ConcurrentHashMap
- I. Overview
- Definition of Concurrent HashMap
- 2.1. Class Definition
- 2.2. Definition of member variables
- 2.3. Definition of paragraph: Segment
- 2.4,HashEntry
- Concurrent HashMap Concurrent Access
- 3.1 JDK 1.7 put(key,value)
- 3.2 JDK1.7 get(key,value)
- 3.3 JDK 1.7 remove
- 3.4 Corcurrent HashMap Access Summary
- JDK 1.8 Concurrent HashMap
I. Overview
Concurrent Map is similar to HashMap. The main difference is that Concurrent HashMap uses segmented locks. Each segmented lock maintains several buckets. Multiple threads can access buckets on different segmented locks at the same time, which makes it more concurrent (concurrency is the number of Segment s).
In Concurrent HashMap, both read and write operations can guarantee high performance: read operations (almost) do not need to be locked, while write operations only lock segments of the operation without affecting client access to other segments. In particular, under ideal conditions, Concurrent HashMap can support 16 threads to perform concurrent write operations (if the concurrency level is set to 16), and any number of threads to read operations;

Concurrent HashMap's efficient concurrency mechanism is as follows:
- Ensuring Write Operation in Concurrent Environment by Lock Segmentation Technology
- Through the invariance of HashEntry, the memory visibility of Volatile variables and lock-and-reread mechanism, efficient and safe reading operations are guaranteed.
- The security of cross-section operation is controlled by two schemes: unlocking and locking.
Definition of Concurrent HashMap
2.1. Class Definition
Concurrent HashMap inherits AbstractMap and implements the Concurrent Map interface:
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V> implements ConcurrentMap<K, V>, Serializable { ... }
2.2. Definition of member variables
Concurrent HashMap adds two attributes to locate segments, segmentMask and segmentShift. The underlying structure of Concurrent HashMap is a Segment array, not an Object array.
final int segmentMask; // For locating segments, the size is equal to the size of the segments array minus 1, which is immutable. final int segmentShift; // For locating segments, the size equals 32 (the number of bits with hash value) minus the size of segments by a pair of values at the bottom of 2, which is immutable. final Segment<K,V>[] segments; // The underlying structure of Concurrent HashMap is a Segment array.
2.3. Definition of paragraph: Segment
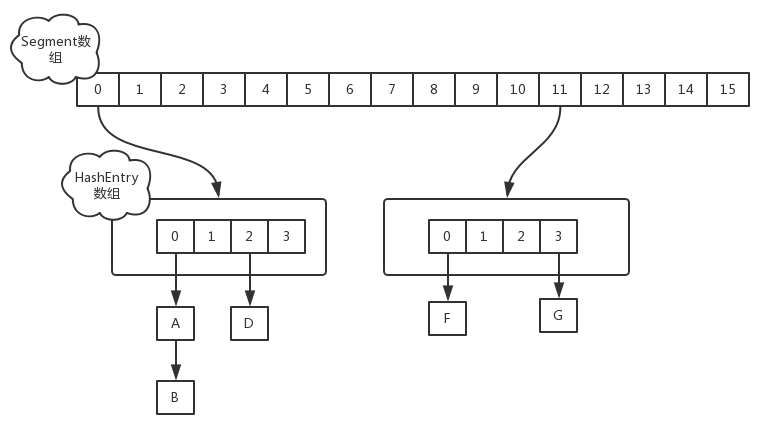
The Segment class inherits from the ReentrantLock class, enabling the Segment object to act as a lock. Each Segment object is used to guard several buckets contained in its member object table. A table is an array of linked lists made up of HashEntry objects, and each group member of the table array is a bucket.
