Java collection [key]
The collection stores the reference, memory and collection architecture diagram of the object
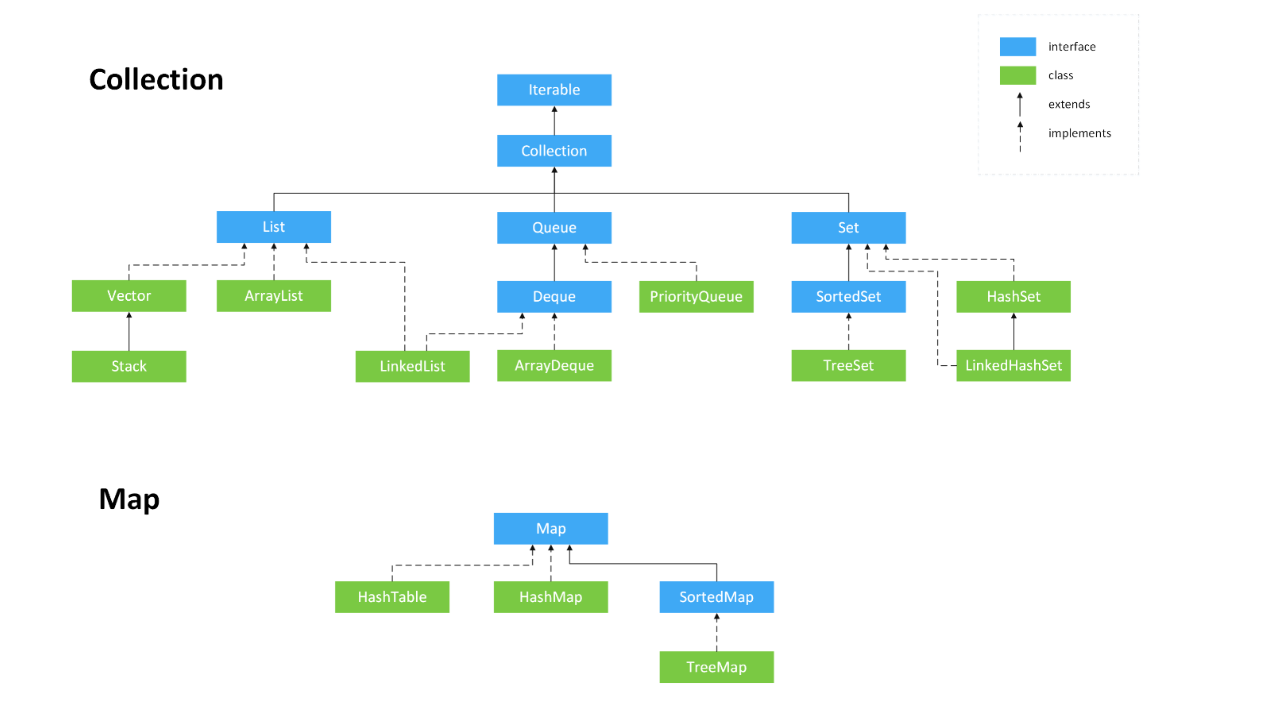
1. Iterable interface:
-
Iterator method: call the iterator method to return an iterator of type iterator
public class IteratorTest { public static void main(String[] args) { Collection c = new HashSet(); c.add(100) ; //Automatic packing c.add(20) ; Iterator it = c.iterator(); //Returns the collection iterator object, which is used to iterate (traverse) the collection! //An iterator is similar to a snapshot, which records the current state (structure) of a collection. Once the state changes, the iterator needs to be retrieved, while(it.hasNext()){ Object obj = it.next() ; System.out.println(obj); if (obj instanceof Integer) System.out.println("The return is Integer type"); } } } //The returned iterator, it can be regarded as a pointer to the previous position of the first element of the iterator! it.hasnext()Is the next element it.next()No matter what type the element is, a object Type object it.remove()Iterator delete, that is, delete the elements in the snapshot, and the elements in the collection will also be deleted!
2. Collection interface:
Common methods:
-
add (Object obj): adds an element to the collection
-
size (): returns the number of elements in the collection, not the capacity of the collection
-
contains: the bottom layer calls the euqals method. Its essence is to compare the elements in the collection with them. If equals is overridden, the contents will be compared. Otherwise, the memory address will be used to judge whether they are equal
-
remove: the bottom layer calls the equals method, which is essentially the same as the contains method!
Summary: the equals method needs to be rewritten!
