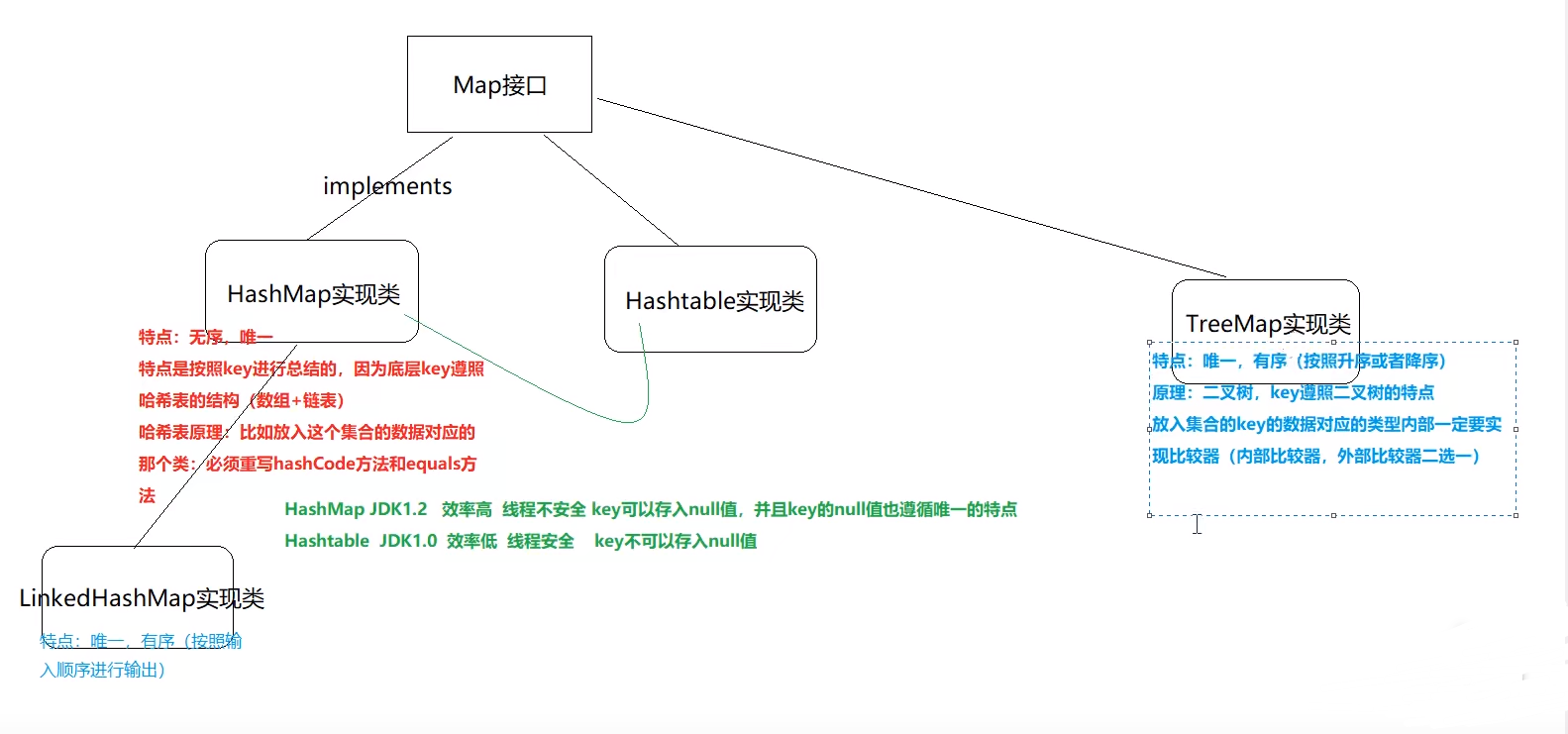
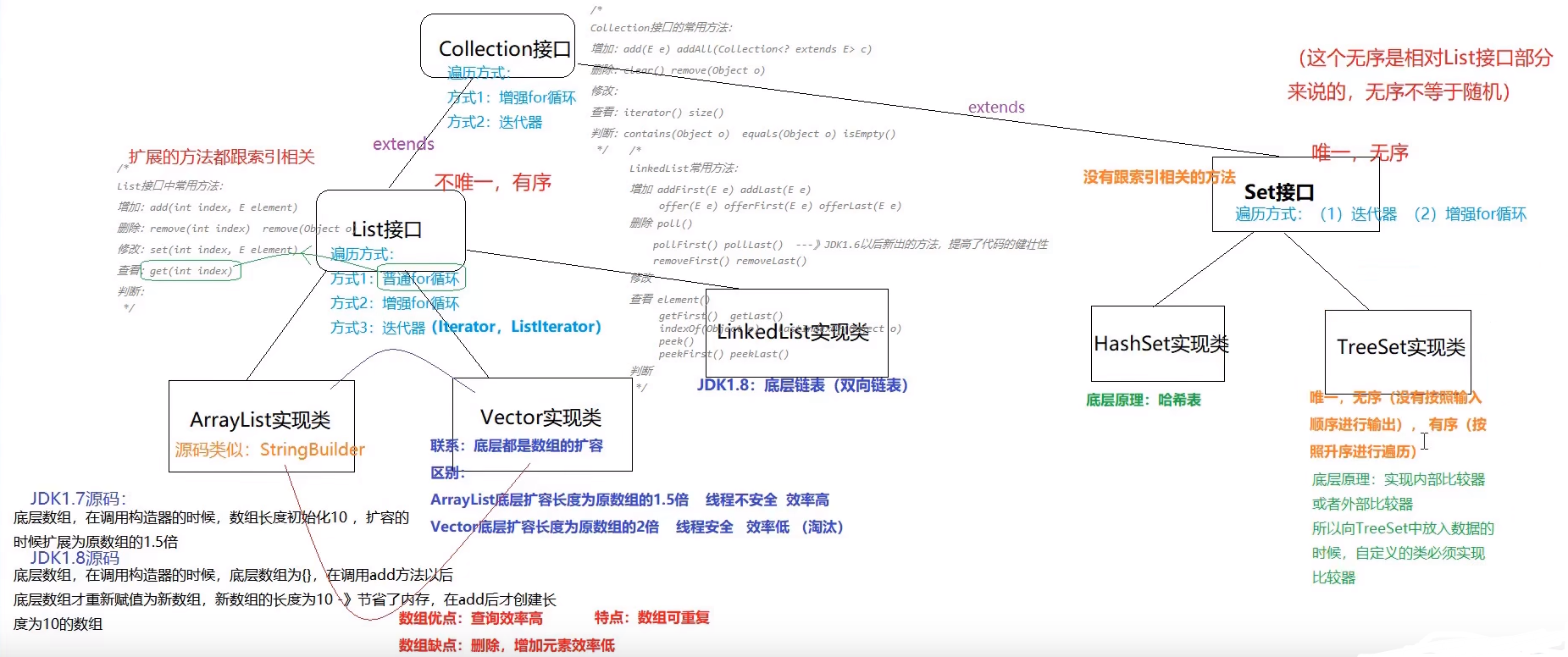
HashMap
Store key value pairs. First calculate the position in the bucket according to the key, and then put the instance in the corresponding bucket (tail insertion). If the number of instances in the bucket exceeds a certain range, the linked list will become a red black tree (but its red black tree structure still maintains the structure of two-way linked list), and if the number of nodes in the red black tree is less than a certain range, it will also degenerate into a linked list. If the number reaches the threshold, the capacity will be doubled. Recalculate the instance position and put it into a new bucket.
Objects used as keys must implement the hashCode method and the equals method.