static final class Segment<K,V> extends ReentrantLock implements Serializable { transient volatile int count; // The number of elements in a Segment, visible transient int modCount; //Number of operations (such as put or remove operations) that affect the size of count transient int threshold; // Threshold, when the number of elements in the Segment exceeds this value, Segments will be expanded. transient volatile HashEntry<K,V>[] table; // Link list array; final float loadFactor; // Load factor of segment, whose value is equal to that of Concurrent HashMap }
ConcurretnHashMap allows multiple modification (write) operations to be executed concurrently. The key lies in the use of lock segmentation technology, which uses different locks to control the modification (write) of different parts of the hash table, while Segments are used within Concurrent HashMap to represent these different parts. In fact, each segment is essentially a small hash table, and each segment has its own lock (the Segment class inherits the ReentrantLock class). In this way, as long as multiple modification (write) operations occur on different segments, they can be performed concurrently. After inserting three HashEntry nodes of ABC in turn, the following schematic diagram of Segment structure is shown:
2.4,HashEntry
HashEntry is also an encapsulated key-value pair, including key, hash, value and next, where key, hash, next are declared final and the value field is modified by volatile, so the HashEntry object is almost immutable, which is why ContHashMap does not need to be locked.
The next field is declared final, which means that nodes can only be inserted from the head of the list.
value is decorated with volatile to ensure that threads can read the latest values, which is also why locks are not required.
static final class HashEntry<K,V> { final int hash; final K key; volatile V value; volatile HashEntry<K,V> next; }
Concurrent HashMap Concurrent Access
In Concurrent HashMap, when a thread reads a mapping table, it can usually be completed without locking, and only when the container is structurally modified (e.g., put operation, remove operation, etc.) needs locking.
3.1 JDK 1.7 put(key,value)
The concurrent write operation among multiple threads is realized by the segment ed table. Firstly, it locates the HashEntry through the hashcode of the key, traverses the key value and overrides the corresponding value. If it is not found, it adds an Entry to the head.
Before inserting Key/Value pairs into Concurrent HashMap using put operation, we first check whether this insertion will cause the number of nodes in Segment to exceed threshold. If so, we first expand and re-hash Segment. In particular, it should be noted that the re-hashing of Concurrent HashMap is actually a re-hashing of a section of Concurrent HashMap.
public V put(K key, V value) { if (value == null) //The key and value are not allowed to be null in Concurrent HashMap. throw new NullPointerException(); int hash = hash(key.hashCode()); //Compute the corresponding HashCode return segmentFor(hash).put(key, hash, value, false); //Find the corresponding segment according to HashCode } final Segment<K,V> segmentFor(int hash) { //Move the segmentShift bit unsigned to the right according to the incoming HashCode, and then work with the segmentMask return segments[(hash >>> segmentShift) & segmentMask]; } V put(K key, int hash, V value, boolean onlyIfAbsent) { lock(); // Lock the current segment try { int c = count; if (c++ > threshold) // If the threshold is exceeded rehash();//Double hashing, doubling the length of the table array HashEntry<K,V>[] tab = table; // table is Volatile // Locate to a particular bucket in the segment //Reduce the hash value and the length of the table by 1, and take "and" int index = hash & (tab.length - 1); HashEntry<K,V> first = tab[index]; // first points to the head of the list in the bucket HashEntry<K,V> e = first; // Check if there are nodes with the same key in the bucket while (e != null && (e.hash != hash || !key.equals(e.key))) e = e.next; V oldValue; if (e != null) { // There are nodes with the same key in the bucket oldValue = e.value; if (!onlyIfAbsent) e.value = value; // Update value }else { // There are no nodes with the same key in the bucket oldValue = null; ++modCount; // Add new nodes to the list, modCount plus 1 // Create HashEntry and link it to the header of the table tab[index] = new HashEntry<K,V>(key, hash, first, value); count = c; //write-volatile, the update of count value must be in the last step (volatile variable) } return oldValue; // Returns the old value (null if there is no node with the same key in the bucket) } finally { unlock(); // Unlock in the final clause } }
3.2 JDK1.7 get(key,value)
Instead of using lock synchronization, we just get whether the value of Entry is null or not. For null, we retrieve it again by locking, that is, lock re-reading.
