This is the first article in the Java Web Crawler series. If you don't know about the Java Web Crawler series, see What basic knowledge do you need to learn Java web crawler? This is the case. The first one is about the introduction of Java web crawler. In this article, we take the news headlines and details pages of Hupu List as an example. The contents we need to extract are as follows:
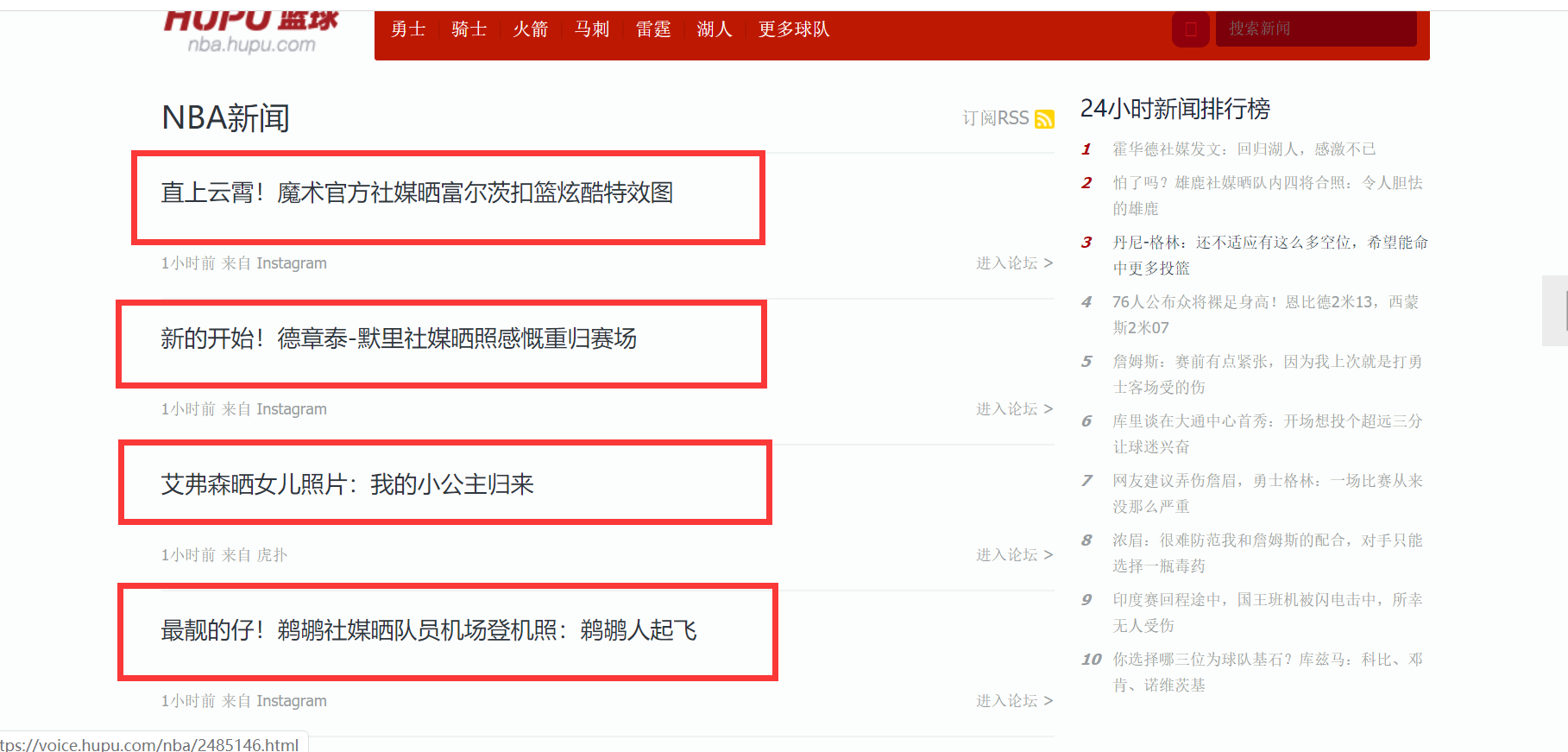
We need to extract the circled text and its corresponding links. In the process of extracting, we will use two ways to extract, one is Jsoup, the other is httpclient + regular expression. This is also the two common ways used by Java web crawlers. You don't know that these two ways are irrelevant. There will be corresponding manual later. Before I formally write the extraction program, I will explain the environment of Java crawler series blog posts. All demo s in this series of blog posts are built using SpringBoot. Whatever environment you use, you just need to import the appropriate package correctly.
