JDBC core technology
JDBC overview
Data persistence
-
Persistence: save data to a power down storage device for later use. In most cases, especially for enterprise applications, data persistence means saving the data in memory to the hard disk for "solidification", and the implementation process of persistence is mostly completed through various relational databases.
-
The main application of persistence is to store the data in memory in relational database. Of course, it can also be stored in disk file and XML data file.
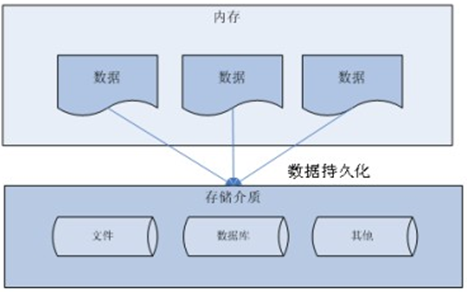
Data storage technology in Java
-
In Java, database access technology can be divided into the following categories:
-
JDBC direct access to database
-
JDO (Java Data Object) technology
-
Third party O/R tools, such as Hibernate, Mybatis, etc
-
-
JDBC is the cornerstone of java accessing database. JDO, Hibernate and MyBatis just better encapsulate JDBC.
JDBC introduction
- JDBC(Java Database Connectivity) is a common interface (a set of API s) independent of a specific database management system and general SQL database access and operation. It defines the standard Java class libraries used to access the database (java.sql,javax.sql). These class libraries can be used to access database resources in a standard and convenient way.
- JDBC provides a unified way to access different databases and shields some details for developers.
- The goal of JDBC is to enable Java programmers to use JDBC to connect to any database system that provides JDBC drivers, so that programmers do not need to know too much about the characteristics of a specific database system, which greatly simplifies and speeds up the development process.
- If there is no JDBC, the Java program accesses the database as follows:
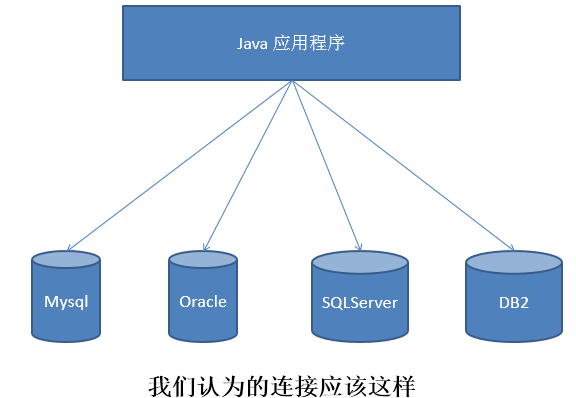
- With JDBC, the Java program accesses the database as follows:
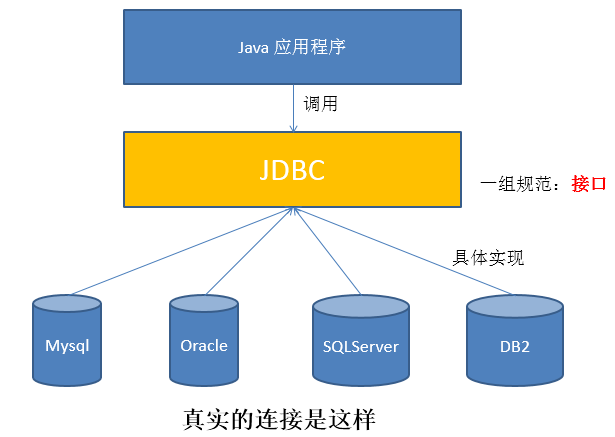
- The summary is as follows:
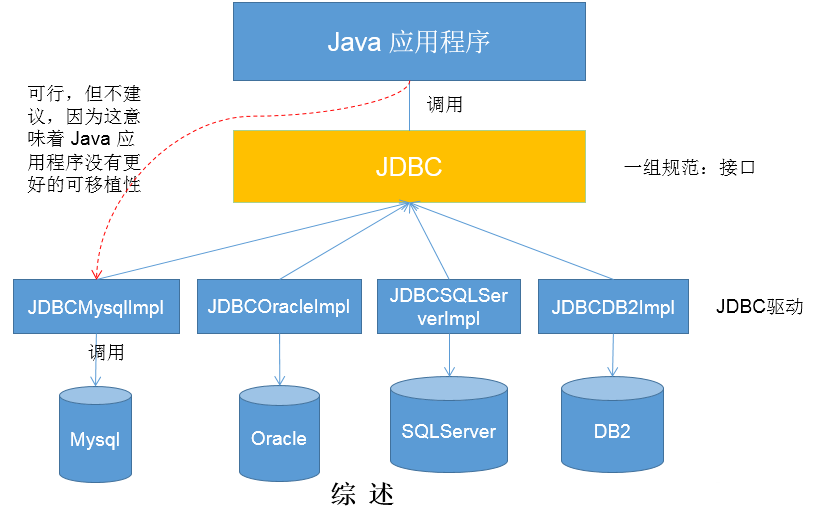
JDBC architecture
- JDBC interface (API) includes two levels:
- Application oriented API: Java API, abstract interface, for application developers to use (connect to the database, execute SQL statements, and obtain results).
- Database oriented API: Java Driver API for developers to develop database drivers.
JDBC is a set of interfaces provided by sun company for database operation. java programmers only need to program for this set of interfaces.
Different database manufacturers need to provide different implementations for this set of interfaces. The collection of different implementations is the driver of different databases———— Interface oriented programming
JDBC programming steps
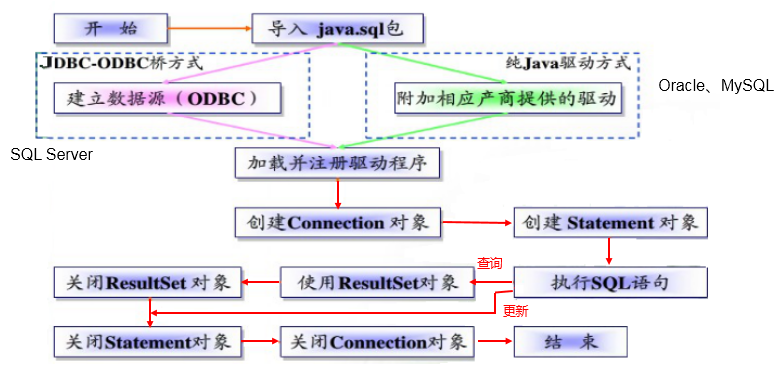
Supplement: ODBC(Open Database Connectivity) is launched by Microsoft under the Windows platform. The user only needs to call ODBC API in the program, and the ODBC driver converts the call into a call request to a specific database.
Get database connection
Element 1: Driver interface implementation class
Driver interface introduction
-
java. sql. The driver interface is the interface that all JDBC drivers need to implement. This interface is provided for database manufacturers. Different database manufacturers provide different implementations.
-
In the program, you do not need to directly access the classes that implement the Driver interface, but the Driver manager class (java.sql.DriverManager) calls these Driver implementations.
- Oracle driver: Oracle jdbc. driver. OracleDriver
- mySql driver: com mySql. jdbc. Driver
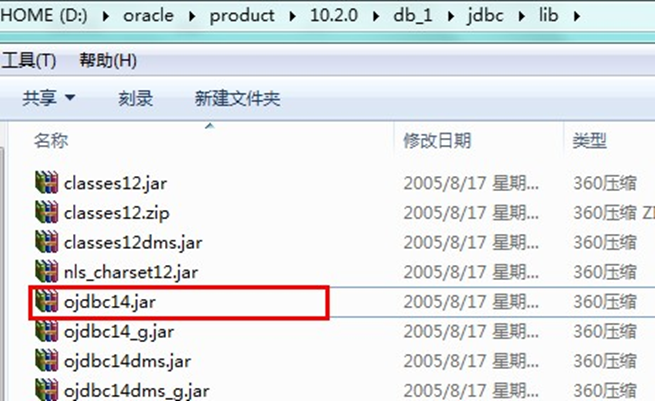
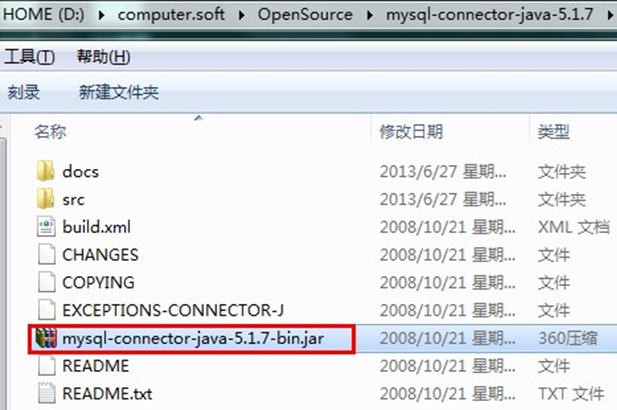
- Copy the above jar package to a directory of the Java project. It is customary to create a new lib folder.
Right click the driver jar – > build path – > add to build path
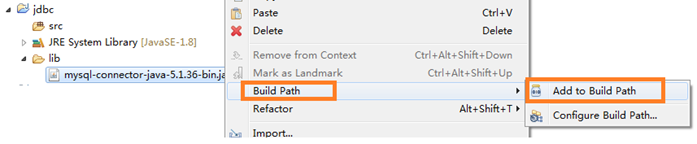
Note: if it is a Dynamic Web Project, just put the driver jar in the lib directory in the WEB-INF directory in the WebContent (some development tools are called WebRoot) directory
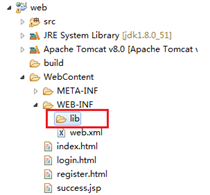
Loading and registering JDBC drivers
-
Load driver: to load the JDBC driver, you need to call the static method forName() of Class class and pass the Class name of the JDBC driver to be loaded
- Class.forName("com.mysql.jdbc.Driver");
-
Register driver: DriverManager class is the driver manager class, which is responsible for managing drivers
-
Using drivermanager Register driver (COM. Mysql. JDBC. Driver) to register the driver
-
Usually, it is not necessary to explicitly call the registerDriver() method of the DriverManager class to register the instance of the Driver class, because the Driver class of the Driver interface contains a static code block in which DriverManager will be called The registerDriver() method to register an instance of itself. The following figure shows the source code of the Driver implementation class of MySQL:
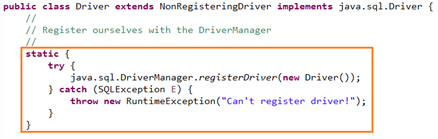
-
Element 2: URL
-
JDBC URL is used to identify a registered driver. The driver manager selects the correct driver through this URL to establish a connection to the database.
