
1. General
Reprint: jdk11 source code - Analysis of SynchronousQueue source code
Synchronous queue is a synchronous blocking queue. Each put operation must wait for a take operation. Each take operation must also wait for a put operation.
SynchronousQueue has no capacity and cannot store element node information. It cannot obtain elements through the peek method. The peek method will directly return null. Because there is no element, it cannot be iterated. Its iterator method will return an empty iterator collection emptyIterator();.
Synchronous queue is more suitable for thread communication, information transmission, state switching and other application scenarios. A thread must wait for another thread to transmit some information before it can continue to execute.
Synchronous queue is not commonly used, but it is useful in the thread pool, so let's also analyze it.
Executors. SynchronousQueue used in newcachedthreadpool() method:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
The implementation of SynchronousQueue is an extension of the dual stack and dual queue algorithm described in "nonlocking concurrent objects with condition synchronization" by W.N.Scherer III and M.L.Scott. For the original English description of the algorithm, see: original text
(Lifo) stack is used in unfair mode, while (Fifo) queue is used in fair mode. The performance of the two is roughly similar. Fifo supports higher throughput, and Lifo can maintain higher thread locality.
thread locality:

The above is quoted from a master's thesis: Research on Java language synchronization optimization based on just in time compiler
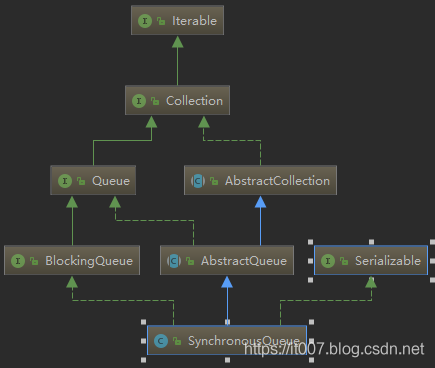
SynchronousQueue class diagram:
2.Transferer
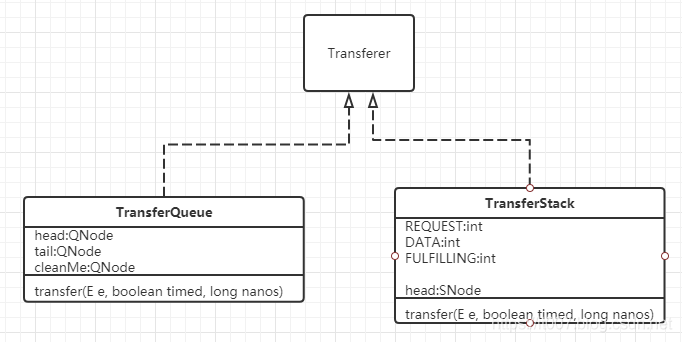
Transferer is an internal abstract class of SynchronousQueue, which is shared by dual stack and dual queue algorithms. It has only one transfer method, which is used to transfer elements from producers to consumers; Or the consumer calls this method to get data from the producer.
The concept of producer and consumer is borrowed here. In fact, SynchronousQueue is also a special producer consumer implementation.
abstract static class Transferer<E> {
abstract E transfer(E e, boolean timed, long nanos);
}
Because the SynchronousQueue queue has no capacity, the operations of producers and consumers will be similar. Here, the jdk author abstracts it into a method to implement put and take operations. It simplifies the code, but makes it a little more difficult to read.
The first parameter e of transfer: if it is not empty, it is put data, but the current thread needs to wait for the consumer to take the data before it can return.
If it is empty, the consumer will fetch the data. If there is no data to fetch, it will be blocked. The data he took is the data put in by the producer.
timed: Whether to set timeout. nanos: Timeout.
If the return value of the transfer method is empty, it represents timeout or interruption.
Transferer has two implementation classes: TransferQueue and TransferStack.
The difference between these two classes is whether they are fair or not. TransferQueue is fair and TransferStack is not fair.
public SynchronousQueue() {
this(false);
}
//Constructor to specify the fairness policy. Default is unfair
public SynchronousQueue(boolean fair) {
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
}
Next, analyze the source code of the fair mode TransferQueue.
3.TransferQueue
TransferQueue is an extension of Scherer Scott dual queue algorithm. It uses internal nodes instead of marker pointers.
