The algorithm implementation of hashjoin itself is not complex. To say that it is very complex, it may be that when the optimizer selects the execution plan, whether to select hashjoin and appearance, and the internal table may be more complex. Anyway, with hashjoin now, the optimizer has another choice when choosing the join algorithm. MySQL is based on pragmatism. I believe this enhancement also answers some questions. Some functions are not incompetent, but have priority.
At 8.0 Before 18, MySQL only supported nestlopjoin algorithm. The simplest is a simple nestloop connection. MySQL optimizes the algorithm, including block nested loop connection, index nested loop connection and batch key access. Through these optimizations, the urgency of hashjoin can be alleviated to a certain extent. Next, we will discuss these connection optimizations for MySQL in a separate chapter. Next, we will discuss hashjoin.
Hash Join algorithm
Nestloopjoin algorithm is simply a double loop, which traverses the surface (drive table), for each row of records on the surface, then traverses the inner table, and then determines whether the join conditions are met, and then determines whether to spit out the records to the last execution node. In terms of algorithm, this is a complexity of M * n. Hash join is an optimization for equal join scenarios. The basic idea is to load the external data into memory and establish a hash table. In this way, you can complete the join operation and output the matching records only by traversing the internal table once. If all the data can be loaded into memory, of course, the logic is simple. Generally speaking, this kind of join is called CHJ (classic hash join). MariaDB has implemented this kind of hash join algorithm before. If all the data cannot be loaded into memory, it needs to be loaded into memory in batches, and then joined in batches. The following describes the implementation of these join algorithms.
In-Memory Join(CHJ)
HashJoin generally includes two processes, the build process of creating hash table and the probe process of detecting hash table.
1).build phase
Traverse the surface, take the join condition as the key, query the required columns as the value, and create a hash table. This involves a basis for selecting the appearance, which is mainly to judge by evaluating the size of the two tables (result set) participating in the join. Whoever is young will be selected. In this way, it is easier to put down the hash table with limited memory.
2).probe phase
After the hash table is built, traverse the inner table row by row. For each record in the inner table, calculate the hash value for the join condition and find it in the hash table. If it matches, output it, otherwise skip. When all internal table records are traversed, the whole process is over. Refer to the following figure for the process, from MySQL official blog
On the left is the build process, on the right is the probe process, country_id is equal_ For join conditions, the countries table is the outer table, and the persons table is the inner table.
On-Disk Hash Join
The limitation of CHJ is that it requires memory to accommodate the entire surface. In mysql, the memory that can be used by a join is controlled by the join buffer size parameter. If the memory required for a connection exceeds the size of the connection buffer, CHJ can't help dividing the surface into several segments, building each segment one by one, then traversing the internal table and probing each segment again. Suppose the surface is divided into n blocks, and then scan the inner table n times. Of course, this approach is weak. In MySQL 8.0, if the memory required by a join exceeds the size of the join buffer, the construction phase will first use hash calculation to divide the outer surface and generate a temporary disk partition; Then, in the detection phase, the same hash algorithm is used to divide the inner table. Because of the same hash function, Same key (the same connection condition) must be in the same partition number. Next, CHJ is performed on the data with the same partition number in the external table and the internal table. After all CHJ fragments are completed, the whole connection process is completed. The cost of this algorithm is that the external table reads IO twice and the internal table writes IO once. Compared with the previous n-scan internal table IO, the current processing method is better.
#include<cstdio>
#include<algorithm>
#include<queue>
#include<cstring>
using namespace std;
struct data
{
int to,next,val;
}e[2*100005];
int cnt,head[10005],prep[10005],pree[10005],flow[10005],ans;
queue<int> que;
int n,m,s,t,u,v,w;
void add(int u,int v,int w)
{
e[++cnt].to=v;
e[cnt].next=head[u];
head[u]=cnt;
e[cnt].val=w;
}
int bfs(int s,int t)
{
while (!que.empty()) que.pop();
flow[s]=0x3f3f3f3f;//Flow records the flow passing this point on Zengguang road
que.push(s);
for (int i=1;i<=n;i++)
{
prep[i]=-1;//Used to record precursor nodes
pree[i]=0;//Used to record the number of the front edge
}
prep[s]=0;
while (!que.empty())
{
int now=que.front();
que.pop();
if (now==t) break;
for (int i=head[now];i;i=e[i].next)
{
if (e[i].val>0&&prep[e[i].to]==-1)
{
que.push(e[i].to);
flow[e[i].to]=min(flow[now],e[i].val);
pree[e[i].to]=i;
prep[e[i].to]=now;
}
}
}
if (prep[t]!=-1) return flow[t];
else return -1;
}
void EK(int s,int t)
{
int delta=bfs(s,t);//Find the maximum flow of the shortest augmented Road
while (delta!=-1)
{
ans+=delta;
for (int j=t;j;j=prep[j])
{
e[pree[j]].val-=delta;
e[pree[j]^1].val+=delta;
//The chained forward star storage edge is stored from number 2, and the number of the reverse edge can be quickly obtained through XOR 1.