-
The standard JDBC URL consists of three parts separated by colons.
- jdbc: sub protocol: sub name
- Protocol: the protocol in the JDBC URL is always jdbc
- Sub protocol: the sub protocol is used to identify a database driver
- Subname: a method of identifying a database. The sub name can be changed according to different sub protocols. The purpose of using the sub name is to provide sufficient information for locating the database. Including host name (corresponding to the ip address of the server), port number and database name
-
give an example:
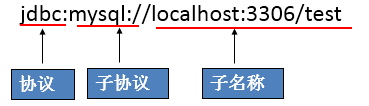
-
JDBC URL s of several common databases
-
MySQL connection URL writing method:
- jdbc:mysql: / / host name: mysql service port number / database name? Parameter = value & parameter = value
- jdbc:mysql://localhost:3306/atguigu
- jdbc: mysql://localhost:3306/atguigu **? Useunicode = true & characterencoding = utf8 * * (if the JDBC program is inconsistent with the server-side character set, it will cause garbled code, then you can specify the server-side character set through parameters)
- jdbc:mysql://localhost:3306/atguigu?user=root&password=123456
-
How to write the connection URL of Oracle 9i:
- jdbc:oracle:thin: @ host name: oracle service port number: database name
- jdbc:oracle:thin:@localhost:1521:atguigu
-
SQL Server connection URL is written as follows:
-
jdbc:sqlserver: / / host name: sqlserver service port number: DatabaseName = database name
-
jdbc:sqlserver://localhost:1433:DatabaseName=atguigu
-
-
Element 3: user name and password
- User and password can tell the database by "attribute name = attribute value"
- You can call the getConnection() method of the DriverManager class to establish a connection to the database
Example of database connection mode
Connection mode I
@Test
public void testConnection1() {
try {
// 1. Provide Java sql. The driver interface implements the object of the class
Driver driver = null;
driver = new com.mysql.jdbc.Driver();
// 2. Provide a url to indicate the specific operation data
String url = "jdbc:mysql://localhost:3306/test";
// 3. Provide the object of Properties, indicating the user name and password
Properties info = new Properties();
info.setProperty("user", "root");
info.setProperty("password", "abc123");
// 4. Call the connect() of the driver to get the connection
Connection conn = driver.connect(url, info);
System.out.println(conn);
} catch (SQLException e) {
e.printStackTrace();
}
}
Note: the API of the third-party database appears explicitly in the above code
Connection mode II
@Test
public void testConnection2() {
try {
// 1. Instantiate Driver
String className = "com.mysql.jdbc.Driver";
Class clazz = Class.forName(className);
Driver driver = (Driver) clazz.newInstance();
// 2. Provide a url to indicate the specific operation data
String url = "jdbc:mysql://localhost:3306/test";
// 3. Provide the object of Properties, indicating the user name and password
Properties info = new Properties();
info.setProperty("user", "root");
info.setProperty("password", "abc123");
// 4. Call the connect() of the driver to get the connection
Connection conn = driver.connect(url, info);
System.out.println(conn);
} catch (Exception e) {
e.printStackTrace();
}
}
Note: compared with method 1, the reflection instantiation Driver is used here, which does not reflect the API of the third-party database in the code. It embodies the idea of interface oriented programming.
Connection mode III
@Test
public void testConnection3() {
try {
// 1. Four basic elements of database connection:
String url = "jdbc:mysql://localhost:3306/test";
String user = "root";
String password = "abc123";
String driverName = "com.mysql.jdbc.Driver";
// 2. Instantiate Driver
Class clazz = Class.forName(driverName);
Driver driver = (Driver) clazz.newInstance();
// 3. Register driver
DriverManager.registerDriver(driver);
// 4. Get connection
Connection conn = DriverManager.getConnection(url, user, password);
System.out.println(conn);
} catch (Exception e) {
e.printStackTrace();
}
}
Description: use DriverManager to connect to the database. Experience the four basic elements necessary to obtain connections.
Connection mode IV
@Test
public void testConnection4() {
try {
// 1. Four basic elements of database connection:
String url = "jdbc:mysql://localhost:3306/test";
String user = "root";
String password = "abc123";
String driverName = "com.mysql.jdbc.Driver";
// 2. Load Driver (① instantiate Driver ② register Driver)
Class.forName(driverName);
// driver = (Driver) clazz.newInstance();
// 3. Register driver
// DriverManager.registerDriver(driver);
/*
The reason why the above code can be commented out is that the Driver class of mysql declares:
static {
try {
DriverManager.registerDriver(new Driver());
} catch (SQLException var1) {
throw new RuntimeException("Can't register driver!");
}
}
*/
// 3. Get connection
Connection conn = DriverManager.getConnection(url, user, password);
System.out.println(conn);
} catch (Exception e) {
e.printStackTrace();
}
}
Note: there is no need to explicitly register the driver. Because the static code block already exists in the source code of DriverManager, the driver registration is realized.
Connection mode V (final version)
@Test
public void testConnection5() throws Exception {
// 1. Load configuration file
InputStream is = ConnectionTest.class.getClassLoader().getResourceAsStream("jdbc.properties");
Properties pros = new Properties();
pros.load(is);
// 2. Read configuration information
String user = pros.getProperty("user");
String password = pros.getProperty("password");
String url = pros.getProperty("url");
String driverClass = pros.getProperty("driverClass");
// 3. Load drive
Class.forName(driverClass);
// 4. Get connection
Connection conn = DriverManager.getConnection(url,user,password);
System.out.println(conn);
}
The configuration file is declared in the src directory of the project: [jdbc.properties]
user=root password=abc123 url=jdbc:mysql://localhost:3306/test driverClass=com.mysql.jdbc.Driver
Description: save the configuration information in the form of configuration file, and load the configuration file in the code
Benefits of using profiles:
① It realizes the separation of code and data. If you need to modify the configuration information, you can modify it directly in the configuration file without going deep into the code
② If the configuration information is modified, the recompilation process is omitted.
Implement CRUD operation using PreparedStatement
Operating and accessing databases
-
The database connection is used to send commands and SQL statements to the database server and accept the results returned by the database server. In fact, a database connection is a Socket connection.
-
In Java There are three interfaces in the SQL package that define different methods of calling the database:
- Statement: an object used to execute a static SQL statement and return the results it generates.
- PrepatedStatement: the SQL statement is precompiled and stored in this object, which can be used multiple times to execute the statement efficiently.
- CallableStatement: used to execute SQL stored procedures
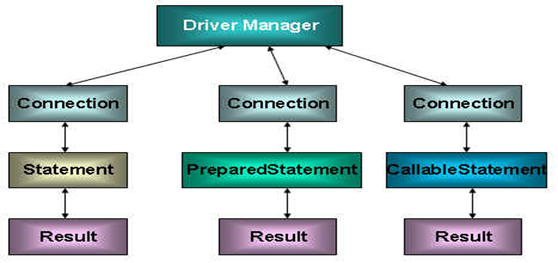
Disadvantages of using Statement to manipulate data table
-
Create the Connection object by calling its createStatement() method. This object is used to execute static SQL statements and return execution results.
-
The following methods are defined in the Statement interface to execute SQL statements:
- int excuteUpdate(String sql): perform UPDATE operations INSERT, UPDATE, DELETE
- ResultSet executeQuery(String sql): execute query operation SELECT
-
However, using Statement to manipulate the data table has disadvantages:
- Problem 1: there is string splicing operation, which is cumbersome
- Problem 2: SQL injection problem
-
SQL injection is to inject illegal SQL statement segments OR commands into the user input data (such as: SELECT user, password FROM user_table WHERE user = 'a' OR 1 = 'AND password =' OR '1' = '1') without sufficient inspection of the user input data, so as to use the system's SQL Engine to complete malicious acts.
-
For Java, to prevent SQL injection, just replace the Statement with Preparedstatement (extended from the Statement).
