introduction
1. Start the server
- My computer – right click – service – select X2 – start
2. Users existing after installation
SYSTEM SYS SCOTT
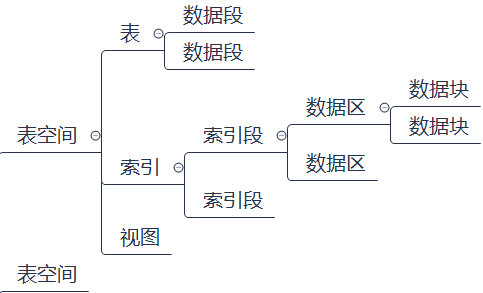
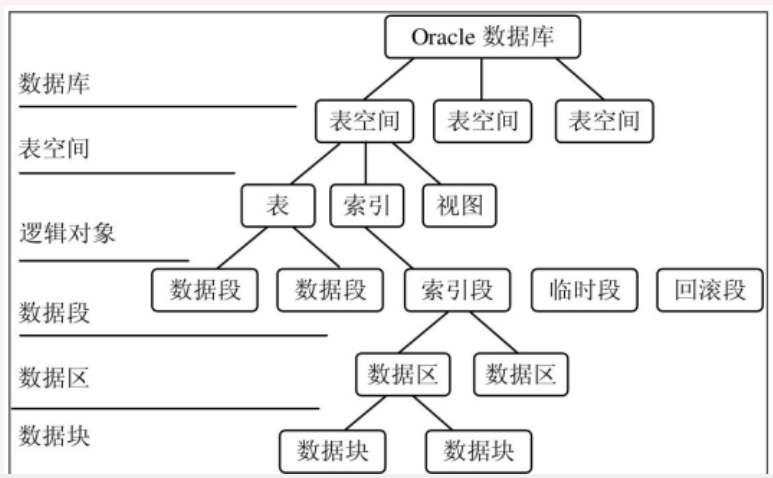
3.Oracle Database
4. Listener
1. A background process running independently on the server
2. When the server is not started, the listener can also run independently
3. Role
It is responsible for monitoring the link requests input by the client and adjusting the link load on the server
4. Working principle
-
The client sends a connection request to the server, and the listener hears the connection request of the client
-
Send the connection request of the client to the database server for processing
-
Establish connection between client and server
-
After the connection is established, the server communicates directly with the client without the participation of the listener
5. Start monitoring
-
Command: lsnrctl start listener name (LISTENER)
-
Service startup in progress
6. Turn off listening
-
Command: lsnrctl stop listener name (LISTENER)
-
Service shutdown in progress
7.listener.ora
-
LISTENER: LISTENER name
-
ORACLE_HOME: home directory of Oracle
-
SID_NAME: the name of the database instance that the listener listens to
-
PROTOCOL: PROTOCOL for listener listening
-
HOST: the HOST name or IP address of the database server
-
PORT: the PORT number used by the listener
**8.D:\develop\Oracle\oracle\network\ADMIN
**
5. Authority
1. Permissions for database objects such as tables and views
-
select retrieve operation
-
insert data insertion
-
Update data update
-
Delete delete data
-
execute execution process
2. Object independent system permissions
-
Create table create table
-
create any table create a table in any schema
-
drop table deletes tables in the current schema
-
drop any table deletes tables in any schema
-
drop user delete user
-
execute any procedure
-
create procedure
-
Create sequence create sequence
-
create session creates a link to the database
-
create synonym
-
Create user create user
-
Create view create view
-
Create trigger create trigger
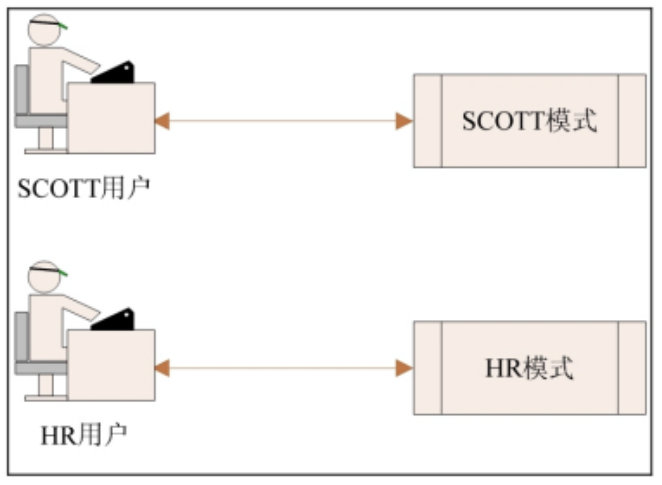
6. Users and modes
1. There is a one-to-one correspondence between user and mode, and their names are the same
2. Diagram
3. Precautions
-
The first mock exam can not exist in the same mode, but the object names in different modes are the same.
