Stream overview
What is flow
Stream is not a collection element. It is not a data structure and does not save data. It is about algorithms and calculations. It is more like an advanced version of Iterator. In the original version of Iterator, users can only explicitly traverse elements one by one and perform some operations on them; In the advanced version of stream, users only need to give what operations they need to perform on the elements contained in it, such as "filter out strings with a length greater than 10", "get the first letter of each string", etc. the stream will implicitly traverse internally and make corresponding data conversion.
Stream is like an Iterator. It is unidirectional and cannot be reciprocated. The data can only be traversed once. After traversing once, it is exhausted. It is like running water flowing in front of you and never returns.
Unlike iterators, Stream can operate in parallel, and iterators can only operate in command and serialization. As the name suggests, when traversing in serial mode, read each item before reading the next item. When parallel traversal is used, the data will be divided into multiple segments, each of which will be processed in different threads, and then the results will be output together. The parallel operation of Stream relies on the Fork/Join framework (JSR166y) introduced in Java 7 to split tasks and speed up the processing process. The evolution of Java's parallel API is basically as follows:
Java. In 1.0-1.4 lang.Thread
Java in 5.0 util. concurrent
Phasers in 6.0, etc
Fork/Join framework in 7.0
Lambda in 8.0
Composition of flow
When we use a stream, there are usually three basic steps:
Obtain a data source → data conversion → execute the operation to obtain the desired result. Each time the original Stream object is converted, a new Stream object is returned (there can be multiple conversions), which allows the operation to be arranged like a chain and become a pipeline, as shown in the figure below.
Figure 1 Composition of stream pipeline
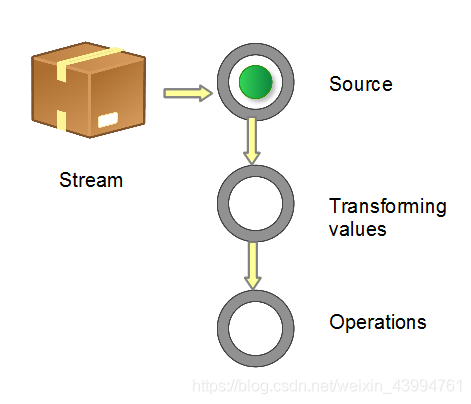
There are several ways to generate a Stream Source:
-
From Collection and array
. Collection.stream()
. Collection.parallelStream()
. Arrays.stream(T array) or Stream.of() -
Static factory
. java.util.stream.IntStream.range()
. java.nio.file.Files.walk() -
Build yourself
. java.util.Spliterator
. other
. Random.ints()
. BitSet.stream()
. Pattern.splitAsStream(java.lang.CharSequence)
. JarFile.stream()
There are two types of operations for streams:
-
Intermediate operator: a stream can be followed by zero or more intermediate operations. Its main purpose is to open the flow, make some degree of data mapping / filtering, and then return a new flow for the next operation. Such operations are lazy, that is, only calling such methods does not really start the traversal of the flow.
-
Terminal operator: a flow can only have one terminal operation. When this operation is executed, the flow will be used as "light" and can no longer be operated. So it must be flowing
Last operation. Only when the Terminal operation is executed can the traversal of the stream really begin, and a result or a side effect will be generated
When performing multiple Intermediate operations on a Stream, each element of the Stream is converted and executed multiple times each time. Is the time complexity the sum of all operations done in N (conversion times) for loops? In fact, this is not the case. All conversion operations are lazy. Multiple conversion operations will only be integrated during Terminal operation and completed in one cycle. We can simply understand that there is a set of operation functions in the Stream. Each conversion operation is to put the conversion function into this set, cycle the set corresponding to the Stream during the Terminal operation, and then execute all functions for each element.
In short, the use of Stream is to implement a filter map reduce process, produce an end result, or cause a side effect.
Construction and transformation of flow
The following provides examples of the most common ways to construct streams.
Several common methods of constructing flow
// 1. Individual values
Stream stream = Stream.of("a", "b", "c");
// 2. Arrays
String [] strArray = new String[] {"a", "b", "c"};
stream = Stream.of(strArray);
stream = Arrays.stream(strArray);
// 3. Collections
List<String> list = Arrays.asList(strArray);
stream = list.stream();
It should be noted that for the basic numerical type, there are three corresponding packaging types: Stream:
IntStream,LongStream,DoubleStream. Of course, we can also use Stream, Stream >, Stream, but boxing and unboxing will be time-consuming, so we provide corresponding streams for these three basic numerical types.
