UNION introduction
DataStream. The Union () method combines two or more datastreams into one output datastream with the same type as the input stream
The event confluence mode is FIFO mode. Operators do not produce a specific sequence of event flows. The union operator also does not de duplicate. Each input event is sent to the next operator.
explain:
1. The elements of the union merged stream must be the same
2.union can merge multiple streams
3. The union does not remove the weight, and the merging order is first in first out
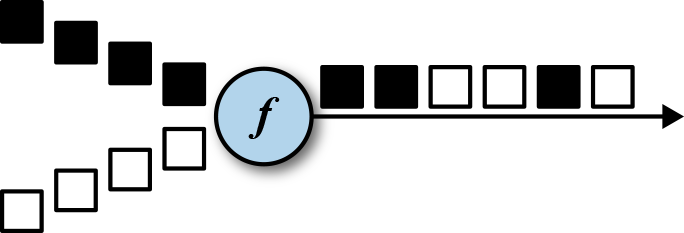
Specific usage:
DataStream<SensorReading> parisStream = ...
DataStream<SensorReading> tokyoStream = ...
DataStream<SensorReading> rioStream = ...
DataStream<SensorReading> allCities = parisStream
.union(tokyoStream, rioStream)
CONNECT
CONNECT is also used to merge multiple data streams. Its function is similar to that of UNION. The difference is:
Connect can only connect two data streams, and union can connect multiple data streams.
The data types of the two data streams connected by connect can be inconsistent, and the data types of the two data streams connected by union must be consistent.
Two datastreams are converted into ConnectedStreams after being connected. ConnectedStreams will apply different processing methods to the data of the two streams, and the state can be shared between the two streams.
connect is often used in scenarios where one data stream uses another for control processing.
Specific usage:
Merge flow:
// first stream
DataStream<Integer> first = ...
// second stream
DataStream<String> second = ...
// connect streams
ConnectedStreams<Integer, String> connected = first.connect(second);
Merge two keyby
DataStream<Tuple2<Integer, Long>> one = ...
DataStream<Tuple2<Integer, String>> two = ...
// keyBy two connected streams
ConnectedStreams<Tuple2<Int, Long>, Tuple2<Integer, String>> keyedConnect1 = one
.connect(two)
.keyBy(0, 0); // key both input streams on first attribute
// alternative: connect two keyed streams
ConnectedStreams<Tuple2<Integer, Long>, Tuple2<Integer, String>> keyedConnect2 = one
.keyBy(0)
.connect(two.keyBy(0));
CoGroup:
This operation is to group two data streams / sets according to the key, and then process the data with the same key. However, it is slightly different from the join operation. If it does not find data matching the other in one stream / data set, it will still be output.
import org.apache.flink.api.common.functions.CoGroupFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.triggers.CountTrigger;