-
Code demonstration:
public class StatementTest {
// Disadvantages of using Statement: you need to spell SQL statements, and there is a problem of SQL injection
@Test
public void testLogin() {
Scanner scan = new Scanner(System.in);
System.out.print("user name:");
String userName = scan.nextLine();
System.out.print("password:");
String password = scan.nextLine();
// SELECT user,password FROM user_table WHERE USER = '1' or ' AND PASSWORD = '='1' or '1' = '1';
String sql = "SELECT user,password FROM user_table WHERE USER = '" + userName + "' AND PASSWORD = '" + password
+ "'";
User user = get(sql, User.class);
if (user != null) {
System.out.println("Login successful!");
} else {
System.out.println("Wrong user name or password!");
}
}
// Query the data table using Statement
public <T> T get(String sql, Class<T> clazz) {
T t = null;
Connection conn = null;
Statement st = null;
ResultSet rs = null;
try {
// 1. Load configuration file
InputStream is = StatementTest.class.getClassLoader().getResourceAsStream("jdbc.properties");
Properties pros = new Properties();
pros.load(is);
// 2. Read configuration information
String user = pros.getProperty("user");
String password = pros.getProperty("password");
String url = pros.getProperty("url");
String driverClass = pros.getProperty("driverClass");
// 3. Load drive
Class.forName(driverClass);
// 4. Get connection
conn = DriverManager.getConnection(url, user, password);
st = conn.createStatement();
rs = st.executeQuery(sql);
// Get metadata of result set
ResultSetMetaData rsmd = rs.getMetaData();
// Gets the number of columns in the result set
int columnCount = rsmd.getColumnCount();
if (rs.next()) {
t = clazz.newInstance();
for (int i = 0; i < columnCount; i++) {
// //1. Gets the name of the column
// String columnName = rsmd.getColumnName(i+1);
// 1. Get alias of column
String columnName = rsmd.getColumnLabel(i + 1);
// 2. Obtain the data in the corresponding data table according to the column name
Object columnVal = rs.getObject(columnName);
// 3. Encapsulate the data obtained from the data table into the object
Field field = clazz.getDeclaredField(columnName);
field.setAccessible(true);
field.set(t, columnVal);
}
return t;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// close resource
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (st != null) {
try {
st.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
return null;
}
}
To sum up:
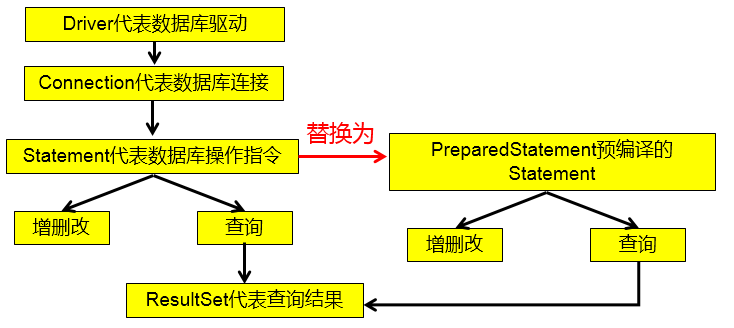
Use of PreparedStatement
PreparedStatement introduction
-
The PreparedStatement object can be obtained by calling the preparedStatement(String sql) method of the Connection object
-
PreparedStatement interface is a sub interface of Statement, which represents a precompiled SQL Statement
-
The parameters in the SQL statement represented by the PreparedStatement object are marked with a question mark (?) Call the setXxx() method of the PreparedStatement object to set these parameters The setXxx() method has two parameters. The first parameter is the index of the parameter in the SQL statement to be set (starting from 1), and the second parameter is the value of the parameter in the SQL statement to be set
PreparedStatement vs Statement
-
Code readability and maintainability.
-
PreparedStatement maximizes performance:
- DBServer provides performance optimization for precompiled statements. Because the precompiled statement may be called repeatedly, the execution code of the statement compiled by the DBServer compiler is cached. As long as it is the same precompiled statement in the next call, it does not need to be compiled. As long as the parameters are directly passed into the compiled statement execution code, it will be executed.
- In the statement statement statement, even if it is the same operation, because the data content is different, the whole statement itself cannot match, and there is no meaning of caching the statement The fact is that no database caches the compiled execution code of ordinary statements. In this way, the incoming statement will be compiled once every execution.
- (syntax check, semantic check, translation into binary commands, cache)
-
PreparedStatement prevents SQL injection
Data type conversion table corresponding to Java and SQL
| Java type | SQL type |
|---|---|
| boolean | BIT |
| byte | TINYINT |
| short | SMALLINT |
| int | INTEGER |
| long | BIGINT |
| String | CHAR,VARCHAR,LONGVARCHAR |
| byte array | BINARY , VAR BINARY |
| java.sql.Date | DATE |
| java.sql.Time | TIME |
| java.sql.Timestamp | TIMESTAMP |
Add, delete and modify operations using PreparedStatement
// General add, delete and change operations (embodiment 1: add, delete and change; embodiment 2: for different tables)
public void update(String sql,Object ... args){
Connection conn = null;
PreparedStatement ps = null;
try {
// 1. Get database connection
conn = JDBCUtils.getConnection();
/ /2.obtain PreparedStatement Examples of (Or: precompiled sql sentence)
ps = conn.prepareStatement(sql);
// 3. Fill placeholder
for(int i = 0;i < args.length;i++){
ps.setObject(i + 1, args[i]);
}
// 4. Execute sql statement
ps.execute();
} catch (Exception e) {
e.printStackTrace();
}finally{
// 5. Close resources
JDBCUtils.closeResource(conn, ps);
}
}
Query operation using PreparedStatement
// General query for different tables: return an object (version 1.0)
public <T> T getInstance(Class<T> clazz, String sql, Object... args) {
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
// 1. Get database connection
conn = JDBCUtils.getConnection();
// 2. Precompile the sql statement to obtain the PreparedStatement object
ps = conn.prepareStatement(sql);
// 3. Fill placeholder
for (int i = 0; i < args.length; i++) {
ps.setObject(i + 1, args[i]);
}
// 4. Execute executeQuery() to get the result set: ResultSet
rs = ps.executeQuery();
// 5. Get metadata of result set: ResultSetMetaData
ResultSetMetaData rsmd = rs.getMetaData();
// 6.1 get columncount and columnlabel through ResultSetMetaData; Get column value through ResultSet
int columnCount = rsmd.getColumnCount();
if (rs.next()) {
T t = clazz.newInstance();
for (int i = 0; i < columnCount; i++) {// Traverse each column
// Get column value
Object columnVal = rs.getObject(i + 1);
// Gets the alias of the column: the alias of the column, using the property name of the class as the alias
String columnLabel = rsmd.getColumnLabel(i + 1);
// 6.2 using reflection, assign values to the corresponding attributes of the object
Field field = clazz.getDeclaredField(columnLabel);
field.setAccessible(true);
field.set(t, columnVal);
}
return t;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 7. Close resources
JDBCUtils.closeResource(conn, ps, rs);
}
return null;
}
Note: the query operation implemented by PreparedStatement can replace the query operation implemented by Statement, and solve the problems of Statement concatenation and SQL injection.
ResultSet and ResultSetMetaData
ResultSet
-
The query needs to call the executeQuery() method of PreparedStatement, and the query result is a ResultSet object
-
The ResultSet object encapsulates the result set of database operation in the form of logical table, and the ResultSet interface is provided and implemented by the database manufacturer
-
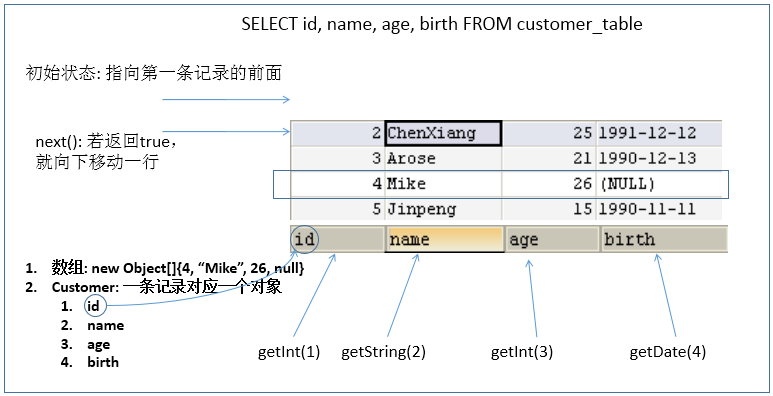
What the ResultSet returns is actually a data table. There is a pointer to the front of the first record in the data table.
-
The ResultSet object maintains a cursor pointing to the current data row. Initially, the cursor is before the first row and can be moved to the next row through the next() method of the ResultSet object. Call the next () method to check whether the next line is valid. If valid, the method returns true and the pointer moves down. Equivalent to a combination of hasNext() and next () methods of the Iterator object.
-
When the pointer points to a row, you can get the value of each column by calling getXxx(int index) or getXxx(int columnName).
- For example: getInt(1), getString("name")
- Note: the indexes in the relevant Java API s involved in the interaction between Java and database start from 1.
-
Common methods of ResultSet interface:
-
boolean next()
-
getString()
-
...
-
ResultSetMetaData
-
An object that can be used to get information about the types and properties of columns in a ResultSet object
-
ResultSetMetaData meta = rs.getMetaData();
-
getColumnName(int column): gets the name of the specified column
-
getColumnLabel(int column): gets the alias of the specified column
-
getColumnCount(): returns the number of columns in the current ResultSet object.
-
getColumnTypeName(int column): retrieves the database specific type name of the specified column.
-
getColumnDisplaySize(int column): indicates the maximum standard width of the specified column, in characters.
-
isNullable(int column): indicates whether the value in the specified column can be null.
-
isAutoIncrement(int column): indicates whether the specified columns are automatically numbered so that they are still read-only.
-
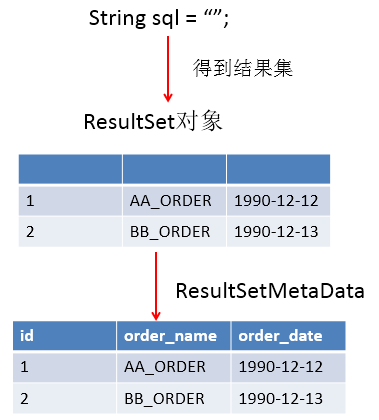
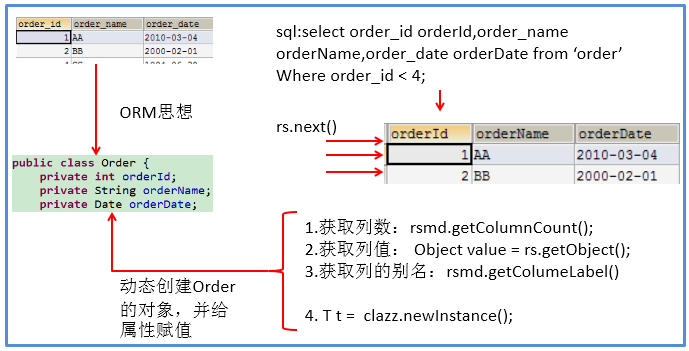
Question 1: after getting the result set, how do you know which columns are in the result set? What is the column name?
You need to use an object that describes the ResultSet, that is, ResultSetMetaData
Question 2: about ResultSetMetaData
- How to get ResultSetMetaData: just call the getMetaData() method of ResultSet
- Get the number of columns in the ResultSet: call the getColumnCount() method of ResultSetMetaData
- Get the alias of each column in the ResultSet: call the getColumnLabel() method of ResultSetMetaData
Release of resources
- Release ResultSet, Statement,Connection.
- Database Connection is a very rare resource and must be released immediately after use. If the Connection cannot be closed in time and correctly, it will lead to system downtime. The principle of Connection is to create it as late as possible and release it as early as possible.