-
Users can directly access other schema objects. If they want to access other schema objects, they must have the corresponding access permissions of the object
-
When users want to access other schema objects, they must append the schema name as a prefix
-
Granting the role of CONNECT but not the role of resource will cause users to CONNECT to the ORACLE database but cannot create tables
7. Services
-
Transaction terminology: a collection of operations that make up a single logical unit of work
-
Characteristics of transactions
Atomicity uniformity Isolation Permanent
8. Role
- It can have the same name as the table, not the user
- It can be enabled and disabled at any time
- You can grant object permissions, system permissions, and roles to roles
9. Physical independence of data
- It means that the user's application and the data stored in the database on disk are independent of each other
10. The model of entity set expressed by two-dimensional table structure is relational model
Build table
1. Basic knowledge
1. The data is not stored directly in the database, but in the table
2. The database consists of tables, relationships and operation objects
3. Entities
- Record with rows in the database
- Existing objectively and can be described
3. Entity attribute: represented by columns in the database
4.E-R
-
E: OK
-
R: Relationship
5. Table
- Rows - store entity records
- Column -- stores attribute fields for each entity
6. Data redundancy: redundant and duplicate data
7. Primary key
-
A record can be uniquely identified
-
Cannot be empty
-
principle
Try to select a single key as the primary key Try to use the column with few numerical changes as the primary key
8. Identification column
2. Data integrity
1. Records can be uniquely determined by a field
2. Category
-
Entity integrity
Primary key constraint primary key Unique constraint unique The primary key is unique and not empty Unique constraint can be null The primary key uniqueness constraint is automatically indexed Identification column: automatically numbered; cannot be edited If the primary key is composed of multiple keys, a primary key field may have duplicate values
-
Referential integrity
Foreign key constraint foreign key Establish a relationship (two tables are established one at a time). The data in the secondary table must be imported from the primary key in the primary table and cannot be generated out of thin air be careful When there is no corresponding record in the main table, you cannot add the record to the sub table You cannot change the value in the main table, resulting in data isolation in the child table There is a corresponding record between the sub table and the main table. This record cannot be deleted from the main table Delete the sub table before deleting the main table Child table objects are not deleted when the parent table is deleted
-
Domain integrity
The value of each column does not meet the limit of each column Data type constraints Check constraints: check Scope constraints Format Constraints
check(age>=18 and age<=20)
And
check(age between 18 and 30)
check(sex='male' or sex='female')
or
check(sex in('male','female'))
Default value constraint: default 'male' Non empty constraint: not null
3. Table building
1. Grammar
- Keywords are case insensitive and default uppercase
created table Table name( Field name 1 data type, Field name 2 data type, ....... The last one doesn't add, );
2. Data type
-
char
0-2000 Fixed length
-
varchar2
0-4000 Lengthen
-
number(m,n)
m:Number of numbers n:Fractional part The excess is rounded off
-
date
sysdate Current server time
-
to_ Date (value, 'mode')
to_date('2001-4-8','yyyy-mm-dd') -
clod
Save document Only character type data can be stored
-
blob
Save audio and video pictures
3. The default value of data without specified value after table creation is not null, but the value after default
4. Delete
1. Delete table
- drop table name
2. Delete all records
- delete from table name
3. Delete a data line
- delete from table name where filter criteria
4. Delete all data in the table and cannot roll back
- truncate table
5. Insert data
insert into Table name(Field name[,Field name 2.....]) values (value[,Value 2.........])
insert into Table name values (value[,Value 2.........])
1. Add the data in Table 1 to table 2
-
Table 2 when present
insert into Table 2(Field 1,Field 2...) select Column 1,Column 2... from Table 1 insert into classInfo(cid,cname) select deptno,dname from dept; insert into classInfo(cid,cname,cyear,clen) select deptno,dname,2019,4 from dept;
-
When table 2 does not exist
create table New table name as select Column 1... from Data source table The structure of the new table is consistent with that of the data source table Copy table structure but not data create table New table name as select Column 1... from Data source table where 1=0
2. Provisional table
SELECT SYSDATE FROM dual; insert into Table name select Column 1 value,Column 2 value,... from dual union select Column 1 value,Column 2 value,... from dual
6. View
1. Check the records in the table
select Field name[,Field name 2.......] from Table name select * from Table name
*Show all fields is not recommended for use in projects
2. View constraints in the table
select * from user_constraints where table_name='Table name'
Note: all table names are capitalized
7. Modification
1. Rename table name
- alter table name rename to new table name
2. Heavy life
- alter table name rename column old column name to new column name
3. New column
- alter table name add new column name data type
4. Modify column type
- alter table name modify column name data type
5. Delete column
- alter table name drop column name
6. Update
- update table name set field 1 - value 1 [, field 2 = value 2...] [where filter criteria]
constraint
1. Primary key constraint
- alter table name add constraint primary key constraint name primary key (column name 1,...)
