Implementation of distributed lock
There are three common implementations of distributed locks:
- Redis implementation
- Zookeeper implementation
- Database implementation
1. Redis based implementation
There are three important commands in Redis. Distributed locking can be realized through these three commands
- setnx key val: if and only if the key does not exist, set a string with key val and return 1; If the key exists, do nothing and return 0.
- expire key timeout: set a timeout for the key, with the unit of second. After this time, the key will be automatically deleted.
- delete key: deletes a key
1.1 implementation principle
- When acquiring a lock, use the setnx command to set a kv, where k is the name of the lock and v is a random number. If it is set successfully, the lock will be acquired. If it is not set successfully, it will fail. If the maximum time for trying to acquire a lock is set, the step needs to be repeated continuously within the maximum time until the lock is acquired or the maximum time is exceeded.
- Use the expire command to set a reasonable timeout for the key just created to prevent it from being released through the timeout when the lock cannot be released correctly. This timeout needs to be set according to the project request;
- When releasing a lock, v judge whether it is the original lock or not. If it is the lock, execute delete to release the lock.
1.2 implementation mode
1.2. 1 native code
public class DistributedLock implements Lock {
private static JedisPool JEDIS_POOL = null;
private static int EXPIRE_SECONDS = 60;
public static void setJedisPool(JedisPool jedisPool, int expireSecond) {
JEDIS_POOL = jedisPool;
EXPIRE_SECONDS = expireSecond;
}
private String lockKey;
private String lockValue;
private DistributedLock(String lockKey) {
this.lockKey = lockKey;
}
public static DistributedLock newLock(String lockKey) {
return new DistributedLock(lockKey);
}
@Override
public void lock() {
if (!tryLock()) {
throw new IllegalStateException("Lock not acquired");
}
}
@Override
public void lockInterruptibly() throws InterruptedException {
}
@Override
public boolean tryLock() {
return tryLock(0, null);
}
@Override
public boolean tryLock(long time, TimeUnit unit) {
Jedis conn = null;
String retIdentifier = null;
try {
conn = JEDIS_POOL.getResource();
lockKey = UUID.randomUUID().toString();
// The timeout period for acquiring the lock. If it exceeds this time, the acquisition of the lock will be abandoned
long end = 0;
if (time != 0) {
end = System.currentTimeMillis() + unit.toMillis(time);
}
do {
if (conn.setnx(lockKey, lockValue) == 1) {
conn.expire(lockKey, EXPIRE_SECONDS);
return true;
}
try {
Thread.sleep(10);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
} while (System.currentTimeMillis() < end);
} catch (JedisException e) {
if (lockValue.equals(conn.get(lockKey))) {
conn.del(lockKey);
}
e.printStackTrace();
} finally {
if (conn != null) {
conn.close();
}
}
return false;
}
@Override
public void unlock() {
Jedis conn = null;
try {
conn = JEDIS_POOL.getResource();
if (lockValue.equals(conn.get(lockKey))) {
conn.del(lockKey);
}
} catch (JedisException e) {
e.printStackTrace();
} finally {
if (conn != null) {
conn.close();
}
}
}
@Override
public Condition newCondition() {
return null;
}
}
There is also a problem in the above code. setnx and expire are carried out in two steps. Although exceptions are handled in catch and possible locks are deleted, this method is not friendly. A good solution is to execute lua script. In spring, redis lock and redismission are implemented through lua scripts
local lockClientId = redis.call('GET', KEYS[1])
if lockClientId == ARGV[1] then
redis.call('PEXPIRE', KEYS[1], ARGV[2])
return true
elseif not lockClientId then
redis.call('SET', KEYS[1], ARGV[1], 'PX', ARGV[2])
return true
end
return false
1.2. 2. Implementation of spring redis lock
1. Import and storage
In the Spring Boot project, the version number will be automatically configured according to the Spring Boot dependency management
Maven
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-integration</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.integration</groupId>
<artifactId>spring-integration-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2. Configure redis
In application XXX Configuration in YML
spring:
redis:
host: 127.0.0.1
port: 6379
timeout: 2500
password: xxxxx
3. Add configuration
RedisLockConfig.java
import java.util.concurrent.TimeUnit;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.integration.redis.util.RedisLockRegistry;
@Configuration
public class RedisLockConfig {
@Bean
public RedisLockRegistry redisLockRegistry(RedisConnectionFactory redisConnectionFactory) {
return new RedisLockRegistry(redisConnectionFactory, "redis-lock",
TimeUnit.MINUTES.toMillis(10));
}
}
4. Use
@Autowired
private RedisLockRegistry lockRegistry;
Lock lock = lockRegistry.obtain(key);
boolean locked = false;
try {
locked = lock.tryLock();
if (!locked) {
// No logic to acquire lock
}
// Logic for obtaining locks
} finally {
// Be sure to unlock
if (locked) {
lock.unlock();
}
}
1.2. 3. Redismission implementation
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379").setPassword("xxxxxx").setDatabase(0);
RedissonClient redissonClient = Redisson.create(config);
RLock rLock = redissonClient.getLock("lockKey");
boolean locked = false;
try {
/*
* waitTimeout The maximum waiting time for an attempt to acquire a lock. If it exceeds this value, it is considered that acquiring a lock has failed
* leaseTime The holding time of the lock. Beyond this time, the lock will automatically expire
*/
locked = rLock.tryLock((long) waitTimeout, (long) leaseTime, TimeUnit.SECONDS);
if (!locked) {
// There is no logic to acquire locks
}
// Logic for obtaining locks
} catch (Exception e) {
throw new RuntimeException("aquire lock fail");
} finally {
if(locked)
rLock.unlock();
}
1.3 advantages and disadvantages
Advantages: the performance of redis itself is relatively high. Even if there are a large number of setnx commands, it will not degrade
Disadvantages:
- If the timeout set by the key is too short, the lock may be released before the business process has finished processing, resulting in other requests obtaining the lock
- If the timeout set by the key is too long and the lock is not released, some requests will wait for the lock for a long time
- In the process of lock attempts, CPU resources will be wasted
Aiming at the second disadvantage, the reission uses the renewal mechanism to detect whether the lock is still in progress at regular intervals. If it is still running, the corresponding key will be increased for a certain time to ensure that the key will not be automatically deleted when it expires when the lock is running
2. Implementation based on Zookeeper
2.1 implementation principle
Distributed locks that can be implemented by temporary ordered nodes based on zookeeper.
