1, Optimize index
1. Not indexed
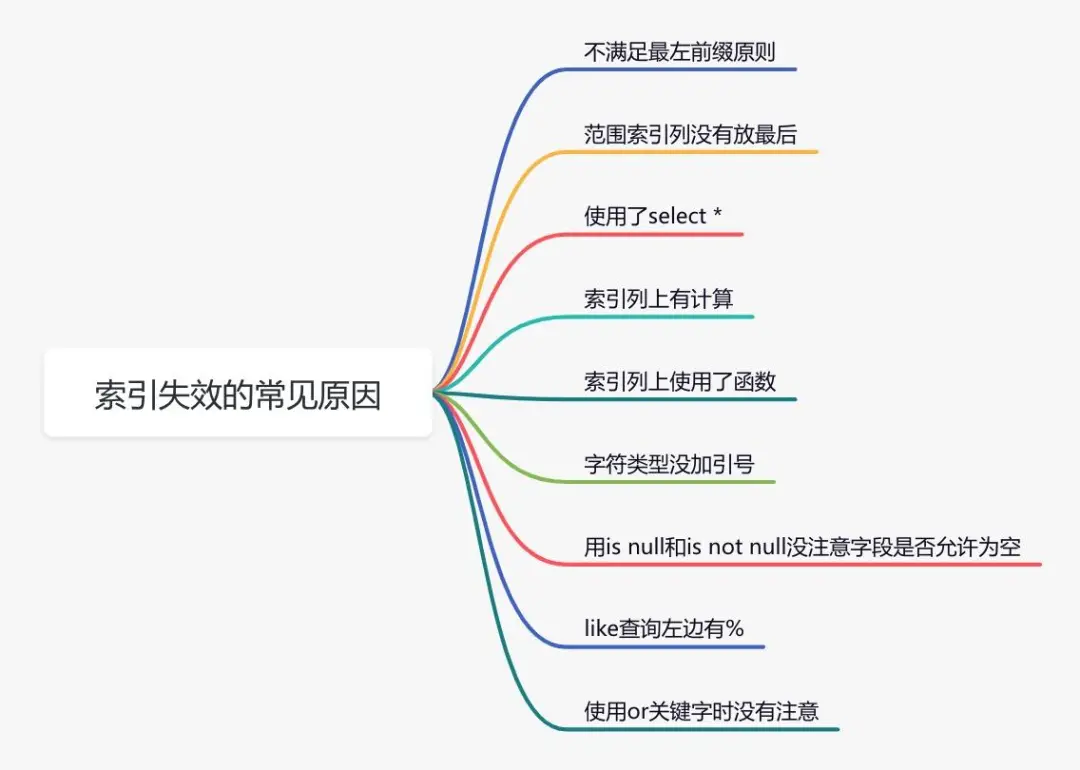
2. The index is not effective
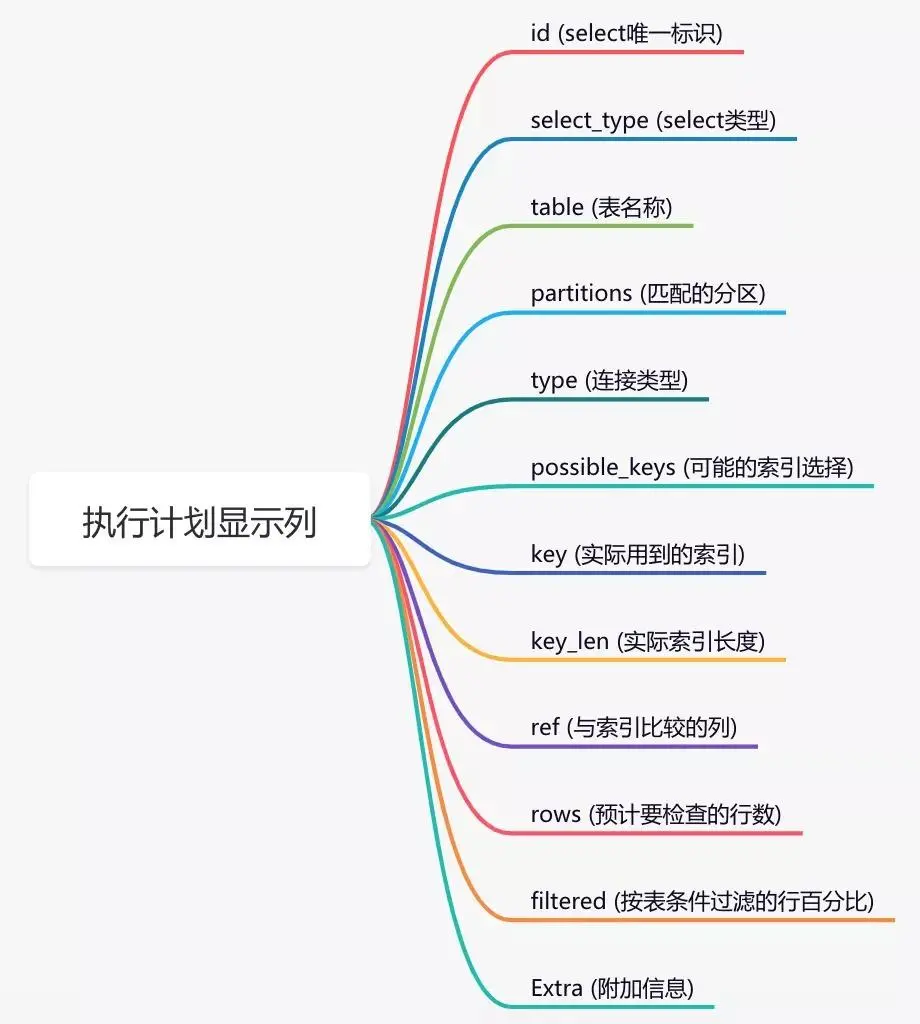
//explain check index usage explain select * from `tb_order` where code='002';
Reason for index failure
3. Wrong index
For the same sql, only the input parameters are different. Sometimes it's index a, but sometimes it's index b? This is because mysql will select the wrong index. If necessary, you can use force index to force the query sql to go to an index.
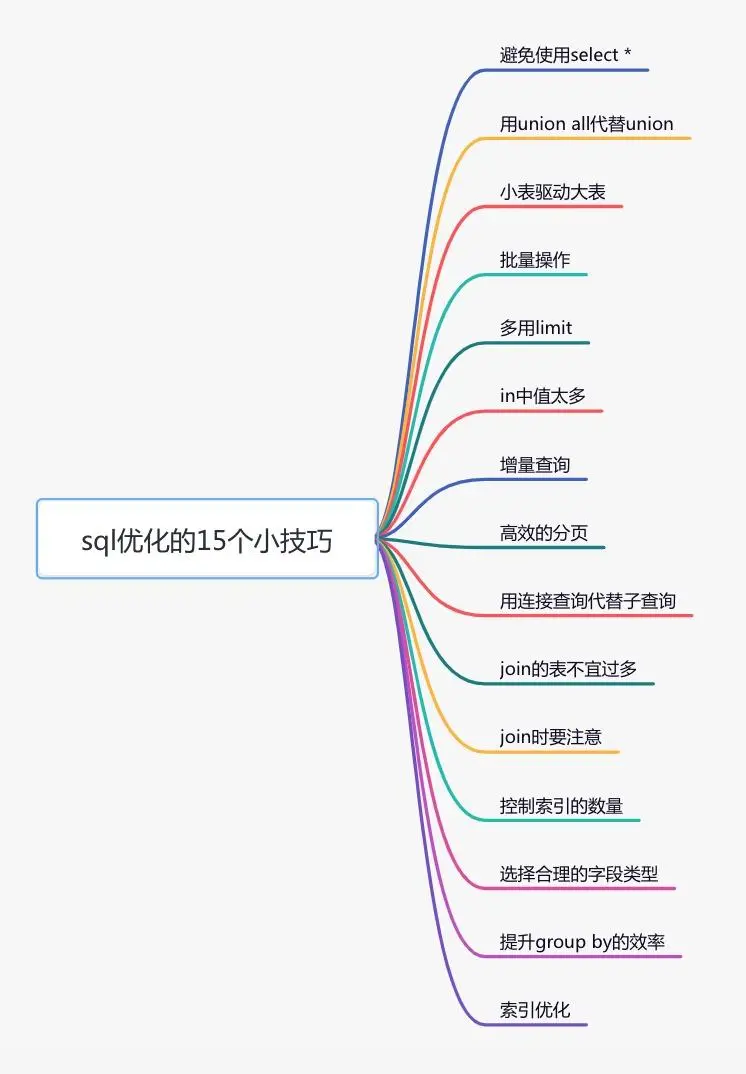
2, Optimize sql statements
3, Remote call
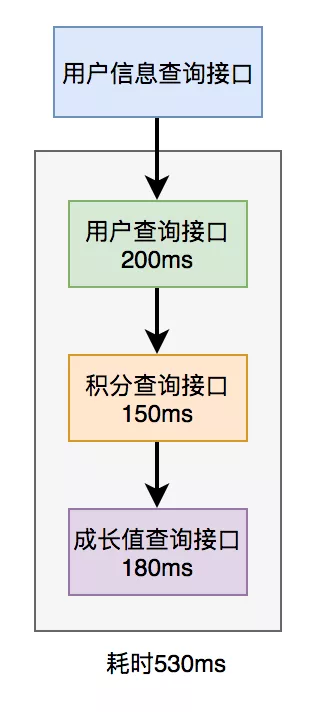
1. Parallel call
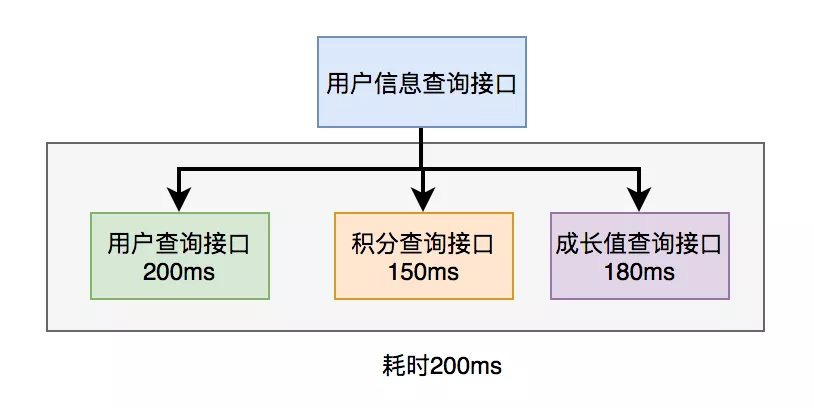
Before Java 8, the Callable interface can be implemented to obtain the results returned by the thread. Java 8 will implement this function through the CompleteFuture class. Take CompleteFuture as an example:
