
I. Basic concepts
Hash table: also known as hash table, is a commonly used data structure. It can access data directly according to the key value, so as to write and search data within the time complexity of O(1).
Hash function: A function that maps a key value to a location in a hash list.
Collision: Sometimes different key values are mapped to the same hash table location, which is called collision.
Load factor: Number of elements added to the Hash list / length of the hash table. It is a parameter to measure how full a hash table can be.
When a collision occurs, it means that the hash function of multiple keys has the same value, which requires extra cost to find the final location. Therefore, an ideal hash function needs to distribute the key values evenly in the hash table.
In addition, hash tables can not be loaded too slowly, if they are too full, the probability of collision will be greatly increased, but if they are too loose, it will waste too much space, so the loading factor needs to take an appropriate value to improve the efficiency of hash tables.
Common collision resolution methods are:
-
Open Addressing: When a conflict occurs, a specific formula is used to calculate the new location until no conflict occurs. For example:
Among them, f is a hash function, m is the maximum length of the hash table, and d is an increment, which can be fixed or random.H=(f(key) + d) % m - Chain Address Method: Connect conflicting elements with linked lists. When searching, look one by one in the list. As shown in the following figure:
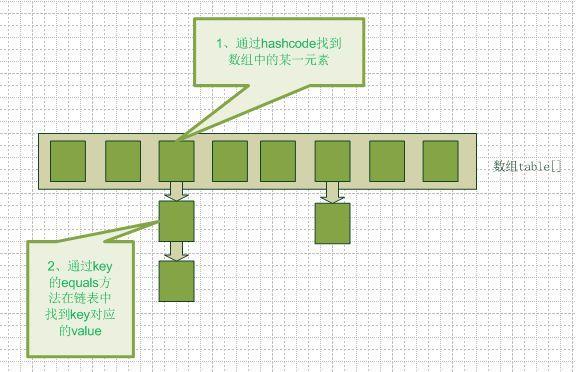
-
Rehashing method: A set of hash functions is preset. When collision occurs, other hash functions are used to calculate until no collision occurs.
Class Definition
HashMap classes are defined as follows:public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable
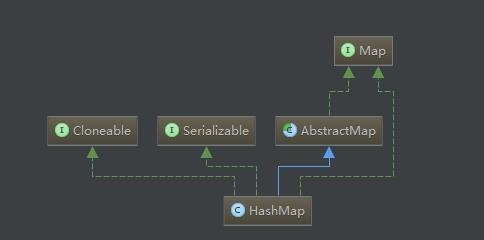
Cloneable and Serilizable interfaces, as we mentioned earlier, are declarative interfaces, and there is no way to do it.
Map interface defines the basic methods needed for data structure in the form of < key, value > mainly including storage, query, judgment of the number of elements, deletion and so on.
AbstractMap also implements Map interface, so HashMap can no longer implement Map interface. Map interface is still implemented here. Personal understanding may be the following reasons:
- Force HashMap to implement the methods declared in Map.
- It acts as a declaration that HashMap is a member of the Map family.
3. Storage structure
HashMap stores elements based on arrays. When collisions occur, the chain address method is used to solve them. Therefore, the storage structure of HashMap is the same as that of the chain address method in Section 1.
transient Entry[] table;
Entry can be understood as a node of a linked list. Its basic data structure is as follows:
static class Entry<K,V> { final K key; // key value V value; // Value value Entry<K,V> next; // Reference to the next element in the list final int hash; // hash value of element }
Here are two points to note:
- Class Entry is declared static
- The fields key and hash are declared final
An important difference between static inner classes and ordinary inner classes is that non-static attributes in external classes cannot be referenced in static inner classes, which is more secure for attributes in external classes. Therefore, when we consider using internal classes, we should try to use static internal classes whenever possible, unless attributes in external classes are needed in internal classes.
Key and hash are declared final for security reasons, i.e. key and hash values are not allowed to be modified after initialization.
These two points are worth learning.