General steps: when the client locks a method, a unique temporary ordered node is generated under the directory of the specified node corresponding to the method on zookeeper. The way to judge whether to obtain a lock is very simple. You only need to judge the smallest sequence number in the ordered node. When the lock is released, just delete the instantaneous node. At the same time, it can avoid the deadlock caused by the failure to release the lock caused by service downtime.
When the first node applies for the lock xxxlock, it is as follows: under the xxxlock persistent node, create a temporary ordered node of the lock. At this time, because the lock is the one with the smallest sequence number among the ordered nodes, the lock is obtained at this time

When the first node is still processing the business logic without releasing the lock, the second node applies for the xxlock lock and creates a temporary ordered node of the lock. At this time, because the lock is not the smallest of the ordered nodes, the lock cannot be obtained at this time. You need to wait until the lock:1 node is deleted, At this time, lock:2 will watch its previous node (i.e. lock:1) and obtain the lock after lock:1 is deleted
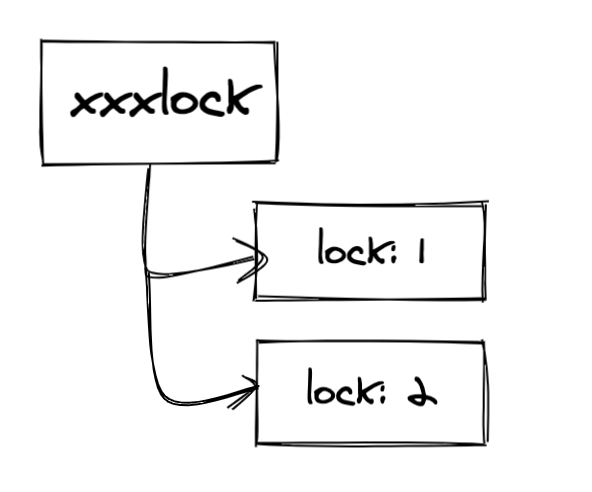
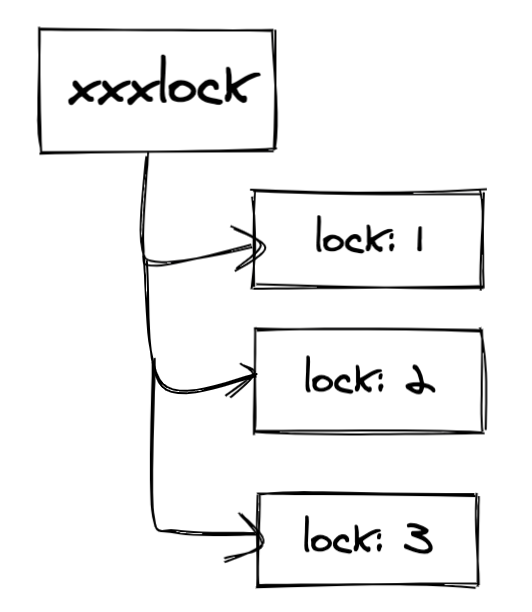
When the first node is still processing the business logic without releasing the lock, the second node is still queuing. When the third node applies for a lock, a temporary ordered node of lock is created. At this time, because the lock is not the smallest of the ordered nodes, the lock cannot be obtained at this time, You need to wait until the above nodes (lock:1 and lock:2) are deleted to obtain the lock. At this time, lock:3 will watch its previous node (i.e. lock:2) until lock:2 is deleted to obtain the lock
2.2 use
2.2. 1 using spring integration zookeeper
Maven.
