7: Database connection pool
7.1 necessity of JDBC database connection pool
-
When developing web programs based on database, the traditional mode basically follows the following steps:
- Establish database connection in the main program (such as servlet and beans)
- Perform sql operations
- Disconnect database
-
Problems in the development of this model:
- Ordinary JDBC database connections are obtained using DriverManager. Each time a Connection is established to the database, the Connection must be loaded into memory, and then the user name and password must be verified (it takes 0.05s ~ 1s). When you need a database Connection, ask for one from the database and disconnect it after execution. This way will consume a lot of resources and time** The Connection resources of the database have not been well reused** If hundreds or even thousands of people are online at the same time, frequent database Connection operation will occupy a lot of system resources, and even cause server crash.
- **For each database connection, it must be disconnected after use** Otherwise, if the program fails to close due to exceptions, it will lead to memory leakage in the database system and eventually restart the database. (recall: what is Java's memory leak?)
- This development cannot control the number of connection objects created, and system resources will be allocated without consideration. If there are too many connections, it may also lead to memory leakage and server crash.
7.2 database connection pool technology
-
In order to solve the problem of database connection in traditional development, database connection pool technology can be used.
-
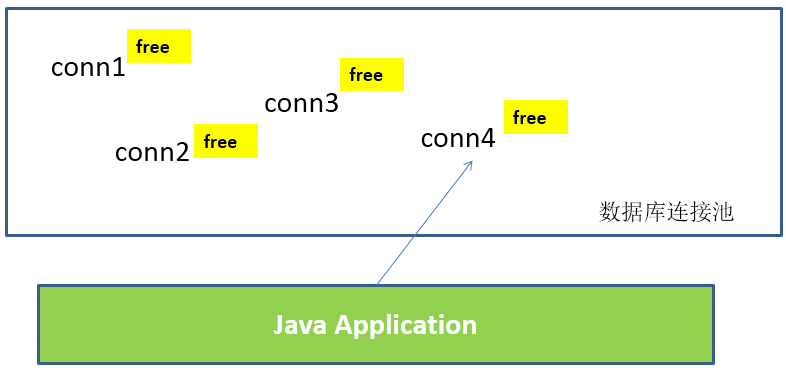
The basic idea of database connection pool is to establish a "buffer pool" for database connections. Put a certain number of connections in the buffer pool in advance. When you need to establish a database connection, just take one from the buffer pool and put it back after use.
-
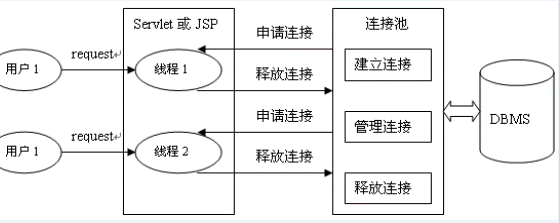
Database connection pool is responsible for allocating, managing and releasing database connections. It allows applications to reuse an existing database connection instead of re establishing one.
-
During initialization, the database connection pool will create a certain number of database connections into the connection pool. The number of these database connections is set by the minimum number of database connections. No matter whether these database connections are used or not, the connection pool will always ensure that there are at least so many connections. The maximum number of database connections in the connection pool limits the maximum number of connections that the connection pool can occupy. When the number of connections requested by the application from the connection pool exceeds the maximum number of connections, these requests will be added to the waiting queue.
- working principle:
-
Advantages of database connection pool technology
1. Resource reuse
Because the database connection can be reused, it avoids frequent creation and releases a lot of performance overhead caused by the connection. On the basis of reducing system consumption, on the other hand, it also increases the stability of system operation environment.
