Chapter 13 IO flow
Use of File class
1. An object of file class, which represents a file or a file directory (commonly known as folder)
2. The file class is declared in Java Under IO package
3. The file class involves the creation, deletion, renaming, modification time, file size and other methods of files or file directories, and does not involve the operation of writing or reading file contents. If you need to read or write the contents of the file, you must use the IO stream to complete it.
4. Objects of subsequent File classes are often passed to the stream constructor as parameters, indicating the "end point" of reading or writing.
use:
1. How to create an instance of File class
- File(String filePath)
- File(String parentPath,String childPath)
- File(File parentFile,String childPath)
Note that the instantiation is only an object of new File. At this time, it is still at the memory level, and the File has not been created in the hard disk.
2. Relative path: the specified path compared to a certain path
Absolute path: the path of a file or file directory including a drive letter
explain:
In IDEA, if the development uses the unit test method in JUnit to test, the relative path is under the current Module. If you use the main() test, the relative path is under the current Project. (if the file is placed under Module and main () is used, write the specified Module in the relative path first, find the Module, and then find the corresponding file in it.)
The reason is that the relative path refers to who called it. The unit test method only takes effect under the current Module, while the main() takes effect under the current Project.
In Eclipse: no matter using the unit test method or using the main() test, the relative path is under the current Project.
3. Path separator: Windows: \ Unix: /. However, at present, windows write / write can also be recognized.
- windows and DOS systems use "\" by default
- UNIX and URL s are represented by "/"
Java programs support cross platform operation, so the path separator should be used with caution.
To solve this problem, the File class provides a constant:
public static final String separator. Provide separators dynamically according to the operating system.
File file1 = new File("d:\\mao\\info.txt");
File file2 = new File("d:" + File.separator + "mao" + File.separator + "info.txt");
File file3 = new File("d:/mao");
Instantiation code example:
@Test
public void test1(){
//1. How to create an instance of File class
// File(String filePath)
// File(String parentPath,String childPath)
// File(File parentFile,String childPath)
//2. Relative path: the specified path compared to a certain path
// Absolute path: the path to the file or file directory including the drive letter
File file1 = new File("hello.txt");//(in unit test method) relative to the current Module
//3. Path separator: Windows: \ \ Unix: /. But at present, windows write / write can also be recognized
File file2 = new File("E:\\workspace\\workspace_base\\Project01\\Senior");
//After creating the object, it is still at the memory level
//Constructor 2:
File file3 = new File("E:\\workspace\\workspace_base\\Project01","Senior");
//Constructor 3
File file4 = new File(file3,"Senior");
}
Common methods of File class
Get function of File class
public String getAbsolutePath(): get absolute path
public String getPath(): get path
public String getName(): get the name
public String getParent(): get the directory path of the upper level file. If none, null is returned
public long length(): get the length of the file (i.e. the number of bytes). Cannot get the length of the directory.
public long lastModified(): gets the last modification time, in milliseconds
The following two methods are used for file directories
public String[] list(): get the name array of all files or file directories in the specified directory
public File[] listFiles(): get the File array of all files or File directories in the specified directory
File file2 = new File("E:\\workspace\\workspace_base\\Project01\\Senior");
String[] list = file2.list();
for (String s :
list) {
System.out.println(s);
}
File file2 = new File("E:\\workspace\\workspace_base\\Project01\\Senior");
File[] files = file2.listFiles();
for (File f :
files) {
System.out.println(f);
}
Rename function of File class
public boolean renameTo(File dest): rename the file to the specified file path
Note that renaming the path means moving the file to another path.
For example: file1 Take renameto (file2) as an example. To ensure that it returns true, file1 exists in the hard disk, and file2 cannot exist in the hard disk.
/**
* public boolean renameTo(File dest):Rename the file to the specified file path
* For example: file1 Rename to (File2) as an example
* To return true, file1 exists in the hard disk and file2 cannot exist in the hard disk.
*/
@Test
public void test2(){
File file1 = new File("hello.txt");
File file2 = new File("D:\\io\\hi.txt");
//In this way, file1 will be moved to the file2 file directory, and since file2 is a file, the file name of file1 will also become the file name of file2
boolean renameTo = file1.renameTo(file2);
System.out.println(renameTo);
}
Judgment function of File class
public boolean isDirectory(): judge whether it is a file directory
public boolean isFile(): judge whether it is a file
public boolean exists(): judge whether it exists (whether it exists here is to judge whether it exists on the hard disk.)
public boolean canRead(): judge whether it is readable
public boolean canWrite(): judge whether it is writable
public boolean isHidden(): judge whether to hide
When operating a file, you'd better first judge whether the file exists on the hard disk through exists().
Creation function of File class
Create the corresponding file or file directory in the hard disk:
public boolean createNewFile(): creates a file. If the file exists, it will not be created and false will be returned
public boolean mkdir(): create a file directory. If this file directory exists, it will not be created. If the upper directory of this file directory does not exist, it will not be created.
public boolean mkdirs(): create a file directory. If the upper file directory does not exist, create it together
Note: if you create a file or there is no write letter path in the file directory, it is under the project path (i.e. relative path) by default.
Delete function of File class
To delete a file or file directory from your hard disk drive:
public boolean delete(): deletes files or folders
Delete precautions: delete in Java does not go to the recycle bin.
To delete a file directory, please note that the file directory cannot contain files or file directories
public void test2() throws IOException {
File file1 = new File("hello.txt");
if (!file1.exists()){
//File creation
file1.createNewFile();//Need to handle exception
System.out.println("Deleted successfully");
}else {
//Delete file
file1.delete();
System.out.println("Deleted successfully");
}
//Creation of file directory
File file3 = new File("d:\\io\\io1\io3");
//If the upper directory of this file directory does not exist, it will not be created.
boolean mkdir = file3.mkdir();
if (mkdir){
System.out.println("Created successfully 1");
}
//If the upper file directory does not exist, create it together
boolean mkdirs = file3.mkdirs();
if (mkdirs){
System.out.println("Created successfully 2");
}
}
Differences in attribute values after object creation
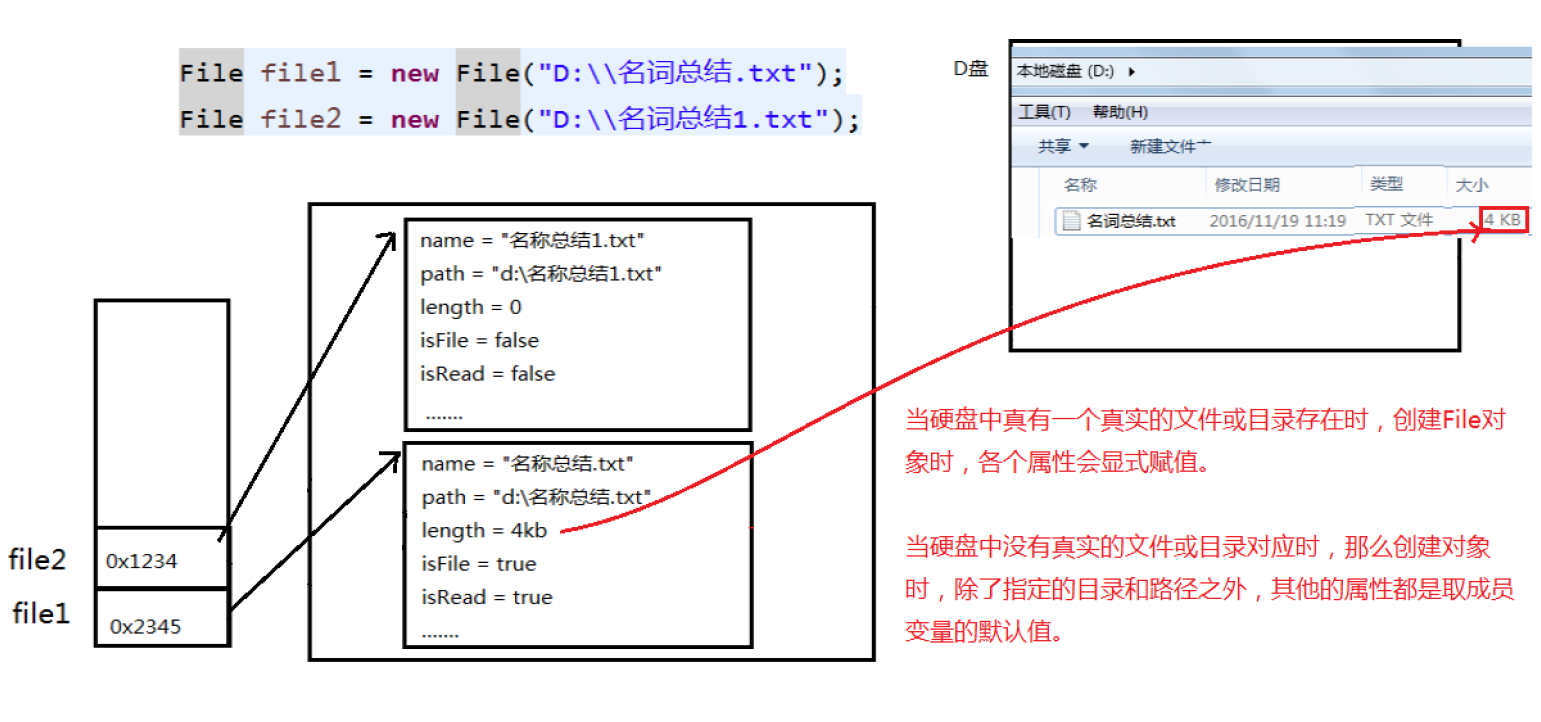
When a real File or directory exists in the hard disk, each attribute will be explicitly assigned when creating the File.
