preface
As long as you know something about collections, you must know that HashMap is thread unsafe. We should use ConcurrentHashMap. But why is HashMap thread unsafe? I also encountered such problems during the previous interview, but I only stayed at the level of knowing that * * * is * * * and didn't deeply understand why * * * is * * *. So today we revisit the problem of unsafe HashMap threads.
First of all, it should be emphasized that the thread insecurity of HashMap is reflected in the problems of dead loop, data loss and data coverage. Dead loop and data loss are in jdk1 Problems in JDK1.7 8 has been solved, but there will still be data coverage in 1.8.
Thread insecurity caused by capacity expansion
The thread insecurity of HashMap mainly occurs in the capacity expansion function, that is, the root cause is in the transfer function, jdk1 The transfer function of HashMap in 7 is as follows
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
This code is the capacity expansion operation of HashMap, repositioning the subscript of each bucket, and migrating the elements to the new array by header interpolation. The head insertion method will reverse the order of the linked list, which is also the key point to form an endless loop. After understanding the header insertion method, continue to see how it causes dead circulation and data loss.
Analysis process of dead cycle and data loss caused by capacity expansion
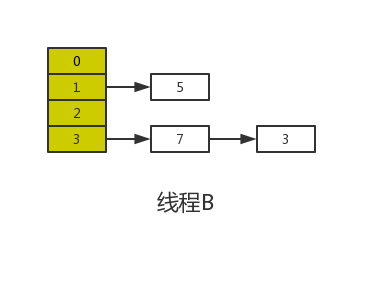
Suppose that two threads A and B expand the following HashMap at the same time:
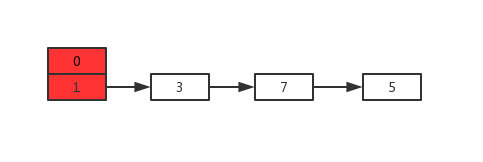
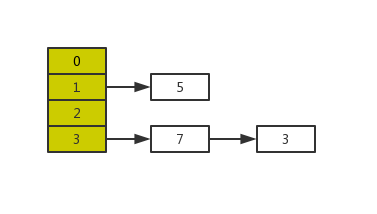
The results of normal capacity expansion are as follows:
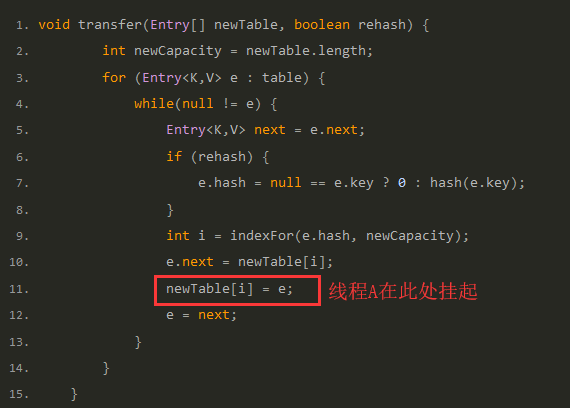
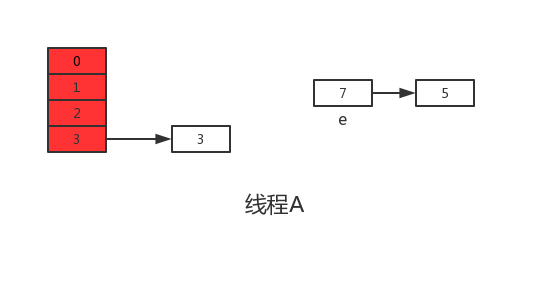
However, when thread A executes line 11 of the transfer function above, the CPU time slice runs out and thread A is suspended. As shown in the following figure:
At this time, in thread A: e=3, next=7, e.next=null
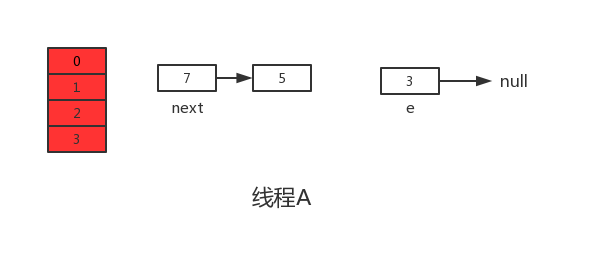
When the time slice of thread A is exhausted, the CPU starts to execute thread B and successfully completes the data migration in thread B
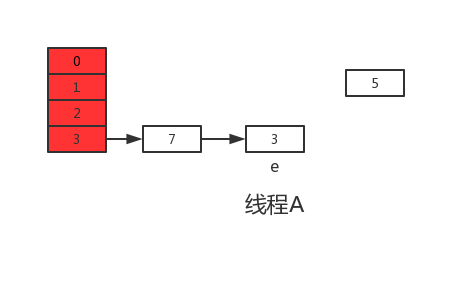
Here's the point. According to the Java memory mode, after thread B performs data migration, the newTable and table in the main memory are the latest, that is, 7 next=3,3.next=null.