//Define thread pool
@Configuration
public class MyThreadConfig {
@Bean
public ThreadPoolExecutor threadPoolExecutor(ThreadPoolConfigProperties pool) {
return new ThreadPoolExecutor(
pool.getCoreSize(),
pool.getMaxSize(),
pool.getKeepAliveTime(),
TimeUnit.SECONDS,
new LinkedBlockingDeque<>(100000),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);
}
}
@Resource
private ThreadPoolExecutor executor;
public UserInfo getUserInfo(Long id) throws InterruptedException, ExecutionException {
final UserInfo userInfo = new UserInfo();
CompletableFuture userFuture = CompletableFuture.supplyAsync(() -> {
getRemoteUserAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture bonusFuture = CompletableFuture.supplyAsync(() -> {
getRemoteBonusAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture growthFuture = CompletableFuture.supplyAsync(() -> {
getRemoteGrowthAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture.allOf(userFuture, bonusFuture, growthFuture).join();
userFuture.get();
bonusFuture.get();
growthFuture.get();
return userInfo;
}
2. Data cache
Data is uniformly stored in one place, such as redis
4, Asynchronous processing
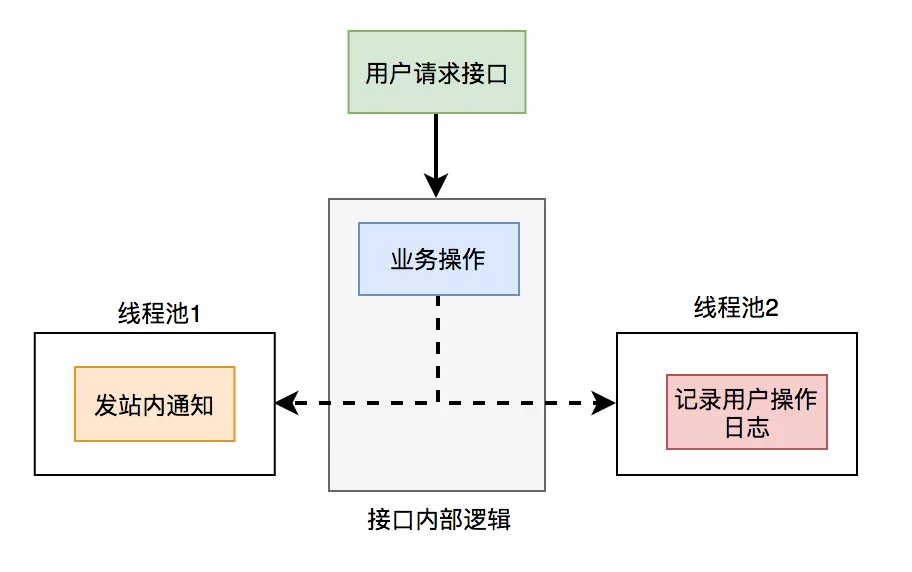
1. Thread pool
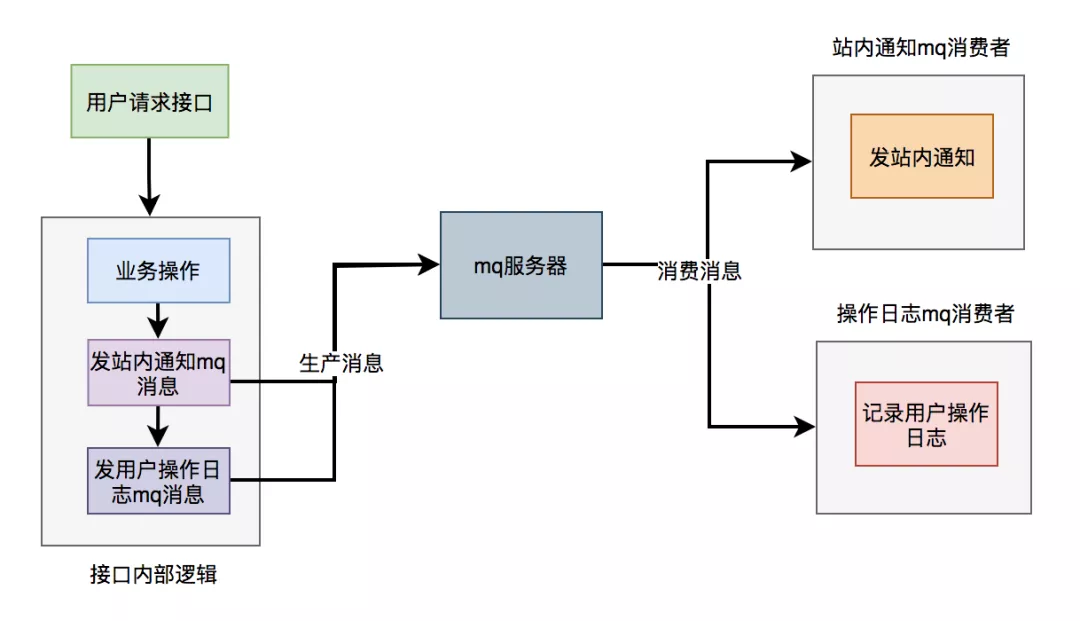
2.mq
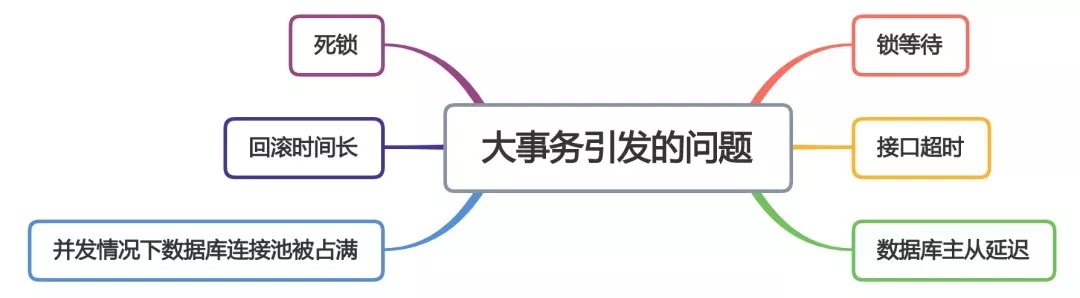
5, Avoid big business
6, Lock granularity
1.synchronized
public synchronized doSave(String fileUrl) {
mkdir();
uploadFile(fileUrl);
sendMessage(fileUrl);
}
This method locks directly, and the granularity of the lock is a little coarse. Because the methods of uploading files and sending messages in doSave method do not need to be locked. Only when you create a directory method, you need to lock it.
public void doSave(String path,String fileUrl) {
synchronized(this) {
if(!exists(path)) {
mkdir(path);
}
}
uploadFile(fileUrl);
sendMessage(fileUrl);
}
2.redis distributed lock
public void doSave(String path,String fileUrl) {
if(this.tryLock()) {
mkdir(path);
}
uploadFile(fileUrl);
sendMessage(fileUrl);
}
private boolean tryLock() {
try {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return true;
}
} finally{
unlock(lockKey,requestId);
}
return false;
}
3 database distributed lock
There are three kinds of locks in mysql database:
- Table lock: fast locking, no deadlock. However, the locking granularity is large, the probability of lock conflict is the highest, and the concurrency is the lowest.
