preface
The difference between ArrayList and LinkedList is often mentioned. A clear understanding of the difference between them is helpful to consolidate their basic development skills. Choosing the right data structure in the right place can help them write more high-quality code. Combined with their source code, this paper analyzes their composition and difference.
1, Basic structure
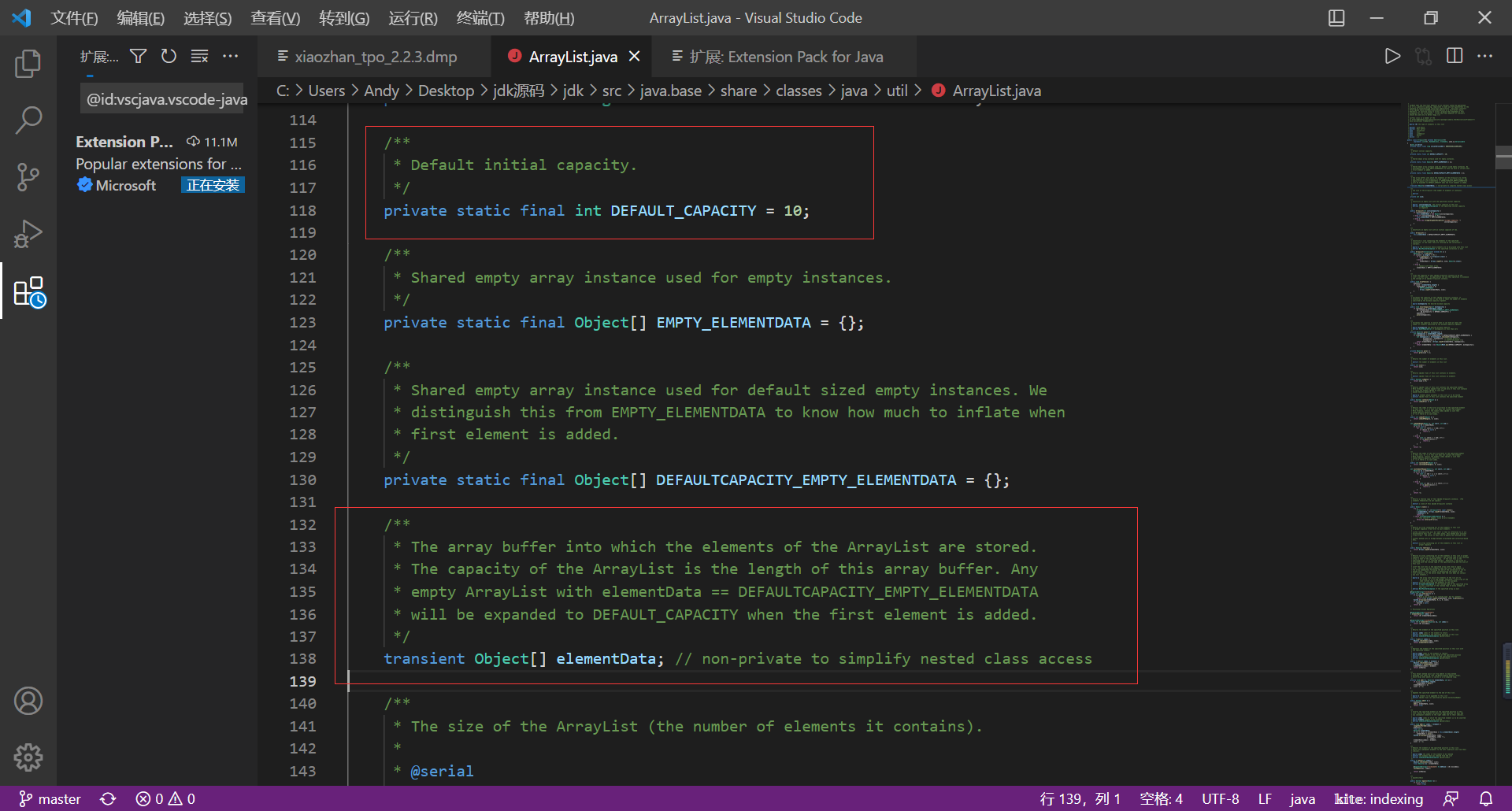
ArrayList
ArrayList is implemented based on dynamic data (sequence table), and the default storage capacity is 10
