1, Installing Selenium
There are usually two methods to crawl data using Ajax interface:
- One is to dig deep into the logic, find out the construction logic of the parameters required by the request, and use Python code to reproduce and construct Ajax requests;
- The other is to directly simulate the operation of the browser and bypass this process, because the data can be seen in the browser, so if you can directly climb down the data, of course, you can obtain the corresponding information.
The two methods have their own advantages and disadvantages. The specific one needs to be analyzed according to the actual situation. Take a simple example: if you have tight working hours and heavy tasks, the boss has to worry about the data, and the logic of website request parameter construction is relatively complex, we can take the second way to get the data first, and the performance can be ignored first.
Aside: personally, I don't like using Selenium very much. If all data is captured by Selenium, the performance is too low, the API provided is not too stable, and there are many websites for Selenium feature detection, but it is very good for Selenium to do some auxiliary operations.
This paper mainly introduces the second method, which simulates the operation of the browser and crawls data. Selenium is an automatic testing tool. It can drive the browser to complete specific operations, such as click, drop-down, drag, etc. it can also obtain the source code of the page currently presented by the browser, so as to achieve what you see is what you crawl. This crawling method is still very effective for some pages dynamically rendered by JavaScript. Official learning documents: https://selenium-python.readthedocs.io/installation.html
Before using Selenium, the following three conditions should be met:
(1) Make sure the browser is installed correctly on your computer. (suggestion: install Chrome browser, and follow-up blog posts will mainly explain Chrome browser). Readers without Chrome browser can open the following Baidu online disk link to download.