Methods in other interfaces refer to API documentation
3. List interface
3.1 ArrayList analysis*
ArrayList is the main implementation class of List. The underlying layer uses Object [] storage. It is suitable for frequent search work, and the thread is unsafe
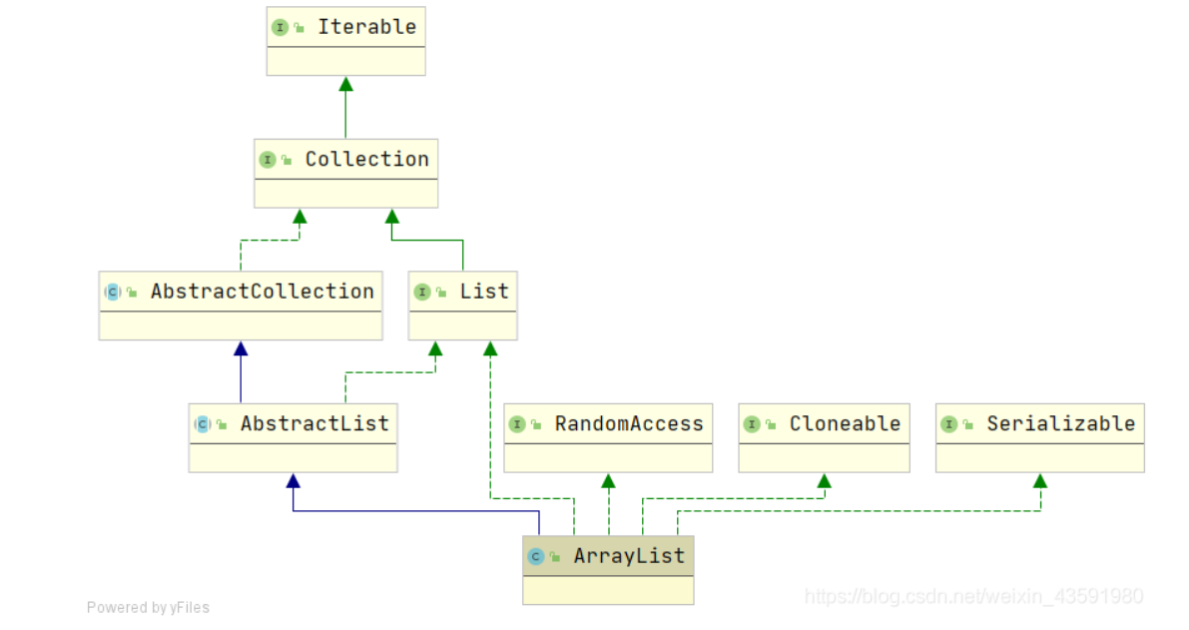
ArrayList is also called dynamic array. The bottom layer is a List based on array. The difference between ArrayList and array is that it has the ability of dynamic expansion. As can be seen from the inheritance system diagram, ArrayList:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
...
}
- List, RandomAccess, clonable, Java io. Serializable and other interfaces
- List is implemented, with basic operations such as adding, deleting and traversing
- RandomAccess is realized, which has the ability of random access
- Cloneable is implemented, which can be cloned (shallow copy) list clone()
- It implements Serializable and can be serialized
ArrayList initialization
After JDK8, execute parameterless construction. The bottom layer first creates an array with initialization capacity of 0. When adding the first element, the initialization capacity is 10!
Supplement: when JDK6 new constructs an ArrayList Object without parameters, it directly creates an Object [] array elementData with a length of 10.
/**
* Default initial capacity size
*/
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
*The default constructor uses the initial capacity of 10 to construct an empty list (parameterless construction)
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* Constructor with initial capacity parameter. (user specified capacity)
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {//Initial capacity greater than 0
//Create an array of initialCapacity sizes
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {//Initial capacity equal to 0
//Create an empty array
this.elementData = EMPTY_ELEMENTDATA;
} else {//If the initial capacity is less than 0, an exception is thrown
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
Careful students will find that when creating an ArrayList with a parameterless construction method, an empty array is actually initialized and assigned. When you really add elements to the array, you really allocate capacity. That is, when the first element is added to the array, the capacity of the array is expanded to 10
ArrayList capacity expansion mechanism
int newCapacity = oldCapacity + (oldCapacity >> 1);
//Therefore, after each capacity expansion of ArrayList, the capacity will become about 1.5 times the original capacity (1.5 times if the oldCapacity is even, otherwise it is about 1.5 times)
/**
* ArrayList The core method of capacity expansion is the growth () method.
*/
private void grow(int minCapacity) {
// oldCapacity is the old capacity and newCapacity is the new capacity
int oldCapacity = elementData.length;
//Move oldCapacity one bit to the right, which is equivalent to oldCapacity /2,
//We know that bit operation is much faster than integer division. The result of the whole sentence expression is to update the new capacity to 1.5 times the old capacity,
int newCapacity = oldCapacity + (oldCapacity >> 1);
//Then check whether the new capacity is greater than the minimum required capacity. If it is still less than the minimum required capacity, take the minimum required capacity as the new capacity of the array,
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//Then check whether the new capacity exceeds the maximum capacity defined by ArrayList,
//If it exceeds, call hugeCapacity() to compare minCapacity with MAX_ARRAY_SIZE,
//If minCapacity is greater than MAX_ARRAY_SIZE, the new capacity is integer MAX_ Value, otherwise, the new capacity size is MAX_ARRAY_SIZE.
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
//Compare minCapacity and MAX_ARRAY_SIZE
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
Summary of capacity expansion: when the capacity of ArrayList is insufficient, expand the capacity to 1.5 times the original capacity according to the rules. If the minimum capacity still does not meet the demand after capacity expansion, the capacity will be updated to the required capacity. At this time, check whether the current capacity exceeds the maximum capacity defined by ArrayList. If it exceeds the maximum capacity defined by ArrayList, it will be updated to Max capacity defined by ArrayList_ ARRAY_ SIZE
3.2,LinkedList
LinkedList is a List implemented as a two-way linked List. In addition to being used as a List, it can also be used as a queue or stack
Bidirectional linked list: contains two pointers, one prev points to the previous node and one next points to the next node.
