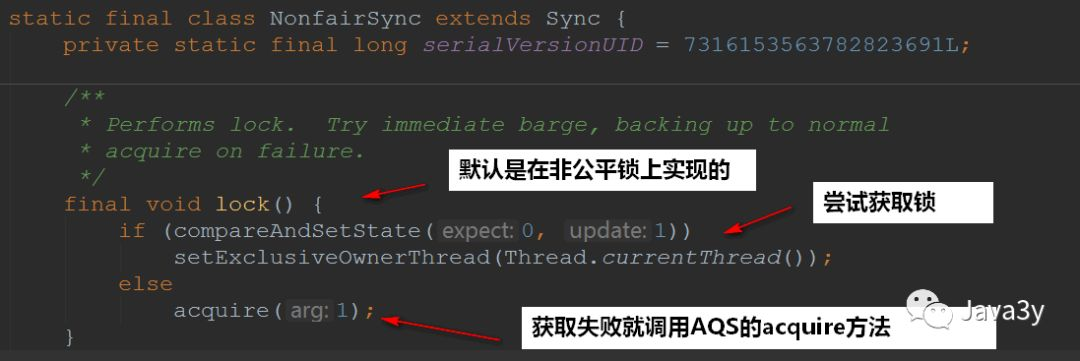
If you attempt to acquire a lock and fail to acquire it, call the acquire(1) method of AQS
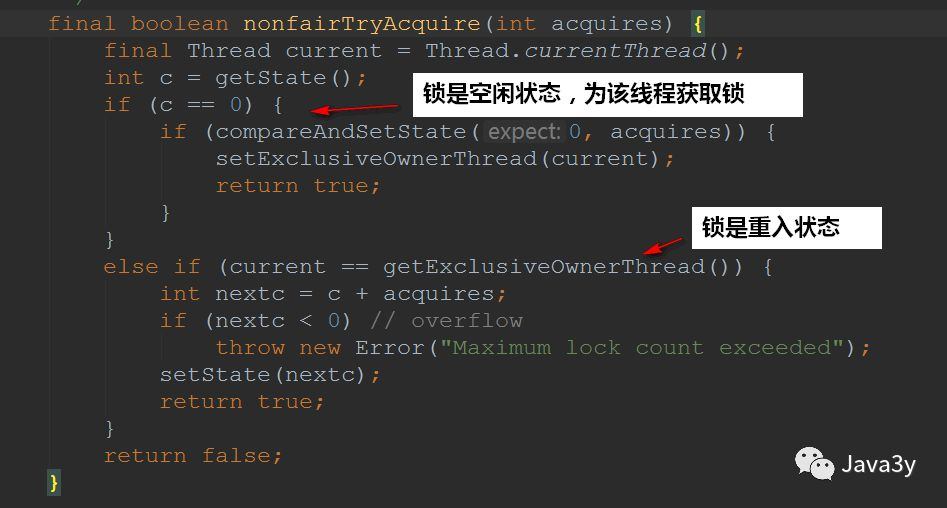
We have seen the acquire(1) method briefly in AQS, where tryAcquire() is implemented by subclasses

Let's take a look at tryAcquire():
1.4 fair lock method
The fair lock method actually has one more state condition:
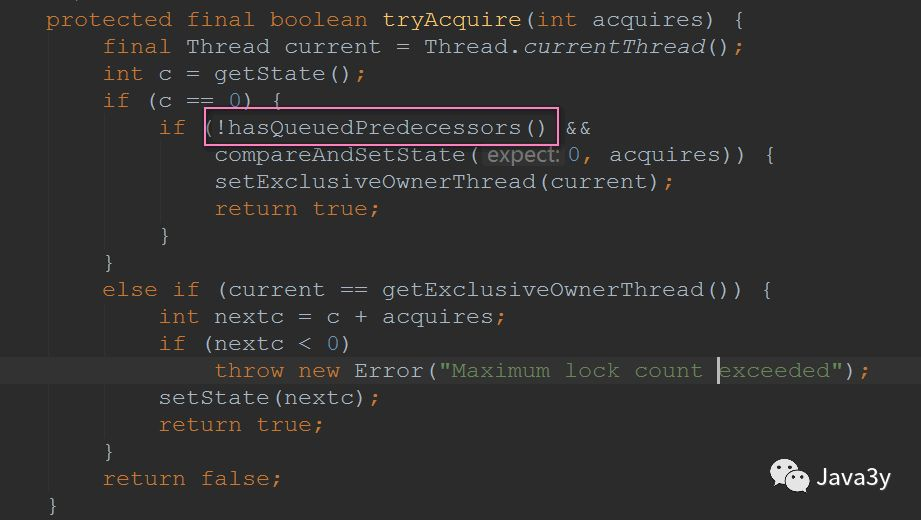
This method mainly determines whether the current thread is the first in the CLH synchronization queue. If yes, it returns false; otherwise, it returns true.
