Hello, I'm 3y. Before the text, report the progress of austin project to all shareholders:
Generally speaking, I feel that the response this time is good, although the amount of reading is not high. But there are many more people who leave messages, and many people are worried about whether I will lose my pigeon (I broke halfway through the update)
I can only say: don't panic, absolutely not pigeons, you just chase more.

I have decided to carry my computer home every weekend and run to the nearby library when I have time (the library is YYDS for learning, and the efficiency at home is much lower than that of the Library)
There are not many BB S. Let's continue to talk about a topic today: log
01. What is a log
The so-called log, in my understanding, is to record the information when the program is running

In the early days of Java or in our early learning stage, the log printing was all based on System.out.println();
Does this work? To be discussed.
For most beginners, easy to use! The information I want to see can be seen directly in the console. How convenient it is. The first run results of learning Java are generated by System.out.println(); There is no need to have any learning cost.
For most workers, local debugging is OK, but even if the program is deployed to the server.
The production environment is different from the local environment:
- More logs need to be recorded in the production environment (after all, it runs online as a system / project, and it is impossible to print only a little content)
- The log content of the production environment needs to be retained to the file (as a retention, it will not be said that problems are found online at the first time, and many need to find historical log data)
- The log content of the production environment needs to have a certain standard format (at least the log recording time needs to be)
- ...
For the above requirements, System.out.println(); Are not available.
Therefore, we can see that the projects written in the company do not use System.out.println(); Logged

02. Java log system
After working, you will find that each time you introduce a framework, there are almost corresponding log packages under this framework.
I have integrated several projects in the company before (merging several original projects into one project).
At that time, it was thought that the previous colleagues disassembled the project too carefully, resulting in a certain waste of resources (after all, each project will deploy at least two online machines). Therefore, the company wanted us to merge some small projects for some time.
As for the right and wrong of doing this, I won't talk about it.
In the process of merging, the most troublesome problem is to solve the dependency conflict (all Maven projects, there will be Maven arbitration). Here, the most obvious problem is the Java log package.
If you know a lot about Java logs, you should have heard of the following names: Log4j(log for java), JUL(Java Util Logging), JCL (Jakarta common logging), Slf4j(Simple Logging Facade for Java), Logback and Log4j2

If you are more careful, you will find that the Java log implementations adopted by different technical frameworks are likely to be different.
Since the implementation is different, is the corresponding API call different? (after all, it is not like JDBC. It defines a set of interface specifications. Each database manufacturer implements the JDBC specifications, and programmers can finish programming for JDBC interface.)
Isn't this a mess? Think of here, the blood pressure gradually came up? Don't panic. The Java log Slf4j(Simple Logging Facade for Java) mentioned above is similar to what JDBC does.
It defines the log interface (facade mode). When the project uses other log frameworks, it should adapt to it! (Note: JDBC defines the interface, which is implemented by the database manufacturer. Slf4j also defines the interface, but it is suitable for other Java log implementations, Sao or not?)
When we look at a picture on Slf4j's official website, we should understand it very well:

After a long time, I want to express that in the project, we'd better use the API provided by Slf4j. As for the real LOG implementation, Slf4j can be used for bridging (in this way, maybe one day we want to change from log4j to logback, and the program code doesn't need to be changed)
03. What's the use of logs?
Students who have not yet developed a production environment may think that logging is used to locate problems, but it is not entirely.
On the one hand, we use logs to locate problems. On the other hand, a lot of our data comes from logs
Don't think that the data stored in the database is important. The log data recorded when our program runs is also important.
In the field of big data, there are many data sources: relational database, crawler, log, etc

For example, my previous company had a framework for processing logs:
- We normally output the log information to the file
- The framework provides us with the background configuration (path of file and Kafka Topic Name)
What the framework does is to convert the contents of our log file into Kafka messages (if the user needs to convert the contents of which log file into MQ messages, it is done under the configuration on the platform)
With the Kafka message, can valuable data be generated by cleaning the log with the stream processing platform (Storm/Spark/Flink)

04. Austin log
After pulling the log foundation for so long, I just want the students who don't understand the log to have an understanding.
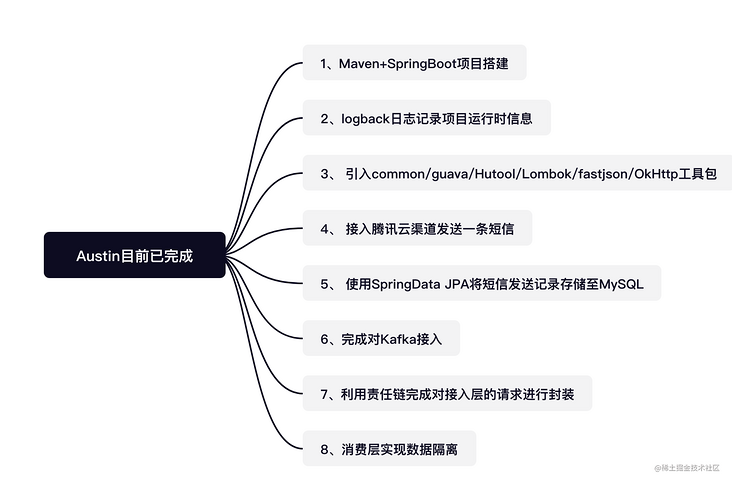
Let's go back to the austin project, which is still in the "new folder" stage.
SpringBoot is used to build the technical framework of austin project. The default log combination of SpringBoot is Slf4j + logback
Almost all the projects I came into contact with in the company are this combination, so I don't intend to move, so I directly use logback as austin's log implementation framework (if I want to change to another log implementation one day, in theory, I just need to introduce the corresponding bridge package).
05. Initial experience of logback log
Without any configuration, as long as we introduce the package of SpringBoot, we can directly use the log function. The specific effects are shown in the figure below