Convert stream to other data structures
// 1. Array String[] strArray1 = stream.toArray(String[]::new); // 2. Collection List<String> list1 = stream.collect(Collectors.toList()); List<String> list2 = stream.collect(Collectors.toCollection(ArrayList::new)); Set set1 = stream.collect(Collectors.toSet()); Stack stack1 = stream.collect(Collectors.toCollection(Stack::new)); // 3. String String str = stream.collect(Collectors.joining()).toString();
A Stream can only be used once, and the above code has been reused several times for simplicity.
matters needing attention
Another thing to note is that forEach is a terminal operation, so after it is executed, the elements of the Stream will be "consumed", and you cannot perform two terminal operations on a Stream. The following code is wrong:
stream.forEach(element -> doOneThing(element)); stream.forEach(element -> doAnotherThing(element));
forEach cannot modify its own local variable value, nor can it end the loop in advance with keywords such as break/return.
Intermediate operator
For data flow, after the intermediate operator executes the specified processing program, the data flow can still be passed to the next level operator.
There are 8 kinds of intermediate operators (parallel and sequential are excluded, which do not involve the processing of data flow):
- Map (mapto int, mapto long, mapto double) conversion operators, such as a - > b, are provided by default.
- flatmap(flatmapToInt,flatmapToLong,flatmapToDouble) flattening operation, such as flattening int[]{2,3,4} into 2,3,4, that is, from one data to three data. Here, the operator of flattening into int,long,double is provided by default.
- limit current limiting operation. For example, if there are 10 data streams, I can use the first 3.
- Distinct de duplication operation, de duplication of repeated elements, and the equals method is used at the bottom.
- Filter operation to filter unwanted data.
- peek pick out operation. If you want to perform some operations on the data, such as reading, editing and modifying.
- Skip skip operation, skip some elements.
- sorted(unordered) sorting operation is used to sort elements. The premise is to implement the Comparable interface. Of course, you can also customize the comparator.
map
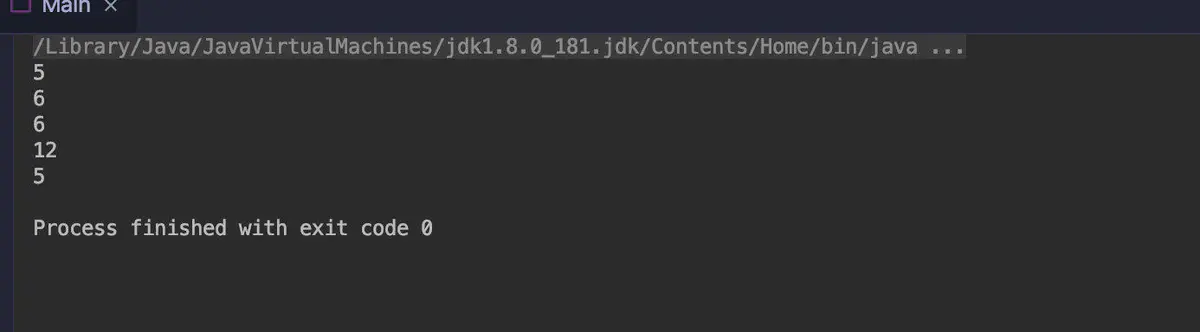
1. In simple use, the map operation converts the original word into the length of each order, and uses the length() method of String itself, which returns the type of int.
public class Main {
public static void main(String[] args) {
Stream.of("apple","banana","orange","waltermaleon","grape")
.map(String::length) //Length converted to word int
.forEach(System.out::println);
}
}
The results are shown in the figure below:
2. Object attribute extraction
Extract the name attribute in the UserVO object into an array
public static void main(String[] args) {
List<UserVO> userVOs = new ArrayList<>();
userVOs.add(new UserVO("Zhang San", 13));
userVOs.add(new UserVO("Li Si", 15));
userVOs.add(new UserVO("Wang Wu", 18));
testStreamMap(userVOs);
}
public static void testStreamMap(List<UserVO> userVOs) {
List<String> userNames = userVOs.stream().map(UserVO::getName).collect(Collectors.toList());
userNames.stream().forEach(item-> System.out.println(item));
}
3. Building objects based on attributes
public static void testStreamMap2() {
Stream.of("Zhang San", "Li Si", "Wang Wu").map(s -> new UserVO(s, 18)).forEach(item-> System.out.println(item.getName()));
}
4. Convert to uppercase
List<String> output = wordList.stream(). map(String::toUpperCase). collect(Collectors.toList());
5. Square number
List<Integer> nums = Arrays.asList(1, 2, 3, 4); List<Integer> squareNums = nums.stream(). map(n -> n * n). collect(Collectors.toList());
mapToInt
Convert the element in the data stream to int, which limits the type of conversion int, the resulting stream is IntStream, and the result can only be converted to int.