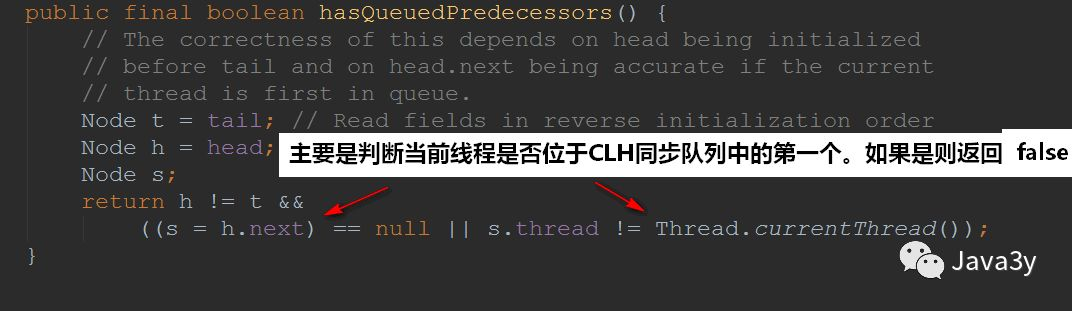
1.5 unlock method
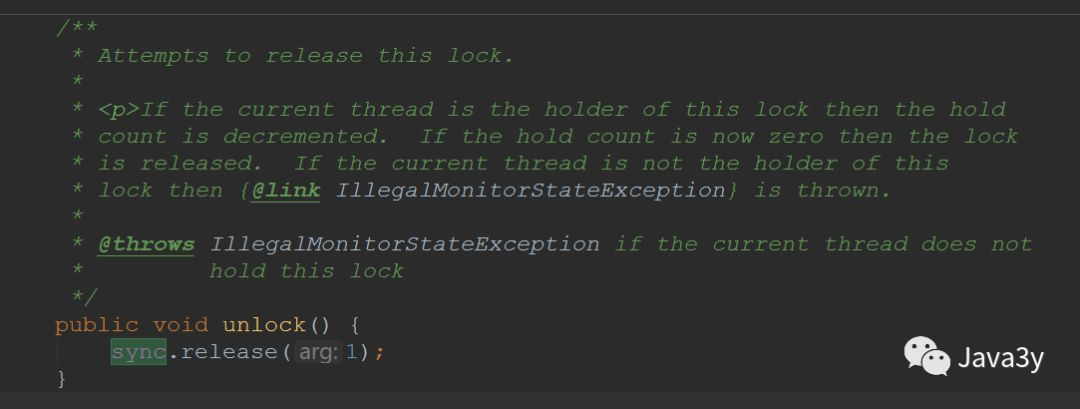
The unlock method is also defined in AQS:
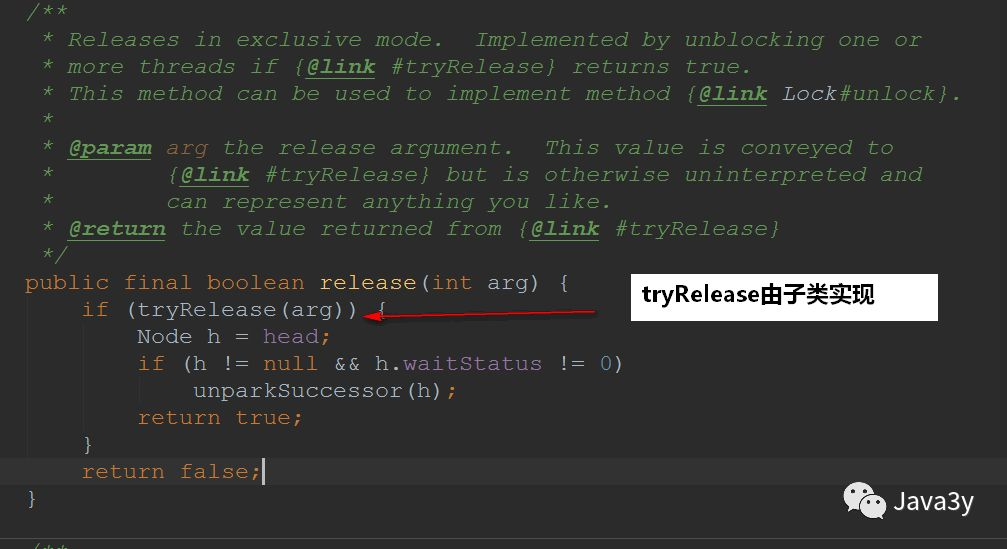
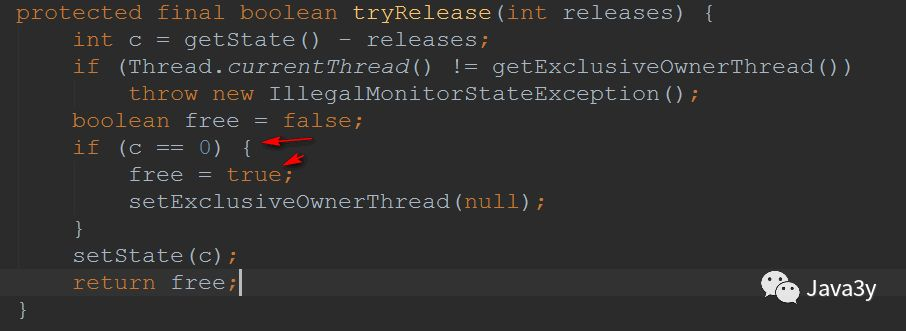
To see how tryRelease(arg) is implemented:
2, ReentrantReadWriteLock
We know that both synchronized built-in lock and ReentrantLock are mutually exclusive locks (only one thread can enter the critical area (locked area) at a time)
ReentrantReadWriteLock is a read-write lock:
-
When reading data, multiple threads can enter the critical area (locked area) at the same time
-
When writing data, both read and write threads are mutually exclusive
Generally speaking: most of us read more data and modify less data. So this read-write lock is very useful in this scenario!