When there is no corresponding real file or directory, except for the specified directory and path, other attributes take the default value of the member variable.
practice:
1. Judge whether there is suffix under the specified directory jpg file, if any, output the file name
First use the public String[] list() of the File class to get the File name, and then use the endwith(String s) method of the String class.
public class FindJPGFileTest {
@Test
public void test1(){
File srcFile = new File("d:\\code");
String[] fileNames = srcFile.list();
for(String fileName : fileNames){
if(fileName.endsWith(".jpg")){
System.out.println(fileName);
}
}
}
@Test
public void test2(){
File srcFile = new File("d:\\code");
File[] listFiles = srcFile.listFiles();
for(File file : listFiles){
if(file.getName().endsWith(".jpg")){
System.out.println(file.getAbsolutePath());
}
}
}
/*
* File Class provides two file filter methods
* public String[] list(FilenameFilter filter)
* public File[] listFiles(FileFilter filter)
*/
@Test
public void test3(){
File srcFile = new File("d:\\code");
File[] subFiles = srcFile.listFiles(new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
return name.endsWith(".jpg");
}
});
for(File file : subFiles){
System.out.println(file.getAbsolutePath());
}
}
}
2. Traverse all file names in the specified directory, including the files in the sub file directory.
Calculate the size of the expanded Directory: 1
Extension 2: delete the specified file directory and all files under it (note that when deleting the directory, there can be no content under the directory)
Main idea: recursive method
public class ListFilesTest {
public static void main(String[] args) {
// Recursion: file directories
/** Print out the names of all files in the specified directory, including the files in the sub file directory */
// 1. Create directory object
File dir = new File("E:\workspace\workspace_base\Project01\Senior");
// 2. Print sub files of the directory
printSubFile(dir);
}
public static void printSubFile(File dir) {
// Print sub files of the directory
File[] subfiles = dir.listFiles();
for (File f : subfiles) {
if (f.isDirectory()) {// File directory
printSubFile(f);
} else {// file
System.out.println(f.getAbsolutePath());
}
}
}
// Mode 2: Circular implementation
// List the subordinate contents of the file directory. If only one level is listed
// Using String[] list() of File class is relatively simple
public void listSubFiles(File file) {
if (file.isDirectory()) {
String[] all = file.list();
for (String s : all) {
System.out.println(s);
}
} else {
System.out.println(file + "It's a file!");
}
}
// List the subordinates of file directory. If its subordinates are still directories, then list the subordinates of subordinates, and so on
// It is recommended to use File[] listFiles() of File class
public void listAllSubFiles(File file) {
if (file.isFile()) {
System.out.println(file);
} else {
File[] all = file.listFiles();
// If all[i] is a file, print directly
// If all[i] is a directory, then get its next level
for (File f : all) {
listAllSubFiles(f);// Recursive call: calling yourself is called recursion
}
}
}
// Extension 1: find the size of the space where the specified directory is located
// Find the total size of any directory
public long getDirectorySize(File file) {
// If file is a file, return file directly length()
// file is a directory, and the total size is the sum of all the sizes of its next level
long size = 0;
if (file.isFile()) {
size += file.length();
} else {
File[] all = file.listFiles();// Get the next level of file
// Size of cumulative all[i]
for (File f : all) {
size += getDirectorySize(f);// Size of f;
}
}
return size;
}
// Extension 2: delete the specified directory
public void deleteDirectory(File file) {
// If file is a file, delete it directly
// If file is a directory, first kill its next level, and then delete yourself
if (file.isDirectory()) {
File[] all = file.listFiles();
// Circular deletion is the next level of file
for (File f : all) {// f represents each subordinate of the file
deleteDirectory(f);
}
}
// Delete yourself
file.delete();
}
}
IO stream
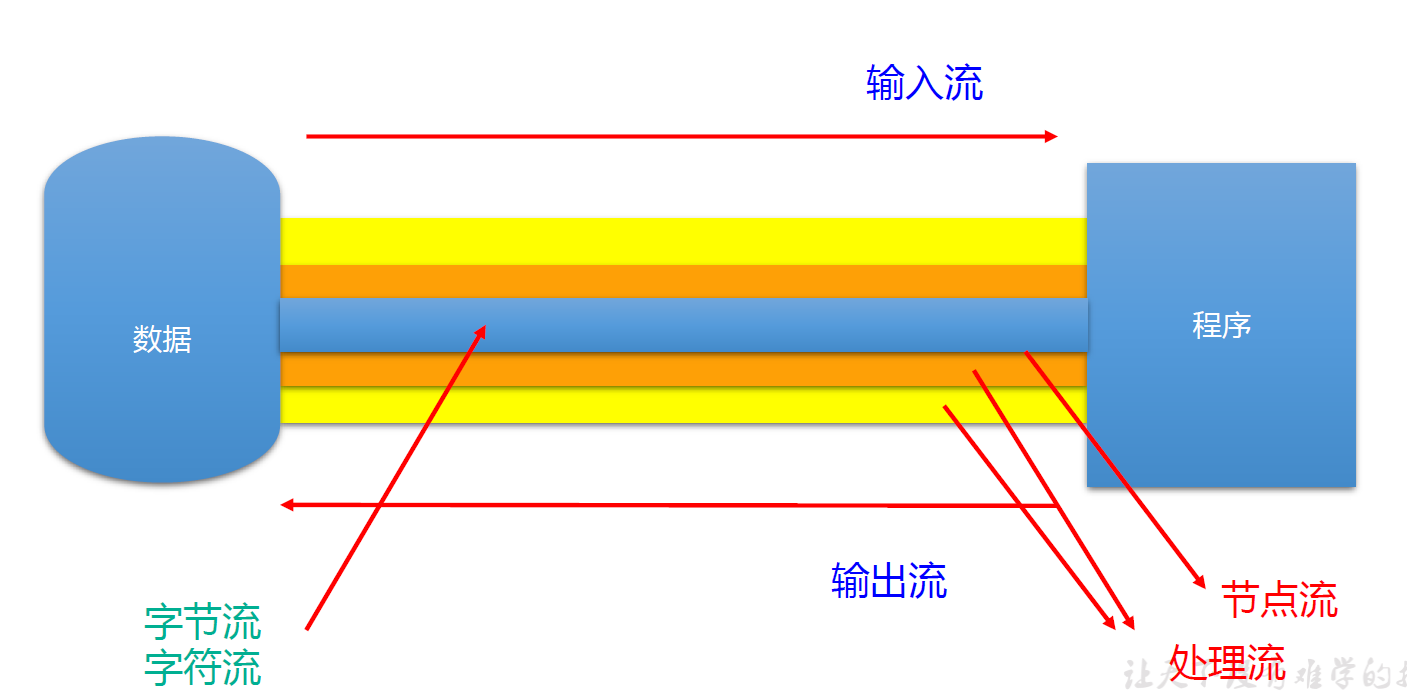
IO stream overview
input: read external data (data from disk, optical disc and other storage devices) into the program (memory).
Output: output program (memory) data to disk, optical disc and other storage devices.
Classification of flow:
- According to different operation data units, it is divided into byte stream (8 bit) and character stream (16 bit)
- According to the flow direction of data flow, it is divided into input flow and output flow
- According to the different roles of flow, it can be divided into node flow and processing flow
The byte stream (0, 1 code) is suitable for transmitting non text data such as pictures, videos, etc.
Character stream (char,2 bytes) is suitable for transmitting text data, such as ". txt"
The stream directly acting on the file is called node stream; The flow acting on the existing flow is called processing flow, which can be nested at multiple levels.
Difference between node flow and processing flow:
Node flow: read and write data directly from the data source or destination
Processing flow: it is not directly connected to the data source or destination, but "connected" on the existing flow (node flow or processing flow), so as to provide more powerful reading and writing functions for the program through data processing.
