introduction
Introduction to Java technology and the course of installing java development software and using it to create simple programs.
Learning the Java language
Courses that describe basic concepts such as classes, objects, inheritance, data types, generics, and packages.
Basic Java classes
Courses on exceptions, basic input / output, concurrency, regular expressions, and the platform environment.
Basic I/O
Covers Java platform classes for basic input and output. It focuses on I/O flow, which is a powerful concept that can greatly simplify I/O operations. This course also introduces serialization, which allows programs to write entire objects to the stream and read them again. Then this lesson will introduce some file system operations, including random access to files. Finally, the advanced features of New I/O API are briefly introduced.
I/O flow
I/O flows represent input sources or output destinations. A stream can represent many different types of sources and destinations, including disk files, devices, other programs, and memory arrays.
Streams support many different types of data, including simple bytes, raw data types, localized characters, and objects. Some streams simply pass data; Others manipulate and transform data in useful ways.
No matter how they work internally, all flows present the same simple model to the program that uses them: a flow is a sequence of data. The program uses the input stream to read data from the source, one item at a time:
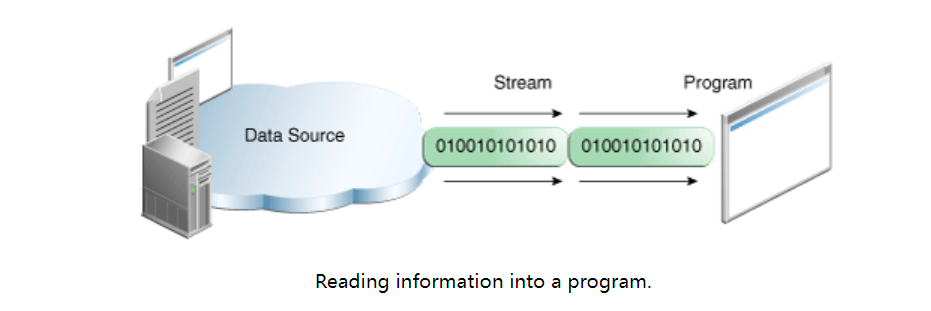
The program uses the output stream to write data to the target, one item at a time:
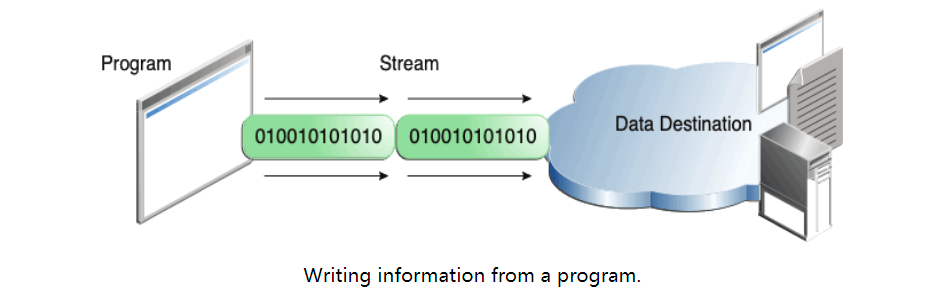
In this lesson, we will see that streams can handle various types of data, from raw values to advanced objects.
The data source and data destination shown in the figure above can be anything that saves, generates or uses data. Obviously, this includes disk files, but the source or destination can also be another program, a peripheral, a network socket, or an array.
In the next section, we will use the most basic stream, byte stream, to demonstrate the common operation of stream I/O. For the sample input, we will use the sample file Xanadu Txt, which contains the following verses:
In Xanadu did Kubla Khan
A stately pleasure-dome decree:
Where Alph, the sacred river, ran
Through caverns measureless to man
Down to a sunless sea.
Byte stream
The program uses byte stream to perform 8-bit byte input and output. All byte stream classes are derived from InputStream and OutputStream.
There are many byte stream classes. To demonstrate how byte streams work, we will focus on file I/O byte streams FileInputStream and FileOutputStream. Other types of byte streams are used in roughly the same way; The main difference between them is the way they are constructed.
Use byte stream
We will study FileInputStream and FileOutputStream through a sample program called CopyBytes, which uses byte streams to copy Xanadu byte by byte at a time txt.
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class CopyBytes {
public static void main(String[] args) throws IOException {
FileInputStream in = null;
FileOutputStream out = null;
try {
in = new FileInputStream("xanadu.txt");
out = new FileOutputStream("outagain.txt");
int c;
while ((c = in.read()) != -1) {
out.write(c);
}
} finally {
if (in != null) {
in.close();
}
if (out != null) {
out.close();
}
}
}
}
CopyBytes spends most of its time in a simple loop, reading the input stream and writing to the output stream, one byte at a time, as shown in the following figure.
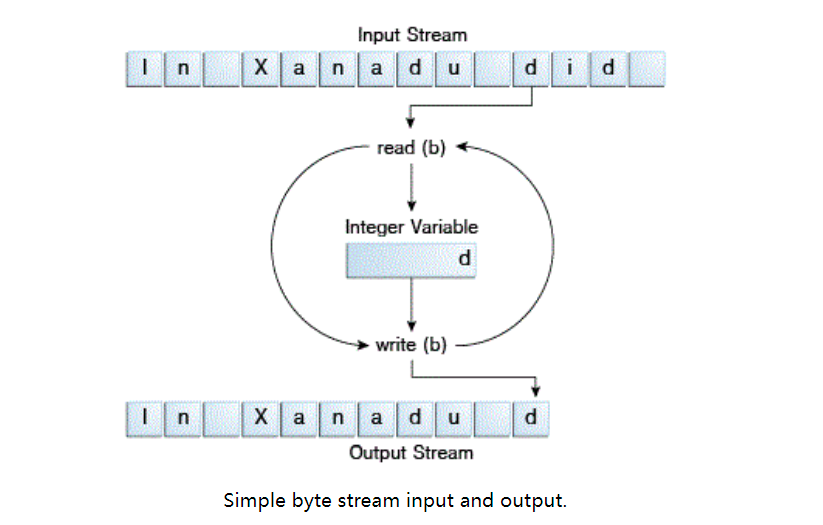
Always close flow
It is important to close the stream when it is no longer needed -- very important, CopyBytes uses the finally block to ensure that both streams will be closed even if an error occurs. This approach helps to avoid serious resource leakage.
One possible error is that CopyBytes cannot open one or two files. When this happens, the rheological value corresponding to the file will never change from its initial value to null value. This is why CopyBytes ensures that each variable contains an object reference before calling close.
When not to use byte stream
CopyBytes looks like an ordinary program, but it actually represents a low-level I/O that should be avoided. Because Xanadu Txt contains character data, so the best way is to use character stream, which will be discussed in the next section. There are also streams for more complex data types. Byte streams should only be used for the most basic I/O.
So why talk about byte streams? Because all other stream types are based on byte streams.
Character stream
The Java platform uses Unicode to store character values. Character stream I/O automatically converts this internal format to a local character set. In the western language environment, the local character set is usually an 8-bit superset of ASCII.
For most applications, the I/O of character stream is not more complex than that of byte stream. Input and output using stream classes are automatically converted to and from the local character set. A program that uses a character stream instead of a byte stream can automatically adapt to the local character set and prepare for Internationalization - all without the extra effort of the programmer.
If internationalization is not a priority, you can simply use character stream classes without paying too much attention to character set issues. Then, if internationalization becomes a priority, your program can be adjusted without a lot of recoding. For more information, see the internationalization section.
Use character stream
All character stream classes are derived from Reader and Writer. Like byte stream, there are also character stream classes dedicated to file I/O: FileReader and FileWriter. The CopyCharacters sample demonstrates these classes.
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class CopyCharacters {
public static void main(String[] args) throws IOException {
FileReader inputStream = null;
FileWriter outputStream = null;
try {
inputStream = new FileReader("xanadu.txt");
outputStream = new FileWriter("characteroutput.txt");
int c;
while ((c = inputStream.read()) != -1) {
outputStream.write(c);
}
} finally {
if (inputStream != null) {
inputStream.close();
}
if (outputStream != null) {
outputStream.close();
}
}
}
}
CopyCharacters is very similar to CopyBytes. The most important difference is that CopyCharacters use FileReader and FileWriter for input and output, rather than FileInputStream and FileOutputStream. Note that both CopyBytes and CopyCharacters use an int variable to read and write. However, in CopyCharacters, the int variable holds a character value in its last 16 bits; In CopyBytes, the int variable holds a byte value in its last 8 bits.
Character stream using byte stream
Character streams are usually "wrappers" of byte streams. Character streams use word junction streams to perform physical I/O, while character streams handle the conversion between characters and bytes. For example, FileReader uses FileInputStream and FileWriter uses FileOutputStream.
There are two common byte to character "bridge" streams: InputStreamReader and OutputStreamWriter. When there are no prepackaged character stream classes that meet your needs, use them to create character streams. The sockets lesson in networking trail shows how to create a character stream from the byte stream provided by the socket class.
Row oriented I / O
Character I/O usually occurs in larger units than a single character. A common unit is a line: a string of characters ending with a line terminator. The line terminator can be a carriage return / line feed sequence ("r\n"), a single carriage return ("r"), or a single line feed ("n"). Support for all possible line terminators allows programs to read text files created on any widely used operating system.
Let's modify the CopyCharacters example to use row oriented I/O. To do this, we must use two classes that we haven't seen before, BufferedReader and PrintWriter. We'll explore these classes in more depth in Buffered I/O and Formatting. For now, we are only interested in their support for line-oriented I/O.
import java.io.FileReader;
import java.io.FileWriter;
import java.io.BufferedReader;
import java.io.PrintWriter;
import java.io.IOException;
public class CopyLines {
public static void main(String[] args) throws IOException {
BufferedReader inputStream = null;
PrintWriter outputStream = null;
try {
inputStream = new BufferedReader(new FileReader("xanadu.txt"));
outputStream = new PrintWriter(new FileWriter("characteroutput.txt"));
String l;
while ((l = inputStream.readLine()) != null) {
outputStream.println(l);
}
} finally {
if (inputStream != null) {
inputStream.close();
}
if (outputStream != null) {
outputStream.close();
}
}
}
}
Calling readLine will return a line of text. CopyLines uses println to output each line, which appends the line terminator of the current operating system. This may be different from the line terminator used in the input file.
In addition to characters and lines, there are many ways to construct text input and output. For more information, see Scanning and Formatting.
Buffer stream
Most of the examples we've seen so far use unbuffered I/O. This means that every read or write request is handled directly by the underlying operating system. This can greatly reduce the efficiency of the program, because each such request usually triggers disk access, network activity, or other relatively expensive operations.
To reduce this overhead, the Java platform implements buffered I/O streams. The buffered input stream reads data from a storage area called a buffer; The native input API is only called when the buffer is empty. Similarly, the buffered output stream writes data to the buffer and calls the native output API only when the buffer is full.
Programs can use the wrapper style we have used many times to convert an unbuffered stream into a buffered stream, where the unbuffered stream object is passed to the constructor of the buffered stream class. Here is how to modify the constructor call in the CopyCharacters example to use buffered I/O:
inputStream = new BufferedReader(new FileReader("xanadu.txt"));
outputStream = new BufferedWriter(new FileWriter("characteroutput.txt"));
There are four buffered stream classes used to wrap unbuffered streams: BufferedInputStream and BufferedOutputStream create buffered byte streams, while BufferedReader and BufferedWriter create buffered character streams.
Flush buffer flow
It usually makes sense to write to the buffer at the critical point without waiting for the buffer to fill up. This is called a flush buffer.
Some buffered output classes support automatic refresh, specified by optional constructor parameters. When auto refresh is enabled, some critical events cause the buffer to be flushed. For example, an automatically refreshed PrintWriter object flushes the buffer every time println or format is called. For more information about these methods, see formatting.
To manually brush a new stream, call its refresh method. The refresh method is valid for any output stream, but not unless the stream is buffered.
Scan and format
Programming I/O usually involves converting neatly formatted data that people like to use. To help you do this, the Java platform provides two APIs. The scanner API decomposes the input into a single token associated with the data bit. The formatting API assembles data into well formatted, human readable forms.
scanning
Scanner type objects are used to decompose formatted input into tokens and translate individual tags according to their data types.
Decompose input into tokens
By default, the scanner uses blank separator markers. (white space characters include spaces, tabs, and line terminators. For a complete list, see the documentation for Character.isWhitespace.) To understand how scanning works, let's look at ScanXan, a program that reads Xanadu Txt and print them line by line.
import java.io.*;
import java.util.Scanner;
public class ScanXan {
public static void main(String[] args) throws IOException {
Scanner s = null;
try {
s = new Scanner(new BufferedReader(new FileReader("xanadu.txt")));
while (s.hasNext()) {
System.out.println(s.next());
}
} finally {
if (s != null) {
s.close();
}
}
}
}
Note that when the Scanner object is completed, ScanXan will call the Scanner's close method. Even if the Scanner is not a stream, you need to close it to indicate that you have completed its underlying stream.
The output of ScanXan is as follows:
In Xanadu did Kubla Khan A stately pleasure-dome ...
To use a different token delimiter, call useDelimiter() and specify a regular expression. For example, suppose you want the token separator to be a comma, optionally followed by a space. You'll call,
s.useDelimiter(",\\s*");
**Translation of unique symbols**
The ScanXan example treats all input tags as simple String values. Scanner also supports tokens of all basic types of the Java language (except char), as well as BigInteger and BigDecimal. In addition, values can use thousands of separators. Therefore, in the U.S. locale, scanner correctly reads the String "32767" to represent an integer value.
We must mention locale, because thousands of separators and decimal symbols are locale specific. Therefore, if we do not specify that the scanner should use the U.S. region, the following example will not work correctly in all regions. This is not something you usually need to worry about, because your input data usually comes from sources that use the same locale as you. But this example is part of the Java Tutorial and has been released around the world.
The ScanSum sample reads the double value in the file and adds it. This is the source:
import java.io.FileReader;
import java.io.BufferedReader;
import java.io.IOException;
import java.util.Scanner;
import java.util.Locale;
public class ScanSum {
public static void main(String[] args) throws IOException {
Scanner s = null;
double sum = 0;
try {
s = new Scanner(new BufferedReader(new FileReader("usnumbers.txt")));
s.useLocale(Locale.US);
while (s.hasNext()) {
if (s.hasNextDouble()) {
sum += s.nextDouble();
} else {
s.next();
}
}
} finally {
s.close();
}
System.out.println(sum);
}
}
This is the sample input file usnumbers txt
8.5 32,767 3.14159 1,000,000.1
The output string is "1032778.74159". In some regions, the sentence point will be a different character because of system Out is a PrintStream object, and this class does not provide a method to override the default locale. We can cover the language environment of the whole program -- or we can use only formats, as described in the following topic "formatting".
format
The stream object that implements formatting is an instance of printwriter (character stream class) or printstream (byte stream class).