- Row lock: deadlock occurs when locking is slow. However, the locking granularity is the smallest, the probability of lock conflict is the lowest, and the concurrency is the highest.
- Gap lock: the cost and locking time are bounded between table lock and row lock. It will have deadlock. The locking granularity is limited between table lock and row lock, and the concurrency is general.
The higher the concurrency, the better the interface performance. Therefore, the optimization direction of database lock is to use row lock first, gap lock second, and table lock second.
7, Paging processing
The request to obtain all data at one time is changed to multiple times, and only part of the user's data is obtained each time. Finally, it is merged and summarized.
1. Synchronous call
List<List<Long>> allIds = Lists.partition(ids,200);
for(List<Long> batchIds:allIds) {
List<User> users = remoteCallUser(batchIds);
}
2. Asynchronous call
List<List<Long>> allIds = Lists.partition(ids,200);
final List<User> result = Lists.newArrayList();
allIds.stream().forEach((batchIds) -> {
CompletableFuture.supplyAsync(() -> {
result.addAll(remoteCallUser(batchIds));
return Boolean.TRUE;
}, executor);
})
8, Add cache
1.redis cache
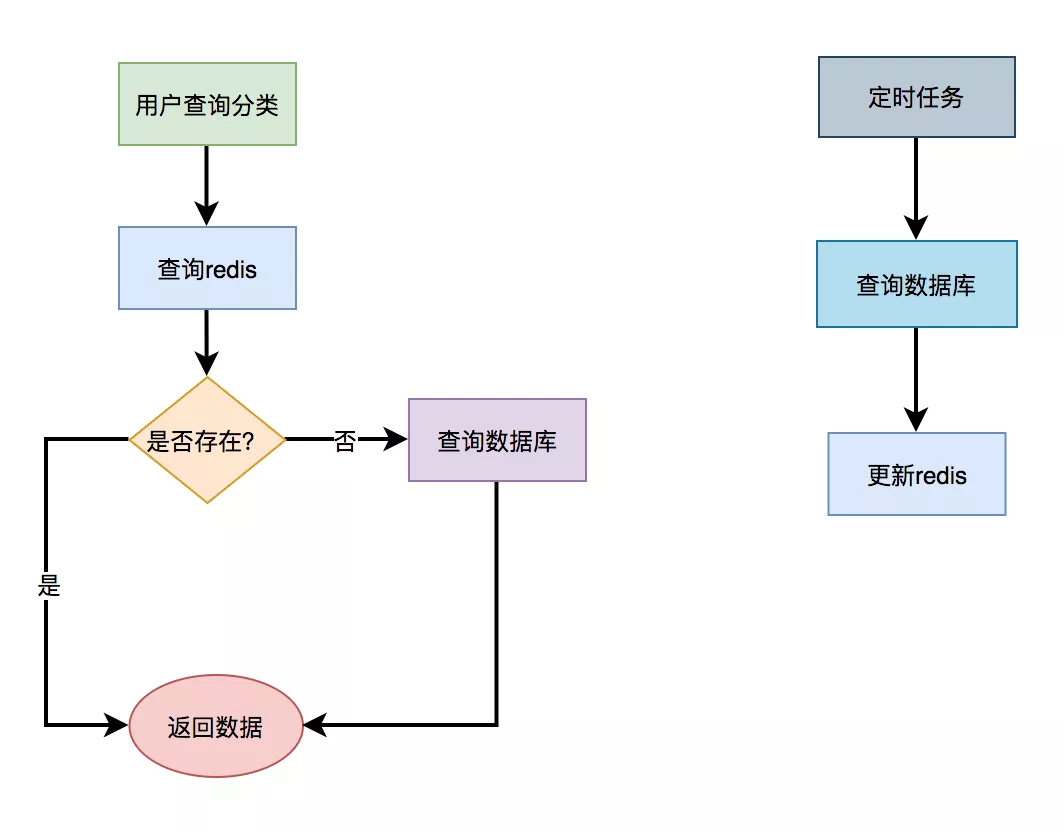
3. L2 cache
Use L2 cache, that is, memory based cache. In addition to their own handwriting memory cache, the currently used memory cache frameworks include guava, Ehcache, caffeine, etc.