Then, thread A obtains the CPU time slice, continues to execute newTable[i] = e, and puts 3 into the position corresponding to the new array. After this round of cycle, the situation of thread A is as follows:
Then continue to execute the next round of cycle. At this time, e=7. When reading e.next from the main memory, it is found that 7.0 in the main memory next=3, then next=3, and put 7 into the new array by head interpolation, and continue to execute this cycle. The results are as follows:
Execute the next cycle and find that next=e.next=null, so this cycle will be the last one. Next, when e.next=newTable[i] is executed, that is, 3 After next = 7, 3 and 7 are connected to each other. When newTable[i]=e is executed, 3 is reinserted into the linked list by header interpolation. The execution results are shown in the following figure:
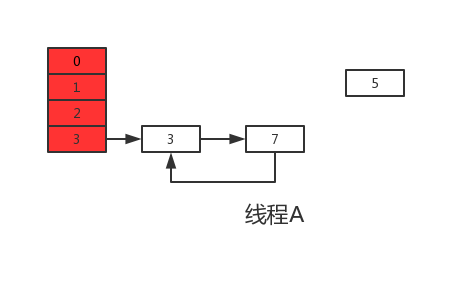
As mentioned above, at this time, e.next=null, that is, next=null. When e=null is executed, the next cycle will not be carried out. The capacity expansion operation of threads A and B is completed. Obviously, after thread A is executed, A ring structure appears in the HashMap. When the HashMap is operated in the future, an endless loop will appear.
It can be seen from the above figure that element 5 is inexplicably lost during capacity expansion, which leads to the problem of data loss.
JDK1. Thread unsafe in 8
According to jdk1 7 problems in jdk1 8 has been well solved. If you read the source code of 1.8, you will find that you can't find the transfer function because jdk1 8. The data migration is completed directly in the resize function. Another word, jdk1 8 tail interpolation is used in element insertion.
Why jdk1 8. There will be data coverage. Let's take a look at the following jdk1 put operation code in 8:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // If there is no hash collision, insert the element directly
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
The sixth line of code is to judge whether hash collision occurs. Assuming that both threads A and B are put ting, and the insertion subscript calculated by the hash function is the same, thread A is suspended due to the depletion of time slice after executing the sixth line of code, while thread B inserts elements at the subscript after obtaining the time slice, completes the normal insertion, and then thread A obtains the time slice, Since the hash collision has been judged before, all users will not judge at this time, but directly insert, which leads to the data inserted by thread B being overwritten by thread A, so the thread is unsafe.
In addition, there is A + + size at line 38 of the code. We think so. It is still threads A and B. when these two threads carry out put operation at the same time, it is assumed that the zise size of the current HashMap is 10. When thread A executes the code at line 38, it obtains the size value of 10 from the main memory and is ready for + 1 operation. However, due to the depletion of time slices, it has to give up the CPU, Thread B happily gets the CPU or gets the value of size 10 from the main memory for + 1 operation, completes the put operation and writes size=11 back to the main memory, and then thread A gets the CPU again and continues to execute (at this time, the value of size is still 10). After the put operation is completed, thread A and thread B still write size=11 back to the memory. At this time, both threads A and B perform A put operation, but the value of size is only increased by 1, All this is because data coverage leads to thread insecurity.
summary
The thread insecurity of HashMap is mainly reflected in the following two aspects:
1. At jdk1 In 7, when the capacity expansion operation is performed concurrently, the ring chain and data loss will be caused.
2. At jdk1 In 8, data coverage occurs when put operations are performed concurrently.