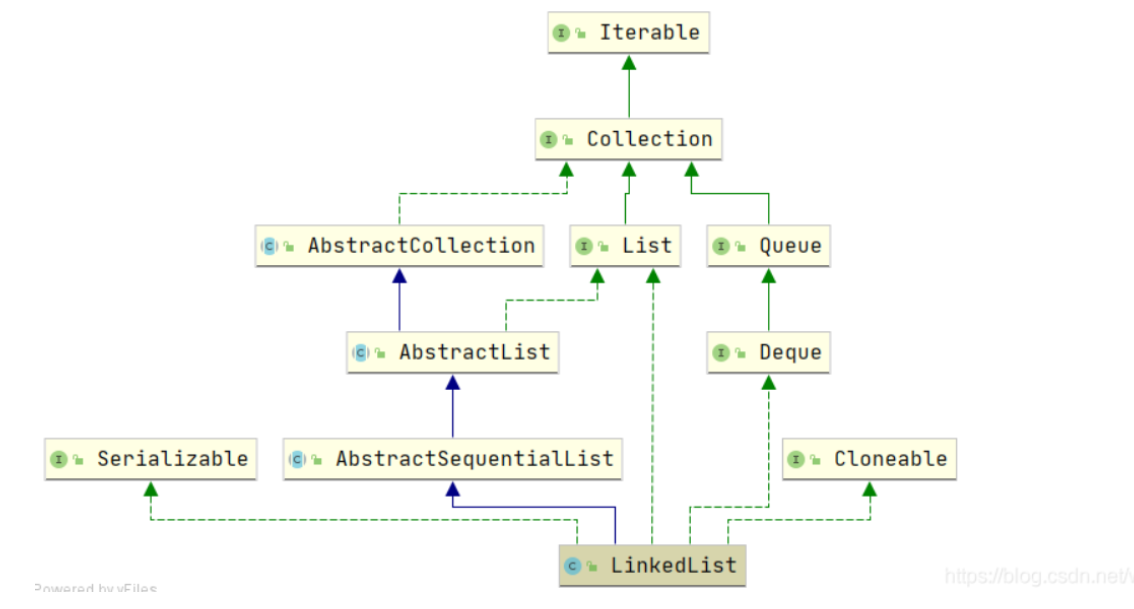
Source code analysis:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
It can be seen that LinkedList implements Cloneable and Serializable interfaces, indicating that it can be cloned or serialized! Similarly, when LinkedList is cloned, it is the same as ArrayList. Both are shallow copies.
1. Basic properties of LinkedList
// Number of elements in the linked list transient int size = 0; // Head node of linked list transient Node<E> first; // Tail node of linked list transient Node<E> last;
The three basic attributes are modified by the keyword transient so that they are not serialized.
2. Node class (node)
//Single node analysis
private static class Node<E> {
E item; //Store elements
Node<E> next; //Address of the next node
Node<E> prev; //Address of the previous node
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
As can be seen from the code, this is a two-way linked list structure.
3. Construction method
public LinkedList() { //Nonparametric structure
}
public LinkedList(Collection<? extends E> c) { // Appends all elements in the specified collection to the end of this list
this();
addAll(c);
}
Difference between bidirectional linked list and bidirectional circular linked list
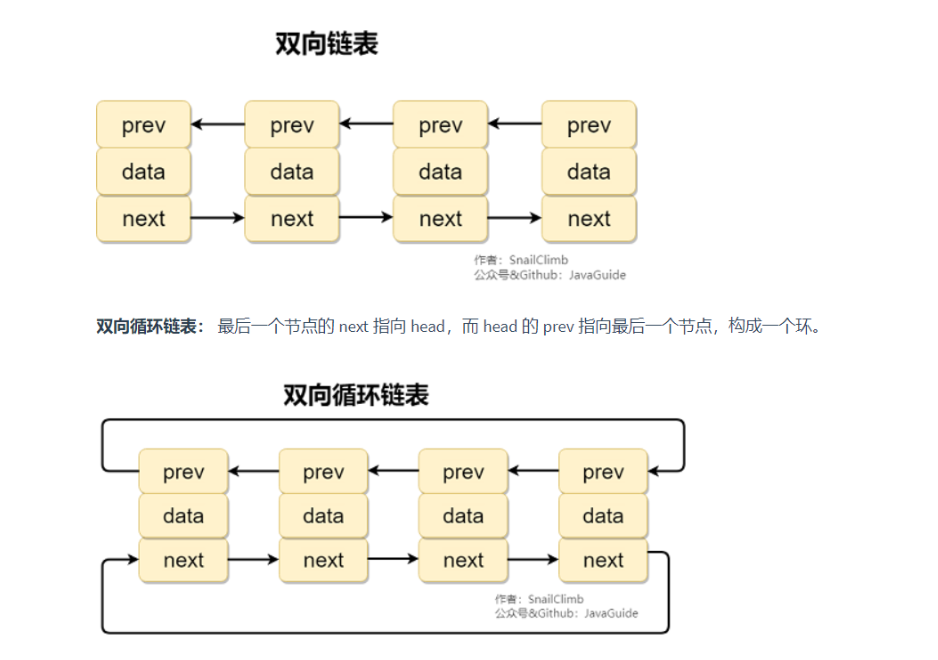
JDK1. Before 6, it was a circular linked list, jdk1 7 cancels the cycle. Pay attention to the difference between bidirectional linked list and bidirectional circular linked list
Add element
The implementation principle of the method of adding elements in the middle of LinkedList is the process of adding elements in the middle of a typical double linked list!