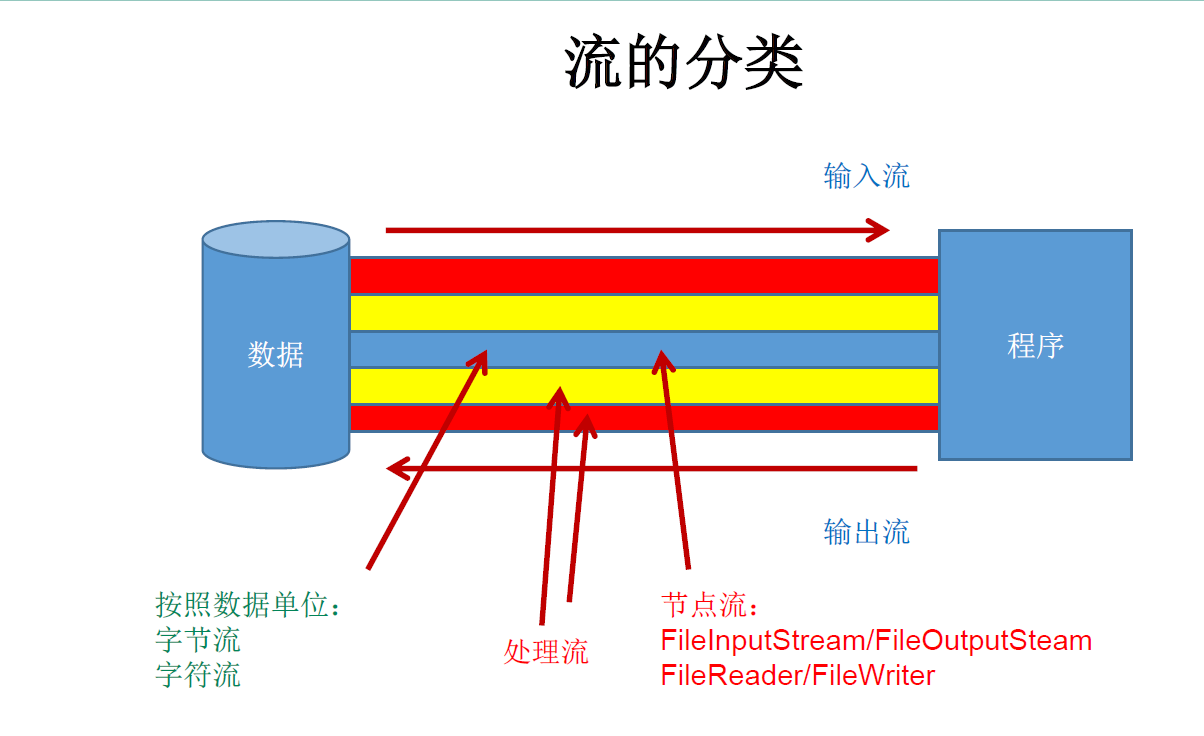
- Java's IO stream involves more than 40 classes, which are actually very regular. They are derived from the following four abstract base classes. (these four are abstract classes)
- The names of subclasses derived from these four classes are suffixed with their parent class names.
| (abstract base class) | Byte stream | Character stream |
|---|---|---|
| Input stream | InputStream | Reader |
| Output stream | OutputStream | Writer |
The row accessing the file is node flow, and the following columns are processing flow.
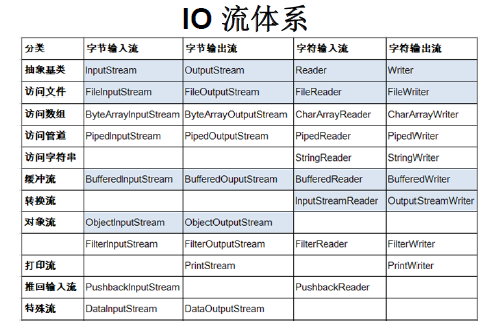
Structure system of flow:
| Abstract base class | Node stream (or file stream) | Buffered stream (a kind of processing stream) |
|---|---|---|
| InputStream | FileInputStream | BufferedInputStream |
| OutputStream | FileOutputStream | BufferedOutputStream |
| Reader | FileReader | BufferedReader |
| Writer | FileWriter | BufferedWriter |
Basic operation of reading data by FileReader
Put the hello. Under Module Txt file content is read into the program and output to the console
Description:
1. Understanding of read(): return one character read in. Returns - 1 if the end of the file is reached
2. Exception handling: to ensure that flow resources can be closed. Try catch finally processing is required
3. The read file must exist, otherwise FileNotFoundException will be reported.
Try catch finally is required for stream handling exceptions
Steps:
1. Instantiate the object of File class to indicate the File to be operated
2. Provide specific flow
3. Data reading
4. Close the flow
@Test
public void test1(){
FileReader fr = null;
try {
//1. Instantiate the object of File class to indicate the File to be operated
File file = new File("hello.txt");//Compared with the current Module in the unit test method
//2. Provide specific flow
fr = new FileReader(file);
//3. Data reading
//read(): returns a character read in. If the end of the file is reached, - 1 is returned
//Mode 1; Note that read here can be compared to the next() method of iterator traversal operation in the collection
/*int data = fr.read();
while (data != -1){
System.out.print((char) data);
data = fr.read();
}*/
//Mode 2: grammatical modification of mode 1
int data;
while ((data = fr.read()) != -1){
System.out.print((char) data);
}
} catch (IOException e) {
e.printStackTrace();
} finally {//Try catch finally should be used for exception handling, because the flow closing operation must be executed, and the JVM cannot handle it automatically
//The JVM cannot do anything about other physical connections, such as database connection, input stream, output stream and Socket connection
//4. Close the flow
/*try {
//This judgment must be written, otherwise a null pointer exception may be reported. Because it is possible to directly report exceptions and generate exception objects,
// The program stops. At this time, the byte stream object has not been generated, so it cannot point to the close operation
if (fr != null)
fr.close();
} catch (IOException e) {
e.printStackTrace();
}*/
//Try catch before judgment is no different from try catch after judgment.
if (fr != null){
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
Template:
@Test
public void test2(){
FileReader fr = null;
try {
File file = new File("hello.txt");
fr = new FileReader(file);
int data;
while ((data = fr.read()) != -1) {
System.out.println((char) data);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
}
try {
if (fr != null)
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
Upgrade the read() operation: use the overloaded method of read().
The null parameter method of read() used earlier can only read one character at a time, which is too inefficient. Use the overload method to read more than one character at a time.
Understanding of read(): return a character read in. Returns - 1 if the end of the file is reached
read(char[] cbuf): returns the number of characters read into the cbuf array each time. If the end of the file is reached, - 1 is returned.
Note the difference between the return values of the two methods
//Upgrade the read() operation: use the overloaded method of read().
@Test
public void test3() throws FileNotFoundException {
FileReader fr = null;
try {
//1. Instantiation of file class
File file = new File("hello.txt");
//2. Instantiation of FileReader stream
fr = new FileReader(file);
//3. Read in operation
//read(char[] cbuf): returns the number of characters read into the cbuf array each time. If the end of the file is reached, - 1 is returned
char[] cbuf = new char[5];
int len;
while ((len = fr.read(cbuf)) != -1){
//Mode 1
/*
Wrong writing
for (int i = 0; i < cbuf.length; i++) {
System.out.print(cbuf[i]);//HelloWorld123ld
}*/
//Correct: read a few this time, and you can traverse a few
for (int i = 0; i < len; i++) {
System.out.print(cbuf[i]);//HelloWorld123
}
//Method 2: use the string to convert the character array into a string
/*The wrong way corresponds to the wrong way of writing
String str = new String(cbuf);
System.out.println(cbuf);*/
//Correct writing
String str = new String(cbuf,0,len);//Read the of the character array from the first index position to the second index position
System.out.println(str);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//4. Closure of resources
try {
if (fr != null)
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
read(char[] cbuf) passes in a parameter. It means to fill the array every time to the end of the file. If it is not enough, just put all the rest in.
Graphic char [] reading data process
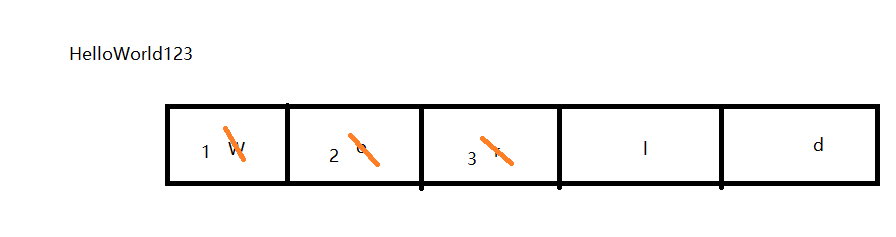
Each time, the read data is overwritten with the previous data, which explains why the loop condition in the for loop is I < len, and several are read each time.
FileWriter writes out data
Steps:
1. Provide the object of File class to indicate the File to be written out
2. Provide the object of FileWriter for writing out data
3. Write out the operation
4. Closing of flow resources
be careful:
1. For output operation, the corresponding File may not exist. No exception will be reported
2. If the file in the hard disk corresponding to file does not exist, this file will be automatically created during output.
If the File in the hard disk corresponding to File exists:
① if the constructor used by the stream is: FileWriter(file,false) / FileWriter(file): overwrite the original file
② if the constructor used by the stream is: FileWriter(file,true): it will not overwrite the original file, but add content on the basis of the original file
/*
Write data from memory to a file on the hard disk
explain:
1.For output operation, the corresponding File may not exist. No exception will be reported
2.File If the file in the corresponding hard disk does not exist, it will be automatically created during the output process.