Note: the only PrintStream object you may need is system Out and system err. (for more information about these objects, see I/O on the command line.) When you need to create a formatted output stream, instantiate PrintWriter instead of PrintStream.Like all byte stream and character stream objects, instances of PrintStream and PrintWriter implement a set of standard write methods for simple byte and character output. In addition, both PrintStream and PrintWriter implement the same set of methods to convert internal data into formatted output. Two levels of formats are available:
- print and println format individual values in a standard way.
- Format formats almost any number of values based on the format string, and there are many options for precise formatting.
print and println methods
Call print or println to output a single value after converting the value using the appropriate toString method. We can see in the Root example:
public class Root {
public static void main(String[] args) {
int i = 2;
double r = Math.sqrt(i);
System.out.print("The square root of ");
System.out.print(i);
System.out.print(" is ");
System.out.print(r);
System.out.println(".");
i = 5;
r = Math.sqrt(i);
System.out.println("The square root of " + i + " is " + r + ".");
}
}
The following is the output of Root:
The square root of 2 is 1.4142135623730951. The square root of 5 is 2.23606797749979.
The variables i and r are formatted twice: the first time using overloaded print code and the second time using the conversion code automatically generated by the Java compiler, which also uses toString. You can format any value in this way, but you don't have much control over the results.
format method
The format method formats multiple parameters based on the format string. The format string is composed of static text embedded with format specifier; The output format is unchanged except for the string specifier.
Format strings support many features. In this tutorial, we only introduce some basic knowledge. For a complete description, see in the API specification Format String Syntax.
The Root2 example formats two values with a format call:
public class Root2 {
public static void main(String[] args) {
int i = 2;
double r = Math.sqrt(i);
System.out.format("The square root of %d is %f.%n", i, r);
}
}
The output is as follows:
The square root of 2 is 1.414214.
Like the three format specifiers used in this example, all format specifiers start with% and end with a one or two character conversion that specifies the type of formatted output generated. The three transformations used here are:
- d formats integer values into decimal values.
- f formats floating-point values as decimal values.
- n outputs platform specific line terminators.
Here are some other transformations:
- x formats integers as hexadecimal values.
- s formats any value as a string.
- tB formats integers as locale specific month names.
There are many other transformations.
be careful:All format specifiers except%% and% n must match parameters. If not, an exception is thrown.
In the Java programming language, escape characters always generate line breaks (\ u000A). Do not use \ n unless you specifically want line breaks. To get the correct line separator for the local platform, use% n.
In addition to the transformation, the Format specifier can contain several other elements that further customize the formatted output. Here is an example, Format, which uses all possible element types.
public class Format {
public static void main(String[] args) {
System.out.format("%f, %1$+020.10f %n", Math.PI);
}
}
Output:
3.141593, +00000003.1415926536
Other elements are optional. The following figure shows how the longer specifier is broken down into elements.
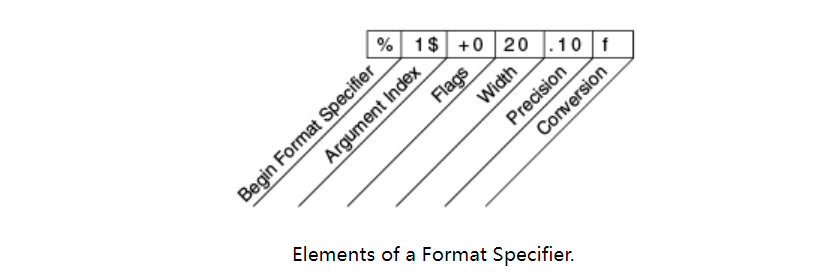
Elements must appear in the order they appear. From the right, the optional elements are:
- Precision. For floating-point values, this is the mathematical precision of the formatted value. For s and other general conversions, this is the maximum width of the formatted value; If necessary, the value is truncated to the right.
- Width. The minimum width of the formatted value; This value is populated if necessary. By default, this value is filled with spaces on the left.
- Flags specifies additional formatting options. In the Format example, the + Flag specifies that numbers should always be formatted with symbols, while the 0 flag specifies that 0 is a padding character. Other flags include - (padding on the right) and (Format numbers with thousands of region specific separators). Note that some flags cannot be used with some other flags or some transformations.
- The Argument Index allows you to explicitly match specified parameters. You can also specify < to match the previous parameters. Therefore, this example can be said: system out. format("%f, %<+020.10f %n", Math.PI);
IO operations from the command line
Programs usually run from the command line and interact with users in the command line environment. The Java platform supports this interaction in two ways: through standard flow and console.
Standard flow
Standard flow is a feature of many operating systems. By default, they read input from the keyboard and write output to the display. They also support I/O on files and between programs, but this feature is controlled by the command-line interpreter, not the program.
The Java platform supports three standard streams: standard input through system in; Standard output through system out; Standard error, via system Err access. These objects are automatically defined and do not need to be opened. Both standard output and standard error are output; Using error output alone allows users to transfer regular output to a file and still be able to read error messages. For more information, see the documentation for the command line interpreter.
You might expect standard streams to be character streams, but for historical reasons, they are byte streams. System.out and system Err is defined as a PrintStream object. Although it is technically a byte stream, PrintStream uses an internal character stream object to simulate many characteristics of character stream.
In contrast, system In is a byte stream without character stream characteristics. To use standard input as a character stream, wrap System.in InputStreamReader in.
InputStreamReader cin = new InputStreamReader(System.in);
Console
A more advanced alternative to standard flow is the Console. This is a separate, predefined Console type object that has most of the features provided by standard flow, among others. The Console is particularly useful for secure password entry. The Console object also provides a real character stream through its reader and writer methods.
Before the program can use console, it must try to call system Console () to retrieve the console object. This method returns the console object if it is available. If system If console returns NULL, console operations are not allowed, either because they are not supported by the operating system or because the program is started in a non interactive environment.
The Console object supports secure password entry through its readPassword method. This method can protect password input in two ways. First, it suppresses echo, so the password is not visible on the user's screen. Second, readPassword returns an array of characters instead of a string, so you can rewrite the password and delete it from memory once it is no longer needed.
The Password example is a prototype program for changing a user's Password. It demonstrates several Console methods.
import java.io.Console;
import java.util.Arrays;
import java.io.IOException;
public class Password {
public static void main (String args[]) throws IOException {
Console c = System.console();
if (c == null) {
System.err.println("No console.");
System.exit(1);
}
String login = c.readLine("Enter your login: ");
char [] oldPassword = c.readPassword("Enter your old password: ");
if (verify(login, oldPassword)) {
boolean noMatch;
do {
char [] newPassword1 = c.readPassword("Enter your new password: ");
char [] newPassword2 = c.readPassword("Enter new password again: ");
noMatch = ! Arrays.equals(newPassword1, newPassword2);
if (noMatch) {
c.format("Passwords don't match. Try again.%n");
} else {
change(login, newPassword1);
c.format("Password for %s changed.%n", login);
}
Arrays.fill(newPassword1, ' ');
Arrays.fill(newPassword2, ' ');
} while (noMatch);
}
Arrays.fill(oldPassword, ' ');
}
// Dummy change method.
static boolean verify(String login, char[] password) {
// This method always returns
// true in this example.
// Modify this method to verify
// password according to your rules.
return true;
}
// Dummy change method.
static void change(String login, char[] password) {
// Modify this method to change
// password according to your rules.
}
}
The Password class follows these steps:
- Attempt to retrieve the Console object. Abort if the object is not available.
- Call console ReadLine prompts and reads the user's login name.
- Call console Readpassword prompts and reads the user's existing password.
- Call verify to confirm that the user is authorized to change the password. (in this case, verify is a virtual method that always returns true.)
- Repeat the following steps until the user enters the same password twice.
a. Call console Readpassword prompt twice and read the new password.
b. If the user enters the same password twice, change is called to change it. (again, change is a virtual method.)
c. Overwrite the two passwords with spaces. - Overwrite the old password with a space.
data stream
The data flow supports binary I/O of basic data type values (boolean, char, byte, short, int, long, float and double) and String values. All data streams implement DataInput interface or DataOutput interface. This section focuses on the most widely used implementations of these interfaces: DataInputStream and DataOutputStream.
DataStreams The example demonstrates data flow by writing out a set of data records and then reading them in. Each record consists of three values related to an item on the invoice, as shown in the following table:

Let's look at the key code in the data flow. First, the program defines some constants, which contain the name of the data file and the data to be written into it:
static final String dataFile = "invoicedata";
static final double[] prices = { 19.99, 9.99, 15.99, 3.99, 4.99 };
static final int[] units = { 12, 8, 13, 29, 50 };
static final String[] descs = {
"Java T-shirt",
"Java Mug",
"Duke Juggling Dolls",
"Java Pin",
"Java Key Chain"
};
Then DataStreams opens an output stream. Since DataOutputStream can only be created as a wrapper for existing byte stream objects, DataStreams provides a buffered file output byte stream.
out = new DataOutputStream(new BufferedOutputStream(
new FileOutputStream(dataFile)));
DataStreams writes out the record and closes the output stream.
for (int i = 0; i < prices.length; i ++) {
out.writeDouble(prices[i]);
out.writeInt(units[i]);
out.writeUTF(descs[i]);
}
The writeUTF method writes out the String value in the modified UTF-8 form. This is a variable width character encoding. Ordinary western characters only need one byte.
Now DataStreams reads the data again. First, it must provide an input stream and variables to hold the input data. Like DataOutputStream, DataInputStream must be constructed as a wrapper for byte streams.
in = new DataInputStream(new
BufferedInputStream(new FileInputStream(dataFile)));
double price;
int unit;
String desc;
double total = 0.0;
DataStreams can now read every record in the stream and report the data it encounters.
try {
while (true) {
price = in.readDouble();
unit = in.readInt();
desc = in.readUTF();
System.out.format("You ordered %d" + " units of %s at $%.2f%n",
unit, desc, price);
total += unit * price;
}
} catch (EOFException e) {
}
Note that DataStreams detects the end of file condition by capturing EOFException instead of testing an invalid return value. All implementations of DataInput methods use EOFException instead of return values.
Also note that each specialized write in Datastream exactly matches the corresponding specialized read. The programmer needs to ensure that the output type and input type match in the following way: the input stream consists of simple binary data without indicating the type of individual values or their starting position in the stream.
DataStreams uses a very bad programming technique: it uses floating-point numbers to represent the value of money. In general, floating point numbers are not good for exact values. This is especially bad for decimal fractions, because ordinary values (such as 0.1) have no binary representation.
The correct type for currency values is Java math. BigDecimal. Unfortunately, BigDecimal is an object type, so it cannot handle data streams. However, BigDecimal will handle object streams, which will be discussed in the next section.
Object flow
Just as data flow supports I/O of original data type, object flow also supports I/O of object. Most (but not all) standard classes support serialization of their objects. Those all implement the tag interface Serializable.
The object stream classes are ObjectInputStream and ObjectOutputStream. These classes implement ObjectInput and ObjectOutput, which are sub interfaces of DataInput and DataOutput. This means that all the original data I/O methods involved in the data flow are also implemented in the object flow. Therefore, an object stream can contain a mixture of original and object values. ObjectStreams Examples illustrate this. ObjectStreams created the same application as DataStreams, with some changes. First, the price is now a BigDecimal object to better represent decimals. Secondly, the Calendar object is written to the data file to indicate the invoice date.
If readObject() does not return the expected object type, trying to convert it to the correct type may throw ClassNotFoundException. In this simple example, this is unlikely to happen, so we don't try to catch exceptions. Instead, we notify the compiler that we have noticed this problem by adding ClassNotFoundException to the throws clause of the main method.
Output and input of complex objects
The writeObject and readObject methods are simple to use, but they contain some very complex object management logic. This is not important for a class like Calendar because it just encapsulates the original value. However, many objects contain references to other objects. If readObject wants to reconstruct objects from the stream, it must be able to reconstruct all objects referenced by the original object. These additional objects may have their own references, and so on. In this case, writeObject will traverse the entire object reference network and write all objects in the network to the stream. Therefore, a writeObject call may cause a large number of objects to be written to the stream.
The following illustration demonstrates this, calling writeObject to write a single object named a. This object contains references to objects b and c, while object b contains references to objects d and e. Calling writeobject(a) not only writes an object, but all objects that need to reconstruct an object, so the other four objects in the web will also be written. When one object is read back by readObject, the other four objects are also read back, and all original object references are retained.
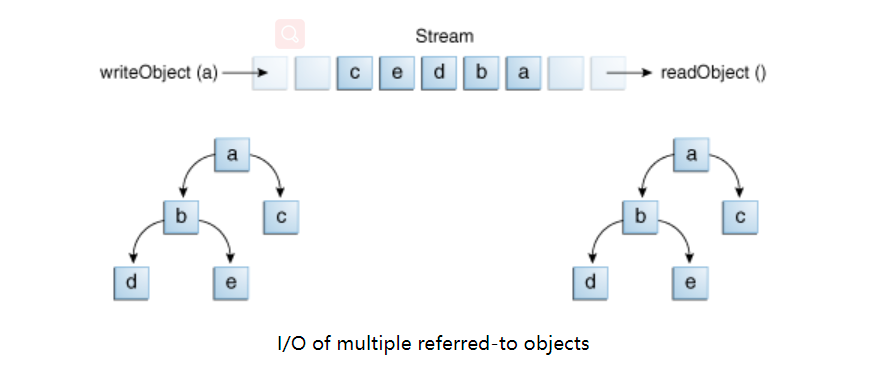
You might wonder what happens if two objects in the same stream contain references to a single object. When they are read back, do they all point to an object? The answer is yes. A stream can contain only one copy of an object, although it can contain any number of references to it. Therefore, if you explicitly write an object to the stream twice, you actually write the reference only twice. For example, if the following code writes the object ob twice to a stream:
Object ob = new Object(); out.writeObject(ob); out.writeObject(ob);
Each writeObject must match a readObject, so the code returned by the read stream looks like this:
Object ob1 = in.readObject(); Object ob2 = in.readObject();
This produces two variables ob1 and ob2, which are references to a single object.
However, if an object is written to two different streams, it is effectively copied - a program reading two streams will see two different objects.