The read-write lock has an interface ReadWriteLock, which defines two methods:
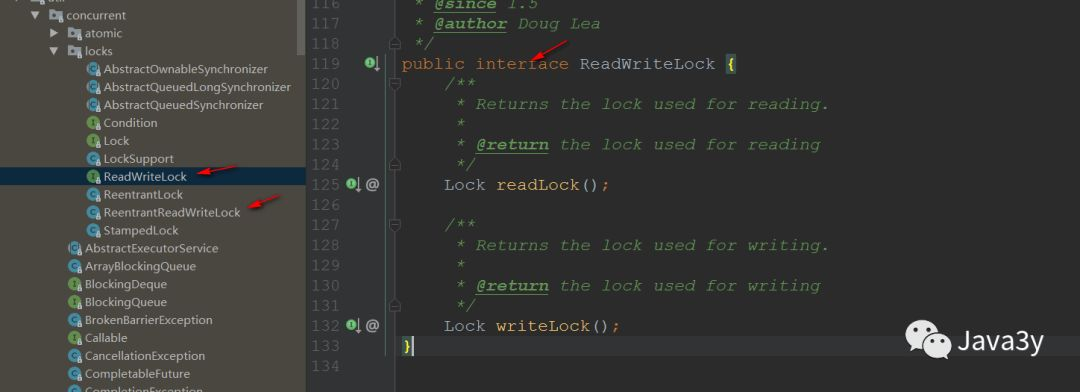
Let's take a look at what the top note says:
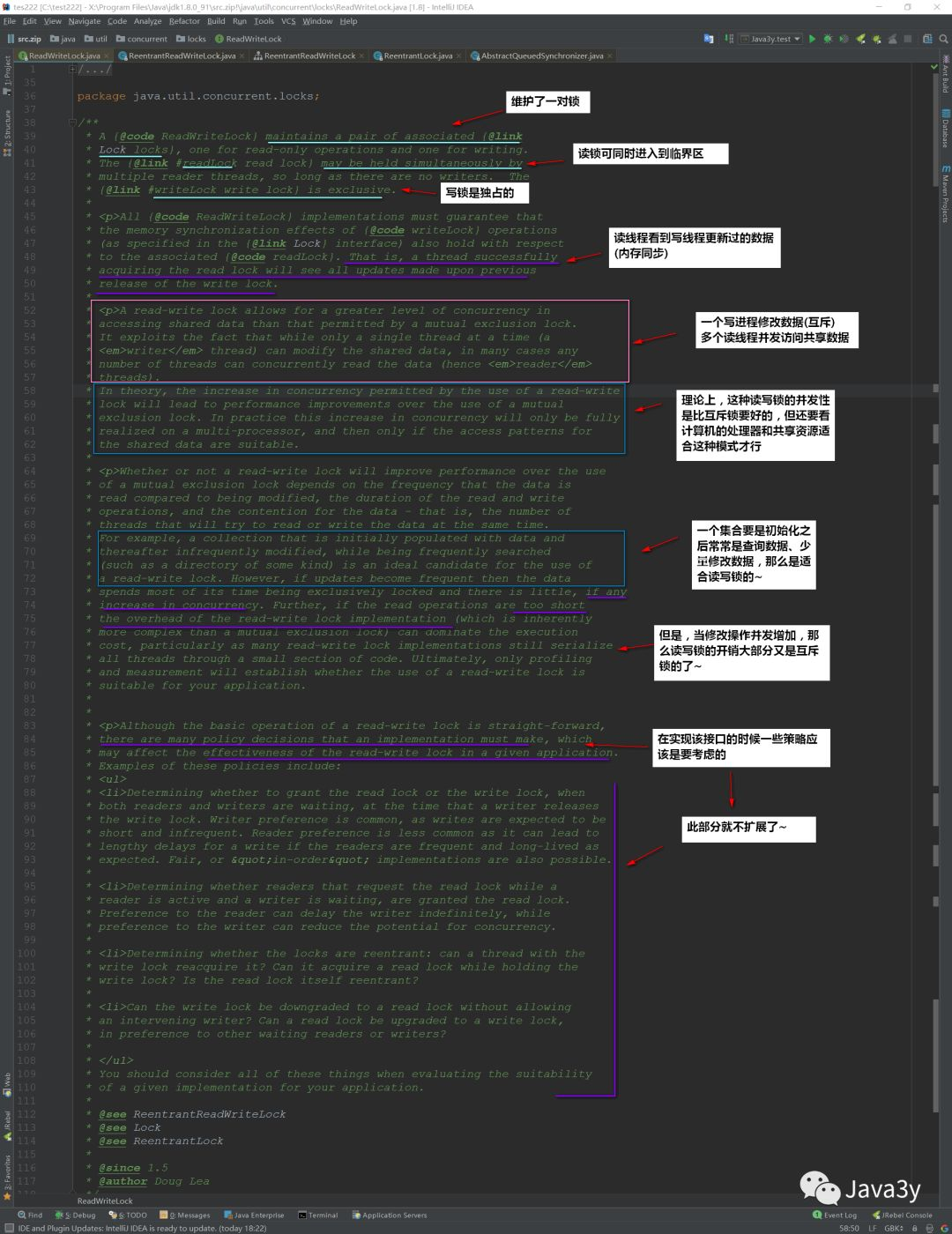
In fact, it probably shows that it can be shared when reading and mutually exclusive when writing
Next, let's take a look at the corresponding implementation classes:
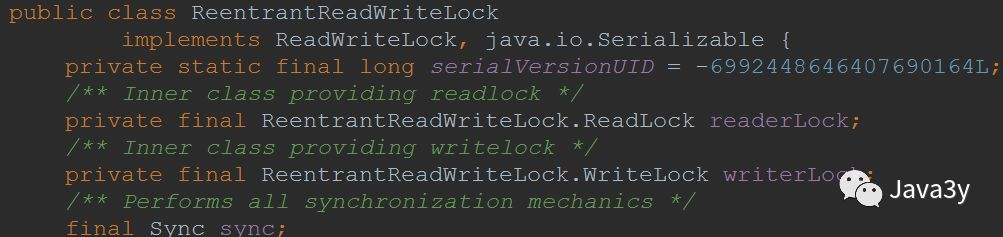
According to the Convention, simply look at its top note:
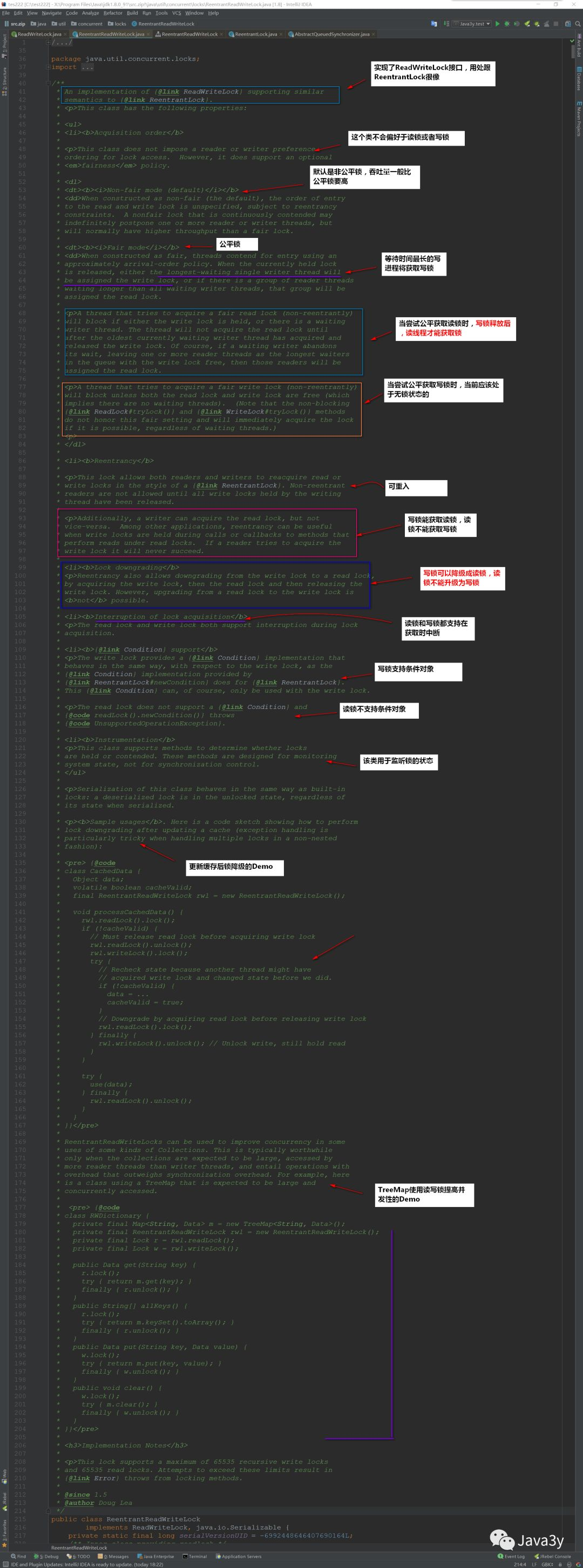
So we can summarize some key points of read-write lock:
-
Read locks do not support condition objects, while write locks support condition objects
-
A read lock cannot be upgraded to a write lock, and a write lock can be downgraded to a read lock
-
Read write locks also have fair and unfair modes
-
Read locks support multiple read threads entering the critical area, and write locks are mutually exclusive
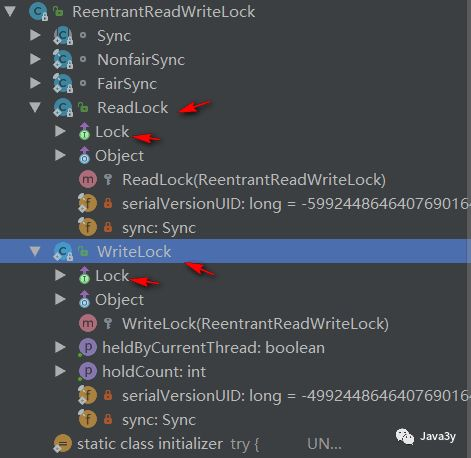