The bottom layer of JDK8 is array + linked list + red black tree
Source code
https://joonwhee.blog.csdn.net/article/details/106324537
Simple test
public class MapTest {
public static void main(String[] args) {
Map<String,Integer> hm = new HashMap<>();
hm.put("scy",1);
hm.put("kcy",2);
System.out.println( hm.size() );
System.out.println( hm.keySet() );
System.out.println( hm.values() );
System.out.println( hm.get("scy") );
System.out.println( hm );
Set<Map.Entry<String, Integer>> ent = hm.entrySet();
for(Map.Entry<String, Integer> i:ent ) {
System.out.println(i);
}
}
}
Operation results
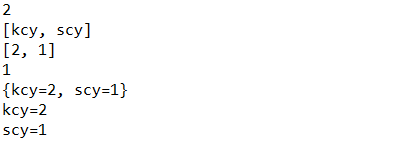
HashMap JDK1.2. High efficiency, unsafe thread, and the Key can be empty
Hashtable JDK1.0 is inefficient. The thread safety Key cannot be stored in null value, and the Key cannot be empty
Hashtable
The bottom layer is array and linked list.
About the difference between HashTable and HashMap in Java:
1. Succession:
HashTable inherits from dictionary and HashMap inherits from AbstractMap, both of which implement Map interface;
2. Thread safety:
The HashTable method is synchronous, that is, thread safe. The method of HaspMap is not synchronous and thread safe. In the case of multithreading concurrency, we can directly use HashTable. If we want to use HashMap, we need to synchronize HashMap by ourselves.
3. Key value:
Null keys and null values are not allowed in HashTable. A null key is allowed in HashMap. The values of one or more keys can be null. In the program, for HashMap, if the return result is null when using the get (parameter is key) method, it may be that the key does not exist or the value corresponding to the key is null, which leads to the ambiguity of the result. Therefore, in HashMap, we cannot use the get() method to query the value corresponding to the key, but should use the containskey() method.
4. Traversal:
The two are implemented differently in traversal mode. Both HashTable and HashMap implement Iterator. However, HashTable also uses Enumeration for historical reasons.
5. Hash value:
HashTable is the hashCode that directly uses the object. HashMap is to recalculate the hash value.
6. Capacity expansion:
The array, initial size and expansion mode of the underlying implementation of HashTable and HashMap. The initial size of HashTable is 11, and each expansion is: 2old+1. The default size of HashMap is 16, and it must be an index of 2. Each expansion is old2.
method
void clear() Clear this hash table so that it does not contain keys. Object clone() Create a shallow copy of this hash table. boolean contains(Object value) Tests that some keys map to the specified values in this hash table. boolean containsKey(Object key) Tests whether the specified object is a key in this hash table. boolean containsValue(Object value) Returns if this hash table maps one or more keys to this value true. Enumeration<V> elements() Returns an enumeration of values in this hash table. Set<Map.Entry<K,V>> entrySet() Returns the of the mappings contained in this map Set View. V get(Object key) Returns the value mapped to the specified key, or null If this mapping contains a mapping for that key. V getOrDefault(Object key, V defaultValue) Returns the value mapped to the specified key, or defaultValue If this mapping contains a mapping for that key. int hashCode() according to Map The definition in the interface returns this Map Hash code value of. Enumeration<K> keys() Returns an enumeration of keys in this hash table. V put(K key, V value) Will specify key Map to key value Specified in value. V remove(Object key) Remove the key (and its corresponding value) from this hash table. boolean remove(Object key, Object value) Delete the entry only if the specified key is currently mapped to the specified value. V replace(K key, V value) The entry for the specified key can be replaced only when the target is mapped to a value. boolean replace(K key, V oldValue, V newValue) The entry for the specified key can be replaced only if it is currently mapped to the specified value. void replaceAll(BiFunction<? super K,? super V,? extends V> function) Replace the value of each entry with the result of calling the given function on that entry until all entries are processed or the function throws an exception. int size() Returns the number of keys in this hash table. String toString() Returns this as a set of entries Hashtable The string representation of the object, enclosed in braces and ASCII Character“ , "(Comma and space). Collection<V> values() Returns the of the values contained in this map Collection View.