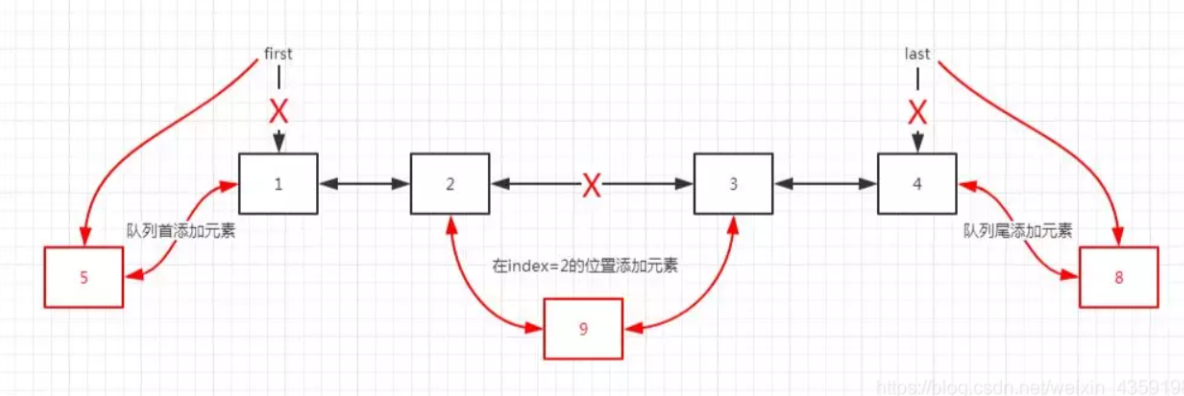
- Adding elements at the beginning and end of the queue is very efficient, and the time complexity is O(1)
- Adding elements in the middle is inefficient. First, find the node at the insertion position, and then modify the pointers of the front and rear nodes. The time complexity is O(n)
add(E e) Add an element addFirst(E e) Add elements to the header addLast(E e) Adding elements to tail nodes removeFirst() Delete header node removeLast() Delete tail node
Delete element
- It is efficient to delete elements at the beginning and end of the queue, and the time complexity is O(1)
- It is inefficient to delete elements by specifying subscripts in the middle. First find the location of the node to be deleted, and then delete it. The time complexity is O(n)
add(int index, E element) Insert the node at the specified location, remove(Object o) Delete node removeFirst() Delete header node removeLast()Delete tail node remove(int index) Delete a node in a location
Summary:
- LinkedList is a List implemented by double linked List;
- LinkedList is also a double ended queue, which has the characteristics of queue, double ended queue and stack;
- LinkedList is very efficient in adding and deleting elements at the beginning and end of the queue, and the time complexity is O(1);
- LinkedList is inefficient to add and delete elements in the middle, and the time complexity is O(n);
- LinkedList does not support random access, so it is inefficient to access non queue elements;
3.3,Vector
- ArrayList is the main implementation class of List. The underlying layer uses Object [] storage, which is suitable for frequent search work, and the thread is unsafe;
- Vector is an ancient implementation class of List. The underlying layer uses Object [] storage, which is thread safe. Almost equal to ArrayList
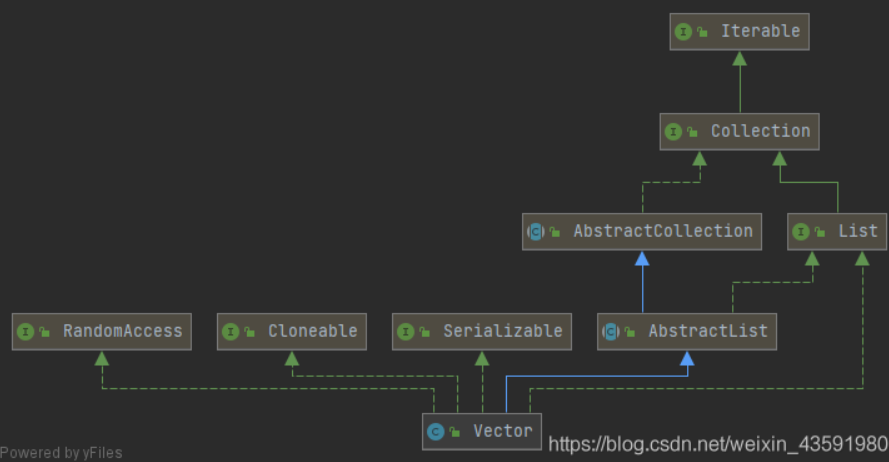
As can be seen from the figure, Vector inherits AbstractList and implements List, RandomAccess, Cloneable and Serializable interfaces. Therefore, Vector supports fast random access, cloning and serialization.
Vector capacity expansion mechanism
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
//Expansion increment: one time of the original capacity. For example, the capacity of Vector is 10, and the capacity after one expansion is 20
// Determines the current capacity size of the array
public synchronized void ensureCapacity(int minCapacity) {
if (minCapacity > 0) {
modCount++;
ensureCapacityHelper(minCapacity);
}
}
// If: current capacity > current array len gt h, call the grow(minCapacity) method to expand the capacity
// Since this method is called in ensureCapacity() and the synchronized lock has been added to the ensureCapacity() method, the
// This method does not need to be locked
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
// Maximum array capacity size
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE
// Core expansion method in Vector set
private void grow(int minCapacity) {
// overflow-conscious code
// Gets the capacity of the old array
int oldCapacity = elementData.length;
// Get the new array capacity after capacity expansion (if necessary)
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
// If the new capacity is less than the actual required capacity of the array, make newCapacity = minCapacity
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// If current required capacity > MAX_ARRAY_SIZE, the new capacity is set to integer MAX_ Value, otherwise set to MAX_ARRAY_SIZE
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
// Maximum capacity
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
4. Set interface
Features: disordered and unrepeatable
Reason: it is mainly because the underlying HashMap adopts the data structure of Hash table (array + linked list + red black tree). Our elements are not necessarily placed there, so they are disordered
4.1,HashSet
The bottom layer is a HashMap and a data structure of a Hash table
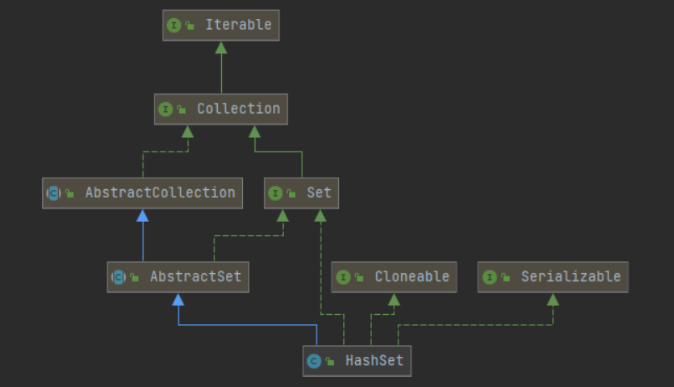
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
Similarly, HashSet is clonable and supports serialization
HashSet source code analysis
Construction method
When a new HashSet is, a HashMap is created at the bottom
public HashSet() {
map = new HashMap<>();
}
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
Insert element
public boolean add(E e) { // Take the element itself as the key and PRESENT as the value, that is, all values in the map are the same.
return map.put(e, PRESENT)==null; // When adding elements to a HashSet, the put() method in the HashMap is called directly,
}
Adding elements to the HashSet is essentially adding elements to the key position of the HashMap in the underlying layer
Delete element
public boolean remove(Object o) {
return map.remove(o)==PRESENT; //To remove an element is essentially to remove the key in the hashmap
}
/**
* Removes all of the elements from this set.