2. Faster system response
During the initialization of the database connection pool, several database connections have often been created and placed in the connection pool for standby. At this time, the initialization of the connection has been completed. For business request processing, the existing available connections are directly used to avoid the time overhead of database connection initialization and release process, so as to reduce the response time of the system
3. New means of resource allocation
For systems where multiple applications share the same database, the maximum number of available database connections of an application can be limited through the configuration of database connection pool at the application layer to avoid an application monopolizing all database resources
4. Unified connection management to avoid database connection leakage
In the more perfect implementation of database connection pool, the occupied connections can be forcibly recovered according to the pre occupation timeout setting, so as to avoid the possible resource leakage in the conventional database connection operation
7.3 multiple open source database connection pools
- The database connection pool of JDBC uses javax sql. DataSource means that DataSource is just an interface, which is usually implemented by servers (Weblogic, WebSphere, Tomcat) and some open source organizations:
- dbcp is a database connection pool provided by Apache. The tomcat server has its own dbcp database connection pool. The speed is relatively c3p0 fast, but hibernate 3 no longer provides support due to its own BUG.
- C3P0 is a database connection pool provided by an open source organization. The * * speed is relatively slow and the stability is OK** hibernate is officially recommended
- Proxool is an open source project database connection pool under sourceforge. It has the function of monitoring the status of the connection pool, and its stability is c3p0 poor
- BoneCP is a database connection pool provided by an open source organization with high speed
- Druid is a database connection pool provided by Alibaba. It is said to be a database connection pool integrating the advantages of DBCP, C3P0 and Proxool. However, it is uncertain whether it is faster than BoneCP
- DataSource is usually called data source, which includes connection pool and connection pool management. Traditionally, DataSource is often called connection pool
- DataSource is used to replace DriverManager to obtain Connection, which is fast and can greatly improve database access speed.
- Special attention:
- The data source is different from the database connection. There is no need to create multiple data sources. It is the factory that generates the database connection. Therefore, the whole application only needs one data source.
- When the database access is finished, the program closes the database connection as before: conn.close(); However, Conn. Close () does not close the physical connection to the database. It only releases the database connection and returns it to the database connection pool.
7.3.1 C3P0 database connection pool
- Get connection method 1
//Use C3P0 database connection pool to obtain database connection: not recommended
public static Connection getConnection1() throws Exception{
ComboPooledDataSource cpds = new ComboPooledDataSource();
cpds.setDriverClass("com.mysql.jdbc.Driver");
cpds.setJdbcUrl("jdbc:mysql://localhost:3306/test");
cpds.setUser("root");
cpds.setPassword("abc123");
// cpds.setMaxPoolSize(100);
Connection conn = cpds.getConnection();
return conn;
}
- Get connection mode 2
//Use the configuration file method of C3P0 database connection pool to obtain database connection: Recommended
private static DataSource cpds = new ComboPooledDataSource("helloc3p0");
public static Connection getConnection2() throws SQLException{
Connection conn = cpds.getConnection();
return conn;
}
The configuration file under src is: [c3p0 config. XML]
<?xml version="1.0" encoding="UTF-8"?> <c3p0-config> <named-config name="helloc3p0"> <!-- Get 4 basic information of connection --> <property name="user">root</property> <property name="password">abc123</property> <property name="jdbcUrl">jdbc:mysql:///test</property> <property name="driverClass">com.mysql.jdbc.Driver</property> <!-- Settings of related properties related to the management of database connection pool --> <!-- If the number of connections in the database is insufficient, How many connections are requested from the database server at a time --> <property name="acquireIncrement">5</property> <!-- The number of connections when initializing the database connection pool --> <property name="initialPoolSize">5</property> <!-- The minimum number of database connections in the database connection pool --> <property name="minPoolSize">5</property> <!-- The maximum number of database connections in the database connection pool --> <property name="maxPoolSize">10</property> <!-- C3P0 The database connection pool can be maintained Statement Number of --> <property name="maxStatements">20</property> <!-- Each connection can be used at the same time Statement Number of objects --> <property name="maxStatementsPerConnection">5</property> </named-config> </c3p0-config>
7.3.2 DBCP database connection pool
- DBCP is an open source connection pool implementation under the Apache Software Foundation, which relies on another open source system under the organization: common pool. If you need to use this connection pool, you should add the following two jar files to the system:
- Commons-dbcp.jar: implementation of connection pool
- Commons-pool.jar: dependency library for connection pool implementation
- Tomcat's connection pool is implemented by this connection pool The database connection pool can be integrated with the application server or used independently by the application.
