If a crawler wants to crawl the required information, the first step is to grab the html content of the page, and then analyze the html to get the desired content. Last essay< Java Crawler Series 1: Write Before Starting > It is mentioned that HttpClient can crawl page content.
Today, let's introduce the tool for grabbing html content: HttpClient.
Around the following points:
-
What is HttpClient
-
Introduction to HttpClient
- Complex application
-
Concluding remarks
I. What is HttpClient
Du Niang said:
HttpClient is a sub-project of Apache Jakarta Common. It can be used to provide an efficient, up-to-date and feature-rich client programming toolkit supporting HTTP protocol, and it supports the latest version and recommendations of HTTP protocol. The main functions provided by HttpClient are listed below. For more details, see the official website of HttpClient. (1) Implementation of all HTTP methods (GET,POST,PUT,HEAD, etc.) (2) Support automatic steering (3) Support HTTPS protocol (4) Supporting proxy servers, etc.
The official website is mentioned here, so by the way, there are some things on its official website.
According to Baidu's HomePage, this is: http://hc.apache.org/httpclient-3.x/ But when you enter, you will find a sentence
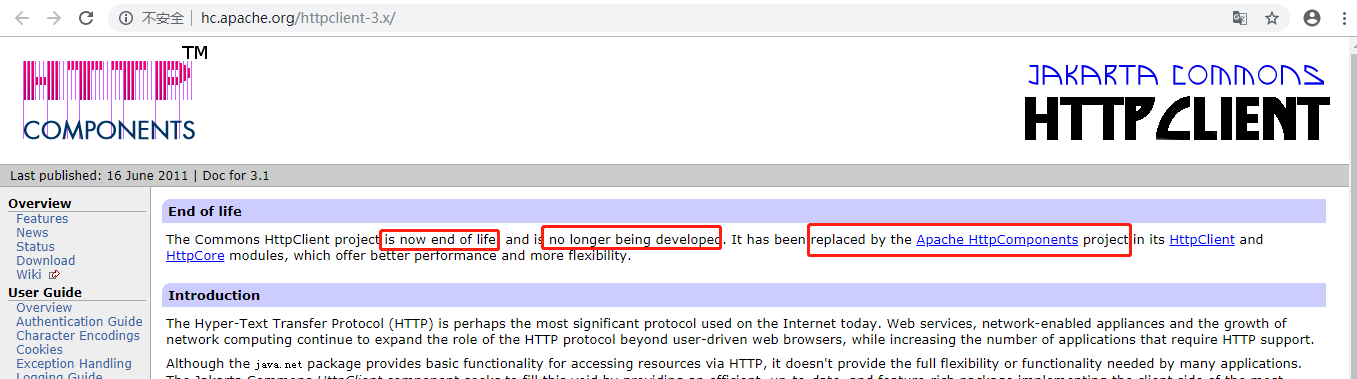
The Commons HttpClient project is no longer maintained and has been replaced by Apache HttpComponents. That is to say, we will use new ones if we want to use them later. Click on this link to Apache Http Components to see its latest version, 4.5, with quick-start examples and professional documentation. Interested and good English friends can study it well.~~
Er ~ ~ That ~ ~ My English is not good, so I don't follow the official website and give my own practice cases of online learning directly.~~
2. An Introduction to HttpClient
- Create a new normal maven project: My name is casual, my name is httpclient_learn
- Modify the pom file to introduce dependencies
<dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.8</version> </dependency>
- New java class
package httpclient_learn; import java.io.IOException; import org.apache.http.HttpEntity; import org.apache.http.HttpStatus; import org.apache.http.client.ClientProtocolException; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.client.utils.HttpClientUtils; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; public class HttpClientTest { public static void main(String[] args) { //1.generate httpclient,It's equivalent to opening a browser CloseableHttpClient httpClient = HttpClients.createDefault(); CloseableHttpResponse response = null; //2.Establish get Request, equivalent to entering a web address in the browser address bar HttpGet request = new HttpGet("https://www.tuicool.com/"); try { //3.implement get Request, equivalent to typing the Enter key after entering the address bar response = httpClient.execute(request); //4.Judge the response state to be 200 and process it. if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) { //5.Getting response content HttpEntity httpEntity = response.getEntity(); String html = EntityUtils.toString(httpEntity, "utf-8"); System.out.println(html); } else { //If the return status is not 200, such as 404 (page does not exist) and so on, do the processing according to the situation, here is omitted. System.out.println("Return status is not 200"); System.out.println(EntityUtils.toString(response.getEntity(), "utf-8")); } } catch (ClientProtocolException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { //6.Close HttpClientUtils.closeQuietly(response); HttpClientUtils.closeQuietly(httpClient); } } }
- To execute the code, we will find that the printed html code is actually the complete html code on the home page.