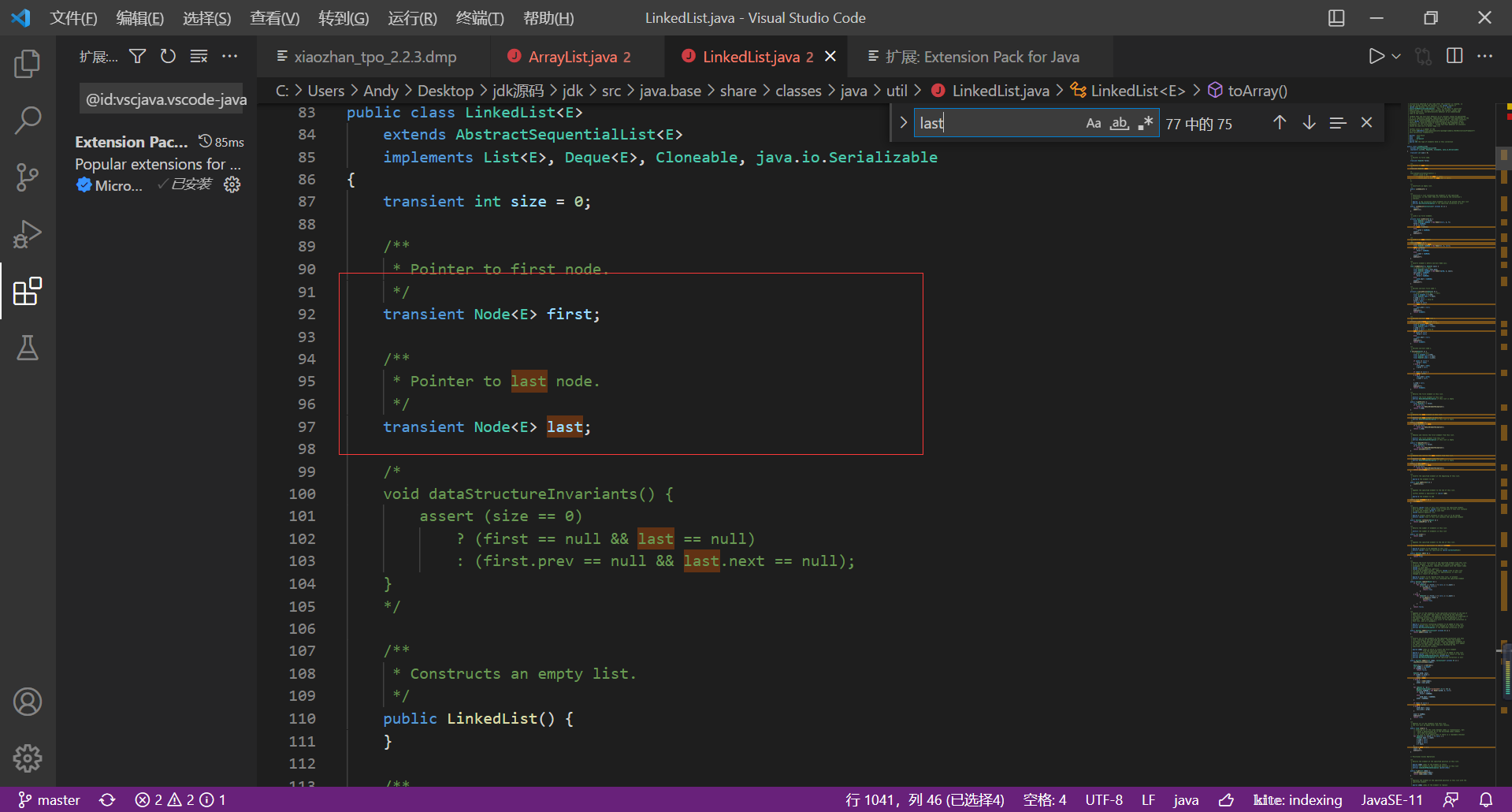
LinkedList
LinkedList is implemented based on the data structure of bidirectional linked list, with head and tail pointers, and a single node has prev pointer and next pointer
2, Addition, deletion, modification and query (CRUD)
1.ArrayList
increase
/**
* This helper method split out from add(E) to keep method
* bytecode size under 35 (the -XX:MaxInlineSize default value),
* which helps when add(E) is called in a C1-compiled loop.
