Java parallel atomic operation class parsing
preface
The JUC package provides a number of atomic operation classes, which are implemented using the non blocking algorithm CAS. Compared with the atomic operation using locks, the performance is greatly improved.
Since the principles of atomic operations are roughly the same, this article only explains the principles of the simple AtomicLong class and the LongAdder class added in JDK8.
Atomic variable operation class
The JUC concurrency package contains AtomicInteger, AtomicLong, AtomicBoolean and other atomic operation classes with similar principles. Next, let's take a look at AtomicLong class.
AtomicLong is an atomic increasing or decreasing class, which is implemented internally using Unsafe. Let's look at the following code.
public class AtomicLong extends Number implements java.io.Serializable {
private static final long serialVersionUID = 1927816293512124184L;
//1. Get Unsafe instance
private static final Unsafe unsafe = Unsafe.getUnsafe();
//2. Store the offset of the variable value
private static final long valueOffset;
//3. Judge whether the JVM supports Long type lockless CAS
static final boolean VM_SUPPORTS_LONG_CAS = VMSupportsCS8();
private static native boolean VMSupportsCS8();
static {
try {
//4. Get the offset of value in AtomicLong
valueOffset = unsafe.objectFieldOffset
(AtomicLong.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
//5. Actual variable value
private volatile long value;
public AtomicLong(long initialValue) {
value = initialValue;
}
......
}First, through Unsafe The getunsafe () method obtains an instance of the Unsafe class,
Why can I get an instance of the Unsafe class? Because the AtomicLong class is also in the rt.jar package, it can be loaded through the BootStrap class loader.
The second and fourth steps obtain the offset of the value variable in the AtomicLong class.
In step 5, the value variable is declared volatile to ensure memory visibility under multithreading, and value stores the value of a specific counter.
Increment and decrement operation codes
Next, let's look at the main functions in AtomicLong.
//Call the unsafe method, set the atomicity value to the original value + 1, and return the incremented value
public final long incrementAndGet() {
return unsafe.getAndAddLong(this, valueOffset, 1L) + 1L;
}
//Call the unsafe method, set the atomicity value to the original value - 1, and return the value after decreasing
public final long decrementAndGet() {
return unsafe.getAndAddLong(this, valueOffset, -1L) - 1L;
}
//Call the unsafe method, set the atomicity value to the original value + 1, and return the original value
public final long getAndIncrement() {
return unsafe.getAndAddLong(this, valueOffset, 1L);
}
//Call the unsafe method, set the atomicity value to the original value - 1, and return the original value
public final long getAndDecrement() {
return unsafe.getAndAddLong(this, valueOffset, -1L);
}The above code implements the operation by calling the getAndAddLong() method of Unsafe. This function is an atomic operation. The first parameter is the reference of the AtomicLong instance, the second parameter is the offset value of the value variable in AtomicLong, and the third parameter is the value of the second variable to be set.
The getAndIncrement() method is in jdk1 The implementation logic in 7 is as follows.
public final long getAndIncrement() {
while (true) {
long current = get();
long next = current + 1;
if (compareAndSet(current,next))
return current;
}
}In this code, each thread gets the current value of the variable (because value is a volatile variable, it gets the latest value), then increases 1 in the working memory, and then uses CAS to modify the value of the variable. If the setting fails, it will continue to cycle until the setting is successful.
The logic in JDK8 is:
public final long getAndAddLong(Object var1, long var2, long var4) {
long var6;
do {
var6 = this.getLongVolatile(var1, var2);
} while(!this.compareAndSwapLong(var1, var2, var6, var6 + var4));
return var6;
}As you can see, jdk1 The loop logic in AtomicLong of 7 has been built in by the atomic operation class Unsafe in JDK8. The reason for the built-in should be that this function can also be used in other places, and the built-in can improve reusability.
compareAndSet(long expect, long update) method
public final boolean compareAndSet(long expect, long update) {
return unsafe.compareAndSwapLong(this, valueOffset, expect, update);
}We can know from the above code that unsafe is called internally Compareandswaplong method. If the value in the atomic variable is equal to expect, update the value with the update value and return true; otherwise, return false.
Let's deepen our understanding by an example of multithreading using AtomicLong to count the number of 0.