Partial source code
https://blog.csdn.net/dingjianmin/article/details/79774192
Simple test
package collectionstest;
import java.util.Hashtable;
public class HashTableTest {
public static void main(String[] args) {
Hashtable<String,Integer> map = new Hashtable<>();
map.put("A", 1);
map.put("B", 2);
map.put("C", 3);
System.out.println(map.get("A"));
System.out.println(map.containsKey("K"));
System.out.println(map.containsValue(1));
System.out.println(map);
}
}
LinkedHashMap
brief introduction
LinkedHashMap inherits from HashMap, and its various operations are based on HashMap operations. Unlike HashMap, LinkedHashMap maintains a two-way Linked list of entries to ensure the order of inserted entries. This is also the meaning of Linked.
method
void clear() Optionally, delete all mappings from the map. protected Object clone() Return to this AbstractMap Shallow copy of instance: keys and values themselves are not cloned. boolean containsKey(Object key) Returns if this mapping contains a mapping for the specified key true . boolean containsValue(Object value) Returns if the mapping maps one or more keys to the specified value true. boolean equals(Object o) Compares the specified object to this mapping for equality. V get(Object key) Returns the value mapped to the specified key, or null If this mapping contains a mapping for that key. int hashCode() Returns the hash code value of this map. boolean isEmpty() Returns if the map does not contain a key value mapping true . Set<K> keySet() Returns the of the keys contained in this map Set View. V put(K key, V value) Optionally, associate the specified value with the specified key in the map. void putAll(Map<? extends K,? extends V> m) Optionally, copy all mappings of the specified map to this map. V remove(Object key) If it exists (from an optional operation), delete a key mapping from the map. int size() Returns the number of key value mappings in this map. String toString() Returns a string representation of this map. Collection<V> values() Returns the of the values contained in this map Collection View.
test
public class LinkedHashMapTest {
public static void main(String[] args) {
// The third parameter specifies the accessOrder value
Map<String, String> linkedHashMap = new LinkedHashMap<>(16, 0.75f, true);
linkedHashMap.put("name1", "josan1");
linkedHashMap.put("name2", "josan2");
linkedHashMap.put("name3", "josan3");
System.out.println("Start sequence:");
Set<Entry<String, String>> set = linkedHashMap.entrySet();
Iterator<Entry<String, String>> iterator = set.iterator();
while(iterator.hasNext()) {
Entry entry = iterator.next();
String key = (String) entry.getKey();
String value = (String) entry.getValue();
System.out.println("key:" + key + ",value:" + value);
}
System.out.println("adopt get Method, resulting in key by name1 Corresponding Entry To the end of the table");
linkedHashMap.get("name1");
Set<Entry<String, String>> set2 = linkedHashMap.entrySet();
Iterator<Entry<String, String>> iterator2 = set2.iterator();
while(iterator2.hasNext()) {
Entry entry = iterator2.next();
String key = (String) entry.getKey();
String value = (String) entry.getValue();
System.out.println("key:" + key + ",value:" + value);
}
}
}

TreeMap
The implementation of TreeMap is the implementation of red black tree algorithm
HashSet
HashSet is actually a HashMap instance, which is an array storing linked lists. It does not guarantee the iterative order of storage elements; This class allows null elements. Duplicate elements are not allowed in HashSet because HashSet is implemented based on HashMap. The elements in HashSet are stored on the key of HashMap, and the values in value are a unified fixed object. private static final Object PRESENT = new Object();

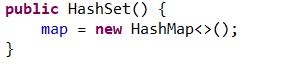


The add method in HashSet calls the put() method in the underlying HashMap, and if it calls put in HashMap, it first determines whether key exists. If key exists, it modifies the value value. If key does not exist, insert this key-value. In the set, because the value value is useless, there is no argument to modify the value value. Therefore, to add an element to the HashSet, first judge whether the element (i.e. key) exists. If there is no insertion, if there is no insertion, there will be no duplicate values in the HashSet.