- It can be closed in finally to ensure that resources can be closed in case of exceptions in other codes.
JDBC API summary
-
Two thoughts
-
The idea of interface oriented programming
-
ORM (object relational mapping)
- A data table corresponds to a java class
- A record in the table corresponds to an object of the java class
- A field in the table corresponds to an attribute of the java class
sql needs to be written in combination with column names and table attribute names. Note the alias.
-
-
Two technologies
- Metadata of JDBC result set: ResultSetMetaData
- Get the number of columns: getColumnCount()
- Get alias of column: getColumnLabel()
- Through reflection, create the object of the specified class, obtain the specified attribute and assign a value
- Metadata of JDBC result set: ResultSetMetaData
Chapter exercise
Exercise 1: insert a piece of data from the console into the table customers in the database. The table structure is as follows:

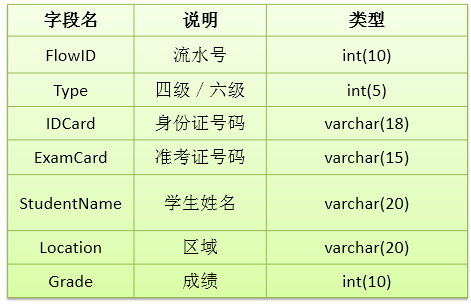
Exercise 2: create the database table examstudent. The table structure is as follows:
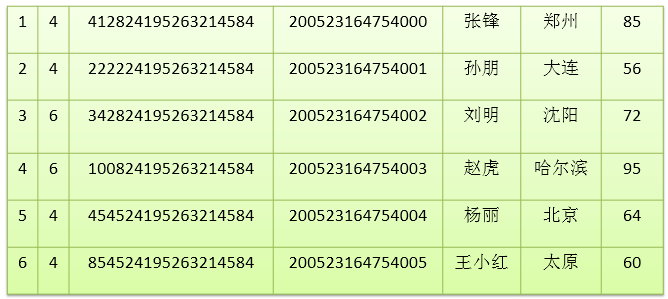
Add the following data to the data table:
Code implementation 1: insert a new student information
Please enter the candidate's details
Type:
IDCard:
ExamCard:
StudentName:
Location:
Grade:
Information entered successfully!
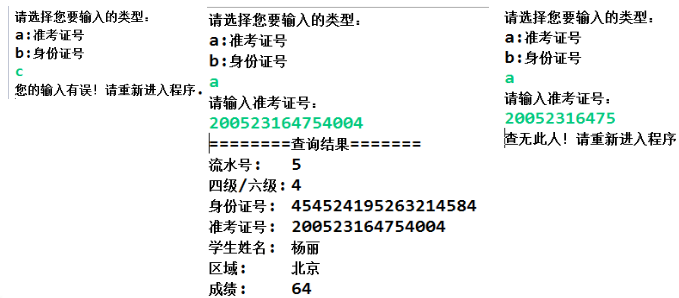
Code implementation 2: establish java program in eclipse: input ID number or ticket number to inquire basic information of students. The results are as follows:
Code implementation 3: complete the deletion function of student information

Operation BLOB type field
MySQL BLOB type
-
In MySQL, BLOB is a large binary object. It is a container that can store a large amount of data. It can hold data of different sizes.
-
PreparedStatement must be used for inserting data of BLOB type, because data of BLOB type cannot be spliced with strings.
-
Four BLOB types of MySQL (they are the same except that they are different in the maximum amount of information stored)
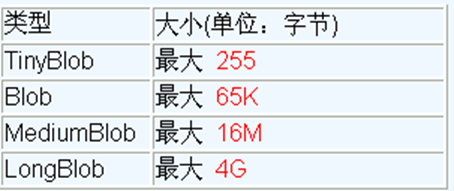
- In actual use, different BLOB types are defined according to the data size to be stored.
- It should be noted that if the stored file is too large, the performance of the database will decline.
- If an error is reported after specifying the related Blob type: xxx too large, find my. In the mysql installation directory INI file plus the following configuration parameters: max_allowed_packet=16M. Also note: modified my After the. INI file, you need to restart the mysql service.
Insert big data type into data table
// Get connection
Connection conn = JDBCUtils.getConnection();
String sql = "insert into customers(name,email,birth,photo)values(?,?,?,?)";
PreparedStatement ps = conn.prepareStatement(sql);
// Fill placeholder
ps.setString(1, "Xu Haiqiang");
ps.setString(2, "xhq@126.com");
ps.setDate(3, new Date(new java.util.Date().getTime()));
// Manipulate variables of Blob type
FileInputStream fis = new FileInputStream("xhq.png");
ps.setBlob(4, fis);
// implement
ps.execute();
fis.close();
JDBCUtils.closeResource(conn, ps);
Modify Blob type field in data table
Connection conn = JDBCUtils.getConnection();
String sql = "update customers set photo = ? where id = ?";
PreparedStatement ps = conn.prepareStatement(sql);
// Fill placeholder
// Manipulate variables of Blob type
FileInputStream fis = new FileInputStream("coffee.png");
ps.setBlob(1, fis);
ps.setInt(2, 25);
ps.execute();
fis.close();
JDBCUtils.closeResource(conn, ps);
Read big data type from data table
String sql = "SELECT id, name, email, birth, photo FROM customer WHERE id = ?";
conn = getConnection();
ps = conn.prepareStatement(sql);
ps.setInt(1, 8);
rs = ps.executeQuery();
if(rs.next()){
Integer id = rs.getInt(1);
String name = rs.getString(2);
String email = rs.getString(3);
Date birth = rs.getDate(4);
Customer cust = new Customer(id, name, email, birth);
System.out.println(cust);
// Read Blob type fields
Blob photo = rs.getBlob(5);
InputStream is = photo.getBinaryStream();
OutputStream os = new FileOutputStream("c.jpg");
byte [] buffer = new byte[1024];
int len = 0;
while((len = is.read(buffer)) != -1){
os.write(buffer, 0, len);
}
JDBCUtils.closeResource(conn, ps, rs);
if(is != null){
is.close();
}
if(os != null){
os.close();
}
}
Batch insert
Batch execution of SQL statements
When you need to insert or update records in batches, you can use the batch update mechanism of Java, which allows multiple statements to be submitted to the database for batch processing at one time. Generally, it is more efficient than submitting processing alone
JDBC batch processing statements include the following three methods:
- addBatch(String): add SQL statements or parameters that need batch processing;
- executeBatch(): execute batch processing statements;
- clearBatch(): clear cached data
Generally, we will encounter two cases of batch execution of SQL statements:
- Batch processing of multiple SQL statements;
- Batch parameter transfer of an SQL statement;
Efficient batch insertion
Example: insert 20000 pieces of data into the data table
- Provide a goods table in the database. Create the following:
CREATE TABLE goods( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(20) );
Implementation level 1: use Statement
Connection conn = JDBCUtils.getConnection();
Statement st = conn.createStatement();
for(int i = 1;i <= 20000;i++){
String sql = "insert into goods(name) values('name_' + "+ i +")";
st.executeUpdate(sql);
}
Implementation level 2: use PreparedStatement
long start = System.currentTimeMillis();
Connection conn = JDBCUtils.getConnection();
String sql = "insert into goods(name)values(?)";
PreparedStatement ps = conn.prepareStatement(sql);
for(int i = 1;i <= 20000;i++){
ps.setString(1, "name_" + i);
ps.executeUpdate();
}
long end = System.currentTimeMillis();
System.out.println("The time spent is:" + (end - start));//82340
JDBCUtils.closeResource(conn, ps);
Implementation level 3
/*
* Modification 1: use addBatch() / executeBatch() / clearBatch()
* Modify 2: the mysql server turns off batch processing by default. We need to use a parameter to enable mysql to turn on batch processing support.
* ?rewriteBatchedStatements=true Write after the url of the configuration file
* Modification 3: use the updated MySQL driver: mysql-connector-java-5.1 37-bin. jar
*
*/
@Test
public void testInsert1() throws Exception{
long start = System.currentTimeMillis();
Connection conn = JDBCUtils.getConnection();
String sql = "insert into goods(name)values(?)";
PreparedStatement ps = conn.prepareStatement(sql);
for(int i = 1;i <= 1000000;i++){
ps.setString(1, "name_" + i);
//1. Save sql
ps.addBatch();
if(i % 500 == 0){
//2. Implementation
ps.executeBatch();
//3. Empty
ps.clearBatch();
}
}
long end = System.currentTimeMillis();
System.out.println("The time spent is:" + (end - start));
// Article 20000: 625
// 1000000: 14733
JDBCUtils.closeResource(conn, ps);
}
Implementation level 4
/*
* Level 4: operate on the basis of level 3
* Setautocommit (false) / commit () using Connection
*/
@Test
public void testInsert2() throws Exception{
long start = System.currentTimeMillis();
Connection conn = JDBCUtils.getConnection();
// 1. Set not to submit data automatically
conn.setAutoCommit(false);
String sql = "insert into goods(name)values(?)";
PreparedStatement ps = conn.prepareStatement(sql);
for(int i = 1;i <= 1000000;i++){
ps.setString(1, "name_" + i);
//1. Save sql
ps.addBatch();
if(i % 500 == 0){
//2. Implementation
ps.executeBatch();
//3. Empty
ps.clearBatch();
}
}
//2. Submission of data
conn.commit();
long end = System.currentTimeMillis();
System.out.println("The time spent is:" + (end - start));//1000000: 4978
JDBCUtils.closeResource(conn, ps);
}
Database transaction
Introduction to database transactions
-
Transaction: a set of logical operation units that transform data from one state to another.
-
Transaction processing (transaction operation): ensure that all transactions are executed as a unit of work. Even in case of failure, this execution mode cannot be changed. When multiple operations are performed in a transaction, or all transactions are committed, these modifications will be permanently saved; Or the database management system will discard all the modifications made, and the whole transaction * * rollback * * will return to the original state.
-
In order to ensure the consistency of data in the database, the manipulation of data should be a discrete group of logical units: when it is completed, the consistency of data can be maintained, and when some operations in this unit fail, the whole transaction should be regarded as an error, and all operations after the starting point should be returned to the starting state.