File If the file in the corresponding hard disk exists:
①If the constructor used by the stream is: FileWriter(file,false) / FileWriter(file): overwrite the original file
②If the constructor used by the stream is: FileWriter(file,true): it will not overwrite the original file, but add content on the basis of the original file
*/
@Test
public void test4(){
FileWriter fw = null;
try {
//1. Provide the object of File class to indicate the File to be written out
File file = new File("hello1.txt");
//2. Provide the object of FileWriter for writing out data
fw = new FileWriter(file,false);
//3. Write out the operation
fw.write("I have a dream!\n");
fw.write("you need to a dream!");
} catch (IOException e) {
e.printStackTrace();
} finally {
//4. Closing of flow resources
try {
if (fw != null)
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Copy files
Use FileReader and FileWriter to copy files
Steps:
1. Create an object of File class to indicate the files read in and written out
2. Create objects for input and output streams
3. Data reading and writing
4. Close resource flow
//Use FileReader and FileWriter to copy files
@Test
public void test5(){
FileReader fr = null;
FileWriter fw = null;
try {
//1. Create an object of File class to indicate the files read in and written out
File srcFile = new File("hello.txt");
File destFile = new File("hello2.txt");
//2. Create objects for input and output streams
fr = new FileReader(srcFile);
fw = new FileWriter(destFile);
//3. Data reading and writing
char[] cbuf = new char[5];
int len;//Record the number of characters read into the cbuf array each time
while ((len = fr.read(cbuf)) != -1){
//Write len characters at a time
fw.write(cbuf,0,len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//It doesn't matter which stream is closed first, but which one is closed first
//Method 1 of closing stream resources
/*try {
fw.close();
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}*/
//Mode 2
/*
This involves the understanding of exception handling
try-catch If the exception is handled, the later code outside the try catch will continue to execute. The code that generates an exception object in try
The later code will not be executed any more and will directly enter the catch, but the later code outside the try catch will continue to be executed.
Unlike throwing throws, throws does not really solve the exception, but is thrown to the method calling it.
After generating the exception object, the subsequent code will not be executed, which is why the code to close the stream resource must be placed in try catch finally
*/
try {
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Note the operation of closing two stream resources, exception handling.
Understanding of exception handling:
Try catch handles the exception, and the code outside and behind try catch will continue to execute. The code behind the sentence that generates an exception object in try will not be executed and will directly enter catch, but the code behind try catch will continue to be executed. Unlike throwing throws, throws does not really solve the exception, but is thrown to the method calling it. After the exception object is generated, the subsequent code will not be executed, which is why the code that closes the stream resource must be placed in try catch finally.
Make an analogy: in the story of the wolf coming, try catch is like driving the wolf away, and throws is like calling adults to help drive the wolf away.
Note: character stream cannot be used to process byte data such as pictures.
FileInputStream cannot read the test of text file
Conclusion:
1. For text files (. txt,. java,. c,. cpp), use character stream processing
2. For non text files (. jpg,. mp3,. mp4,. avi,. doc,. ppt,...), use byte stream processing. (doc is a non text file because it can store pictures, etc.)
Add: if you only want to copy a text file, you can use byte stream processing (as long as you don't look at the content at the memory level), which is equivalent to that byte stream is just a porter. However, character stream cannot be used for copying non text files. It's better to use the corresponding one for what you deal with
Create char [] with character stream and byte [] with byte stream
Using byte stream FileInputStream to process text files may cause garbled code.
If you use byte stream to read text files, there will be garbled code in Chinese. The reason is that English letters account for 8 bits in ASCII code, which can also be read out by using byte stream, but in UTF-8, Chinese accounts for 3 bytes (24 bits), so there will be garbled code when reading. In short, do not use byte streams to read text files.
FileInputStream and FileOutputStream use
Copy the picture:
//Copy the picture
@Test
public void test6(){
FileInputStream fis = null;
FileOutputStream fos = null;
try {
//1. Instantiate file object
File srcFile = new File("Picture 1.jpg");
File destFile = new File("Picture 2.jpg");
//2. Flow generation
fis = new FileInputStream(srcFile);
fos = new FileOutputStream(destFile);
//3. Copy operation
byte[] buffer = new byte[5];
int len;
while ((len = fis.read(buffer)) != -1){
fos.write(buffer,0,len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//4. Close
try {
if (fos != null)
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if (fis != null)
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Encapsulation of the method of copying files:
//Encapsulation of the method of copying files
public void copyFile(String srcPath,String destPath){
FileInputStream fis = null;
FileOutputStream fos = null;
try {
//1. Instantiate file object
File srcFile = new File(srcPath);
File destFile = new File(destPath);
//2. Flow generation
fis = new FileInputStream(srcFile);
fos = new FileOutputStream(destFile);
//3. Copy operation
byte[] buffer = new byte[5];
int len;
while ((len = fis.read(buffer)) != -1){
fos.write(buffer,0,len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//4. Close
try {
if (fos != null)
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if (fis != null)
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
//test
@Test
public void testCopyFile(){
long start = System.currentTimeMillis();
String str1 = "1.avi";
String str2 = "2.avi";
copyFile(str1,str2);
long end = System.currentTimeMillis();
System.out.println(end - start);
}
Buffered stream for non text copying
One of the processing streams: the use of buffer streams
1. Buffer stream:
-
BufferedInputStream
-
BufferedOutputStream
-
BufferedReader
-
BufferedWriter
2. Function: provide the reading and writing speed of the stream. The reason for improving the reading and writing speed: a buffer is provided internally. (the default buffer size provided by BufferedInputStream is 8192 bytes). There is a flush () method inside BufferedOutputStream to refresh the cache. flush() flushes the buffer. If this method is not explicitly called, the buffer will be refreshed only when the buffer is full (empty data and write data). However, if this method is explicitly called, the buffer will be refreshed when this method is executed, regardless of whether it is full or not.
Basically, there will be a flush() method in the processing output stream. If some processing streams don't write flush() automatically, we need to write it, but we don't need to write it again if we automatically write flush() like buffer stream.
3. Processing flow is "socket connection" on the basis of existing flow. (existing flow, node flow can socket processing flow, and processing flow can also socket processing flow)
Steps:
1. Instantiate File object
2. Flow generation. Because the processing flow acts on the node flow, there must be a node flow first
2.1 node flow
2.2 buffer flow
3. Implementation details of operation
4. Resource shutdown. Requirements: first close the flow of the outer layer, and then close the flow of the inner layer. Note: when closing the outer layer flow, the inner layer flow will also be closed automatically. The closure of inner laminar flow can be omitted. Of course, there is no mistake in writing.
/**
* One of the processing streams: the use of buffer streams
* 1.Buffer stream:
* BufferedInputStream
* BufferedOutputStream
* BufferedReader
* BufferedWriter
*
* 2.Function: provide the read and write speed of the stream
* The reason for improving the reading and writing speed: a buffer is provided internally (the default size of the buffer provided by BufferedInputStream is 8192 bytes)
*
*/
public class BufferedTest {
//Copy non text files
@Test
public void test1(){
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
try {
//1. Documentation
File file1 = new File("Picture 1.jpg");
File file2 = new File("Picture 2.jpg");
//2. Flow generation. Because the processing flow acts on the node flow, there must be a node flow first
//2.1 node flow
FileInputStream fis = new FileInputStream(file1);
FileOutputStream fos = new FileOutputStream(file2);
//2.2 buffer flow
bis = new BufferedInputStream(fis);
bos = new BufferedOutputStream(fos);
//3. Copy details
byte[] buffer = new byte[1024];
int len;
while ((len = bis.read(buffer)) != -1){
bos.write(buffer,0,len);
//BufferedOutputStream has a flush() method inside
// bos.flush();// Flush buffer. If this method is not explicitly called, the buffer will be refreshed only when the buffer is full (empty data and write data),
//However, if this method is explicitly called, the buffer will be flushed when this method is executed, regardless of whether it is full or not
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//4. Resource shutdown
//Requirements: first close the flow of the outer layer, and then close the flow of the inner layer
try {
if (bos != null)
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if (bis != null)
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
//Note: when closing the outer layer flow, the inner layer flow will also be closed automatically. The closure of inner laminar flow can be omitted. Of course, there is no mistake in writing.
// fos.close();
// fis.close();
}
}
}
Call system The currenttimemillis () method compares the speed of copying files with and without a buffer stream, and finds that the speed of using a buffer stream is greatly improved. (the premise of comparison is that the size of byte [] array is the same.)
Buffer stream for text copy
Use BufferedReader and BufferedWriter to copy text files
Previously, instantiate the File object to create a node stream and a buffer stream, which can be written together and represented by an anonymous class.
In addition, in BufferedWriter, besides reading a char [], there is also a readLine() method, which reads one line at a time, returns null at the end, and the read content does not include a newline character. You need to add the newline character "\ n" manually or call newLine()
//Use BufferedReader and BufferedWriter to copy text files
@Test
public void test7(){
BufferedReader br = null;
BufferedWriter bw = null;
try {
//Use anonymous classes directly after writing
br = new BufferedReader(new FileReader(new File("hello.txt")));
bw = new BufferedWriter(new FileWriter(new File("hello1.txt")));
//Read / write operation
//Mode 1
/*char[] cbuf = new char[1024];
int len;
while ((len = br.read(cbuf)) != -1){
bw.write(cbuf,0,len);
//BufferedReader The size of the buffer in is 8192 chars, one char is 2 bytes, while the size of the buffer in BufferedInputStream is 8192 bytes
// bw.flush();//BufferedWriter There is this method in, so there is no need to adjust it actively.