* The set will be empty after this call returns.
*/
public void clear() {
map.clear(); //Empty elements in set
}
HashSet summary:
- HashSet internally uses the key of HashMap to store elements, so as to ensure that elements are not repeated;
- HashSet is unordered because the key of HashMap is unordered;
- A null element is allowed in the HashSet because the HashMap allows the key to be null;
- HashSet is non thread safe;
- HashSet has no get() method;
4.2,TreeSet
The bottom layer is a TreeMap, which is also the data structure of red black tree in essence
5. Map interface:
- clear(): clear the Map collection
- size(): counts the number of key value pairs in the Map collection
- Put (object key, object value): add a key value pair < key, value >
- get(Object key): obtain the corresponding value through a key
- remove(Object key): delete a pair of key value pairs through the key
- values(): returns all values in the Map Collection. The return value type is Collection type
- keyset(): returns all keys in the Map Set. The return value type is Set, because the key itself is a Set set!
- entrySet<Map.Entry < key, value > >: integrate each pair of key value pairs in the map Set into a whole and put them into a Set set. The generic type is map Entry is essentially a static internal class in the map collection
Map traversal
HashMap<Object, Object> map = new HashMap<>();
map.put(1,"Zhang San");
map.put(2,"Zhang San 2");
map.put(3,"Zhang San 3");
Method 1: get all the information first key Indirectly obtain all corresponding value
Set<Object> sets = map.keySet();
for (Object key : sets) {
System.out.println("key="+key+ " " +"value="+map.get(key));
}
Method 2: directly obtain each matching key value pair as a whole, and then get Attribute is OK!
Set<Map.Entry<Object, Object>> entries = map.entrySet();
for (Map.Entry<Object, Object> entry : entries) {
System.out.println("key="+entry.getKey()+ " " +"value="+entry.getValue());
}
5.1,HashMap *
The bottom layer of HashMap is the combination of array and linked list, that is, linked list hash (hash table).
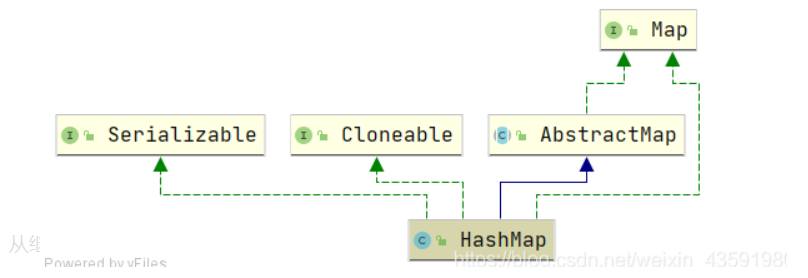
- HashMap implements the clonable interface and can be cloned.
- HashMap implements the Serializable interface, which belongs to the markup interface. HashMap objects can be serialized and deserialized.
- HashMap inherits AbstractMap. The parent class provides the Map implementation interface and has all the functions of Map to minimize the work required to implement this interface.
1, The underlying implementation of HashMap
JDK1. Before 8
HashMap obtains the hash value through the hashCode of the key after being processed by the perturbation function, and then determines the storage location of the current element through the routing addressing method: (n - 1) & hash (where n refers to the length of the array). If there is an element in the current location, it will judge whether the hash value and key of the element to be stored are the same. If they are the same, Direct coverage, otherwise, the conflict can be solved through zipper method.
After JDK 1.8
jdk1. After 8, there are great changes in resolving hash conflicts. When the length of the linked list is greater than the threshold (or the boundary value of the red black tree, which is 8 by default) and the length of the current array is greater than 64, all data at this index position is stored in the red black tree. Similarly, if the number of nodes on the red black tree is less than 6, it will be automatically converted into a single linked list.
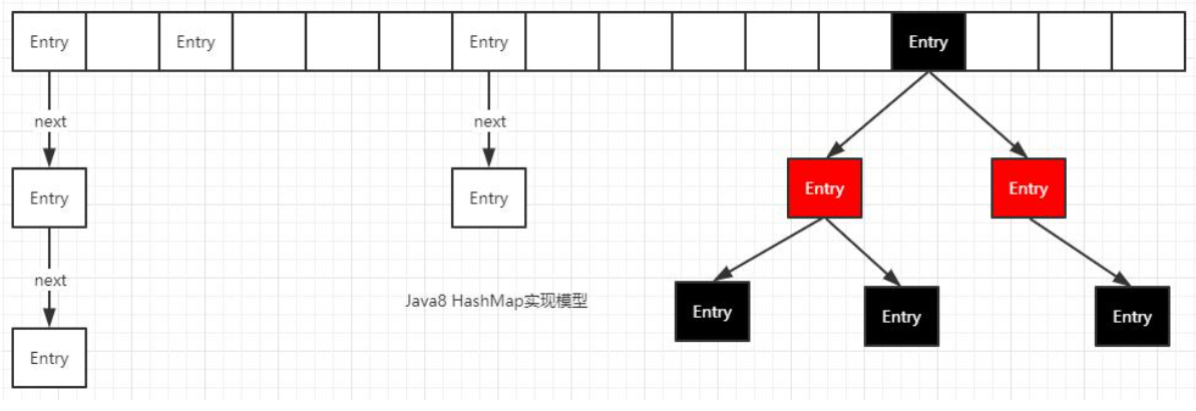
Extension: the so-called perturbation function (hash algorithm) refers to the hash method of HashMap. The hash method, that is, the perturbation function, is used to prevent some poorly implemented hashCode() methods. In other words, the collision can be reduced after using the perturbation function.