Therefore, to judge whether the key exists, we need to rewrite the equals () and hashCode() methods of the class of the element. When adding an object to the Set, first call the hashCode() method of the class where the object is located to calculate the hash value of the secondary object, which determines the storage position of the object in the Set; If there is no stored object in this location, it will be stored directly. If there is an existing object, compare whether the two objects are the same through the equals() of the class where the object is located. If they are the same, they cannot be added.
method
boolean add(E e) Adds the specified element to this collection if it does not already exist. void clear() Remove all elements from this collection. Object clone() Return to this HashSet Shallow copy of the instance: the element itself is not cloned. boolean contains(Object o) Returns if the collection contains the specified element true . boolean isEmpty() If this collection does not contain elements, returns true . Iterator<E> iterator() Returns the iterator of the elements in this collection. boolean remove(Object o) If present, deletes the specified element from the collection. int size() Returns the number of elements in this collection (its cardinality). Spliterator<E> spliterator() Create on elements in this collection late-binding And fault fast Spliterator .
Simple test
public class HashSetTest {
public static void main(String[] args) {
HashSet hs = new HashSet<>();
hs.add("Sun Chuangyu");
hs.add(2);
hs.add(3.0);
for(Object i:hs) {
System.out.println(i);
}
}
}
Operation results

When the custom class is placed in the HashSet, the equals and hashcode methods should be overridden.
LinkedHashSet
LinkedHashMap Inheriting from HashMap, its various operations are based on HashMap operations. Unlike HashMap, LinkedHashMap maintains a two-way Linked list of entries to ensure the order of inserted entries. This is also the meaning of Linked.
method
Spliterator<E> spliterator() Create on elements in this collection late-binding And fault fast Spliterator from HashSet Inherited from add, clear, clone, contains, isEmpty, iterator, remove, size from AbstractSet In succession equals, hashCode, removeAll from AbstractCollection Inherited from Methods addAll, containsAll, retainAll, toArray, toArray, toString from Object Inherited from finalize, getClass, notify, notifyAll, wait, wait, wait from Set Inherited from add, addAll, clear, contains, containsAll, equals, hashCode, isEmpty, iterator, remove, removeAll, retainAll, size, toArray, toArray from Collection Inherited from parallelStream, removeIf, stream from Iterable Inherited from forEach
Simple test
package collectionstest;
import java.util.HashSet;
import java.util.LinkedHashSet;
public class HashSetTest {
public static void main(String[] args) {
LinkedHashSet<Integer> hs = new LinkedHashSet<>();
hs.add(1);
hs.add(2);
hs.add(5);
hs.add(2);
hs.add(3);
System.out.println(hs);
}
}
Operation results

TreeSet
Unique, ascending, custom classes need to write comparators.
common method
boolean add(E e) Adds the specified element to this collection if it does not already exist. boolean addAll(Collection<? extends E> c) Adds all elements in the specified collection to this collection. E ceiling(E e) Returns the smallest element in this collection that is greater than or equal to the given element, or if there is no such element null . void clear() Remove all elements from this collection. Object clone() Return to this TreeSet A shallow copy of the instance. Comparator<? super E> comparator() Returns the comparator used to sort the elements in the collection, or null,If this collection uses the of its elements natural ordering . boolean contains(Object o) Returns if the collection contains the specified element true . Iterator<E> descendingIterator() Returns iterators for the elements in the collection in descending order. NavigableSet<E> descendingSet() Returns a reverse ordered view of the elements contained in this collection. E first() Returns the current first (lowest) element in this collection. E floor(E e) Returns the largest element in this collection that is less than or equal to the given element. If there is no such element, it returns null . SortedSet<E> headSet(E toElement) Returns a view of a portion of this collection whose elements are strictly less than toElement . NavigableSet<E> headSet(E