}*/
//Method 2: BufferedReader also provides another method
String data;
while ((data = br.readLine()) != null){//readLine() reads one line at a time and returns null at the end
//Method 1:
// bw.write(data + "\n");//data does not contain line breaks
//Method 2
bw.write(data);//data does not contain line breaks
bw.newLine();//Provides line feed operations
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//close resource
try {
if (bw != null)
bw.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if (br != null)
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Summary:
| Node stream (or file stream) | Buffered stream (a kind of processing stream) |
|---|---|
| FileInputStream (read(byte[] buffer)) | BufferedInputStream (read(byte[] buffer)) |
| FileOutputStream (write(byte[] buffer,0,len)) | BufferedOutputStream (write(byte[] buffer,0,len)) / flush() |
| FileReader (read(char[] cbuf)) | BufferedReader ( read(char[] cbuf) / readLine() ) |
| FileWriter (write(char[] cbuf,0,len)) | BufferedWriter (write(char[] cbuf,0,len)) / flush() |
FileInputStream fis = new FileInputStream(new File("hello.txt"));//Constructor FileInputStream (file)
FileInputStream fis1 = new FileInputStream("hello.txt");//Constructor FileInputStream(String name)
//Both are the same. The second is to convert the path into a file object first
Implement file encryption
Exercise: realize the file encryption operation (tip: use XOR operation.)
Image encryption:
//Image encryption
@Test
public void test8(){
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream("Picture 1.jpg");
fos = new FileOutputStream("Picture 3.jpg");
byte[] buffer = new byte[1024];
int len;
while ((len = fis.read(buffer)) != -1){
//Encryption operation: byte by byte encryption is required, so the cyclic implementation modifies the byte array
/*
Note that this method is wrong, because foreach takes out the element and assigns it to another variable, which cannot modify the array itself
It should be noted that the foreach loop cannot be used to modify the array elements
for (byte b :
buffer) {
b = (byte) (b ^ 5);
}
*/
//correct
for (int i = 0; i < len; i++) {
//The range of byte is - 128 ~ 127, which is also stored in the array. The result of operation with integer is integer, so it needs to be forcibly converted
//XOR operation. In binary, the same is 0 and the different is 1 The original value can be obtained by another XOR operation
//So the decryption code doesn't need to change here.
buffer[i] = (byte) (buffer[i] ^ 5);
}
fos.write(buffer,0,len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//close resource
try {
if (fos != null)
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if (fis != null)
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Decryption of pictures:
//Image decryption operation: because the result of XOR operation twice is the same as before, the core code does not need to be changed, just change the file path
//XOR operation: for example, 6 ^ 3 = 5; 5 ^ 3 = 6; You can get the previous results again
@Test
public void test9(){
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream("Picture 3.jpg");
fos = new FileOutputStream("Picture 4.jpg");
byte[] buffer = new byte[1024];
int len;
while ((len = fis.read(buffer)) != -1){
//To encrypt an array of bytes, you need to encrypt a byte loop
/*
Note that this method is wrong, because foreach takes out the element and assigns it to another variable, which cannot modify the array itself
It should be noted that the foreach loop cannot be used to modify the array elements
for (byte b :
buffer) {
b = (byte) (b ^ 5);
}
*/
//correct
for (int i = 0; i < len; i++) {
//The range of byte is - 128 ~ 127, which is also stored in the array. The result of operation with integer is integer, so it needs to be forcibly converted
//XOR operation. In binary, the same is 0 and the different is 1 The original value can be obtained by another XOR operation
//So the decryption code doesn't need to change here.
buffer[i] = (byte) (buffer[i] ^ 5);
}
fos.write(buffer,0,len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//close resource
try {
if (fos != null)
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if (fis != null)
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
be careful:
1. The range of byte is - 128 ~ 127, so the value stored in byte [] array is also in this range. Similar to int []
2.foreach loop cannot change the original array elements, because foreach loop assigns the elements in the array to a new variable. We use new variables and modify them on the new variables.
Gets the number of occurrences of each character on the text
Exercise: get the number of occurrences of each character on the text. (prompt: traverse each character of the text; save the character and its occurrence times in the Map; write the data in the Map to the file)
/**
* Exercise 3: get the number of characters on the text and write the data to the file
*
* Idea:
* 1.Traverse each character of the text
* 2.The number of times characters appear exists in the Map
*
* Map<Character,Integer> map = new HashMap<Character,Integer>();
* map.put('a',18);
* map.put('You ', 2);
*
* 3.Write the data in the map to the file
*/
/*
Note: if unit testing is used, the relative path of the file is the current module
If the main() test is used, the relative path of the file is the current project
*/
@Test
public void testWordCount() {
FileReader fr = null;
BufferedWriter bw = null;
try {
//1. Create a Map collection
Map<Character, Integer> map = new HashMap<Character, Integer>();
//2. Traverse each character and put the number of occurrences of each character into the map
fr = new FileReader("dbcp.txt");
int c = 0;
while ((c = fr.read()) != -1) {
//int restore char
char ch = (char) c;
// Determine whether char appears for the first time in the map
if (map.get(ch) == null) {
map.put(ch, 1);
} else {
map.put(ch, map.get(ch) + 1);
}
}
//3. Save the data in the map to the file count txt
//3.1 create Writer
bw = new BufferedWriter(new FileWriter("wordcount.txt"));
//3.2 traverse the map and then write the data
Set<Map.Entry<Character, Integer>> entrySet = map.entrySet();
for (Map.Entry<Character, Integer> entry : entrySet) {
//The ASCII codes corresponding to space, tab, carriage return and line feed are different, so they should be matched one by one
switch (entry.getKey()) {
case ' ':
bw.write("Space=" + entry.getValue());
break;
case '\t'://\t represents the tab key character
bw.write("tab key=" + entry.getValue());
break;
case '\r'://
bw.write("enter=" + entry.getValue());
break;
case '\n'://
bw.write("Line feed=" + entry.getValue());
break;
default:
//In addition to the above four, the others fall here
bw.write(entry.getKey() + "=" + entry.getValue());
break;
}
bw.newLine();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//4. Shut down
if (fr != null) {
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (bw != null) {
try {
bw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
Conversion flow
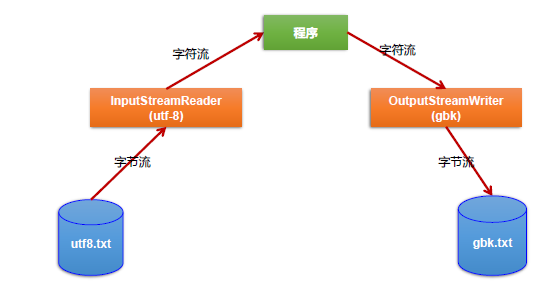
Originally, byte stream is not recommended to process text data. Now there is a conversion stream, which can convert byte stream into character stream and character stream into byte stream.
Processing flow 2: use of conversion flow
1. Conversion stream: it belongs to character stream
InputStreamReader: converts a byte input stream to a character input stream
OutputStreamWriter: converts a character output stream to a byte output stream
Determine whether it is a character stream or a byte stream from the suffix of the name.
2. Function: provide conversion between byte stream and character stream
3. Decoding: byte, byte array - > character array, string
Encoding: character array, string - > byte, byte array
(remember that decoding is the conversion from what you can't understand to what you can understand; coding is the conversion from what you can understand to what you can't understand.)
Encoding determines the format of decoding. Whatever format is used for encoding, it needs to be decoded in whatever format.
4. Character set
Use of InputStreamReader:
Note which character set is used in the constructor.
//The use of InputStreamReader realizes the conversion from byte input stream to character input stream
@Test
public void test10(){
InputStreamReader isr = null;
try {
FileInputStream fis = new FileInputStream("hello.txt");
//InputStreamReader isr = new InputStreamReader(fis);// Use the system (IDEA) default character set
//Parameter 2 indicates the character set. Which character set to use depends on the file hello Txt character set used when saving
isr = new InputStreamReader(fis,"UTF-8");
char[] cbuf = new char[3];
int len;
while ((len = isr.read(cbuf)) != -1){
String str = new String(cbuf,0,len);
System.out.print(str);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (isr != null)
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Use InputStreamReader and OutputStreamWriter together
//Use InputStreamReader and OutputStreamWriter together
@Test
public void test11(){
InputStreamReader isr = null;
OutputStreamWriter osw = null;
try {
//Realize reading files with UTF-8 and writing files with GBK
isr = new InputStreamReader(new FileInputStream("hello.txt"),"UTF-8");
osw = new OutputStreamWriter(new FileOutputStream("hello_gbk.txt"),"GBK");
//Implementation details
char[] cbuf = new char[20];
int len;
while ((len = isr.read(cbuf)) != -1){
osw.write(cbuf,0,len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (osw != null)
osw.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if (isr != null)
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Coding application of conversion stream:
- You can store characters in a specified encoding format
- Text data can be interpreted according to the specified coding format
- The action of specifying the encoding table is completed by the constructor
Character set (understand content)
Origin of coding table:
Computers can only recognize binary data, which originated from electrical signals in the early days. In order to facilitate the application of the computer, it can recognize the characters of various countries. The words of each country are expressed in numbers and correspond one by one to form a table. This is the coding table.
Common coding tables:
ASCII: American standard information interchange code. It can be represented by 7 bits of a byte.
