Core parameters
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
/**
* The number of key-value mappings contained in this map.
*/
transient int size;
/**
* The next size value at which to resize (capacity * load factor).
* @serial
*/
// If table == EMPTY_TABLE then this is the initial capacity at which the
// table will be created when inflated.
int threshold;
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;
/**
* The number of times this HashMap has been structurally modified
* Structural modifications are those that change the number of mappings in
* the HashMap or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
*/
transient int modCount;- threhold: if the actual load exceeds this value, the capacity will be expanded.
- loadFactor: expansion factor.
- Real capacity * LoadFactor = threehold
- Entry < K, V > [] this is an array of entries < K, V >, which represents the whole hash table. Each entry < K, V > represents a bucket, which is a linked list. Because of this, even if a hash conflict occurs, it can be placed in the same bucket.
- modCount
We know that HashMap is not thread safe, that is, you may have other threads operating the map at the same time. Use modCount to record the modification times of the modification set.
We will encounter an exception ConcurrentModificationException when deleting the set elements while iterating. The reason is that whether you use the entrySet() method or the keySet() method, you will still use the nextEntry() method in the Iterator iterator built in the set during the for loop. If you do not use the remove() method built in the Iterator, Then the value of the number of record changes inside the Iterator will not be synchronized. When you call the nextentry () method the next time you loop, you will throw an exception.
Construction of a hashmap
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}Let's see what these two constants are
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
The two default values see that the capacity is 16 and the load factor is 0.75, which is the default value of threhold and loadFactor to be assigned later.
Functions called by the pointforward constructor:
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
}The default capacity is 16 and the load factor is 0.75, which is assigned to initialCapacity and loadFactor respectively.
The threshold will be set to 16 * 0.75 at the first put
put () detailed explanation
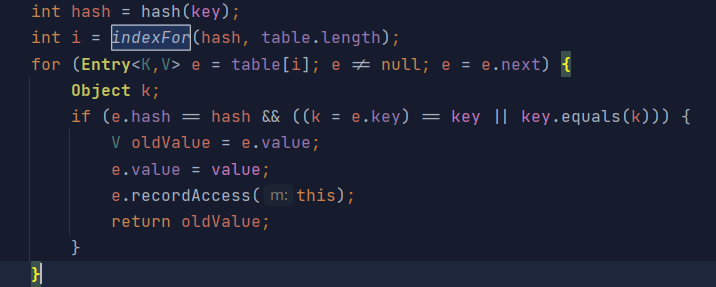
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}If the map is empty, (this table is the above-mentioned entry < K, V > [],) is initialized through the inflateTable(threshold)
/**
* Inflates the table.
*/
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}The original capacity is converted into binary (rounded up) and assigned to capacity as the actual capacity, such as 7 into 8 and 9 into 16. (I have a little doubt, why do you do this) take a look at the roundUpToPowerOf2() function
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}Then, the threshold is changed to the loadFactor times of the new capacity.
The first put initializes the array, and its capacity becomes an idempotent of not less than 2 of the specified capacity. Then the threshold is determined according to the load factor. Obviously, the visible load factor can be changed. If the ability is enough. (I can't do it for the time being anyway)
Continue. If the key value is empty, you will enter another method
/**
* Offloaded version of put for null keys
*/
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}The meaning of this method is to check the first bucket (a linked list) of the entire hash table to see if there is any key value in the linked list that is empty. If so, assign val to it. And return the value represented by null. Otherwise, enter the addEntry method
/**
* Adds a new entry with the specified key, value and hash code to
* the specified bucket. It is the responsibility of this
* method to resize the table if appropriate.
*
* Subclass overrides this to alter the behavior of put method.
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}If there is no load, that is, the threshold is not full and the bucket is empty, enter the createEntry method
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}Insert this node into the current bucket header.
If the load is, expand the capacity, recalculate the hash value, obtain the bucket index according to the new hash value, and insert it again. If the key value is not empty, calculate a new hash according to the key value, and then calculate a new index according to the hash. The method of calculating a new index is as follows:
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}This is why the length of the hash table must be a power of 2. After subtracting one more bit, all the bits except the highest bit are 1, which is compared with the hash to get the result.
We can see that if the capacity is to the power of 2, the binary obtained by length - 1 is 1 except for the complement. According to the rules of the & operator, 0 & 0 = 0; 0&1=0; 1&1=1; This means that no matter what the value of h is, as long as the binary code of length - 1 is such a rule, it can be guaranteed that the value of hash only participates in the operation with the same bit of length - 1
For example, the result of binary codes a (10101011) & b (00001111) is C (00001011). The result of C will only be affected by the last four bits of b binary code, because the complement of b is 0, that is, the index obtained by H & (length - 1) will not be greater than length, so it will not cross the boundary.
If the key value is not empty, the hash is directly calculated to obtain the index for circulation. The for loop traverses all nodes of the linked list represented by the bucket index calculated above. Then judge whether there are nodes in the linked list that have the same hash value as the node to be inserted and have the same equals or = = results. If there is a common node, it will be overwritten and the old value will be returned. Otherwise, insert the node.
Here is a brief introduction to the method of hash: (you can learn from this by manually calculating the hash value)
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}get() details
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}If the key is empty, go to getForNullKey()
private V getForNullKey() {
if (size == 0) {
return null;
}
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}This is consistent with the put method just seen. It is accessed where the bucket index is 0. Needless to say.
Not empty, in
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}First calculate the hash according to the key value, then calculate the index according to the hash, find the bucket, traverse each node of the linked list, and return when a node with the same key or equals as the target hash is encountered.
resize() explanation
This is an expansion method
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
New capacity = old capacity * 2
New load = new capacity * expansion factor
When a new container is established, the of the old container should be transferred. transfer method
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}In the process of element migration, it is possible to trigger an endless loop (infinite list inversion) in a multi-threaded context.
The reason for the ring linked list is probably as follows: thread 1 is ready to process the node, thread 2 successfully expands the HashMap, and the linked list has been sorted in reverse. Then thread 1 may have a ring linked list when processing the node.
The addresses calculated by different threads are different
The reason is that some have been expanded and some have not