public class Main {
public static void main(String[] args) {
Stream.of("apple", "banana", "orange", "waltermaleon", "grape")
.mapToInt(e -> e.length()) //Convert to int
.forEach(e -> System.out.println(e));
}
}
mapToLong and mapToDouble are similar to mapToInt
flatmap
The function of flatmap is to flatten and flatten the elements, reorganize the flattened elements into a Stream, and merge these streams into a Stream in series.
public class Main {
public static void main(String[] args) {
Stream.of("a-b-c-d","e-f-i-g-h")
.flatMap(e->Stream.of(e.split("-")))
.forEach(e->System.out.println(e));
}
}
limit
Limit the number of elements. Just pass in the long type to indicate the maximum number of restrictions
public class Main {
public static void main(String[] args) {
Stream.of(1,2,3,4,5,6)
.limit(3) //Limit three
.forEach(e->System.out.println(e)); //The first three 1, 2 and 3 will be output
}
}
distinct
duplicate removal
public class Main {
public static void main(String[] args) {
Stream.of(1,2,3,1,2,5,6,7,8,0,0,1,2,3,1)
.distinct() //duplicate removal
.forEach(e->System.out.println(e));
}
}
filter
Some elements are filtered, and those that do not meet the screening conditions will not be able to enter the downstream of the stream
public class Main {
public static void main(String[] args) {
Stream.of(1,2,3,1,2,5,6,7,8,0,0,1,2,3,1)
.filter(e->e>=5) //Filter less than 5
.forEach(e->System.out.println(e));
}
}
skip
Skip element
public class Main {
public static void main(String[] args) {
Stream.of(1,2,3,4,5,6,7,8,9)
.skip(4) //Skip the first four
.forEach(e->System.out.println(e)); //The output should be only 5, 6, 7, 8, 9
}
}
sorted
The bottom layer of sorting depends on the Comparable implementation, and a user-defined comparator can also be provided.
The sorting of streams is carried out through sorted, which is stronger than the sorting of arrays. The reason is that you can first carry out various map s, filter s, limit s, skip and even distinct on streams to reduce the number of elements before sorting, which can help the program significantly shorten the execution time.
1. Simple sorting
public class Main {
public static void main(String[] args) {
Stream.of(2,1,3,6,4,9,6,8,0)
.sorted()
.forEach(e->System.out.println(e));
}
}
2. Sort by field in object
//positive sequence List<UserVO> sortedList = list.stream().sorted(Comparator.comparing(UserVO::getAge)).collect(Collectors.toList()); //Reverse order List<UserVO> reverseSortedList = list.stream().sorted(Comparator.comparing(UserVO::getAge).reversed()).collect(Collectors.toList());
Termination operator
After the data is processed in the middle, it is the end operator's turn to play; The termination operator is used to collect or consume data. The data will not flow downward when it comes to the termination operation. The termination operator can only be used once.
- collect collects all data. This operation is very important. The official Collectors provide many Collectors. It can be said that the core of Stream lies in Collectors.
- Count statistics operation to count the final number of data.
- findFirst and findAny search operations. The return type of the first and any search operations is Optional.
- The values of match and Boolean match in the operation flow are whether they match the conditions.
- For min and max maximum operations, you need to customize the comparator to return the maximum and minimum values in the data stream.
- Reduce protocol operation, which regulates the value of the whole data stream into one value. The bottom layer of count, min and max is to use reduce.
- forEach and forEachOrdered traversal operations, where the final data is consumed.
- toArray array operation, which converts the elements of the data stream into an array.
Collect (core)
Collection: the collector provided by the system can be used to collect the final data stream into containers such as List, Set and Map.