- The data source is different from the database connection. There is no need to create multiple data sources. It is the factory that generates the database connection. Therefore, the whole application only needs one data source.
- When the database access is finished, the program closes the database connection as before: conn.close(); However, the above code does not close the physical connection to the database. It only releases the database connection and returns it to the database connection pool.
- Configuration attribute description
| attribute | Default value | explain |
|---|---|---|
| initialSize | 0 | The number of initialization connections created when the connection pool started |
| maxActive | 8 | The maximum number of simultaneous connections in the connection pool |
| maxIdle | 8 | The maximum number of free connections in the connection pool. More free connections will be released. If set to a negative number, it means no limit |
| minIdle | 0 | The minimum number of free connections in the connection pool. Below this number, new connections will be created. The closer the parameter is to the maxIdle, the better the performance, because the creation and destruction of connections consume resources; But not too big. |
| maxWait | unlimited | Maximum waiting time. When there is no available connection, the connection pool waits for the maximum time for the connection to be released. If the time limit is exceeded, an exception will be thrown. If - 1 is set, it means unlimited waiting |
| poolPreparedStatements | false | Whether the Statement of the open pool is prepared |
| maxOpenPreparedStatements | unlimited | The maximum number of simultaneous connections after the prepared of the pool is turned on |
| minEvictableIdleTimeMillis | The time when a connection in the connection pool is idle and expelled from the connection pool | |
| removeAbandonedTimeout | 300 | Recycling unused (discarded) connections beyond the time limit |
| removeAbandoned | false | After the removeAbandonedTimeout time is exceeded, whether to recycle unused connections (discarded) |
- Get connection method 1:
public static Connection getConnection3() throws Exception {
BasicDataSource source = new BasicDataSource();
source.setDriverClassName("com.mysql.jdbc.Driver");
source.setUrl("jdbc:mysql:///test");
source.setUsername("root");
source.setPassword("abc123");
//
source.setInitialSize(10);
Connection conn = source.getConnection();
return conn;
}
- Get connection mode 2:
//Use the configuration file method of dbcp database connection pool to obtain database connection: Recommended
private static DataSource source = null;
static{
try {
Properties pros = new Properties();
InputStream is = DBCPTest.class.getClassLoader().getResourceAsStream("dbcp.properties");
pros.load(is);
//Create the corresponding DataSource object according to the provided BasicDataSourceFactory
source = BasicDataSourceFactory.createDataSource(pros);
} catch (Exception e) {
e.printStackTrace();
}
}
public static Connection getConnection4() throws Exception {
Connection conn = source.getConnection();
return conn;
}
The configuration file under src is: [dbcp.properties]
driverClassName=com.mysql.jdbc.Driver url=jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=true&useServerPrepStmts=false username=root password=abc123 initialSize=10
7.3.3 Druid database connection pool
Druid is a database connection pool implementation on Alibaba's open source platform. It combines the advantages of C3P0, DBCP, Proxool and other DB pools, and adds log monitoring. It can well monitor the connection of DB pool and the execution of SQL. It can be said that Druid is a DB connection pool for monitoring, which can be said to be one of the best connection pools at present.