Important attributes:
// Head and tail nodes of the queue transient volatile QNode head; transient volatile QNode tail; /** * It refers to the node that has been cancelled. This node may not be disconnected from the queue because it is the last inserted node when canceling */ transient volatile QNode cleanMe;
Two main methods:
public void put(E e) throws InterruptedException {
if(e == null) throw new NullPointerException();
if (transferer.transfer(e, false, 0) == null) {//The return value is null, which means timeout or interruption
Thread.interrupted();//Reset the interrupt state and throw an interrupt exception
throw new InterruptedException();
}
}
public E take() throws InterruptedException {
E e = transferer.transfer(null, false, 0);
if (e != null)
return e;
Thread.interrupted();//Reset the interrupt state and throw an interrupt exception
throw new InterruptedException();
}
put: add the formulation element to the queue and wait for a thread to take it away
Take:: take an element from the counterpart. If the queue is empty, wait for another thread to insert into the node
4.QNode
QNode is the internal class of TransferQueue and represents the internal node. It has only one next pointer, a typical one-way linked list structure.
static final class QNode {
volatile QNode next;
volatile Object item; // Use the CAS operation to set the item value, from null to a value, or set it to null
volatile Thread waiter; // Thread waiting. This field is used to control the park and unpark operations
final boolean isData; // Used to determine whether it is a write thread (producer) or a read thread (consumer)
}
5.transfer method
The basic idea of transfer:
Cycle through the following two situations:
-
If the queue is empty or all nodes in the queue are in the same mode, add the current node to the waiting queue. Wait for completion or cancellation, and then return the matching item
-
If a waiting node already exists in the queue and the mode of the waiting node is different from that of the current node, the peer node of the queue will be queued out and the matching item will be returned.
The translation may not be very good. Here, paste the original English text:
- If queue apparently empty or holding same-mode nodes, try to add node to queue of waiters,
wait to be fulfilled (or cancelled) and return matching item. - If queue apparently contains waiting items, and this call is of complementary mode,
try to fulfill by CAS'ing item field of waiting node and dequeuing it, and then returning matching item.
In fact, it's also easy to understand. Since SynchronousQueue is a synchronous blocking queue and does not store any data (threads are stored in the waiting queue, not data queue), when the queue is empty and a put request comes, he will join the queue and wait for take to take away the data. If there are many put threads waiting in the queue when a put request comes, the thread will directly join the queue. If there are many take threads waiting, it means that there are many threads waiting to get data. Then directly give the data to the first thread waiting.
vice versa.
The implication here is that if the queue is not empty, their mode (read or write) must be the same.
//When the constructor initializes the TransferQueue, it initializes a virtual node to which both head and tail point
TransferQueue() {
QNode h = new QNode(null, false); // initialize to dummy node.
head = h;
tail = h;
}
E transfer(E e, boolean timed, long nanos) {
QNode s = null; // constructed/reused as needed
//isData: true indicates write and false indicates read
boolean isData = (e != null);//e is not empty, indicating that it comes with data and is a write thread (producer)
for (;;) {
QNode t = tail;
QNode h = head;
if (t == null || h == null) // If both head and tail are empty, loop until one is not empty.
continue;
if (h == t || t.isData == isData) { // If the queue is empty or the mode (read or write) is the same
QNode tn = t.next;
if (t != tail) // Verify again whether t is consistent with tail. Because there is no lock, multithreading, and the tail pointer may change
continue;
if (tn != null) { // Similarly, t.next may have a value due to multithreading. Imagine that another thread adds a new node and the tail moves back one bit. At this time, t still points to the old tail, so t.next has a value.???
advanceTail(t, tn);//
continue;
}
if (timed && nanos <= 0L) // can't wait
return null;
if (s == null)
s = new QNode(e, isData);//New node for adding to the waiting queue
if (!t.casNext(null, s)) // CAS sets the next node. If the setting fails, try again
continue;
advanceTail(t, s); // Move tail pointer
Object x = awaitFulfill(s, e, timed, nanos);
if (x == s) { // wait was cancelled
clean(t, s);
return null;
}
if (!s.isOffList()) { // not already unlinked
advanceHead(t, s); // unlink if head
if (x != null) // and forget fields
s.item = s;
s.waiter = null;
}
return (x != null) ? (E)x : e;
} else { // complementary-mode
QNode m = h.next; // node to fulfill
if (t != tail || m == null || h != head)
continue; // inconsistent read
Object x = m.item;
if (isData == (x != null) || // m already fulfilled
x == m || // m cancelled
!m.casItem(x, e)) { // lost CAS
advanceHead(h, m); // dequeue and retry
continue;
}
advanceHead(h, m); // successfully fulfilled
LockSupport.unpark(m.waiter);
return (x != null) ? (E)x : e;
}
}
}
void advanceTail(QNode t, QNode nt) {
if (tail == t)
QTAIL.compareAndSet(this, t, nt);
}
Object awaitFulfill(QNode s, E e, boolean timed, long nanos) {
/* Same idea as TransferStack.awaitFulfill */
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
int spins = (head.next == s)
? (timed ? MAX_TIMED_SPINS : MAX_UNTIMED_SPINS)
: 0;
for (;;) {
if (w.isInterrupted())
s.tryCancel(e);
Object x = s.item;
if (x != e)
return x;
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel(e);
continue;
}
}
if (spins > 0) {
--spins;
Thread.onSpinWait();
}
else if (s.waiter == null)
s.waiter = w;
else if (!timed)
LockSupport.park(this);
else if (nanos > SPIN_FOR_TIMEOUT_THRESHOLD)
LockSupport.parkNanos(this, nanos);
}
}