Jsoup-based information extraction
Let's use Jsoup to extract news information. If you don't know about Jsoup, please refer to it. https://jsoup.org/
Start by creating a Springboot project with a random name and introducing Jsoup dependencies into pom.xml
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.12.1</version>
</dependency>Okay, let's analyze the page together. You haven't browsed it yet, presumably. Click here to browse Hupu News This is the case. In the list page, we use the F12 review element to view the page structure. After our analysis, we find that the list news is under the <div class="news-list"> tag, and each news is a li tag. The analysis results are as follows:
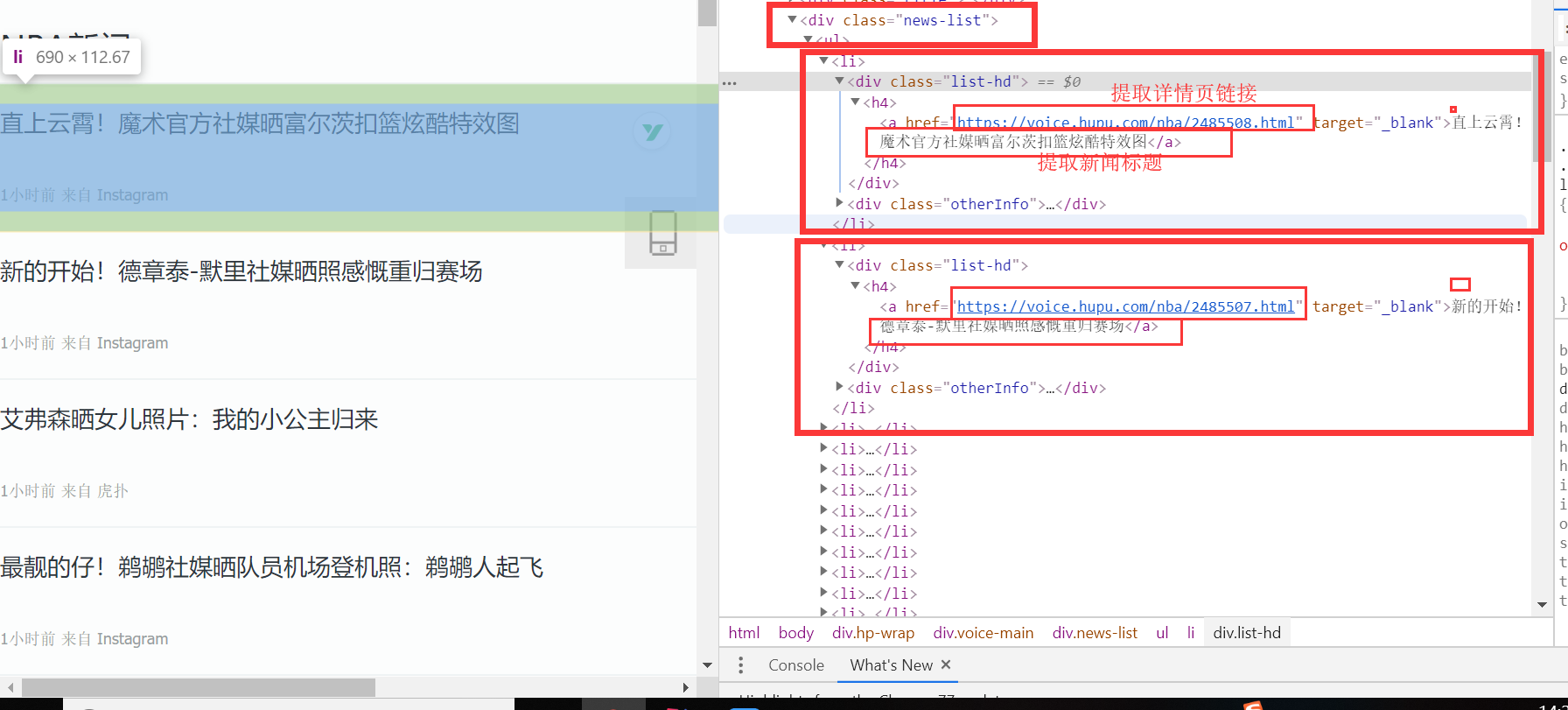
Because we already know the css selector before, we compiled the code of css selector of our a tag: Div. news-list > UL > Li > Div. list-hd > H4 > a, combining with the opy function of browser. Everything is ready. We compiled the code of extracting information in Jsoup mode together:
/**
* jsoup Ways to Get Tiger Pop News List Page
* @param url Hupu News List page url
*/
public void jsoupList(String url){
try {
Document document = Jsoup.connect(url).get();
// Using css selector to extract list news a tag
// <a href= "https://voice.hupu.com/nba/2484553.html" target="_blank">Howard: I had a 30-day diet during the summer break, which tested my mind and body.</a>
Elements elements = document.select("div.news-list > ul > li > div.list-hd > h4 > a");
for (Element element:elements){
// System.out.println(element);
// Get Details Page Links
String d_url = element.attr("href");
// Get the title
String title = element.ownText();
System.out.println("Details page links:"+d_url+" ,Details page title:"+title);
}
} catch (IOException e) {
e.printStackTrace();
}
}Using Jsoup to extract information is still very simple. It is completed in 5 or 6 lines of code. For more information about how Jsoup extracts node information, you can refer to the official website tutorial of jsoup. Let's write the main method to execute the jsoupList method and see if the jsoupList method is correct.