<!DOCTYPE html> <html lang="zh-cn"> <head> //Note to the old rookie in Java development: Because of too much content, the details are no longer posted. </head> <body>//Note to the old rookie in Java development: Due to too much content, the specific content is no longer posted.
</body> </html>
Successful operation!
Well, here's a simple example.
Climbing a website is not an addiction. Let's do another dozen. Next, let's change the website: https://www.tuicool.com/ You will find that the result is as follows:
Return status is not 200
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
</head>
<body>
<p> System detection of relatives is not a real person behavior, due to system resource constraints, we can only refuse your request. If you have any questions, you can contact us at http://weibo.com/tuicool2012/. </p>
</body>
</html>
The crawler program has been identified. What can we do? Don't worry. Look down slowly.
3. Complex Applications
The second website can not be visited, because the website has anti-crawler processing, how to bypass him?
1. The simplest way is to disguise the request header, look at the code, and add the contents in the red box before execution.
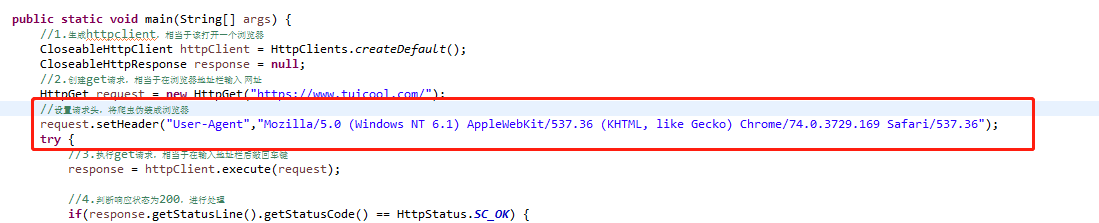
You'll find that the return results have changed, and there's real content (red letter warning, regardless of it, we've got at least html content)
Where did the new section of the code come from?
Please open F12 of Google Browser, right here it is:
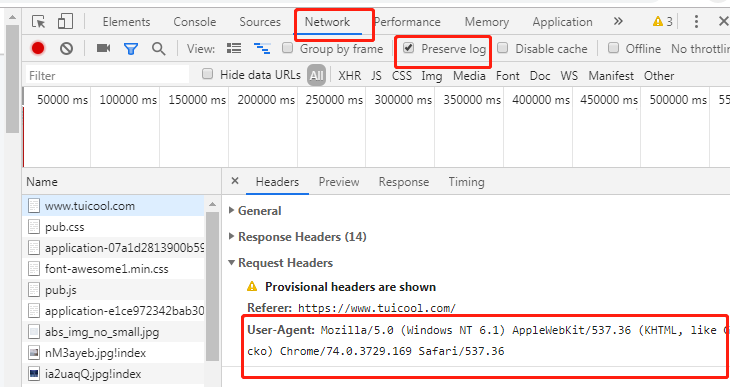
Of course, we can also set other header information requested, such as cookie s, etc.
2. The above is disguised as a browser. In fact, if you disguise it and visit it many times in a short time, the website will block your ip. At this time, you need to change your IP address and use proxy IP.
There are some free proxy ip websites on the internet, such as xici

We chose IPS that had survived for a long time and had just been verified. I chose "112.85.168.223:9999" here. The code is as follows.
//2.Establish get Request, equivalent to entering a web address in the browser address bar HttpGet request = new HttpGet("https://www.tuicool.com/"); //Set the request header to disguise the crawler as a browser request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"); HttpHost proxy = new HttpHost("112.85.168.223", 9999); RequestConfig config = RequestConfig.custom().setProxy(proxy).build(); request.setConfig(config);
Execute the code and return the html result normally. If the proxy ip just doesn't work, it will report an error. The following shows that the connection timeout, at this time a new proxy ip needs to be replaced.
3. In addition, the program is identified because too many visits are made in a short time, which is a frequency that normal people will not have, so we can also slow down the crawling speed, let the program sleep for a period of time to crawl next is also a simple anti-crawler method.
IV. Concluding remarks
This article briefly introduces httpclient and its official website, and explains how to use it with code. It also mentions that if we encounter anti-crawler, we can use some simple anti-crawler methods to deal with it.
I haven't studied any other complex anti-reptilian methods, which are used in combination. For example, after climbing for a period of time, the website needs to input validation code to verify that people are operating. I don't care how to break through the validation code. Instead, I get the proxy ip pool and change the ip one by one when encountering the validation code, so that I can avoid the validation code. If there are other ways, please leave a message.