public V get(Object key) { int hash = hash(key.hashCode()); return segmentFor(hash).get(key, hash); } V get(Object key, int hash) { if (count != 0) { // read-volatile, first read the count variable HashEntry<K,V> e = getFirst(hash); // Getting the list head node in bucket while (e != null) { if (e.hash == hash && key.equals(e.key)) { // Find if there is a key-value pair for the specified Key in the chain V v = e.value; if (v != null) // If you read that the value field is not null, return directly return v; // If you read that the value field is null, it means that a reordering has taken place and that it is read again after locking. return readValueUnderLock(e); // recheck } e = e.next; } } return null; // If not, return null directly } //Locked Reread Source: V readValueUnderLock(HashEntry<K,V> e) { lock(); try { return e.value; } finally { unlock(); } }
3.3 JDK 1.7 remove
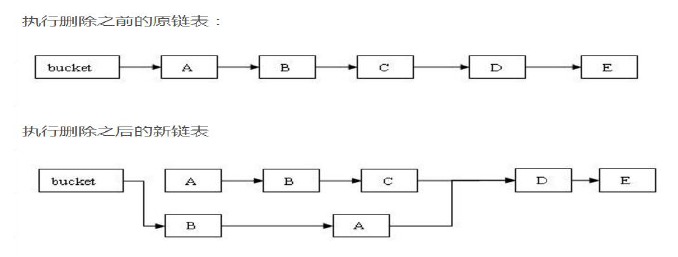
In Segmen, remote also finds specific linked list according to hash code, and then traverses the linked list to find the nodes to be deleted. Finally, all the nodes after the nodes to be deleted are kept in the new linked list, and the nodes before the nodes to be deleted are cloned into the new linked list.
public V remove(Object key) { int hash = hash(key.hashCode()); return segmentFor(hash).remove(key, hash, null); } V remove(Object key, int hash, Object value) { lock(); // Lock up try { int c = count - 1; HashEntry<K,V>[] tab = table; int index = hash & (tab.length - 1); // Positioning barrel HashEntry<K,V> first = tab[index]; HashEntry<K,V> e = first; while (e != null && (e.hash != hash || !key.equals(e.key))) // Find key-value pairs to be deleted e = e.next; V oldValue = null; if (e != null) { // find V v = e.value; if (value == null || value.equals(v)) { oldValue = v; // All entries following removed node can stay // in list, but all preceding ones need to be // cloned. ++modCount; // All nodes after the nodes to be deleted remain in the list as they are. HashEntry<K,V> newFirst = e.next; // All nodes before the node to be deleted are cloned into the new list for (HashEntry<K,V> p = first; p != e; p = p.next) newFirst = new HashEntry<K,V>(p.key, p.hash,newFirst, p.value); tab[index] = newFirst; // Re-place the chain after deleting the specified node and reorganizing it into the bucket count = c; // write-volatile, update Volatile variable count } } return oldValue; } finally { unlock(); // Final clause unlock } }
3.4 Corcurrent HashMap Access Summary
When accessing Concurrent HashMap, the specific segment is located first, and then the whole Concurrent HashMap is accessed by accessing the specific segment. In particular, both read and write operations of Concurrent HashMap have high performance: there is no need to lock the read operation, while in write operation, only the segment of operation is locked by lock segmentation technology without affecting the client's access to other segments.
JDK 1.8 Concurrent HashMap
From RentrantLock + Segment + HashEntry in JDK version 1.7 to synchronized+CAS+HashEntry + red-black tree in JDK version 1.8, Concurrent HashMap only adds synchronized operations to control concurrency.
-
The implementation of JDK 1.8 reduces the granularity of locks. The granularity of JDK 1.7 locks is based on Segment s and contains multiple HashEntry, while the granularity of JDK 1.8 locks is HashEntry (the first node).
-
JDK 1.8 version of the data structure becomes simpler, making the operation clearer and smoother. Because synchronized synchronization has been used for synchronization, the concept of segmented lock is not needed, and the data structure of Segment is not needed. Because of the reduction of granularity, the complexity of implementation is also increased.
-
JDK 1.8 uses red-black tree to optimize the list. Traversing a long list is a long process, and the traversal efficiency of red-black tree is very fast, instead of a certain threshold list.
-
Why JDK 1.8 uses built-in lock synchronized instead of re-entry lock ReentrantLock:
1. In relatively low-granularity locking mode, synchronized is not inferior to ReentrantLock. In coarse-granularity locking, ReentrantLock may control all low-granularity boundaries through Conditions, which is more flexible. In low-granularity, Conditions have no advantage.
2. synchronized optimization based on JVM has larger space, and using embedded keywords is more natural than using API.