ISO8859-1: Latin code table. European code table. Represented by 8 bits of a byte.
GB2312: Chinese coding table of China. Up to two bytes encode all characters (English characters are also represented by one byte, while some Chinese characters are represented by one byte and some are represented by two bytes)
GBK: China's Chinese coding table has been upgraded to integrate more Chinese characters and symbols. Two byte encoding at most (English characters are also represented by one byte, while some Chinese characters are represented by one byte and some are represented by two bytes)
Unicode: international standard code, which integrates all characters currently used by human beings. Assign a unique character code to each character. All text is represented by two bytes.
UTF-8: variable length encoding method. 1-4 bytes can be used to represent a character.
GBK, GB2312 and other double byte encoding methods. The highest bit is 1 or 0 to represent two bytes and one byte.
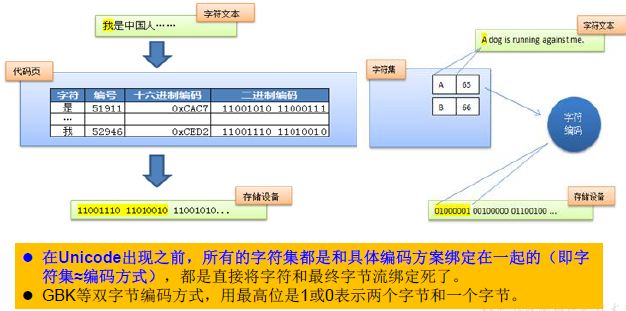
Unicode is not really implemented. The reason is that Unicode is not perfect. Here are three problems. One is that we already know that only one byte is enough for English letters. The second problem is how to distinguish Unicode from ASCII? How does the computer know that two bytes represent one symbol instead of two symbols respectively? Third, if the encoding method is the same as that of GBK and other double bytes, and the highest bit is 1 or 0 to represent two bytes and one byte, there are many fewer values, which can not be used to represent characters, not enough to represent all characters. Unicode could not be popularized for a long time until the emergence of the Internet.
Many * * UTF (UCS Transfer Format) * * standards for transmission have emerged. As the name suggests, * * UTF-8 is to transmit data 8 bits at a time, while UTF-16 is to transmit data 16 bits at a time** This is a code designed for transmission and makes the code borderless, so that the characters of all cultures in the world can be displayed.
Unicode only defines a huge and * * universal character set, * * and specifies a unique number for each character. The specific byte stream stored depends on the character coding scheme. The recommended Unicode encodings are UTF-8 and UTF-16.

Chinese takes up three bytes in UTF-8.
ANSI National Standards Institute
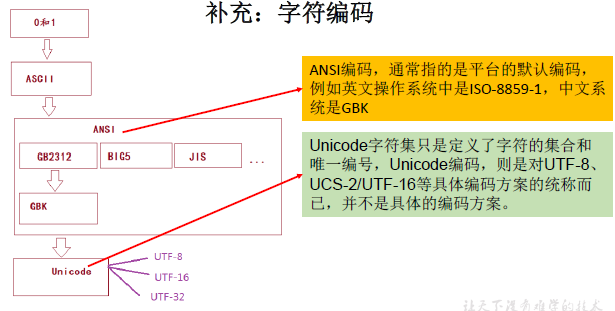
Encoding determines the format of decoding. Whatever format is used for encoding, it needs to be decoded in whatever format.
Client / browser < – > background (java, python...) < – > Database
The character set used before and after is required to be unified: UTF-8
Other streams
Use of other streams:
1. Standard input and output streams
2. Print stream
3. Data flow
Standard input and output streams
1.System.in: standard input stream, which is input from the keyboard by default
System.out: standard output stream, which is output from the console by default.
System. The type of in is InputStream (type is the type of return value)
System. The type of out is PrintStream, which is a subclass of FilterOutputStream, which is a subclass of OutputStream
2. Redirection: * * change the default device through setIn and setOut methods of System class, * * reassign the input and output devices.
public static void setIn(InputStream in)
public static void setOut(PrintStream out)
Exercise: input a string from the keyboard and convert the whole line of string read into uppercase output. Then continue the input operation until you exit the program when you enter "e" or "exit".
Method 1: use the Scanner implementation and call next() to return a string
Points needing attention in the program: ① use the equals() method to judge the same string. ② In order to avoid null pointer exceptions, the determined is usually written in front of the variable. “e”. equalsIgnoreCase(str)
/**
* When inputting a string from the keyboard, it is required to convert the read whole line of string into uppercase output.
* Then continue the input operation until you exit the program when you enter "e" or "exit".
* Method 1: use the Scanner implementation and call next() to return a string
* Method 2: use system In implementation. System.in -- > Transform stream -- > readLine() of BufferedReader
* Cause system In returns InputStream, which is a byte stream. To use character stream, you need to convert it first
*/
@Test
public void test12(){
//Method 1
Scanner scanner = new Scanner(System.in);
while (true){
System.out.println("Please enter a string to convert to uppercase(input\"e\"perhaps\"exit\"Representative exit procedure): ");
String str = scanner.next();
//Use equals() to judge the equality of strings
//In order to avoid null pointer exceptions, the determined is usually written in front of the variable.
if ("e".equalsIgnoreCase(str) || "exit".equalsIgnoreCase(str)){//This is the best way
//if (str.equals("e") || str.equals("exit")){
System.out.println("Exit the program successfully!");
break;
}
String toUpperCase = str.toUpperCase();
System.out.println(toUpperCase);
}
}
Method 2: use system In implementation. System.in -- > Transform stream -- > readLine() of BufferedReader. Cause system In returns InputStream, which is a byte stream. To use character stream, you need to convert it first. (note that you need to use conversion stream processing)
@Test
public void test13(){
BufferedReader br = null;
try {
//Method 2
InputStreamReader isr = new InputStreamReader(System.in);
br = new BufferedReader(isr);
while (true){
System.out.println("Please enter a string:");
String str = br.readLine();
if ("e".equalsIgnoreCase(str) || "exit".equalsIgnoreCase(str)){
System.out.println("The program is over!");
break;
}
String upperCase = str.toUpperCase();
System.out.println(upperCase);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//close resource
try {
if (br != null)
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Exercise: create a program named myinput java: Contain the methods for reading int, double, float, boolean, short, byte and String values from the keyboard.
The string type is read from the console. To convert to int, you need to call the wrapper class to convert to the corresponding type.
public class MyInput {
// Read a string from the keyboard
public static String readString() {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
// Declare and initialize the string
String string = "";
// Get the string from the keyboard
try {
string = br.readLine();
} catch (IOException ex) {
System.out.println(ex);
}
// Return the string obtained from the keyboard
return string;
}
// Read an int value from the keyboard
public static int readInt() {
return Integer.parseInt(readString());
}
// Read a double value from the keyboard
public static double readDouble() {
return Double.parseDouble(readString());
}
// Read a byte value from the keyboard
public static double readByte() {
return Byte.parseByte(readString());
}
// Read a short value from the keyboard
public static double readShort() {
return Short.parseShort(readString());
}
// Read a long value from the keyboard
public static double readLong() {
return Long.parseLong(readString());
}
// Read a float value from the keyboard
public static double readFloat() {
return Float.parseFloat(readString());
}
}
Solve the problem that you cannot input from the console in the @ Test unit Test method in IDEA
Step1 : Help — > Edit Custom VM Options
Step 2: open and add
-Deditable.java.test.console=true
Step 3: restart IDEA
Print stream
Print stream: PrintStream and PrintWriter provide a series of overloaded print() and println()
Function: convert the data format of basic data type into string output
explain:
- Provides a series of overloaded print() and println() methods for output of multiple data types
- The output of PrintStream and PrintWriter will not throw IOException
- PrintStream and PrintWriter have automatic flush function
- All characters printed by PrintStream are converted to bytes using the platform's default character encoding. When you need to write characters instead of bytes, you should use the PrintWriter class.
- System.out returns an instance of PrintStream
@Test
public void test14() {
PrintStream ps = null;
try {
FileOutputStream fos = new FileOutputStream(new File("D:\\IO\\text.txt"));
// Create a printout stream and set it to automatic refresh mode (the output buffer will be refreshed when writing newline character or byte '\ n')
ps = new PrintStream(fos, true);
if (ps != null) {// Change standard output stream (console output) to file
System.setOut(ps);
//Modify output mode
}
for (int i = 0; i <= 255; i++) { // Output ASCII characters
System.out.print((char) i);
if (i % 50 == 0) { // One row for every 50 data
System.out.println(); // Line feed
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
if (ps != null) {
ps.close();
}
}
}
System.out.println() where system Out returns PrintStream, which is output from the console by default, while println () converts the content into a string for output.
Call the setOut(PrintStream out) method of the System class to change the output device.
Application: when you want to save the output data, you can call setOut() to specify a new output location and save the output in a file.
data stream
1.DataInputStream and DataOutputStream
2. Function: used to read or write variables or strings of basic data types. For example, write the variables or strings in memory to the file, or read the basic data type variables and strings stored in the file into memory and save them in variables. (so this data flow is the communication between memory level and physical storage level)
3. Application: persist the data in memory and save it in the hard disk.
Exercise: write out strings in memory and variables of basic data types into files.
//Write out the string and basic data type variables in memory to the file.