2.1 reentrantreadwritelock internal class
ReentrantReadWriteLock has two more internal classes (both Lock implementations) than ReentrantLock to maintain read and write locks, but the principal still uses Syn:
-
WriteLock
-
ReadLock
2.2 status indication of read lock and write lock
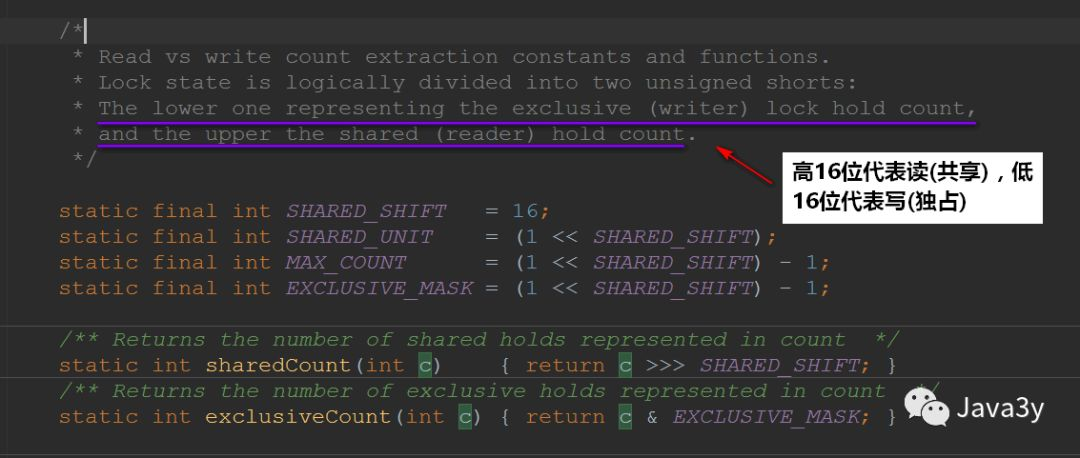
state is used on the ReentrantLock lock to represent the synchronization status (or the number of reentries), while the ReentrantReadWriteLock represents the read-write status as follows:
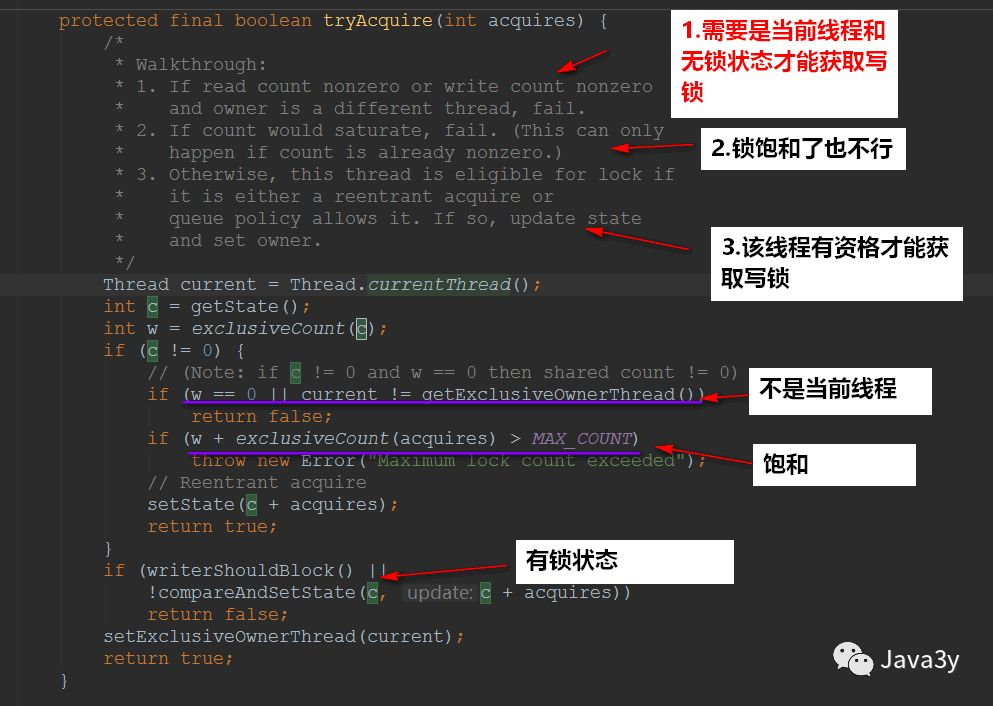
2.3 acquisition of write lock
It mainly calls acquire(1) of syn:

Go in and see the implementation:
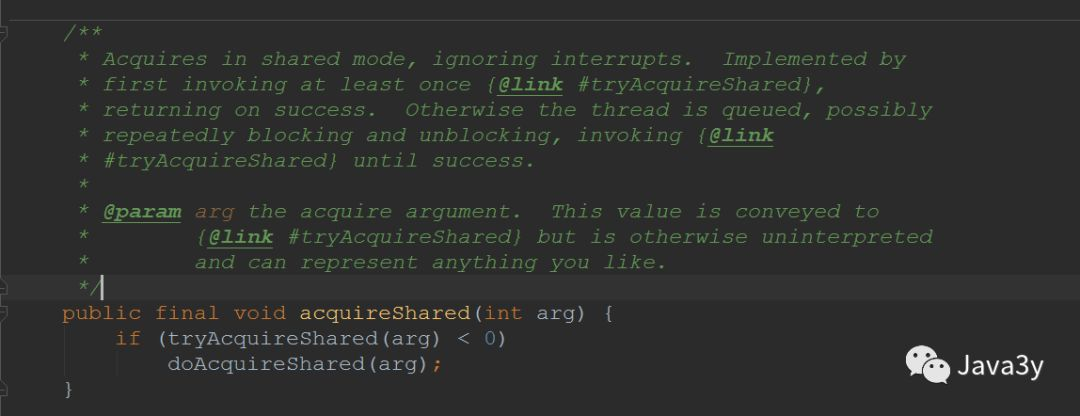
2.4 read lock acquisition
Acquiring a write lock calls the acquireShared(int arg) method:
The internal call is: doAcquireShared(arg); Method (also implemented in Syn), let's take a look at:
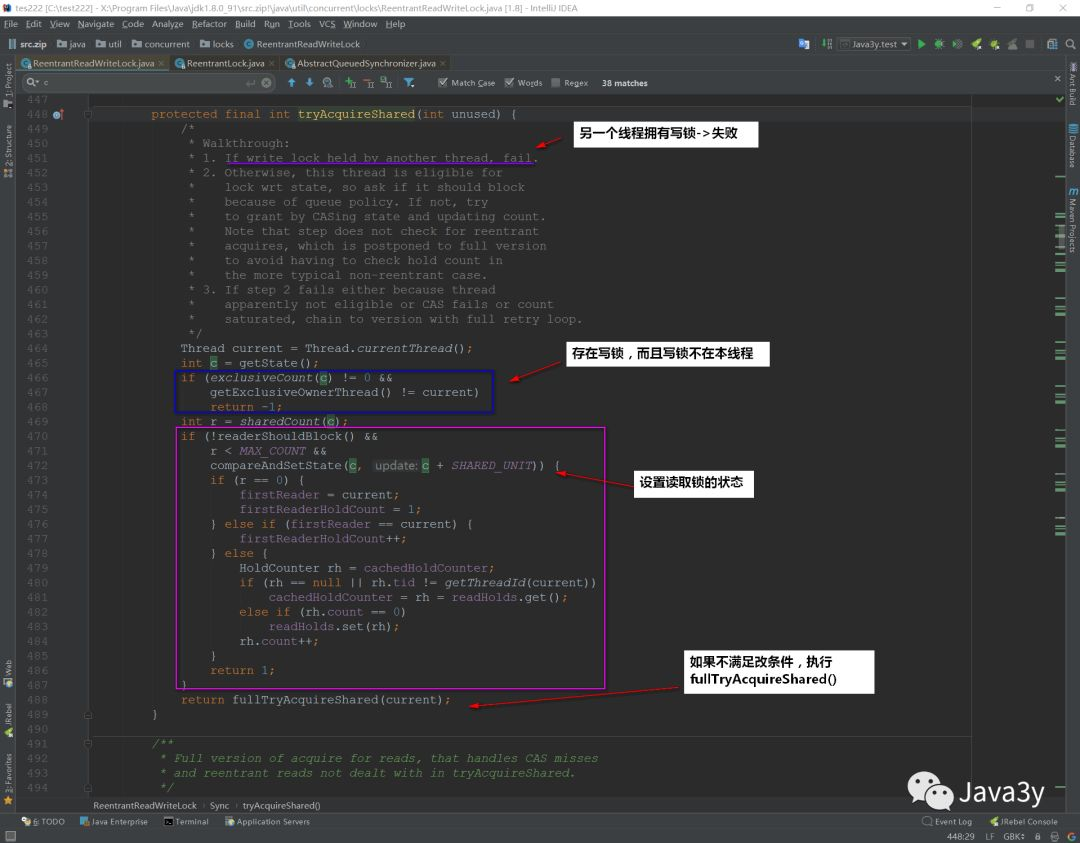
3, Finally
Here is a brief summary of this article:
-
AQS is the basis of ReentrantReadWriteLock and ReentrantLock, because the default implementation is in the internal class Syn, which inherits AQS~
-
Both ReentrantReadWriteLock and ReentrantLock support fair and unfair modes. In fair mode, we will check whether the FIFO queue thread is in the queue head, but not in fair mode
-
ReentrantReadWriteLock is a read-write lock. If there are many more read threads than write threads, you can consider using it. It uses the state variable. The upper 16 bits are read locks and the lower 16 bits are write locks
-
A write lock can be downgraded to a read lock, but a read lock cannot be upgraded to a write lock
-
Write locks are mutually exclusive and read locks are shared.
reference material:
-
http://cmsblogs.com/?page_id=111
7 deadlock explanation
Using multithreading in Java may lead to deadlock. Deadlock will keep the program stuck and no longer execute the program. We can only restart the program by stopping and restarting.