/**
* @author Mystery jack
* Official account: Java rookie programmer
* @date 2022/1/4
* @Description Count the number of 0
*/
public class AtomicTest {
private static AtomicLong atomicLong = new AtomicLong();
private static Integer[] arrayOne = new Integer[]{0, 1, 2, 3, 0, 5, 6, 0, 56, 0};
private static Integer[] arrayTwo = new Integer[]{10, 1, 2, 3, 0, 5, 6, 0, 56, 0};
public static void main(String[] args) throws InterruptedException {
final Thread threadOne = new Thread(() -> {
final int size = arrayOne.length;
for (int i = 0; i < size; ++i) {
if (arrayOne[i].intValue() == 0) {
atomicLong.incrementAndGet();
}
}
});
final Thread threadTwo = new Thread(() -> {
final int size = arrayTwo.length;
for (int i = 0; i < size; ++i) {
if (arrayTwo[i].intValue() == 0) {
atomicLong.incrementAndGet();
}
}
});
threadOne.start();
threadTwo.start();
//Wait for the thread to finish executing
threadOne.join();
threadTwo.join();
System.out.println("count The total is: " + atomicLong.get()); //Total count: 7
}
}This code is very simple. Every time a 0 is found, AtomicLong's atomic increment method will be called.
When there is no atomic class, certain synchronization measures are required to implement the counter, such as synchronized keyword, but these are blocking algorithms, which have a certain impact on the performance, while AtomicLong uses CAS non blocking algorithm, which has better performance.
However, AtomicLong still has performance problems under high parallel distribution. JDK8 provides a LongAdder class with better performance under high parallel distribution.
LongAdder introduction
As mentioned earlier, when AtomicLong is used under high concurrency, a large number of threads will compete for the same atomic variable at the same time. However, since CAS operation of only one thread will succeed at the same time, it will cause a large number of threads to continuously spin and try CAS operation after competition failure, which will waste CPU resources in vain.
Therefore, an atomic increment or decrement class LongAdder is added in JDK8 to overcome the disadvantage of high concurrency AtomicLong. Since the performance bottleneck of AtomicLong is caused by multiple threads competing for the update of a variable, if a variable is divided into multiple variables and multiple threads compete for multiple resources, will the performance problem be solved? Yes, that's the idea of LongAdder.
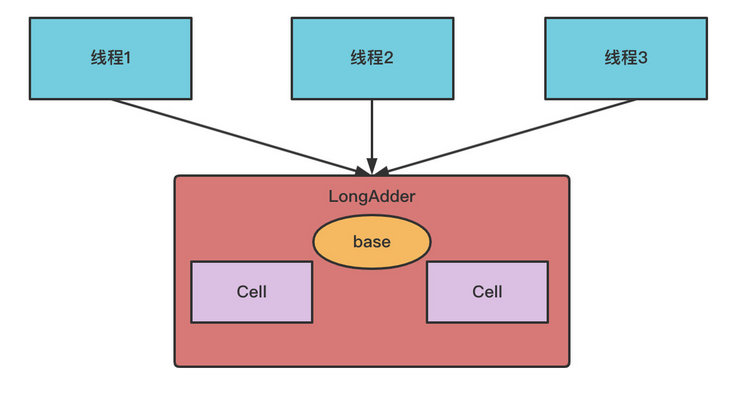
As shown in the figure above, when using LongAdder, multiple Cell variables are maintained internally, and each Cell has a long variable with an initial value of 0. In this way, under the same concurrency, the number of threads competing for a single thread update operation will be reduced, which will reduce the concurrency of competing for shared resources in a disguised manner.
In addition, if multiple threads fail to compete for the same Cell atomic variable, they will not always spin retry, but try other Cell variables for CAS attempts, which increases the possibility that the current thread will retry CAS successfully. Finally, when obtaining the current value of LongAdder, the value values of all Cell variables are accumulated and then returned by base.
LongAdder maintains an atomic update array with delayed initialization (the Cell array is null by default) and a base value variable base. It does not create the Cells array at the beginning, but when it is used, that is, lazy loading.
When judging that the cell array is null and concurrent threads are reduced at the beginning, all accumulation is carried out on the base variable, keeping the size of the cell array to the nth power of 2. During initialization, the number of cell elements in the cell array is 2, and the variable entity in the array is of cell type. Cell type is an improvement of AtomicLong to reduce cache contention, that is, to solve the problem of pseudo sharing.
When multiple threads modify multiple variables in a cache line concurrently, because only one thread can operate the cache line at the same time, it will lead to performance degradation. This problem is called pseudo sharing.
Generally speaking, the cache line has 64 bytes. We know that a long is 8 bytes. After filling 5 long, there are 48 bytes in total.
In Java, the object header occupies 8 bytes in 32-bit system and 16 bytes in 64 bit system. In this way, filling 5 long types can fill 64 bytes, that is, a cache line.
JDK 8 and later versions of Java provide sun misc. The @ contained annotation can solve the problem of pseudo sharing.
128 bytes of padding will be added after the @ contained annotation is used, and the - XX: - restrictcontained option needs to be turned on to take effect.
The real core of solving pseudo sharing in LongAdder is the Cell array, which uses the @ contained annotation.