Take caffeine as an example, which is officially recommended by spring.
The first step is to add dependencies
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.6.0</version>
</dependency>
Step 2: configure the CacheManager and enable EnableCaching.
@Configuration
@EnableCaching
public class CacheConfig {
@Bean
public CacheManager cacheManager(){
CaffeineCacheManager cacheManager = new CaffeineCacheManager();
//Caffeine configuration
Caffeine<Object, Object> caffeine = Caffeine.newBuilder()
//Expires after a fixed time after the last write
.expireAfterWrite(10, TimeUnit.SECONDS)
//Maximum number of cache entries
.maximumSize(1000);
cacheManager.setCaffeine(caffeine);
return cacheManager;
}
}
Step 3: use the Cacheable annotation to get the data
@Service
public class CategoryService {
@Cacheable(value = "category", key = "#categoryKey")
public CategoryModel getCategory(String categoryKey) {
String json = jedis.get(categoryKey);
if(StringUtils.isNotEmpty(json)) {
CategoryTree categoryTree = JsonUtil.toObject(json);
return categoryTree;
}
return queryCategoryTreeFromDb();
}
}
Call categoryservice When using the getcategory () method, first get the data from the cafe cache. If you can get the data, you will directly return the data without entering the method body. If the data cannot be obtained, check the data from redis again. If it is found, the data is returned and put into the cafe. If no data is found, the data is directly obtained from the database and put into the cafe cache.
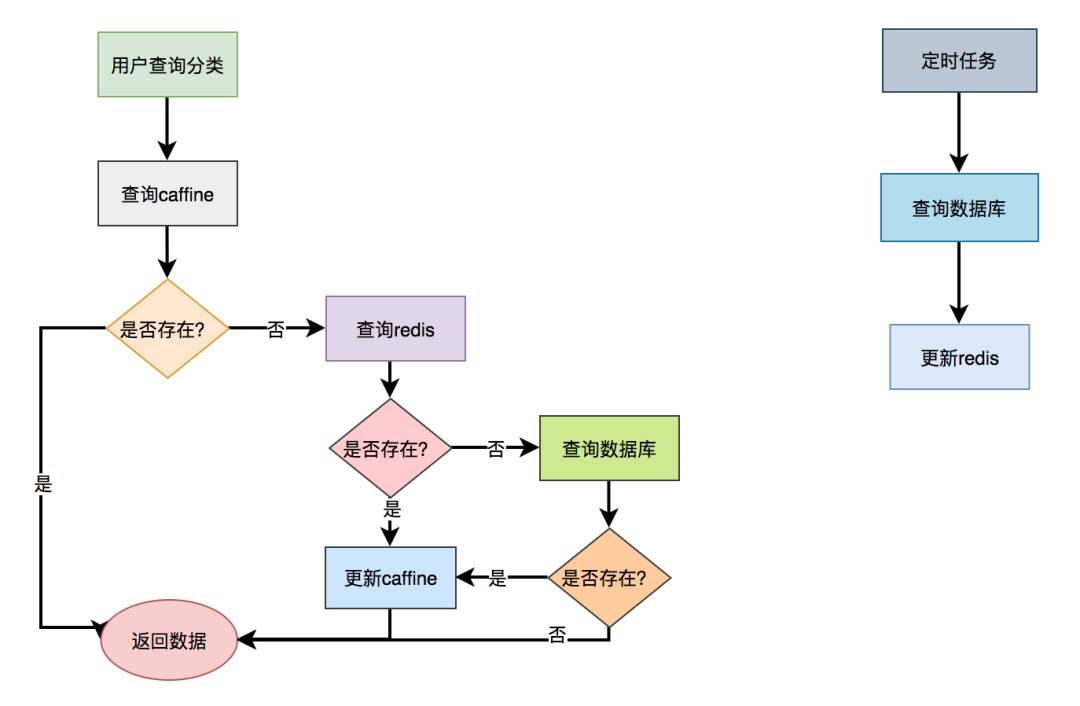
Note: the performance of this scheme is better, but one disadvantage is that if the data is updated, the cache cannot be refreshed in time. In addition, if there are multiple server nodes, there may be different data on each node.