Last example https://blog.csdn.net/xxkalychen/article/details/117149540?spm=1001.2014.3001.5502 Setting Flink's data source to Socket is just to provide streaming data for testing. This is not generally used in production. The standard model is to obtain streaming data from message queues. Flink provides the encapsulation of connecting with Kafka. We only need a little change to obtain data from Kafka.
However, a Kafka server needs to be built before modification. The specific construction process is not detailed here. Now let's modify the program.
1, Add pom dependency.
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>${flink.version}</version>
</dependency>Its version should be consistent with that of flink.
2, Modify the test class. Let's create another test class.
package com.chris.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.util.Arrays;
import java.util.Properties;
/**
* @author Chris Chan
* Create on 2021/5/22 7:23
* Use for:
* Explain: Flink Streaming data from Kafka
*/
public class KafkaStreamTest {
public static void main(String[] args) throws Exception {
new KafkaStreamTest().execute(args);
}
private void execute(String[] args) throws Exception {
//Get execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//Configure kafka
Properties properties = new Properties();
properties.put("bootstrap.servers", "flink.chris.com:9092");
properties.put("group.id", "flink_group_1");
//Get data from socket
DataStreamSource<String> streamSource = env.addSource(new FlinkKafkaConsumer<String>("topic_flink", new SimpleStringSchema(), properties));
//wordcount calculation
SingleOutputStreamOperator<Tuple2<String, Integer>> operator = streamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
/**
* map calculation
* @param value Input data sentences separated by spaces
* @param out map Collector after calculation
* @throws Exception
*/
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
//Separate words with spaces
String[] words = value.split(" ");
//Count the usage frequency of words and put them into the collector
Arrays.stream(words)
//Wash the front and back spaces
.map(String::trim)
//Filter out empty strings
.filter(word -> !"".equals(word))
//Add collector
.forEach(word -> out.collect(new Tuple2<>(word, 1)));
}
})
//word is grouped according to the first field of two tuples, and the second field is counted
.keyBy(0).sum(1);
operator.print();
env.execute();
}
}
The revised part is also four lines.
//Configure kafka
Properties properties = new Properties();
properties.put("bootstrap.servers", "flink.chris.com:9092");
properties.put("group.id", "flink_group_1");
//Get data from socket
DataStreamSource<String> streamSource = env.addSource(new FlinkKafkaConsumer<String>("topic_flink", new SimpleStringSchema(), properties));Configure Kafka's server and consumer group, then create consumers and obtain data from Kafka.
3, Testing.
Before testing, first start zookeeper and kafka, and put kafka in the production and sending state of subject message.
nohup /var/app/kafka_2.13-2.8.0/bin/zookeeper-server-start.sh /var/app/kafka_2.13-2.8.0/config/zookeeper.properties > /var/app/kafka_2.13-2.8.0/logs/zookeeper.log 2>&1 & nohup /var/app/kafka_2.13-2.8.0/bin/kafka-server-start.sh /var/app/kafka_2.13-2.8.0/config/server.properties > /var/app/kafka_2.13-2.8.0/logs/kafka.log 2>&1 &
/var/app/kafka_2.13-2.8.0/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic_flink
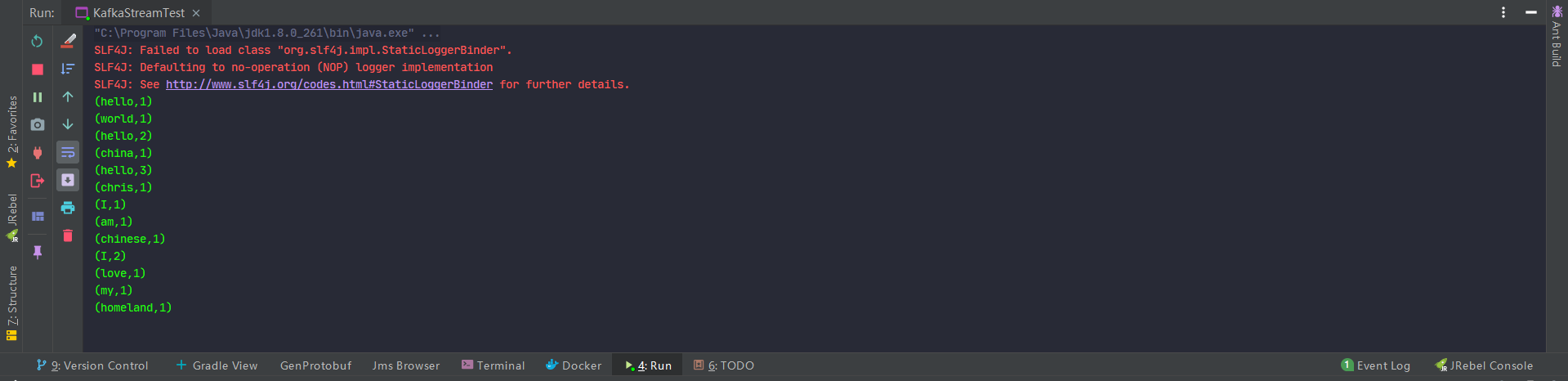
Run the program and input data in kafka.

View background.
Submit to the cluster for execution.
However, it is not successful. The reason is very simple. Flink cluster only contains the basic necessary packages of Flink, which are not included in other packages used in the project, so there will be an exception that the relevant classes cannot be found. Therefore, we also need to configure maven's assembly plug-in in a completely packaged way.
Add in pom
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.chris.flink.KafkaStreamTest</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>This configuration specifies a main class.
Then pack.
mvn clean package assembly:assembly
The packaging process takes a long time, because this method needs to package all the dependent packages. After the package is completed, there is one under the target
flink-demo-20210522-1.0.0-SNAPSHOT-jar-with-dependencies.jar
This is the complete jar package we need.
Transfer this package from the page and find that the main class has been filled in when creating the task, because we have configured a main class in the list. If you want to use another main class, modify it.
After submitting, wait for a while, and you will be in the running state, waiting for data.
We enter data in kafka.

View online standard output.

After the test, I found that there was a small worry that didn't exist. It turns out that when testing storm, the basic package needed locally cannot be online, otherwise it will conflict. Therefore, it is very troublesome to constantly change the scope in pom. I thought that this kind of problem would also occur in flink, but it didn't. It was much easier.