File I/O (using NIO.2)
Note: this tutorial reflects the file I/O mechanism introduced in the JDK 7 release.java.nio.file package and its related packages Java nio. file. Attribute, which provides comprehensive support for file I/O and accessing the default file system. Although the API has many classes, you only need to focus on a few entry points. You will see that this API is very intuitive and easy to use.
This tutorial first asks, what is a Path? Then, it introduces the Path class, the main entry point of the package. Explains the methods related to syntax operations in the Path class. This tutorial then introduces another main class in the package, the Files class, which contains methods for handling file operations. Firstly, some common concepts of file operation are introduced. This tutorial describes how to check, delete, copy, and move Files.
Before you learn about file I/O and directory I/O, this tutorial describes how to manage metadata. Explained random access to files and examined specific problems with symbols and hard links.
Next, we will introduce some very powerful but more advanced topics. First, demonstrate the function of recursively traversing the file tree, and then introduce how to use wildcards to search for files. Next, we will explain and demonstrate how to monitor changes to the directory. Then, give some attention to methods that are not suitable for other places.
Finally, if you wrote file I/O code before the release of Java SE 7, there is a mapping from the old API to the new API and about file Important information about the topath method is provided to developers who want to take advantage of the new API without rewriting existing code.
What is a path?
File systems store and organize files on some form of media (usually one or more hard drives) in an easily retrievable manner. Most storage systems use a hierarchical (or hierarchical) file structure. At the top of the tree is one (or more) root nodes. Under the root node, there are files and directories (folders in Microsoft Windows). Each directory can contain files and subdirectories, and subdirectories can contain files and subdirectories, and so on, which may have almost unlimited depth.
What is a path?
The following figure shows a directory tree with a single root node. Microsoft Windows supports multiple root nodes. Each root node is mapped to a volume, such as C: \ or D: \. The Solaris Operating system supports a single root node, represented by the slash character /.
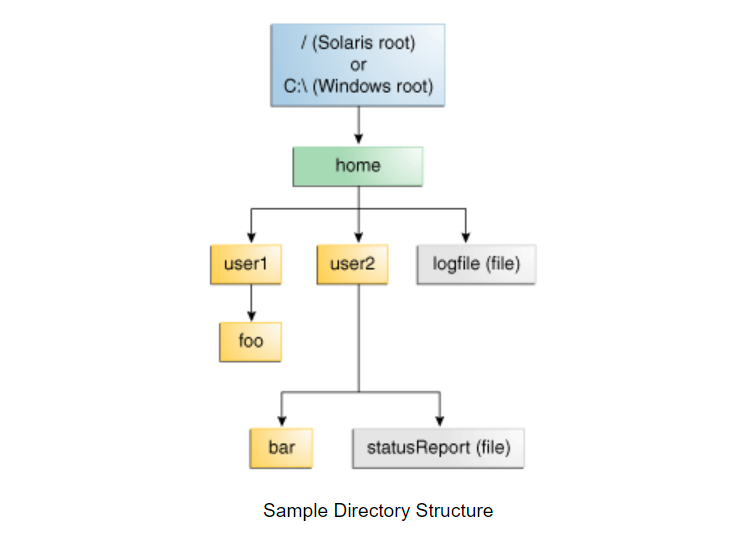
The file is identified by its path in the file system, starting from the root node. For example, the statusReport file in the above figure is described in the Solaris Operating System as follows:
/home/user2/statusReport
In Microsoft Windows, the description method of statusReport is as follows:
C:\home\use2\statusReport
The characters used to separate directory names (also known as separators) are file system specific: the Solaris Operating system uses a forward slash (/), and Microsoft Windows uses a backslash ().
Relative or absolute?
The path can be relative or absolute. The absolute path always contains the root element and the complete list of directories needed to locate the file. For example: / home/user2/statusReport is an absolute path. All the information needed to locate the file is contained in the path string.
A relative path needs to be combined with another path to access a file. For example, joe/foo is a relative path. Without more information, the program cannot reliably locate the joe/foo directory in the file system.
Symbolic connection
File system objects are usually directories or files. These objects are familiar to everyone. However, some file systems also support the concept of symbolic links. symbolic link is also called symlink or soft link.
A symbolic link is a special file that serves as a reference to another file. In most cases, symbolic links are transparent to applications, and operations on symbolic links are automatically redirected to the target of the link. (the file or directory pointed to is called the target of the link.) The exception is that symbolic links are deleted or renamed, in which case the link itself is deleted or renamed rather than the target of the link.
In the figure below, logFile is a normal file for users, but it is actually a symbolic link to dir/logs/HomeLogFile. HomeLogFile is the target of the link.
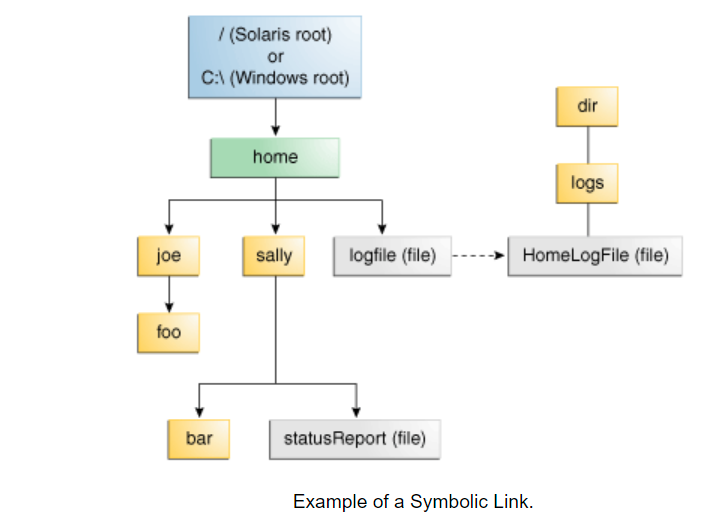
Symbolic links are usually transparent to users. Reading or writing to symbolic links is the same as reading or writing to other files or directories.
Phrase parsing links mean replacing symbolic links with actual locations in the file system. In this example, parsing logFile will generate dir/logs/HomeLogFile.
In the actual scenario, most file systems are free to use symbolic links. Occasionally, inadvertently created symbolic links can lead to circular references. Circular references occur when the target of a link points to the original link. Circular references can be indirect: directory a points to directory b, directory b points to directory c, and directory c contains a subdirectory pointing to directory a. Circular references can cause confusion when a program recursively traverses the directory structure. However, this situation has been considered and will not cause your program to loop indefinitely.
The next page will discuss the Path class, the core of file I/O support in the Java programming language.
Path class
The Path class is introduced in the Java SE 7 distribution. It is Java nio. One of the main entry points for the file package. If your application uses file I/O, you will want to understand the powerful features of this class.
Note: if you use Java io. File jdk7 before the code, you can still use file Topath method to take advantage of the function of the Path class. For more information, see legacy file I/O code.As the name suggests, the Path class is a programmatic representation of the Path in the file system. The Path object contains a list of file names and directories used to construct the Path, and is used to check, locate, and manipulate files.
The path instance reflects the underlying platform. In the Solaris Operating System, the path uses the Solaris syntax (/ home/joe/foo), while in Microsoft Windows, the path uses the windows syntax (C: home\joe\foo). Path is not system independent. You cannot compare the path from the Solaris file system and expect it to match the path from the windows file system, even if the directory structure is the same and the two instances locate the same relative files.
The file or directory corresponding to Path may not exist. You can create a Path instance and manipulate it in many ways: you can add it, extract its fragments, and compare it with another Path. When appropriate, you can use the methods in the Files class to check whether the file corresponding to Path exists, create a file, open a file, delete a file, change its permissions, and so on.
The next section details the Path class.
Path operation
The Path class includes various methods that can be used to obtain information about the Path, access Path elements, convert the Path to other forms, or extract part of the content of the Path. There are also methods for matching Path strings and for removing Path redundancy. This lesson discusses these Path methods, sometimes called syntax operations, because they operate on the Path itself without accessing the file system.
Create path
The path instance contains information that specifies the location of a file or directory. When defining path, path provides a list of one or more names. You can include a root element or a file name, but neither is required. Path may contain only one directory or file name.
You can easily create a Path object from the Path (note the plural) helper class by using one of the following methods:
Path p1 = Paths.get("/tmp/foo");
Path p2 = Paths.get(args[0]);
Path p3 = Paths.get(URI.create("file:///Users/joe/FileTest.java"));
Paths. The get method is an abbreviation for the following code:
Path p4 = FileSystems.getDefault().getPath("/users/sally");
The following example creates / u/joe / logs / foo Log, suppose your home directory is / u/joe, or C: Joe \ logs \ foo Log (if you are on Windows).
Path p5 = Paths.get(System.getProperty("user.home"),"logs", "foo.log");
Retrieve path information
You can think of Path as storing these name elements as a sequence. The highest element in the directory structure is at index 0. The lowest element in the directory structure is at index [n-1], where n is the number of name elements in the Path. There are ways to use these indexes to retrieve individual elements or subsequences of Path.
The examples in this lesson use the following directory structure.
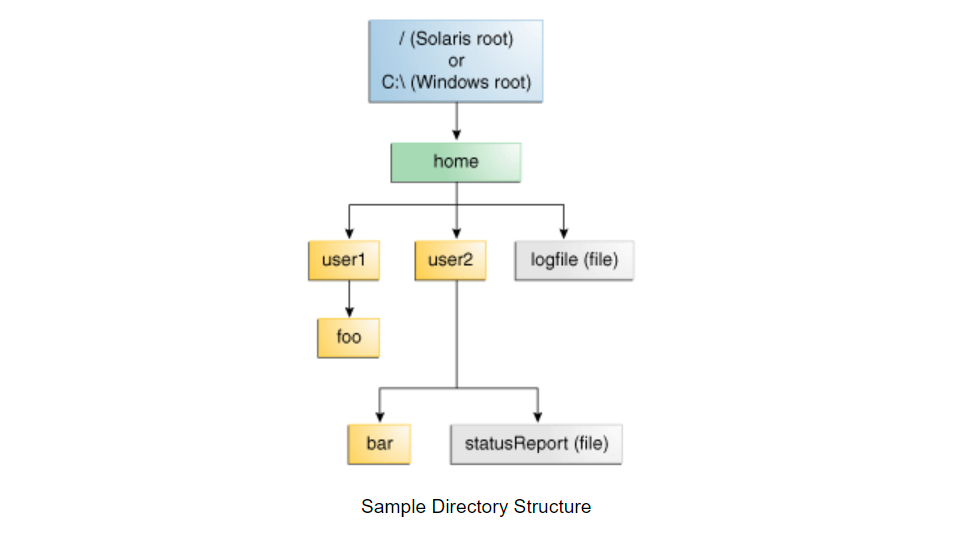
The following code snippet defines a Path instance, and then calls several methods to get information about the path:
// None of these methods requires that the file corresponding
// to the Path exists.
// Microsoft Windows syntax
Path path = Paths.get("C:\\home\\joe\\foo");
// Solaris syntax
Path path = Paths.get("/home/joe/foo");
System.out.format("toString: %s%n", path.toString());
System.out.format("getFileName: %s%n", path.getFileName());
System.out.format("getName(0): %s%n", path.getName(0));
System.out.format("getNameCount: %d%n", path.getNameCount());
System.out.format("subpath(0,2): %s%n", path.subpath(0,2));
System.out.format("getParent: %s%n", path.getParent());
System.out.format("getRoot: %s%n", path.getRoot());
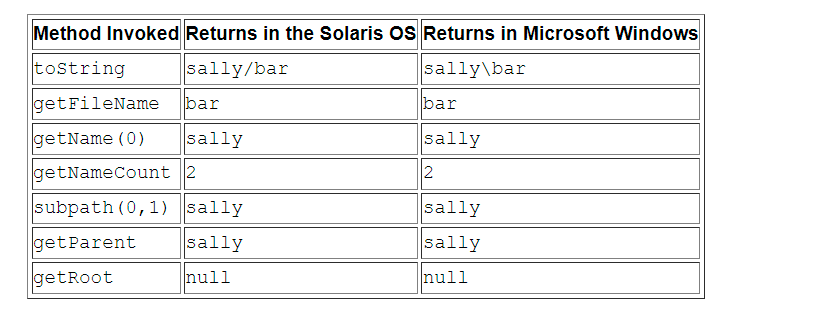
The following is the output of the Windows and Solaris Operating Systems:
| Method Invoked | Returns in the Solaris OS | Returns in Microsoft Windows | Comment |
|---|---|---|---|
| toString | /home/joe/foo | C:\home\joe\foo | Returns the string representation of the path. If the path is filesystems getDefault(). getPath (string) or paths Created by get (the latter is a convenient method of getPath), which performs a small amount of syntax cleanup. For example, in the UNIX operating system, it corrects the input string / / home/joe/foo to / home/joe/foo. |
| getFileName | foo | foo | Returns the last element in the file name or name element sequence. |
| getName(0) | home | home | Returns the path element corresponding to the specified index. The 0th element is the path element closest to the root. |
| getNameCount | 3 | 3 | Returns the number of elements in the path. |
| subpath(0,2) | home/joe | home\joe | Returns a subsequence (excluding the root element) of the Path specified by the start index and the end index. |
| getParent | /home/joe | \home\joe | Returns the path of the parent directory. |
| getRoot | / | C:\ | Returns the root directory of the path. |
The previous example shows the output of the absolute path. In the following example, a relative path is specified:
// Solaris syntax
Path path = Paths.get("sally/bar");
or
// Microsoft Windows syntax
Path path = Paths.get("sally\\bar");
The output of Solaris and Windows operating system is as follows:
Remove path redundancy
Many file systems use "." The symbol indicates the current directory and the "..." symbol indicates the parent directory. You may encounter a situation where Path contains redundant directory information. Perhaps the server is configured to save its log files in "/ dir/logs /." Directory, you want to delete the "/." at the end of the Path Symbol.
The following examples include redundancy:
/home/./joe/foo /home/sally/../joe/foo
The normalize method removes any redundant elements, including any "." Or "directory /...". The previous two examples are normalized to / home/joe/foo.
It should be noted that normalize does not check the file system when cleaning up the path. This is a purely syntactic operation. In the second example, if sally is a symbolic link, deleting sally /... May cause the path to no longer locate the expected file.
To clean up the path and ensure that the result is located in the correct file, you can use the toRealPath method. This method is described in the conversion path in the next section.
