This article is Optimization of Java high concurrency spike API Course notes.
Editor: IDEA
Java version: java8
Previously:
I Second kill system environment construction and DAO layer design
II Second kill system Service layer
III Second kill system web layer
High concurrency optimization analysis
Where does concurrency occur? For a second kill of a commodity, naturally, there will be a high concurrency bottleneck under the specific commodity details page.

The red part is the occurrence point of high concurrency.
Why get the system time separately? Because not all resources are obtained from the server.

Therefore, you need to obtain the time separately to specify the current time of the server.
CDN: content distribution network, a system to accelerate users' access to data. Deployed on the network node closest to the user. There is no need to access the back-end server to hit the CDN.
Obtaining system time does not need to be optimized. The memory accessed once is about 10ns, and there is no back-end access.
Get seckill address: CDN cache cannot be used, which is suitable for server cache: redis, etc. Low cost of consistency maintenance.
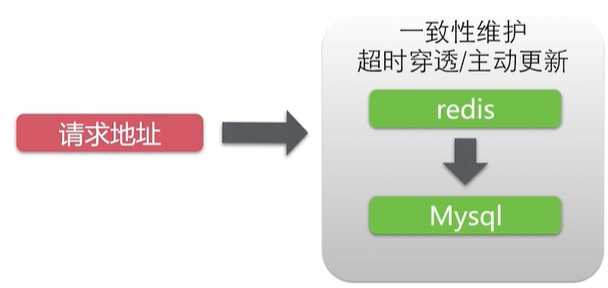
Execute second kill operation: CDN cannot be used, back-end caching is difficult: inventory problem, one line data competition: hot goods.
Second kill scheme:

Cost analysis: operation and maintenance cost and stability: nosql,mq, etc. Development cost: data consistency, rollback scheme. Idempotency is difficult to guarantee: repeated second kill problem. Not suitable for novice architecture.
Why not use MySQL?
An update, MySQL can QPS very high.
java control transaction behavior analysis:
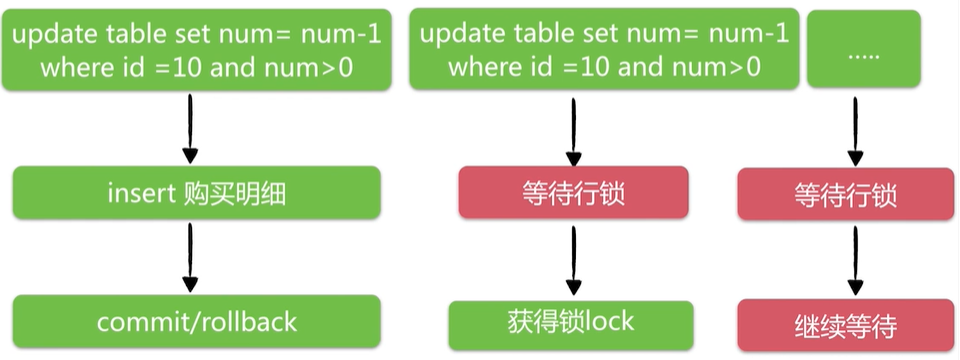
Bottleneck analysis:

Optimization analysis: row level locks are released after commit, so the optimization direction is to reduce the holding time of row level locks.
Delay analysis: local machine room, possibly 1ms, remote machine room:
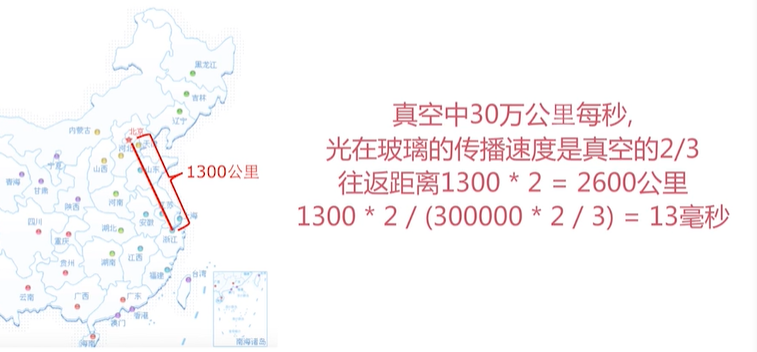
The round-trip may take 20ms, and the maximum concurrency is 50QPS.