SpringBoot is a framework where conventions are greater than configurations
SpringBoot will load the configuration file named logback.xml or logback-spring.xml under resources by default (the XML format can also be changed to groovy format)
If none exists, logback will call the basic configurator by default to create a minimized configuration.
The minimization configuration consists of a console appender associated to the root logger. Output is formatted with PatternLayoutEncoder with mode% d {HH: mm: SS. SSS} [% thread]% - 5level% logger {36} -% MSG% n

06. logback configuration
It can be found from the above that the default logback configuration does not meet our requirements (it is printed on the console). We want to record the log in a file.
Therefore, we will create a new logback configuration under resources. Common configurations are as follows:
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="10 seconds">
<contextName>austin</contextName>
<!-- Setting the log output path enables“ ${}"To use variables. TODO Here, you need to read the configuration -->
<property name="log.path" value="logs"/>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<!--Format output:%d Indicates the date,%thread Represents the thread name,%-5level: The level is displayed 5 characters wide from the left%msg: Log messages,%n Is a newline character-->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
<!-- Set character set -->
<charset>UTF-8</charset>
</encoder>
</appender>
<!-- Time scrolling output level by INFO journal -->
<appender name="INFO_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- The path and file name of the log file being recorded -->
<file>${log.path}/austin-info.log</file>
<!--Log file output format-->
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
<charset>UTF-8</charset>
</encoder>
<!-- The rolling strategy of the logger, recording by date and by size -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- Daily log archive path and format -->
<fileNamePattern>${log.path}/logs/austin-info-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>1000MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!--Log file retention days-->
<maxHistory>15</maxHistory>
</rollingPolicy>
<!-- This log file only records info Rank -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>info</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!-- Time scrolling output level by ERROR journal -->
<appender name="ERROR_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- The path and file name of the log file being recorded -->
<file>${log.path}/austin-error.log</file>
<!--Log file output format-->
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
<charset>UTF-8</charset> <!-- Set character set here -->
</encoder>
<!-- The rolling strategy of the logger, recording by date and by size -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${log.path}/austin-error-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>1000MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!--Log file retention days-->
<maxHistory>15</maxHistory>
</rollingPolicy>
<!-- This log file only records ERROR Rank -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>ERROR</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<root level="info">
<!-- TODO console You can print only for dev Environmental -->
<appender-ref ref="CONSOLE"/>
<appender-ref ref="INFO_FILE"/>
<appender-ref ref="ERROR_FILE"/>
</root>
</configuration>
The log configuration will not be invariable. Now the project has just been built, it will be as simple as possible.
07. Colored eggs
The night before this article was published, ZhenDong suddenly asked me what MQ I use more now. I answered casually: Kafka. I basically contact MQ with Kafka
He said he was writing a good thing and would send it out at that time. As soon as I heard it, I must be interested.

Links to articles posted by ZhenDong: https://mp.weixin.qq.com/s/JC...
The article is probably about the leaders of the American League. They encapsulated a set of SDK with AOP + dynamic template, and then gracefully recorded the operation log (in other words, the leaders do not want the log to be written on the business code, which is difficult to manage. Abstract the action of writing log and record the log uniformly with annotations)
The article is still very wonderful. I recommend reading it again.
After reading the article, Mr. ZhenDong realized a set by himself, which is almost finished. By the way, I discussed the use scenario with him, and I feel that my project can also use that set of things (there is an elegant way to log, who doesn't love it)
I've already made a reservation. When he sends me the source code, I'll learn the implementation idea (later projects also use the SDK provided by him to log, and if there is a problem, start spraying 🐶 [Goutou. jpg]). When he's finished writing the article, I'll reprint it and study with you.

After learning this kind of wheel or experience idea, you can blow it during the interview. You can say that you have transformed the project system from the original ghost like (introducing the background) * to such elegant (* * the results obtained * *), and interspersed your own implementation ideas and pits encountered in the process (* * arduous process * *) Which interviewer doesn't love this bright spot?
08. Summary
I think the log is in an important position in a project. Our data and positioning problems are inseparable from the log. The logs of some projects are quite chaotic, which is particularly troublesome to maintain.
In fact, I can write my own logback configuration and ignore it, but I still insist on sorting it out. This article combs the log knowledge from the beginning according to the dimension of "project". I hope it will be helpful to you.
Project source code Gitee link: https://gitee.com/austin
Project source code GitHub link: https://github.com/austin

Focus on my WeChat official account Java3y!
[Online interviewer + write Java project from scratch] Continuous high-intensity update! Seek star
It's not easy to be original!! three times!!