Conversion path
You can convert paths in three ways. If you need to convert the Path to a string that can be opened from the browser, you can use toUri. For example:
Path p1 = Paths.get("/home/logfile");
// Result is file:///home/logfile
System.out.format("%s%n", p1.toUri());
The toAbsolutePath method converts a path to an absolute path. If the incoming path is already absolute, it will return the same path object. The toAbsolutePath method is useful when dealing with file names entered by users. For example:
public class FileTest {
public static void main(String[] args) {
if (args.length < 1) {
System.out.println("usage: FileTest file");
System.exit(-1);
}
// Converts the input string to a Path object.
Path inputPath = Paths.get(args[0]);
// Converts the entered path to an absolute path.
// Typically, this means adding the current working directory in advance.
// If this example is called as follows:
// The getRoot and getParent methods of java FileTest foo will return null on the original "inputPath" instance.
// Calling getRoot and getParent on the 'fullPath' instance will return the expected value.
Path fullPath = inputPath.toAbsolutePath();
}
}
The toAbsolutePath method converts user input and returns a Path that returns useful values when querying. The file does not need to exist, and this method can work.
The toRealPath method returns the actual path of an existing file. This method performs several operations simultaneously:
- If true is passed to the method and the file system supports symbolic links, the method resolves any symbolic links in the path.
- If the Path is relative, the absolute Path is returned.
- If the Path contains any redundant elements, it returns a Path that removes them.
This method throws an exception if the file does not exist or cannot be accessed. When you want to handle any of these situations, you can catch exceptions. For example:
try {
Path fp = path.toRealPath();
} catch (NoSuchFileException x) {
System.err.format("%s: no such" + " file or directory%n", path);
// Logic for case when file doesn't exist.
} catch (IOException x) {
System.err.format("%s%n", x);
// Logic for other sort of file error.
}
Add two paths
You can combine paths using the resolve method. Pass in a partial path that does not contain the root element, which is appended to the original path.
For example, consider the following code snippet:
// Solaris
Path p1 = Paths.get("/home/joe/foo");
// Result is /home/joe/foo/bar
System.out.format("%s%n", p1.resolve("bar"));
or
// Microsoft Windows
Path p1 = Paths.get("C:\\home\\joe\\foo");
// Result is C:\home\joe\foo\bar
System.out.format("%s%n", p1.resolve("bar"));
Passing the absolute path to the resolve method will return the incoming path:
// Result is /home/joe
Paths.get("foo").resolve("/home/joe");
Create a path between two paths
When writing file I/O code, a common requirement is to be able to build a path from one location in the file system to another. You can use the relativize method to solve this problem. This method constructs a path that starts from the original path and ends at the location specified by the incoming path. The new path is relative to the original path.
For example, consider two relative paths defined as joe and sally:
Path p1 = Paths.get("joe");
Path p2 = Paths.get("sally");
In the absence of any other information, it is assumed that joe and sally are brother nodes, which means that the nodes are located at the same level of the tree structure. To navigate from joe to sally, you need to navigate first to the parent node, and then down to sally:
// Result is ../sally Path p1_to_p2 = p1.relativize(p2); // Result is ../joe Path p2_to_p1 = p2.relativize(p1);
Consider a slightly more complex example:
Path p1 = Paths.get("home");
Path p3 = Paths.get("home/sally/bar");
// Result is sally/bar
Path p1_to_p3 = p1.relativize(p3);
// Result is ../..
Path p3_to_p1 = p3.relativize(p1);
In this case, the two paths share the same node home. To navigate from home to bar, first navigate down to sally, and then down to bar. From bar to home, you need to move up two layers.
If only one path contains a root element, you cannot construct a relative path. If both paths contain root elements, the ability to construct relative paths depends on the system.
recursion Copy The example uses the relativize and resolve methods.
Compare two paths
The Path class supports equals, enabling you to test whether two paths are equal. The startsWith and endsWith methods allow you to test whether a Path starts or ends with a specific string. These methods are easy to use. For example:
Path path = ...;
Path otherPath = ...;
Path beginning = Paths.get("/home");
Path ending = Paths.get("foo");
if (path.equals(otherPath)) {
// equality logic here
} else if (path.startsWith(beginning)) {
// path begins with "/home"
} else if (path.endsWith(ending)) {
// path ends with "foo"
}
The Path class implements the Iterable interface. The iterator method returns an object that allows you to iterate over the name element in the Path. The first element returned is the element closest to the root in the directory tree. The following code snippet traverses a Path and prints each name element:
Path path = ...;
for (Path name: path) {
System.out.println(name);
}
The Path class also implements the Comparable interface. You can use compareTo to compare Path objects, which is very useful for sorting.
You can also put objects in Collection Path. For more information about this powerful feature, see Collections.
When you want to verify that two Path objects locate the same file, you can use the isSameFile method. See checking whether two paths find the same file section in the section checking files or directories.
File operation
The Files class is Java nio. Another major entry point for the file package. This class provides a rich set of static methods for reading, writing, and manipulating Files and directories. The Files method acts on an instance of the Path object. Before moving on to the rest, you should familiarize yourself with the following common concepts:
- Free system resources
- Catch exception
- Variable parameter
- Atomic operation
- Method chain
- What is globe?
- Link awareness
Free system resources
Many of the resources used in this API, such as streams or channels, implement or extend Java io. Closeable interface. One requirement of a closeable resource is that when it is no longer needed, the close method must be called to release the resource. Ignoring closing resources can have a negative impact on the performance of your application. The try with resources statement described in the next section handles this step for you.
Catch exception
For file I/O, unexpected situations are inevitable: when a file exists (or does not exist), the program cannot access the file system, the default file system implementation does not support specific functions, and so on. Many errors may be encountered.
All methods of accessing the file system can throw an IOException. The best practice for catching these exceptions is to embed these methods into the try with resources statement introduced in the Java SE 7 release. The advantage of the try with resources statement is that when the resource is no longer needed, the compiler automatically generates code to close the resource. The following code shows how this might look:
Charset charset = Charset.forName("US-ASCII");
String s = ...;
try (BufferedWriter writer = Files.newBufferedWriter(file, charset)) {
writer.write(s, 0, s.length());
} catch (IOException x) {
System.err.format("IOException: %s%n", x);
}
For more information, see the try with resources section.
Alternatively, you can embed file I/O methods into the try block and catch any exceptions in the catch block. If your code opens any streams or channels, you should close them in the finally block. Using the try catch finally method, the previous example is as follows:
Charset charset = Charset.forName("US-ASCII");
String s = ...;
BufferedWriter writer = null;
try {
writer = Files.newBufferedWriter(file, charset);
writer.write(s, 0, s.length());
} catch (IOException x) {
System.err.format("IOException: %s%n", x);
} finally {
if (writer != null) writer.close();
}
For more information, see the catching and handling exceptions section.
In addition to IOException, many specific exceptions extend FileSystemException. This class has some useful methods that return the file involved (getFile), the detailed message string (getMessage), the reason why the file system operation failed (getReason), and the "other" file involved (if any) (getOtherFile).
The following code snippet shows how to use the getFile method:
try (...) {
...
} catch (NoSuchFileException x) {
System.err.format("%s does not exist\n", x.getFile());
}
For clarity, the file I/O example in this lesson may not show exception handling, but your code should always include it.
Variable parameter
When a flag is specified, several Files methods accept any number of parameters. For example, in the following method signature, the ellipsis after the CopyOption parameter indicates that the method accepts a variable number of parameters, or varargs, as they are usually called:
Path Files.move(Path, Path, CopyOption...)
When a method accepts a varargs parameter, you can pass it a comma separated list of values or an array of values (CopyOption []).
In the move example, this method can be called as follows:
import static java.nio.file.StandardCopyOption.*;
Path source = ...;
Path target = ...;
Files.move(source,
target,
REPLACE_EXISTING,
ATOMIC_MOVE);
For more information about varargs syntax, see the section on any number of parameters.
Atomic operation
Some Files methods, such as move, can automatically perform certain operations in some file systems. An atomic file operation is an operation that cannot be interrupted or "partially" performed. Either the entire operation is performed or the operation fails. When multiple processes are running on the same area of the file system, it is very important to ensure that each process accesses a complete file.
Method chain
Many file I/O methods support the concept of method chains.
First, call a method that returns the object. Then immediately call the object's method, which will return another object, and so on. Many I/O examples use the following technologies:
String value = Charset.defaultCharset().decode(buf).toString();
UserPrincipal group = file.getFileSystem().getUserPrincipalLookupService().lookupPrincipalByName("me");
This technique produces compact code and allows you to avoid declaring unnecessary temporary variables.
What is globe?
Two methods in the Files class accept glob parameters, but what is glob?
You can use glob syntax to specify pattern matching behavior.
The glob pattern is specified as a string and matches other strings, such as a directory or file name. Glob syntax follows the following simple rules:
- The asterisk * can match any number of characters (including mismatches).
- The two asterisks * * are similar to *, but cross the directory boundary. This syntax is usually used to match the full path.
- question mark? Match only one character.
- Braces specify the collection of sub patterns. For example:
1) {sun,moon,stars} matches "sun", "Moon" or "stars".
2) {temp *, tmp *} matches all strings starting with "temp" or "tmp". - Square brackets represent a set of individual characters or, when hyphens (-) are used, a range of characters. For example:
1) [aeiou] matches any lowercase vowel.
2) [0-9] matches any number.
3) [A-Z] matches any uppercase letter.
4) [a-z, a-z] matches any uppercase or lowercase letter.
In square brackets, *? Match yourself with \. - All other characters match themselves.
- To match *? Or other special characters that can be escaped using the backslash character \. For example: \ match a single backslash,? Match question mark.
Here are some examples of glob syntax:
- *. html -- matches all html terminated string
- ??? —— A string that matches all three letters or numbers
- *[0-9] * -- match all strings containing numeric values
- *. {htm,html,pdf} - match any htm, . html or pdf terminated string
- a?*.java -- matches any that starts with a followed by at least one letter or number java terminated string
- {foo *, * [0-9] *} -- matches any string beginning with foo or any string containing numeric values
glob syntax is powerful and easy to use. However, if it doesn't meet your needs, you can also use regular expressions. For more information, see the regular expressions lesson.
For more information about glob syntax, see the API Specification for the getPathMatcher method in the FileSystem class.
Link awareness
The Files class is "link aware". Each Files method either detects what to do when a symbolic link is encountered, or provides an option that allows you to configure the behavior when a symbolic link is encountered.
Check files or directories
You have a Path instance that represents a file or directory, but does the file exist in the file system? Is it readable? Writable? Executable?
Verify that the file or directory exists
The methods in the Path class are syntactic, which means they operate on the Path instance. But eventually you have to access the file system to verify that a particular Path exists. You can use the exists(Path, LinkOption...) and notExists(Path, LinkOption...) methods to do this. Please note that! Files.exists(path) is not equivalent to files notExists(Path). When you test whether a file exists, there may be three results:
- Verify that the file exists.
- Verify that the file does not exist.
- Unknown file status. This result may occur when the program cannot access the file.
If both exists and notExists return false, the existence of the file cannot be verified.
Check file accessibility
To verify that the program can access the file as needed, you can use the isReadable(Path), isWritable(Path), and isExecutable(Path) methods.
The following code snippet verifies that a specific file exists and that the program has the ability to execute it.
Path file = ...;
boolean isRegularExecutableFile = Files.isRegularFile(file) &
Files.isReadable(file) & Files.isExecutable(file);
Check whether the two paths find the same file
When you have a file system that uses symbolic links, you can have two different paths to locate the same file. The isSameFile(Path, Path) method compares two paths to determine whether they locate the same file in the file system. For example:
Path p1 = ...;
Path p2 = ...;
if (Files.isSameFile(p1, p2)) {
// Logic when the paths locate the same file
}
Delete file or directory
You can delete files, directories, or links. For symbolic links, the link is deleted, not the target of the link. For the directory, the directory must be empty, otherwise the deletion will fail.
The Files class provides two deletion methods.
The delete(Path) method deletes the file or throws an exception when the deletion fails. For example, if the file does not exist, a NoSuchFileException is thrown. You can catch exceptions to determine the reason for the deletion failure, as follows:
try {
Files.delete(path);
} catch (NoSuchFileException x) {
System.err.format("%s: no such" + " file or directory%n", path);
} catch (DirectoryNotEmptyException x) {
System.err.format("%s not empty%n", path);
} catch (IOException x) {
// File permission problems are caught here.
System.err.println(x);
}
The deleteIfExists(Path) method also deletes the file, but does not throw an exception if the file does not exist. Silent failure is useful when you have multiple threads deleting a file and you don't want to throw an exception just because one thread deletes the file first.
Copy files or directories
You can use the copy(Path, Path, CopyOption...) method to copy a file or directory. If the target file exists, the copy fails unless replace is specified_ The existing option.
You can copy directories. However, the files in the directory are not copied, so even if the original directory contains files, the new directory is empty.
When you copy a symbolic link, the target of the link is copied. If you want to copy the link itself instead of the content of the link, specify NOFOLLOW_LINKS or replace_ The existing option.
This method accepts a variable parameter. The following StandardCopyOption and LinkOption enumerations are supported:
- REPLACE_EXISTING -- copy is performed even if the target file already exists. If the target is a symbolic link, the link itself is copied (not the target of the link). If the destination is a non empty directory, the copy fails with a DirectoryNotEmptyException exception.
- COPY_ATTRIBUTES -- copy the file attributes related to the file to the target file. The exact file attributes supported are related to the file system and platform, but cross platform supports the last modification time and copying it to the target file.
- NOFOLLOW_LINKS -- indicates that symbolic links should not be followed. If the file to be copied is a symbolic link, copy the link (not the target of the link).
If you are not familiar with enumerations, see the Enum types section.
The copy method is used as follows:
import static java.nio.file.StandardCopyOption.*; ... Files.copy(source, target, REPLACE_EXISTING);
In addition to file replication, the Files class also defines methods that can be used to replicate between Files and streams. The copy(InputStream, Path, CopyOptions...) method can be used to copy all bytes in the input stream to a file. The copy(Path, OutputStream) method can be used to copy all bytes in the file to the output stream.
Copy The example uses copy and files The walkfiletree method supports recursive replication. For more information, see the section traversing the file tree.
Move files or directories
You can use the move(Path, Path, CopyOption...) method to move files or directories. If the target file exists, the move fails unless replace is specified_ The existing option.
Empty directories can be moved. If the directory is not empty, it is allowed to move the directory without moving the contents of the directory. In UNIX systems, moving a directory to the same partition usually requires renaming the directory. In this case, this method works even when the directory contains files.
This method accepts a varargs parameter -- supports the following StandardCopyOption enumerations:
- REPLACE_EXISTING -- the move operation will be performed even if the target file already exists. If the target is a symbolic link, the symbolic link is replaced, but the object it points to is not affected.