@Test
public void test15(){
DataOutputStream dos = null;
try {
dos = new DataOutputStream(new FileOutputStream("data.txt"));
dos.writeUTF("Lau Andy");
dos.flush();//Refresh operation to write the data in memory to the file
dos.write(23);
dos.flush();
dos.writeBoolean(true);
dos.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
//close resource
try {
if (dos != null)
dos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Note: the file generated by DataOutputStream cannot be opened and read directly by double clicking (otherwise it is garbled). DataInputStream should also be called to read the file into memory for display
**Note: * * the order of reading different types of data should be consistent with the order of the data saved when writing the file. Otherwise, an error is reported.
Read the basic data type variables and characters stored in the file into memory and save them in variables:
/*
Read the basic data type variables and characters stored in the file into memory and save them in variables.
Note: the file generated by DataOutputStream cannot be opened and read directly by double clicking (otherwise it is garbled), and DataInputStream should also be called
Read the file into memory and display
Note: the order of reading different types of data should be consistent with the order of saved data when writing the file. Otherwise, an error is reported.
*/
@Test
public void test16(){
DataInputStream dis = null;
try {
dis = new DataInputStream(new FileInputStream("data.txt"));
String name = dis.readUTF();
int age = dis.readInt();
boolean isMale = dis.readBoolean();
System.out.println("name = " + name);
System.out.println("age = " + age);
System.out.println("isMale = " + isMale);
} catch (IOException e) {
e.printStackTrace();
} finally {
//close resource
try {
if (dis != null)
dis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Object flow
1.ObjectInputStream and ojbectoutputstream
2. Function: the processing stream used to store and read basic data type data or objects. Its strength is that it can write objects in Java to the data source and restore objects from the data source.
- Serialization: the mechanism of saving basic type data or objects with ObjectOutputStream class (writing hard disk files from memory)
- Deserialization: the mechanism of reading basic type data or objects with ObjectInputStream class (reading from hard disk file into memory)
ObjectOutputStream and ObjectInputStream cannot serialize static and transient decorated member variables
Serialization of objects:
The object serialization mechanism allows Java objects in memory to be converted into platform independent binary streams, which allows such binary streams to be permanently stored on disk or transmitted to another network node through the network// When other programs get this binary stream, they can restore it to the original Java object.
Serialization process: save java objects in memory to disk or transmit them through the network, which is realized by ObjectOutputStream
**Note in the middle: * * data streams, object streams and other data streams written from memory to hard disk need to explicitly call flush()
//Serialization process: save java objects in memory to disk or transmit them through the network, which is realized by ObjectOutputStream
@Test
public void test1(){
ObjectOutputStream oos = null;
try {
oos = new ObjectOutputStream(new FileOutputStream("object.txt"));
oos.writeObject(new String("Windy day"));
//Refresh operation
oos.flush();//Data streams, object streams, etc. that are written from memory to the hard disk need to explicitly call flush()
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (oos != null)
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Deserialization: restore the object in the disk file to a java object in memory, which is implemented by ObjectInputStream
What we need to know is that the files generated by writing data streams and object streams from memory to the hard disk cannot be double clicked to open and view. We should use the corresponding read operation to read them into memory
//Data stream, object stream and other files generated by writing from memory to hard disk cannot be opened and viewed by double clicking. Corresponding read operations should be used to read them into memory
//Deserialization: restore the object in the disk file to a java object in memory, which is implemented by ObjectInputStream
@Test
public void test2(){
ObjectInputStream ois = null;
try {
ois = new ObjectInputStream(new FileInputStream("object.txt"));
Object object = ois.readObject();
String str = (String) object;//When we already know the type of object, we can force conversion
System.out.println(str);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
try {
if (ois != null)
ois.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
If you want a java object to be serializable, you need to meet the corresponding requirements. The user-defined class can be serialized only if it meets the following requirements: (one is indispensable)
1. Interface to be implemented: Serializable (it's OK to implement this Externalizable interface, but it's rarely used.)
2. The current class provides a global constant: serialVersionUID (serial version number). (this must be)
public static final long serialVersionUID = -6849794470754667710L; //The serialVersionUID of this long type can be written casually, positive or negative.
serialVersionUID is used to indicate the compatibility between different versions of a class. In short, its purpose is to use serialized objects for version control, and whether each version is compatible during deserialization.
If the class does not show the definition of this static constant, its value is automatically generated by the Java runtime environment according to the internal details of the class. If the instance variable of the class is modified, the serialVersionUID may change. Therefore, it is recommended to explicitly declare.
3. In addition to the Serializable interface that the current custom class needs to implement, all its internal attributes must also be Serializable. (by default, basic data type and String can be serialized). [for example, if the type of an attribute in the current user-defined class is another user-defined class, then other user-defined classes as attributes must be Serializable before this user-defined class can be serialized.]
Supplement: ObjectOutputStream and ObjectInputStream cannot serialize member variables decorated with static and transient.
After serialization and deserialization of member variables modified with static and transient, the result is the default value of the attribute, such as String = null; Because these two decorated cannot be serialized, the data in memory cannot be saved in the hard disk, and the natural reading is also the default value.
An analogy: for example, if a person (an object) wants to travel through time and space through the time and space gate (this process can be understood as serialization), each part (each attribute) of the body must be serializable in order to serialize.
The attributes modified by static are classified and not owned by the object, so they cannot be serialized; transient means to prohibit the serialization of modified attributes
Summary requirements:
1. Interface to be implemented: Serializable
2. The current class provides a global constant: serialVersionUID
3. In addition to the Serializable interface that the current custom class needs to implement, all its internal attributes must also be Serializable. (by default, basic data type and String can be serialized).
Serialization is a mechanism that must be implemented for both parameters and return values of RMI (Remote Method Invoke), and RMI is the basis of Java EE. Therefore, serialization mechanism is the basis of Java EE platform.
The focus of this part is to understand the serialization mechanism, which is closely related to the following Java EE. We must implement the serialization mechanism, and the actual transmission is JSON (JSON is a string)
Talk about your understanding of Java io. Serializable interface. We know it is used for serialization. It is an empty method interface. Is there any other understanding?
Objects that implement the Serializable interface can be converted into a series of bytes, and can be completely restored to the original appearance in the future** This process can also be carried out through the network. This means that the serialization mechanism can automatically compensate for differences between operating systems** In other words, you can create an object on a Windows machine, serialize it, send it to a Unix machine over the network, and then "reassemble" there accurately. You don't have to care about how the data is represented on different machines, the order of bytes or any other details.
Because most classes as parameters, such as String and Integer, implement Java io. Serializable interfaces can also take advantage of polymorphism as parameters to make the interface more flexible.
RandomAccessFile
RandomAccessFile class supports "random access". The program can directly jump to any place of the file to read and write the file
- Only partial contents of the file can be accessed
- You can append content to an existing file
Use of RandomAccessFile
1.RandomAccessFile directly inherits from Java Lang. object class, which implements DataInput and DataOutput interfaces
2.RandomAccessFile can be used as both an input stream and an output stream (but you need to create two objects, one as an input stream and one as an output stream)
3. If RandomAccessFile is used as the output stream, if the file written out does not exist, it will be automatically created during execution; If the file written out exists, the contents of the original file will be overwritten. (by default, the number of overwrites can be retained.)
Supplement: ① overwrite the file: replace all the contents of the file with new contents; ② append the file: append the contents after the original file; ③ overwrite the contents of the file: retain the contents of the original file, overwrite the contents, and retain the contents that can be covered as much as possible, and those that are not covered.
Constructor (the parameter is a file or path, not the previous byte stream / character stream)
public RandomAccessFile(File file, String mode)
public RandomAccessFile(String name, String mode)
To create an instance of RandomAccessFile class, you need to specify a mode parameter, which specifies the access mode of RandomAccessFile:
-
r: Open as read-only (only files can be read)
-
rw: open for reading and writing (can read or write)
-
rwd: open for reading and writing; Synchronize file content updates
-
rws: open for reading and writing; Synchronize file content and metadata updates
Note: there is no separate "w".
If the mode is read-only r. Instead of creating a file, it will read an existing file. If the read file does not exist, an exception will appear. If the mode is rw read / write. If the file does not exist, it will be created. If it does exist, it will not be created.
jdk1.6. When writing data in "rw" mode, the data will not be written to the hard disk immediately; while in "rwd", the data will be written to the hard disk immediately. If the data writing process is abnormal, the written data in "rwd" mode will be saved to the hard disk, and "rw" will be lost.
RandomAccessFile or byte [] array
@Test
public void test1(){
RandomAccessFile raf1 = null;
RandomAccessFile raf2 = null;
try {
raf1 = new RandomAccessFile("Picture 1.jpg","r");//Can only read
raf2 = new RandomAccessFile("Picture 3.jpg","rw");//Readable and writable
//Or byte [] array
byte[] buffer = new byte[1024];
int len;
while ((len = raf1.read(buffer)) != -1){
raf2.write(buffer,0,len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (raf2 != null)
raf2.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if (raf1 != null)
raf1.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Default overwrite from scratch:
@Test
public void test2(){
RandomAccessFile raf1 = null;
try {
raf1 = new RandomAccessFile("hello.txt","rw");
raf1.write("xyz".getBytes());
/*
The original text content is HelloWorld123, and the modified content is xyzloWorld123.