package com.atguigu.druid;
import java.sql.Connection;
import java.util.Properties;
import javax.sql.DataSource;
import com.alibaba.druid.pool.DruidDataSourceFactory;
public class TestDruid {
public static void main(String[] args) throws Exception {
Properties pro = new Properties(); pro.load(TestDruid.class.getClassLoader().getResourceAsStream("druid.properties"));
DataSource ds = DruidDataSourceFactory.createDataSource(pro);
Connection conn = ds.getConnection();
System.out.println(conn);
}
}
The configuration file under src is: [druid.properties]
url=jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=true username=root password=123456 driverClassName=com.mysql.jdbc.Driver initialSize=10 maxActive=20 maxWait=1000 filters=wall
- Detailed configuration parameters:
| to configure | default | explain |
|---|---|---|
| name | The significance of configuring this attribute is that if there are multiple data sources, they can be distinguished by name during monitoring. If there is no configuration, a name will be generated in the format: "DataSource -" + system identityHashCode(this) | |
| url | The url to connect to the database is different from database to database. For example: MySQL: JDBC: mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto | |
| username | User name to connect to the database | |
| password | Password to connect to the database. If you don't want the password written directly in the configuration file, you can use ConfigFilter. See here for details: https://github.com/alibaba/druid/wiki/ Using ConfigFilter | |
| driverClassName | Automatic identification according to url is optional. If druid is not configured, dbType will be automatically identified according to url, and then corresponding driverclassname will be selected (under recommended configuration) | |
| initialSize | 0 | The number of physical connections established during initialization. Initialization occurs when the display calls the init method or the first getConnection |
| maxActive | 8 | Maximum number of connection pools |
| maxIdle | 8 | It is no longer used, and the configuration has no effect |
| minIdle | Minimum number of connection pools | |
| maxWait | Maximum wait time to get a connection, in milliseconds. After maxWait is configured, the fair lock is enabled by default, and the concurrency efficiency will be reduced. If necessary, you can use a non fair lock by configuring the useUnfairLock attribute to true. | |
| poolPreparedStatements | false | Whether to cache preparedStatement, that is, PSCache. PSCache greatly improves the performance of databases that support cursors, such as oracle. It is recommended to close under mysql. |
| maxOpenPreparedStatements | -1 | To enable PSCache, it must be configured to be greater than 0. When greater than 0, poolPreparedStatements will be automatically triggered and modified to true. In Druid, there will be no problem that PSCache in Oracle occupies too much memory. You can configure this value to be larger, such as 100 |
| validationQuery | The sql used to check whether the connection is valid requires a query statement. If validationQuery is null, testonmirror, testOnReturn and testwhiteidle will not work. | |
| testOnBorrow | true | When applying for a connection, execute validationQuery to check whether the connection is valid. This configuration will reduce the performance. |
| testOnReturn | false | When returning the connection, execute validationQuery to check whether the connection is valid. This configuration will reduce the performance |
| testWhileIdle | false | It is recommended to configure to true, which will not affect performance and ensure security. Check when applying for a connection. If the idle time is greater than timebetween evictionrunsmillis, run validationQuery to check whether the connection is valid. |
| timeBetweenEvictionRunsMillis | It has two meanings: 1) the destroy thread will detect the connection interval; 2) the judgment basis of testwhiteidle. See the description of testwhiteidle attribute for details | |
| numTestsPerEvictionRun | No longer used, a DruidDataSource only supports one EvictionRun | |
| minEvictableIdleTimeMillis | ||
| connectionInitSqls | sql executed during physical connection initialization | |
| exceptionSorter | According to dbType, it is automatically recognized that when the database throws some unrecoverable exceptions, the connection is discarded | |
| filters | The attribute type is string. The extension plug-ins are configured by alias. The commonly used plug-ins are: filter for monitoring statistics: stat, filter for log: log4j, filter for defending sql injection: wall | |
| proxyFilters | The type is List. If both filters and proxyFilters are configured, it is a combination relationship, not a replacement relationship |
8. Apache dbutils implements CRUD operation
8.1 introduction to Apache dbutils
-
Commons dbutils is an open source JDBC tool class library provided by Apache organization. It is a simple encapsulation of JDBC with very low learning cost. Using dbutils can greatly simplify the workload of JDBC coding without affecting the performance of the program.
-
API introduction:
- org.apache.commons.dbutils.QueryRunner
- org.apache.commons.dbutils.ResultSetHandler
- Tools: org apache. commons. dbutils. DbUtils
-
API package description:
[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-1f8f4xoa-164250286905) (webresource7bf643a7df00265841c2753fdfbe2972)]
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-HUpPO4CD-1642502486905)(WEBRESOURCE0fc71c407b28aad4169edd415deedfa2)]
9.2 use of main API s
9.2.1 DbUtils
- DbUtils: provides tool classes for routine work such as closing connections and loading JDBC drivers. All methods in them are static. The main methods are as follows:
- public static void close(…) throws java.sql.SQLException: the DbUtils class provides three overloaded shutdown methods. These methods check whether the supplied parameter is NULL, and if not, they close the Connection, Statement and ResultSet.