Byte filling is wasteful for most isolated multiple atomic operations, because atomic operations are scattered in memory irregularly (that is, the memory addresses of multiple atomic variables are discontinuous), and it is very unlikely that multiple atomic variables will be put into the same cache line. However, the memory addresses of atomic array elements are continuous, so multiple elements in the array can often share a cache line. Therefore, the @ contained annotation is used to fill the bytes of the Cell class, which prevents multiple elements in the array from sharing a cache line, which is an improvement in performance.
LongAdder source code analysis
Question:
- What is the structure of LongAdder?
- Which Cell element in the Cell array should the current thread access?
- How to initialize a Cell array?
- How to expand the Cell array?
- How to handle the conflict when the thread accesses the allocated Cell element?
- How to ensure the atomicity of the Cell element allocated for thread operation?
Next, let's look at the structure of LongAdder:
The LongAdder class inherits from the Striped64 class and maintains these three variables inside Striped64.
- The real value of LongAdder is actually the sum of the value of base and the value of all Cell elements in the Cell array. Base is a basic value, which is 0 by default.
- cellsBusy is used to realize spin lock. The status values are only 0 and 1. When creating Cell elements, expanding Cell array or initializing Cell array, CAS is used to operate this variable to ensure that only one thread can operate one of them at the same time.
transient volatile Cell[] cells; transient volatile long base; transient volatile int cellsBusy;
public class LongAdder extends Striped64 implements Serializable {Cell structure
Let's take a look at the structure of Cell.
@sun.misc.Contended static final class Cell {
volatile long value;
Cell(long x) { value = x; }
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long valueOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> ak = Cell.class;
valueOffset = UNSAFE.objectFieldOffset
(ak.getDeclaredField("value"));
} catch (Exception e) {
throw new Error(e);
}
}
}You can see that a variable declared volatile is maintained internally. Volatile is declared here to ensure memory visibility. In addition, the CAS function ensures the atomicity of the value value in the Cell element allocated when the current thread is updated through CAS operation. You can also see that the Cell class is modified by @ contented to avoid pseudo sharing.
So far, we have known the answers to questions 1 and 6.
sum()
The sum() method returns the current value. The internal operation is to accumulate all the value values inside the Cell, and then accumulate the base.
Because the Cell array is not locked when calculating the sum, other threads may modify the Cell value or expand the capacity during the accumulation process. Therefore, the value returned by sum is not very accurate, and its return value is not an atomic snapshot value when calling the sum() method.
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}reset()
The reset() method is a reset operation. Set the base to 0. If the Cell array has elements, the elements are reset to 0.
public void reset() {
Cell[] as = cells; Cell a;
base = 0L;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
a.value = 0L;
}
}
}sumThenReset()
sumThenReset() method is a modified version of sum() method, which resets the current Cell and base to 0 after using sum to accumulate the corresponding Cell value.
This method has thread safety problems. For example, when the first calling thread clears the Cell value, the accumulated value of the next thread is 0.
public long sumThenReset() {
Cell[] as = cells; Cell a;
long sum = base;
base = 0L;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null) {
sum += a.value;
a.value = 0L;
}
}
}
return sum;
}add(long x)
Next, let's focus on the add() method, which can answer other questions just now.
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
//(1)
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
//(2)
if (as == null || (m = as.length - 1) < 0 ||
//(3)
(a = as[getProbe() & m]) == null ||
//(4)
!(uncontended = a.cas(v = a.value, v + x)))
//(5)
longAccumulate(x, null, uncontended);
}
}
final boolean casBase(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, BASE, cmp, val);
}This method first determines whether cells are null. If they are null, they are accumulated on the base. If the cells are not null or the thread fails to execute the code cas, go to the second step. Step 2 and step 3 of the code determine which Cell element in the cells array the current thread should access. If the element mapped by the current thread exists, execute code 4.
The fourth step mainly uses the CAS operation to update the value value of the allocated Cell element. If the element mapped by the current thread does not exist or exists but the CAS operation fails, execute code 5.
Which Cell element of the cells array should be accessed by the thread is calculated through getprobe() & M, where m is the number of current cells array elements - 1, and getprobe() is used to obtain the value of the variable threadLocalRandomProbe in the current thread. This value is 0 at first, and will be initialized in step 5 of the code. Moreover, the current thread ensures the atomicity of updating the value value of the Cell element through the cas function of the allocated Cell element.
Now we have understood the second question.
Let's take a look at the longAccumulate(x,null,uncontended) method, which is mainly used to initialize and expand the cells array.