import org.apache.flink.util.Collector;
import java.util.Random;
import java.util.concurrent.TimeUnit;
public class CoGroupMain {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
final Random random = new Random();
DataStreamSource<Tuple2<String, String>> source1 = env.addSource(new RichSourceFunction<Tuple2<String, String>>() {
boolean isRunning = true;
String[] s1 = {"1,a", "2,b", "3,c", "4,d", "5,e"};
public void run(SourceContext<Tuple2<String, String>> ctx) throws Exception {
int size = s1.length;
while (isRunning) {
TimeUnit.SECONDS.sleep(1);
String[] s = s1[random.nextInt(size)].split(",");
Tuple2 t = new Tuple2();
t.f0 = s[0];
t.f1 = s[1];
ctx.collect(t);
}
}
public void cancel() {
isRunning = false;
}
});
DataStreamSource<Tuple2<String, String>> source2 = env.addSource(new RichSourceFunction<Tuple2<String, String>>() {
boolean isRunning = true;
String[] s1 = {"1,a", "2,b", "3,c", "4,d", "5,e", "6,f", "7,g", "8,h"};
public void run(SourceContext<Tuple2<String, String>> ctx) throws Exception {
int size = s1.length;
while (isRunning) {
TimeUnit.SECONDS.sleep(3);
String[] s = s1[random.nextInt(size)].split(",");
Tuple2 t = new Tuple2();
t.f0 = s[0];
t.f1 = s[1];
ctx.collect(t);
}
}
public void cancel() {
isRunning = false;
}
});
source1.coGroup(source2)
.where(new KeySelector<Tuple2<String, String>, Object>() {
public Object getKey(Tuple2<String, String> value) throws Exception {
return value.f0;
}
}).equalTo(new KeySelector<Tuple2<String, String>, Object>() {
public Object getKey(Tuple2<String, String> value) throws Exception {
return value.f0;
}
}).window(ProcessingTimeSessionWindows.withGap(Time.seconds(3)))
.trigger(CountTrigger.of(1))
.apply(new CoGroupFunction<Tuple2<String, String>, Tuple2<String, String>, Object>() {
public void coGroup(Iterable<Tuple2<String, String>> first, Iterable<Tuple2<String, String>> second, Collector<Object> out) throws Exception {
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append("DataStream first:\n");
for (Tuple2<String, String> value : first) {
stringBuffer.append(value.f0 + "=>" + value.f1 + "\n");
}
stringBuffer.append("DataStream second:\n");
for (Tuple2<String, String> value : second) {
stringBuffer.append(value.f0 + "=>" + value.f1 + "\n");
}
out.collect(stringBuffer.toString());
}
}).print();
env.execute();
}
}
Join
There are four common join s in flink:
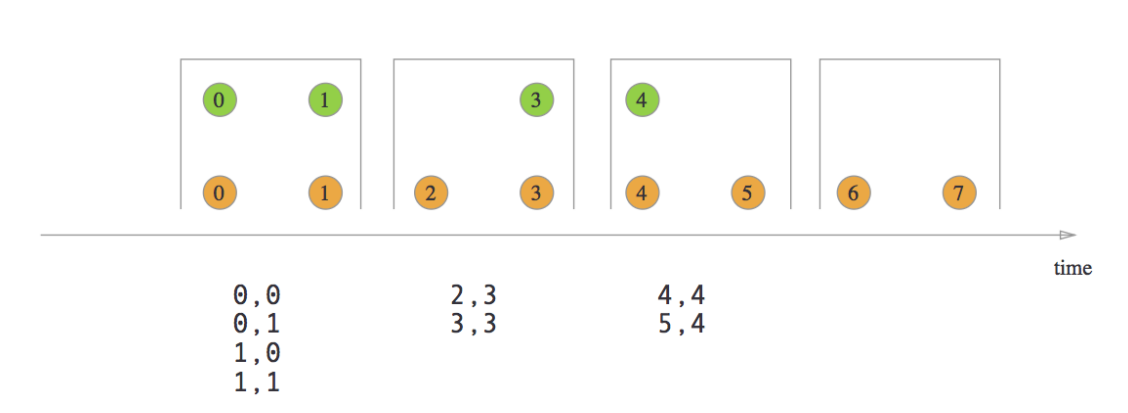
- Tumbling Window Join
- Sliding Window Join