public static void main(String[] args) {
String url = "https://voice.hupu.com/nba";
CrawlerBase crawlerBase = new CrawlerBase();
crawlerBase.jsoupList(url);
}The main method is executed and the following results are obtained:
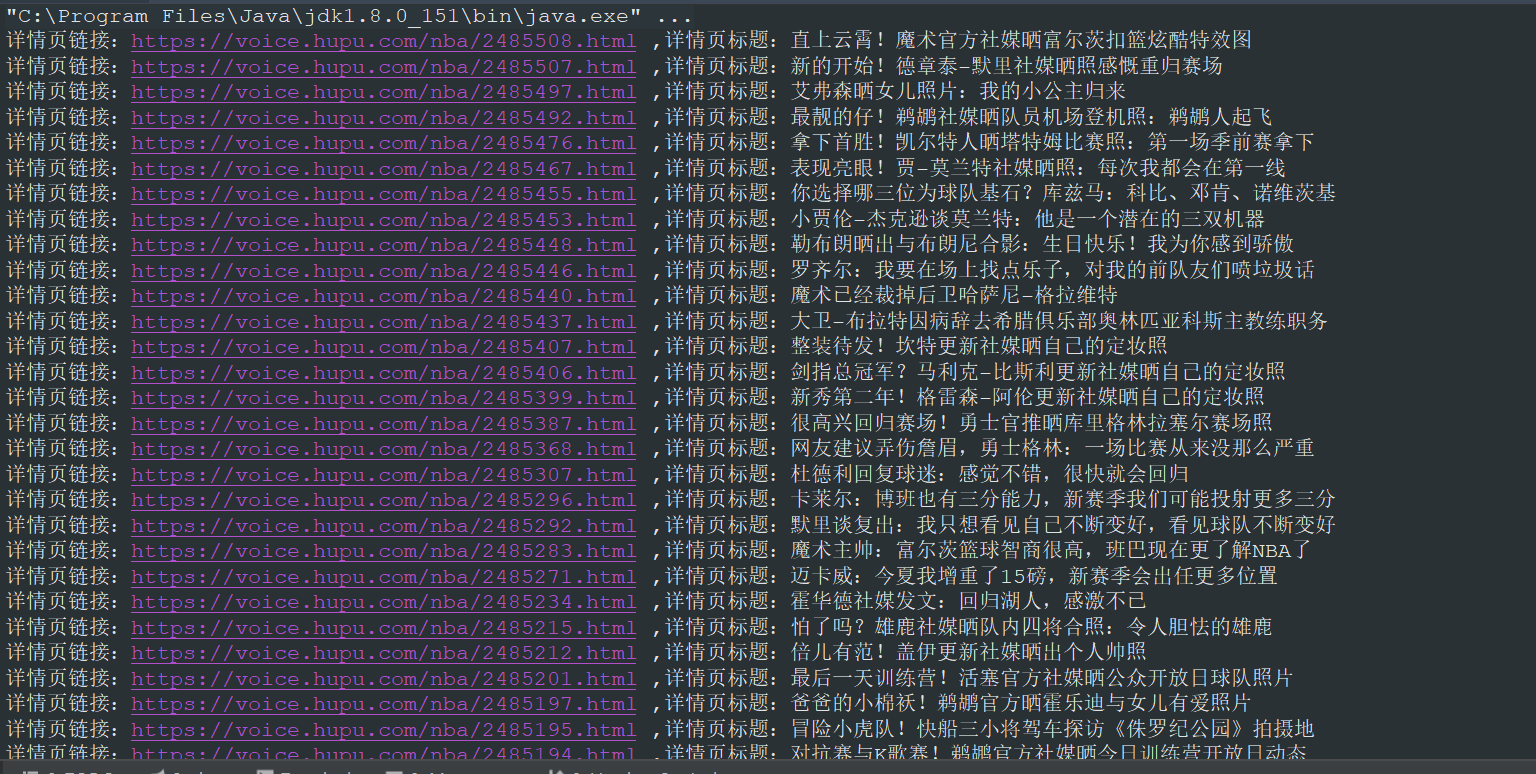
From the results, we can see that we have correctly extracted the information we want. If you want to collect the information of detail pages, you just need to write a method of collecting detail pages, extract the corresponding node information of detail pages in the method, and then pass the link extracted from list pages into the method of extracting detail pages.