3. For the memory pressure of JVM, RentrantLock based on API will spend more memory under a large number of data operations. Although it is not a bottleneck, it is also a choice basis.Structure of 1.7 and 1.8
In version 1.7 of JDK, the data structure of Concurrent HashMap consists of a Segment array and multiple HashEntries:
In JDK 1.8:
The first improvement is to cancel the segments field, directly use transient volatile HashEntry < K, V > [] table to save data, and use table array elements as locks, thus realizing the locking of each row of data, further reducing the probability of concurrent conflicts;
Improvement 2: Change the original table array + one-way linked list data structure to table array + one-way linked list + red-black tree structure. For hash tables, the core capability is to distribute keyhash evenly in arrays. If the hash is homogeneous after hash, the length of each queue in the table array is mainly 0 or 1. However, the actual situation is not always so ideal. Although the default load factor of Concurrent HashMap class is 0.75, there are still some cases where the queue length is too long in the case of too much data or bad luck. If the one-way list is still used, the time complexity of querying a node is O(n). Therefore, when the number of lists exceeds 8 (default value), the structure of red-black tree is adopted in jdk1.8, so the query time complexity can be reduced to O(logN), which can improve the performance.

JDK 1.8 put
public V put(K key, V value) { return putVal(key, value, false); } /** Implementation for put and putIfAbsent */ final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); int hash = spread(key.hashCode()); //Two hash, reduce hash conflict, and distribute evenly int binCount = 0; for (Node<K,V>[] tab = table;;) { //Iterate the table Node<K,V> f; int n, i, fh; //Here is the above method of construction is not initialized, here to judge, for null call initTable initialization, belongs to lazy mode initialization. if (tab == null || (n = tab.length) == 0) tab = initTable(); else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {//If there is no data in the i position, insert directly without a lock if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } else if ((fh = f.hash) == MOVED)//If the expansion is carried out, the expansion operation is carried out first. tab = helpTransfer(tab, f); else { V oldVal = null; //If none of the above conditions are satisfied, then lock operation is necessary, that is, there is a hash conflict, lock the head node of the chain or the red-black tree. synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0) { //Represents that the node is a linked list structure binCount = 1; for (Node<K,V> e = f;; ++binCount) { K ek; //Here, put ting the same key overrides the original value if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } Node<K,V> pred = e; if ((e = e.next) == null) { //Insert the end of the list pred.next = new Node<K,V>(hash, key, value, null); break; } } } else if (f instanceof TreeBin) {//Red-black tree structure Node<K,V> p; binCount = 2; //Rotating insertion of red-black tree structure if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) { //If the length of the linked list is greater than 8, the red-black tree will be converted. if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } addCount(1L, binCount);//Statistical size and check for expansion return null; }
1. If there is no initialization, call the initTable () method first to initialize the process.
2. Direct CAS insertion without hash conflict
3. If the expansion operation is still in progress, the first step is to expand the capacity.
4. If there is hash conflict, lock to ensure thread safety. There are two cases: one is that the linked list form is directly traversed to the end of insertion, the other is that the red-black tree is inserted according to the structure of the red-black tree.
5. Finally, if the number of linked lists is greater than the threshold 8, the structure of the black mangrove must be transformed first, and the break enters the loop again.
6. If the addition is successful, call the addCount () method to count the size and check if the expansion is needed
JDK1.8 get
public V get(Object key) { Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek; int h = spread(key.hashCode()); //Calculate hash twice if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1) & h)) != null) {//Read the Node element of the first node if ((eh = e.hash) == h) { //If the node is the first node, it returns if ((ek = e.key) == key || (ek != null && key.equals(ek))) return e.val; } //The hash value is negative, indicating that the expansion is under way. At this time, look up ForwardingNode's find method to locate the next table. //Find, find and return else if (eh < 0) return (p = e.find(h, key)) != null ? p.val : null; while ((e = e.next) != null) {//Neither the first node nor Forwarding Node, traverse down if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek)))) return e.val; } } return null; }
get process:
1. Calculate the hash value, locate the table index position, and return if the first node matches.
2. When encountering expansion, the find method flagged ForwardingNode is invoked to find the node, and the match returns.
3. If none of the above is true, traverse the nodes down, and the matching returns, otherwise it returns to null.