//Disturbance function
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
The so-called "zipper method" is to combine linked list and array. In other words, create a linked list array, and each cell in the array is a linked list. If hash conflicts are encountered, the conflicting values can be added to the linked list.
2, Capacity expansion mechanism of HashMap
HashMap = = array + scattered list + red black tree
- The default initial bucket number of HashMap is 16 (array bits). If the length of the linked list in a bucket is greater than 8, judge first:
- If the number of buckets is less than 64, expand the capacity first (2 times), and then recalculate the hash value, so that the length of the linked list in the bucket becomes shorter (the reason why the length of the linked list becomes shorter is related to the positioning method of the bucket, please look down).
- If the bucket number is greater than 64 and the length of the linked list in a bucket is greater than 8, the linked list is trealized (red black tree, i.e. self balanced binary tree)
- If the number of nodes in the red black tree is less than 6, the tree will also become a linked list again.
Conclusion: therefore, the tree condition is obtained: the linked list threshold is greater than 8 and the bucket number is greater than 64 (array length).
Elements are put into the bucket (array) and the way to locate the bucket (array positioning method): locate through the array subscript i. when adding elements, the calculation formula of the target bucket position i, i = hash & (Cap - 1), and cap is the capacity
Why give priority to the expansion of bucket number (array length) rather than direct tree?
- The purpose of this is because when the bucket number (array length) is small, the red black tree structure should be avoided as much as possible. In this case, changing to the red black tree structure will reduce the efficiency. Because red and black trees need to rotate left, right and color to maintain balance. At the same time, when the array length is less than 64, the search time is relatively faster. Therefore, in order to improve performance and reduce search time, the linked list is converted to a red black tree only when the underlying threshold is greater than 8 and the array length is greater than 64
- When the threshold is greater than 8 and the array length is greater than 64, although the red black tree is added as the underlying data structure, the structure becomes complex, but the efficiency becomes higher when the long linked list is converted to the red black tree.
3, HashMap features:
- Storage disorder
- Both key and value positions can be null, but there can only be one null in the key position;
- Capacity: the capacity is the length of the array, that is, the number of buckets. The default is 16 and the maximum is the 30th power of 2. It can be treed only when the capacity reaches 64.
- Load factor: the load factor is used to calculate the capacity expansion when the capacity reaches. The default load factor is 0.75.
- Tree: tree. When the capacity reaches 64 and the length of the linked list reaches 8, it will be tree. When the length of the linked list is less than 6, it will be de tree.
- The key position is unique and controlled by the underlying data structure;
- jdk1. The data structure before 8 is linked list + array, jdk1 8 followed by linked list + array + red black tree;
- When the threshold (boundary value) > 8 and the bucket number (array length) is greater than 64, the linked list is converted into a red black tree. The purpose of changing into a red black tree is to query efficiently;
4, HashMap the process of storing data
That is, the execution process of adding elements to the hash table
//Test code
HashMap<Object, Object> map = new HashMap<>();
map.put("1","Song Qixiang 1") ;
map.put("2","Song Qixiang 2") ;
map.put("3","Song Qixiang 3") ;
map.put("3","Song Qixiang 3(Covered)") ; //cover
}
Perform process analysis:
- First, HashMap < string, integer > HashMap = new hashmap(); When creating a HashMap collection object, the HashMap construction method does not create an array, but creates an array with a length of 16 (i.e., 16 buckets) when the put method is called for the first time, and the Node[] table (Entry[] table before jdk1.8) is used to store key value pair data;
- Encapsulate < K, V > into a Node object. The bottom layer will call the hashCode method of key to obtain the hash value, and then convert the hash value into the subscript of the array through the hash algorithm (hash function). If the subscript position (bucket position) does not have any elements, the Node node will be added to this position. If there is a linked list on the bucket position, at this time, The key will be compared with the key of each Node in the linked list. If false is returned, the Node will be added to the end of the linked list. If one of them returns true, the value of the Node will be overwritten by the current Node;
Note: in the execution process of put, the HashCode method and equals method of the instance must be rewritten;
5, HashMap related interview questions
The specific principle will be analyzed in detail below. Here, we will first understand what will be asked during the interview, and read the source code with questions for easy understanding
1. How is the hash function implemented in HashMap? What are the implementation methods of hash functions?
A: hash the hashcode of the key. If the key is null, directly assign the hash value to 0. Otherwise, move the unsigned right 16 bits, and then perform XOR bit operation, as shown in the code (key = = null)? 0 : (h = key.hashCode()) ^ (h >>> 16)
In addition to the above methods, there are square middle method, pseudo-random number method and remainder method. The efficiency of these three methods is relatively low, and the efficiency of unsigned right shift 16 bit XOR is the highest.
2. What happens when the hashcodes of two objects are equal?
A: hash collision (hash conflict) will occur. If the content of the key value is the same, replace the old value. Otherwise, connect to the back of the linked list. If the length of the linked list exceeds the threshold 8, it will be converted to red black tree storage
3. What is hash collision and how to solve it?
A: as long as the hash code values calculated by the key s of the two elements are the same, hash collision will occur. jdk8 previously used linked lists to resolve hash collisions. jdk8 then uses linked list + red black tree to solve hash collision.
4. If the hashcodes of two keys are the same, how to store key value pairs?
A: compare whether the contents are the same through equals.
- Same: the new value overwrites the previous value.