Default overwrite from scratch
*/
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (raf1 != null)
raf1.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
The RandomAccessFile object contains a record pointer to indicate the location of the current read / write location. RandomAccessFile class object can move the record pointer freely:
- long getFilePointer(): get the current position of the file record pointer
- void seek(long pos): locate the file record pointer to the pos position
Using seek(long pos) to realize the coverage from the specified location; Call the method to obtain the file length to append content at the end of the file
@Test
public void test2(){
RandomAccessFile raf1 = null;
try {
raf1 = new RandomAccessFile("hello.txt","rw");
raf1.seek(3);//Adjust the pointer to the position marked with 3. Insert from pointer
/*//To add and fill in the content at the end of the file, just position the pointer to the end of the file
raf1.seek(new File("hello.txt").length());//Call file length method*/
raf1.write("xyz".getBytes());
/*
The original text content is HelloWorld123. After modification, it is Helxyzorld123.
Overwrite from pointer
*/
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (raf1 != null)
raf1.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
4. RandomAccessFile can "insert" data through relevant operations.
RandomAccessFile is used to realize the effect of data insertion
: implementation method: first save the position to be inserted and all subsequent data temporarily. At this time, the pointer has pointed to the end of the file, and you need to call the pointer back. After overwriting, call the write method to write the temporarily saved data (at this time, the pointer has reached the end of the insertion content, just call the method to overwrite the saved file directly)
There are many places worth learning from in this method. After saving the following data, the pointer should be recalled. Save the data in StringBuilder (at this time at the memory level).
/*
RandomAccessFile is used to realize the effect of data insertion
Implementation method: first save the position to be inserted and all the data behind it temporarily. At this time, the pointer has pointed to the end of the file, and you need to call the pointer back.
After overwriting, call the write method to write the temporarily saved data (at this time, the pointer has reached the end of the inserted content,
Directly call the method to overwrite the saved file)
*/
@Test
public void test3(){
RandomAccessFile raf = null;
try {
raf = new RandomAccessFile("hello.txt","rw");
raf.seek(3);//Adjust the pointer to the position marked with angle 3
//Save all data after pointer 3 to StringBuilder
StringBuilder builder = new StringBuilder((int) new File("hello.txt").length());
//The reason why String is not used is that it is inefficient and requires frequent replacement of memory areas. Because StringBuilder has a default value, I'm afraid the file is too long,
//First specify the length of StringBuilder directly, and then expand the capacity to save
byte[] buffer = new byte[20];
int len;
while ((len = raf.read(buffer)) != -1){
builder.append(new String(buffer,0,len));//There is no byte [] parameter in the constructor, so it is converted to a string first
}
//Call back the pointer and write "xyz"
raf.seek(3);
raf.write("xyz".getBytes());
//Write the data in StringBuilder to a file. (at this time, the pointer has been pointed at the correct position, so there is no need to adjust it)
//The write parameter can only be a byte [] array. StringBuilder must first convert to String and then to byte [] array
raf.write(builder.toString().getBytes());
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (raf != null)
raf.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/*
result:
Original content: HelloWo modified content: HelxyzloWo
rld123 rld123
*/
}
To implement the insert operation, you need to save too much temporary data, which is memory consuming at the memory level.
You can also use ByteArrayOutputStream stream stream to store temporary data, for example
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buffer = new byte[10];
int len;
while ((len = fis.read(buffer)) != -1) {
baos.write(buffer, 0, len);
}
return baos.toString();
The bottom layer of ByteArrayOutputStream is also stored in a char [] array. Calling the write() method is to write the data into the char [] array.
The RandomAccessFile class can be used to realize the insertion effect, which can realize the function of breakpoint continuation. Specific implementation ideas:
RandomAccessFile can be used to realize the function of multi-threaded breakpoint download. Anyone who has used the download tool knows that before downloading, two temporary files will be created, one is an empty file with the same size as the downloaded file, and the other is a file that records the location of the file pointer. Each pause will save the last pointer, and then when the breakpoint is downloaded, It will continue to download from the last place, so as to realize the function of breakpoint download or upload.
NIO overview
Java NIO (New IO, non blocking IO) can be understood in both ways; Non blocking IO
At present, NIO is only for understanding. I'll talk more about it later when it comes to the framework.
NIO supports buffer oriented (IO is stream oriented) and channel based IO operations. NIO will read and write files in a more efficient way.
Java API provides two sets of NIO, one for standard input and output NIO and the other for network programming NIO.
|-----java.nio.channels.Channel
|-----FileChannel: processing local files
|-----SocketChannel: the Channel of TCP network programming client
|-----Serversocketchannel: the server-side Channel of TCP network programming
|-----Datagram Channel: the Channel of the sender and receiver in UDP network programming
With the release of JDK 7, Java has greatly extended NIO and enhanced its support for file processing and file system features, so that we call them NIO 2. NIO has become an increasingly important part of file processing because of some functions provided by NIO.
Path, Paths, and Files core API s
Paths, Files, etc. followed by s, Arrays, math, etc. are tool classes that provide static methods.
Early Java only provided a File class to access the File system, but the function of File class is relatively limited and the performance of the method provided is not high. Moreover, most methods only return failure when there is an error, and do not provide exception information.
NIO. In order to make up for this deficiency, the path interface is introduced, which represents a platform independent path and describes the location of files in the directory structure. Path can be regarded as an upgraded version of the File class, and the actually referenced resources may not exist.
In the past, IO operations were written like this:
import java.io.File;
File file = new File("index.html");
But in Java 7, we can write this:
import java.nio.file.Path;
import java.nio.file.Paths;
Path path = Paths.get("index.html");
Meanwhile, NiO 2 in Java nio. Files and paths tool classes are also provided under the file package. Files contains a large number of static tool methods to operate files; Paths contains two static factory methods that return Path. Factory design pattern: it is specially used to create objects.
The static get() method provided by the Paths class is used to obtain the Path object:
- static Path get(String first, String... more): used to string multiple characters into a path
- Static Path get (uri): returns the Path corresponding to the specified uri
Path interface
Path common methods:
- String toString(): returns the string representation of the calling Path object
- boolean startsWith(String path): judge whether to start with path path
- boolean endsWith(String path): judge whether to end with path path
- boolean isAbsolute(): judge whether it is an absolute path
- Path getParent(): the returned path object contains the entire path, not the file path specified by the path object
- Path getRoot(): returns the root path of the calling path object
- Path getFileName(): returns the file name associated with the calling path object
- int getNameCount(): returns the number of elements behind the Path root directory
- Path getName(int idx): returns the path name of the specified index location idx
- Path toAbsolutePath(): returns the calling path object as an absolute path
- Path resolve(Path p): merge two paths and return the path object corresponding to the merged path
- File toFile(): converts Path to an object of file class
Files class
java.nio.file.Files is a tool class used to manipulate files or directories.
Files common methods:
- Path copy(Path src, Path dest, CopyOption... how): copy of files
- Path createdirectory (path, fileattribute <? >... attr): create a directory
- Path CreateFile (path, fileattribute <? >... arr): create a file
- Void delete (path): delete a file / directory. If it does not exist, an error will be reported
- Void deleteifexists (path): delete the file / directory corresponding to the path if it exists
- Path move(Path src, Path dest, CopyOption... how): move src to dest
- Long size (path): returns the size of the specified file
Files common method: used to judge
- Boolean exists (path, linkoption... opts): judge whether the file exists
- Boolean isdirectory (path, linkoption... opts): judge whether it is a directory
- Boolean isregularfile (path, linkoption... opts): judge whether it is a file
- Boolean ishidden (path): judge whether it is a hidden file
- Boolean is readable (path): judge whether the file is readable
- Boolean iswritable (path): judge whether the file is writable
- Boolean notexists (path, linkoption... opts): judge whether the file does not exist
Files common method: used to operate content
- Seekablebytechannel newbytechannel (path, openoption... how): gets the connection to the specified file, and how specifies the opening method.
- DirectoryStream Newdirectorystream (path): open the directory specified in path
- InputStream newinputstream (path, openoption... how): get the InputStream object
- OutputStream newoutputstream (path, openoption... how): get the OutputStream object
Importing third-party jar packages from IDEA
Note that the ". class" bytecode files are stored in the jar package, and the ". java" files are used for development
Use the third-party jar package to read and write data.
jar package is equivalent to providing additional API, which is not the API in JDK.
Import jar package in IDEA:
If it is imported under the current Module: current Module - > New - > directory
The third-party jar package is placed in the Lib folder (or libs), and the full name of lib is library
Copy the jar package to the package
It cannot be used at this time. The following settings should be made: select the jar package and right click – > Add as library
Select OK
At this point, it can be used as an API.
After testing, you can use the API under the jar package
Use jar package to copy files:
//Use jar package to copy files.
@Test
public void test4(){
File srcFile = new File("Picture 1.jpg");
File destFile = new File("Picture 3.jpg");
try {
//The jar package actually encapsulates the basic methods we learn. The underlying knowledge is still to process files with streams
FileUtils.copyFile(srcFile,destFile);
} catch (IOException e) {
e.printStackTrace();
}
}