The default length of the hash table is 16, the maximum length is 20, and the default load factor is 0.75.
static final int DEFAULT_INITIAL_CAPACITY = 16; static final int MAXIMUM_CAPACITY = 1 << 30; static final float DEFAULT_LOAD_FACTOR = 0.75f;
IV. Core Approaches
1. Construction Method
Let's first look at the most commonly used construction methods:
public HashMap() { // Set the load factor to the default value this.loadFactor = DEFAULT_LOAD_FACTOR; // Threshold of the number of elements in hash list, which exceeds the threshold, needs to be expanded threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR); // Initialize hash table table = new Entry[DEFAULT_INITIAL_CAPACITY]; init(); } void init() {}
We see that the init method is actually empty and is left to a subclass of the HasMap class to implement, such as LinkedHashMap.
Let's look at a constructor that specifies initialization parameters:
/** * Constructing HashMap by Initializing Parameters * @param initialCapacity Initial capacity * @param loadFactor Loading factor */ public HashMap(int initialCapacity, float loadFactor) { // The initial test capacity must be greater than or equal to 0. if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); // Initial capacity should not exceed the 30th power of 2 if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; // Check whether the loading factor is legal if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); // Find a value so that the value is the second power of 2 and larger than the initialization capacity int capacity = 1; while (capacity < initialCapacity) capacity <<= 1; this.loadFactor = loadFactor; threshold = (int)(capacity * loadFactor); table = new Entry[capacity]; init(); }
From the above code, we can see that the initialization capacity is always the second power of 2. Why does the length of a Hash list have to be the second power of 2? The answer to this question will be given later.
2.put method
// Store key,value in Hash list public V put(K key, V value) { // If the key is empty, it means that the key can be null. if (key == null) return putForNullKey(value); // Notice that the hash value of key is hashed again here. int hash = hash(key.hashCode()); // The location of the array to be saved for calculating the key int i = indexFor(hash, table.length); // There may already be a lot of collision elements in this location, so traversal is required. for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; // If the key to be saved is equal to the existing key, it is overwritten. if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null; } // Store null as key in hash table private V putForNullKey(V value) { for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(0, null, value, 0); return null; } // The main purpose of perturbation function is to distribute hash values more randomly into hash tables. static int hash(int h) { h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); } // Mapping hash values to a location in the hash table static int indexFor(int h, int length) { return h & (length-1); } // Add a new list element to the list header void addEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<K,V>(hash, key, value, e); // After adding new elements, if the length threshold is exceeded, the capacity will be expanded to twice the original value. if (size++ >= threshold) resize(2 * table.length); } // Capacity expansion void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; // If the maximum length has been reached before, the expansion can no longer be continued. if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } Entry[] newTable = new Entry[newCapacity]; transfer(newTable); table = newTable; threshold = (int)(newCapacity * loadFactor); } // Transfer old tables to new ones void transfer(Entry[] newTable) { Entry[] src = table; int newCapacity = newTable.length; // Traverse through each element of the old table, recalculate the position in the new table, and add it to the new table for (int j = 0; j < src.length; j++) { Entry<K,V> e = src[j]; if (e != null) { src[j] = null; do { Entry<K,V> next = e.next; int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next; } while (e != null); } } }
There are several points to be noted here:
- In put method, int hash = hash(key.hashCode()); this sentence hashes the hash value of key once again, in order to prevent the hash function of some keys from being implemented poorly, so that the hash value distribution is not uniform enough, so the original hash value is disturbed again, so that it can be more uniformly distributed to the hash table.
- The indexFor method carries out bit-by-bit and-by-bit sum, which is the reason why the length of the hash table is the second power of 2, because only the length of the hash table is the second power of 2, (length-1) will be high-order 0 and low-order 1, which is convenient for operation and operation.
3.get method
After understanding the principle of put method, let's look at get method again.
public V get(Object key) { if (key == null) return getForNullKey(); // Because hash is executed at put, get needs to be executed again to match int hash = hash(key.hashCode()); // Calculate the corresponding location of the hash table and traverse the list. If found, return for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) return e.value; } // If not found, return null return null; } // The key is a null element, if it exists, at table[0]. private V getForNullKey() { for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) return e.value; } return null; }
Reference material:
1.Static nested class in Java, why?
2.What is the hash principle of HashMap in JDK source code?