-
This is a phenomenon we don't want to see. We should try our best to avoid deadlock!
The causes of deadlock can be summarized into three sentences:
-
The current thread has resources required by other threads
-
The current thread waits for resources already owned by other threads
-
Do not give up their own resources
1.1 sequence deadlock
First, let's take a look at how the simplest deadlock (lock sequence deadlock) occurs:
public class LeftRightDeadlock {
private final Object left = new Object();
private final Object right = new Object();
public void leftRight() {
// Get left lock
synchronized (left) {
// Get right lock
synchronized (right) {
doSomething();
}
}
}
public void rightLeft() {
// Get right lock
synchronized (right) {
// Get left lock
synchronized (left) {
doSomethingElse();
}
}
}
}
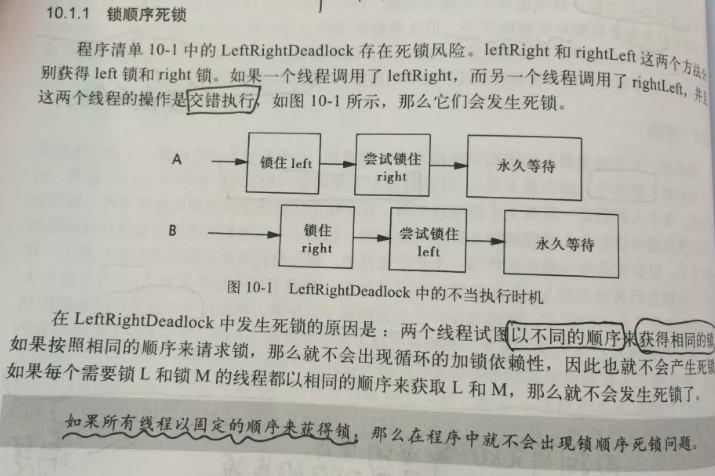
Our threads are interleaved, so the following situations are likely to occur:
-
Thread A calls the leftRight() method to get the left lock
-
At the same time, thread B calls the rightLeft() method to get the right lock
-
Thread A and thread B continue to execute. At this time, thread A needs A right lock to continue to execute. At this point, thread B needs A left lock to continue execution.
-
However, the left lock of thread A is not released, and the right lock of thread B is not released.
-
So they can only wait, and this kind of waiting is indefinite -- > permanent waiting -- > deadlock
1.2 dynamic lock sequence deadlock
Let's take a look at the following example. Do you think there will be a life and death lock?
// transfer accounts
public static void transferMoney(Account fromAccount,
Account toAccount,
DollarAmount amount)
throws InsufficientFundsException {
// Lock remittance account
synchronized (fromAccount) {
// Lock incoming account
synchronized (toAccount) {
// Judge whether the balance is greater than 0
if (fromAccount.getBalance().compareTo(amount) < 0) {
throw new InsufficientFundsException();
} else {
// Deduction from remittance account
fromAccount.debit(amount);
// Increase in incoming account
toAccount.credit(amount);
}
}
}
}</code></pre>
The above code seems to have no problem: lock two accounts to judge whether the balance is sufficient before transferring!
However, it is also possible to deadlock:
-
If two threads call transferMoney() at the same time
-
Thread A transfers money from account X to account Y
-
Thread B transfers money from account Y to account X
-
Then a deadlock will occur.
A:transferMoney(myAccount,yourAccount,10);
B:transferMoney(yourAccount,myAccount,20);
1.3 deadlock between collaboration objects
public class CooperatingDeadlock {
// Warning: deadlock-prone!
class Taxi {
@GuardedBy("this") private Point location, destination;
private final Dispatcher dispatcher;
public Taxi(Dispatcher dispatcher) {
this.dispatcher = dispatcher;
}
public synchronized Point getLocation() {
return location;
}
// setLocation requires Taxi built-in lock
public synchronized void setLocation(Point location) {
this.location = location;
if (location.equals(destination))
// Calling notifyAvailable() requires the Dispatcher built-in lock
dispatcher.notifyAvailable(this);
}
public synchronized Point getDestination() {
return destination;
}
public synchronized void setDestination(Point destination) {
this.destination = destination;
}
}
class Dispatcher {
@GuardedBy("this") private final Set<Taxi> taxis;
@GuardedBy("this") private final Set<Taxi> availableTaxis;
public Dispatcher() {
taxis = new HashSet<Taxi>();
availableTaxis = new HashSet<Taxi>();
}
public synchronized void notifyAvailable(Taxi taxi) {
availableTaxis.add(taxi);
}
// Calling getImage() requires the Dispatcher built-in lock
public synchronized Image getImage() {
Image image = new Image();
for (Taxi t : taxis)
// Calling getLocation() requires a Taxi built-in lock
image.drawMarker(t.getLocation());
return image;
}
}
class Image {
public void drawMarker(Point p) {
}
}
}
Both getImage() and setLocation(Point location) above need to obtain the information of the two locks
-
And the lock is not released during operation
This is the implicit acquisition of two locks (collaboration between objects)
This method can easily cause deadlock
2, Methods to avoid deadlock
Deadlock avoidance can be summarized into three methods:
-
Fixed locking sequence (for deadlock)
-
Open call (for deadlock caused by collaboration between objects)
-
Use timing lock -- > trylock()
-
If the waiting time for obtaining the lock times out, an exception will be thrown instead of waiting all the time!
-
2.1 fixed lock sequence to avoid deadlock
The reason for the deadlock of transferMoney() above is that the locking order is inconsistent~
-
As the book says: if all threads obtain locks in a fixed order, there will be no lock sequence deadlock in the program!