- Public static void closequiet (...): this kind of method can not only avoid closing when the Connection, Statement and ResultSet are NULL, but also hide some SQLEeception thrown in the program.
- public static void commitAndClose(Connection conn)throws SQLException: used to commit the connected transaction and close the connection
- Public static void commitandclosequiet (connection conn): used to submit a connection and then close the connection. SQL exceptions are not thrown when closing the connection.
- public static void rollback(Connection conn)throws SQLException: conn is allowed to be null because a judgment is made inside the method
- public static void rollbackAndClose(Connection conn)throws SQLException
- rollbackAndCloseQuietly(Connection)
- public static boolean loadDriver(java.lang.String driverClassName): this party loads and registers the JDBC driver, and returns true if successful. Using this method, you do not need to catch this exception ClassNotFoundException.
9.2.2 QueryRunner class
-
This class simplifies SQL query. It can be used together with ResultSetHandler to complete most database operations and greatly reduce the amount of coding.
-
The QueryRunner class provides two constructors:
- Default constructor
- You need a javax sql. Datasource is used as the constructor of parameters
-
Main methods of QueryRunner class:
- to update
- public int update(Connection conn, String sql, Object... params) throws SQLException: used to perform an update (insert, update or delete) operation.
- ...
- insert
- Public < T > t INSERT (connection Conn, string SQL, resultsethandler < T > RSH, object... Params) throws sqlexception: only INSERT statements are supported, where RSH - the handler used to create the result object from the resultset of auto generated keys Return value: An object generated by the handler That is, the automatically generated key value
- ...
- Batch processing
- public int[] batch(Connection conn,String sql,Object[][] params)throws SQLException: INSERT, UPDATE, or DELETE statements
- public T insertBatch(Connection conn,String sql,ResultSetHandler rsh,Object[][] params)throws SQLException: only INSERT statements are supported
- ...
- query
-public Object query(Connection conn, String sql, ResultSetHandler rsh,Object... params) throws SQLException: executes a query operation. In this query, each element value in the object array is used as the replacement parameter of the query statement. This method handles the creation and closing of PreparedStatement and ResultSet by itself.- ...
- to update
-
test
// Test add
@Test
public void testInsert() throws Exception {
QueryRunner runner = new QueryRunner();
Connection conn = JDBCUtils.getConnection3();
String sql = "insert into customers(name,email,birth)values(?,?,?)";
int count = runner.update(conn, sql, "He Chengfei", "he@qq.com", "1992-09-08");
System.out.println("Added" + count + "Records");
JDBCUtils.closeResource(conn, null);
}
// Test delete
@Test
public void testDelete() throws Exception {
QueryRunner runner = new QueryRunner();
Connection conn = JDBCUtils.getConnection3();
String sql = "delete from customers where id < ?";
int count = runner.update(conn, sql,3);
System.out.println("Deleted" + count + "Records");
JDBCUtils.closeResource(conn, null);
}
9.2.3 ResultSetHandler interface and implementation class
-
This interface is used to handle Java sql. Resultset to convert the data into another form as required.
-
The ResultSetHandler interface provides a separate method: object handle (Java. SQL. Resultset. RS).
-
Main implementation classes of the interface:
- ArrayHandler: converts the first row of data in the result set into an object array.
- ArrayListHandler: convert each row of data in the result set into an array and store it in the List.
- **BeanHandler: * * encapsulates the first row of data in the result set into a corresponding JavaBean instance.
- **BeanListHandler: * * encapsulate each row of data in the result set into a corresponding JavaBean instance and store it in the List.
- ColumnListHandler: store the data of a column in the result set in the List.
- KeyedHandler(name): encapsulate each row of data in the result set into a map, and then save these maps into a map. The key is the specified key.
- **MapHandler: * * encapsulates the first row of data in the result set into a Map. key is the column name and value is the corresponding value.