<dependency>
<!-- spring integration -->
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-integration</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.integration</groupId>
<artifactId>spring-integration-zookeeper</artifactId>
</dependency>
Gradle.
compile "org.springframework.integration:spring-integration-zookeeper:5.1.2.RELEASE"
Add configuration
@Configuration
public class ZookeeperLockConfig {
@Value("${zookeeper.host}")
private String zkUrl;
@Bean
public CuratorFrameworkFactoryBean curatorFrameworkFactoryBean() {
return new CuratorFrameworkFactoryBean(zkUrl);
}
@Bean
public ZookeeperLockRegistry zookeeperLockRegistry(CuratorFramework curatorFramework) {
return new ZookeeperLockRegistry(curatorFramework, "/lock");
}
}
use
@Autowired
private ZookeeperLockRegistry lockRegistry;
Lock lock = lockRegistry.obtain(key);
boolean locked = false;
try {
locked = lock.tryLock();
if (!locked) {
// No logic to acquire lock
}
// Logic for obtaining locks
} finally {
// Be sure to unlock
if (locked) {
lock.unlock();
}
}
2.2. 2 using Apache cursor
Maven
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>5.1.0</version>
</dependency>
use
CuratorFramework curatorFramework = CuratorFrameworkFactory.newClient(
connectString,
sessionTimeoutMs,
connectionTimeoutMs,
new RetryNTimes(retryCount, elapsedTimeMs));
InterProcessMutex mutex = new InterProcessMutex(curatorFramework, "lock name");
mutex.acquire(); // Acquire lock
mutex.acquire(long time, TimeUnit unit) // Acquire the lock and set the maximum wait time
mutex.release(); // Release lock
2.3 advantages and disadvantages
advantage:
- Solve the single point problem and deploy zookeeper through cluster;
- Because the temporary node used can ensure that the lock can be released in case of accidents in the project. When the session is disconnected abnormally, the temporary node will be deleted automatically;
- There is no need to set the storage expiration time, which avoids the problems caused by the expiration of Redis lock;
Disadvantages:
- The performance is not as good as Redis implementation;
3. Implementation based on Database
3.1 implementation principle
create table distributed_lock ( id int(11) unsigned NOT NULL auto_increment primary key, key_name varchar(30) unique NOT NULL comment 'Lock name', update_time datetime default current_timestamp on update current_timestamp comment 'Update time' )ENGINE=InnoDB comment 'Database lock';
Method 1: it is implemented through insert and delete
Using the database unique index, when we want to obtain a lock, we insert a piece of data. If the insert is successful, we obtain the lock. After obtaining the lock, we delete the lock through the delete statement
In this way, the lock will not wait. If you want to set the maximum time to obtain the lock, you need to implement it yourself
Method 2: through for update
The following operations need to be performed in a transaction
select * from distributed_lock where key_name = 'lock' for update;
Add for update after the query statement, and the database will add an exclusive lock to the database table during the query. When an exclusive lock is added to a record, other threads cannot add an exclusive lock to the record. Another feature of for update is blocking, which indirectly implements a blocking queue. However, the blocking time of for update is determined by the database rather than the program.
In MySQL 8, the for update statement can be added with nowait to achieve non blocking usage
select * from distributed_lock where key_name = 'lock' for update nowait;
When the InnoDB engine locks, row level locks are only used when querying through the index, otherwise they are table locks, and if the query fails to find data, they will also be upgraded to table locks.
This method needs to be used when data already exists in the database.
3.2 advantages and disadvantages
advantage:
If the database has been used in the project, the database can be used directly without introducing other middleware to reduce dependency
It is easy to understand by using the database directly.
Disadvantages:
- Operating the database requires a certain overhead, and the performance problem needs to be considered;
- Using row level locks in the database is not necessarily reliable, especially when our lock table is not large;
- There is no lock timeout mechanism, so you must delete the lock yourself. How to delete the lock after a failure becomes a problem
- The for update method must be inside the transaction. If the business operation cannot be executed in the transaction, it is another problem
- All kinds of problems will make the whole scheme more and more complex in the process of solving problems.
4. Comparison
From a performance perspective (from high to low) cache > zookeeper > = database
From the perspective of reliability (from high to low), zookeeper > cache > Database
| Problems and Realization | Redis | Zookeeper | database |
|---|---|---|---|
| performance | high | in | low |
| reliability | in | high | low |
| Expired delete | Yes, set the expiration time, or delete it manually | Manually delete after executing business logic | 1. After the for update transaction is completed, the database is automatically released 2 Manually delete after executing business logic in insert mode |
| Blocking queue | No, it needs to be solved by the client | Solve the problem by listening to the previous lock and use the watch mechanism | 1. The for update database solves the problem by itself 2 The insert mode needs to be solved by the client |
| The business is not completed within the timeout | You need to write your own renewal mechanism to complete it. Redission has implemented it internally | No such problem | 1. The execution time of for update is too long, which may lead to the timeout of the transaction itself. 2 There is no such problem with the insert method |
| The lock is not manually deleted due to an item exception | redis has an expiration time. It will be deleted automatically after the expiration time | After the session is disconnected, the temporary node is automatically deleted | 1. for update mechanism: the database will be cleared automatically 2 You have to think of your own solution for the insert method |