- ATOMIC_MOVE -- performs a move operation as an atomic file operation. If the file system does not support atomic movement, an exception is thrown. Using ATOMIC_MOVE, you can move a file to a directory and ensure that any process monitoring the directory accesses a complete file.
The following shows how to use the move method:
import static java.nio.file.StandardCopyOption.*; ... Files.move(source, target, REPLACE_EXISTING);
Although you can implement the move method on a single directory, as shown above, this method is most often used with the file tree recursion mechanism. For more information, see the section traversing the file tree.
Manage metadata (file and file store properties)
Metadata is defined as "data about other data". In the file system, data is contained in files and directories, and metadata tracks the information of these objects: is it an ordinary file, a directory or a link? What is its size, creation date, last modification date, file owner, group owner, and access rights?
The metadata of a file system is often called its file attributes. The Files class contains methods that can be used to get a single property of a file or set a property.
| Methods | Comment |
|---|---|
| size(Path) | Returns the size of the specified file in bytes. |
| isDirectory(Path, LinkOption) | Returns true if the specified Path locates a file belonging to a directory. |
| isRegularFile(Path, LinkOption...) | Returns true if the specified Path locates to a normal file. |
| isSymbolicLink(Path) | Returns true if the specified Path locates to a file that is a symbolic link. |
| isHidden(Path) | Returns true if the specified Path locates a file that the file system considers hidden. |
| getLastModifiedTime(Path, LinkOption...) ,setLastModifiedTime(Path, FileTime) | Returns or sets the last modification time of the specified file. |
| getOwner(Path, LinkOption...) ,setOwner(Path, UserPrincipal) | Returns or sets the owner of the file. |
| getPosixFilePermissions(Path, LinkOption...),setPosixFilePermissions(Path, Set< PosixFilePermission >) | Returns or sets the POSIX file permissions for the file. |
| getAttribute(Path, String, LinkOption...),setAttribute(Path, String, Object, LinkOption...) | Returns or sets the value of a file property. |
If a program needs multiple file attributes at the same time, the method of retrieving a single attribute may be inefficient. Repeated access to the file system to retrieve a single attribute can adversely affect performance. For this reason, the Files class provides two readAttributes methods to obtain the attributes of Files in a batch operation.
| Method | Comment |
|---|---|
| readAttributes(Path, String, LinkOption...) | Read the attributes of the file in the form of batch operation. The String parameter identifies the property to be read. |
| readAttributes(Path, Class< A>, LinkOption...) | Read the attributes of the file in the form of batch operation. The Class parameter is the type of the requested attribute. This method returns an object of this Class. |
Before showing the example of the readAttributes method, it should be mentioned that different file systems have different concepts about which attributes should be tracked. For this reason, related file attributes are grouped into views. Views map to specific file system implementations, such as POSIX or DOS, or to public functions, such as file ownership.
The following views are supported:
- BasicFileAttributeView -- provides a view of the basic attributes that all file system implementations need to support.
- DosFileAttributeView -- uses the standard four bit extended basic attribute view supported by file systems that support DOS attributes.
- PosixFileAttributeView -- extends the basic attribute view with attributes supported on file systems that support the POSIX standard family, such as UNIX. These attributes include file owner, group owner, and 9 related access rights.
- FileOwnerAttributeView -- supported by any file system implementation that supports the concept of file owner.
- AclFileAttributeView -- supports reading or updating the access control list (ACL) of files. Support NFSv4 ACL model. Any ACL model, such as Windows ACL model, can support ACL models with well-defined NFSv4 model mapping.
- UserDefinedFileAttributeView -- supports user-defined metadata. This view can be mapped to any extension mechanism supported by the system. For example, in the Solaris Operating System, you can use this view to store the MIME type of the file.
A particular file system implementation may only support basic file attribute views, or it may support several of these file attribute views. File system implementations may support other attribute views that are not included in this API.
In most cases, you should not directly handle any FileAttributeView interface. (if you need to use FileAttributeView directly, you can access it through the getFileAttributeView(Path, Class, LinkOption...) method.)
The readAttributes method uses generics and can be used to read the attributes of any file attribute view. The examples in the rest of this page use the readAttributes method.
Basic file properties
As mentioned earlier, to read the basic properties of a file, you can use one of the files Readattributes method, which reads all basic attributes in a batch operation. This is much more efficient than accessing the file system individually to read each individual attribute. The varargs parameter currently supports LinkOption enumeration NOFOLLOW_LINKS. Use this option when you do not want to follow symbolic links.
About timestamp: the basic attribute set includes three timestamps: c reatetime, lastModifiedTime and lastAccessTime. In a particular implementation, these timestamps may not be supported, in which case the corresponding accessor method will return implementation specific values. If supported, the timestamp is returned as a FileTime object.The following code snippet reads and prints the basic file attributes of a given file and uses the methods in the BasicFileAttributes class.
Path file = ...;
BasicFileAttributes attr = Files.readAttributes(file, BasicFileAttributes.class);
System.out.println("creationTime: " + attr.creationTime());
System.out.println("lastAccessTime: " + attr.lastAccessTime());
System.out.println("lastModifiedTime: " + attr.lastModifiedTime());
System.out.println("isDirectory: " + attr.isDirectory());
System.out.println("isOther: " + attr.isOther());
System.out.println("isRegularFile: " + attr.isRegularFile());
System.out.println("isSymbolicLink: " + attr.isSymbolicLink());
System.out.println("size: " + attr.size());
In addition to the accessor method shown in this example, there is also a fileKey method, which either returns an object that uniquely identifies the file or returns null (if no file key is available).
Set timestamp
The following code snippet sets the last modification time (in milliseconds):
Path file = ...;
BasicFileAttributes attr =
Files.readAttributes(file, BasicFileAttributes.class);
long currentTime = System.currentTimeMillis();
FileTime ft = FileTime.fromMillis(currentTime);
Files.setLastModifiedTime(file, ft);
}
DOS file properties
DOS file attributes are also supported on file systems other than DOS (such as Samba). The following code snippet uses the method of the DosFileAttributes class.
Path file = ...;
try {
DosFileAttributes attr =
Files.readAttributes(file, DosFileAttributes.class);
System.out.println("isReadOnly is " + attr.isReadOnly());
System.out.println("isHidden is " + attr.isHidden());
System.out.println("isArchive is " + attr.isArchive());
System.out.println("isSystem is " + attr.isSystem());
} catch (UnsupportedOperationException x) {
System.err.println("DOS file" +
" attributes not supported:" + x);
}
However, you can use setAttribute(Path, String, Object, LinkOption...) method to set DOS attribute, as shown below:
Path file = ...; Files.setAttribute(file, "dos:hidden", true);
POSIX file permissions
POSIX is the acronym of UNIX portable operating system interface for UNIX. It is a set of IEEE and ISO standards designed to ensure interoperability between different types of UNIX. If a program complies with these POSIX standards, it should be easy to migrate to other POSIX compatible operating systems.
In addition to file owners and group owners, POSIX supports nine file permissions: read, write, and execute permissions for file owners, members of the same group, and "others".
The following code snippet reads the POSIX file attributes of a given file and prints them to standard output. The code uses the methods in the PosixFileAttributes class.
Path file = ...;
PosixFileAttributes attr =
Files.readAttributes(file, PosixFileAttributes.class);
System.out.format("%s %s %s%n",
attr.owner().getName(),
attr.group().getName(),
PosixFilePermissions.toString(attr.permissions()));
PosixFilePermissions helper class provides several useful methods, as shown below:
- The toString method used in the previous code snippet converts file permissions to a string (for example, rw-r – R --).
- The fromString method accepts a string representing file permissions and constructs a file permission set.
- The asFileAttribute method accepts a set of file permissions and constructs a file attribute that can be passed to path CreateFile or path Createdirectory method.
The following code snippet reads the attributes from a file and creates a new file, assigning the attributes of the original file to the new file:
Path sourceFile = ...;
Path newFile = ...;
PosixFileAttributes attrs =
Files.readAttributes(sourceFile, PosixFileAttributes.class);
FileAttribute<Set<PosixFilePermission>> attr =
PosixFilePermissions.asFileAttribute(attrs.permissions());
Files.createFile(file, attr);
The asFileAttribute method wraps permissions as FileAttribute. The code then attempts to create a new file with these permissions. Note that umask also applies, so the new file may be more secure than the requested permissions.
To set the permissions of a file to a value represented as a hard coded string, you can use the following code:
Path file = ...;
Set<PosixFilePermission> perms =
PosixFilePermissions.fromString("rw-------");
FileAttribute<Set<PosixFilePermission>> attr =
PosixFilePermissions.asFileAttribute(perms);
Files.setPosixFilePermissions(file, perms);
Chmod The example recursively changes the permissions of a file in a manner similar to the Chmod utility.
Set the owner of the file or group
To convert names to objects that can be stored as file owners or group owners, you can use the userprincipalookupservice service. The service looks up the name or group name as a string and returns the UserPrincipal object representing the string. You can use the file system The getuserprincipalookupservice method obtains the user principal lookup service of the default file system.
The following code snippet shows how to set the file owner using the setOwner method:
Path file = ...;
UserPrincipal owner = file.GetFileSystem().getUserPrincipalLookupService()
.lookupPrincipalByName("sally");
Files.setOwner(file, owner);
There is no special purpose method in the Files class to set the group owner. However, a safe way is through the POSIX file properties view, as shown below:
Path file = ...;
GroupPrincipal group =
file.getFileSystem().getUserPrincipalLookupService()
.lookupPrincipalByGroupName("green");
Files.getFileAttributeView(file, PosixFileAttributeView.class)
.setGroup(group);
User defined file properties
If your file system implementation does not support enough file attributes to meet your needs, you can use UserDefinedAttributeView to create and track your own file attributes.
Some implementations map this concept to features like NTFS optional data streams and extended attributes on file systems such as ext3 and ZFS. Most implementations limit the size of the value, for example, ext3 limits the size of the value to 4kb.
The MIME type of the file can be stored as user-defined attributes through the following code snippet:
Path file = ...;
UserDefinedFileAttributeView view = Files
.getFileAttributeView(file, UserDefinedFileAttributeView.class);
view.write("user.mimetype",
Charset.defaultCharset().encode("text/html");
To read MIME type properties, you can use the following code snippet:
Path file = ...; UserDefinedFileAttributeView view = Files.getFileAttributeView(file,UserDefinedFileAttributeView.class); String name = "user.mimetype"; ByteBuffer buf = ByteBuffer.allocate(view.size(name)); view.read(name, buf); buf.flip(); String value = Charset.defaultCharset().decode(buf).toString();
Xdd The example shows how to get, set, and delete user-defined properties.
Note: in Linux, you may need to enable extended attributes for user-defined attributes. If you receive an unsupported operationexception when trying to access the user-defined properties view, you need to remount the file system. The following command remounts the root partition using the extended properties of the ext3 file system. If this command is not appropriate for your Linux style, refer to the documentation.$ sudo mount -o remount,user_xattr /
If you want the changes to take effect permanently, add an entry in / etc/fstab.
File storage properties
You can use the FileStore class to learn about file storage, such as the amount of free space. getFileStore(Path) method gets the file store of the specified file.
The following code snippet prints the usage of the file storage space where a specific file is located:
Path file = ...; FileStore store = Files.getFileStore(file); long total = store.getTotalSpace() / 1024; long used = (store.getTotalSpace() - store.getUnallocatedSpace()) / 1024; long avail = store.getUsableSpace() / 1024;
DiskUsage The example uses this API to print all the disk space information stored in the default file system. This example uses the getFileStores method in the FileSystem class to get all the file stores of the FileSystem.
Read, write, and create files
This page discusses the details of reading, writing, creating, and opening files. There are a large number of file I/O methods to choose from. In order to better understand this API, the following figure arranges the file I/O methods according to complexity.

At the far left of the figure are the utility methods readAllBytes, readAllLines and write, which are designed for simple and common situations. To their right are methods for iterating over text streams or lines, such as newBufferedReader, newBufferedWriter, and then newInputStream and newOutputStream. These methods can be used with Java IO package interoperability. On their right are methods that handle ByteChannels, SeekableByteChannels, and ByteBuffers, such as the newByteChannel method. Finally, on the far right is the method of using FileChannel for advanced applications that require file locking or memory mapped I/O.
OpenOptions parameter
Several methods in this section take an optional OpenOptions parameter. This parameter is optional. The API tells you what the default behavior of the method is when it is not specified.
The following StandardOpenOptions enumerations are supported:
- WRITE -- open the file for WRITE access.
- APPEND -- APPEND new data to the end of the file. This option is used in conjunction with the WRITE or CREATE options.
- TRUNCATE_EXISTING -- truncates the file to zero bytes. This option is used in conjunction with the WRITE option.
- CREATE_NEW -- create a new file, and throw an exception if the file already exists.
- CREATE - if the file exists, open it; If not, CREATE a new file.
- DELETE_ON_CLOSE -- deletes the file when the stream is closed. This option is useful for temporary files.
- SPARSE -- indicates that a newly created file is SPARSE. This advanced option can be used on some file systems, such as NTFS, where large files with data "gaps" can be stored in a more efficient manner without taking up disk space.
- SYNC - keep files (content and metadata) synchronized with the underlying storage device.
- DSYNC -- keep the file content synchronized with the underlying storage device.
Common methods of small files
Read all bytes or lines in the file
If you have a small file and want to read all its contents at once, you can use the readAllBytes(Path) or readAllLines(Path, Charset) methods. These methods handle most of the work for you, such as opening and closing streams, but are not intended to deal with large files. The following code shows how to use the readAllBytes method:
Path file = ...; byte[] fileArray; fileArray = Files.readAllBytes(file);
Writes all bytes or lines to the file
You can use one of these write methods to write bytes or lines to a file.
- write(Path, byte[], OpenOption...)
- write(Path, Iterable< extends CharSequence>, Charset, OpenOption...)
The following code snippet shows how to use the write method.
Path file = ...; byte[] buf = ...; Files.write(file, buf);
Buffering I/O method of text file
java. nio. It can bypass the bottleneck of some I/O packets in the I/O layer, which may lead to the movement of data packets in the I/O layer.
Read files using buffered stream I/O
The newBufferedReader(Path, Charset) method opens a file for reading and returns a BufferedReader. This method can be used to read text from the file in an effective way.
The following code snippet shows how to use the newBufferedReader method to read data from a file. The file is encoded in "US-ASCII".