Link: https://pan.baidu.com/s/1FpM6lXNf4nUoEtJrQVKHnw Extraction code: k2s2 --From Baidu online disk super member V7 Sharing
(2) Properly install the Selenium Library of Python. The command is as follows:
pip/pip3 install -i http://pypi.douban.com/simple --trusted-host pypi.douban.com selenium
(3) Install a chrome driver. Different platforms are installed in different ways. Here are Windows and MacOS as examples.
-
Click the menu of Chrome and help ⇒ about Chrome, you can view the version number of Chrome. Here, my version is 96.0.4664.45, as shown in the figure:
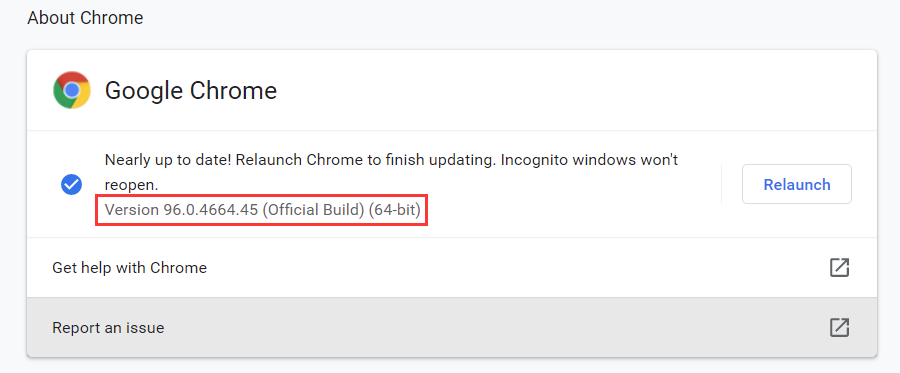
Remember the Chrome version number, which is required when selecting the Chrome driver version later. -
Download chrome driver. Open the official website of ChromeDriver, and the link is: https://sites.google.com/chromium.org/driver/downloads . The official website cannot be opened. Please refer to other download addresses below for downloading:
Download address: https://sites.google.com/a/chromium.org/chromedriver / (official website) Other download addresses: https://chromedriver.storage.googleapis.com/index.html https://npm.taobao.org/mirrors/chromedriver / (choose one)
You can see that the latest supported Chrome browser version so far is 97, and the latest version is subject to the official website, as shown in the figure:
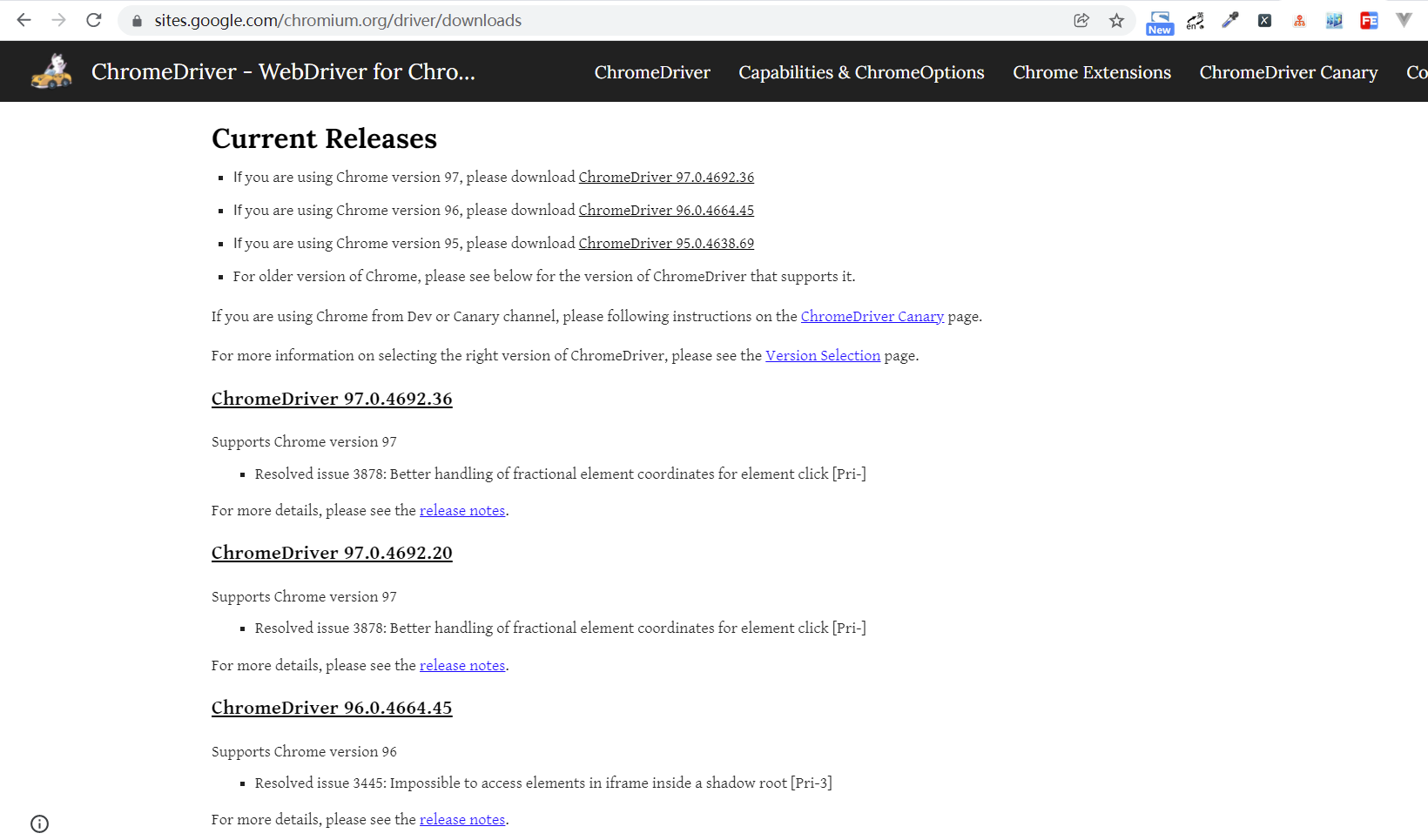
Each version has a corresponding introduction to the supporting chrome version. Please find the corresponding chrome driver version of your Chrome browser version and download it again, otherwise it may not work normally. Since the chrome driver version here is 96.0.4664.45, the matching method is:First find the first one, 96, be sure to find it Then find the second one, 0, and be sure to find it Then find the third one, 4664, which should be there Finally, find the fourth one, 45: it's best to have it. Just click it directly. If not, it doesn't matter. Find the one closest to 45 and click in.