JDBC transaction processing
-
Once the data is submitted, it cannot be rolled back.
-
When does data mean submission?
- When a connection object is created, the transaction is automatically committed by default: each time an SQL statement is executed, if the execution is successful, it will be automatically committed to the database instead of rolling back.
- **Close the database connection and the data will be submitted automatically** If there are multiple operations, and each operation uses its own separate connection, the transaction cannot be guaranteed. That is, multiple operations of the same transaction must be under the same connection.
-
In order to execute multiple SQL statements as one transaction in JDBC program:
- Call setAutoCommit(false) of the Connection object; To cancel the auto commit transaction
- After all SQL statements have been successfully executed, call commit(); Method commit transaction
- When an exception occurs, call rollback(); Method rolls back the transaction
If the Connection is not closed at this time and may be reused, you need to restore its automatic submission state setAutoCommit(true). Especially when using database Connection pool technology, it is recommended to restore the auto commit state before executing the close() method.
[case: user AA transfers 100 to user BB]
public void testJDBCTransaction() {
Connection conn = null;
try {
// 1. Get database connection
conn = JDBCUtils.getConnection();
// 2. Start transaction
conn.setAutoCommit(false);
// 3. Database operation
String sql1 = "update user_table set balance = balance - 100 where user = ?";
update(conn, sql1, "AA");
// Analog network exception
//System.out.println(10 / 0);
String sql2 = "update user_table set balance = balance + 100 where user = ?";
update(conn, sql2, "BB");
// 4. If there is no exception, commit the transaction
conn.commit();
} catch (Exception e) {
e.printStackTrace();
// 5. If there are exceptions, roll back the transaction
try {
conn.rollback();
} catch (SQLException e1) {
e1.printStackTrace();
}
} finally {
try {
// 6. Restore the automatic submission function of each DML operation
conn.setAutoCommit(true);
} catch (SQLException e) {
e.printStackTrace();
}
// 7. Close the connection
JDBCUtils.closeResource(conn, null, null);
}
}
Among them, the methods of database operation are:
// General addition, deletion and modification operations after using transactions (version 2.0)
public void update(Connection conn ,String sql, Object... args) {
PreparedStatement ps = null;
try {
// 1. Get the instance of PreparedStatement (or: precompiled sql statement)
ps = conn.prepareStatement(sql);
// 2. Fill placeholder
for (int i = 0; i < args.length; i++) {
ps.setObject(i + 1, args[i]);
}
// 3. Execute sql statement
ps.execute();
} catch (Exception e) {
e.printStackTrace();
} finally {
// 4. Close resources
JDBCUtils.closeResource(null, ps);
}
}
ACID property of the transaction
-
Atomicity
Atomicity means that a transaction is an indivisible unit of work, and operations in a transaction either occur or do not occur. -
Consistency
Transactions must transition the database from one consistency state to another. -
Isolation
Transaction isolation means that the execution of a transaction cannot be disturbed by other transactions, that is, the operations and data used within a transaction are isolated from other concurrent transactions, and the concurrent transactions cannot interfere with each other. -
Durability
Persistence means that once a transaction is committed, its changes to the data in the database are permanent, and other subsequent operations and database failures should not have any impact on it.
Concurrency of database
-
For multiple transactions running at the same time, when these transactions access the same data in the database, if the necessary isolation mechanism is not taken, various concurrency problems will be caused:
- Dirty read: for two transactions T1 and T2, T1 reads the fields that have been updated by T2 but have not been committed. After that, if T2 rolls back, the content read by T1 is temporary and invalid.
- Non repeatable reading: for two transactions T1 and T2, T1 reads a field, and then T2 updates the field. After that, T1 reads the same field again, and the value is different.
- Phantom reading: for two transactions T1 and T2, T1 reads a field from a table, and T2 inserts some new rows into the table. After that, if T1 reads the same table again, several more rows will appear.
-
Isolation of database transactions: the database system must have the ability to isolate and run various transactions concurrently, so that they will not affect each other and avoid various concurrency problems.
-
The degree to which a transaction is isolated from other transactions is called the isolation level. The database specifies multiple transaction isolation levels. Different isolation levels correspond to different interference levels. The higher the isolation level, the better the data consistency, but the weaker the concurrency.
Four isolation levels
-
The database provides four transaction isolation levels:

-
Oracle supports two transaction isolation levels: read committed and serial. The default transaction isolation level of Oracle is read committed.
-
Mysql supports four transaction isolation levels. The default transaction isolation level of Mysql is REPEATABLE READ.
Set isolation level in MySql
-
Every time you start a mysql program, you get a separate database connection Each database connection has a global variable @@tx_isolation, indicating the current transaction isolation level.
-
To view the current isolation level:
SELECT @@tx_isolation;
-
Set the isolation level of the current mySQL connection:
set transaction isolation level read committed;
-
Set the global isolation level of the database system:
set global transaction isolation level read committed;
-
Supplementary operation:
-
Create mysql database user:
create user tom identified by 'abc123';
-
Grant permissions
#Grant the tom user who logs in through the network with full permissions on all libraries and tables, and set the password to abc123 grant all privileges on *.* to tom@'%' identified by 'abc123'; #Use the local command line method to grant the tom user the authority to insert, delete, modify and query all tables under the atguigudb library. grant select,insert,delete,update on atguigudb.* to tom@localhost identified by 'abc123';
-
DAO and related implementation classes
- DAO: the class and interface of Data Access Object to access data information, including CRUD (Create, regression, Update, Delete) of data, without any business-related information. It is sometimes called BaseDAO
- Function: in order to realize the modularization of functions, it is more conducive to code maintenance and upgrading.
- The following is the embodiment of DAO use in the book city project of Java Web stage in Silicon Valley:
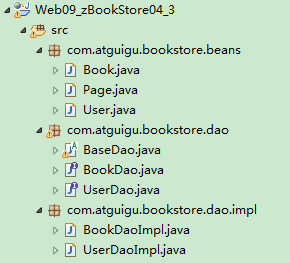
- Hierarchy:

[BaseDAO.java]
package com.atguigu.bookstore.dao;
import java.lang.reflect.ParameterizedType;
import java.lang.reflect.Type;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.List;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanHandler;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.apache.commons.dbutils.handlers.ScalarHandler;
/**
* Define an inherited Dao that performs basic operations on the database
*
* @author HanYanBing
*
* @param <T>
*/
public abstract class BaseDao<T> {
private QueryRunner queryRunner = new QueryRunner();
// Define a variable to receive generic types
private Class<T> type;
// Get the Class object of T and get the type of generic type. The generic type is determined only when it is inherited by the subclass
public BaseDao() {
// Gets the type of the subclass
Class clazz = this.getClass();
// Gets the type of the parent class
// getGenericSuperclass() is used to get the type of the parent class of the current class
// ParameterizedType represents a type with a generic type
ParameterizedType parameterizedType = (ParameterizedType) clazz.getGenericSuperclass();
// Get the specific generic type getActualTypeArguments get the type of the specific generic type
// This method returns an array of types
Type[] types = parameterizedType.getActualTypeArguments();
// Gets the type of the specific generic·
this.type = (Class<T>) types[0];
}
/**
* General addition, deletion and modification operations
*
* @param sql
* @param params
* @return
*/
public int update(Connection conn,String sql, Object... params) {
int count = 0;
try {
count = queryRunner.update(conn, sql, params);
} catch (SQLException e) {
e.printStackTrace();
}
return count;
}
/**
* Get an object
*
* @param sql
* @param params
* @return
*/
public T getBean(Connection conn,String sql, Object... params) {
T t = null;
try {
t = queryRunner.query(conn, sql, new BeanHandler<T>(type), params);
} catch (SQLException e) {
e.printStackTrace();
}
return t;
}
/**
* Get all objects
*
* @param sql
* @param params
* @return
*/
public List<T> getBeanList(Connection conn,String sql, Object... params) {
List<T> list = null;
try {
list = queryRunner.query(conn, sql, new BeanListHandler<T>(type), params);
} catch (SQLException e) {
e.printStackTrace();
}
return list;
}
/**
* Get a method that is worthy of being used to execute, such as select count(*) Such sql statements
*
* @param sql
* @param params
* @return
*/
public Object getValue(Connection conn,String sql, Object... params) {
Object count = null;
try {
// Call the query method of queryRunner to get a single value
count = queryRunner.query(conn, sql, new ScalarHandler<>(), params);
} catch (SQLException e) {
e.printStackTrace();
}
return count;
}
}
[BookDAO.java]
package com.atguigu.bookstore.dao;
import java.sql.Connection;
import java.util.List;
import com.atguigu.bookstore.beans.Book;
import com.atguigu.bookstore.beans.Page;
public interface BookDao {
/**
* Query all records from the database
*
* @return
*/
List<Book> getBooks(Connection conn);
/**
* Insert a record into the database
*
* @param book
*/
void saveBook(Connection conn,Book book);
/**
* Delete a record from the database based on the book id
*
* @param bookId
*/
void deleteBookById(Connection conn,String bookId);
/**
* Query a record from the database according to the id of the book
*
* @param bookId
* @return
*/
Book getBookById(Connection conn,String bookId);
/**
* Update a record from the database according to the book id
*
* @param book
*/
void updateBook(Connection conn,Book book);
/**
* Get book information with pagination
*
* @param page: Is a page object that contains only the pageNo attribute entered by the user
* @return The returned Page object is a Page object that contains all properties
*/
Page<Book> getPageBooks(Connection conn,Page<Book> page);
/**
* Get book information with pagination and price range
*
* @param page: Is a page object that contains only the pageNo attribute entered by the user
* @return The returned Page object is a Page object that contains all properties
*/
Page<Book> getPageBooksByPrice(Connection conn,Page<Book> page, double minPrice, double maxPrice);
}
[UserDAO.java]
package com.atguigu.bookstore.dao;
import java.sql.Connection;
import com.atguigu.bookstore.beans.User;
public interface UserDao {
/**