1. Simple example
public class Main {
public static void main(String[] args) {
Stream.of("apple", "banana", "orange", "waltermaleon", "grape")
.collect(Collectors.toSet()) //set container
.forEach(e -> System.out.println(e));
}
}
2. Convert Stream to container or Map
// Convert Stream to container or Map
Stream<String> stream = Stream.of("I", "love", "you", "too");
List<String> list = stream.collect(Collectors.toList()); // (1)
Set<String> set = stream.collect(Collectors.toSet()); // (2)
Map<String, Integer> map = stream.collect(Collectors.toMap(Function.identity(), String::length)); // (3)
The above code lists how to convert Stream into List, Set and Map respectively. Although the semantics of the code is very clear, we still have several questions:
Function. What does identity () do?
What does String::length mean?
What are Collectors?
Static method and default method of interface
If Function is an interface, then Function What does identity () mean? This should be explained from two aspects:
1.Java 8 allows you to add specific methods to the interface. There are two specific methods in the interface: default method and static method. identity() is a static method of Function interface.
2.Function.identity() returns a Lambda expression object whose output is the same as the input, which is equivalent to a Lambda expression in the form of T - > t.
Does the above explanation give you more questions? Don't ask me why there are specific methods in the interface, and don't tell me that you think t - > t is more intuitive than the identity() method. I will tell you that the default method in the interface is a helpless move. It is very difficult or even impossible to add new abstract methods to the defined interface in Java 7 and before, because all classes that implement the interface must be re implemented. Imagine adding a stream() abstract method to the Collection interface? The default method is used to solve this embarrassing problem by directly implementing the newly added method in the interface. Since the default method has been introduced, why not add the static method to avoid special tool classes!
Method reference
Syntax forms such as String::length are called method references. This syntax is used to replace some specific forms of Lambda expressions
count
Count the number of elements in the data stream, and return the long type.
public class Main {
public static void main(String[] args) {
long count = Stream.of("apple", "banana", "orange", "waltermaleon", "grape")
.count();
System.out.println(count);
}
}
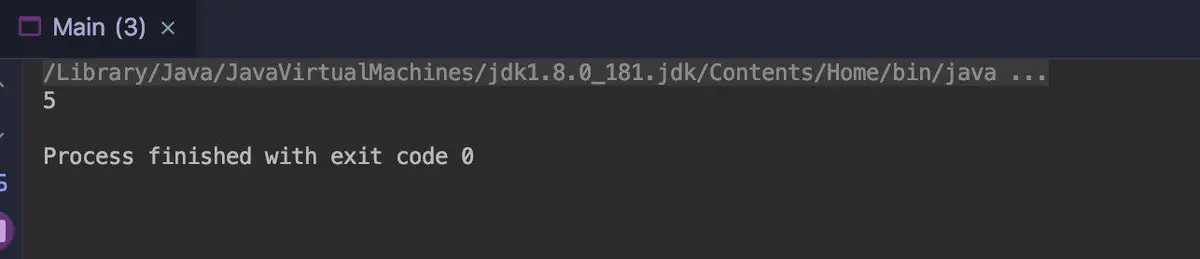
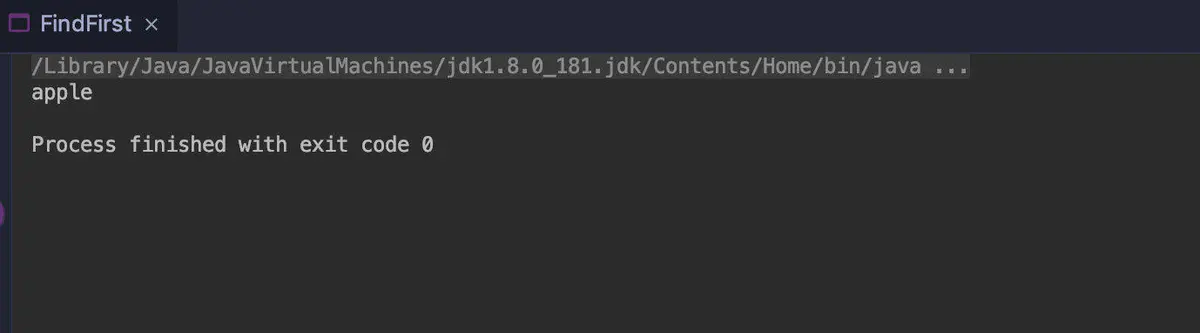
findFirst
Get the first element in the stream, or empty.