- Different: traverse the linked list (or tree) of the bucket: if it cannot be found, add a new key value pair to the linked list (or tree)
5. Why must the capacity be the n-th power of 2? What happens if the input value is not a power of 2, such as 10?
A: in order to make HashMap access efficient and minimize collisions, that is, try to distribute data evenly. As we mentioned above, the range of Hash values is - 2147483648 to 2147483647, which adds up to about 4 billion mapping space. As long as the Hash function is mapped evenly and loosely, it is difficult to collide in general applications. But the problem is that an array with a length of 4 billion can't fit into memory. Therefore, this Hash value cannot be used directly. Before using, you have to modulo the length of the array, and the remainder can be used to store the position, that is, the corresponding array subscript. The subscript of this array is evaluated as "(n - 1) & Hash". (n represents the length of the array). This explains why the length of HashMap is to the power of 2.
How should this algorithm be designed?
We may first think of using% remainder operation. However, the point comes: "in the remainder (%) operation, if the divisor is a power of 2, it is equivalent to the and (&) operation minus one from its divisor (that is, the premise of hash% length = = hash & (length-1) is that length is the nth power of 2;)." And using binary bit operation &, the operation efficiency can be improved compared with% which explains why the length of HashMap is the power of 2.
6. What if when creating a HashMap object, the length of the input array is 10 instead of the n-power of 2?
HashMap<String, Integer> hashMap = new HashMap(10);
The HashMap two parameter constructor will use the tableSizeFor(initialCapacity) method to obtain an n-th idempotent of 2 closest to and greater than length (for example, the n-th idempotent of 2 closest to and greater than 10 is 16)
6, Summary:
(1) HashMap is a hash table, which adopts the storage structure of (array + linked list + red black tree);
(2) The default initial capacity of HashMap is 16 (1 < < 4), the default loading factor is 0.75f, and the capacity is always the nth power of 2;
(3) When HashMap is expanded, the capacity of each time becomes twice that of the original;
(4) When the number of buckets is less than 64, it will not be trealized, but will only be expanded;
(5) When the number of buckets is greater than 64 and the number of elements in a single bucket is greater than 8, tree;
(6) When the number of elements in a single bucket is less than 6, reverse tree;
(7) HashMap is a non thread safe container;
(8) The time complexity of finding and adding elements in HashMap is O(1);
5.2,HashTable
Because of thread safety, HashMap (non thread safety) is a little more efficient than Hashtable (thread safety). In addition, Hashtable is basically eliminated. Don't use it in code.
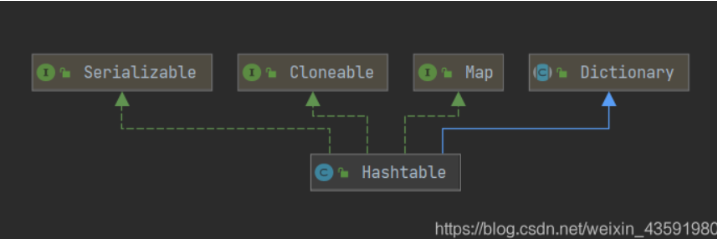
The Dictionary class is an obsolete class (see the comments in its source code). The parent class is abandoned, and naturally its child class Hashtable is less used.
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
Differences between HashTable and HashMap:
- Thread safe: HashMap is non thread safe, and Hashtable is thread safe, because the internal methods of Hashtable are basically modified by synchronized. (if you want to ensure thread safety, use concurrent HashMap!);
- Efficiency: because of thread safety, HashMap is a little more efficient than Hashtable. In addition, Hashtable is basically eliminated and should not be used in code;
- Support for Null key and Null value: HashMap can store Null key and value, but there can only be one null as a key and multiple null as a value; Hashtable is not allowed to have Null key and Null value, otherwise NullPointerException will be thrown.
- The difference between the initial capacity size and each expansion capacity size: ① if the initial capacity value is not specified during creation, the default initial size of Hashtable is 11. After each expansion, the capacity becomes the original 2n+1. The default initialization size of HashMap is 16. After each expansion, the capacity becomes twice the original. ② If the initial capacity value is given during creation, the Hashtable will directly use the size you give, and HashMap will expand it to the power of 2 (the tableSizeFor() method in HashMap ensures that the source code is given below). That is, HashMap always uses the power of 2 as the size of the hash table. Later, we will explain why it is the power of 2.
- Underlying data structure: jdk1 HashMap after 8 has made great changes in resolving hash conflicts. When the length of the linked list is greater than the threshold (8 by default) (it will be judged before converting the linked list to a red black tree. If the length of the current array is less than 64, it will choose to expand the array first instead of converting to a red black tree), convert the linked list to a red black tree to reduce the search time. Hashtable does not have such a mechanism.
Properties
The subclasses of HashTable, key and value, only support strings< String , String >
public
class Properties extends Hashtable<Object,Object> {
setProperty: add element
public synchronized Object setProperty(String key, String value) {
return put(key, value); //The bottom layer calls the put method of the map interface
}
getProperty: delete by key
public String getProperty(String key) {
Object oval = super.get(key);
String sval = (oval instanceof String) ? (String)oval : null;
return ((sval == null) && (defaults != null)) ? defaults.getProperty(key) : sval;
}
5.3,TreeMap
TreeMap uses a red black tree to store elements, which can ensure that elements are traversed according to the size of the key value.
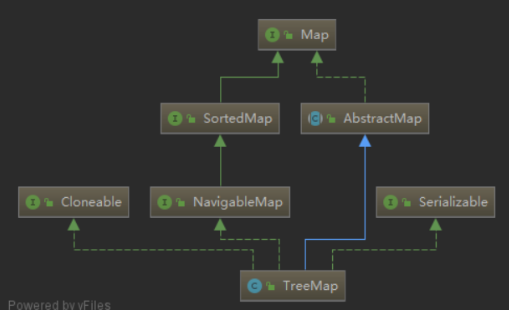
TreeMap implements interfaces such as Map, SortedMap, NavigableMap, Cloneable, Serializable, etc.