}
delta=bfs(s,t);
}
}
int main()
{
scanf("%d%d%d%d",&n,&m,&s,&t);
cnt=1;
for (int i=1;i<=m;i++)
{
scanf("%d%d%d",&u,&v,&w);
## summary
The interview inevitably makes people anxious. Everyone who has experienced it knows. But it's much easier if you anticipate the questions the interviewer will ask you in advance and come up with appropriate answers.
In addition, it is said that "the interview makes a rocket, and the work screws". For friends preparing for the interview, you only need to understand one word: brush!
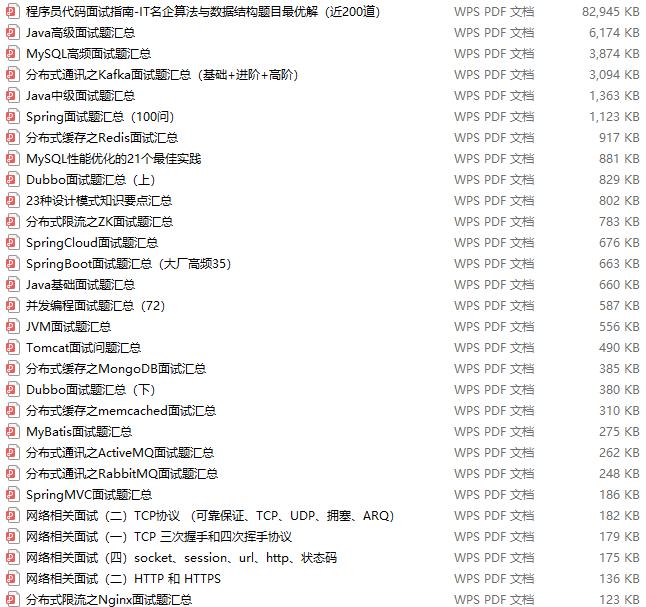
Brush me, brush hard! Since I'm here to talk about the interview today, I have to come to the real interview. It didn't take me 28 days to do a job“ Java Analytical collection of interview questions for senior positions in front-line large factories: JAVA Basics-intermediate-Advanced interview+SSM frame+Distributed+performance tuning +Microservices+Concurrent programming+network+Design pattern+Data structure and algorithm "
> **[Data collection method: click here to download for free](https://gitee.com/vip204888/java-p7)**
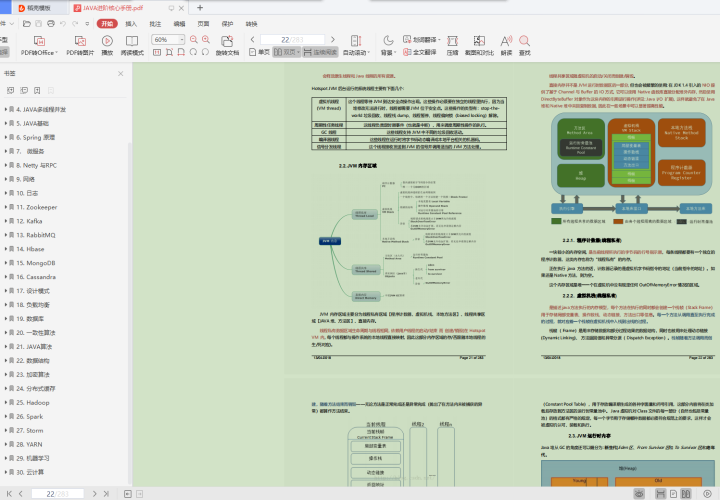
In addition to simply brushing questions, you also need to prepare a book[ JAVA Advanced core knowledge manual]: JVM,JAVA Set JAVA Multithreading concurrency JAVA Foundation Spring Principles, microservices Netty And RPC,Network, log Zookeeper,Kafka,RabbitMQ,Hbase,MongoDB,Cassandra,Design pattern, load balancing, database, consistency algorithm JAVA Algorithm, data structure, encryption algorithm, distributed cache Hadoop,Spark,Storm,YARN,Machine learning and cloud computing are best used to check leaks and fill vacancies.
A copy needs to be prepared[ JAVA Advanced core knowledge manual]: JVM,JAVA Set JAVA Multithreading concurrency JAVA Foundation Spring Principles, microservices Netty And RPC,Network, log Zookeeper,Kafka,RabbitMQ,Hbase,MongoDB,Cassandra,Design pattern, load balancing, database, consistency algorithm JAVA Algorithm, data structure, encryption algorithm, distributed cache Hadoop,Spark,Storm,YARN,Machine learning and cloud computing are best used to check leaks and fill vacancies.