Then we can transform the above example into this:
public class InduceLockOrder {
// Additional locks to avoid two objects with equal hash values (even if few)
private static final Object tieLock = new Object();
public void transferMoney(final Account fromAcct,
final Account toAcct,
final DollarAmount amount)
throws InsufficientFundsException {
class Helper {
public void transfer() throws InsufficientFundsException {
if (fromAcct.getBalance().compareTo(amount) < 0)
throw new InsufficientFundsException();
else {
fromAcct.debit(amount);
toAcct.credit(amount);
}
}
}
// Get the hash value of the lock
int fromHash = System.identityHashCode(fromAcct);
int toHash = System.identityHashCode(toAcct);
// Lock according to the hash value
if (fromHash < toHash) {
synchronized (fromAcct) {
synchronized (toAcct) {
new Helper().transfer();
}
}
} else if (fromHash > toHash) {// Lock according to the hash value
synchronized (toAcct) {
synchronized (fromAcct) {
new Helper().transfer();
}
}
} else {// Additional locks to avoid two objects with equal hash values (even if few)
synchronized (tieLock) {
synchronized (fromAcct) {
synchronized (toAcct) {
new Helper().transfer();
}
}
}
}
}
}
Get the corresponding hash value to fix the locking order, so that we won't have the problem of deadlock!
2.2 open call to avoid deadlock
In the case of deadlock between collaboration objects, the main reason is that when a method is called, it needs to hold the lock, and other locked methods are called inside the method!
-
If you do not need to hold a lock when calling a method, this call is called an open call!
We can transform it in this way:
Synchronous code blocks are best used only to protect operations involving shared state!
class CooperatingNoDeadlock {
@ThreadSafe
class Taxi {
@GuardedBy("this") private Point location, destination;
private final Dispatcher dispatcher;
public Taxi(Dispatcher dispatcher) {
this.dispatcher = dispatcher;
}
public synchronized Point getLocation() {
return location;
}
public synchronized void setLocation(Point location) {
boolean reachedDestination;
// Add Taxi built-in lock
synchronized (this) {
this.location = location;
reachedDestination = location.equals(destination);
}
// The synchronization code block is executed , Release lock
if (reachedDestination)
// Add Dispatcher built-in lock
dispatcher.notifyAvailable(this);
}
public synchronized Point getDestination() {
return destination;
}
public synchronized void setDestination(Point destination) {
this.destination = destination;
}
}
@ThreadSafe
class Dispatcher {
@GuardedBy("this") private final Set<Taxi> taxis;
@GuardedBy("this") private final Set<Taxi> availableTaxis;
public Dispatcher() {
taxis = new HashSet<Taxi>();
availableTaxis = new HashSet<Taxi>();
}
public synchronized void notifyAvailable(Taxi taxi) {
availableTaxis.add(taxi);
}
public Image getImage() {
Set<Taxi> copy;
// Dispatcher built-in lock
synchronized (this) {
copy = new HashSet<Taxi>(taxis);
}
// The synchronization code block is executed , Release lock
Image image = new Image();
for (Taxi t : copy)
// Add Taix built-in lock
image.drawMarker(t.getLocation());
return image;
}
}
class Image {
public void drawMarker(Point p) {
}
}
}
2.3 use timing lock
Use an explicit Lock and use the tryLock() method when acquiring a Lock. When the wait exceeds the time limit, trylock () does not wait all the time, but returns an error message.
Using tryLock() can effectively avoid deadlock~~
2.4 deadlock detection
Although the cause of deadlock is that we don't design well enough, we may not know where the deadlock occurred when writing code.
JDK provides us with two ways to detect:
-
JConsole is a graphical interface tool provided by JDK. We use JConsole, a tool provided by JDK
-
Jstack is a command line tool of JDK, which is mainly used for thread Dump analysis.
For details, please refer to:
-
https://www.cnblogs.com/flyingeagle/articles/6853167.html
3, Summary
Deadlock occurs mainly due to:
-
Interleaving execution between threads
-
Solution: lock in a fixed order
-
-
When executing a method, you need to hold the lock without releasing it
-
Solution: reduce the scope of synchronization code block. It is best to lock only when operating shared variables
-
-
Permanent waiting
-
If the time limit of tryLock() is exceeded, the error is returned
-
Look at deadlock at the operating system level (this is my previous note, very simple):
8 synchronization tool class (auxiliary class)
Java provides us with three synchronization tool classes:
-
Countdownlatch
-
Cyclicbarrier
-
Semaphore
1, CountDownLatch
1.1 introduction to countdownlatch
Simply put: CountDownLatch is a synchronous helper class that allows one or more threads to wait until other threads complete their operations.
In fact, there are only two commonly used API s: await() and countDown()
instructions:
-
Count initializes CountDownLatch, and then the thread that needs to wait calls the await method. The await method is blocked until count=0. When other threads complete their own operations, call countDown() to reduce the counter count by 1. When the count is reduced to 0, all waiting threads will be released
-
To put it bluntly, the wait is controlled through the count variable. If the count value is 0 (the tasks of other threads have been completed), the execution can continue.
1.2CountDownLatch example
Example: 3y is now working as an intern. Other employees haven't finished work yet. 3y is embarrassed to go first. When all other employees are gone, 3y will go again.
import java.util.concurrent.CountDownLatch;
public class Test {
public static void main(String[] args) {
final CountDownLatch countDownLatch = new CountDownLatch(5);
System.out.println("It's six o'clock now.....");
// 3y thread start
new Thread(new Runnable() {
@Override
public void run() {
try {
// await() is called here, not wait()
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("...The other five employees have gone,3y You can finally go");
}
}).start();
// Other employee threads start
for (int i = 0; i < 5; i++) {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("staff xxxx Are you off duty?");
countDownLatch.countDown();
}
}).start();
}
}
}
Output result:
Another example: 3y is now responsible for the warehouse module function, but the ability is too poor and the writing is very slow. Other employees need to wait until 3y is finished before they can continue to write.