* Get a record from the database according to the User name and password in the User object
*
* @param user
* @return User There is a record in the database. There is no such record in the null database
*/
User getUser(Connection conn,User user);
/**
* Get a record from the database according to the User name in the User object
*
* @param user
* @return true There is a record in the database. false there is no such record in the database
*/
boolean checkUsername(Connection conn,User user);
/**
* Inserts a User object into the database
*
* @param user
*/
void saveUser(Connection conn,User user);
}
[BookDaoImpl.java]
package com.atguigu.bookstore.dao.impl;
import java.sql.Connection;
import java.util.List;
import com.atguigu.bookstore.beans.Book;
import com.atguigu.bookstore.beans.Page;
import com.atguigu.bookstore.dao.BaseDao;
import com.atguigu.bookstore.dao.BookDao;
public class BookDaoImpl extends BaseDao<Book> implements BookDao {
@Override
public List<Book> getBooks(Connection conn) {
// Call the method to get a List in BaseDao
List<Book> beanList = null;
// Write sql statement
String sql = "select id,title,author,price,sales,stock,img_path imgPath from books";
beanList = getBeanList(conn,sql);
return beanList;
}
@Override
public void saveBook(Connection conn,Book book) {
// Write sql statement
String sql = "insert into books(title,author,price,sales,stock,img_path) values(?,?,?,?,?,?)";
// Call the general addition, deletion and modification methods in BaseDao
update(conn,sql, book.getTitle(), book.getAuthor(), book.getPrice(), book.getSales(), book.getStock(),book.getImgPath());
}
@Override
public void deleteBookById(Connection conn,String bookId) {
// Write sql statement
String sql = "DELETE FROM books WHERE id = ?";
// Call the general addition, deletion and modification method in BaseDao
update(conn,sql, bookId);
}
@Override
public Book getBookById(Connection conn,String bookId) {
// Call the method to get an object in BaseDao
Book book = null;
// Write sql statement
String sql = "select id,title,author,price,sales,stock,img_path imgPath from books where id = ?";
book = getBean(conn,sql, bookId);
return book;
}
@Override
public void updateBook(Connection conn,Book book) {
// Write sql statement
String sql = "update books set title = ? , author = ? , price = ? , sales = ? , stock = ? where id = ?";
// Call the general addition, deletion and modification methods in BaseDao
update(conn,sql, book.getTitle(), book.getAuthor(), book.getPrice(), book.getSales(), book.getStock(), book.getId());
}
@Override
public Page<Book> getPageBooks(Connection conn,Page<Book> page) {
// Gets the total number of records of books in the database
String sql = "select count(*) from books";
// Call the method to get a single value in BaseDao
long totalRecord = (long) getValue(conn,sql);
// Set the total number of records in the page object
page.setTotalRecord((int) totalRecord);
// Get the List of records stored in the current page
String sql2 = "select id,title,author,price,sales,stock,img_path imgPath from books limit ?,?";
// Call the method to get a collection in BaseDao
List<Book> beanList = getBeanList(conn,sql2, (page.getPageNo() - 1) * Page.PAGE_SIZE, Page.PAGE_SIZE);
// Set the List to the page object
page.setList(beanList);
return page;
}
@Override
public Page<Book> getPageBooksByPrice(Connection conn,Page<Book> page, double minPrice, double maxPrice) {
// Gets the total number of records of books in the database
String sql = "select count(*) from books where price between ? and ?";
// Call the method to get a single value in BaseDao
long totalRecord = (long) getValue(conn,sql,minPrice,maxPrice);
// Set the total number of records in the page object
page.setTotalRecord((int) totalRecord);
// Get the List of records stored in the current page
String sql2 = "select id,title,author,price,sales,stock,img_path imgPath from books where price between ? and ? limit ?,?";
// Call the method to get a collection in BaseDao
List<Book> beanList = getBeanList(conn,sql2, minPrice , maxPrice , (page.getPageNo() - 1) * Page.PAGE_SIZE, Page.PAGE_SIZE);
// Set the List to the page object
page.setList(beanList);
return page;
}
}
[UserDaoImpl.java]
package com.atguigu.bookstore.dao.impl;
import java.sql.Connection;
import com.atguigu.bookstore.beans.User;
import com.atguigu.bookstore.dao.BaseDao;
import com.atguigu.bookstore.dao.UserDao;
public class UserDaoImpl extends BaseDao<User> implements UserDao {
@Override
public User getUser(Connection conn,User user) {
// Call the method to get an object in BaseDao
User bean = null;
// Write sql statement
String sql = "select id,username,password,email from users where username = ? and password = ?";
bean = getBean(conn,sql, user.getUsername(), user.getPassword());
return bean;
}
@Override
public boolean checkUsername(Connection conn,User user) {
// Call the method to get an object in BaseDao
User bean = null;
// Write sql statement
String sql = "select id,username,password,email from users where username = ?";
bean = getBean(conn,sql, user.getUsername());
return bean != null;
}
@Override
public void saveUser(Connection conn,User user) {
//Write sql statement
String sql = "insert into users(username,password,email) values(?,?,?)";
//Call the general addition, deletion and modification methods in BaseDao
update(conn,sql, user.getUsername(),user.getPassword(),user.getEmail());
}
}
[Book.java]
package com.atguigu.bookstore.beans;
/**
* Books
* @author keke
*
*/
public class Book {
private Integer id;
private String title; // title
private String author; // author
private double price; // Price
private Integer sales; // sales volume
private Integer stock; // stock
private String imgPath = "static/img/default.jpg"; // Path of cover picture
//Constructor, get(), set(), toString() strategy
}
[Page.java]
package com.atguigu.bookstore.beans;
import java.util.List;
/**
* Page number class
* @author keke
*
*/
public class Page<T> {
private List<T> list; // The collection of records found on each page
public static final int PAGE_SIZE = 4; // Number of records displayed per page
private int pageNo; // Current page
// private int totalPageNo; // Total pages, calculated
private int totalRecord; // The total number of records is obtained by querying the database
[User.java]
package com.atguigu.bookstore.beans;
/**
* User class
* @author keke
*
*/
public class User {
private Integer id;
private String username;
private String password;
private String email;
Database connection pool
The necessity of JDBC database connection pool
-
When developing web programs based on database, the traditional mode basically follows the following steps:
- Establish database connection in the main program (such as servlet and beans)
- Perform sql operations
- Disconnect database
-
Problems in the development of this model:
- Ordinary JDBC database connections are obtained using DriverManager. Each time a Connection is established to the database, the Connection must be loaded into memory, and then the user name and password must be verified (it takes 0.05s ~ 1s). When you need a database Connection, ask for one from the database and disconnect it after execution. This way will consume a lot of resources and time** The Connection resources of the database have not been well reused** If hundreds or even thousands of people are online at the same time, frequent database Connection operation will occupy a lot of system resources, and even cause server crash.
- **For each database connection, it must be disconnected after use** Otherwise, if the program fails to close due to exceptions, it will lead to memory leakage in the database system and eventually restart the database. (recall: what is Java's memory leak?)
- This development cannot control the number of connection objects created, and system resources will be allocated without consideration. If there are too many connections, it may also lead to memory leakage and server crash.
Database connection pool technology
-
In order to solve the problem of database connection in traditional development, database connection pool technology can be used.
-
The basic idea of database connection pool is to establish a "buffer pool" for database connections. Put a certain number of connections in the buffer pool in advance. When you need to establish a database connection, just take one from the buffer pool and put it back after use.
-
Database connection pool is responsible for allocating, managing and releasing database connections. It allows applications to reuse an existing database connection instead of re establishing one.
-
During initialization, the database connection pool will create a certain number of database connections into the connection pool. The number of these database connections is set by the minimum number of database connections. No matter whether these database connections are used or not, the connection pool will always ensure that there are at least so many connections. The maximum number of database connections in the connection pool limits the maximum number of connections that the connection pool can occupy. When the number of connections requested by the application from the connection pool exceeds the maximum number of connections, these requests will be added to the waiting queue.
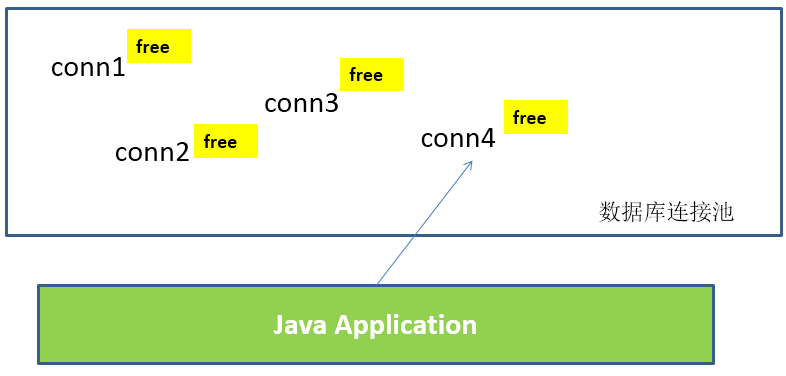
- working principle:
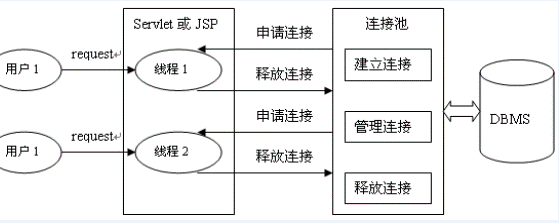
-
Advantages of database connection pool technology
1. Resource reuse
Because the database connection can be reused, it avoids frequent creation and releases a lot of performance overhead caused by the connection. On the basis of reducing system consumption, on the other hand, it also increases the stability of system operation environment.
2. Faster system response
During the initialization of the database connection pool, several database connections have often been created and placed in the connection pool for standby. At this time, the initialization of the connection has been completed. For business request processing, the existing available connections are directly used to avoid the time overhead of database connection initialization and release process, so as to reduce the response time of the system
3. New means of resource allocation
For systems where multiple applications share the same database, the maximum number of available database connections of an application can be limited through the configuration of database connection pool at the application layer to avoid an application monopolizing all database resources
4. Unified connection management to avoid database connection leakage
In the more perfect implementation of database connection pool, the occupied connections can be forcibly recovered according to the pre occupation timeout setting, so as to avoid the possible resource leakage in the conventional database connection operation
Multiple open source database connection pools
- The database connection pool of JDBC uses javax sql. DataSource means that DataSource is just an interface, which is usually implemented by servers (Weblogic, WebSphere, Tomcat) and some open source organizations:
- dbcp is a database connection pool provided by Apache. The tomcat server has its own dbcp database connection pool. The speed is relatively c3p0 fast, but hibernate 3 no longer provides support due to its own BUG.