*/
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
* @throws OutOfMemoryError if minCapacity is less than zero
*/
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length;
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, /* minimum growth */
oldCapacity >> 1 /* preferred growth */);
return elementData = Arrays.copyOf(elementData, newCapacity);
} else {
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
}
}
private Object[] grow() {
return grow(size + 1);
}
As we all know, if the value added to an array exceeds the boundary, it is necessary to expand the capacity of the array; Let's assume that there is an ArrayList. Now the elements in it are full, and then we try to add elements to it. At this time, we will call the add() function. Then, according to the source code I added above, the add function will call the grow() function, so we will analyze the grow function.
Then we can see that there may be two situations when calling the add function:
1. There are no elements in the original list (uninitialized), and a new sequence table is directly generated. The size is the maximum of the default size and the added element size
2. There are elements in the original list. At this time, two tasks need to be completed
- Expand the capacity of the original dynamic array
- Add the elements of the original dynamic array to the new dynamic array
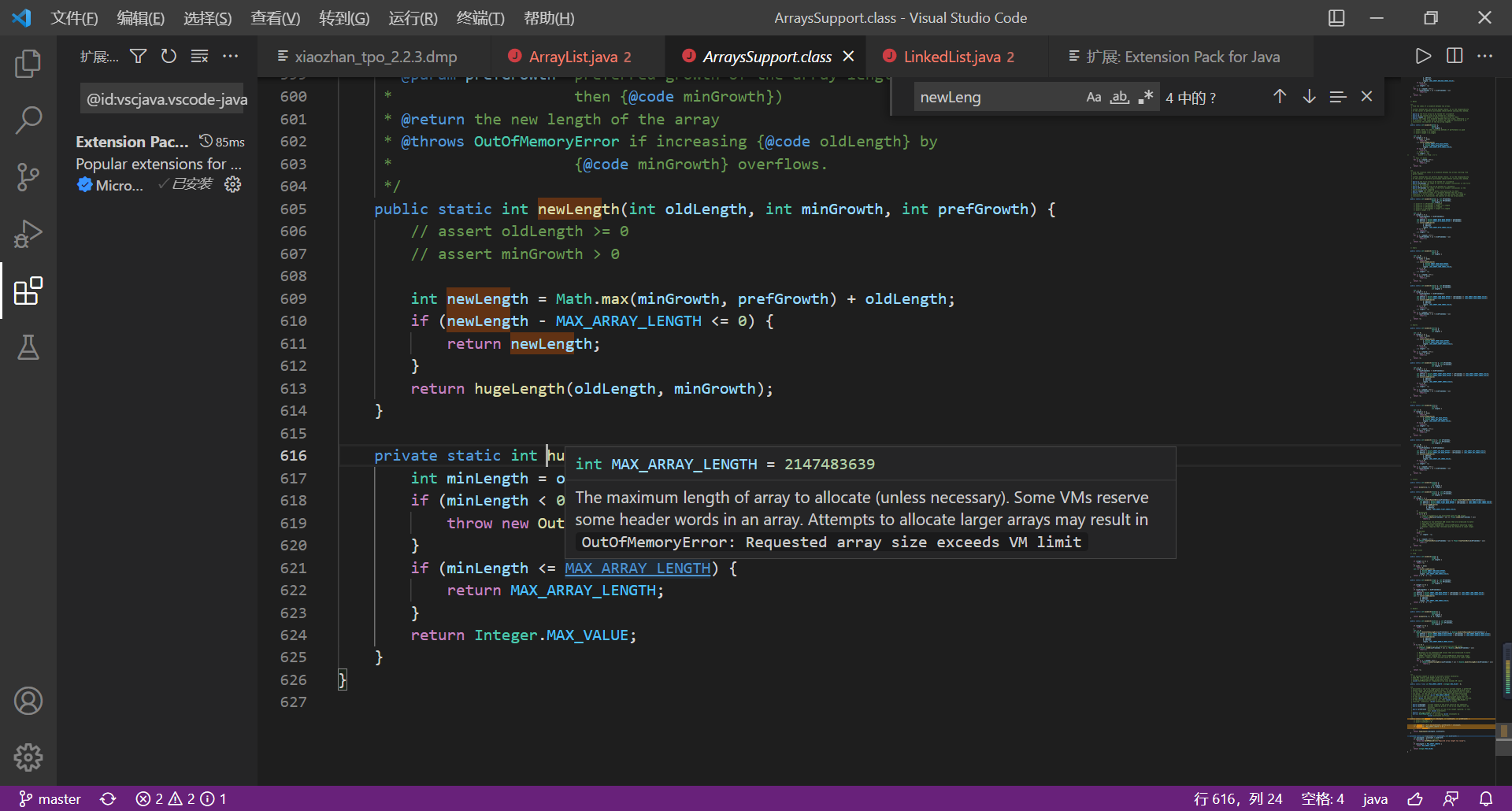
The second step is nothing more than O(n) level replication. Here we focus on what happens in the step of capacity expansion, that is, calling arrayssupport What happened in the step of newlength (), let's take a look at the source code;
public static int newLength(int oldLength, int minGrowth, int prefGrowth) {
// assert oldLength >= 0
// assert minGrowth > 0
int newLength = Math.max(minGrowth, prefGrowth) + oldLength;
if (newLength - MAX_ARRAY_LENGTH <= 0) {
return newLength;
}
return hugeLength(oldLength, minGrowth);
}
private static int hugeLength(int oldLength, int minGrowth) {
int minLength = oldLength + minGrowth;
if (minLength < 0) { // overflow
throw new OutOfMemoryError("Required array length too large");
}