Find the corresponding download list, as shown in the figure:
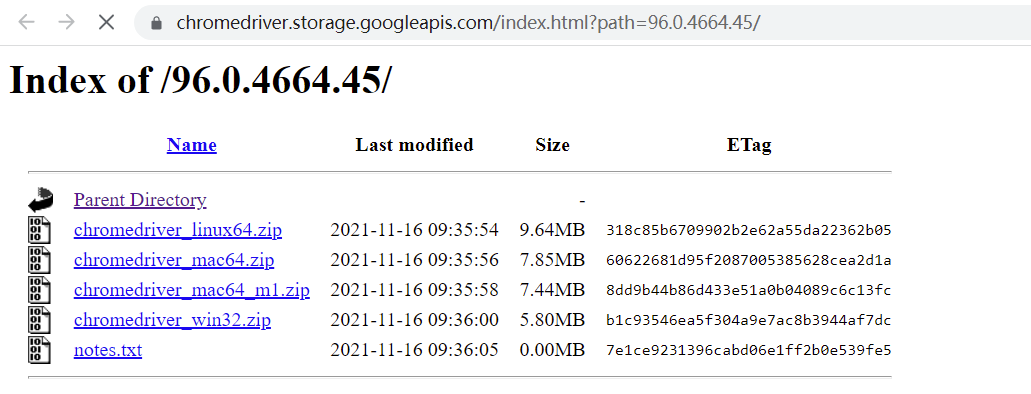
Download win32.zip for Windows system, mac64.zip for Intel chip for Mac system, and Mac64 for M1 chip for Mac system_ M1.zip. Download linux64.zip for Linux system. After downloading and extracting, you will get an executable file of chrome driver. -
After downloading, configure the chrome driver executable to the environment variable. Under Windows, it is recommended to directly drag the chromedriver.exe file to the Scripts directory of Python, as shown in the figure:
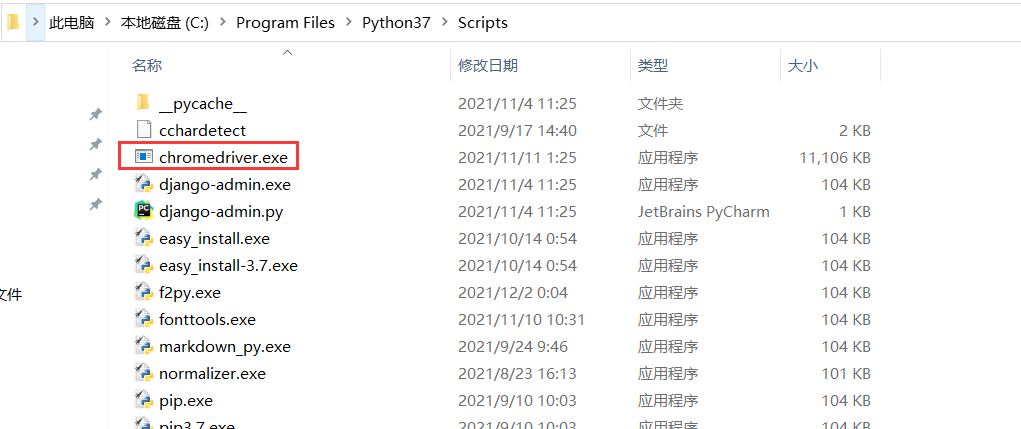
You can also configure the path to the environment variable separately. Please solve the configuration method of the environment variable by yourself. Under Linux and Mac, you need to configure the executable file to the environment variable or move the file to the directory belonging to the environment variable. For example, to move a file to the / usr/bin directory, first enter its path from the command line, and then move it to / usr/bin:sudo mv chromedriver /usr/bin Note: some Mac Your computer may experience permissions problems
Of course, you can also configure the ChromeDriver to $PATH. First, you can put the executable file in a directory. The directory can be selected arbitrarily. For example, put the current executable file in / usr/local/chromedriver directory, and then modify the ~ /. profile file. The commands are as follows:
export PATH="$PATH:/usr/local/chromedriver" MacOS The following commands are recommended: cd Desktop sudo cp chromedriver /usr/local/bin/chromedriver Password: ls /usr/local/bin | grep chromedriver chromedriver
Save and then execute: you can complete the addition of environment variables.