- C3P0 is a database connection pool provided by an open source organization. The * * speed is relatively slow and the stability is OK** hibernate is officially recommended
- Proxool is an open source project database connection pool under sourceforge. It has the function of monitoring the status of the connection pool, and its stability is c3p0 poor
- BoneCP is a database connection pool provided by an open source organization with high speed
- Druid is a database connection pool provided by Alibaba. It is said to be a database connection pool integrating the advantages of DBCP, C3P0 and Proxool. However, it is uncertain whether it is faster than BoneCP
- DataSource is usually called data source, which includes connection pool and connection pool management. Traditionally, DataSource is often called connection pool
- DataSource is used to replace DriverManager to obtain Connection, which is fast and can greatly improve database access speed.
- Special attention:
- The data source is different from the database connection. There is no need to create multiple data sources. It is the factory that generates the database connection. Therefore, the whole application only needs one data source.
- After the database access is completed, the program closes the database connection as before: conn.close(); However, Conn. Close () does not close the physical connection to the database. It only releases the database connection and returns it to the database connection pool.
C3P0 database connection pool
- Get connection method 1
// Use C3P0 database connection pool to obtain database connection: not recommended
public static Connection getConnection1() throws Exception{
ComboPooledDataSource cpds = new ComboPooledDataSource();
cpds.setDriverClass("com.mysql.jdbc.Driver");
cpds.setJdbcUrl("jdbc:mysql://localhost:3306/test");
cpds.setUser("root");
cpds.setPassword("abc123");
// cpds.setMaxPoolSize(100);
Connection conn = cpds.getConnection();
return conn;
}
- Get connection mode 2
// Use the configuration file method of C3P0 database connection pool to obtain database connection: Recommended
private static DataSource cpds = new ComboPooledDataSource("helloc3p0");
public static Connection getConnection2() throws SQLException{
Connection conn = cpds.getConnection();
return conn;
}
The configuration file under src is: [c3p0 config. XML]
<?xml version="1.0" encoding="UTF-8"?> <c3p0-config> <named-config name="helloc3p0"> <!-- Get 4 basic information of connection --> <property name="user">root</property> <property name="password">abc123</property> <property name="jdbcUrl">jdbc:mysql:///test</property> <property name="driverClass">com.mysql.jdbc.Driver</property> <!-- Settings of related properties related to the management of database connection pool --> <!-- If the number of connections in the database is insufficient, How many connections are requested from the database server at a time --> <property name="acquireIncrement">5</property> <!-- The number of connections when initializing the database connection pool --> <property name="initialPoolSize">5</property> <!-- The minimum number of database connections in the database connection pool --> <property name="minPoolSize">5</property> <!-- The maximum number of database connections in the database connection pool --> <property name="maxPoolSize">10</property> <!-- C3P0 The database connection pool can be maintained Statement Number of --> <property name="maxStatements">20</property> <!-- Each connection can be used at the same time Statement Number of objects --> <property name="maxStatementsPerConnection">5</property> </named-config> </c3p0-config>
DBCP database connection pool
- DBCP is an open source connection pool implementation under the Apache Software Foundation, which relies on another open source system under the organization: common pool. If you need to use this connection pool, you should add the following two jar files to the system:
- Commons-dbcp.jar: implementation of connection pool
- Commons-pool.jar: dependency library for connection pool implementation
- **Tomcat's connection pool is implemented by this connection pool** The database connection pool can be integrated with the application server or used independently by the application.
- The data source is different from the database connection. There is no need to create multiple data sources. It is the factory that generates the database connection. Therefore, the whole application only needs one data source.
- After the database access is completed, the program closes the database connection as before: conn.close(); However, the above code does not close the physical connection to the database. It only releases the database connection and returns it to the database connection pool.
- Configuration attribute description
| attribute | Default value | explain |
|---|---|---|
| initialSize | 0 | The number of initialization connections created when the connection pool started |
| maxActive | 8 | The maximum number of simultaneous connections in the connection pool |
| maxIdle | 8 | The maximum number of free connections in the connection pool. More free connections will be released. If set to a negative number, it means no limit |
| minIdle | 0 | The minimum number of free connections in the connection pool. Below this number, new connections will be created. The closer the parameter is to the maxIdle, the better the performance, because the creation and destruction of connections consume resources; But not too big. |
| maxWait | unlimited | Maximum waiting time. When there is no available connection, the connection pool waits for the maximum time for the connection to be released. If the time limit is exceeded, an exception will be thrown. If - 1 is set, it means unlimited waiting |
| poolPreparedStatements | false | Whether the Statement of the open pool is prepared |
| maxOpenPreparedStatements | unlimited | The maximum number of simultaneous connections after the prepared of the pool is turned on |
| minEvictableIdleTimeMillis | The time when a connection in the connection pool is idle and expelled from the connection pool | |
| removeAbandonedTimeout | 300 | Recycling unused (discarded) connections beyond the time limit |
| removeAbandoned | false | After the removeAbandonedTimeout time is exceeded, whether to recycle unused connections (discarded) |
- Get connection method 1:
public static Connection getConnection3() throws Exception {
BasicDataSource source = new BasicDataSource();
source.setDriverClassName("com.mysql.jdbc.Driver");
source.setUrl("jdbc:mysql:///test");
source.setUsername("root");
source.setPassword("abc123");
//
source.setInitialSize(10);
Connection conn = source.getConnection();
return conn;
}
- Get connection mode 2:
// Use the configuration file method of dbcp database connection pool to obtain database connection: Recommended
private static DataSource source = null;
static{
try {
Properties pros = new Properties();
InputStream is = DBCPTest.class.getClassLoader().getResourceAsStream("dbcp.properties");
pros.load(is);
// Create the corresponding DataSource object according to the provided BasicDataSourceFactory
source = BasicDataSourceFactory.createDataSource(pros);
} catch (Exception e) {
e.printStackTrace();
}
}
public static Connection getConnection4() throws Exception {
Connection conn = source.getConnection();
return conn;
}
The configuration file under src is: [dbcp.properties]
driverClassName=com.mysql.jdbc.Driver url=jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=true&useServerPrepStmts=false username=root password=abc123 initialSize=10 #...
Druid database connection pool
Druid is a database connection pool implementation on Alibaba's open source platform. It combines the advantages of C3P0, DBCP, Proxool and other DB pools, and adds log monitoring. It can well monitor the connection of DB pool and the execution of SQL. It can be said that Druid is a DB connection pool for monitoring, which can be said to be one of the best connection pools at present.
package com.atguigu.druid;
import java.sql.Connection;
import java.util.Properties;
import javax.sql.DataSource;
import com.alibaba.druid.pool.DruidDataSourceFactory;
public class TestDruid {
public static void main(String[] args) throws Exception {
Properties pro = new Properties(); pro.load(TestDruid.class.getClassLoader().getResourceAsStream("druid.properties"));
DataSource ds = DruidDataSourceFactory.createDataSource(pro);
Connection conn = ds.getConnection();
System.out.println(conn);
}
}
The configuration file under src is: [druid.properties]
url=jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=true username=root password=123456 driverClassName=com.mysql.jdbc.Driver initialSize=10 maxActive=20 maxWait=1000 filters=wall
- Detailed configuration parameters:
| to configure | default | explain |
|---|---|---|
| name | The significance of configuring this attribute is that if there are multiple data sources, they can be distinguished by name during monitoring. If there is no configuration, a name will be generated in the format: "DataSource -" + system identityHashCode(this) | |
| url | The url to connect to the database is different from database to database. For example: MySQL: JDBC: mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20. 149.85:1521:ocnauto | |
| username | User name to connect to the database | |
| password | Password to connect to the database. If you don't want the password written directly in the configuration file, you can use ConfigFilter. See here for details: https://github.com/alibaba/druid/wiki/ Using ConfigFilter | |
| driverClassName | Automatic identification according to url is optional. If druid is not configured, dbType will be automatically identified according to url, and then corresponding driverclassname will be selected (under recommended configuration) | |
| initialSize | 0 | The number of physical connections established during initialization. Initialization occurs when the display calls the init method or the first getConnection |
| maxActive | 8 | Maximum number of connection pools |
| maxIdle | 8 | It is no longer used, and the configuration has no effect |
| minIdle | Minimum number of connection pools | |
| maxWait | Maximum wait time to get a connection, in milliseconds. After maxWait is configured, the fair lock is enabled by default, and the concurrency efficiency will be reduced. If necessary, you can use a non fair lock by configuring the useUnfairLock attribute to true. | |
| poolPreparedStatements | false | Whether to cache preparedStatement, that is, PSCache. PSCache greatly improves the performance of databases that support cursors, such as oracle. It is recommended to close under mysql. |
| maxOpenPreparedStatements | -1 | To enable PSCache, it must be configured to be greater than 0. When greater than 0, poolPreparedStatements is automatically triggered and modified to true. In Druid, there will be no problem that PSCache in Oracle occupies too much memory. You can configure this value to be larger, such as 100 |
| validationQuery | The sql used to check whether the connection is valid requires a query statement. If validationQuery is null, testonmirror, testOnReturn, and testwhiteidle will not work. | |
| testOnBorrow | true | When applying for a connection, execute validationQuery to check whether the connection is valid. This configuration will reduce performance. |
| testOnReturn | false | When returning the connection, execute validationQuery to check whether the connection is valid. This configuration will reduce the performance |
| testWhileIdle | false | It is recommended to configure to true, which will not affect performance and ensure security. Check when applying for a connection. If the idle time is greater than timebetween evictionrunsmillis, run validationQuery to check whether the connection is valid. |
| timeBetweenEvictionRunsMillis | It has two meanings: 1) the destroy thread will detect the connection interval; 2) the judgment basis of testwhiteidle. See the description of testwhiteidle property for details | |
| numTestsPerEvictionRun | No longer used, a DruidDataSource only supports one EvictionRun | |
| minEvictableIdleTimeMillis | ||
| connectionInitSqls | sql executed during physical connection initialization | |
| exceptionSorter | According to dbType, it is automatically recognized that when the database throws some unrecoverable exceptions, the connection is discarded | |
| filters | The attribute type is string. The extension plug-ins are configured by alias. The commonly used plug-ins are: filter for monitoring statistics: stat, filter for log: log4j, filter for defending sql injection: wall | |
| proxyFilters | The type is List. If both filters and proxyFilters are configured, it is a combination relationship, not a replacement relationship |
Apache dbutils implements CRUD operations
Introduction to Apache dbutils
-
Commons dbutils is an open source JDBC tool class library provided by Apache organization. It is a simple encapsulation of JDBC with very low learning cost. Using dbutils can greatly simplify the workload of JDBC coding without affecting the performance of the program.