Optimization ideas:
Put the client logic on the MySQL server to avoid the impact of network delay and GC.
Two options:
- Customize the SQL scheme: update /*+[auto_commit] * /. If successful, it will succeed. If unsuccessful, it will roll back. You need to modify the MySQL source code.
- Using stored procedures: the whole transaction is completed on the MySQL side.
Optimization summary:
- Front end control: exposed interface, button anti repetition
- Dynamic and static data separation: CDN cache (static resources), backend cache (such as redis)
- Transaction contention Optimization: reduce transaction lock time
redis backend optimized cache coding
Optimizing the address exposure interface using redis
Download and install redis.
D:\Program Files (x86)\Renren.io\Redis>redis-cli.exe -h 127.0.0.1 -p 6379 127.0.0.1:6379> set myKey abc OK 127.0.0.1:6379> get myKey "abc"
Used in conjunction with java, pom.xml adds dependencies:
<!--redis Dependency introduction-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.5.0</version>
</dependency>
<!--Serialization operation-->
<dependency>
<groupId>com.dyuproject.protostuff</groupId>
<artifactId>protostuff-core</artifactId>
<version>1.1.6</version>
</dependency>
<dependency>
<groupId>com.dyuproject.protostuff</groupId>
<artifactId>protostuff-runtime</artifactId>
<version>1.1.6</version>
</dependency>
In the SecKillServiceImpl.java file, the code that originally exposed the url is:
/**
* When the second kill is on, the second kill interface address is output
* Otherwise, the system time and second kill time are output
*
* @param seckillId
*/
@Override
public Exposer exportSecKillUrl(long seckillId) {
// Check database
SecKill secKill = secKillDao.queryById(seckillId);
if(secKill == null) {
// id not found, false
return new Exposer(false,seckillId);
}
Date startTime = secKill.getStartTime();
Date endTime = secKill.getEndTime();
Date nowTime = new Date();
if(nowTime.getTime()<startTime.getTime()
|| nowTime.getTime()>endTime.getTime()) {
return new Exposer(false,seckillId, nowTime.getTime(),
startTime.getTime(),endTime.getTime());
}
// Irreversible
String md5 = getMD5(seckillId);
return new Exposer(true,md5,seckillId);
}
Create RedisDao.java under the DAO folder because it also deals with data.

RedisDao.java
public class RedisDao {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
private JedisPool jedisPool;
public RedisDao(String ip,int port) {
jedisPool = new JedisPool(ip,port);
}
private RuntimeSchema<SecKill> schema = RuntimeSchema.createFrom(SecKill.class);
public SecKill getSeckill(long seckillId) {
// redis operation logic
try {
Jedis jedis = jedisPool.getResource();
try {
String key = "seckill:"+seckillId;
// redis does not implement internal serialization
// get gets a binary array byte [], through deserialization - > object (seckill)
// Adopt custom serialization protostuff
// protostuff:pojo has get set methods
byte[] bytes = jedis.get(key.getBytes(StandardCharsets.UTF_8));
// It is obtained. protostuff conversion is required
// Byte array and schema are required
if (bytes != null) {
// Create an empty object to put the object generated by deserialization
SecKill secKill = schema.newMessage();
ProtostuffIOUtil.mergeFrom(bytes,secKill,schema);
// seckill is deserialized
return secKill;
}
} finally {
jedis.close();
}
} catch (Exception e) {
logger.error(e.getMessage(),e);
}
return null;
}
public String putSeckill(SecKill secKill) {
// Set: object (seckill) - > bytes [] serialization operation
try {
Jedis jedis = jedisPool.getResource();
try {
String key = "seckill:"+secKill.getSeckillId();
byte[] bytes = ProtostuffIOUtil.toByteArray(secKill,schema,
LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE));
// Timeout cache
int timeout = 60*60; // 1 hour
String result = jedis.setex(key.getBytes(StandardCharsets.UTF_8),timeout,bytes);
return result; //Adding cache information, success or failure
} finally {
jedis.close();
}
} catch (Exception e) {
logger.error(e.getMessage(),e);
}
return null;
}
}
There are two methods, put and get. Serialization is also involved. protostuff is used.