The focus here is on its return value type: Optional. This is also a concept that imitates the Scala language. As a container, it may or may not contain a value. The purpose of using it is to avoid NullPointerException as much as possible.
public class FindFirst {
public static void main(String[] args) {
Optional<String> stringOptional = Stream.of("apple", "banana", "orange", "waltermaleon", "grape")
.findFirst();
stringOptional.ifPresent(e->System.out.println(e));
}
}
findAny
Gets any element in the stream.
public class FindAny {
public static void main(String[] args) {
Optional<String> stringOptional = Stream.of("apple", "banana", "orange", "waltermaleon", "grape")
.parallel()
.findAny(); //In parallel flow, the results returned each time may be the same or different
stringOptional.ifPresent(e->System.out.println(e));
}
}
Match
Stream has three match methods. Semantically speaking:
allMatch: all elements in the Stream conform to the incoming predicate and return true
anyMatch: as long as one element in the Stream matches the incoming predicate, it returns true
noneMatch: none of the elements in the Stream match the incoming predicate, and return true
None of the elements in the noneMatch data stream match the condition.
public class NoneMatch {
public static void main(String[] args) {
boolean result = Stream.of("aa","bb","cc","aa")
.noneMatch(e->e.equals("aa"));
System.out.println(result);
}
}
allMatch,anyMatch
List<Person> persons = new ArrayList();
persons.add(new Person(1, "name" + 1, 10));
persons.add(new Person(2, "name" + 2, 21));
persons.add(new Person(3, "name" + 3, 34));
persons.add(new Person(4, "name" + 4, 6));
persons.add(new Person(5, "name" + 5, 55));
boolean isAllAdult = persons.stream().
allMatch(p -> p.getAge() > 18);
System.out.println("All are adult? " + isAllAdult);
boolean isThereAnyChild = persons.stream().
anyMatch(p -> p.getAge() < 12);
System.out.println("Any child? " + isThereAnyChild);
Output:
All are adult? false Any child? true
min
The smallest one, the incoming comparator, may not be available (if the data stream is empty)
public class Main {
public static void main(String[] args) {
Optional<Integer> integerOptional = Stream.of(0,9,8,4,5,6,-1)
.min((e1,e2)->e1.compareTo(e2));
integerOptional.ifPresent(e->System.out.println(e));
}
max
The largest element needs to be passed into the comparator, or it may not (when the flow is Empty).
public class Main {
public static void main(String[] args) {
Optional<Integer> integerOptional = Stream.of(0,9,8,4,5,6,-1)
.max((e1,e2)->e1.compareTo(e2));
integerOptional.ifPresent(e->System.out.println(e));
}
}
forEachOrdered
It is suitable for iteration in the case of parallel flow, and can ensure the order of iteration.
public class ForEachOrdered {
public static void main(String[] args) {
Stream.of(0,2,6,5,4,9,8,-1)
.parallel()
.forEachOrdered(e->{
System.out.println(Thread.currentThread().getName()+": "+e);});
}
}
Collector collector (key)
The Collector is stream A tool interface (class) tailored for the collect () method.
Generate a Map using collect()
As mentioned earlier, the back of Stream depends on some data source. The data source can be array, container, etc., but not Map. Conversely, it is possible to generate a Map from a Stream, but we need to figure out what the key and value of the Map represent respectively. The fundamental reason is that we need to figure out what to do. Generally, the result of collect() is Map in three cases:
1. Use collectors For the collector generated by tomap (), the user needs to specify how to generate the key and value of the Map.
2. Use collectors The collector generated by partitioningby() is used when performing two partition operations on elements.
3. Use collectors The collector generated by groupingby() is used when performing group operations on elements.
Case 1: the collector generated by toMap() is the most direct. As mentioned in the previous example, this is the same as collectors Tocollection(). The following code shows how to convert the student list into a Map composed of < student, GPA >. Very intuitive, no need to say more.
// Use toMap() to count student GPA
Map<Student, Double> studentToGPA =
students.stream().collect(Collectors.toMap(Functions.identity(),// How to generate a key
student -> computeGPA(student)));// How to generate value
Case 2: the collector generated using partitioningBy(), which is applicable to dividing the elements in the Stream into two complementary and intersecting parts according to a binary logic (whether they meet the conditions or not), such as gender, pass or not. The following code shows that students are divided into two parts: pass or fail.