- **MapListHandler: * * encapsulate each row of data in the result set into a Map, and then store it in the List
- **ScalarHandler: * * query single value object
-
test
Test query: query a record
/*
* Test query: query a record
*
* Implementation class using ResultSetHandler: BeanHandler
*/
@Test
public void queryTest() {
QueryRunner runner = new QueryRunner();
try {
Connection connection = DruildTest.getDruidConnection();
String sql = "select id,name,email,birth from my_jdbc.customers where id = ?";
BeanHandler<Customer> handler = new BeanHandler<>(Customer.class);
Customer customer = runner.query(connection, sql, handler, 16);
System.out.println(customer);
} catch (SQLException e) {
e.printStackTrace();
}
}
Test query: query a set composed of multiple records
/*
* Test query: query a set composed of multiple records
*
* Implementation class using ResultSetHandler: BeanListHandler
*/
@Test
public void queryTest2() {
QueryRunner runner = new QueryRunner();
try {
Connection connection = DruildTest.getDruidConnection();
String sql = "select id,name,email,birth from my_jdbc.customers";
BeanListHandler<Customer> handler = new BeanListHandler<>(Customer.class);
List<Customer> customers = runner.query(connection, sql, handler);
customers.forEach(System.out::println);
} catch (SQLException e) {
e.printStackTrace();
}
}
Implementation class of custom ResultSetHandler
/*
* Implementation class of custom ResultSetHandler
*/
@Test
public void testQueryInstance1() throws Exception{
QueryRunner runner = new QueryRunner();
Connection conn = JDBCUtils.getConnection3();
String sql = "select id,name,email,birth from customers where id = ?";
ResultSetHandler<Customer> handler = new ResultSetHandler<Customer>() {
@Override
public Customer handle(ResultSet rs) throws SQLException {
System.out.println("handle");
return new Customer(1,"Tom","tom@126.com",new Date(123323432L));
if(rs.next()){
int id = rs.getInt("id");
String name = rs.getString("name");
String email = rs.getString("email");
Date birth = rs.getDate("birth");
return new Customer(id, name, email, birth);
}
return null;
}
};
Customer customer = runner.query(conn, sql, handler, 23);
System.out.println(customer);
JDBCUtils.closeResource(conn, null);
}
Update a piece of data
@SneakyThrows
@Test
public void updateTest() {
QueryRunner queryRunner = new QueryRunner();
Connection connection = DruildTest.getDruidConnection();
String sql = "update my_jdbc.user set address = ? where id = ?";
int update = queryRunner.update(connection, sql, "Shanghai", 4);
System.out.println(update);
DbUtils.closeQuietly(connection);
}
Queries are similar to the largest, smallest, average, sum, and number related data
/*
* How to query data related to the largest, smallest, average, sum, and number,
* Using ScalarHandler
*
*/
@Test
public void testQueryValue() throws Exception{
QueryRunner runner = new QueryRunner();
Connection conn = JDBCUtils.getConnection3();
//Test 1:
// String sql = "select count(*) from customers where id < ?";
// ScalarHandler handler = new ScalarHandler();
// long count = (long) runner.query(conn, sql, handler, 20);
// System.out.println(count);
//Test 2:
String sql = "select max(birth) from customers";
ScalarHandler handler = new ScalarHandler();
Date birth = (Date) runner.query(conn, sql, handler);
System.out.println(birth);
JDBCUtils.closeResource(conn, null);
}
JDBC summary
summary
@Test
public void testUpdateWithTx() {
Connection conn = null;
try {
//1. Get connection(
//① Handwritten connection: JDBC utils getConnection();
//② Use database connection pool: C3P0;DBCP;Druid
//2. Perform a series of CRUD operations on the data table
//① Use PreparedStatement to realize general addition, deletion, modification and query operations (version 1.0 \ version 2.0)
//version2. Public void update (connection Conn, string SQL, object... Args) {}
//version2. Query public < T > t getInstance (connection Conn, class < T > clazz, string SQL, object... Args) {}
//② Use the QueryRunner class provided in the jar package provided by dbutils
//Submit data
conn.commit();
} catch (Exception e) {
e.printStackTrace();
try {
//Undo Data
conn.rollback();
} catch (SQLException e1) {
e1.printStackTrace();
}
}finally{
//3. Close the connection
//① JDBCUtils.closeResource();
//② Using the dbutils class provided in the jar package provided by dbutils provides the related operation of closing
}
}