2. Foreign key constraints
- alter table name add constraint foreign key constraint name foreign key references
Primary table name (primary key column)
3. Unique constraints
- alter table name add constraint unique constraint name (column name)
4. Check constraints
- alter table name add constraint check constraint name check (check condition)
5. Non NULL constraint
- alter table table name modify column name not null
6. Default constraint
- alter table table name modify column name default value
7. Row level constraints
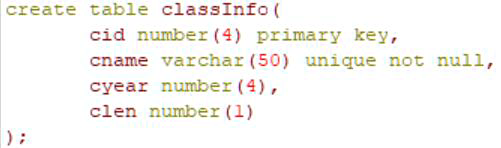
8. Table level constraints
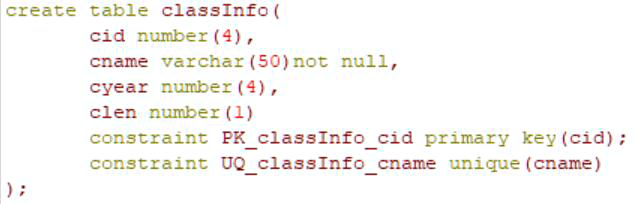
sequence
1. Create sequence object
- create sequence <sequence_name>
2. The range of each increase in the sequence is 1 by default
- increment by n
3. The serial number at the beginning of the sequence. The default is 1
- start with n
4. The maximum value (ascending order) that the sequence can generate represents the minimum value (descending order) that the sequence can generate
- [maxvalue n][minvalue n]
5. After the sequence reaches the maximum value, start generating the sequence again. The default value is nocycle
- [cycle|nocycle]
6. Allow faster generation of sequences
- [cache n|nocache]
7. Get the current serial number
- select <sequence_name>.currval from dual
8. Get the next serial number
- select <sequence_name>.nextval from dual
9. Delete sequence
- drop sequence <sequence_name>
10. Using sequence operation is irreversible
affair
1. Transaction submission
commit
2. Transaction rollback
rollback
update tb_user set upwd='1' where usid=1001; savepoint p1; rollback to p1;
3. Mark the points in the transaction that can be rolled back
savepoint
4. Four characteristics
1. Atomicity
-
A transaction is an inseparable unit of work, either doing or not doing (either successful or failed)
-
It can be regarded as the same transaction, success or failure together
update tb_user set upwd='1237' where usid=1001; update emp set ename='JIM' where empno=7369;
2. Consistency
- A transaction must be a database that changes from one consistency state to another. Consistency is closely related to atomicity
3. Isolation
- The execution of a transaction cannot be disturbed by other transactions, that is, the internal operations and data used in a transaction are isolated from other concurrent transactions, and the concurrent tasks do not interfere with each other
4. Persistence
- Once a transaction is committed, its impact on the database is permanent
Operator
1. Arithmetic operator
+ , - , * , /
2. Comparison operator
1. Not equal to
!= <>
2.<, >, <=, >=
3. Between a and B
between A and B and
4. Between a and B
in(A,B) or
5. No
not
6. Matching
-
perfect match
=
-
Incomplete match
with X start like 'X%' with X start,And only one character after like 'X_'
7.is null
3. Logical operators
1.and, or, not
select cid,cname from classinfo1 where exists (select * from student where student.cid=classinfo1.cid);
2.any,all,some
select* from student where cid=1003 and age > all(select age from student where cid=1001);
4. Set operator
1. Existence
exists
2. Does not exist
not exists
select cid,cname from classinfo1 where not exists (select * from student where student.cid=classinfo1.cid);
5. Join operator
1. Query statement A
XXX
Query statement B
-
union
Automatically eliminate completely duplicate information
-
union all
Show all, including duplicates
-
intersect
Get the same data in two tables
-
minus
Returns the result of the first statement but the second statement does not
2.||
-
Student number_ full name
select sid||'_'||sname from student;
Basic query
1. Query data in two tables at the same time
select s.*,c.* from student s,classInfo1 c;
2. Check the records in the table
select Field name[,Field name 2.......] from Table name select * from Table name
3. View the constraints in the table
select * from user_constraints where table_name='Table name' Note: all table names are capitalized
4. Grouping
group by xx Press xx Group having xx Press after grouping xx screen where xx Filter before grouping
5. Query all values of a column
all
6. Filter duplicate data
distinct
7. Query statement structure
select [distinct] <column1 [as new name],colimn2...>
from <table>
[where <condition>]
[group by xx]
[having <condition>]
[order by xx asc/desc]
8. Paging query
1.rowid
The address of this record in memory
2.rownum
Usage scenario: Before query by specific conditions n Data bar
select rownum,emp.* from emp where rownum<=10;
be careful Directly querying the following statements will not succeed select rownum,emp.* from emp where rownum>10 no result The last few statements of difference search Query pseudo columns generated by all data select rownum rn,emp.* from emp; according to rn query select * from (select rownum rn,emp.* from emp) a where rn >10;