-
API introduction:
- org.apache.commons.dbutils.QueryRunner
- org.apache.commons.dbutils.ResultSetHandler
- Tools: org apache. commons. dbutils. DbUtils
-
API package description:
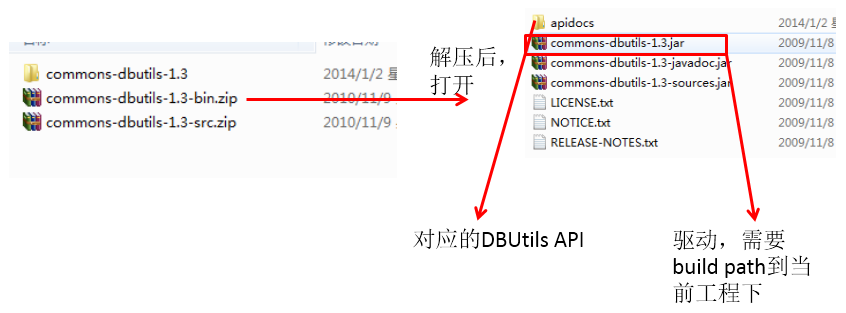

Use of major API s
DbUtils
- DbUtils: provides tool classes for routine work such as closing connections and loading JDBC drivers. All methods in them are static. The main methods are as follows:
- public static void close(…) throws java.sql.SQLException: the DbUtils class provides three overloaded shutdown methods. These methods check whether the supplied parameter is NULL, and if not, they close the Connection, Statement, and ResultSet.
- Public static void closequiet (...): this kind of method can not only avoid closing when the Connection, Statement and ResultSet are NULL, but also hide some SQLEeception thrown in the program.
- public static void commitAndClose(Connection conn)throws SQLException: used to commit the connected transaction and close the connection
- Public static void commitandclosequiet (connection conn): used to submit a connection and then close the connection. SQL exceptions are not thrown when closing the connection.
- public static void rollback(Connection conn)throws SQLException: conn is allowed to be null because a judgment is made inside the method
- public static void rollbackAndClose(Connection conn)throws SQLException
- rollbackAndCloseQuietly(Connection)
- public static boolean loadDriver(java.lang.String driverClassName): this party loads and registers the JDBC driver, and returns true if successful. Using this method, you do not need to catch this exception ClassNotFoundException.
QueryRunner class
-
This class simplifies SQL query. It can be used together with ResultSetHandler to complete most database operations and greatly reduce the amount of coding.
-
The QueryRunner class provides two constructors:
- Default constructor
- You need a javax sql. Datasource is used as the constructor of parameters
-
Main methods of QueryRunner class:
- to update
- public int update(Connection conn, String sql, Object... params) throws SQLException: used to perform an update (insert, update or delete) operation.
- ...
- insert
- public T insert(Connection conn,String sql,ResultSetHandler rsh, Object... params) throws SQLException: only INSERT statements are supported, where RSH - the handler used to create the result object from the resultset of auto generated keys Return value: An object generated by the handler That is, the automatically generated key value
- ...
- Batch processing
- public int[] batch(Connection conn,String sql,Object[][] params)throws SQLException: INSERT, UPDATE, or DELETE statements
- public T insertBatch(Connection conn,String sql,ResultSetHandler rsh,Object[][] params)throws SQLException: only INSERT statements are supported
- ...
- query
- public Object query(Connection conn, String sql, ResultSetHandler rsh,Object... params) throws SQLException: executes a query operation. In this query, each element value in the object array is used as the replacement parameter of the query statement. This method handles the creation and closing of PreparedStatement and ResultSet by itself.
- ...
- to update
-
test
// Test add
@Test
public void testInsert() throws Exception {
QueryRunner runner = new QueryRunner();
Connection conn = JDBCUtils.getConnection3();
String sql = "insert into customers(name,email,birth)values(?,?,?)";
int count = runner.update(conn, sql, "He Chengfei", "he@qq.com", "1992-09-08");
System.out.println("Added" + count + "Records");
JDBCUtils.closeResource(conn, null);
}
// Test delete
@Test
public void testDelete() throws Exception {
QueryRunner runner = new QueryRunner();
Connection conn = JDBCUtils.getConnection3();
String sql = "delete from customers where id < ?";
int count = runner.update(conn, sql,3);
System.out.println("Deleted" + count + "Records");
JDBCUtils.closeResource(conn, null);
}
ResultSetHandler interface and implementation class
-
This interface is used to handle Java sql. Resultset to convert the data into another form as required.
-
The ResultSetHandler interface provides a separate method: object handle (Java. SQL. Resultset. RS).
-
Main implementation classes of the interface:
-
ArrayHandler: converts the first row of data in the result set into an object array.
-
ArrayListHandler: convert each row of data in the result set into an array and store it in the List.
-
**BeanHandler: * * encapsulates the first row of data in the result set into a corresponding JavaBean instance.
-
**BeanListHandler: * * encapsulate each row of data in the result set into a corresponding JavaBean instance and store it in the List.
-
ColumnListHandler: store the data of a column in the result set in the List.
-
KeyedHandler(name): encapsulate each row of data in the result set into a map, and then save these maps into a map. The key is the specified key.
-
**MapHandler: * * encapsulates the first row of data in the result set into a Map. key is the column name and value is the corresponding value.
-
**MapListHandler: * * encapsulate each row of data in the result set into a Map, and then store it in the List
-
**ScalarHandler: * * query single value object
-
-
test
/*
* Test query: query a record
*
* Implementation class using ResultSetHandler: BeanHandler
*/
@Test
public void testQueryInstance() throws Exception{
QueryRunner runner = new QueryRunner();
Connection conn = JDBCUtils.getConnection3();
String sql = "select id,name,email,birth from customers where id = ?";
//
BeanHandler<Customer> handler = new BeanHandler<>(Customer.class);
Customer customer = runner.query(conn, sql, handler, 23);
System.out.println(customer);
JDBCUtils.closeResource(conn, null);
}
/*
* Test query: query a set composed of multiple records
*
* Implementation class using ResultSetHandler: BeanListHandler
*/
@Test
public void testQueryList() throws Exception{
QueryRunner runner = new QueryRunner();
Connection conn = JDBCUtils.getConnection3();
String sql = "select id,name,email,birth from customers where id < ?";
//
BeanListHandler<Customer> handler = new BeanListHandler<>(Customer.class);
List<Customer> list = runner.query(conn, sql, handler, 23);
list.forEach(System.out::println);
JDBCUtils.closeResource(conn, null);
}
/*
* Implementation class of custom ResultSetHandler
*/
@Test
public void testQueryInstance1() throws Exception{
QueryRunner runner = new QueryRunner();
Connection conn = JDBCUtils.getConnection3();
String sql = "select id,name,email,birth from customers where id = ?";
ResultSetHandler<Customer> handler = new ResultSetHandler<Customer>() {
@Override
public Customer handle(ResultSet rs) throws SQLException {
System.out.println("handle");
// return new Customer(1,"Tom","tom@126.com",new Date(123323432L));
if(rs.next()){
int id = rs.getInt("id");
String name = rs.getString("name");
String email = rs.getString("email");
Date birth = rs.getDate("birth");
return new Customer(id, name, email, birth);
}
return null;
}
};
Customer customer = runner.query(conn, sql, handler, 23);
System.out.println(customer);
JDBCUtils.closeResource(conn, null);
}
/*
* How to query data related to the largest, smallest, average, sum, and number,
* Using ScalarHandler
*
*/
@Test
public void testQueryValue() throws Exception{
QueryRunner runner = new QueryRunner();
Connection conn = JDBCUtils.getConnection3();
// Test 1:
// String sql = "select count(*) from customers where id < ?";
// ScalarHandler handler = new ScalarHandler();
// long count = (long) runner.query(conn, sql, handler, 20);
// System.out.println(count);
// Test 2:
String sql = "select max(birth) from customers";
ScalarHandler handler = new ScalarHandler();
Date birth = (Date) runner.query(conn, sql, handler);
System.out.println(birth);
JDBCUtils.closeResource(conn, null);
}
JDBC summary
@Test
public void testUpdateWithTx() {
Connection conn = null;
try {
// 1. Get connection(
// ① Handwritten connection: JDBC utils getConnection();
// ② Use database connection pool: C3P0;DBCP;Druid
// 2. Perform a series of CRUD operations on the data table
// ① Use PreparedStatement to realize general addition, deletion, modification and query operations (version 1.0 \ version 2.0)
// version2. Public void update (connection Conn, string SQL, object... Args) {}
// version2. Query public < T > t getInstance (connection Conn, class < T > clazz, string SQL, object... Args) {}
// ② Use the QueryRunner class provided in the jar package provided by dbutils
// Submit data
conn.commit();
} catch (Exception e) {
e.printStackTrace();
try {
// Undo Data
conn.rollback();
} catch (SQLException e1) {
e1.printStackTrace();
}
}finally{
// 3. Close the connection
// ① JDBCUtils.closeResource();
// ② Using the dbutils class provided in the jar package provided by dbutils provides the related operation of closing
}
}