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
storage structure
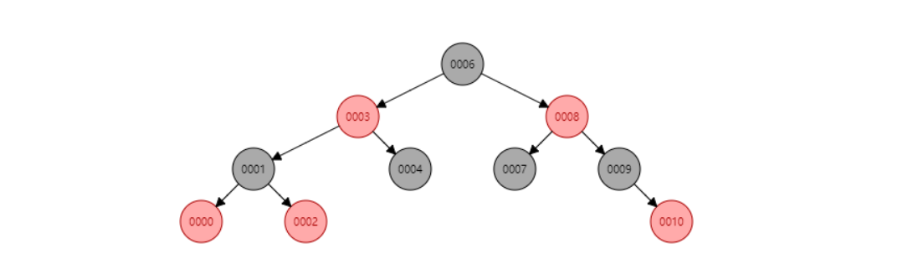
TreeMap only uses red black trees (special AVL (self balancing) binary trees), so its time complexity is O(log n). Let's review the characteristics of red black trees
Source code analysis
Basic properties of TreeMap:
private final Comparator<? super K> comparator;
private transient Entry<K,V> root; //Root node
/**
* The number of entries in the tree
*/
private transient int size = 0; //Number of elements
/**
* The number of structural modifications to the tree.
*/
private transient int modCount = 0; //Modification times
Construction method of TreeMap
/**
* By default, the key must implement the Comparable interface
*/
public TreeMap() {
comparator = null;
}
/**
* Use the passed in comparator to compare the size of two key s
*/
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
/**
* key The Comparable interface must be implemented to save all the elements in the incoming map to the new TreeMap
*/
public TreeMap(Map<? extends K, ? extends V> m) {
comparator = null;
putAll(m);
}
/**
* Use the comparator of the incoming map and save all the elements in the incoming map to a new TreeMap
*/
public TreeMap(SortedMap<K, ? extends V> m) {
comparator = m.comparator();
try {
buildFromSorted(m.size(), m.entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
}
TreeMap comparison method:
Because TreeMap will sort the elements in it, the sorting method needs to be defined by ourselves!
-
Method 1: let the class implement the comparable interface and rewrite the compareTo method to make the class itself comparable!
-
Method 2: when creating a TreeMap, pass in a comparator Comaparator (customize a class and override the compare method), and compare according to the rules of the comparator!
Traversal of TreeMap
When we print out the TreeMap set, we traverse the self balanced binary tree in middle order
Treemap insert element
That is, insert elements into the binary tree
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check // If there is no root node, insert it directly into the root node
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator; //Gets the comparator in the comparator collection
if (cpr != null) { //If the incoming comparator comparator is initialized, override the compare method
do {
parent = t;
cmp = cpr.compare(key, t.key); // The compare method of the comparator will be called to make the inserted node compare with each node
if (cmp < 0) // The size of the node is determined by the difference, so as to determine the position of the inserted node
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else { // If the initialization does not pass in the comparator, the key implements the comparable interface and rewrites the compareTo method
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key; //Convert our key into a comparable object
do {
parent = t;
cmp = k.compareTo(t.key); //Then we call the key compareTo method in each node.
//Similarly, the insertion node position is determined by making a difference
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e; //< 0 is inserted into the left subtree of the node
else
parent.right = e; //>0 is inserted into the right subtree of the node
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
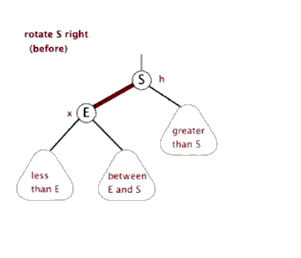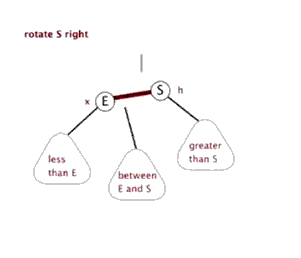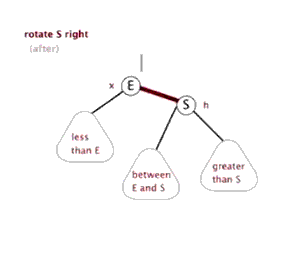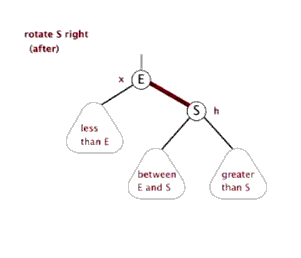
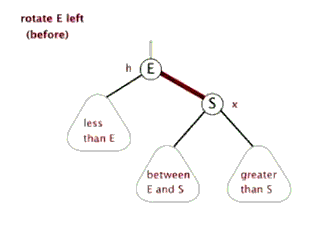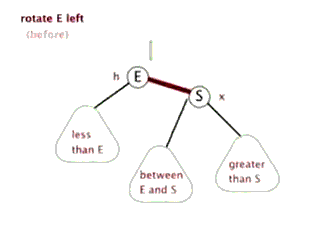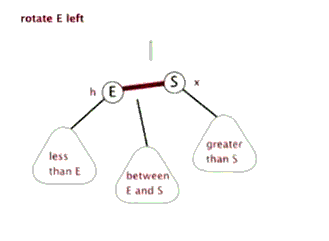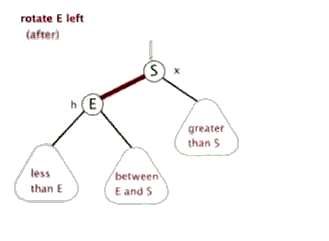
6. Red black tree
Tree - > binary tree - > binary search tree - > AVL tree - > red black tree
See youdaoyun's notes for details;
Sinistral
Dextral