3. Three steps
-
1. Filter out the data to be paged
select * from emp where sal>=1000
-
2. Generate pseudo columns from filtered data
select rownum rn,a.* from (select * from emp where sal>=1000) a
-
3. Screening
select * from ( select rownum rn,a.* from (select * from emp where sal>=1000) a) b where b.rn>0 and b.rn<=3
-
2-3 step by step
select * from ( select rownum rn,a.* from (select * from emp where sal>=1000) a where rownum<=6) b where b.rn>3
-
Writing sql statements in java
pageSize How many pieces of data are displayed per page pageNum What page of data is displayed select * from ( select rownum rn,a.* from (select * from emp where sal>=1000) a where rownum<=pageSize*pageNum) b where b.rn>(pageNum-1)*pageSize
Common functions
1. Numerical function
floor(x) Rounding off decimal parts trunc(x,y) take x retain y Decimal place ceil(x) Round up round(x) rounding
2. Character function
lower()
All lowercase
upper()
All uppercase
length()
length
substr(a,b,c)
intercept a Zhongcong b Start taking c Characters
replace(a,b,c)
stay a Medium b cover c replace
instr(a,b,c,d)
a Searched string
b The string you want to search
c Start of search,The default is 1
d The first J Location of the first occurrence,The default is 1
case
when... then...
end
select sid,sname,addr ,
case
when instr(addr,'province',1,1)>0 then substr(addr,1,instr(addr,'province',1,1))
when instr(addr,'province',1,1)<1 then substr(addr,1,instr(addr,'area',1,1))
when addr is null then 'The address is unknown'
end province from student;
3. Conversion function
to_date(a,b) String a Convert to date type b to_char(a,b) Add date or data a Convert to char data type
4. Date function
sysdate Returns the current date add_months(d1,n1) Return on date d1 On the basis of n1 New date in months last_day(d1) Return date d1 Date of the last day of the month extract(c1 from d1) Return date d1 Date of the last day of the month Don't understand help documents
5. Aggregate function
max(x) min(x) avg(x) sum(x) count(x) Number of query rows
6. Analysis function
row_number() row_number() over (partition by col1 order by col2) according to COL1 Grouping, according to COL2 Sorting, and this value represents the sequence number after internal sorting in each group (continuous and unique in the group) rank() rank ( ) over ( [query_partition_clause] order_by_clause ) Jump sort. When there are two second places, the next is the fourth place (also in each group) dense_rank() dense_rank ( ) over ( [query_partition_clause] order_by_clause ) dense_rank()It is a continuous sort. When there are two second places, it is still followed by the third place
7. Other functions
nvl(a,b)
If empty, return b Non null return a
decode(a,x1,x2,y1,y2,b)
a==x1 return(x2)
a==y1 return(y2)
else return(b)
order by Column name 1 asc Ascending order/desc Descending order (Default ascending order), Column name 2 [desc/asc] -sort
3. Conversion function
to_date(a,b) String a Convert to date type b to_char(a,b) Add date or data a Convert to char data type
Advanced query
1. Inner join
select Listing from Table name inner join Table name 2 on join condition
-
It has nothing to do with the order of the table
-
An inline join returns a row only if at least one row belonging to both tables meets the join condition
-
An inner join eliminates any mismatched rows in another table
2. Outreach
1. Left join
select Listing from Table name 1 left join Table name 2 on join condition
- Give priority to finding all qualified data in table name 1. If there is no corresponding data in table name 2, fill in the value with NULL
- (the left table completely displays the contents matching the left and right tables. If the left table has no records on the right table, null will be displayed)
2. Right join
select Listing from Table name 1 right join Table name 2 on join condition
- All rows in the right table and fields not in the left table are replaced with null
Give priority to finding all qualified data in table name 2. If there is no corresponding data in table name 1, fill in the value with NULL
– (the right and left tables completely display the matching contents of + left and right tables. If the right table has no records in the left table, null will be displayed)
3. Full join
select Listing from Table name 1 full join Table name 2 on join condition
- Both the left and right tables show insufficient information
3. Cross join
select Listing from Table name 1 cross join Table name 2 on join condition
- Each row in the left table is combined with each row in the right table
- Cartesian product = left table data row * right table data row
- Returns the Cartesian product of two tables. The number of rows returned = the product of the number of rows of two tables
- The data table with where rows * rows is used at the same time when filtering and filling data