Charset charset = Charset.forName("US-ASCII");
try (BufferedReader reader = Files.newBufferedReader(file, charset)) {
String line = null;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} catch (IOException x) {
System.err.format("IOException: %s%n", x);
}
Write files using buffered stream I/O
You can use the newBufferedWriter(Path, Charset, OpenOption...) method to write files using BufferedWriter.
The following code snippet shows how to use this method to create a file encoded in "US-ASCII":
Charset charset = Charset.forName("US-ASCII");
String s = ...;
try (BufferedWriter writer = Files.newBufferedWriter(file, charset)) {
writer.write(s, 0, s.length());
} catch (IOException x) {
System.err.format("IOException: %s%n", x);
}
Unbuffered stream and Java Methods of ioapi interoperability
Read files using streaming I/O
To open a file for reading, you can use the newInputStream(Path, OpenOption...) method. This method returns an unbuffered input stream for reading bytes from a file.
Path file = ...;
try (InputStream in = Files.newInputStream(file);
BufferedReader reader =
new BufferedReader(new InputStreamReader(in))) {
String line = null;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} catch (IOException x) {
System.err.println(x);
}
Create and write files using streaming I/O
You can use the newOutputStream(Path, OpenOption...) method to create, append, or write files. This method opens or creates a file for writing bytes and returns an unbuffered output stream.
This method accepts an optional OpenOption parameter. If no open option is specified and the file does not exist, a new file is created. If the file exists, it will be truncated. This option is equivalent to using CREATE and truncate_ The existing option calls the method.
The following example opens a log file. If the file does not exist, create it. If the file exists, open to append.
import static java.nio.file.StandardOpenOption.*;
import java.nio.file.*;
import java.io.*;
public class LogFileTest {
public static void main(String[] args) {
// Convert the string to a
// byte array.
String s = "Hello World! ";
byte data[] = s.getBytes();
Path p = Paths.get("./logfile.txt");
try (OutputStream out = new BufferedOutputStream(
Files.newOutputStream(p, CREATE, APPEND))) {
out.write(data, 0, data.length);
} catch (IOException x) {
System.err.println(x);
}
}
}
Methods of channel and ByteBuffers
Read and write files using channel I/O
When stream I/O reads one character at a time, channel I/O reads one buffer at a time. The ByteChannel interface provides basic read and write functions. SeekableByteChannel is a ByteChannel, which has the ability to maintain and change a position in the channel. SeekableByteChannel also supports truncating files associated with channels and querying the size of files.
This makes it possible to read the file to a different location and then move it to a different location. For more information, see the random access file section.
There are two ways to read and write channel I/O.
- newByteChannel(Path, OpenOption...)
- newByteChannel(Path, Set<? extends OpenOption>, FileAttribute<?>...)
Both newByteChannel methods allow you to specify a list of OpenOption options. In addition to another option, the same open option used by the newOutputStream method is supported: READ is required because seekablebytecnel supports READ and write.
Specify READ to open the READ channel. Specifying WRITE or APPEND opens the WRITE channel. If these options are not specified, the channel is opened for reading.
The following code snippet reads a file and prints it to standard output:
public static void readFile(Path path) throws IOException {
// Files.newByteChannel() defaults to StandardOpenOption.READ
try (SeekableByteChannel sbc = Files.newByteChannel(path)) {
final int BUFFER_CAPACITY = 10;
ByteBuffer buf = ByteBuffer.allocate(BUFFER_CAPACITY);
// Read the bytes with the proper encoding for this platform. If
// you skip this step, you might see foreign or illegible
// characters.
String encoding = System.getProperty("file.encoding");
while (sbc.read(buf) > 0) {
buf.flip();
System.out.print(Charset.forName(encoding).decode(buf));
buf.clear();
}
}
}
The following example, written for UNIX and other POSIX file systems, creates a log file with a specific set of file permissions. This code creates a log file and appends it to the log file if it already exists. When creating log files, the owner has read-write permission and the group has read-only permission.
import static java.nio.file.StandardOpenOption.*;
import java.nio.*;
import java.nio.channels.*;
import java.nio.file.*;
import java.nio.file.attribute.*;
import java.io.*;
import java.util.*;
public class LogFilePermissionsTest {
public static void main(String[] args) {
// Create the set of options for appending to the file.
Set<OpenOption> options = new HashSet<OpenOption>();
options.add(APPEND);
options.add(CREATE);
// Create the custom permissions attribute.
Set<PosixFilePermission> perms =
PosixFilePermissions.fromString("rw-r-----");
FileAttribute<Set<PosixFilePermission>> attr =
PosixFilePermissions.asFileAttribute(perms);
// Convert the string to a ByteBuffer.
String s = "Hello World! ";
byte data[] = s.getBytes();
ByteBuffer bb = ByteBuffer.wrap(data);
Path file = Paths.get("./permissions.log");
try (SeekableByteChannel sbc =
Files.newByteChannel(file, options, attr)) {
sbc.write(bb);
} catch (IOException x) {
System.out.println("Exception thrown: " + x);
}
}
}
Methods of creating regular and temporary files
create a file
You can use the createFile (path, fileattribute <? >) method to create an empty file with an initial attribute set. For example, if you want a file to have a specific set of file permissions when you create it, you can use the createFile method to do this. If no attributes are specified, the file is created using the default attributes. If the file already exists, createFile throws an exception.
In a single atomic operation, the createFile method checks whether the file exists and creates the file with the specified attributes, which makes the process safer from malicious code.
The following code snippet creates a file with default properties:
Path file = ...;
try {
// Create the empty file with default permissions, etc.
Files.createFile(file);
} catch (FileAlreadyExistsException x) {
System.err.format("file named %s" +
" already exists%n", file);
} catch (IOException x) {
// Some other sort of failure, such as permissions.
System.err.format("createFile error: %s%n", x);
}
An example of POSIX file permissions is to create a file with preset permissions using CreateFile (path, fileattribute <? >).
You can also create a new file using the newOutputStream method, as described in creating and writing files using stream I/O. If you open a new output stream and close it immediately, an empty file is created.
Create temporary file
You can use the following createTempFile method to create a temporary file:
- createTempFile(Path, String, String, FileAttribute<?>)
- createTempFile(String, String, FileAttribute<?>)
The first method allows the code to specify a directory for temporary files, and the second method creates a new file in the default temporary file directory. Both methods allow you to specify a suffix for the file name, and the first method also allows you to specify a prefix. The following code snippet shows an example of the second method:
try {
Path tempFile = Files.createTempFile(null, ".myapp");
System.out.format("The temporary file" +
" has been created: %s%n", tempFile)
;
} catch (IOException x) {
System.err.format("IOException: %s%n", x);
}
The result of running this file is as follows:
The temporary file has been created: /tmp/509668702974537184.myapp
The specific format of the temporary file name is platform specific.
Random access file
Random access to files allows unordered or random access to file contents. To access a file randomly, you need to open the file, find a specific location, and read and write the file.
This function can be realized through SeekableByteChannel interface. The SeekableByteChannel interface extends channel I/O with the concept of current location. Method enables you to set or query a location from which you can then read or write data. The API consists of some easy-to-use methods:
- Position -- returns the current position of the channel
- position(long) -- sets the position of the channel
- read(ByteBuffer) -- reads bytes from the channel to the buffer
- write(ByteBuffer) -- writes bytes from the buffer to the channel
- truncate(long) -- truncate the files (or other entities) connected to the channel
When I/O channels are used to read and write files, path. Is displayed The newbytechannel method returns an instance of SeekableByteChannel. On the default file system, you can directly use the channel, or you can convert it to FileChannel, which allows you to access more advanced features, such as mapping an area of a file directly to memory for faster access, locking an area of a file, or reading and writing bytes from an absolute location without affecting the current location of the channel.
The following code snippet opens a file for reading and writing by using one of the newbytecnel methods. The returned seekablebytecnel is converted to FileChannel. Then, read 12 bytes from the beginning of the file and write the string "I was here!" at that position. Move the current position in the file to the end and append 12 bytes from the beginning. Finally, the string "I was here!" Is appended and the channel in the file is closed.
String s = "I was here!\n";
byte data[] = s.getBytes();
ByteBuffer out = ByteBuffer.wrap(data);
ByteBuffer copy = ByteBuffer.allocate(12);
try (FileChannel fc = (FileChannel.open(file, READ, WRITE))) {
// Read the first 12
// bytes of the file.
int nread;
do {
nread = fc.read(copy);
} while (nread != -1 && copy.hasRemaining());
// Write "I was here!" at the beginning of the file.
fc.position(0);
while (out.hasRemaining())
fc.write(out);
out.rewind();
// Move to the end of the file. Copy the first 12 bytes to
// the end of the file. Then write "I was here!" again.
long length = fc.size();
fc.position(length-1);
copy.flip();
while (copy.hasRemaining())
fc.write(copy);
while (out.hasRemaining())
fc.write(out);
} catch (IOException x) {
System.out.println("I/O Exception: " + x);
}
Create and read directories
Some of the methods discussed earlier, such as deletion, deal with files, links and directories. But how do I list all the directories at the top of the file system? How do I list the contents of a directory or create a directory?
Lists the root directory of the file system
File system The getrootdirectories method can list all root directories of the file system. This method returns an iteratable that enables you to traverse all root directories using the enhanced for statement.
The following code snippet prints the root directory of the default file system:
Iterable<Path> dirs = FileSystems.getDefault().getRootDirectories();
for (Path name: dirs) {
System.err.println(name);
}
Create directory
You can use the createdirectory (path, fileattribute <? >) method to create a new directory. If you do not specify any FileAttributes, the new directory will have default attributes. For example:
Path dir = ...; Files.createDirectory(path);
The following code snippet creates a new directory with specific permissions on the POSIX file system:
Set<PosixFilePermission> perms =
PosixFilePermissions.fromString("rwxr-x---");
FileAttribute<Set<PosixFilePermission>> attr =
PosixFilePermissions.asFileAttribute(perms);
Files.createDirectory(file, attr);
When one or more parent directories may not exist yet, to create multi-level directories, you can use the convenient method createdirectories (path, fileattribute <? >). Like the createdirectory (path, fileattribute <? >) method, you can specify a set of optional initial file attributes. The following code snippet uses the default attributes:
Files.createDirectories(Paths.get("foo/bar/test"));
Create directories from top to bottom as needed. In the example of foo/bar/test, if the foo directory does not exist, it will be created. Next, create the bar directory (if necessary), and finally, create the test directory.
This method may fail after creating some (but not all) parent directories.
Create temporary directory
You can use the createTempDirectory method to create a temporary directory:
- createTempDirectory(Path, String, FileAttribute<?>...)
- createTempDirectory(String, FileAttribute<?>...)
The first method allows the code to specify a location for the temporary directory, and the second method creates a new directory in the default temporary file directory.
Lists the contents of the directory
You can use the newDirectoryStream(Path) method to list all the contents of the directory. This method returns an object that implements the DirectoryStream interface. The class that implements the DirectoryStream interface also implements Iterable, so you can traverse the directory stream and read all objects. This method can be well extended to very large directories.
Remember: the DirectoryStream returned is a stream. If you don't use the try with resources statement, don't forget to close the flow in the finally block. The try with resources statement will handle this problem for you.The following code snippet shows how to print the contents of a directory:
Path dir = ...;
try (DirectoryStream<Path> stream = Files.newDirectoryStream(dir)) {
for (Path file: stream) {
System.out.println(file.getFileName());
}
} catch (IOException | DirectoryIteratorException x) {
// IOException can never be thrown by the iteration.
// In this snippet, it can only be thrown by newDirectoryStream.
System.err.println(x);
}
The Path object returned by the iterator is the name of the entry resolved according to the directory. Therefore, if you list the contents of the / tmp directory, the entries will be returned in the form of / tmp/a, / tmp/b, and so on.
This method returns the entire contents of a directory: files, links, subdirectories, and hidden files. If you want to make a more selective selection of the retrieved content, you can use one of the other newDirectoryStream methods, as described later on this page.
Note that if an exception occurs during directory iteration, a DirectoryIteratorException exception will be thrown, with IOException as the reason. Iterator methods cannot throw exceptions.
Filtering directory lists using Globbing
If you only want to get files and subdirectories whose names match a specific pattern, you can use the newDirectoryStream(Path, String) method, which provides a built-in glob filter. If you are not familiar with glob syntax, see what is glob?
For example, the following code snippet lists Java related files: class,. Java and jar file:
Path dir = ...;
try (DirectoryStream<Path> stream =
Files.newDirectoryStream(dir, "*.{java,class,jar}")) {
for (Path entry: stream) {
System.out.println(entry.getFileName());
}
} catch (IOException x) {
// IOException can never be thrown by the iteration.
// In this snippet, it can // only be thrown by newDirectoryStream.
System.err.println(x);
}
Write your own catalog filter
Maybe you want to filter the contents of the directory based on some criteria other than pattern matching. You can create your own filter by implementing directorystream Filter < T > interface. This interface consists of a method accept, which determines whether a file meets the search requirements.
For example, the following code snippet implements a filter that only retrieves directories:
DirectoryStream.Filter<Path> filter =
newDirectoryStream.Filter<Path>() {
public boolean accept(Path file) throws IOException {
try {
return (Files.isDirectory(path));
} catch (IOException x) {
// Failed to determine if it's a directory.
System.err.println(x);
return false;
}
}
};
Once the filter is created, you can use the newdirectorystream (path, directorystream. Filter <? Super Path >) method. The following code snippet uses the isDirectory filter to output only subdirectories of the directory to standard output:
Path dir = ...;
try (DirectoryStream<Path>
stream = Files.newDirectoryStream(dir, filter)) {
for (Path entry: stream) {
System.out.println(entry.getFileName());
}
} catch (IOException x) {
System.err.println(x);
}
This method is only used to filter a single directory. However, if you want to find all subdirectories in the file tree, you can use the mechanism of traversing the file tree.
Links, symbols or other
As mentioned earlier, Java nio. The file package, especially the Path class, is "link aware". Each Path method either detects what to do when a symbolic link is encountered, or provides an option that allows you to configure the behavior when a symbolic link is encountered.
So far, the discussion has been about symbolic links or soft links, but some file systems also support hard links. Hard links are more restrictive than symbolic links, as follows:
- The target of the link must exist.
- Hard links are usually not allowed on directories.
- Hard links are not allowed across partitions or volumes.: Therefore, they cannot exist across file systems.
- Hard links look and behave like regular files, so it's hard to find them.
- For any purpose, a hard link is the same entity as the original file. They have the same file permissions, timestamps, and so on. All properties are the same.
Due to these limitations, hard links are not used as often as symbolic links, but the Path method works seamlessly with hard links.