// Partition students into passing and failing
Map<Boolean, List<Student>> passingFailing = students.stream()
.collect(Collectors.partitioningBy(s -> s.getGrade() >= PASS_THRESHOLD));
Case 3: use the collector generated by groupingBy(), which is a flexible case. Similar to the group by statement in SQL, groupingby () here also groups data according to a certain attribute, and elements with the same attribute will be corresponding to the same key in the Map. The following code shows employees grouped by department:
// Group employees by department
Map<Department, List<Employee>> byDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment));
The above is just the basic usage of grouping. Sometimes just grouping is not enough. group by is used in SQL to assist other queries, such as 1 First group employees by department, 2 Then count the number of employees in each department. The designer of Java class library has also considered this situation, and the enhanced version of groupingBy() can meet this demand. The enhanced version of groupingBy() allows us to group elements before performing certain operations, such as summation, counting, averaging, type conversion, etc. The collector that groups elements first is called an upstream collector, and the collector that performs other operations later is called a downstream collector.
// Use downstream collectors to count the number of people in each department
Map<Department, Integer> totalByDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment,
Collectors.counting()));// Downstream collector
Does the logic of the above code look more like SQL? Highly unstructured. What's more, downstream collectors can also include more downstream collectors, which is not a trick added to show off technology, but the needs of the actual scene. Consider the scenario of grouping employees by department. If we want to get the name (string) of each Employee instead of one Employee object, we can do it in the following ways:
// Distribute groups of employees according to departments and keep only the names of employees
Map<Department, List<String>> byDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment,
Collectors.mapping(Employee::getName,// Downstream collector
Collectors.toList())));// Further downstream collector
Use collect() to do string join
This must be a favorite function. Collectors are used for string splicing The collector generated by joining() bid farewell to the for loop. Collectors. The joining () method has three rewriting forms, corresponding to three different splicing methods. Needless to say, the code is unforgettable.
// Using collectors Joining() splicing string
Stream<String> stream = Stream.of("I", "love", "you");
//String joined = stream.collect(Collectors.joining());// "Iloveyou"
//String joined = stream.collect(Collectors.joining(","));// "I,love,you"
String joined = stream.collect(Collectors.joining(",", "{", "}"));// "{I,love,you}"
Optional
This is also a concept that imitates the Scala language. As a container, it may or may not contain a value. The purpose of using it is to avoid NullPointerException as much as possible.
Two use cases of Optional
String strA = " abcd ", strB = null;
print(strA);
print("");
print(strB);
getLength(strA);
getLength("");
getLength(strB);
public static void print(String text) {
// Java 8
Optional.ofNullable(text).ifPresent(System.out::println);
// Pre-Java 8
if (text != null) {
System.out.println(text);
}
}
public static int getLength(String text) {
// Java 8
return Optional.ofNullable(text).map(String::length).orElse(-1);
// Pre-Java 8
// return if (text != null) ? text.length() : -1;
};
In the case of more complex if (XX! = null), the readability of using Optional code is better, and it provides compile time check, which can greatly reduce the impact of Runtime Exception such as NPE on the program, or force programmers to deal with null problems earlier in the coding phase, rather than leaving it to be found and debugged at runtime.
The findAny, max/min, reduce and other methods in Stream return Optional values. Another example is intstream Average () returns OptionalDouble and so on.
Other supplements
iterate
Generate an arithmetic sequence
Stream.iterate(0, n -> n + 3).limit(10). forEach(x -> System.out.print(x + " "));
Output:
0 3 6 9 12 15 18 21 24 27
Characteristic summary
- Not a data structure
- It has no internal storage. It just uses the operation pipeline to grab data from the source (data structure, array, generator function, IO channel).
- It also never modifies the data of the underlying data structure encapsulated by itself. For example, the filter operation of Stream will generate a new Stream that does not contain the filtered elements, instead of deleting those elements from the source.
- All Stream operations must take lambda expressions as parameters.
- Index access is not supported.
- You can request the first element, but you cannot request the second, third, or last element. However, please refer to the next item.
- It's easy to generate arrays or lists.
- Inerting.
- Many Stream operations are delayed backward until it finds out how much data it needs in the end.
- Intermediate operations are always lazy.
- Parallel capability.
- When a Stream is parallelized, there is no need to write multithreaded code, and all operations on it will be carried out automatically in parallel.
- Can be infinite.
- A collection has a fixed size, but a Stream does not. Short circuiting operations such as limit(n) and findFirst() can operate on an infinite Stream and complete it quickly.
reference: https://blog.csdn.net/weixin_43994761/article/details/90025385
https://www.jianshu.com/p/11c925cdba50