source ~/.profile
-
Verify installation. After the configuration is completed, you can execute the chromedriver command directly from the command line. Enter at the command line:
chromedriver
The input console has similar outputs, as shown in the figure:
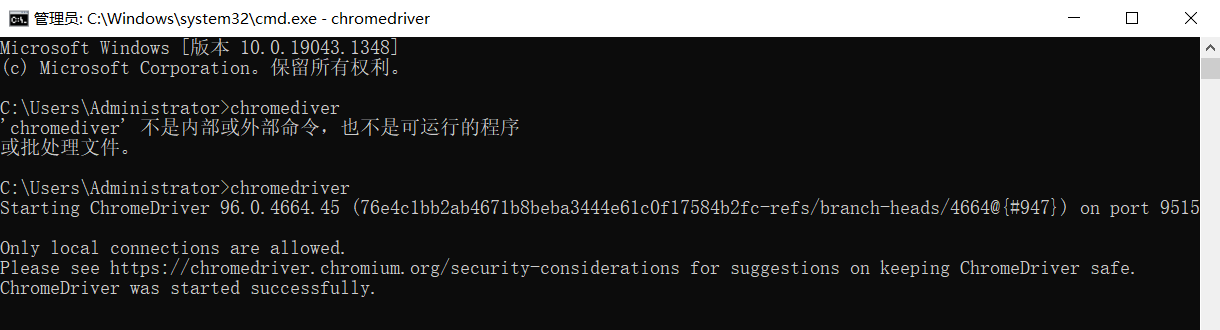
If there is a similar output, it proves that the environment variables of chrome driver are configured. Then test in the program and execute the following Python code:# -*- coding: utf-8 -*- # @Time : 2021/12/6 23:53 # @Author : AmoXiang # @FileName: selenium_test.py # @Software: PyCharm # @Blog : https://blog.csdn.net/xw1680? from selenium import webdriver browser = webdriver.Chrome()
After running, a blank Chrome browser will pop up to prove that all configurations are OK. If there is no pop-up, please check the configuration of each step before. If you flash back after popping up, it may be that the chrome driver version and chrome version are not simple. Please replace the chrome driver version. If there is no problem, then we can start using Selenium to achieve what we see is what we climb. Linux system, please handle it yourself.
2, Use of Selenium
1. Basic usage:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 0:16
# @Author : AmoXiang
# @FileName: demo1.py
# @Software: PyCharm
# @Blog : https://blog.csdn.net/xw1680?
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome() # Initialize the browser object and assign it to the browser
# webdriver.Firefox()
# webdriver.Edge()
# webdriver.Safari()
try:
# Just pass in the URL of the web page to be requested to the parameter URL
browser.get(url="https://www.baidu.com ") # use the get method to request web pages
_input = browser.find_element_by_id("kw") # Find node
# Equivalent _input = browser.find_element(By.ID, "kw")
_input.send_keys("AmoXiang") # Enter text
_input.send_keys(Keys.ENTER)
wait = WebDriverWait(browser, 10)
wait.until(EC.presence_of_all_elements_located((By.ID, "content_left")))
print(browser.current_url) # Get the url of the current page
print(browser.get_cookies()) # Get cookie
print(browser.page_source) # Page source code
finally:
browser.close()