Before unit testing, RedisDao needs to be injected into spring-dao.xml:
<!--You need to configure it yourself redis dao-->
<bean id="redusDao" class="cn.orzlinux.dao.cache.RedisDao">
<constructor-arg index="0" value="localhost" />
<constructor-arg index="1" value="6379" />
</bean>
Conduct unit tests:
@RunWith(SpringJUnit4ClassRunner.class)
//Tell JUnit the spring configuration file
@ContextConfiguration({"classpath:spring/spring-dao.xml"})
public class RedisDaoTest {
private long id = 1001;
@Autowired
private RedisDao redisDao;
@Autowired
private SecKillDao secKillDao;
@Test
public void testSeckill() {
// get and put
// Get from cache
SecKill secKill = redisDao.getSeckill(id);
// No, just look it up in the database
// Put it back to redis after finding it
if(secKill==null) {
secKill = secKillDao.queryById(id);
if(secKill != null) {
String result = redisDao.putSeckill(secKill);
System.out.println(result);
secKill = redisDao.getSeckill(id);
System.out.println(secKill);
}
}
}
}
It can be verified by querying redis on the command line. It can be seen that:
127.0.0.1:6379> get seckill:1001 "\b\xe9\a\x12\x11500\xe7\xa7\x92\xe6\x9d\x80iphone12\x18\xbc\x84=!\x00evL|\x01\x00\x00)\x00\xe4\xcd\xb3\xc5\x01\x00\x001\xf8z/N|\x01\x00\x00" 127.0.0.1:6379> get seckill:1002 (nil)
The reason why redis cache can be used here is that there may be thousands of people who kill a commodity. The URL s of these people accessing the commodity are the same. They don't need to search the database frequently. They can be directly stored in the cache.
Second kill operation concurrency optimization
Transaction execution:

Simple optimization
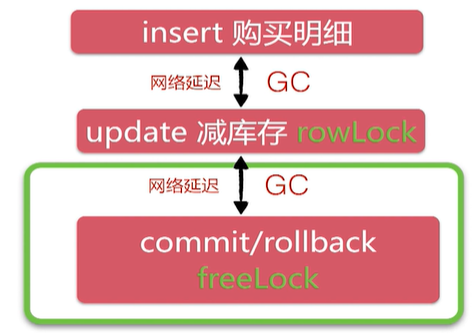
The collision probability of insert operation is low. The server determines whether to execute update according to the insert result, eliminates repeated second kill, and no longer locks update. Then update row level locks, which can reduce the holding time of row level locks.
Source code change database operation time:
@Override
@Transactional
public SeckillExecution executeSeckill(long seckillId, long userPhone, String md5) throws
SeckillException, RepeatKillException, SeckillException {
if(md5==null || !md5.equals(getMD5(seckillId))) {
// The second kill data has been rewritten and modified
throw new SeckillException("seckill data rewrite");
}
// Execute the second Kill Logic: reduce inventory and record purchase behavior
Date nowTime = new Date();
try {
// Record purchase behavior
int insertCount = successKilledDao.insertSuccessKilled(seckillId,userPhone);
if(insertCount<=0) {
// Repeat second kill
throw new RepeatKillException("seckill repeated");
} else {
// Reduce inventory. Hot commodity competition
int updateCount = secKillDao.reduceNumber(seckillId,nowTime);
if(updateCount<=0) {
// No record updated, the second kill is over
throw new SeckillCloseException("seckill is closed");
} else {
//Second kill success
SuccessKilled successKilled = successKilledDao.queryByIdWithSeckill(seckillId,userPhone);
return new SeckillExecution(seckillId, SecKillStatEnum.SUCCESS,successKilled);
}
}
} catch (SeckillCloseException | RepeatKillException e1){
throw e1;
} catch (Exception e) {
logger.error(e.getMessage(),e);
// All compile time exceptions are converted to run-time exceptions so that spring can roll back
throw new SeckillException("seckill inner error"+e.getMessage());
}
}
Depth optimization
SQL transactions are executed on the MySQL side (stored procedures).
stored procedure
Stored Procedure is a set of SQL statements to complete specific functions in a large database system. It is stored in the database and is permanently valid after one compilation. Users execute it by specifying the name of the Stored Procedure and giving parameters (if the Stored Procedure has parameters). Stored Procedure is an important object in database.