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
//6. Initialize the value of the current thread variable ThreadLocalRandomProbe
int h;
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // force initialization
h = getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
for (;;) {
Cell[] as; Cell a; int n; long v;
//7.
if ((as = cells) != null && (n = as.length) > 0) {
//8.
if ((a = as[(n - 1) & h]) == null) {
if (cellsBusy == 0) { // Try to attach new Cell
Cell r = new Cell(x); // Optimistically create
if (cellsBusy == 0 && casCellsBusy()) {
boolean created = false;
try { // Recheck under lock
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created)
break;
continue; // Slot is now non-empty
}
}
collide = false;
}
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
//9. If the current Cell exists, execute CAS setting
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
//10. The current number of Cell elements is greater than the number of CPU s
else if (n >= NCPU || cells != as)
collide = false; // At max size or stale
//11. Is there a conflict
else if (!collide)
collide = true;
//12. If the current number of elements does not reach the number of CPU s and there is a conflict, expand the capacity
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == as) { // Expand table unless stale
//12.1
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
//12.2
cellsBusy = 0;
}
//12.3
collide = false;
continue; // Retry with expanded table
}
//13. In order to find an idle Cell, recalculate the hash value, and xorshift algorithm generates a random number
h = advanceProbe(h);
}
//14. Initialize Cell array
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table
if (cells == as) {
//14.1
Cell[] rs = new Cell[2];
//14.2
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
//14.3
cellsBusy = 0;
}
if (init)
break;
}
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // Fall back on using base
}
}This method is complex. We mainly focus on problem 3, problem 4 and problem 5.
- How to initialize a Cell array?
- How to expand the Cell array?
- How to handle the conflict when the thread accesses the allocated Cell element?
When each thread executes step 6 of the code for the first time, it initializes the value of the current thread variable ThreadLocalRandomProbe, which is mainly used to calculate which cell element in the cells array the current thread allocates to.
The initialization of the cells array is carried out in step 14 of the code. cellsBusy is an identifier. 0 indicates that the current cells array has not been initialized or expanded, and no Cell element is being created. 1 indicates that the cells array is being initialized or expanded, and a new element is being created. The 0 or 1 state is switched through CAS, and casCellsBusy() is called.
Assuming that the current thread sets cellsBuys to 1 through CAS, the current thread starts the initialization operation, and other threads cannot expand the capacity at this time. For example, the code (14.1) initializes the number of cells array to 2, and then uses h & 1 to calculate the location where the current thread should access the cell array. h is the threadLocalRandomProbe variable of the current thread. Then the cells array is identified and initialized, and finally (14.3) the cellsBusy flag is reset. Although CAS operation is not used here, it is thread safe because cellsBusy is of volatile type to ensure memory visibility. The values of the two elements in the initialized cells array are still null. Now we know the answer to question 3.
The expansion of cells array is performed in step 12 of the code. The expansion of cells is conditional, that is, the expansion operation is performed after the conditions in step 10 and 11 are not met. Specifically, the capacity expansion will be carried out only when the number of elements in the current cells is less than the number of CPU s in the current machine, and multiple threads access the same element in the cells, resulting in the CAS failure of a thread.
Why is the number of CPUs involved? Only when each CPU runs a thread can the effect of multithreading be the best. That is, when the number of cells array elements is the same as the number of CPUs, each Cell uses a CPU for processing. At this time, the performance is the best.
Step 12 of the code is to set cellsBusy to 1 through CAS before capacity expansion. Assuming CAS is successful, execute the code (12.1) to expand the capacity to twice the previous capacity, and copy the Cell element to the expanded array. In addition, after the expansion, the cells array contains not only the copied elements, but also other new elements. The values of these elements are still null. Now we know the answer to question 4.
In steps 7 and 8 of the code, the current thread calls the add() method and calculates the Cell element subscript to be accessed according to the random number threadLocalRandomProbe and the number of cells elements of the current thread. Then, if the value of the corresponding subscript element is found to be null, add a Cell element to the cells array, And set cellsBusy to 1 before adding it to the cells array.
In step 13 of the code, the random value threadLocalRandomProbe of the current thread is recalculated for the thread with failed CAS to reduce the chance of conflict when accessing the cells element next time. Here we know the answer to question 5.
summary
This class shares the high competition through the internal cells array and issues the amount of competition when multiple threads update an atomic variable at the same time, so that multiple threads can update the elements in the cells array in parallel at the same time. In addition, the array element Cell is decorated with the @ contained annotation, which prevents multiple atomic variables in the cells array from being put into the same cache line, that is, pseudo sharing is avoided.
Compared with LongAdder, LongAccumulator can provide a non-zero initial value for the accumulator, which can only provide the default value of 0. In addition, the former can also specify accumulation rules, such as multiplication without accumulation. You only need to pass in a custom binocular operator when constructing the LongAccumulator, while the latter has built-in accumulation rules.