2. Find nodes:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 0:38
# @Author : AmoXiang
# @FileName: demo2.py
# @Software: PyCharm
# @Blog : https://blog.csdn.net/xw1680?
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('http://tjj.sc.gov.cn/scstjj/tjgb/common_list.shtml')
# ############## Find a single node ###############
one = browser.find_element_by_id('list-data')
two = browser.find_element_by_css_selector('#list-data')
three = browser.find_element_by_xpath('//*[@id="list-data"]')
# Equivalent to the following method
_one = browser.find_element(By.ID, 'list-data')
print(one, two, three, _one)
# ############## Find multiple nodes ###############
lis = browser.find_elements_by_css_selector()
# Equivalent to the following:
# browser.find_elements(By.CSS_SELECTOR, '#list-data li')
print(lis)
browser.close()
3. Node interaction:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 0:52
# @Author : AmoXiang
# @FileName: demo3.py
# @Software: PyCharm
# @Blog : https://blog.csdn.net/xw1680?
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('http://tjj.sc.gov.cn/scstjj/tjgb/common_list.shtml')
input_ = browser.find_element_by_id('searchWord')
input_.send_keys('Statistical bulletin')
time.sleep(1)
input_.clear()
time.sleep(3)
input_.send_keys('Decision budget')
button = browser.find_element_by_id('searchbtn')
button.click()
browser.close()
4. Action chain:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 0:56
# @Author : AmoXiang
# @FileName: demo4.py
# @Software: PyCharm
# @Blog : https://blog.csdn.net/xw1680?
from selenium import webdriver
from selenium.webdriver import ActionChains
import time
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable') # Get the dragged node
target = browser.find_element_by_css_selector('#droppable') # Drag to target node
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
time.sleep(5)
browser.close()
5. Run JavaScript:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 1:06
# @Author : AmoXiang
# @FileName: demo5.py
# @Software: PyCharm
# @Blog : https://blog.csdn.net/xw1680?
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://tjj.sc.gov.cn/scstjj/tjgb/common_list.shtml')
# In practice, we may calculate the distance of each drag
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
With the execute_script() method, almost all functions that are not provided with an API can be implemented by running JavaScript.
6. Get node information:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 1:10
# @Author : AmoXiang
# @FileName: demo6.py
# @Software: PyCharm
# @Blog : https://blog.csdn.net/xw1680?
from selenium import webdriver
browser = webdriver.Chrome()
url = 'http://tjj.sc.gov.cn/scstjj/tjgb/common_list.shtml'
browser.get(url)
logo = browser.find_element_by_xpath('//a[@class="logo"]/img')
print(logo)
# Use the get_attribute() method to get the attribute, and just pass in the attribute name you want to get
print(logo.get_attribute('src'))
# TODO 2. Get text value
search_btn = browser.find_element_by_id("searchbtn")
print(search_btn.text)
# TODO 3. Get ID, location, tag name and size
print(search_btn.id)
print(search_btn.location)
print(search_btn.tag_name)
print(search_btn.size)
7. Switch Frame:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 1:19
# @Author : AmoXiang
# @FileName: demo7.py
# @Software: PyCharm
# @Blog : https://blog.csdn.net/xw1680?
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
try:
logo = browser.find_element_by_class_name('logo')
except NoSuchElementException:
print('NO LOGO')
browser.switch_to.parent_frame()
logo = browser.find_element_by_class_name('logo')
print(logo)
print(logo.text)
8. Delayed waiting:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 1:22
# @Author : AmoXiang
# @FileName: demo8.py
# @Software: PyCharm
# @Blog : https://blog.csdn.net/xw1680?
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
# Implicit waiting
# browser.implicitly_wait(10)
browser.get('http://tjj.sc.gov.cn/scstjj/tjgb/common_list.shtml')
# input_ = browser.find_element_by_class_name('logo')
# print(input_)
# Display wait
wait = WebDriverWait(browser, 10)
input_ = wait.until(EC.presence_of_element_located((By.ID, 'searchWord')))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#searchbtn')))
print(input_, button)