if (minLength <= MAX_ARRAY_LENGTH) {
return MAX_ARRAY_LENGTH;
}
return Integer.MAX_VALUE;
}
Seeing this, we are suddenly enlightened. We also feel the good intentions of the Java language designer and contact the two parameters passed in the growth () function above
- minCapacity - oldCapacity
- Oldcapacity > > 1 / / shift right to get half the original length
As we can see, there are two cases of generating new lengths here
First, take the maximum value that the newly added length is half of the value added to the element and the length of the original dynamic array - If the newly added length is less than the assignable length, the newly added length will be expanded directly
- If the newly added length is greater than the allocable length, the minimum allocation length minGrowth is taken. For example, if only 1 is added to the array at this time, but according to the first allocation method, expand half of the original dynamic array beyond the memory allocation space, select only minLength to 1, and the result is to expand the dynamic array to the maximum length
So what is the maximum value of dynamic array length? We can see that it is Integer MAX_ Value is the upper bound of Integer length. As for the reason, the author understands that dynamic arrays are collected with Integer as the following table. If it is exceeded, unpredictable errors will occur.
If you want to enlarge it, you can change Integer to other data types and regenerate your own data structure. Of course, this involves many application problems, which I won't repeat here.
Delete
/**
* Removes the element at the specified position in this list.
* Shifts any subsequent elements to the left (subtracts one from their
* indices).
*
* @param index the index of the element to be removed
* @return the element that was removed from the list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E remove(int index) {
Objects.checkIndex(index, size);
final Object[] es = elementData;
@SuppressWarnings("unchecked") E oldValue = (E) es[index];
fastRemove(es, index);
return oldValue;
}
/**
* Private remove method that skips bounds checking and does not
* return the value removed.