httpclient + regular expression
Above, we used Jsoup to extract tiger pool list news correctly. Next, we use httpclient + regular expression to extract tiger pool list news. What problems will be involved in using this method? The way of httpclient + regular expression involves a lot of knowledge points. It involves regular expression, Java regular expression and httpclient. If you don't know that yet, you can click on the link below for a brief understanding.
Regular expressions: regular expression
Java regular expressions: Java Regular Expressions
httpclient: httpclient
In the pom.xml file, we introduced the httpclient related Jar package
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.10</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpcore</artifactId>
<version>4.4.10</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpmime</artifactId>
<version>4.5.10</version>
</dependency>With regard to the news page of Tiger Pop List, we have made a simple analysis when using Jsoup mode. Here we will not repeat the analysis. For regular expression extraction, we need to find structures that can represent list news, such as <div class="list-hd"> <h4> <a href="https://voice.hupu.com/nba/2485508.html" target="_blank"> straight up the sky! Magic official media exposed Fultz dunk cool special effect map </a> </h4> </div> this structure, each list news only links and headlines are different, the rest are the same, and <div class= "list-hd"> is unique to list news. It's better not to match a tag regularly, because a tag also exists in other places, so we need to do other processing to increase our difficulty. Now that we understand the selection of regular constructs, let's look at the code extracted by httpclient + regular expression mode:
/**
* httpclient + Regular Expressions Get Tiger Pop News List Pages
* @param url Hupu News List page url
*/
public void httpClientList(String url){
try {
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(url);
CloseableHttpResponse response = httpclient.execute(httpGet);
if (response.getStatusLine().getStatusCode() == 200) {
HttpEntity entity = response.getEntity();
String body = EntityUtils.toString(entity,"utf-8");
if (body!=null) {
/*
* Replace line breaks, tabs, carriage returns, and remove these symbols. Regular representations are simpler to write.
* Only space symbols and other normal fonts
*/
Pattern p = Pattern.compile("\t|\r|\n");
Matcher m = p.matcher(body);
body = m.replaceAll("");
/*
* Extracting regular expressions from list pages
* li after line breaks are removed
* <div class="list-hd"> <h4> <a href="https://voice.hupu.com/nba/2485167.html" target="_blank">Interaction with fans! Celtic Official Sunshine Team Open Training Day Photos </a> </h4> </div>
*/
Pattern pattern = Pattern
.compile("<div class=\"list-hd\">\\s* <h4>\\s* <a href=\"(.*?)\"\\s* target=\"_blank\">(.*?)</a>\\s* </h4>\\s* </div>" );
Matcher matcher = pattern.matcher(body);
// Match all data that conforms to regular expressions
while (matcher.find()){
// String info = matcher.group(0);
// System.out.println(info);
// Extract links and titles
System.out.println("Details page links:"+matcher.group(1)+" ,Details page title:"+matcher.group(2));
}
}else {
System.out.println("Handling failure!!! Get the text empty");
}
} else {
System.out.println("Handling failure!!! Return status code:" + response.getStatusLine().getStatusCode());
}
}catch (Exception e){
e.printStackTrace();
}
}From the number of lines of code, we can see that there are many more than Jsource mode. Although there are many codes, it is relatively simple as a whole. In the above method, I made a special treatment. First, I replaced the line breaks, tabs and carriage return characters in the string body obtained by httpclient, because this treatment can reduce some additional interference when writing regular expressions. Next, we modify the main method to run the httpClientList method.