9. Forward and backward:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 1:37
# @Author : AmoXiang
# @FileName: demo9.py
# @Software: PyCharm
# @Blog : https://blog.csdn.net/xw1680?
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://tjj.sc.gov.cn/scstjj/tjgb/common_list.shtml')
time.sleep(2)
browser.get('http://tjj.sc.gov.cn/scstjj/tjgb/common_list_2.shtml')
time.sleep(2)
browser.get('http://tjj.sc.gov.cn/scstjj/tjgb/common_list_3.shtml')
time.sleep(2)
browser.back()
time.sleep(3)
browser.forward()
time.sleep(3)
browser.close()
10,Cookie:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.jd.com')
print(browser.get_cookies())
browser.add_cookie({'name': 'name',
'value': 'jd', 'domain': 'www.jd.com'})
print(browser.get_cookies())
browser.delete_all_cookies()
print(browser.get_cookies()) # Most of them have been deleted, and there may be some left
11. Tab Management:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 1:42
# @Author : AmoXiang
# @FileName: demo10.py
# @Software: PyCharm
# @Blog : https://blog.csdn.net/xw1680?
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles) # Gets all currently open tabs
browser.switch_to.window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to.window(browser.window_handles[0])
browser.get('https://python.org')
12. Anti shielding:
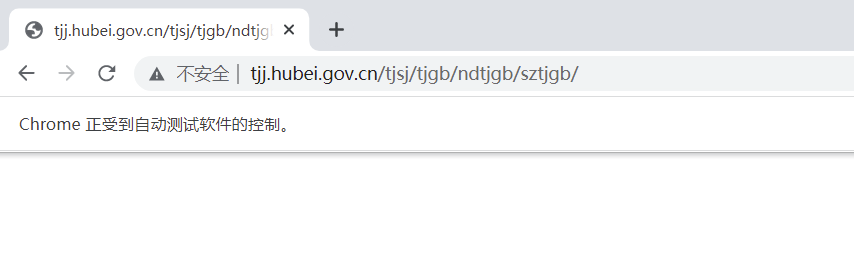
Many websites have added Selenium detection. In most cases, the basic principle of detection is to detect whether the window.navigator object in the current browser window contains the webdriver attribute. When using the browser normally, this attribute is undefined. Once Selenium is used, it will set the webdriver attribute to the window.navigator object. Many websites use JavaScript statements to determine whether there is webdriver attribute. If there is direct shielding. A typical case website: http://tjj.hubei.gov.cn/tjsj/tjgb/ndtjgb/sztjgb/ , we use the above principle to detect whether the webdriver attribute exists. If we use Selenium to directly grab the data of the website, the website will return the page shown in the following figure:
In Selenium, CDP can be used (i.e. chrome devtools protocol) to solve this problem, it can be used to execute JavaScript statements when each page is just loaded, and set the webdriver attribute to null. The CDP method executed here is called Page.addScriptToEvaluateOnNewDocument, and the above JavaScript statements can be passed in. In addition, several can be added There are two options to hide webdriver prompt bar and automatic extension information. The code is as follows:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 1:53