*/
private void fastRemove(Object[] es, int i) {
modCount++;
final int newSize;
if ((newSize = size - 1) > i)
System.arraycopy(es, i + 1, es, i, newSize - i);
es[size = newSize] = null;
}
Here, the method of overwrite deletion is adopted, that is, the elements on the right of the i node to be deleted are moved uniformly by Copy, and the time complexity is O(n);
check
Query is a relatively simple part, because ArrayList is an index based data interface, and its bottom layer is a dynamic array similar to sequential table. It can randomly access elements with O(1) time complexity.
change
In fact, change is the same as query. Based on the structure of sequence table, these two operations are very simple, and there is no major optimization direction for optimization. Just look at the source code directly
public E set(int index, E element) {
Objects.checkIndex(index, size);
checkForComodification();
E oldValue = root.elementData(offset + index);
root.elementData[offset + index] = element;
return oldValue;
}
We can see that the validity of the input data is checked first, and then the consistency of the two threads of modification and query is guaranteed by checkForComodification(), and finally the modification is made.
2.LinkedList
increase
/**
* Appends the specified element to the end of this list.
*
* <p>This method is equivalent to {@link #addLast}.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
linkLast(e);
return true;
}
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
Here, because the insertion has head and tail pointers, the insertion always maintains the complexity of o(1);
Delete
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
/**
* Unlinks non-null node x.
*/
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
The deleted source code uses the equals method, so the null pointer is verified. At the same time, ensure whether there is an element of null pointer. If there is, delete it; Deletion is the most basic deletion method of double ended linked list
change
public void set(E e) {
if (lastReturned == null)
throw new IllegalStateException();
checkForComodification();
lastReturned.item = e;
}
In fact, LinkedList doesn't have the concept of subscript, so it doesn't use much set method. lastReturned used here is a part of the implementation of iterator, which can be understood as the location accessed last time. It is mainly used to improve access efficiency
check
/**
* Returns {@code true} if this list contains the specified element.
* More formally, returns {@code true} if and only if this list contains
* at least one element {@code e} such that
* {@code Objects.equals(o, e)}.
*
* @param o element whose presence in this list is to be tested
* @return {@code true} if this list contains the specified element
*/
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
/**
* Returns the index of the first occurrence of the specified element
* in this list, or -1 if this list does not contain the element.
* More formally, returns the lowest index {@code i} such that
* {@code Objects.equals(o, get(i))},
* or -1 if there is no such index.
*
* @param o element to search for
* @return the index of the first occurrence of the specified element in
* this list, or -1 if this list does not contain the element
*/
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
Searching is from the beginning node to the end node. Null pointer verification is introduced. The time complexity is O(n)
3, Summary based on underlying data structure
To sum up, we can make the following summary:
- Random access efficiency: ArrayList is more efficient than LinkedList in random access. Because LinkedList is a linear data storage method, you need to move the pointer to find it from front to back.
- Adding and deleting efficiency: LinkedList is more efficient than ArrayList in non head and tail adding and deleting operations, because ArrayList adding and deleting operations will affect the subscripts of other data in the array.
- Generally speaking, ArrayList is more recommended when the elements in the set need to be read frequently, and LinkedList is more recommended when there are many insert and delete operations.
4, Comparison of ArrayList and Vector
Thread safety: Vector uses Synchronized to realize thread synchronization, which is thread safe, while ArrayList is non thread safe. Add: LinkedList is also non thread safe and can only be used in a single threaded environment.
Performance: ArrayList is better than Vector in performance.
Capacity expansion: both ArrayList and Vector will dynamically adjust the capacity according to the actual needs, but the capacity expansion of Vector will double each time, while ArrayList will only increase by 50%.
The capacity expansion mechanism of ArrayList has been fully described in the add() method above. If there are still unclear UUS, you can check or leave a message above.
5, The difference between ArrayList and Array
Array can store basic data types and objects, while ArrayList can only store objects.
Array is specified with a fixed size, while ArrayList size is automatically expanded.
The built-in methods of Array are not as many as ArrayList. For example, addAll, removeAll, iteration and other methods are only available in ArrayList.