import java.util.concurrent.CountDownLatch;
public class Test {
public static void main(String[] args) {
final CountDownLatch countDownLatch = new CountDownLatch(1);
// 3y thread start
new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("3y Finally finished");
countDownLatch.countDown();
}
}).start();
// Other employee threads start
for (int i = 0; i < 5; i++) {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Other employees need to wait 3 y");
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("3y Finally finished,Other employees can start!");
}
}).start();
}
}
}
Output result:
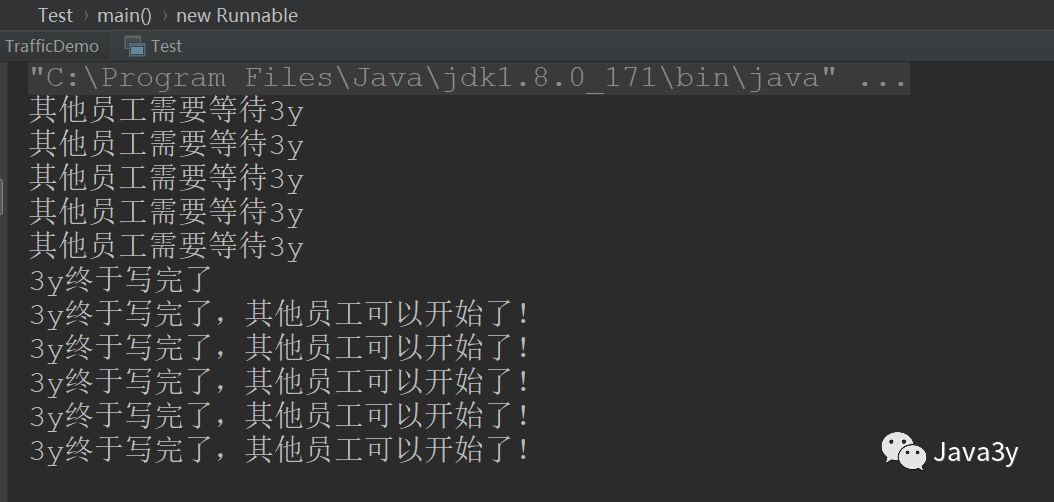
reference material:
-
https://blog.csdn.net/qq_19431333/article/details/68940987
-
https://blog.csdn.net/panweiwei1994/article/details/78826072
-
http://www.importnew.com/15731.html
2, CyclicBarrier
2.1CyclicBarrier introduction
Simply put: CyclicBarrier allows a group of threads to wait for each other until they reach a common barrier point. It is called cyclic because after all waiting threads are released, the CyclicBarrier can be reused (compared with CountDownLatch, which cannot be reused)
2.2CyclicBarrier
Example: 3y and his girlfriend made an appointment to eat in Guangzhou and Shanghai. Because 3y and 3y's girlfriend live in different places, the natural way to go is different. So they agreed to meet at the subway station of TIYU West Road and agreed to send a circle of friends when they met each other.
import java.util.concurrent.BrokenBarrierException; import java.util.concurrent.CyclicBarrier;
public class Test {
public static void main(String[] args) {
final CyclicBarrier CyclicBarrier = new CyclicBarrier(2);
for (int i = 0; i < 2; i++) {
new Thread(() -> {
String name = Thread.currentThread().getName();
if (name.equals("Thread-0")) {
name = "3y";
} else {
name = "girl friend";
}
System.out.println(name + "To Sports West");
try {
// Both of them have to go to the sports west to make a circle of friends
CyclicBarrier.await();
// They arrived at sports west , Saw the other party send a circle of friends :
System.out.println("Follow" + name + "Go to Shanghai to eat at night~");
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}).start();
}
}
}
Test results:
After playing for a day, they returned home, 3y and their girlfriend agreed to chat after taking a bath
import java.util.concurrent.BrokenBarrierException; import java.util.concurrent.CyclicBarrier;
public class Test {
public static void main(String[] args) {
final CyclicBarrier CyclicBarrier = new CyclicBarrier(2);
for (int i = 0; i < 2; i++) {
new Thread(() -> {
String name = Thread.currentThread().getName();
if (name.equals("Thread-0")) {
name = "3y";
} else {
name = "girl friend";
}
System.out.println(name + "To Sports West");
try {
// Both of them have to go to the sports west to make a circle of friends
CyclicBarrier.await();
// They arrived at sports west , Saw the other party send a circle of friends :
System.out.println("Follow" + name + "Go to Shanghai to eat at night~");
// get home
CyclicBarrier.await();
System.out.println(name + "take a shower");
// Chat together after taking a bath
CyclicBarrier.await();
System.out.println("Chat together");
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}).start();
}
}
}
Test results:
reference material:
-
https://blog.csdn.net/panweiwei1994/article/details/78827000
3, Semaphore
3.1 introduction to semaphore
Semaphore is actually the number of threads that can be accessed at the same time. It maintains a set of "licenses".
-
When the acquire() method is called, a license is consumed. If there is no license, it will block up
-
When the release() method is called, a license is added.
-
The number of these "licenses" is actually a count variable~
3.2Semaphore example
3y girlfriend opened a small shop selling yogurt. The shop can only accommodate five customers to choose and buy at a time. If there are more than five, you need to queue up~~~
import java.util.concurrent.Semaphore;
public class Test {
public static void main(String[] args) {
// Suppose 50 people come to the gate of the yogurt store at the same time
int nums = 50;
// The yogurt shop can only accommodate 10 people to choose yogurt at the same time
Semaphore semaphore = new Semaphore(10);
for (int i = 0; i < nums; i++) {
int finalI = i;
new Thread(() -> {
try {
// Yes " No. " You can go to the yogurt store to choose and buy
semaphore.acquire();
System.out.println("customer" + finalI + "In the selection of goods,purchase...");
// Suppose xx is selected for a long time , Bought
Thread.sleep(1000);
// Return a permit , The back can come in and buy
System.out.println("customer" + finalI + "The purchase is finished...");
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
}
Output result:
Anyway, only five customers can buy and choose yogurt stores at the same time.
reference material:
-
https://blog.csdn.net/qq_19431333/article/details/70212663
-
https://blog.csdn.net/panweiwei1994/article/details/78827248
4, Summary
Java provides us with three synchronization tool classes:
-
Countdownlatch
-
A thread waits for other threads to execute before it executes (other threads wait for a thread to execute before it executes)
-
-
Cyclicbarrier
-
A group of threads wait for each other to a certain state, and this group of threads execute at the same time.
-
-
Semaphore
-
Controls the simultaneous execution of a group of threads.
-