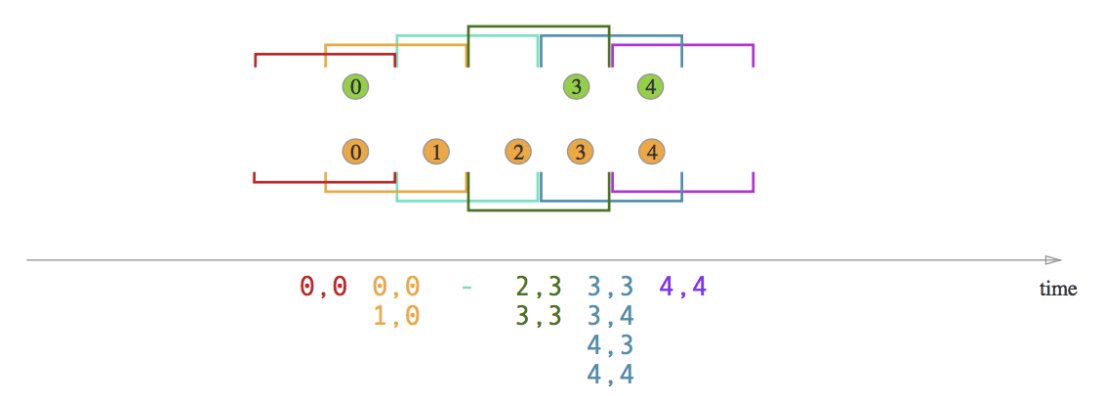
- Session Window Join
- Interval Join
The programming model of Join is:
stream.join(otherStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)
Instance of Tumbling Window Join:
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.triggers.CountTrigger;
public class TumblingMain {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//Set time semantics
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream<Tuple2<String, String>> source1 = env.socketTextStream("192.168.6.23", 9022)
.map(new MapFunction<String, Tuple2<String, String>>() {
public Tuple2<String, String> map(String value) throws Exception {
return Tuple2.of(value.split(" ")[0], value.split(" ")[1]);
}
});
DataStream<Tuple2<String, String>> source2 = env.socketTextStream("192.168.6.23", 9023)
.map(new MapFunction<String, Tuple2<String, String>>() {
public Tuple2<String, String> map(String value) throws Exception {
return Tuple2.of(value.split(" ")[0], value.split(" ")[1]);
}
});
source1.join(source2)
.where(new KeySelector<Tuple2<String, String>, Object>() {
public Object getKey(Tuple2<String, String> value) throws Exception {
return value.f0;
}
})
.equalTo(new KeySelector<Tuple2<String, String>, Object>() {
public Object getKey(Tuple2<String, String> value) throws Exception {
return value.f0;
}
})
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.trigger(CountTrigger.of(1))
.apply(new JoinFunction<Tuple2<String, String>, Tuple2<String, String>, Object>() {
public Object join(Tuple2<String, String> first, Tuple2<String, String> second) throws Exception {
if (first.f0.equals(second.f0)) {
return first.f1 + " " + second.f1;
}
return null;
}
}).print();
env.execute();
}
}
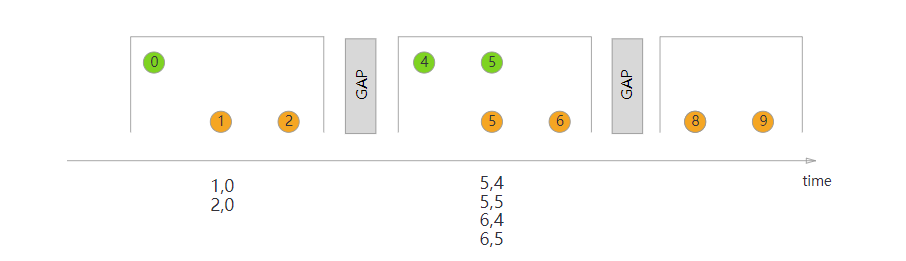
Interval Join
Interval join will join two data streams according to the same key, and the data within the time range of one stream will be processed. It is usually used to pull the relevant packet data into a wide table within a certain time range. We can usually use an expression similar to the following to use interval join to process two data streams
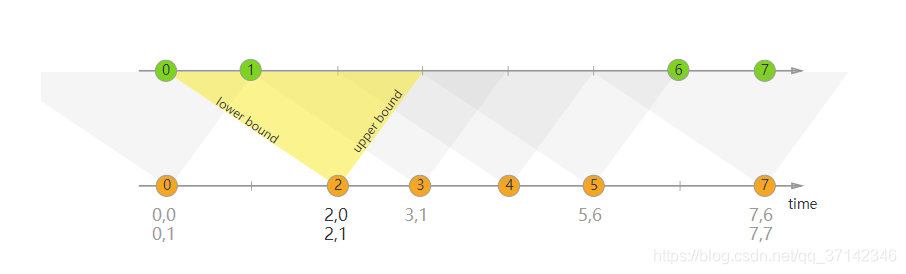
Interval Join becomes a model:
orangeStream
.keyBy(<KeySelector>)
.intervalJoin(greenStream.keyBy(<KeySelector>))
.between(Time.milliseconds(-2), Time.milliseconds(1))
.process (new ProcessJoinFunction<Integer, Integer, String(){
@Override
public void processElement(Integer left, Integer right, Context ctx, Collector<String> out) {
out.collect(first + "," + second);
}
});