# @Author : AmoXiang
# @FileName: demo11.py
# @Software: PyCharm
# @Blog : https://blog.csdn.net/xw1680?
from selenium import webdriver
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
browser = webdriver.Chrome(options=option)
browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'
})
browser.get('http://tjj.hubei.gov.cn/tjsj/tjgb/ndtjgb/sztjgb/')
In this way, the whole page can be loaded, as shown in the following figure:
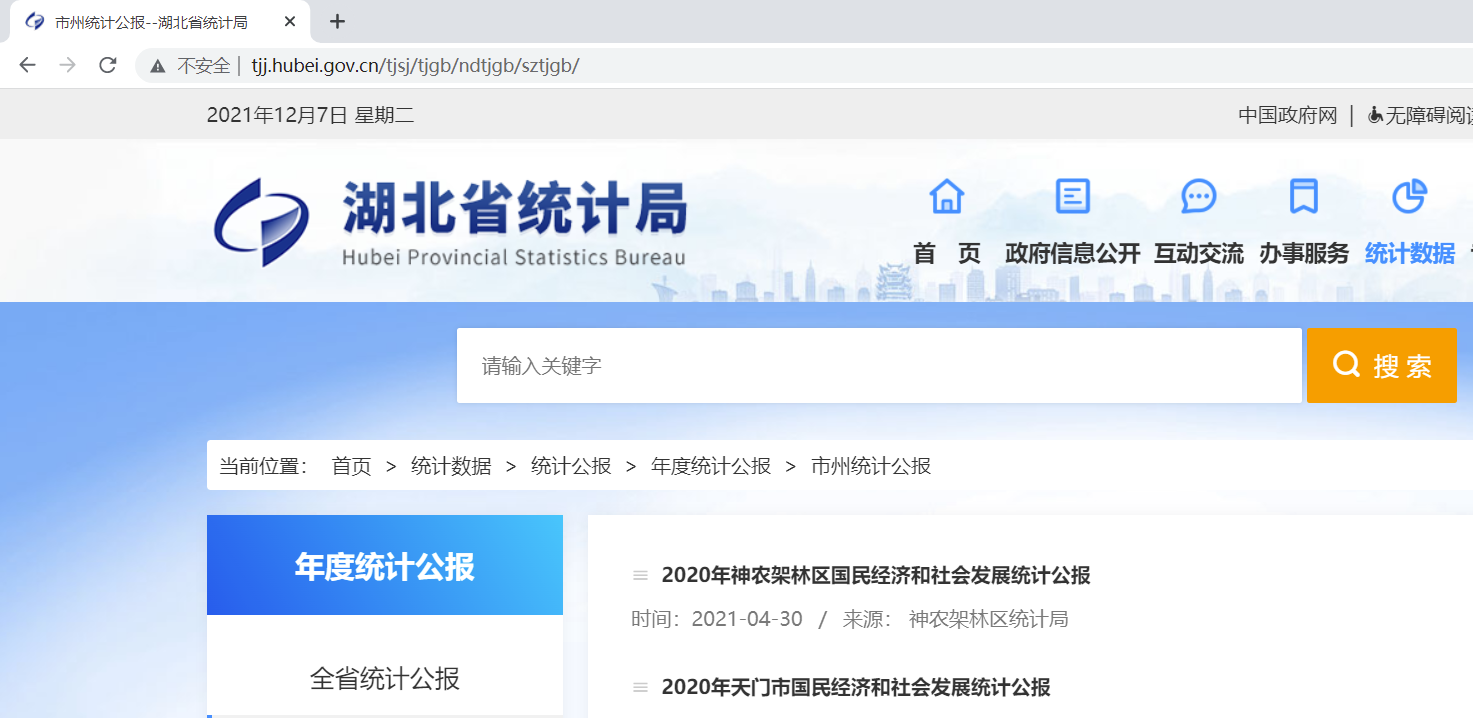
Note: in most cases, the above methods can realize the anti shielding of Selenium. However, some special websites will set more feature detection for WebDriver property. In this case, specific troubleshooting may be required.
13. Headless mode:
# -*- coding: utf-8 -*-
# @Time : 2021/12/7 2:10
# @Author : AmoXiang
# @FileName: demo12.py
# @Software: PyCharm
# @Blog : https://blog.csdn.net/xw1680?
from selenium import webdriver
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_argument('--headless') # Headless mode: save resource loading time and network bandwidth to a certain extent
browser = webdriver.Chrome(options=option)
browser.set_window_size(1366, 768)
browser.get('https://www.baidu.com')
browser.get_screenshot_as_file('preview.png')
So far, this is the end of today's case. I declare here that I wrote this article just to learn and communicate, and let more readers who study reptiles take fewer detours, save time, and do not need to do other purposes. If there is infringement, please contact the blogger to delete it. Thank you for reading this blog, and I hope this article can become a leader in your programming. Have a good reading !

If I want to be the most beautiful person in the audience, I must insist on learning to obtain more knowledge, change my destiny with knowledge, witness my growth with blog and prove my efforts with action.
If my blog is helpful to you and if you like my blog content, please praise, comment and collect three times with one click! It is said that those who praise will not be too bad and will be full of vitality every day! If you really want to whore for nothing, I wish you happy every day. Welcome to my blog often.
coding is not easy. Everyone's support is the driving force for me to stick to it. Don't forget to pay attention to me after you like it!