The advantages are obvious. Let's talk about the disadvantages: difficult debugging and poor portability. If the business data model changes, the stored procedures of large projects will change greatly.
The stored procedure optimizes the holding time of transaction row level locks. Don't rely too much on stored procedures. Simple logic can rely on stored procedures.
Define a stored procedure:
-- Second kill execution stored procedure
DELIMITER $$ -- console ;Convert to\$\$ express sql The operation is ready
-- Define stored procedures
-- Parameters: in input parameter ; out Output parameters
-- row_count(): Returns the last modification type sql Number of affected rows
-- row_count: 0 Data not modified,>0 Number of rows modified,<0 sql Error or not executed
# SUCCESS(1, "second kill succeeded"),
# END(0, "end of second kill"),
# REPEAT_KILL(-1, "repeat second kill"),
# INNER_ERROR(-2, "system exception"),
# DATA_REWRITE(-3, "data tampering")
CREATE PROCEDURE `seckill`.`execute_seckill`
(in v_seckill_id bigint, in v_phone bigint,
in v_kill_time timestamp,out r_result int)
BEGIN
DECLARE insert_count int DEFAULT 0;
START TRANSACTION;
insert ignore into success_killed
(seckill_id, user_phone,create_time)
values (v_seckill_id,v_phone,v_kill_time);
select row_count() into insert_count;
IF (insert_count=0) THEN
ROLLBACK;
set r_result = -1;
ELSEIF (insert_count<0) THEN
ROLLBACK;
set r_result = -2;
ELSE
update seckill
set number = number-1
where seckill_id = v_seckill_id
and end_time > v_kill_time
and start_time < v_kill_time
and number>0;
select row_count() into insert_count;
IF (insert_count = 0) THEN
ROLLBACK;
set r_result = 0;
ELSEIF(insert_count<0) then
ROLLBACK;
set r_result = -2;
ELSE
COMMIT;
set r_result = 1;
end if;
end if;
END;
$$ -- End of stored procedure definition
delimiter ;
-- console Define variables
set @r_result=-3;
-- Execute stored procedure
call execute_seckill(1001,19385937587,now(),@r_result);
-- Get results
select @r_result;
In this way, the insert and update operations are completed on the server side.
To use this stored procedure, you need to add a new method in SeckillDao.java:
// Using stored procedures to perform a second kill void killByProcedure(Map<String,Object> paramMap);
Then implement sql statements through xml:
<!--mybatis Call stored procedure-->
<select id="killByProcedure" statementType="CALLABLE">
call execute_seckill(
#{seckillId,jdbcType=BIGINT,mode=IN},
#{phone,jdbcType=BIGINT,mode=IN},
#{killTime,jdbcType=TIMESTAMP,mode=IN},
#{result,jdbcType=INTEGER,mode=OUT}
)
</select>
A new method is added to the SecKillService interface and implemented in SecKillServiceImpl.java:
/**
* Stored procedure execution second kill
*
* @param seckillId
* @param userPhone
* @param md5
* @return
* @throws SeckillException
* @throws RepeatKillException
* @throws SeckillCloseException
*/
@Override
public SeckillExecution executeSeckillProcedure(long seckillId, long userPhone, String md5) {
if(md5==null || !md5.equals(getMD5(seckillId))) {
// The second kill data has been rewritten and modified
throw new SeckillException("seckill data rewrite");
}
Date nowTime = new Date();
Map<String,Object> map = new HashMap<>();
map.put("seckillId",seckillId);
map.put("phone",userPhone);
map.put("killTime",nowTime);
map.put("result",null);
// When executing a stored procedure, only result is assigned
try {
secKillDao.killByProcedure(map);
// Get result
int result = MapUtils.getInteger(map,"result",-2);
if(result == 1) {
SuccessKilled sk = successKilledDao.queryByIdWithSeckill(seckillId,userPhone);
return new SeckillExecution(seckillId,SecKillStatEnum.SUCCESS,sk);
} else {
return new SeckillExecution(seckillId,SecKillStatEnum.stateOf(result));
}
} catch (Exception e) {
logger.error(e.getMessage(),e);
return new SeckillExecution(seckillId,SecKillStatEnum.INNER_ERROR);
}
}
Finally, the controller layer replaces the original execution second kill method with this one.
This article was published on orzlinux.cn