There are several ways to deal specifically with links, which are described in the following sections:
Create symbolic links
If your file system supports it, you can use the createsymboliclink (Path, Path, fileattribute <? >) method to create a symbolic link. The second Path parameter represents the target file or directory, which may or may not exist. The following code snippet creates a symbolic link with default permissions:
Path newLink = ...;
Path target = ...;
try {
Files.createSymbolicLink(newLink, target);
} catch (IOException x) {
System.err.println(x);
} catch (UnsupportedOperationException x) {
// Some file systems do not support symbolic links.
System.err.println(x);
}
The FileAttributes variable parameter allows you to specify the initial file attributes that are automatically set when the link is created. However, this parameter is for future use and has not been implemented yet.
Create hard link
You can use the createLink(Path, Path) method to create a hard link (or regular link) to an existing file. The second Path parameter locates the existing file. It must exist, otherwise NoSuchFileException will be thrown. The following code snippet shows how to create a link:
Path newLink = ...;
Path existingFile = ...;
try {
Files.createLink(newLink, existingFile);
} catch (IOException x) {
System.err.println(x);
} catch (UnsupportedOperationException x) {
// Some file systems do not
// support adding an existing
// file to a directory.
System.err.println(x);
}
Detect symbolic link
To determine whether a Path instance is a symbolic link, you can use the isSymbolicLink(Path) method. The following code snippet shows how to do this:
Path file = ...; boolean isSymbolicLink = Files.isSymbolicLink(file);
For more information, see managing metadata.
Find the target of the link
You can obtain the target of the symbolic link through the readsymbolic link (path) method, as shown below:
Path link = ...;
try {
System.out.format("Target of link" +
" '%s' is '%s'%n", link,
Files.readSymbolicLink(link));
} catch (IOException x) {
System.err.println(x);
}
If Path is not a symbolic link, this method throws a NotLinkException.
Traversing the file tree
Do you need to create an application that will recursively access all files in the file tree? Maybe you need to delete each in the tree Each file found or not accessed by class last year. You can do this using the FileVisitor interface.
FileVisitor interface
To traverse the file tree, you first need to implement a FileVisitor. FileVisitor specifies the necessary behaviors of key points in the traversal process: when the file is accessed, before the directory is accessed, after the directory is accessed, and when the directory fails to be accessed. The interface has four methods corresponding to these situations:
- preVisitDirectory -- calls before accessing directory entries.
- postVisitDirectory -- calls after accessing all entries in the directory. If any errors are encountered, a specific exception is passed to the method.
- visitFile -- called on the accessed file. The file's BasicFileAttributes are passed to this method, or you can use the file attribute package to read a specific set of attributes. For example, you can choose to read the DosFileAttributeView of the file to determine whether the file has the "hidden" bit set.
- visitFileFailed -- called when the file cannot be accessed. A specific exception is passed to the method. You can choose whether to throw an exception, print it to the console or log file, and so on.
If you do not need to implement all four FileVisitor methods, you can extend the SimpleFileVisitor class instead of implementing the FileVisitor interface. This class implements the FileVisitor interface, which accesses all files in the tree and throws an IOError when an error is encountered. You can extend this class and override only the methods you need.
The following is an example of extending SimpleFileVisitor to print all entries in the file tree. Whether the entry is a normal file, symbolic link, directory, or other "unspecified" type of file, it prints the entry. It also prints the size (in bytes) of each file. Any exceptions encountered are printed to the console.
The FileVisitor method is shown in bold:
import static java.nio.file.FileVisitResult.*;
public static class PrintFiles
extends SimpleFileVisitor<Path> {
// Print information about
// each type of file.
@Override
public FileVisitResult visitFile(Path file,
BasicFileAttributes attr) {
if (attr.isSymbolicLink()) {
System.out.format("Symbolic link: %s ", file);
} else if (attr.isRegularFile()) {
System.out.format("Regular file: %s ", file);
} else {
System.out.format("Other: %s ", file);
}
System.out.println("(" + attr.size() + "bytes)");
return CONTINUE;
}
// Print each directory visited.
@Override
public FileVisitResult postVisitDirectory(Path dir,
IOException exc) {
System.out.format("Directory: %s%n", dir);
return CONTINUE;
}
// If there is some error accessing
// the file, let the user know.
// If you don't override this method
// and an error occurs, an IOException
// is thrown.
@Override
public FileVisitResult visitFileFailed(Path file,
IOException exc) {
System.err.println(exc);
return CONTINUE;
}
}
Start process
Once FileVisitor is implemented, how to start file traversal? There are two walkFileTree methods in the Files class.
- walkFileTree(Path, FileVisitor)
- walkFileTree(Path, Set< FileVisitOption>, int, FileVisitor)
The first method requires only a starting point and a FileVisitor instance. You can call the PrintFiles file accessor as follows:
Path startingDir = ...; PrintFiles pf = new PrintFiles(); Files.walkFileTree(startingDir, pf);
The second walkFileTree method allows you to specify additional limits on the number of access levels and a set of FileVisitOption enumerations. If you want to ensure that this method traverses the entire file tree, you can specify Integer. MAX_VALUE is the maximum depth parameter.
You can specify FileVisitOption enum, FOLLOW_LINKS, which indicates that symbolic links should be followed.
The following code snippet shows how to call a method with four parameters:
import static java.nio.file.FileVisitResult.*; Path startingDir = ...; EnumSet<FileVisitOption> opts = EnumSet.of(FOLLOW_LINKS); Finder finder = new Finder(pattern); Files.walkFileTree(startingDir, opts, Integer.MAX_VALUE, finder);
Considerations when creating FileVisitor
Traverse the depth of the file tree first, but you can't make any assumptions about the iterative order of accessing subdirectories.
If your program will change the file system, you need to carefully consider how to implement FileVisitor.
For example, if you want to write recursive deletion, first delete the files in the directory, and then delete the directory itself. In this case, delete the directory in the postVisitDirectory.
If you are writing a recursive copy, you need to create a new directory in preVisitDirectory before attempting to copy the file to it (in visitFiles). If you want to keep the attributes of the source directory (similar to the UNIX cp -p command), you need to do so in the postVisitDirectory after the file is copied. Copy The example shows how to do this.
If you are writing a file search, you can perform a comparison in the visitFile method. This method finds all files that meet your criteria, but does not find directories. If you want to find both files and directories, you must also perform a comparison in the preVisitDirectory or postVisitDirectory methods. Find The example demonstrates how to do this.
You need to decide whether you want to follow symbolic links. For example, if you are deleting files, symbolic links may not be recommended. If you are copying a file tree, you may want to allow this. By default, walkFileTree does not follow symbolic links.
Call the visitFile method on the file. If you have specified FOLLOW_LINKS option, and your file tree has a circular link to the parent directory, then this circular directory will be reported in the visitFileFailed method using FileSystemLoopException. The following code snippet shows how to capture circular links from Copy Examples:
@Override
public FileVisitResult
visitFileFailed(Path file,
IOException exc) {
if (exc instanceof FileSystemLoopException) {
System.err.println("cycle detected: " + file);
} else {
System.err.format("Unable to copy:" + " %s: %s%n", file, exc);
}
return CONTINUE;
}
This happens only if the program follows symbolic links.
Control flow
Maybe you want to traverse the file tree to find a specific directory, and then you want to terminate the process. Maybe you want to skip a specific directory.
The FileVisitor method returns a FileVisitResult value. You can stop the file traversal process, or control whether a directory is accessed by the value you return in the FileVisitor method:
- CONTINUE -- indicates that file traversal should CONTINUE. If the preVisitDirectory method returns CONTINUE, the directory is accessed.
- TERMINATE -- immediately TERMINATE file traversal. After this value is returned, no file traversal method will be called.
- SKIP_SUBTREE -- when preVisitDirectory returns this value, the specified directory and its subdirectories will be skipped. The branch was cut off from the tree.
- SKIP_SIBLINGS -- when preVisitDirectory returns this value, the specified directory will not be accessed, postVisitDirectory will not be called, and other unreachable peer directories will not be accessed. If returned from the postVisitDirectory method, no other sibling directories will be accessed. Essentially, nothing further will happen in the specified directory.
In this code, any directory named SCCS will be skipped:
import static java.nio.file.FileVisitResult.*;
public FileVisitResult
preVisitDirectory(Path dir,
BasicFileAttributes attrs) {
(if (dir.getFileName().toString().equals("SCCS")) {
return SKIP_SUBTREE;
}
return CONTINUE;
}
In this code, as long as a specific file is found, the name of the file will be printed to the standard output, and the traversal of the file ends:
import static java.nio.file.FileVisitResult.*;
// The file we are looking for.
Path lookingFor = ...;
public FileVisitResult
visitFile(Path file,
BasicFileAttributes attr) {
if (file.getFileName().equals(lookingFor)) {
System.out.println("Located file: " + file);
return TERMINATE;
}
return CONTINUE;
}
example
The following example demonstrates the file traversal mechanism:
- Find ——Recursive file trees look for files and directories that match a particular glob pattern. This example will be discussed in the find file.
- Chmod ——Recursively change the permissions of the file tree (POSIX systems only).
- Copy ——Recursively copy the file tree.
- WatchDir ——Demonstrates the mechanism for monitoring files created, deleted, or modified in a directory. Call this program with the - r option to observe the changes of the whole tree. For more information about the file notification service, see the chapter monitoring directory changes.
Find file
If you've ever used shell scripts, you've probably used pattern matching to locate files. In fact, you may have used it extensively. If you haven't used it yet, pattern matching creates a pattern with special characters, and then you can compare the file name with the pattern. For example, in most shell scripts, the asterisk * matches any number of characters. For example, the following command lists all in the current directory html ending file:
% ls *.html
java. nio. The file package provides programming support for this useful feature. Each file system implementation provides a PathMatcher. You can use the getPathMatcher(String) method in the file system class to retrieve the PathMatcher of the file system. The following code snippet gets the path matcher for the default file system:
String pattern = ...;
PathMatcher matcher =
FileSystems.getDefault().getPathMatcher("glob:" + pattern);
The string parameter passed to getPathMatcher specifies the syntax style and pattern to match. This example specifies the glob syntax. If you are not familiar with glob syntax, please refer to what is glob.
The Glob syntax is easy to use and flexible, but you can also use regular expressions or regex syntax if you like. For more information about regular expressions, see the regular expressions chapter. Some file system implementations may support other syntax.
If you want to use other forms of string based pattern matching, you can create your own PathMatcher class. The examples on this page use glob syntax.
Once the PathMatcher instance is created, you can match files based on it. The PathMatcher interface has a separate method, matches, which takes a Path parameter and returns a Boolean value: it either matches the pattern or does not match. The following code snippet looks for java or class and print these files to standard output:
PathMatcher matcher =
FileSystems.getDefault().getPathMatcher("glob:*.{java,class}");
Path filename = ...;
if (matcher.matches(filename)) {
System.out.println(filename);
}
Recursive pattern matching
Searching for files that match a particular pattern is closely related to traversing the file tree. How many times do you know that the file is somewhere in the file system, but where? Alternatively, you may need to find all files with a specific file extension in the file tree.
Find The example does exactly that. Find is similar to the UNIX Find utility, but with reduced functionality. You can extend this example to include additional features. For example, the find utility supports the - prune flag to exclude the entire subtree from the search. You can return skip in the preVisitDirectory method_ Subtree to achieve this function. To implement the - L option after the symbolic link, you can use the walkFileTree method with four parameters and pass in FOLLOW_LINKS enumeration (but make sure to test the circular link in the visitFile method).
Run the discovery application in the following format:
% java Find <path> -name "<glob_pattern>"
The pattern is enclosed in quotation marks, so any wildcards are not interpreted by the shell. For example:
% java Find . -name "*.html"
Here is the source code to find the example:
import java.io.*;
import java.nio.file.*;
import java.nio.file.attribute.*;
import static java.nio.file.FileVisitResult.*;
import static java.nio.file.FileVisitOption.*;
import java.util.*;
public class Find {
public static class Finder
extends SimpleFileVisitor<Path> {
private final PathMatcher matcher;
private int numMatches = 0;
Finder(String pattern) {
matcher = FileSystems.getDefault()
.getPathMatcher("glob:" + pattern);
}
// Compares the glob pattern against
// the file or directory name.
void find(Path file) {
Path name = file.getFileName();
if (name != null && matcher.matches(name)) {
numMatches++;
System.out.println(file);
}
}
// Prints the total number of
// matches to standard out.
void done() {
System.out.println("Matched: "
+ numMatches);
}
// Invoke the pattern matching
// method on each file.
@Override
public FileVisitResult visitFile(Path file,
BasicFileAttributes attrs) {
find(file);
return CONTINUE;
}
// Invoke the pattern matching
// method on each directory.
@Override
public FileVisitResult preVisitDirectory(Path dir,
BasicFileAttributes attrs) {
find(dir);
return CONTINUE;
}
@Override
public FileVisitResult visitFileFailed(Path file,
IOException exc) {
System.err.println(exc);
return CONTINUE;
}
}
static void usage() {
System.err.println("java Find <path>" +
" -name \"<glob_pattern>\"");
System.exit(-1);
}
public static void main(String[] args)
throws IOException {
if (args.length < 3 || !args[1].equals("-name"))
usage();
Path startingDir = Paths.get(args[0]);
String pattern = args[2];
Finder finder = new Finder(pattern);
Files.walkFileTree(startingDir, finder);
finder.done();
}
}
Recursively traversing the file tree will be introduced in traversing the file tree.
Observe changes in the catalog
Have you ever found that when you edit a file using the IDE or other editors, a dialog box appears informing you that an open file has changed on the file system and needs to be reloaded? Or, like the NetBeans IDE, the application just quietly updates the file without notifying you. The following example dialog box shows how this notification looks under the free editor jdit:
To implement this function, called file change notification, the program must be able to detect what happened to the relevant directories on the file system. One method is to poll the file system for changes, but this method is inefficient. It cannot be extended to applications with hundreds of open files or directories to monitor.
java. nio. The file package provides a file change notification API called the Watch Service API. This API allows you to register one (or more) directories with the monitoring service. When registering, you tell the service the type of event you are interested in: file creation, deletion or modification. When the service detects an event of interest, it is forwarded to the registered process. A registered process has a thread (or thread pool) that monitors any events it has registered. When an event is passed in, it will be processed as needed.
See service overview
The WatchService API is fairly low-level and allows you to customize it. You can use it as is, or you can choose to create an advanced API on top of this mechanism so that it suits your specific needs. The following are the basic steps required to realize the watch service:
- Create a WatchService monitor for the file system.