toElement, boolean inclusive) Returns a view of a portion of the collection whose elements are less than (or equal to), if inclusive (true) toElement . E higher(E e) Returns the smallest element in the collection that is strictly greater than the given element, or if there is no such element null . boolean isEmpty() If this collection does not contain elements, returns true . Iterator<E> iterator() Returns the iterator of the elements in the collection in ascending order. E last() Returns the current last (highest) element in this collection. E lower(E e) Returns the largest element in this collection, which is strictly smaller than the given element. If there is no such element, it returns null . E pollFirst() Retrieve and delete the first (lowest) element, or return null If the collection is empty. E pollLast() Retrieves and deletes the last (highest) element, and returns if the collection is empty null . boolean remove(Object o) If present, deletes the specified element from the collection. int size() Returns the number of elements in this collection (its cardinality). Spliterator<E> spliterator() Create on elements in this collection late-binding And failover Spliterator . NavigableSet<E> subSet(E fromElement, boolean fromInclusive, E toElement, boolean toInclusive) Returns a view of a portion of the collection whose elements range from fromElement reach toElement . SortedSet<E> subSet(E fromElement, E toElement) Returns a view of a portion of this collection whose elements range from fromElement (Including) to toElement ,Exclusive. SortedSet<E> tailSet(E fromElement) The element that returns this component is greater than or equal to fromElement View of the part of the. NavigableSet<E> tailSet(E fromElement, boolean inclusive) Returns a view of a portion of this collection whose elements are greater than (or equal to), if inclusive (true) fromElement . Methods inherited from class java.util.AbstractSet equals, hashCode, removeAll Methods inherited from class java.util.AbstractCollection containsAll, retainAll, toArray, toArray, toString Methods inherited from class java.lang.Object finalize, getClass, notify, notifyAll, wait, wait, wait Methods inherited from interface java.util.Set containsAll, equals, hashCode, removeAll, retainAll, toArray, toArray Methods inherited from interface java.util.Collection parallelStream, removeIf, stream Methods inherited from interface java.lang.Iterable forEach
Simple test
myStudent.java
package collectionstest;
public class myStudent implements Comparable<myStudent>{
Integer age;
String name;
public int compareTo(myStudent o) {
return this.age-o.age;
}
myStudent(int a,String b){
age = a;
name = b;
}
public String toString() {
return "age="+age+" name="+name;
}
}
The external Comparator shall implement the Comparator interface.
mycompara .java
package collectionstest;
import java.util.Comparator;
import java.util.TreeSet;
class mycompara1 implements Comparator<myStudent>{
public int compare(myStudent a,myStudent b) {
return a.name.compareTo(b.name);
}
}
public class TreeSetTest {
public static void main(String[] args) {
//Internal comparator
TreeSet<myStudent> ts = new TreeSet<>();
ts.add(new myStudent(1,"dda"));
ts.add(new myStudent(2,"as"));
ts.add(new myStudent(4,"fads"));
ts.add(new myStudent(3,"xc"));
ts.add(new myStudent(8,"gad"));
System.out.println(ts);
//External comparator
Comparator<myStudent> mcp = new mycompara1();
TreeSet<myStudent> ts0 = new TreeSet<>(mcp);
ts0.add(new myStudent(1,"dda"));
ts0.add(new myStudent(2,"as"));
ts0.add(new myStudent(4,"fads"));
ts0.add(new myStudent(3,"xc"));
ts0.add(new myStudent(8,"gad"));
System.out.println(ts0);
//Anonymous Inner Class
TreeSet<myStudent> ts1 = new TreeSet<>(new Comparator<myStudent>() {
public int compare(myStudent a,myStudent b) {
return b.age - a.age;
}
});
ts1.add(new myStudent(1,"dda"));
ts1.add(new myStudent(2,"as"));
ts1.add(new myStudent(4,"fads"));
ts1.add(new myStudent(3,"xc"));
ts1.add(new myStudent(8,"gad"));
System.out.println(ts1);
}
}
Operation results

It can be seen that if the external comparator is not set, it will be sorted according to the rules of the internal comparator (age).
If the external comparator is set, the (name) will be displayed in the way of the external comparator.
principle
The big one on the right and the small one on the left.
As long as the middle order traversal can get data from small to large.