public static void main(String[] args) {
String url = "https://voice.hupu.com/nba";
CrawlerBase crawlerBase = new CrawlerBase();
// crawlerBase.jsoupList(url);
crawlerBase.httpClientList(url);
}The results of the operation are as follows:
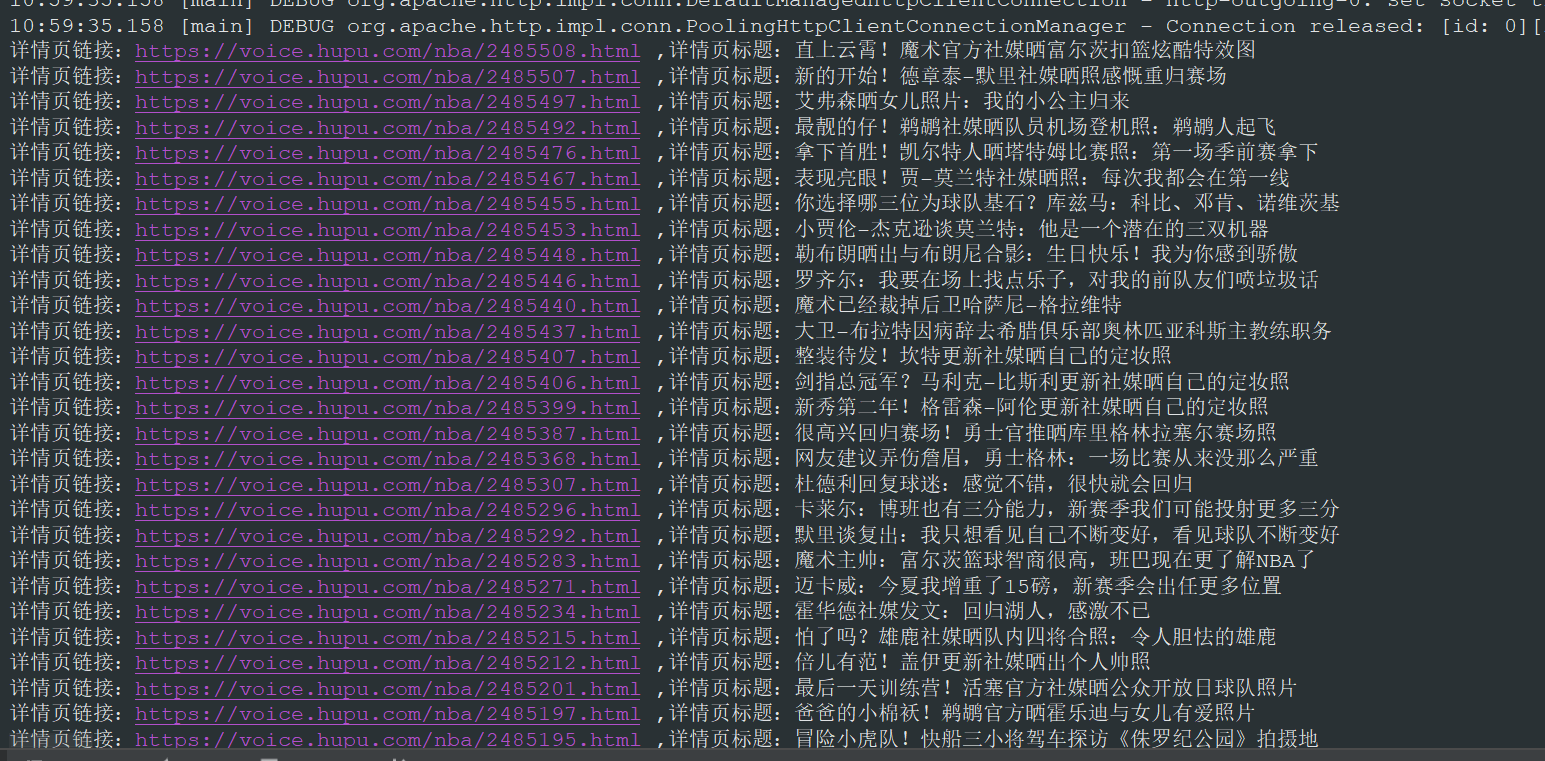
Using httpclient + regular expressions, the title and details page links of list news are also correctly obtained. This is the first article in the Java crawler series. This article is mainly about the introduction of Java web crawler. We use jsource and httpclient + to extract news headlines and links to detail pages of Hupu List news in a regular way. Of course, there are still many incomplete, such as collecting details page information into the database.
Hope the above content will help you. The next one is about simulated landing. If you are interested in Java web crawlers, you might as well pay attention to a wave, learn together, and make progress together.
Source code: click here
The article's shortcomings, I hope you can give more advice, learn together, and make progress together.
Last
Play a small advertisement. Welcome to pay close attention to the Wechat Public Number: "Hirago's Technological Blog" and make progress together.