- For each directory you want to monitor, register it with the monitor. When registering a directory, you can specify the type of event to be notified. You will receive a WatchKey instance for each directory you register.
- Implement an infinite loop to wait for incoming events. When an event occurs, the key signals and is placed in the monitor's queue.
- Retrieve the key from the monitor's queue. You can get the file name from the key.
- Retrieve each pending event (possibly multiple events) for the key and process it as needed.
- Reset key and resume waiting events.
- Shut down the service: monitor the service to exit when the thread exits or when the thread closes (by calling the method it closes).
WatchKeys is thread safe and can work with Java nio. Use with concurrent package. You can specify a thread pool for this job.
Try it
Because this API is more advanced, try it out before continuing. take WatchDir Save the sample to your computer and compile it. Create a test directory that will be passed to the sample. WatchDir uses one thread to handle all events, so it blocks keyboard input while waiting for events. You can run the program in a separate window or in the background, as shown below:
java WatchDir test &
Create, delete, and edit files in the test directory. When these events occur, a message will be printed to the console. When finished, delete the test directory and exit WatchDir. Alternatively, you can manually terminate the process if you wish.
You can also monitor the entire file tree by specifying the - r option. When - r is specified, WatchDir traverses the file tree and registers each directory with the monitoring service.
Create a monitoring service and register events
The first step is to create a new WatchService by using the newWatchService method in the FileSystem class, as shown below:
WatchService watcher = FileSystems.getDefault().newWatchService();
Next, register one or more objects with the monitoring service. Any object that implements the Watchable interface can be registered. The ath class implements the Watchable interface, so every directory to be monitored is registered as a Path object.
Like any Watchable, the Path class implements two register methods. This page uses a two parameter version, register (watchservice, watchevent. Kind <? >...). (the version composed of three parameters accepts a WatchEvent.Modifier, which has not been implemented yet.)
When registering objects with the monitoring service, you can specify the type of event to monitor. The supported standardwatcheventtypes are as follows:
- ENTRY_CREATE -- create a directory entry.
- ENTRY_DELETE -- deletes the directory entry.
- ENTRY_MODIFY -- modify the directory entry.
- OVERFLOW -- indicates that the event may have been lost or discarded. You do not have to register the OVERFLOW event to receive it.
The following code snippet shows how to register a Path instance for these three event types:
import static java.nio.file.StandardWatchEventKinds.*;
Path dir = ...;
try {
WatchKey key = dir.register(watcher,
ENTRY_CREATE,
ENTRY_DELETE,
ENTRY_MODIFY);
} catch (IOException x) {
System.err.println(x);
}
Handling events
The sequence of events in the event processing cycle is as follows:
- Get the watch key. Three methods are provided:
1) poll -- returns a queued key if available. If not available, a null value is returned immediately.
2) poll(long, TimeUnit) -- returns a queued key if one is available. If a queued key is not immediately available, the program will wait until the specified time. The TimeUnit parameter determines whether the specified time is in nanoseconds, milliseconds, or other time units.
3) take -- returns a queued key. If no queue key is available, this method waits. - Handle pending events for key: Get the watchevents list from the pollEvents method.
- Use the kind method to retrieve the type of event. No matter what event the key registers, it may receive OVERFLOW event. You can choose to handle the OVERFLOW or ignore it, but you should test it.
- Retrieves the file name associated with the event. The file name is stored as the context of the event, so the context method is used to retrieve it.
- After handling the key event, you need to put the key back into the ready state by calling reset. If this method returns false, the key is no longer valid and the loop can exit. This step is very important. If the call to reset fails, this key will not receive any further events.
The watch key has a state. At any given time, its state may be one of the following states:
- Ready indicates that the key is ready to accept events. When first created, the key is ready.
- Signaled indicates that one or more events have been queued. Once the key is signaled, it is no longer ready until the reset method is called.
- Invalid indicates that the key is no longer active. This state occurs when one of the following events occurs:
1) The process explicitly cancels the key by using the cancel method.
2) The directory becomes inaccessible.
3) Watch service is off.
The following is an example of an event processing loop. It comes from Email Example, which monitors a directory and waits for new files to appear. When a new file is available, it is checked using the probecontent type (path) method to determine whether it is a text/plain file. The purpose of this is to email the text/plain file to an alias, but the implementation details are left to the reader.
Methods specific to the watch service API are shown in bold:
for (;;) {
// Wait for the key to signal
WatchKey key;
try {
key = watcher.take();
} catch (InterruptedException x) {
return;
}
for (WatchEvent<?> event: key.pollEvents()) {
WatchEvent.Kind<?> kind = event.kind();
// This key is only available in entry_ Register in the create event,
// However, the OVERFLOW event can occur regardless of whether the event is lost or discarded.
if (kind == OVERFLOW) {
continue;
}
// The file name is the context of the event.
WatchEvent<Path> ev = (WatchEvent<Path>)event;
Path filename = ev.context();
// Verify that the new file is a text file.
try {
// Resolve the file name according to the directory.
// If the file name is "test" and the directory is "foo",
// The resolved name is "test/foo".
Path child = dir.resolve(filename);
if (!Files.probeContentType(child).equals("text/plain")) {
System.err.format("New file '%s'" +
" is not a plain text file.%n", filename);
continue;
}
} catch (IOException x) {
System.err.println(x);
continue;
}
// Sends the file to the specified email alias.
System.out.format("Emailing file %s%n", filename);
//Details left to reader....
}
// Reset key - this step is critical if you want to receive more observation events.
// If the key is no longer valid, the directory is inaccessible, so exit the loop.
boolean valid = key.reset();
if (!valid) {
break;
}
}
Retrieve file name
Retrieves the file name from the event context. Email The example uses the following code to retrieve the file name:
WatchEvent<Path> ev = (WatchEvent<Path>)event; Path filename = ev.context();
When you compile the Email example, it will generate the following errors:
Note: Email.java uses unchecked or unsafe operations. Note: Recompile with -Xlint:unchecked for details.
This error is caused by a line of code that converts watchevent < T > to watchevent < Path >. The WatchDir example avoids this error by creating a utility cast method that suppresses unchecked warnings, as follows:
@SuppressWarnings("unchecked")
static <T> WatchEvent<T> cast(WatchEvent<?> event) {
return (WatchEvent<Path>)event;
}
If you are not familiar with @ SuppressWarnings syntax, please refer to the notes section.
When and not to use this API
The Watch Service API is designed for applications that need to be notified of file change events. It is ideal for any application, such as an editor or IDE, which may have many open files and need to ensure that the files are synchronized with the file system. It is also ideal for monitoring directory application servers that may wait jsp or The jar files are deleted in order to deploy them.
This API is not designed for hard drive indexing. Most file system implementations support file change notification. The monitoring service API leverages this support when available. However, when the file system does not support this mechanism, the Watch Service will poll the file system and wait for events.
Other useful methods
Some useful methods are not suitable for other parts of this lesson. They are introduced here.
Determine MIME type
To determine the MIME type of a file, you may find the probecontent type (path) method useful. For example:
try {
String type = Files.probeContentType(filename);
if (type == null) {
System.err.format("'%s' has an" + " unknown filetype.%n", filename);
} else if (!type.equals("text/plain") {
System.err.format("'%s' is not" + " a plain text file.%n", filename);
continue;
}
} catch (IOException x) {
System.err.println(x);
}
Note that probecontent type returns null if the content type cannot be determined.
The implementation of this method is highly platform specific and not absolutely reliable. The content type is determined by the default file type detector of the platform. For example, if the detector is based on If the class extension determines that the content type of the file is application/x-java, it may have been fooled.
If the default value is not enough to meet your needs, you can provide a custom FileTypeDetector.
Email The example uses the probeconontenttype method.
Default file system
To retrieve the default file system, use the getDefault method. Generally, this FileSystems method (note the plural number) is linked to one of the FileSystems methods (note the singular number), as follows:
PathMatcher matcher = FileSystems.getDefault().getPathMatcher("glob:*.*");
Path string separator
Path separators for POSIX file systems are forward slashes, /, and backslashes, \, for Microsoft Windows. Other file systems may use other delimiters. To retrieve the path separator for the default file system, use one of the following methods:
String separator = File.separator; String separator = FileSystems.getDefault().getSeparator();
The getSeparator method is also used to retrieve the path separator for any available file system.
File storage of file system
A file system has one or more file stores to hold its files and directories. File storage represents the underlying storage device. In UNIX operating system, each mounted file system is represented by a file storage area. In Microsoft Windows, each volume is represented by a file store: C:, D:, and so on.
To retrieve a list of all file stores for the file system, you can use the getFileStores method. This method returns an iteratable that allows you to traverse all root directories using the enhanced for statement.
for (FileStore store: FileSystems.getDefault().getFileStores()) {
...
}
If you want to retrieve the file store where a specific file is located, use the getFileStore method in the Files class, as shown below:
Path file = ...; FileStore store= Files.getFileStore(file);
DiskUsage The example of uses the getFileStores method.
Legacy file I/O code
Interoperability with legacy code
Before the release of Java SE 7, Java io. The file class is a mechanism for file I/O, but it has several disadvantages.
- Many methods do not throw errors when they fail. For example, if the file deletion fails, the program will receive a "deletion failure", but it is not known that this is because the file does not exist, the user does not have permission, or there are some other problems.
- The rename method does not work consistently on different platforms.
- There is no real support for symbolic links.
- More metadata support is needed, such as file permissions, file owners, and other security attributes.
- Accessing file metadata is inefficient.
- Many File methods do not scale. Requesting a large directory list on the server may cause a hang. Large directories can also cause memory resource problems, resulting in a denial of service.
- If circular symbolic links exist, it is impossible to write reliable code to recursively traverse the file tree and respond appropriately.
You may use Java io. File, and hope to use Java nio. file. Path function with minimal impact on code.
java. io. The File class provides the toPath method, which converts the old style File instance into Java nio. File. Path instance, as follows:
Path input = file.toPath();
You can then take advantage of the rich feature set available to the Path class.
For example, suppose you have some code that deletes a file:
file.delete();
You can modify this code to use files The delete method is as follows:
Path fp = file.toPath(); Files.delete(fp);
Instead, Path The tofile method constructs a Java io. File object.
Add Java io. The file function is mapped to Java nio. file
Because another method of Java I/O architecture has been completely implemented, it cannot be rebuilt in the Java I/O architecture. If you want to use Java nio. File package provides rich functions. The simplest solution is to use file The topath method, as suggested in the previous section. However, if you don't want to use this method, or it doesn't meet your needs, you must rewrite the file I/O code.
There is no one-to-one correspondence between the two APIs, but the following table gives you an overview of Java io. File API mapped to Java nio. File API and tell you where to get more information.
| java.io.File function | java.nio.file function | Tutorial coverage |
|---|---|---|
| java.io.File | java.nio.file.Path | Path class |
| java.io.RandomAccessFile | The SeekableByteChannel functionality. | Random access file |
| File.canRead, canWrite, canExecute | Files.isReadable, Files.isWritable, and Files.isExecutable. On UNIX file systems, the management metadata (file and file storage properties) package is used to check the permissions of nine files. | Check files or directories and manage metadata |
| File.isDirectory(), File.isFile(), and file length() | Files.isDirectory(Path, LinkOption...), Files.isRegularFile(Path, LinkOption...), and Files.size(Path) | Administrative Meta data |
| File.lastModified() and file setLastModified(long) | Files.getLastModifiedTime(Path, LinkOption...) and files setLastMOdifiedTime(Path, FileTime) | Administrative Meta data |
| File methods for setting various attributes: setExecutable, setReadable, setReadOnly, setWritable | These methods are replaced with setAttribute(Path, String, Object, LinkOption...) by the Files method | Administrative Meta data |
| new File(parent, "newfile") | parent.resolve("newfile") | Path operation |
| File.renameTo | Files.move | Move files or directories |
| File.delete | Files.delete | Delete file or directory |
| File.createNewFile | Files.createFile | create a file |
| File.deleteOnExit | Delete specified by the createFile method_ ON_ Replace with the close option. | create a file |
| File.createTempFile | Files.createTempFile(Path, String, FileAttributes<?>), Files.createTempFile(Path, String, String, FileAttributes<?>) | Create files, use stream I/O to create and write files, and use channel I/O to read and write files |
| File.exists | Files.exists and Files.notExists | Verify that the file or directory exists |
| File.compareTo and equals | Path.compareTo and equals | Compare two paths |
| File.getAbsolutePath and getAbsoluteFile | Path.toAbsolutePath | Conversion path |
| File.getCanonicalPath and getCanonicalFile | Path.toRealPath or normalize | Convert the path (toRealPath) and remove the redundancy (normalize) from the path |
| File.toURI | Path.toURI | Conversion path |
| File.isHidden | Files.isHidden | Retrieve information about the path |
| File.list and listFiles | Path.newDirectoryStream | Lists the contents of the directory |
| File.mkdir and mkdirs | Files.createDirectory | Create directory |
| File.listRoots | FileSystem.getRootDirectories | Lists the root directory of the file system |
| File.getTotalSpace, File.getFreeSpace, File.getUsableSpace | FileStore.getTotalSpace, FileStore.getUnallocatedSpace, FileStore.getUsableSpace, FileStore.getTotalSpace | File storage properties |
summary
java. The IO package contains many classes that your program can use to read and write data. Most classes implement sequential access flows. Sequential access streams can be divided into two categories: read and write bytes and read and write Unicode characters. Each sequential access stream has its own characteristics, such as reading or writing data from a file, filtering data when reading or writing data, or serializing objects.
java. nio. The file package provides extensive support for file and file system I/O. This is a very comprehensive API, but its key entries are as follows:
- The Path class has methods for manipulating paths.
- The Files class has methods for file operations, such as move, copy, delete, and methods for retrieving and setting file properties.
- The FileSystem class has various methods to get information about the file system.
More about NiO 2 information can be found in OpenJDK: NIO Found on the project's website. This site provides NiO 2 provides resources for features beyond the scope of this tutorial, such as multicast, asynchronous I/O, and creating your own file system implementation.
Questions and exercises: basic I/O
problem
- What classes and methods will you use to read several pieces of data at a known location at the end of a large file?
- When format is called, what is the best way to indicate a new row?
- How to determine the MIME type of a file?
- What method would you use to determine whether a file is a symbolic link?
practice
- Write an example to calculate the number of times a specific character (such as e) appears in the file. You can specify this character on the command line. You can use xanadu.txt As an input file.
- The file datafile starts with a long, which tells you the offset of a single int type data block in the same file. Write a program to get int type data. What is int data?